Konferensi Nasional Ilmu Sosial & Teknologi (KNiST) Maret 2016, pp. 303~307
303
Kajian Penerapan Radial Base Function (RBF) Dalam
Mendeteksi Penyakit Tuberculosis (Tb)
Derry Wiliandani
AMIK BSI Karawang e-mail: [email protected]
Abstract
Nowadays in the world of health, the diagnosis of disease becomes a very difficult thing to do. However, medical records have stored symptoms of the patient's illness and the diagnosis of the illness. This kind of thing is very useful for health experts. Tuberculosis is one of the top ten diseases in Indonesia that can claim human life. The purpose of this study is to optimize the Radial Basis Function (RBF) neural network algorithm to improve accuracy in the prediction of tuberculosis. This study was made to predict Tuberculosis disease using Radial Basis Function (RBF) algorithm. To measure the accuracy level of the algorithm is used Counfusion Matrix testing method and ROC curve.
Keywords: Radial Base Function, Tuberculosis
1. Pendahuluan
Dewasa ini dalam dunia kesehatan, diagnosis penyakit menjadi hal yang sangat sulit dilakukan. Namun demikian catatan rekam medis telah menyimpan gejala-gejala penyakit pasien dan diagnosis penyakitnya. Hal seperti ini tentu sangat berguna bagi para ahli kesehatan. Mereka dapat menggunakan catatan rekam medis yang sudah ada sebagai bantuan untuk mengambil keputusan tentang diagnosis penyakit pasien. (Prasetyo, 2012). Penyakit Tuberculosis merupakan salah satu sepuluh penyakit terbesar di Indonesia yang bisa merenggut nyawa manusia. Berdasarkan hal tersebut untuk meningkatkan upaya menurunkan angka kesakitan dan revalensi timbulnya komplikasi pada penyakit Tuberculosis maka perlu kiranya dilakukan penelitian-penelitian yang mengarah pada pembuatan sistem yang dapat mendeteksi timbulnya penyakit Tuberculosis sehingga dapat dilakukan upaya prefentif serta upaya rehabilitatif bagi penderita Tuberculosis dengan pendekatan yang menyeluruh, sehingga dampak terjadinya berbagai penyakit menahun, seperti penyakit Tuberculosis. Informasi yang dihasilkan untuk selanjutnya bisa digunakan oleh edukator Tuberculosis maupun dokter sebagai dasar untuk melakukan tindakan tindakan yang diperlukan. 2. Metode Penelitian
Menurut (Kothari, 2004) Jenis penelitian eksperimen adalah metode yang menguji kebenaran sebuah hipotesis dengan statistik
dan menghubungkan dengan masalah penelitian. Jenis penelitian eksperimen dibagi dua, yaitu eksperimen absolut dan eksperimen komparatif. Eksperimen absolut mengarah kepada dampak yang dihasilkan dari eksperimen, misalnya pengaruh honor dosen terhadap kinerja. Sedangkan eksperimen komparatif yaitu membandingkan dua objek yang berbeda, misalnya membandingkan dua algoritma yang berbeda dengan melihat hasil statistik masing-masing yang mana lebih baik (Kothari, 2004). Penelitian yang penulis ambil untuk penelitian ini adalah Eksperimen Komparatif. Tujuan dari penelitian ini untuk melakukan evaluasi model neural network menggunakan Radial Basis Function (RBF) untuk mengetahui algoritma dalam memprediksi penyakit tuberculosis.. Sedangkan teknik pengumpulan data dilakukan dengan beberapa cara, antara lain:
1. Observasi
Penulis mengumpulkan data yang diperlukan dengan cara meninjau langsung ke perusahaan .
2. Wawancara
Dengan metode ini penulis melakukan wawancara kepada Staff Finance dengan mengajukan pertanyaan yang berhubungan dengan proses pencatatan dan pelaporan PPh 21 pada perusahaan.
