Bab II
Landasan Teori
Pada bab landasan teori, akan dijelaskan mengenai teori yang menunjang didalam penulisan skripsi ini antara lain mengenai basis data, teknologi basis data, definisi
clustering (distribusi basis data), metodologi yang digunakan, topologi dan teknik
pengimplementasian distribusi basis data pada basis data SQL Server 2000. 2.1 Basis Data
Data adalah fakta mengenai objek, orang, dan lain-lain. Sedangkan Informasi adalah hasil analisis dan sintesis terhadap data. Basis data memiliki beberapa definisi (Cengage Learning, 2009), antara lain :
1. Kumpulan data, yang dapat digambarkan sebagai aktifitas dari satu atau lebih organisasi yang berelasi.
2. Kumpulan informasi yang disimpan di dalam komputer secara sistematik sehingga dapat diperiksa menggunakan suatu program komputer untuk memperoleh informasi dari basis data tersebut.
3. Kumpulan data yang saling berhubungan yang disimpan secara bersama sedemikian rupa dan tanpa pengulangan (redudansi) yang tidak perlu, untuk memenuhi berbagai kebutuhan.
4. Sebuah koleksi dari data yang saling berelasi, dimana data tersebut disimpan pada komputer sedemikian hingga sebuah program komputer dapat berinteraksi dan menggunakan data yang disimpan tersebut untuk menyelesaikan masalah ataupun menjawab pertanyaan (Elmasri, 1994). Data didalam basis data perlu diorganisasikan sedemikian rupa sehingga informasi yang terkandung didalamnya mudah diakses. Basis data merupakan komponen
Tujuan pemanfaat basis data, antara lain : 1. Kecepatan dan kemudahan (speed)
Pengguna basis data dapat melakukan beberapa hal : a. menyimpan data
b. melakukan perubahan/manipulasi terhadap data
c. menampilkan kembali data dengan lebih cepat dan mudah dibandingkan dengan cara biasa (baik manual ataupun elektronis). 2. Efisien ruang penyimpanan (space)
Dengan basis data dapat melakukan penekanan jumlah redundansi (pengulangan) data, baik dengan menerapkan sejumlah pengkodean atau dengan membuat relasi-relasi antara kelompok data yang saling berhubungan.
3. Keakuratan (accuracy)
Agar data sesuai dengan aturan dan batasan tertentu dengan cara memanfaatkan pengkodean atau pembentukan relasi antar data bersama dengan penerapan aturan/batasan (constraint) tipe data, domain data, keunikan data.
4. Ketersediaan (availability)
Agar data bisa diakses oleh setiap pengguna yang membutuhkan, dengan penerapan teknologi jaringan serta melakukan pemindahan/penghapusan data yang sudah tidak digunakan / kadaluwarsa untuk menghemat ruang penyimpanan.
5. Kelengkapan (completeness)
Agar data yang dikelola senantiasa lengkap baik relatif terhadap kebutuhan pengguna maupun terhadap waktu, dengan melakukan penambahan baris-baris data ataupun melakukan perubahan struktur
pada basis data; yakni dengan menambahkan field pada tabel atau menambah tabel baru.
6. Keamanan (security)
Agar data yang bersifat rahasia atau proses yang vital tidak jatuh ke orang / pengguna yang tidak berhak, yakni dengan penggunaan account (username dan password) serta menerapkan pembedaan hak akses setiap pengguna terhadap data yang bisa dibaca atau proses yang bisa dilakukan.
7. Kebersamaan (sharability)
Agar data yang dikelola oleh sistem mendukung lingkungan multiuser (banyak pengguna), dengan menjaga / menghindari munculnya problem baru seperti inkonsistensi data (karena terjadi perubahan data yang dilakukan oleh beberapa user dalam waktu yang bersamaan) atau kondisi deadlock (karena ada banyak pengguna yang saling menunggu untuk menggunakan data).
