BAB I
PENDAHULUAN
1.1 Deskripsi Permasalahan
Setiap perusahaan, apakah perusahaan itu perusahaan perdagangan ataupun perusahaan pabrik serta perusahaan jasa selalu mengadakan persediaan. Tanpa adanya persediaan, para pengusaha akan dihadapkan pada resiko bahwa perusahaannya pada suatu waktu tidak dapat memenuhi keinginan pelanggan yang memerlukan atau meminta barang/jasa. Persediaan diadakan apabila keuntungan yang diharapkan dari persediaan tersebut hendaknya lebih besar daripada biaya-biaya yang ditimbulkannya. Sebelum dijelaskan tentang pengertian persediaan, perlu dijelaskan juga bahwa istilah persediaan sama dengan istilah inventory. Persediaan merupakan bagian utama dari modal kerja, sebab dilihat dari jumlahnya biasanya persediaan inilah unsur kerja yang paling besar. Hal ini dapat dipahami karena persediaan merupakan faktor penting dalam menentukan kelancaran operasi perusahaan. Tanpa ada persediaan yang memadai kemungkinan perusahaan tidak bisa mendapatkan keuntungan yang diinginkan sebab proses produksi terganggu. Jadi persediaan merupakan sejumlah barang yang disediakan untuk memenuhi permintaan dari pelanggan. Dalam perusahaan perdagangan pada dasarnya hanya ada satu golongan inventory (persediaan), yang mempunyai sifat perputaran yang sama yaitu yang disebut “Merchandise Inventory” (persediaan barang dagangan). Persediaan ini merupakan persediaan barang yang selalu dalam perputaran, yang selalu dibeli dan dijual, yang tidak mengalami proses lebih lanjut didalam perusahaan tersebut yang mengakibatkan perubahan bentuk dari barang yang bersangkutan. (www.transformasi.net)
memenuhi keinginan dari para pelanggannya. Tentu saja kenyataan ini dapat berakibat buruk bagi perusahaan, karena secara tidak langsung perusahaan menjadi kehilangan kesempatan untuk memperoleh keuntungan yang seharusnya didapatkan. Dalam hal ini yang meliputi barang-barang milik perusahaan dengan maksud untuk dijual dalam suatu periode waktu tertentu atau persediaan barang-barang yang masih dalam pengerjaan atau proses produksi, ataupun persediaan bahan baku yang menunggu penggunaannya dalam suatu proses produksi Oleh karena itu persediaan sebaiknya dapat dikelola dengan baik. (www.pengusahamuslim.com)
Salah satu yang cukup penting berkaitan dengan persediaan adalah masalah biaya yang berkaitan dengan persediaan. Hal ini penting untuk diperhatikan karena akan berpengaruh lansung kepada nilai persediaan dan harga jual ke konsumen nantinya. Bukan tidak mungkin karena salah dalam mengelolah akan berakibat harga jual akan meningkat. Untuk itu perlu diketahui dulu biaya-biaya yang berkaitan dengan persediaan. Sedangkan biaya-biaya yang berkaitan dengan persediaan dapat dikelompokkan kedalam klasifikasi biaya antara lain pengelolaan sediaan, kekurangan sediaan, dan pemesanan dan penerimaan sediaan. Dari ketiga klasifikasi ini akan mengakibatkan tiga jenis baya sediaan, yaitu biaya pengelolaan (pemeliharaan), biaya pesan, dan total biaya sediaan. (Kasmir, 2010) Dalam penelitian ini ada 5 faktor yang mempengaruhi dalam peningkatan total inventory cost PT. ART yaitu persediaan awal, kuantitas pesan, leadtime, frekuensi, pemesanan, dan safety stock. Dengan pendekatan data mining yaitu menggunakan metode decision tree dan naive bayes akan dibuatkan model prediksi dimana model tersebut berfungsi sebagai prediksi dari status inventory cost. Decision tree digunakan untuk membagi kumpulan data yang besar menjadi himpunan-himpunan data yang lebih kecil dan naive bayes sendiri digunakan untuk menentukan probabilitas terjadinya peristiwa dimasa depan berdasarkan data yang telah ada sebelumnya.
Hery Purnomo yang memiliki judul “Pemetaan Kecelakaan Lalu Lintas Berbasis Klasifikasi Naive Bayes dengan Parameter Infrastruktur Jalan” perbedaan antara penelitian kami dengan penelitian ini yaitu pada penelitian ini hanya menggunakan naive bayes saja dan diterapkan untuk memetakan kecelakaan lalu lintas. Tujuan dari penelitian tersebut yaitu untuk memetakan kecelakaan lalu lintas yang terjadi dengan parameter infrastruktur di jalan itu sendir sedangkan hasil dari penelitian tersebut yaitu prediksi dengan Naive Bayes menunjukan bahwa tingkat akurasi rata-rata berkisar antara 29.3653% sampai dengan 78.0415%, ini menunjukan bahwa tidak semua infrastruktur jalan bisa digunakan sebagai parameter sebuah kecelakaan terjadi karena masih ada hasil prediksi yang berada di bawah 50%. Namun ini bukan merupakan hasil final yang langsung diimplementasikan. Prediksi kecelakaan lalu lintas ini masih merupakan penelitian yang sedang berjalan dan belum sepenuhnya selesai. Selain infrastruktur jalan, masih ada hal lain yang menjadi target, antara lain dari sisi kendaraan yang mengalami kecelakaan, manusia yang mengemudikan kendaraan tersebut, dan cuaca dimana kecelakaan itu terjadi. Penelitian lebih lanjut sangat diperlukan untuk melihat seberapa besar korelasi antara target-target tersebut dengan kecelakaan lalu lintas.
Bayes menghasilkan akurasi 99.9799 %. Berdasarkan uji coba yang telah dilakukan, diperoleh bahwa Decision Tree J48 memberikan hasil akurasi sedikit lebih baik dari Naive Bayes dengan selisih akurasi 0,0189%. Namun demikian, secara umum metode Decision Tree dan Naive Bayes sama-sama memiliki akurasi yang baik dalam melakukan klasifikasi kemiripan data pasien.
1.2 Rumusan Masalah
Rumusan masalah pada penelitian ini adalah:
1. Bagaimanakah hasil rule yang terbentuk dari analisis klasifikasi pada peningkatan total inventory cost menggunakan algoritma Decision Tree dan Naïve Bayes?
2. Bagaimana perbandingan hasil prediksi menggunakan algoritma Decision Tree dan Naïve Bayes?
1.3 Tujuan Penelitian
Tujuan penelitian pada penelitian ini adalah:
1. Untuk mengetahui hasil rule yang terbentuk dari analisis klasifikasi pada peningkatan total inventory cost menggunakan algoritma Decision Tree dan Naïve Bayes.
BAB II
TINJAUAN PUSTAKA
2.1 Kajian Deduktif 2.1.1 Klasifikasi
Klasifikasi menurut Bertalya (2009) adalah suatu proses untuk menyatakan suatu objek ke salah satu kategori yang sudah didefinisikan sebelumnya. Proses pembelajaran fungsi target (model klasifikasi) yang memetakan setiap sekumpulan atribut x (input) ke salah satu klas y yang didefinisikan sebelumnya. Inputnya adalah sekumpulan record (training set) dari setiap record tersebut terdiri atas sekumpulan atribut, salah satu atribut adalah klas. Mencari model utk atribut klas sebagai fungsi dari nilai-nilai untuk atribut yang lain. Model klasifikasi digunakan untuk:
1. Pemodelan deskriptif sebagai perangkat penggambaran untuk membedakan objek-objek dari klas berbeda.
2. Pemodelan prediktif digunakan untuk memprediksi label klas untuk record yang tidak diketahui atau tidak dikenal.
Klasifikasi dalam data mining bekerja pada data historis atau data sejarah. Data historis disebut data latihan atau training data. Histori data digunakan sebagai cara mendapatkan pengetahuan dan disebut data pengalaman. Secara sederhana ada 3 proses pemecahan masalah klasifikasi diantaranya:
1. Data historis atau data pengalaman
2. Data historis akan diproses menggunakan algoritma klasifikasi
3. Klassifikasi menghasilkan pengetahuan yang dipresentasikan dalam bentuk diagram pohon keputusan”decission tree”.
Tahapan dari klasifikasi dalam data mining terdiri dari:
dihadapi, training set ini sudah mempunyai informasi yang lengkap baik attribut maupun classnya.
2. Penerapan model, pada tahapan ini model yang sudah dibangun sebelumnya digunakan untuk menentukan attribut / class dari sebuah data baru yang attribut / class-nya belum diketahui sebelumnya.
3. Evaluasi, pada tahapan ini hasil dari penerapan model pada tahapan sebelumnya dievaluasi menggunakan parameter terukur untuk menentukan apakah model tersebut dapat diterima.
