Operand fetch of I2 takes three cycles
•
Pipeline
stalls
for two cycles
Caused by hazards
Limits to pipelining:
Hazards
prevent
next instruction from executing during
its designated clock cycle
Three types of hazards
• Resource hazards
Occurs when two or more instructions use the same resource
Also called structural hazards
• Data hazards
Caused by data dependencies between instructions
Example: Result produced by I1 is read by I2
• Control hazards
Default: sequential execution suits pipelining
Altering control flow (e.g., branching) causes problems Introduce control dependencies
Pipeline Bubble
Untuk menyelesaikan instruksi tertentu, beberapa langkah
dalam pipeline ada yang tidak relevan. Hal ini disebut ‘pipeline bubble’.
Untuk beberapa instruksi, sejumlah langkah dalam pipeline tidak akan dikerjakan. Misalnya, untuk instruksi NOOP, hanya ada dua langkah yang diperlukan yaitu pengambilan instruksi, dan dekode instruksi. Karena itu instruksi ini menyebabkan ‘bubble’ dalam pipeline setelah dua langkah pertama. Sama halnya instruksi LOAD tidak dikerjakan pada tingkat penulisan hasil. Namun demikian, instruksi-instruksi tersebut harus
melalui semua tingkatan tanpa melompati langkah yang tidak diinginkan.
Pipeline Hazard
Pipeline beroperasi dengan efisiensi penuh asalkan program adalah suatu yang ideal yang tidak mengganggu pada tujuan penyelesaian dari satu instruksi untuk setiap clock. Tetapi
kadang-kadang program praktis mempunyai tipe yang berbeda dari hubungan antar-instruski yang dihasilkan pada tempat
pipeline. Dengan kata lain, ketergantungan antara instruksi-instruksi yang berurutan/berdekatan menyebabkan hazard
dalam pipeline dan mempengaruhi operasi mulus dari pipeline instruksi. Ada tiga hal utama yang menyebabkan hazard:
Konflik sumberdaya atau Structural hazard Ketergantungan data atau data hazard
Branch difficulty atau control hazard
Konflik Sumberdaya (structural hazard)
Bila dua segmen berbeda dalam pipeline memerlukan sumberdaya hardware secara bersamaan, maka akan menghasilkan konflik
sumberdaya (resource conflict). Berikut beberapa contoh tipikal:
1. Anggap tingkat akhir WB (penulisan hasil) suatu instruksi
memerlukan akses memori untuk penyimpanan hasil, dan pada waktu yang sama FO (pengambilan operand) juga memerlukan akses memori untuk pengambilan operand untuk instruksi berikutnya. Jelas, salah satunya akan mengalami penundaan. Jika kita menunda akses memori WB, dia akan menunda operasi pipeline untuk instruksi berikutnya
hingga akses memori WB selesai. Dengan kata lain jika kita menunda akses memori FO, operasi parsial instruksi antara FO dan WB akan berjalan terus sedangkan bagian yang mendahului FO akan tetap diam. Satu solusi untuk mengatasi masalah ini adalah dengan menggunakan ‘write output buffer’. Tingkat WB dengan mudah
menyimpan hasil dan ‘informasi kontrol lainnya’ (yaitu alamat memori) pada write buffer sebagai pengganti pengaksesan memori utama.
Dengan kata lain operasi penyimpanan dalam memori utama
dihilangkan dari pipeline. Sirkuit kontrol tambahan melakukan suatu operasi penulisan memori bila memori tersedia dengan mengambil informasi dari write buffer.
Konflik Sumberdaya (structural hazard)
2. Konflik sumberdaya lainnya terjadi bila tingkat FI
memerlukan akses memori untuk pengambilan instruksi dan tingkat FO memerlukan akses memori untuk pengambilan operand pada saat yang sama. Hal ini dapat diselesaikan dengan mempunyai unit-unit memori cache terpisah untuk instruksi (cache kode) dan operand (cache data) seperti pada kasus Mikropresessor Pentium. Secara bersamaan, cache kode dan cache data dapat diakses.
Example
• Conflict for memory in clock cycle 3 I1 fetches operand
Minimizing the impact of
resource conflicts
• Increase available resources • Prefetch
Ketergantungan Data (data hazard)
Jika operand untuk suatu instruksi merupakan hasil dari
instruksi sebelumnya yang belum selesai dalam pipeline, maka kasus ini disebut ketergantungan data (data dependency).
Contoh:
Contoh
I1: add R2,R3,R4 /* R2 = R3 + R4 */
I2: sub R5,R6,R2 /* R5 = R6 – R2 */
Memperlihatkan data dependency
antara I1 and I2
Ketergantungan Data (data hazard)
Jika operand untuk suatu instruksi merupakan hasil dari instruksi sebelumnya yang belum selesai dalam
pipeline, maka kasus ini disebut ketergantungan data (data dependency).