2.2 Teknologi Basis Data
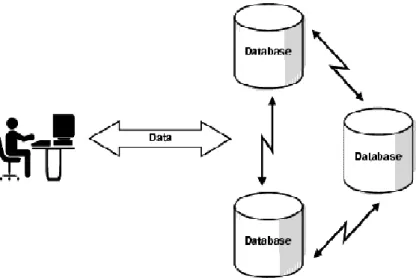
Distribusi basis data merupakan salah satu teknologi basis data. Basis data terdistribusi merupakan kumpulan database yang saling berhubungan secara logika dan tersebar pada sebuah jaringan komputer serta saling bekerjasama dalam melakukan suatu tugas.
Gambar 1. Distribusi Basis Data (Oracles8i administrator’s guide, 1999) Properti yang terutama terdapat pada basis data terdistribusi yaitu :
1. Independensi data terdistribusi : pengguna tidak perlu mengetahui dimana data berada (merupakan pengembangan prinsip independensi data fisik dan logika).
2. Transaksi terdistribusi yang atomic : pengguna dapat menulis transaksi yang mengakses dan mengubah data pada beberapa tempat seperti mengakses transaksi lokal.
Terdapat dua tipe basis data terdistribusi :
1. Homogen : yaitu sistem dimana setiap tempat menjalankan tipe DBMS yang sama.
2. Heterogen : yaitu sistem dimana setiap tempat yang berbeda menjalankan DBMS yang berbeda, baik Relational DBMS (RDBMS) atau non relational DBMS.
Keuntungan basis data terdistribusi, antara lain: 1. Pengawasan distribusi dan pengambilan data
Jika beberapa node yang berbeda dihubungkan, seorang pengguna yang berada pada satu node dapat mengakses data pada node lain.
Contoh : sistem distribusi pada sebuah bank memungkinkan seorang pengguna pada salah satu cabang dapat mengakses data cabang lain. 2. Reliability dan availability
Sistem distribusi dapat terus menerus berfungsi dalam menghadapi kegagalan dari node sendiri atau mata rantai komunikasi antar node. 3. Kecepatan pemrosesan query
Contoh : Jika node-node gagal dalam sebuah sistem terdistribusi, node lainnya dapat melanjutkan operasi jika data telah direplikasi pada beberapa node.
4. Efisiensi dan fleksibel
Data dalam sistem distribusi dapat disimpan dekat dengan titik dimana data tersebut dipergunakan. Data dapat secara dinamik bergerak atau disain, atau salinannya dapat dihapus.
Kerugian basis data terdistribusi, antara lain: 1. Harga software mahal
Hal ini disebabkan sangat sulit untuk membuat sistem database distribusi.
2. Kemungkinan kesalahan lebih besar
Node-node beroperasi secara paralel sehingga lebih sulit untuk menjamin
kebenaran dan algoritma. Adanya kesalahan mungkin tak dapat diketahui.
3. Biaya pemrosesan tinggi
Perubahan pesan dan penambahan perhitungan dibutuhkan untuk mencapai koordinasi antar node.
2.3 Database Clustering
Database clustering adalah kumpulan dari beberapa server yang berdiri sendiri
yang kemudian bekerjasama sebagai suatu sistem tunggal (Hodges, 2007). Saat ini aplikasi basis data semakin berkembang, baik dalam hal kegunaan, ukuran, maupun kompleksitas. Hal ini secara langsung berdampak pada server database sebagai penyedia layanan terhadap akses basis data, konsekuensi dari semua itu adalah beban database server akan semakin bertambah berat dan mengakibatkan kurang optimalnya kinerja dari server tersebut.
Clustering dapat digambarkan dengan jelas sebagai sebuah teknologi yang secara
otomatis mengijinkan sebuah physical server untuk meng-handle dan bertanggung jawab terhadap physical server lain yang mengalami kerusakan. Tujuan dari
clustering basis data adalah, walaupun hardware dan software komputer memiliki
kemungkinan mengalami kerusakan, memungkinkan bagi user untuk segera mengatasi kerusakan tersebut dan mencegah downtime suatu sistem.