2.1.2 Decision Tree
Decision Tree adalah sebuah struktur pohon, dimana setiap node pohon merepresentasikan atribut yang telah diuji, setiap cabang merupakan suatu pembagian hasil uji, dan node daun (leaf) merepresentasikan kelompok kelas tertentu. Level node teratas dari sebuah Decision Tree adalah node akar (root) yang biasanya berupa atribut yang paling memiliki pengaruh terbesar pada suatu kelas tertentu. Pada umumnya Decision Tree melakukan strategi pencarian secara top-down untuk solusinya. Pada proses mengklasifikasi data yang tidak diketahui, nilai atribut akan diuji dengan cara melacak jalur dari node akar (root) sampai node akhir (daun) dan kemudian akan diprediksi kelas yang dimiliki oleh suatu data baru tertentu. Secara singkat bahwa Decision Tree merupakan salah satu metode klasifikasi pada Text Mining. Klasifikasi adalah proses menemukan kumpulan pola atau fungsi-fungsi yang mendeskripsikan dan memisahkan kelas data satu dengan lainnya, untuk dapat digunakan untuk memprediksi data yang belum memiliki kelas data tertentu (Jianwei Han, 2001).
Jika suatu set data mempunyai beberapa pengamatan dengan missing value yaitu record dengan beberapa nilai variabel tidak ada, Jika jumlah pengamatan terbatas maka atribut dengan missing value dapat diganti dengan nilai rata-rata dari variabel yang bersangkutan. (Santosa, 2007)
perlu menghitung dulu nilai informasi dalam satuan bits dari suatu kumpulan objek. Cara menghitungnya dilakukan dengan menggunakan konsep entropy.
Gambar 2.1 Rumus Entropy
Kemudian menghitung perolehan informasi dari output data atau variabel dependent y yang dikelompokkan berdasarkan atribut A, dinotasikan dengan gain (y,A). Perolehan informasi, gain (y,A), dari atribut A relative terhadap output data y adalah:
Gambar 2.2 Rumus Information Gain
nilai (A) adalah semua nilai yang mungkin dari atribut A, dan yc adalah subset dari y dimana A mempunyai nilai c. Term pertama dalam persamaan diatas adalah entropy total y dan term kedua adalah entropy sesudah dilakukan pemisahan data berdasarkan atribut A.
2.1.3 Naïve Bayes
Teorema Bayes dikemukakan oleh seorang pendeta presbyterian Inggris pada tahun 1763 yang bernama Thomas Bayes. Teorema Bayes digunakan untuk menghitung probabilitas terjadinya suatu peristiwa berdasarkan pengaruh yang didapat dari hasil observasi. Algoritma bayes mempelajari kejadian-kejadian dari rekaman database dengan cara memperhitungkan korelasi antara variabel yang dianalisa dengan variabel-variabel lainnya. Hasilnya adalah kita dapat memprediksi sesuatu, misalnya apakah seseorang berasal dari golongan tertentu berdasarkan variabel-variabel yang melekat padanya. Selain itu, naive bayes dapat juga menganalisa variabel-variabel yang paling mempengaruhinya dalam bentuk peluang. (Olson Delen, 2008)
2. Kokoh untuk titik noise yang diisolasi, misalkan titik yang dirata – ratakan ketika mengestimasi peluang bersyarat data.
3. Hanya memerlukan sejumlah kecil data pelatihan untuk mengestimasi parameter (rata-rata dan variansi dari variabel) yang dibutuhkan untuk klasifikasi.
4. Menangani nilai yang hilang dengan mengabaikan instansi selama perhitungan estimasi peluang.
5. Cepat dan efisiensi ruang.
6. Kokoh terhadap atribut yang tidak relevan. Kekurangan Naive Bayesian :
1. Tidak berlaku jika probabilitas kondisionalnya adalah nol, apabila nol maka probabilitas prediksi akan bernilai nol juga.
2. Mengasumsikan variabel bebas.
2.2 Kajian Induktif
mengemudikan kendaraan tersebut, dan cuaca dimana kecelakaan itu terjadi. Penelitian lebih lanjut sangat diperlukan untuk melihat seberapa besar korelasi antara target-target tersebut dengan kecelakaan lalu lintas.
BAB III
METODE PENELITIAN
3.1 Objek Penelitian
Pada penelitian ini tempat yang dijadikan objek penelitian yaitu sebuah perusahaan yang bernama PT. ART
3.2 Metode Pengumpulan Data
Metode pengumpulan data yang digunakan dalam penelitian ini adalah penelitian observasi kemudian hasil dari data yang telah didapatkan asisten pembimbing memberikannya kepada praktikan.
3.3 Jenis Data
3.4 Alur Penelitian
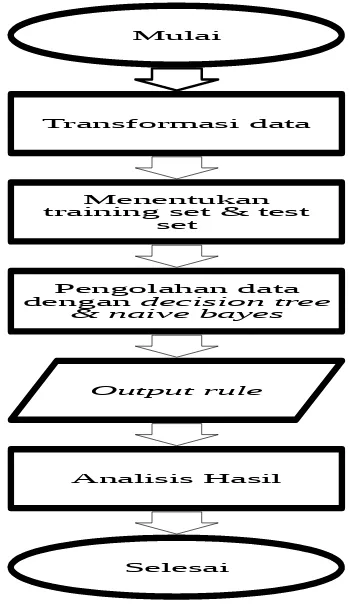
Gambar 3.1 Diagram Alur Penelitian Mulai
Transformasi data
Menentukan
training set & test set
Pengolahan data dengan decision tree
& naive bayes
Output rule
Analisis Hasil
Penjelasan dari diagram alir diatas adalah sebagai berikut:
1. Memulai penelitian dengan melakukan transformasi data sehingga akan didapatkan data yang sudah dikurangi tingkat komplektisitasnya yang kemudian akan memudahkan proses pengolahan karena ukuran data yang diproses sudah menjadi lebih kecil.
2. Melakukan pemilihan training set dan test set yaitu dari 100 data yang ada 1-50 dijadikan sebagai training set sedangkan sisanya 51-100 dijadikan sebagai test set.
3. Setelah itu dilanjutkan untuk pengolahan data dimana yang pertama melakukan pengolahan algoritma decision tree secara manual dengan menggunakan software Ms. Excel dan kemudian secara otomatis untuk decision tree dan naive bayes dengan bantuan software Rapid Miner.
4. Hasil dari pengolahan data yang sudah dilakukan akan ditentukan rule yang terbentuk untuk memberikan suatu keputusan dari kedua algoritma.
BAB IV
HASIL DAN PEMBAHASAN