Three types of data dependencies
require attention
• Read-After-Write (RAW)
One instruction writes that is later read by the other instruction
• Write-After-Read (WAR)
One instruction reads from register/memory that is later written by the other instruction
• Write-After-Write (WAW)
One instruction writes into register/memory that is later written by the other instruction
• Read-After-Read (RAR)
Antara dua instruksi A dan B terjadi ‘RAW’
hazard jika B membaca beberapa item data yang
dimodifikasi oleh A.
‘WAR’ hazard terjadi jika B memodifikasi
beberapa item data yang dibaca oleh A.
‘WAW’ hazard terjadi jika A dan B keduanya
memodifikasi beberapa item data.
Deteksi dini situasi hazard dan koreksi awal
untuk mencegah hazard biasanya dilakukan oleh
hardware logic
yang tepat.
Data dependencies have two implications
•
Correctness issue
Detect dependency and stall
•
Efficiency issue
Try to minimize pipeline stalls
Two techniques to handle data dependencies
•Register interlocking
Also called
bypassing
•
Register forwarding
Register interlocking
•
Provide output result as soon as possible
An Example
•
Forward 1 scheme
Output of I1 is given to I2 as we write the result
into destination register of I1
Reduces pipeline stall by one cycle
•
Forward 2 scheme
Output of I1 is given to I2 during the IE stage of
I1
Implementation
of forwarding in
hardware
• Forward 1 scheme
Result is given as
input from the bus Not from A
• Forward 2 scheme
Result is given as
Register interlocking
• Associate a bit with each register
Indicates whether the contents are correct
0 : contents can be used 1 : do not use contents
• Instructions lock the register when using • Example
Intel Itanium uses a similar bit
Called NaT (Not-a-Thing)
Example
I1: add R2,R3,R4 /* R2 = R3 + R4 */ I2: sub R5,R6,R2 /* R5 = R6 – R2 */
Register forwarding vs. Interlocking
• Forwarding works only when the required values are
in the pipeline
• Intrerlocking can handle data dependencies of a
general nature
• Example
load R3,count ; R3 = count add R1,R2,R3 ; R1 = R2 + R3
add cannot use R3 value until load has placed the count
Bila suatu instruksi cabang (branch)
memasuki pipeline, dia dikenali ketika fase
pendekodean instruksi. Tindakan khusus
dilakukan oleh prosesor untuk instruksi cabang tidak bersyarat
(unconditional branch) dan instruksi cabang bersyarat (conditional branch) dapat dilihat pada bagan alir berikut:
Branches alter control flow
• Require special attention in pipelining
• Need to throw away some instructions in the pipeline
Depends on when we know the branch is taken First example (next slide)
Discards (flush) three instructions I2, I3 and I4 Pipeline wastes three clock cycles
Called branch penalty
• Reducing branch penalty
Determine branch decision early
Delayed branch execution
•
Effectively reduces the branch penalty
•
We always fetch the instruction following
the branch
Why throw it away?
Place a useful instruction to execute
This is called
delay slot
add R2,R3,R4 branch target sub R5,R6,R7 . . .
branch target add R2,R3,R4 sub R5,R6,R7 . . .
Three prediction strategies
• Fixed
Prediction is fixed
Example: branch-never-taken Not proper for loop structures
• Static
Strategy depends on the branch type Conditional branch: always not taken Loop: always taken
• Dynamic
Dynamic branch prediction
•
Uses runtime history
Takes the past
n
branch executions of the
branch type and makes the prediction
•
Simple strategy
Prediction of the next branch is the
majority
of
the previous
n
branch executions
Example
: n
= 3
If two or more of the last three branches were taken, the prediction is “branch taken”
Depending on the type of mix, we get more than
Main memory must operate in one cycle
• This can be accomplished by expensive memory, but • It is usually done with cache
Instruction and data memory must appear
separate
• Harvard architecture has separate instruction & data memories • Again, this is usually done with separate caches
Few buses are used
• Most connections are point to point • Some few-way multiplexers are used
Data is latched (stored in temporary
registers) at each pipeline stage—called
“pipeline registers.”
Analisis berikut menunjukkan bahwa waktu yang
digunakan untuk menyelesaikan
m
instruksi dalam suatu
pipeline
n
tingkat,
Waktu yang digunakan instruksi pertama =
nt
cdi mana
tc
adalah durasi satu siklus clock.
Waktu yang digunakan untuk sisa instruksi (
m
– 1) adalah
(
m
– 1)
tc
.