Secara umum clustering dirancang untuk mengelompokkan sumber daya
(server-server) sehingga memiliki satu kesatuan komputasi. Clustering basis data
merupakan kumpulan server yang dikonfigurasikan oleh suatu perangkat lunak DBMS sehingga menjadi satu kesatuan sistem untuk menangani manajemen basis data (Anonim, Postgresql, 2008).
Menurut Vishal Batra (2008), salah satu manfaat dari clustering basis data adalah terjaganya aspek “Availibility”, artinya akses dari client pada jumlah tertentu secara simultan akan dijamin dapat dilayani oleh server-server dalam lingkungan
cluster. Keterjaminan layanan akan menyebabkan kelancaran akses client.
Clustering dapat juga digambarkan sebagai suatu grup dari dua atau lebih server
(nodes) yang bekerja secara bersamaan dan merepresentasikannya sebagai suatu
virtual server tunggal dalam suatu network (jaringan). Dengan kata lain, ketika
suatu client terhubung ke SQL Server yang memiliki cluster maka yang diketahui oleh client hanyalah suatu SQL Server tunggal. Ketika suatu node (server) mengalami kerusakan, maka tanggung jawab akan dialihkan ke server lain dalam
satu cluster dan akan ada pemberitahuan kepada end user jika ada perbedaan sebelum, selama dan setelah failover terjadi.
Tujuan utama daripada clustering server adalah:
1. High availability server system, dengan clustering server maka akan diperoleh Zero Downtime Server karena jika salah satu server mengalami
down makan server yang lain akan melakukan takeover secara otomatis
sehingga pengguna dan aplikasi tidak terasa jika terjadi perpindahan server yang aktif.
2. High performance server system, dengan clustering server dapat memiliki performance atau kinerja yang tinggi .
2.4 Definisi Distribusi Basis Data (Clustering)
Distribusi Basis Data (Clustering) memiliki beberapa definisi, antara lain:
1. Koleksi data secara logic yang saling berbagi dan secara physical didistribusikan melalui jaringan komputer, (Thomas Connolly, 2005). 2. Suatu alat untuk analisa data, yang memecahkan permasalahan
penggolongan. Obyek nya adalah untuk kasus pendistribusian (orang-orang, objek, peristiwa dll.) ke dalam kelompok, sedemikian sehingga derajat tingkat keterhubungan antar anggota cluster yang sama adalah kuat dan lemah antar anggota dari cluster yang berbeda, (McGraw Hill Professional, 2009).
3. Clustering merupakan suatu proses pembagian sekumpulan objek ke dalam suatu grup atau yang disebut dengan cluster. Cluster merupakan suatu grup dari kumpulan elemen yang sama atau memiliki kesamaan atau terjadi secara bersamaan, (Allan Hisrt, Postgresql, 2008)..
Gambar 2. Clustering Basis Data (IBM, 2006) 2.5 Mode Clustering
Clustering dapat dikonfigurasikan dalam dua mode yaitu : 1. Active/Passive mode :
Pada mode ini, hanya server aktif yang melayani permintaan client. Satu instansi SQL Server terinstal pada kedua sistem server. Dalam mode ini,
server kedua di cluster dikonfigurasi sebagai node pasif dan menjadi node
aktif jika server pertama rusak. Hanya satu lisensi SQL Server yang diperlukan pada mode ini.
2. Active/Active mode :
Pada mode ini, hanya server aktif yang melayani permintaan client. MSCS (Microsoft Cluster Service) memiliki hak untuk memilih salah satu server untuk melayani client. Jika salah satu node aktif rusak, resources akan dipindahkan ke node aktif yang lain.
2.6 Topologi Clustering
Ada empat tipe topologi clustering yaitu : 1. Single instance
Topologi Single instance disebut juga active-passive. Single instance clustering paling sering digunakan saat sistem mengalami mission-critical sehingga menghindari downtime.
2. Multi instance
Topologi Multi instance clustering disebut juga active-active, sebab jika salah satu server tidak aktif maka secara otomatis semua resources dipindahkan ke node aktif yang lain dan lebih efektif dibandingkan dengan
single instance cluster.