4.1 Prepocessing Data 4.1.1 Data Historis
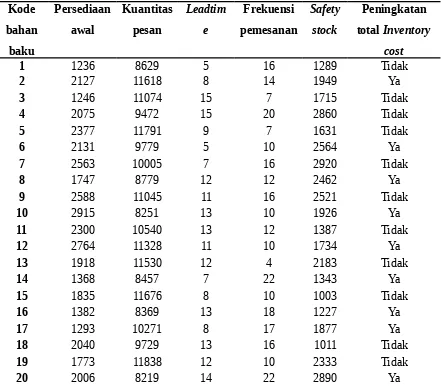
Berdasarkan studi kasus yang diberikan menyangkut prediksi status Inventory cost pada PT. ART apakah terjadi peningkatan atau tidak berdasarkan 5 faktor utama seperti persediaan awal, kuantitas pesan, leadtime, frekuensi pemesanan dan safety stock diketahui data hsitoris seperti pada tabel berikut
Tabel 4. 1 Data Historis
Kode
1 1236 8629 5 16 1289 Tidak
2 2127 11618 8 14 1949 Ya
3 1246 11074 15 7 1715 Tidak
4 2075 9472 15 20 2860 Tidak
5 2377 11791 9 7 1631 Tidak
6 2131 9779 5 10 2564 Ya
7 2563 10005 7 16 2920 Tidak
8 1747 8779 12 12 2462 Ya
9 2588 11045 11 16 2521 Tidak
10 2915 8251 13 10 1926 Ya
11 2300 10540 13 12 1387 Tidak
12 2764 11328 11 10 1734 Ya
13 1918 11530 12 4 2183 Tidak
14 1368 8457 7 22 1343 Ya
15 1835 11676 8 10 1003 Tidak
16 1382 8369 13 18 1227 Ya
17 1293 10271 8 17 1877 Ya
18 2040 9729 13 16 1011 Tidak
19 1773 11838 12 10 2333 Tidak
Kode
22 1721 11234 8 5 1946 Tidak
23 2973 10616 14 20 2522 Ya
24 1058 11772 15 13 2088 Tidak
25 1516 11780 15 20 2779 Ya
26 2704 11883 8 5 2658 Tidak
27 1779 9364 8 6 2192 Tidak
28 2480 9788 12 16 2939 Tidak
29 1554 9076 7 5 2915 Tidak
30 2770 8328 9 16 2814 Ya
31 2413 8597 6 11 1325 Ya
32 2425 9035 8 9 1776 Ya
33 1445 11755 10 16 2897 Ya
34 1637 9750 5 9 1802 Ya
35 2890 10646 6 13 1633 Tidak
36 1904 9276 5 11 1522 Ya
37 2570 10782 12 20 1957 Ya
38 1874 10207 7 16 2622 Ya
39 2683 8471 9 5 1628 Tidak
40 2150 9351 12 10 1540 Ya
41 1862 10083 10 15 1864 Tidak
42 1568 8514 5 17 1533 Ya
43 1313 10641 13 7 1983 Tidak
44 1501 11225 15 14 2343 Tidak
45 2501 9770 8 16 1214 Tidak
46 1924 8817 15 15 1752 Tidak
47 2734 11411 15 16 1803 Ya
48 2140 11770 15 16 2180 Tidak
49 2234 11314 13 11 2352 Tidak
50 1227 9187 11 15 1406 Tidak
51 1581 8699 15 17 2146 Ya
52 1476 9056 9 6 1382 Ya
53 1538 11970 6 16 1066 Tidak
54 1749 10668 12 5 2602 Ya
Kode
56 2795 8424 10 22 1557 Tidak
57 1151 11756 15 4 2165 Ya
58 1214 11013 9 8 2562 Tidak
59 2594 8689 12 9 2702 Tidak
60 1734 8315 8 11 1824 Tidak
61 2922 10255 11 12 2716 Tidak
62 2128 10547 8 4 1641 Ya
63 2564 9632 15 6 2506 Ya
64 1194 8366 12 20 2952 Ya
65 1633 11040 6 16 1145 Tidak
66 1231 9073 14 10 2409 Tidak
67 2370 10325 13 14 2662 Ya
68 1157 8010 5 15 2001 Tidak
69 2600 9552 14 6 1928 Tidak
70 2998 11122 6 12 2787 Ya
71 2734 10176 15 13 2491 Tidak
72 2812 9893 13 13 2645 Ya
73 1009 10187 11 7 2484 Ya
74 2569 11076 6 13 1790 Ya
75 2000 9709 10 16 1370 Tidak
76 2143 10482 5 16 1944 Tidak
77 2928 11804 8 15 1706 Ya
78 2582 8116 13 5 1757 Tidak
79 1886 11891 13 9 1102 Tidak
80 1221 10254 5 15 1297 Ya
81 2526 9721 10 15 1735 Ya
82 1803 9476 14 13 2188 Tidak
83 2331 8323 14 7 1901 Tidak
84 2753 9840 14 13 1816 Tidak
85 2808 8673 13 20 2556 Ya
86 2591 9968 10 16 2188 Tidak
87 1308 8165 15 7 1455 Ya
88 2850 11852 13 9 2044 Ya
89 1564 11080 5 20 2383 Ya
Kode
91 1064 9530 7 12 2699 Tidak
92 2467 10703 6 17 1794 Tidak
93 1370 10462 10 10 2924 Ya
94 1775 8105 12 7 2905 Tidak
95 1864 8956 5 16 1910 Tidak
96 2816 11630 5 16 2219 Ya
97 1737 11569 7 12 2379 Tidak
98 1087 9278 12 16 2421 Tidak
99 2477 9790 12 11 2150 Ya
100 2772 11168 12 22 2393 Ya
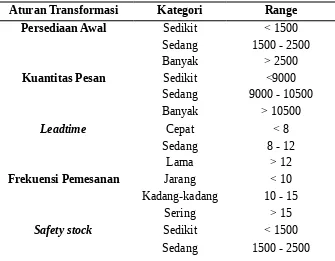
4.1.2 Transformasi Data
Untuk memproses data menjadi training set maka diperlukan transformasi data berdasarkan aturan transformasi yang diberikan pada studi kasus seperti pada tabel berikut
Tabel 4. 2 Aturan Trasnformasi
Aturan Transformasi Kategori Range Persediaan Awal Sedikit < 1500
Sedang 1500 - 2500
Frekuensi Pemesanan Jarang < 10 Kadang-kadang 10 - 15
Sering > 15
Safety stock Sedikit < 1500
Banyak > 2500
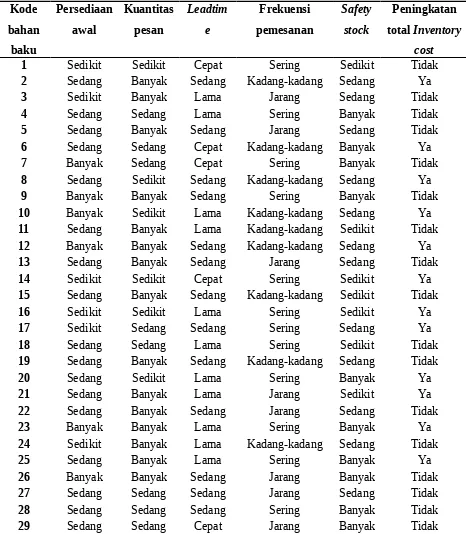
Dari aturan yang telah diberikan maka didapatkan transformasi data seperti pada tabel berikut
Tabel 4. 3 Data Transformasi
Kode
1 Sedikit Sedikit Cepat Sering Sedikit Tidak
2 Sedang Banyak Sedang Kadang-kadang Sedang Ya
3 Sedikit Banyak Lama Jarang Sedang Tidak
4 Sedang Sedang Lama Sering Banyak Tidak
5 Sedang Banyak Sedang Jarang Sedang Tidak
6 Sedang Sedang Cepat Kadang-kadang Banyak Ya
7 Banyak Sedang Cepat Sering Banyak Tidak
8 Sedang Sedikit Sedang Kadang-kadang Sedang Ya
9 Banyak Banyak Sedang Sering Banyak Tidak
10 Banyak Sedikit Lama Kadang-kadang Sedang Ya
11 Sedang Banyak Lama Kadang-kadang Sedikit Tidak
12 Banyak Banyak Sedang Kadang-kadang Sedang Ya
13 Sedang Banyak Sedang Jarang Sedang Tidak
14 Sedikit Sedikit Cepat Sering Sedikit Ya
15 Sedang Banyak Sedang Kadang-kadang Sedikit Tidak
16 Sedikit Sedikit Lama Sering Sedikit Ya
17 Sedikit Sedang Sedang Sering Sedang Ya
18 Sedang Sedang Lama Sering Sedikit Tidak
19 Sedang Banyak Sedang Kadang-kadang Sedang Tidak
20 Sedang Sedikit Lama Sering Banyak Ya
21 Sedang Banyak Lama Jarang Sedikit Ya
22 Sedang Banyak Sedang Jarang Sedang Tidak
23 Banyak Banyak Lama Sering Banyak Ya
24 Sedikit Banyak Lama Kadang-kadang Sedang Tidak
25 Sedang Banyak Lama Sering Banyak Ya
26 Banyak Banyak Sedang Jarang Banyak Tidak
27 Sedang Sedang Sedang Jarang Sedang Tidak
28 Sedang Sedang Sedang Sering Banyak Tidak
30 Banyak Sedikit Sedang Sering Banyak Ya
31 Sedang Sedikit Cepat Kadang-kadang Sedikit Ya
32 Sedang Sedang Sedang Jarang Sedang Ya
33 Sedikit Banyak Sedang Sering Banyak Ya