Total waktu yang digunakan untuk
m
instruksi adalah:
Jika prosesor adalah non-pipeline, maka waktu yang
digunakan untuk m instruksi adalam nmtc dengan
menganggap waktu siklus instruksi sama dengan
ntc
Gain Kinerja (Speed-up) pipeline adalah waktu yang
digunakan dalam mode non-pipeline dibagi waktu
yang digunakan dalam mode pipeline, dapat
dituliskan:
1
m
n
nm
t
1
m
n
nmt
c c
)
(
pipeline
mode
waktu
pipeline
-non
mode
waktu
up
-Speed
Untuk nilai m >> (n – 1), maka (n + m – 1) mendekati m. Karena itu speed-up = nm/m = n
Contoh 11.2. Sebuah program menggunakan 500 s untuk eksekusi pada
sebuah prosesor non-pipeline. Anggap kita menginginkan menjalankan 100 program dengan tipe yang sama pada prosesor pipeline lima tingkat dengan perioda clock 20 s. Berapa rasio speed-up dari pipeline ? Berapa speed-up maksimum yang dapat dicapai ? Berapa throughput ?
Solusi:
Waktu yang digunakan oleh satu program pada prosesor non-pipeline =
mntc = 500 s. Anggap siklus instruksi menggunakan lima clock masing-masing 20 s, jadi m = mntc/ntc = 500/100 = 5. Karena itu, satu program mempunyai 5 instruksi. Jumlah instruksi dalam 100 program = 500 instruksi.
Sekarang kita kalkulasi speed-up ketika 100 program dijalankan dalam prosesor pipeline.
Untuk n = 5 dan m = 500, tc = 20 s.
Speed-up maksimum = n = 5
Efisiensi (rasio speed-up) = speed-up aktual /speed-up maks = 4,96 / 5 = 0,992 = 99,2% (5 500 1)x20 0,0496
1. Gambarkan space-time diagram (Gantt’s chart) untuk pipeline enam-tingkat yang menunjukkan waktu yang digunakan untuk memproses 8
pekerjaan.
2. Tentukan jumlah siklus clock yang digunakan untuk memproses 200 pekerjaan dalam sebuah pipeline enam-tingkat.
3. Sebuah sistem non-pipeline memproses sebuah pekerjaan dalam waktu 50 ns. Dengan pekerjaan yang sama dapat dilakukan dalam pipeline enam-tingkat di mana satu siklus clock = 10 ns.
Tentukan speed-up ratio dalam pipeline untuk
100 pekerjaan. Berapa speed-up maksimum yang dapat dicapai?
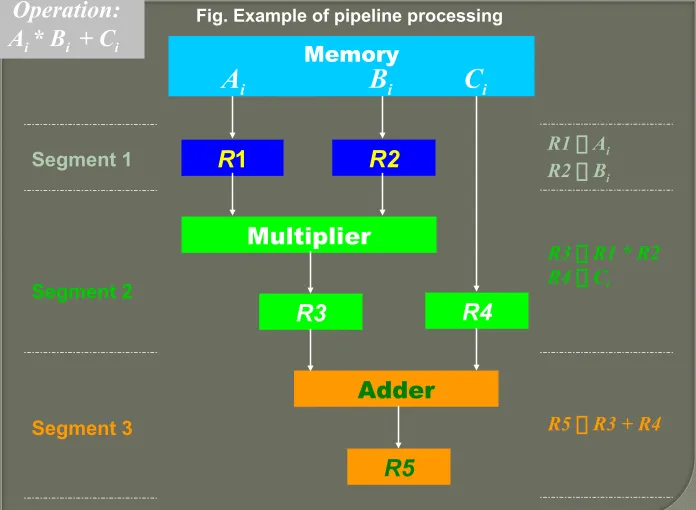
Memory
R
1
R2
Multiplier
R3
R4
Adder
R5
A
iB
iC
iSegment 1
Segment 2
Segment 3
Fig. Example of pipeline processing
R1 Ai
R2 Bi
R3 R1 * R2 R4 Ci
R5 R3 + R4
Operation:
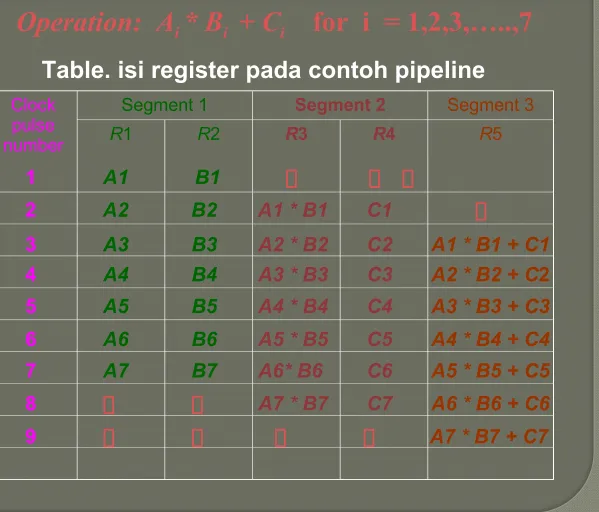
Clock pulse number
Segment 1 Segment 2 Segment 3
R1 R2 R3 R4 R5
Table. isi register pada contoh pipeline
1 A1 B1
2 A2 B2 A1 * B1 C1
3 A3 B3 A2 * B2 C2 A1 * B1 + C1
4 A4 B4 A3 * B3 C3 A2 * B2 + C2 5 A5 B5 A4 * B4 C4 A3 * B3 + C3
6 A6 B6 A5 * B5 C5 A4 * B4 + C4
7 A7 B7 A6* B6 C6 A5 * B5 + C5
8 A7 * B7 C7 A6 * B6 + C6
9 A7 * B7 + C7
S
1S
2S
3S
4= combinational circuits
R
1R
2R
3R
4= registers
S
1R
1S
2R
2S
3R
3S
4R
4Clock
input
segment 1
segment 2
segment 3 segment 4
Pikirkan keadaan di mana sebuah pipeline
k
segment
dengan
waktu siklus clock
t
pdigunakan untuk mengeksekusi
n
task
.