3. N+1
Topologi ini merupakan modifikasi multi instance dimana dua atau lebih node saling berbagi node failover yang sama. Node kedua membutuhkan kapabilitas hardware yang cukup untuk mendukung beban semua server dan pada suatu waktu semua server akan mengalami kegagalan secara bersamaan.
4. N+M
Topologi N+M memiliki keuntungan dibandingkan topologi N+1. Topologi N+M digunakan di environments dimana keterbatasan cost (biaya) memaksa untuk mengurangi jumlah node failover dan pada yang bersamaan memberikan tingkat kinerja yang tinggi.
2.7 Metodologi Distribusi Basis Data
Metodologi distribusi basis data yaitu load balancing dan failover. Untuk penjelasan load balancing dan failover dijelaskan pada sub bab berikut;
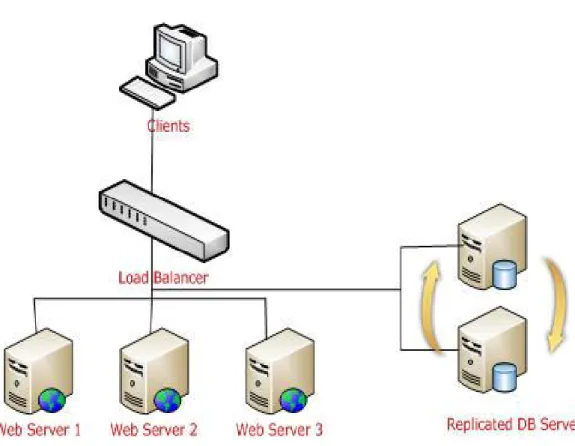
Proses ini mampu mengurangi beban kerja setiap server sehingga tidak ada server yang overload, memungkinkan server untuk menggunakan bandwidth yang tersedia secara lebih efektif, dan menyediakan akses yang cepat ke situs-situs yang di-hosting. Load balancing dapat diimplementasikan dengan menggunakan perangkat keras, perangkat lunak atau gabungan keduanya. Dengan konsep yang sederhana, sebuah load balancer diletakkan di antara client dan server. Load
balancer akan menampung trafik yang datang dan membaginya ke dalam
request-request individual lalu menentukan server mana yang menerima request-request tersebut. Layanan Load Balancing dimungkinkan pengaksesan sumber daya dalam jaringan didistribusikan ke beberapa host lainnya agar tidak terpusat sehingga unjuk kerja jaringan komputer secara keseluruhan bisa stabil (Iwan Rijayana, 2005). Ketika sebuah server sedang diakses oleh para pengguna, maka sebenarnya server tersebut sedang terbebani karena harus melakukan proses permintaan kepada para penggunanya. Jika penggunanya banyak maka prosesnya pun banyak. Session-session komunikasi dibuka oleh server tersebut untuk memungkinkan para pengguna menerima servis dari server tersebut.
Jika satu server saja terbebani, tentu server tersebut tidak bisa banyak melayani para penggunanya karena kemampuan melakukan processing ada batasnya. Solusi yang paling ideal adalah dengan membagi-bagi beban yang datang ke beberapa
server. Jadi yang melayani pengguna tidak hanya terpusat pada satu perangkat
Gambar 3. Load Balancing (IBM, 2006) Beberapa keuntungan dari penerapan load balancing antara lain :
1. Skalabilitas : Ketika beban sistem meningkat, kita dapat melakukan perubahan terhadap sistem agar dapat mengatasi beban sesuai dengan kebutuhan.
2. High Availability : Load balancer secara terus-menerus melakukan pemantauan terhadap server. Jika terdapat server yang mati, maka load
balancer akan menghentikan permintaan ke server tersebut dan
mengalihkannya ke server yang lain.