34 Sedang Sedang Cepat Jarang Sedang Ya
35 Banyak Banyak Cepat Kadang-kadang Sedang Tidak
36 Sedang Sedang Cepat Kadang-kadang Sedang Ya
37 Banyak Banyak Sedang Sering Sedang Ya
38 Sedang Sedang Cepat Sering Banyak Ya
39 Banyak Sedikit Sedang Jarang Sedang Tidak
40 Sedang Sedang Sedang Kadang-kadang Sedang Ya
41 Sedang Sedang Sedang Kadang-kadang Sedang Tidak
42 Sedang Sedikit Cepat Sering Sedang Ya
43 Sedikit Banyak Lama Jarang Sedang Tidak
44 Sedang Banyak Lama Kadang-kadang Sedang Tidak
45 Banyak Sedang Sedang Sering Sedikit Tidak
46 Sedang Sedikit Lama Kadang-kadang Sedang Tidak
47 Banyak Banyak Lama Sering Sedang Ya
48 Sedang Banyak Lama Sering Sedang Tidak
49 Sedang Banyak Lama Kadang-kadang Sedang Tidak
50 Sedikit Sedang Sedang Kadang-kadang Sedikit Tidak
51 Sedang Sedikit Lama Sering Sedang Ya
52 Sedikit Sedang Sedang Jarang Sedikit Ya
53 Sedang Banyak Cepat Sering Sedikit Tidak
54 Sedang Banyak Sedang Jarang Banyak Ya
55 Banyak Sedikit Cepat Jarang Sedang Tidak
56 Banyak Sedikit Sedang Sering Sedang Tidak
57 Sedikit Banyak Lama Jarang Sedang Ya
58 Sedikit Banyak Sedang Jarang Banyak Tidak
59 Banyak Sedikit Sedang Jarang Banyak Tidak
60 Sedang Sedikit Sedang Kadang-kadang Sedang Tidak
61 Banyak Sedang Sedang Kadang-kadang Banyak Tidak
62 Sedang Banyak Sedang Jarang Sedang Ya
63 Banyak Sedang Lama Jarang Banyak Ya
64 Sedikit Sedikit Sedang Sering Banyak Ya
65 Sedang Banyak Cepat Sering Sedikit Tidak
66 Sedikit Sedang Lama Kadang-kadang Sedang Tidak
68 Sedikit Sedikit Cepat Kadang-kadang Sedang Tidak
69 Banyak Sedang Lama Jarang Sedang Tidak
70 Banyak Banyak Cepat Kadang-kadang Banyak Ya
71 Banyak Sedang Lama Kadang-kadang Sedang Tidak
72 Banyak Sedang Lama Kadang-kadang Banyak Ya
73 Sedikit Sedang Sedang Jarang Sedang Ya
74 Banyak Banyak Cepat Kadang-kadang Sedang Ya
75 Sedang Sedang Sedang Sering Sedikit Tidak
76 Sedang Sedang Cepat Sering Sedang Tidak
77 Banyak Banyak Sedang Kadang-kadang Sedang Ya
78 Banyak Sedikit Lama Jarang Sedang Tidak
79 Sedang Banyak Lama Jarang Sedikit Tidak
80 Sedikit Sedang Cepat Kadang-kadang Sedikit Ya
81 Banyak Sedang Sedang Kadang-kadang Sedang Ya
82 Sedang Sedang Lama Kadang-kadang Sedang Tidak
83 Sedang Sedikit Lama Jarang Sedang Tidak
84 Banyak Sedang Lama Kadang-kadang Sedang Tidak
85 Banyak Sedikit Lama Sering Banyak Ya
86 Banyak Sedang Sedang Sering Sedang Tidak
87 Sedikit Sedikit Lama Jarang Sedikit Ya
88 Banyak Banyak Lama Jarang Sedang Ya
89 Sedang Banyak Cepat Sering Sedang Ya
90 Sedang Banyak Sedang Jarang Sedang Ya
91 Sedikit Sedang Cepat Kadang-kadang Banyak Tidak
92 Sedang Banyak Cepat Sering Sedang Tidak
93 Sedikit Sedang Sedang Kadang-kadang Banyak Ya
94 Sedang Sedikit Sedang Jarang Banyak Tidak
95 Sedang Sedikit Cepat Sering Sedang Tidak
96 Banyak Banyak Cepat Sering Sedang Ya
97 Sedang Banyak Cepat Kadang-kadang Sedang Tidak
98 Sedikit Sedang Sedang Sering Sedang Tidak
99 Sedang Sedang Sedang Kadang-kadang Sedang Ya
100 Banyak Banyak Sedang Sering Sedang Ya
4.2 If-Then Rule dari Hasil Klasifikasi 4.2.1 Decision tree
Dari hasil pengolahan data training-set menggunakan Microsoft Excel maka didapatkan hasil perhitungan information gain, rule, pohon keputusan, dan akurasi prediksi seperti pada output output berikut
Perhitungan RootNode
Tabel 4. 4 Perhitungan Atribut Persediaan Awal untuk Roor Node
Persedia
Sedikit Tidak 5 9 Q
1
Sedang Tidak 16 29 Q
2
0.9922 67
Iya 13
Banyak Tidak 6 12 Q
3 1
Iya 6
Total 50
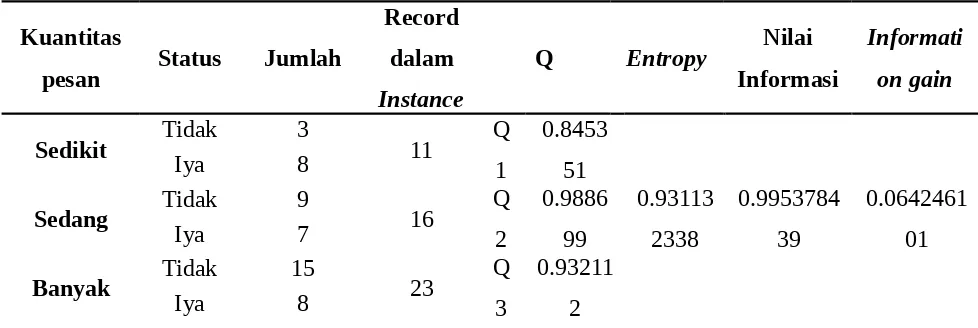
Tabel 4. 5 Perhitungan Atribut Kuantitas Pesan untuk Root Node
Kuantitas
Sedikit Tidak 3 11 Q
1
Sedang Tidak 9 16 Q
2
0.9886 99
Iya 7
Banyak Tidak 15 23 Q
3
0.93211 2
Total 50
Tabel 4. 6 Perhitungan Atribut Leadtime untuk Root Node
Leadtime Status Jumlah
Sedang Tidak 13 22 Q
2
Tabel 4. 7 Perhitungan Atribut Frekuensi Pesan untuk Root Node
Frekuensi
Jarang Tidak 9 12 Q
1
Sering Tidak 8 20 Q
3
0.970 951
Iya 12
Total 50
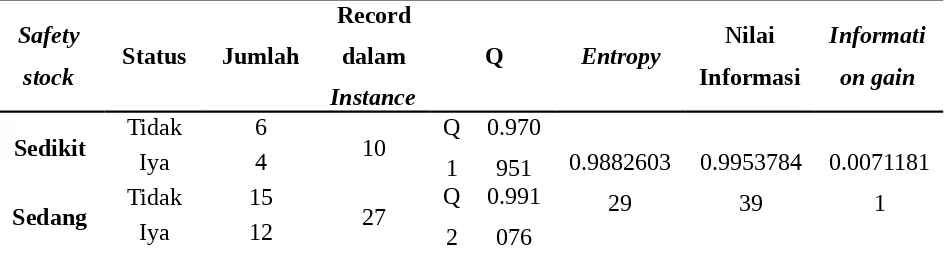
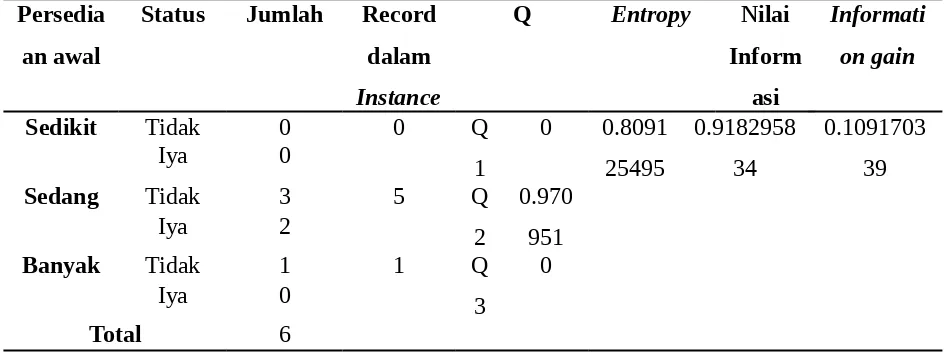
Tabel 4. 8 Perhitungan Atribut Safety stock untuk Root Node
Safety
Sedikit Tidak 6 10 Q
1
Sedang Tidak 15 27 Q
2
0.991 076
Banyak Tidak 6 13 Q
Dari hasil perhitungan root node diatas diketahui bahwa atribut kuantitas pesan mempunyai nilai information gain yang paling besar dengan nilai sebesar 0.064246101 sehingga atribut kuantitas pesan menjadi root node dari pohon keputusan yang terbentuk.
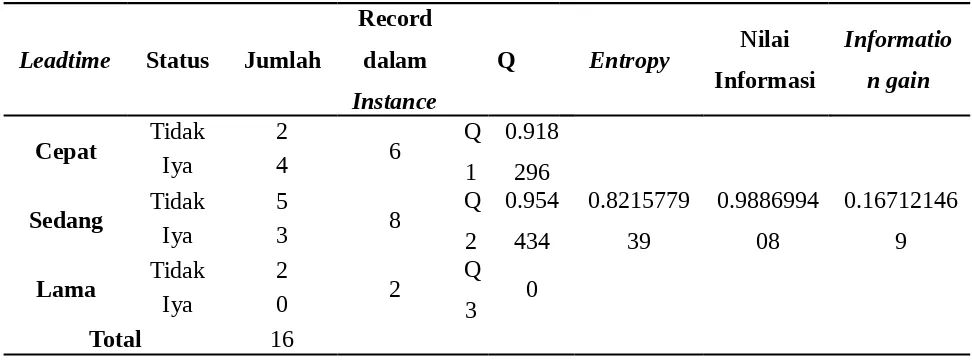
Perhitungan Internal Node 1
Tabel 4. 9 Perhitungan Atribut Persediaan Awal untuk InternalNode 1
Persediaan
Sedikit Tidak 1 2 Q
1 1
Sedang Tidak 6 12 Q
2 1
Tabel 4. 10 Perhitungan Atribut Leadtime untuk InternalNode 1
Tabel 4. 11 Perhitungan Atribut Frekuensi Pemesanan untuk InternalNode 1
Sering Tidak 5 7 Q3 0.863121
Iya 2
Total 16
Tabel 4. 12 Perhitungan Atribut Safety stock untuk InternalNode 1
Safety stock Status Jumlah
Sedang Tidak 2 7 Q2 0.863121
Iya 5
Banyak Tidak 4 6 Q3 0.918296
Iya 2
Total 16
Dari hasil perhitungan internal node 1 diatas diketahui bahwa atribut safety stock mempunyai nilai information gain yang paling besar yaitu dengan nilai sebesar 0.266723222 sehingga safety stock menjadi internal node pertama dari pohon keputusan yang terbentuk.