Task pertama T1 memerlukan waktu sebesar
kt
puntuk
menyelesaikan operasinya karena terdapat
k
segment dalam
pipe.
Sisa task
n-1
muncul dari pipe dengan rate satu task per
siklus clock dan mereka akan selesai selama =
(n-1)t
p.
Karena itu, untuk menyelesaikan n tasks dengan pipeline
k-segment memerlukan siklus clock =
k+(n-1).
S =
(k + n – 1)t
nt
np
Instruksi cabang bersyarat mempunyai dua kondisi: 1.Kondisi yang diuji berhasil; di sini isi pipeline
dibilas dan instruksi pada alamat cabang masuk ke pipeline.
2.Kondisi yang diuji tidak berhasil dan di sini ada eksekusi sekuensial; dalam kasus ini, isi pipeline tidak terpengaruh.
Waktu tunda (delay) yang disebabkan oleh instruksi cabang
bersyarat dijelaskan menggunakan contoh berikut:
Anggap ada m instruksi yang akan dieksekusi:
p adalah probabilitas instruksi cabang bersyarat dan
q adalah probabilitas instruksi cabang yang sukses. Karena itu jumlah instruksi yang menyebabkan
instruksi cabang sukses adalah mpq
Jika tidak ada instruksi cabang di dalam kancah (stream), rutin
program selesai dalam m clock. Semua hasil instruksi
cabang pada pembilasan pipeline dan pengisian kembali adalah dari alamat cabang.
Instruksi dari alamat cabang (alamat target) memerlukan
n
siklus clock untuk pengeksekusian.
Total siklus clock yang diperlukan untuk mengesekusi m
instruksi = (waktu tunda dalam siklus clock yang dimulai dari instruksi cabang) + (siklus clock yang diperlukan
untuk instruksi non-cabang):
= mpqn + {(m – mp) + mp – mpq)}
= mpqn + {(m – mpq)} = mpqn + m(1 – pq) Jadi, m instruksi dieksekusi dalam mpqn + m(1 – pq) siklus clock.
Rata-rata jumlah clock per instruksi (CPI) = 1 + pq(n – 1) Jika program tidak terdapt pencabangan, q = 0; CPI = 1.
Contoh 11.3. Sebuah program mempunyai instruksi cabang 20%. Anggap semua pencabangan berhasil,
hitung speed-up dalam pipepline dengan enam tingkat.
Solusi:
Jika tidak instruksi cabang dalam program, speed-up =
n = jumlah tingkat = 6
p = 0,2
q = 1,0
n = 6
CPI = 1 + pq(n - 1) = 1 + 0,2 x 1,0 x (6-1) = 2,0
Prosesor non-pipline memerlukan 6 clock per instruksi
Contoh 11.4. Sebuah program mempunyai instruksi cabang 20%. Jika dijalankan pada prosesor pipeline
lima tingkat, dari pengamatan menghasilkan
pencabangan sukses 60%. Hitung peningkatan
performanya pada prosesor pipeline. Berapa speed-up
maksimum yang mungkin jika tidak ada
pencabangan ? Solusi:
p = 0,2
q = 0,6
n = 5
CPI = 1 + pq(n - 1) = 1 + 0,2 x 0,6 x (5-1) = 1,48
Prosesor non-pipline memerlukan 5 clock per instruksi
Speed-up = 6/2 = 3
Speed-up maksimum jika tidak ada pencabangan = n =