3. Manageability : Mudah ditata meskipun secara fisik sistem sangat besar. 4. Keamanan (Security) : Untuk semua trafik yang melewati load balancer,
aturan keamanan dapat diimplementasikan dengan mudah. Dengan private
2.7.2 Failover
Failover Clustering adalah proses dimana sistem operasi dan SQL Server 2000 bekerja sama untuk memberikan ketersediaan dalam hal kegagalan aplikasi, kegagalan perangkat keras, kesalahan sistem operasi. Failover clustering hanya tersedia dalam SQL Server Enterprise Edition 2000. Failover clustering memungkinkan pemeliharaan sistem yang akan dilakukan pada komputer sementara node yang lain melakukan pekerjaan dan juga memastikan bahwa sistem downtime dapat diminimalkan. Tujuan failover clustering adalah untuk memberikan availability (ketersediaan) yang tinggi dan mengakomodasi backup, redundansi, dan performance.
Failover clustering dengan Microsoft Cluster Service (MSCS) merupakan suatu cara yang popular untuk meningkatkan availability (ketersediaan) yang tinggi untuk SQL Server. Dengan MSCS, berbagai server atau node terhubung supaya berfungsi sebagai sistem tunggal dan menyediakan sebuah solusi failover secara otomatis. Dengan menggunakan MSCS (Microsoft Cluster Service), maka sangat mudah untuk mengatur suatu cluster database. Layanan MSCS tidak secara khusus untuk basis data clustering, tetapi berpotensi digunakan untuk basis data clustering. MSCS memiliki 3 model yaitu:
1. Single node server cluster (node tunggal cluster server), digunakan untuk mengatur resources pada sebuah server.
2. Single quorum (kuorum tunggal), digunakan untuk memelihara data konfigurasi cluster pada sebuah alat penyimpanan cluster tunggal yang dihubungkan ke semua node. Model single quorum hanya memiliki satu salinan basis data dan disimpan pada jenis perangkat keras tertentu.
3. Setiap node memelihara salinan sendiri dari data konfigurasi cluster. Lebih dari setengah, semua node dalam sebuah cluster harus bekerja untuk menjaga kerja cluster.
Failover Cluster memiliki beberapa manfaat, yaitu sebagai berikut;
1. Direncanakan menampung downtime. Failover cluster dapat memungkinkan untuk downtime sistem tanpa mempengaruhi ketersediaan. 2. Mengurangi downtime yang tidak direncanakan. Failover cluster mengurangi downtime aplikasi terkait dengan kegagalan server dan perangkat lunak dengan menghilangkan titik tunggal kegagalan di tingkat sistem dan aplikasi.
3. Dapat meningkatkan waktu respon. Desain Failover cluster dapat meningkatkan waktu respon karena meningkatnya beban pada server siaga atau kebutuhan untuk memperbarui informasi pada atau dari beberapa
server.
4. Meningkatkan biaya tetap. Perangkat keras tambahan yang memerlukan
failover cluster dengan mudah dapat melipatgandakan biaya infrastruktur.
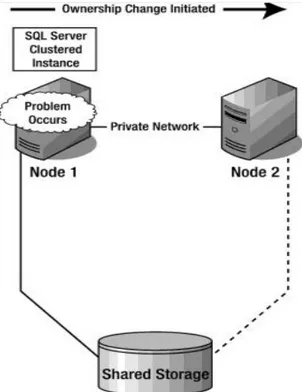
Tahapan proses failover clustering yaitu:
Suatu perusahaan terhubung ke virtual server dan tidak physical server dimana setiap physical server terdiri dari satu host atau beberapa virtual
Jika salah satu physical server gagal dikarenakan baik masalah perangkat keras atau perangkat lunak, maka MSCS akan mendeteksi kegagalan dan memindahkan resources yang berada pada server yang rusak termasuk
virtual server untuk satu atau lebih physical sever ke server lainnya dan
akan menjadi aktif.
End user (klien) yang terhubung ke server yang rusak hanya mengamati penundaan (delay) sesaat dalam mengakses resources, sementara MSCS
me-restart SQL Server services dan memapping kembali koneksi virtual
server (dapat dilihat pada Gambar 5).