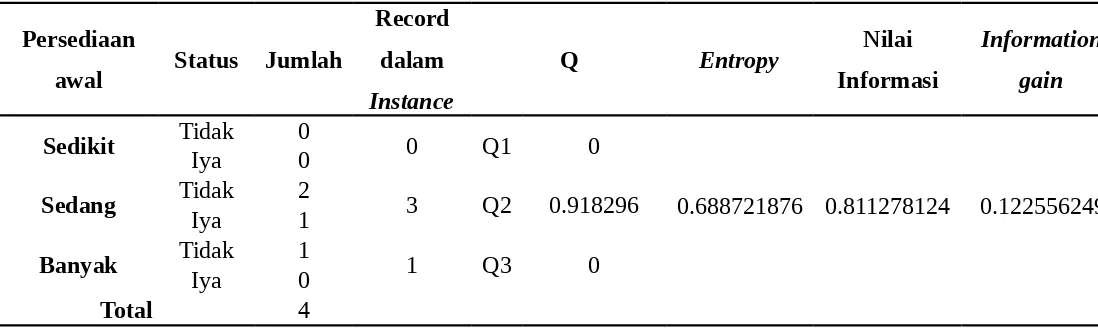
Tabel 4. 13 Perhitungan Atribut Persediaan Awal untuk InternalNode 2
Sedikit Tidak 0 0 Q
1
Tabel 4. 14 Perhitungan Atribut Leadtime untuk InternalNode 2
Leadtime Status Jumlah Record
Tabel 4. 15 Perhitungan Atribut Frekuensi Pemesanan untuk InternalNode 2
Frekuensi
Sering Tidak 3 4 Q3 0.811278
Iya 1
Dari hasil perhitungan internal node 2 diatas diketahui bahwa atribut frekuensi pemesanan mempunyai nilai information gain yang paling besar yaitu dengan nilai sebesar 0.377443751sehingga frekuensi pemesanan menjadi internal node kedua dari pohon keputusan yang terbentuk.
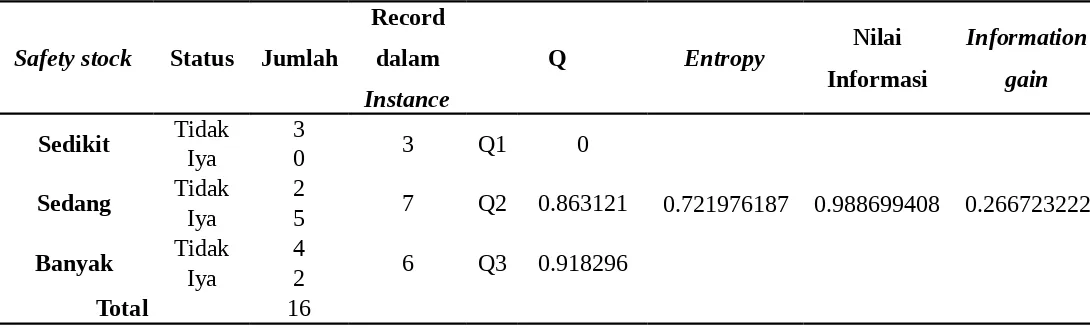
Perhitungan Internal Node 3
Tabel 4. 16 Perhitungan Atribut Persediaan Awal untuk InternalNode 3
Persediaan
Sedang Tidak 2 3 Q2 0.918296
Iya 1
Banyak Tidak 1 1 Q3 0
Iya 0
Total 4
Tabel 4. 17 Perhitungan Atribut Leadtime untuk InternalNode 3
Leadtime Status Jumlah
Record dalam Instance
Q Entropy InformasiNilai Informationgain
Perhitungan Leaf Node
Tabel 4. 18 Perhitungan Atribut Persediaan Awal untuk InternalNode 3
Persediaan
Setelah tahap perhitungan untuk menentukan root node, internal node, dan leaf node selesai dilakukan maka akan didapatkan rule rule yang nantinya akan menjadi panduan kita dalam membuat pohon keputusan dari data yang diolah. Hasil rule yang didapat adalah sebagai berikut
Hasil Rule yang Terbentuk
1. R1= if(kuantitas pesan="Sedikit","Iya"
Dari rule ini diketahui bahwa jika kuantitas pesan sedikit maka status inventory cost akan meningkat.
2. R2= if(kuantitas pesan="Banyak","Tidak"
Dari rule ini diketahui bahwa jika kuantitas pesan banyak maka status inventory cost tidak meningkat.
3. R3= if((kuantitas pesan="Sedang")*(Safety stock="Sedikit"),"Tidak"
Dari rule ini diketahui bahwa jika kuantitas pesan sedang dan safety stock sedikit maka status inventory cost tidak meningkat.
Dari rule ini diketahui bahwa jika kuantitas pesan sedang dan safety stock sedang maka status inventory cost akan meningkat.
5. R5= if((kuantitas pesan="Sedang")*(safety stock="Banyak")*(Frekuensi pemesanan="Jarang"),"Tidak"
Dari rule ini diketahui bahwa jika kuantitas pesan sedang, safety stock banyak, dan frekuensi pemesanan jarang maka status inventory cost tidak meningkat.
6. R6= if((kuantitas pesan="Sedang"*(Safety stock="Banyak")*(Frekuensi pemesanan="Kadang-kadang"),"Iya"
Dari rule ini diketahui bahwa jika kuantitas pesan sedang, safety stock banyak, dan frekuensi pemesanan kadang-kadang maka status inventory cost akan meningkat.
7. R7= if((kuantitas pesan="Sedang")*(safety stock="Banyak")*(frekuensi pemesanan="Sering")*(Lead time="Sedang"),"Tidak"
Dari rule ini diketahui bahwa jika kuantitas pesan sedang, safety stock banyak, frekuensi pemesanan sering, dan leadtime sedang maka status inventory cost tidak meningkat.
8. R8= if((kuantitas pesan="Sedang")(*safety stock="Banyak")*(frekuensi pemesanan="Sering")*(Lead time="Lama"),"Tidak"
Dari rule ini diketahui bahwa jika kuantitas pesan sedang, safety stock banyak, frekuensi pemesanan sering, dan leadtime lama maka status inventory cost tidak meningkat.
Dari rule ini diketahui bahwa jika kuantitas pesan sedang, safety stock banyak, frekuensi pemesanan sering, leadtime cepat dan persediaan awal sedikit maka status inventory cost tidak meningkat.
10. R10= if((kuantitas pesan="Sedang")*(safety stock="Banyak")*(frekuensi pemesanan="Sering")*(Lead time="Cepat")*(Persediaan awal="Sedang"),"Iya" Dari rule ini diketahui bahwa jika kuantitas pesan sedang, safety stock banyak, frekuensi pemesanan sering, leadtime cepat dan persediaan awal sedang maka status inventory cost akan meningkat.
11. R11= if((kuantitas pesan="Sedang")*(safety stock="Banyak")*(frekuensi pemesanan="Sering")*(Leadtime="Cepat")*(Persediaanawal="Banyak"),"Tidak" Dari rule ini diketahui bahwa jika kuantitas pesan sedang, safety stock banyak, frekuensi pemesanan sering, leadtime cepat dan persediaan awal banyak maka status inventory cost tidak meningkat.
Gambar 4. 1 Pohon Keputusan yang Terbentuk
Pada gambar diatas kita dapat mengetahui susunan pohon keputusan yang terbentuk berdasarkan hasil rule yang didapat. Pada pohon keputusan, atribut yang menjadi root nodenya adalah kuantitas pesan, sedangkan yang menjadi internal nodenya yaitu safety stock, frekuensi pemesanan dan leadtime. Penjelasan pengambilan keputusan yang dapat dijelaskan dari pohon keputusan tersebut adalah sebagai berikut
1. Jika kuantitas pesan sedikit maka status inventory cost akan meningkat. 2. Jika kuantitas pesan banyak maka status inventory cost tidak meningkat.
3. Jika kuantitas pesan sedang dan safety stock sedikit maka status inventory cost tidak meningkat
4. Jika kuantitas pesan sedang dan safety stock sedang maka status inventory cost akan meningkat
(Tidak) Safety stock sedang (Iya) Safety stock sedang
(Iya) Safety stock banyak Safety stock
5. Jika kuantitas pesan sedang, safety stock banyak, dan frekuensi pemesanan jarang maka status inventory cost tidak meningkat
6. Jika kuantitas pesan sedang, safety stock banyak, dan frekuensi pemesanan kadang-kadang maka status inventory cost akan meningkat
7. Jika kuantitas pesan sedang, safety stock banyak, frekuensi pemesanan sering, dan leadtime sedang maka status inventory cost tidak meningkat
8. Jika kuantitas pesan sedang, safety stock banyak, frekuensi pemesanan sering, dan leadtime lama maka status inventory cost tidak meningkat
9. Jika kuantitas pesan sedang, safety stock banyak, frekuensi pemesanan sering, leadtime cepat dan persediaan awal sedikit maka status inventory cost tidak meningkat 10. Jika kuantitas pesan sedang, safety stock banyak, frekuensi pemesanan sering, leadtime cepat dan persediaan awal sedang maka status inventory cost akan meningkat 11. Jika kuantitas pesan sedang, safety stock banyak, frekuensi pemesanan sering, leadtime cepat dan persediaan awal banyak maka status inventory cost tidak meningkat
Perhitungan Akurasi
Tabel 4. 19 Perhitungan Akurasi Algoritma Decision tree Menggunakan Microsoft Excel
Kode
51 Sedang Sedikit Lama Sering Sedang Ya Iya
52 Sedikit Sedang Sedang Jarang Sedikit Ya Tidak
Kode
54 Sedang Banyak Sedang Jarang Banyak Ya Tidak
55 Banyak Sedikit Cepat Jarang Sedang Tidak Iya
56 Banyak Sedikit Sedang Sering Sedang Tidak Iya
57 Sedikit Banyak Lama Jarang Sedang Ya Tidak
58 Sedikit Banyak Sedang Jarang Banyak Tidak Tidak
59 Banyak Sedikit Sedang Jarang Banyak Tidak Iya
60 Sedang Sedikit Sedang
Kadang-kadang
Sedang Tidak Iya
61 Banyak Sedang Sedang
Kadang-kadang
Banyak Tidak Iya
62 Sedang Banyak Sedang Jarang Sedang Ya Tidak
63 Banyak Sedang Lama Jarang Banyak Ya Tidak
64 Sedikit Sedikit Sedang Sering Banyak Ya Iya
65 Sedang Banyak Cepat Sering Sedikit Tidak Tidak
66 Sedikit Sedang Lama
Kadang-kadang
Sedang Tidak Iya
67 Sedang Sedang Lama
Kadang-kadang
Banyak Ya Iya
68 Sedikit Sedikit Cepat
Kadang-kadang
Sedang Tidak Iya
69 Banyak Sedang Lama Jarang Sedang Tidak Iya
70 Banyak Banyak Cepat
Kadang-kadang
Banyak Ya Tidak
71 Banyak Sedang Lama
Kadang-kadang
Sedang Tidak Iya
72 Banyak Sedang Lama
Kadang-kadang
Banyak Ya Iya
73 Sedikit Sedang Sedang Jarang Sedang Ya Iya
74 Banyak Banyak Cepat
Kadang-kadang
Sedang Ya Tidak
75 Sedang Sedang Sedang Sering Sedikit Tidak Tidak
Kode
77 Banyak Banyak Sedang
Kadang-kadang
Sedang Ya Tidak
78 Banyak Sedikit Lama Jarang Sedang Tidak Iya
79 Sedang Banyak Lama Jarang Sedikit Tidak Tidak
80 Sedikit Sedang Cepat
Kadang-kadang
Sedikit Ya Tidak
81 Banyak Sedang Sedang
Kadang-kadang
Sedang Ya Iya
82 Sedang Sedang Lama
Kadang-kadang
Sedang Tidak Iya
83 Sedang Sedikit Lama Jarang Sedang Tidak Iya
84 Banyak Sedang Lama
Kadang-kadang
Sedang Tidak Iya
85 Banyak Sedikit Lama Sering Banyak Ya Iya
86 Banyak Sedang Sedang Sering Sedang Tidak Iya
87 Sedikit Sedikit Lama Jarang Sedikit Ya Iya
88 Banyak Banyak Lama Jarang Sedang Ya Tidak
89 Sedang Banyak Cepat Sering Sedang Ya Tidak
90 Sedang Banyak Sedang Jarang Sedang Ya Tidak
91 Sedikit Sedang Cepat
Kadang-kadang
Banyak Tidak Iya
92 Sedang Banyak Cepat Sering Sedang Tidak Tidak
93 Sedikit Sedang Sedang
Kadang-kadang
Banyak Ya Iya
94 Sedang Sedikit Sedang Jarang Banyak Tidak Iya
95 Sedang Sedikit Cepat Sering Sedang Tidak Iya
96 Banyak Banyak Cepat Sering Sedang Ya Tidak
97 Sedang Banyak Cepat
Kadang-kadang
Sedang Tidak Tidak
98 Sedikit Sedang Sedang Sering Sedang Tidak Iya
99 Sedang Sedang Sedang
Kadang-kadang
Sedang Ya Iya
Tabel 4. 20 Perhitungan Akurasi dan Eror
Eror 0.66 66%
Akuras i
0.34 34%
Berdasarkan hasil perhitungan akurasi menggunakan data test-set dari dari transformasi yang terbentuk sebelumnya, didapatkan nilai akurasi sebesar 34% dan nilai eror sebesar 66% sehingga nilai akurasi < nilai eror yang berarti data yang digunakan untuk memprediksi training-set tidak akurat dan tidak dapat digunakan untuk meprediksi ada atau tidaknya peningkatan yang terjadi pada inventory cost PT. ART.
4.2.1.2 Rapid Miner
Gambar 4. 3 OutputDecision tree Pada Rapid Miner
Gambar 4. 4 Output Akurasi Algoritma Tree decision dengan Rapid Miner
Pada output di atas diketahui nilai akurasi algorima tree decision dengan menggunakan Software Rapid Miner pada data test-set sebesar 40%. Hasil akurasi ini sedikit berbeda dengan hasil akurasi algoritma tree decision menggunakan Microsoft Excel yang hanya sebesar 34%. Pada output diatas diketahui prediksi “Ya” akan terjadi peningkatan inventory cost dan benar ada 11 data. Sedangkan prediksi “Ya” akan terjadi peningkatan inventory cost dan ternyata salah ada 17 data. Pada prediksi berikutnya untuk “Tidak” pada peningkatan inventory cost dan ternyata salah ada 13 data. Sedangkan pada prediksi “Tidak” pada peningkatan inventory cost dan ternyata benar ada 9 data.
4.2.2 Naïve Bayes
Gambar 4. 5 Pengolahan Data Menggunakan Algoritma Naïve Bayes
Berdasarkan hasil output diatas dapat diketahui bahwa:
1. Atribut Presediaan awal dengan parameter “Sedikit” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.185 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.174
2. Atribut Presediaan awal dengan parameter “Sedang” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.592 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.564
3. Atribut Presediaan awal dengan parameter “Banyak” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.592 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.564
4. Atribut Kuantitas pesan dengan parameter “Sedikit” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.112 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.347
5. Atribut Kuantitas pesan dengan parameter “Banyak” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.555 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.347
6. Atribut Kuantitas pesan dengan parameter “Sedang” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.333 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.304
7. Atribut Leadtime dengan parameter “Cepat” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.148 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.304
8. Atribut Leadtime dengan parameter “Sedang” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.481 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.391
9. Atribut Leadtime dengan parameter “Lama” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.370 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.304
11. Atribut Frekuensi pemesanan dengan parameter “Kadang-kadang” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.370 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.347
12. Atribut Frekuensi pemesanan dengan parameter “Jarang” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.333 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.131
13. Atribut Safety stock dengan parameter “Sedikit” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.222 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.174
14. Atribut Safety stock dengan parameter “Sedang” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.555 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.521
15. Atribut Safety stock dengan parameter “Banyak” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.222 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.304
Gambar 4. 7 Output Akurasi Algoritma Naïve Bayes dengan Rapid Miner
4.3 Analisa If-Then Rule
Dari hasil pengolahan data yang dilakukan baik secara manual (Microsoft Excel) ataupun menggunakan bantuan Software Rapid Miner untuk algoritma Tree decision dan Naïve Bayes didapatkan perbedaan hasil dari kedua cara yang digunakan khususnya pada tree decision saat menggunakan Microsoft Excel dan saat menggunakan Software Rapid Miner. Untuk pengolahan data perhitungan algoritma tree decision menggunakan Microsoft Excel didapatkan hasil rule sebagai berikut
1. Jika kuantitas pesan sedikit maka status inventory cost akan meningkat.
Pada hal ini berarti jika kuantitas pesan PT. ART sedikit maka otomatis frekuensi pemesanan untuk barangnya akan meningkat sehingga akan meningkatkan biaya setiap kali menyimpan barang (dalam jumlah sedikit). Berbeda jika PT . ART melakukan pemesanan barang dengan kuantittas besar, maka otomatis frekuensi pesannya akan rendah dan hanya sesekali saja menyimpan barang tetapi dalam jumlah yang besar. Hal yang perlu diingat adalah bahwa biaya pesan merupakan salah satu jenis biaya operasional tetap yang tidak dipengaruhi oleh volume, jadi banyak atau tidaknya barang yang disimpan tidak berpengaruh terhadap biaya yang dikeluarkan. Akan tetapi jika kita menyimpan barang dalam jumlah sedikit tetapi sering malah akan meningkatkan biaya simpan karena biaya simpan dihitung setiap kali kita menyimpan barang.
2. Jika kuantitas pesan banyak maka status inventory cost tidak meningkat.
3. Jika kuantitas pesan sedang dan safety stock sedikit maka status inventory cost tidak meningkat
Pada hal ini jika PT. ART melakukan pemesanan barang dalam jumlah sedang dan safety stock barang pada gudang sedikit maka tidak akan menambah atau meningkatkan biaya inventory cost perusahaan. Jumlah safety stock yang sedikit dinilai sangat wajar dimiliki oleh suatu perusahaan sebagai batas aman jumlah barang yang dimiliki menyangkut adanya waktu menunggu terhadap pesanan yang dilakukan apalagi kuantitas pesan yang diminta perusahaan dalam jumlah yang tidak banyak tetapi tidak sedikit juga.
4. Jika kuantitas pesan sedang dan safety stock sedang maka status inventory cost akan meningkat
Dalam hal ini jika PT. ART melakukan pemesanan barang dalam jumlah sedang dan mempunyai safety stock sedang juga, maka biaya inventory cost perusahaan akan meningkat atau bertambah. Hal ini dikarenakan jumlah barang safety stock yang cukup ditambah lagi pesanan barang yang datang dalam jumlah yang cukup pula kemungkinan akan memerlukan ruang lagi untuk penyimpanan ataupun akan meningkatkan biaya perawatan barang yang disimpan dikarenakan jumlah barang yang bertambah banyak dari semula sehingga biaya perawatan yang diperlukan juga meningkat melihat pertambahan barang.
5. Jika kuantitas pesan sedang, safety stock banyak, dan frekuensi pemesanan jarang maka status inventory cost tidak meningkat
6. Jika kuantitas pesan sedang, safety stock banyak, dan frekuensi pemesanan kadang-kadang maka status inventory cost akan meningkat
Pada keputusan ini jika PT. ART melakukan pemesanan barang dalam jumlah sedang, mempunyai safety stock barang yang banyak, dan melakukan pemesanan barang kadang-kadang maka akan meningkatkan biaya inventory cost. Jumlah barang yang dipesan dalam jumlah cukup dan persediaan safety stock yang banyak saja sudah akan meningkatkan biaya inventory cost apalagi jika perusahaan melakukan pemesanan barang dalam durasi yang cukup seperti kadang kadang maka otomatis akan menambah biaya inventory cost perusahaan.
7. Jika kuantitas pesan sedang, safety stock banyak, frekuensi pemesanan sering, dan leadtime sedang maka status inventory cost tidak meningkat
Dalam keputusan ini berarti jika perusahaan melakukan pemesanan barang dalam jumlah sedang, sudah mempunyai safety stock banyak di gudang, rentan pemesanan yang sering dan mempunyai waktu leadtime yang sedang maka tidak akan meningkatkan biaya inventory cost pada perusahaan. Meskipun perusahaan melakukan pemesanan dalam jumlah sedang, sudah mempunyai persedian barang yang banyak, frekuensi pemesanan yang sering, tetapi tidak menambah biaya biaya inventory cost hal ini dikarenakan waktu leadtime yang dimiliki perusahaan cukup cepat sehingga perusahaan tidak perlu menyimpan barang dan bisa langsung menjualnya.
8. Jika kuantitas pesan sedang, safety stock banyak, frekuensi pemesanan sering, dan leadtime lama maka status inventory cost tidak meningkat
perusahaan sehingga meskipun perusahaan memiliki waktu leadtime yang lama tetap tidak menambah biaya inventory cost.
9. Jika kuantitas pesan sedang, safety stock banyak, frekuensi pemesanan sering, leadtime cepat dan persediaan awal sedikit maka status inventory cost akan meningkat
Dalam keputusan ini berarti jika perusahaan melakukan pemesanan barang dalam jumlah sedang, sudah mempunyai safety stock banyak di gudang, rentan pemesanan yang sering, mempunyai waktu leadtime yang lama, serta mempunyai persediaan awal yang sedikit maka tidak akan meningkatkan biaya inventory cost pada perusahaan. Hal tersebut dikarenakan persediaan awal yang dimiliki oleh perusahaan hanya sedikit dan kemungkinan tidak menambah ruang pada gudang penyimpanan sehingga tidak akan menambah biaya simpan atau inventory cost.
10. Jika kuantitas pesan sedang, safety stock banyak, frekuensi pemesanan sering, leadtime cepat dan persediaan awal sedang maka status inventory cost akan meningkat
Dalam keputusan ini berarti jika perusahaan melakukan pemesanan barang dalam jumlah sedang, sudah mempunyai safety stock banyak di gudang, rentan pemesanan yang sering, mempunyai waktu leadtime yang lama, serta mempunyai persediaan awal yang sedang atau cukup maka akan meningkatkan biaya inventory cost pada perusahaan. Hal tersebut dikarenakan persediaan awal yang yang dimiliki oleh perusahaan sebetulnya sudah cukup dan safety stock yang dimiliki juga sudah memadai, jika perusahaan melakukan pemesanan lagi untuk barang maka kemungkinan besar akan menambah biaya inventory costnya.
11. Jika kuantitas pesan sedang, safety stock banyak, frekuensi pemesanan sering, leadtime cepat dan persediaan awal banyak maka status inventory cost akan meningkat
pemesanan yang sering, mempunyai waktu leadtime yang lama, serta mempunyai persediaan awal yang sedang atau cukup maka akan meningkatkan biaya inventory cost pada perusahaan. Hal tersebut dikarenakan persediaan awal yang yang dimiliki oleh perusahaan lebih dari cukup dan safety stock yang dimiliki juga sudah memadai, jika perusahaan melakukan pemesanan lagi untuk barang maka kemungkinan besar akan menambah biaya inventory costnya sama seperti pada rule yang terbentuk sebelumnya.
Dari hasil perhitungan algoritma Naïve Bayes menggunakan rapid miner didapatkan hasil sebagai berikut
1. Atribut Presediaan awal dengan parameter “Sedikit” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.185 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.174
Hal ini berarti bahwa peluang munculnya keputusan “tidak” untuk atribut persediaan awal yang sedikit sebesar 0.185 sedangkan kemungkinan munculnya keputusan “ya” pada pesediaan awal yang sedikit sebesar 0.174 sehingga dari besarnya kemungkinan ini maka keputusan “tidak” yang kemungkinan besar akan muncul atau menjadi keputusan nantinya.
2. Atribut Presediaan awal dengan parameter “Sedang” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.592 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.564
Hal ini berarti bahwa peluang munculnya keputusan “tidak” untuk atribut persediaan awal yang sedang sebesar 0.592 sedangkan kemungkinan munculnya keputusan “ya” pada pesediaan awal yang sedang sebesar 0.564 sehingga dari besarnya kemungkinan ini maka keputusan “tidak” yang kemungkinan besar akan muncul atau menjadi keputusan nantinya.
Hal ini berarti bahwa peluang munculnya keputusan “tidak” untuk atribut persediaan awal yang banyak sebesar 0.222 sedangkan kemungkinan munculnya keputusan “ya” pada pesediaan awal yang banyak sebesar 0.261 sehingga dari besarnya kemungkinan ini maka keputusan “ya” yang kemungkinan besar akan muncul atau menjadi keputusan nantinya.
4. Atribut Kuantitas pesan dengan parameter “Sedikit” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.112 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.347
Hal ini berarti bahwa peluang munculnya keputusan “tidak” untuk atribut kuantitas pesan yang sedikit sebesar 0.112 sedangkan kemungkinan munculnya keputusan “ya” pada kuantitas pesan yang sedikit sebesar 0.347 sehingga dari besarnya kemungkinan ini maka keputusan “ya” yang kemungkinan besar akan muncul atau menjadi keputusan nantinya.
5. Atribut Kuantitas pesan dengan parameter “Banyak” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.555 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.347
Hal ini berarti bahwa peluang munculnya keputusan “tidak” untuk atribut kuantitas pesan yang banyak sebesar 0.555 sedangkan kemungkinan munculnya keputusan “ya” pada kuantitas pesan yang banyak sebesar 0.347 sehingga dari besarnya kemungkinan ini maka keputusan “tidak” yang kemungkinan besar akan muncul atau menjadi keputusan nantinya.
6. Atribut Kuantitas pesan dengan parameter “Sedang” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.333 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.304
besarnya kemungkinan ini maka keputusan “tidak” yang kemungkinan besar akan muncul atau menjadi keputusan nantinya.
7. Atribut Leadtime dengan parameter “Cepat” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.148 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.304
Hal ini berarti bahwa peluang munculnya keputusan “tidak” untuk atribut leadtime yang cepat sebesar 0.148 sedangkan kemungkinan munculnya keputusan “ya” pada leadtime yang cepat sebesar 0.304 sehingga dari besarnya kemungkinan ini maka keputusan “ya” yang kemungkinan besar akan muncul atau menjadi keputusan nantinya.
8. Atribut Leadtime dengan parameter “Sedang” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.481 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.391
Hal ini berarti bahwa peluang munculnya keputusan “tidak” untuk atribut leadtime yang sedang sebesar 0.481 sedangkan kemungkinan munculnya keputusan “ya” pada leadtime yang sedang sebesar 0.391 sehingga dari besarnya kemungkinan ini maka keputusan “tidak” yang kemungkinan besar akan muncul atau menjadi keputusan nantinya.
9. Atribut Leadtime dengan parameter “Lama” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.370 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.304
10. Atribut Frekuensi pemesanan dengan parameter “Sering” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.296 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.521
Hal ini berarti bahwa peluang munculnya keputusan “tidak” untuk atribut frekuensi pemesanan yang sering sebesar 0.296 sedangkan kemungkinan munculnya keputusan “ya” pada frekuensi pemesanan yang sering sebesar 0.521 sehingga dari besarnya kemungkinan ini maka keputusan “ya” yang kemungkinan besar akan muncul atau menjadi keputusan nantinya.
11. Atribut Frekuensi pemesanan dengan parameter “Kadang-kadang” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.370 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.347
Hal ini berarti bahwa peluang munculnya keputusan “tidak” untuk atribut frekuensi pemesanan kadang-kadang sebesar 0.370 sedangkan kemungkinan munculnya keputusan “ya” pada frekuensi pemesanan kadang-kadang sebesar 0.347 sehingga dari besarnya kemungkinan ini maka keputusan “tidak” yang kemungkinan besar akan muncul atau menjadi keputusan nantinya.
12. Atribut Frekuensi pemesanan dengan parameter “Jarang” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.333 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.131
Hal ini berarti bahwa peluang munculnya keputusan “tidak” untuk atribut frekuensi pemesanan jarang sebesar 0.333 sedangkan kemungkinan munculnya keputusan “ya” pada frekuensi pemesanan jarang sebesar 0.131 sehingga dari besarnya kemungkinan ini maka keputusan “tidak” yang kemungkinan besar akan muncul atau menjadi keputusan nantinya.
Hal ini berarti bahwa peluang munculnya keputusan “tidak” untuk atribut safety stock sedikit sebesar 0.222 sedangkan kemungkinan munculnya keputusan “ya” pada safety stock yang sedikit sebesar 0.174 sehingga dari besarnya kemungkinan ini maka keputusan “tidak” yang kemungkinan besar akan muncul atau menjadi keputusan nantinya.
14. Atribut Safety stock dengan parameter “Sedang” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.555 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.521
Hal ini berarti bahwa peluang munculnya keputusan “tidak” untuk atribut safety stock sedang sebesar 0.555 sedangkan kemungkinan munculnya keputusan “ya” pada safety stock yang sedangt sebesar 0.521 sehingga dari besarnya kemungkinan ini maka keputusan “tidak” yang kemungkinan besar akan muncul atau menjadi keputusan nantinya.
15. Atribut Safety stock dengan parameter “Banyak” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.222 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.304
BAB V
KESIMPULAN DAN REKOMENDASI
5.1 Kesimpulan
Berdasarkan hasil analisis dan pembahasan yang dilakukan didapatkan kesimpulan sebagai berikut
1. Berdasarkan hasil pengolahan data untuk algoritma tree decision dan naïve bayes menggunakan software Microsoft Excel dan Rapid Miner didapatkan hasil rule sebagai berikut untuk rule tree decision
a. R1= if(kuantitas pesan="Sedikit","Iya"
Dari rule ini diketahui bahwa jika kuantitas pesan sedikit maka status inventory cost akan meningkat.
b. R2= if(kuantitas pesan="Banyak","Tidak"
Dari rule ini diketahui bahwa jika kuantitas pesan banyak maka status inventory cost tidak meningkat.
c. R3= if((kuantitas pesan="Sedang")*(Safety stock="Sedikit"),"Tidak" Dari rule ini diketahui bahwa jika kuantitas pesan sedang dan safety stock sedikit maka status inventory cost tidak meningkat.
d. R4= if((kuantitas pesan="Sedang")*(Safety stock="Sedang"),"Iya" Dari rule ini diketahui bahwa jika kuantitas pesan sedang dan safety stock sedang maka status inventory cost akan meningkat.
e. R5= if((kuantitas pesan="Sedang")*(safety stock="Banyak")*(Frekuensi pemesanan="Jarang"),"Tidak"
Dari rule ini diketahui bahwa jika kuantitas pesan sedang, safety stock banyak, dan frekuensi pemesanan jarang maka status inventory cost tidak meningkat.
Dari rule ini diketahui bahwa jika kuantitas pesan sedang, safety stock banyak, dan frekuensi pemesanan kadang-kadang maka status inventory cost akan meningkat.
g. R7= if((kuantitas pesan="Sedang")*(safety stock="Banyak")*(frekuensi pemesanan="Sering")*(Lead time="Sedang"),"Tidak"
Dari rule ini diketahui bahwa jika kuantitas pesan sedang, safety stock banyak, frekuensi pemesanan sering, dan leadtime sedang maka status inventory cost tidak meningkat.
h. R8= if((kuantitas pesan="Sedang")(*safety stock="Banyak")*(frekuensi pemesanan="Sering")*(Lead time="Lama"),"Tidak"
Dari rule ini diketahui bahwa jika kuantitas pesan sedang, safety stock banyak, frekuensi pemesanan sering, dan leadtime lama maka status inventory cost tidak meningkat.
i. R9= if((kuantitas pesan="Sedang")*(safety stock="Banyak")*(frekuensi pemesanan="Sering")*(Leadtime="Cepat")*(Persediaanawal="Sedikit"),"Tid ak"
Dari rule ini diketahui bahwa jika kuantitas pesan sedang, safety stock banyak, frekuensi pemesanan sering, leadtime cepat dan persediaan awal sedikit maka status inventory cost tidak meningkat.
j. R10= if((kuantitas pesan="Sedang")*(safety stock="Banyak")*(frekuensi pemesanan="Sering")*(Lead time="Cepat")*(Persediaan awal="Sedang"),"Iya"
Dari rule ini diketahui bahwa jika kuantitas pesan sedang, safety stock banyak, frekuensi pemesanan sering, leadtime cepat dan persediaan awal sedang maka status inventory cost akan meningkat.
k. R11= if((kuantitas pesan="Sedang")*(safety stock="Banyak")*(frekuensi pemesanan="Sering")*(Leadtime="Cepat")*(Persediaanawal="Banyak"),"Tid ak"
Pada algoritma Naïve Bayes didapatkan hasil rule sebagai berikut
a. Atribut Presediaan awal dengan parameter “Sedikit” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.185 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.174
b. Atribut Presediaan awal dengan parameter “Sedang” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.592 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.564
c. Atribut Presediaan awal dengan parameter “Banyak” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.592 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.564
d. Atribut Kuantitas pesan dengan parameter “Sedikit” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.112 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.347
e. Atribut Kuantitas pesan dengan parameter “Banyak” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.555 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.347
f. Atribut Kuantitas pesan dengan parameter “Sedang” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.333 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.304
g. Atribut Leadtime dengan parameter “Cepat” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.148 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.304
h. Atribut Leadtime dengan parameter “Sedang” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.481 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.391
i. Atribut Leadtime dengan parameter “Lama” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.370 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.304
k. Atribut Frekuensi pemesanan dengan parameter “Kadang-kadang” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.370 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.347
l. Atribut Frekuensi pemesanan dengan parameter “Jarang” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.333 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.131
m. Atribut Safety stock dengan parameter “Sedikit” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.222 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.174
n. Atribut Safety stock dengan parameter “Sedang” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.555 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.521
o. Atribut Safety stock dengan parameter “Banyak” akan muncul keputusan “Tidak” dengan probablitias sebesar 0.222 sedangkan untuk keputusan “Ya” memiliki nilai probabilitas 0.304
2. Pada output perhitungan akurasi untuk algorima tree decision dengan menggunakan Software Rapid Miner pada data test-set sebesar 40%. Hasil akurasi ini sedikit berbeda dengan hasil akurasi algoritma tree decision menggunakan Microsoft Excel yang hanya sebesar 34%. Sedangkan nilai akurasi yang didapat dari algoritma Naïve Bayes dengan menggunakan Software Rapid Miner pada data test-set adalah sebesar 42%. Dari hasil ini kita dapat mengetahui bahwa penggunaan algoritma Nive Bayes lebih baik dikarenakan hasil akurasi yang dihasilkan lebih besar dibandingkan menggunakan algoritma tree decision baik secara manual (Microsoft Excel ataupun menggunakan Rapid Miner)
5.2 Rekomendasi
1. Untuk penelitian selanjutnya, kami berharap peneliti mampu menggunakan software lebih baik lagi sehingga kesalahan atau eror yang terjadi pada software khususnya penggunaan Rapid Miner dapat diminimalisir agar output yang dihasilkan dari proses komputasi software tidak jauh berbeda dari hasil perhitungan secara manual yang dilakuan dikarenakan proses perhitungan komputasi seharusnya merupakan suatu bentuk representative dari hasil perhitungan manual.
REFERENSI
Bertalya. (2009). Konsep Data Mining. Jakarta: Universitas Gunadarma
Han, Jiawei, Micheline Kamber. 2001. Data mining Concepts and. Techniques. Morgan Kaufmann Publisher.
Kasmir (2010), Analisis Laporan Keuangan, PT Raja Grafindo, Jakarta
Olson, D. L., & Delen, D. (2008). Advanced Data Mining Techniques. Springer-Verlag Berlin Heidelberg.
Santosa, Budi. 2007. Data Mining : Teknik Pemanfaatan Data untuk keperluan Bisnis. Graha Ilmu. Yogyakarta.
www.pengusahamuslim.com diakses pada 1 Juli 2015