3. Studi Pustaka
Dalam hal ini penulis selain observasi dan wawancara juga mengumpulkan data dengan mencari bahan referensi dari buku,
makalah, dan website. 3. Pembahasan
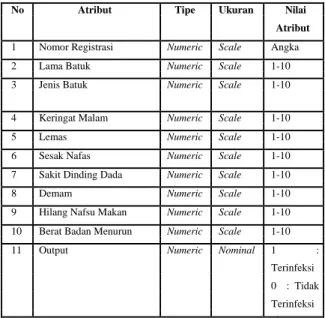
Tabel 1 Atribute, tipe, ukuran dan nilai Atribut
No Atribut Tipe Ukuran Nilai
Atribut
1 Nomor Registrasi Numeric Scale Angka 2 Lama Batuk Numeric Scale 1-10 3 Jenis Batuk Numeric Scale 1-10
4 Keringat Malam Numeric Scale 1-10 5 Lemas Numeric Scale 1-10 6 Sesak Nafas Numeric Scale 1-10 7 Sakit Dinding Dada Numeric Scale 1-10 8 Demam Numeric Scale 1-10 9 Hilang Nafsu Makan Numeric Scale 1-10 10 Berat Badan Menurun Numeric Scale 1-10 11 Output Numeric Nominal 1 :
Terinfeksi 0 : Tidak Terinfeksi
Data hasil pemeriksaan dapat dilihat pada tabel 2 berikut :
Tabel 2. Data hasil pemeriksaan penyakit tuberculosis
Hilan Nomor
Lama Jenis
Keringat Lema Sesak
Sakit
Dema
g Berat
NO Registras Batu Dindin Nafsu Badan Output
Batuk Malam s Nafas m
i k g Dada Maka Menurun
n 1 000826 5 1 1 1 2 1 3 1 1 0 2 000827 5 4 4 5 7 10 3 2 1 0 3 000828 3 1 1 1 2 2 3 1 1 0 4 000829 6 8 8 1 3 4 3 7 1 0 5 000830 4 1 1 3 2 1 3 1 1 0 6 000831 8 10 10 8 7 10 9 7 1 1 7 000832 1 1 1 1 2 10 3 1 1 0 8 000833 2 1 2 1 2 1 3 1 1 0 9 000834 2 1 1 1 2 1 1 1 5 0 10 000835 4 2 1 1 2 1 2 1 1 0 11 000836 1 1 1 1 1 1 3 1 1 0 12 000837 2 1 1 1 2 1 2 1 1 0 13 000838 5 3 3 3 2 3 4 4 1 1 14 000839 1 1 1 1 2 3 3 1 1 0 15 000840 8 7 5 10 7 9 5 5 4 1
ISBN: 978-602-61242-4-1
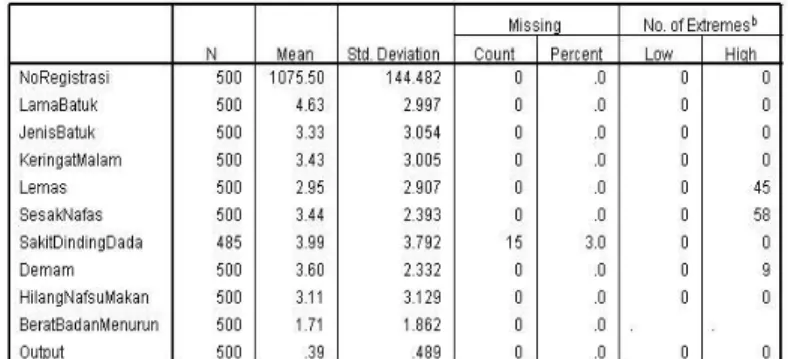
Berdasarkan tabel 2, data yang di peroleh untuk penelitian ini sebanyak 500 record hasil pemeriksaan penyakit tuberculosis, baik data yang bermasalah maupun data yang tidak bermasalah. Untuk mendapatkan data yang berkualitas diperlukan teknik dalam preprosessing (Han & Kamber, 2006), yaitu: 1. Data Cleaning
Data cleaning bekerja untuk membersihkan nilai yang kosong, tidak konsisten atau mungkin tuple yang kosong (missing values
Dari tabel 4 di atas, terlihat bahwa pada atribut dan noisy).
2. Data Integration Sakit Dinding Dada terdapat 1 record atau 3 Data Integration berfungsi menyatukan persen data yang memiliki missing value. tempat penyimpanan (arsip) yang berbeda Pengolahan Awal Data
ke dalam satu data. 1. Pembentukan Sumber Data Random (Set
3. Data Reduction the Random Seed)
Jumlah atribut dan tuple yang digunakan Ditentukan inisiasi pembangkit aktif (active untuk data training mungkin terlalu besar, generator initialization), yaitu nilai awal (starting hanya beberapa atribut yang diperlukan point) berupa nilai tetap (fixed value): 9191972. sehingga atribut yang tidak diperlukan akan
dihapus. Tuple dalam data set mungkin terjadi duplikasi atau terdapat tuple yang sama, sehingga untuk memprediksi jumlah tuple, tuple yang sama dijadikan dalam satu tuple untuk mewakili tuple tersebut.
Berdasarkan data yang diperoleh, tidak perlu lagi dilakukan data integration, hal ini disebabkan karena tempat penyimpanan (arsip) yang digunakan hanya bersumber dari satu tempat penyimpanan (arsip) saja, sehingga tidak diperlukan adanya proses penyatuan tempat penyimpanan (arsip). Sedangkan proses data cleaning dan data reduction perlu dilakukan. Hal ini disebabkan karena dalam data yang diperoleh masih terdapat kemungkinan adanya data yang bernilai kosong, tidak konsisten atau mungkin tuple yang kosong (missing values dan noisy) serta adanya kemungkinan terjadi duplikasi atau terdapat tuple yang sama.
a. Data Cleaning (Menghilangkan Missing
Value) Gambar 1. Pemilahan data untuk Training
b. Dalam data, terdapat 1 missing value, Sampel dan Holdout sample
seperti terlihat pada tabel 3 berikut : Setelah semua langkah yang dibutuhkan untuk Tabel 3. Data Missing Value analisa telah dilakukan, maka terlihat hasil
prediksi berdasarkan data training sebagai
berikut :
Berdasarkan data diatas, maka didapatkan hasil identifikasi seperti terlihat pada tabel 4 berikut:
Tabel 4. Statistik Missing Value
KNiST, 30 Maret 2016
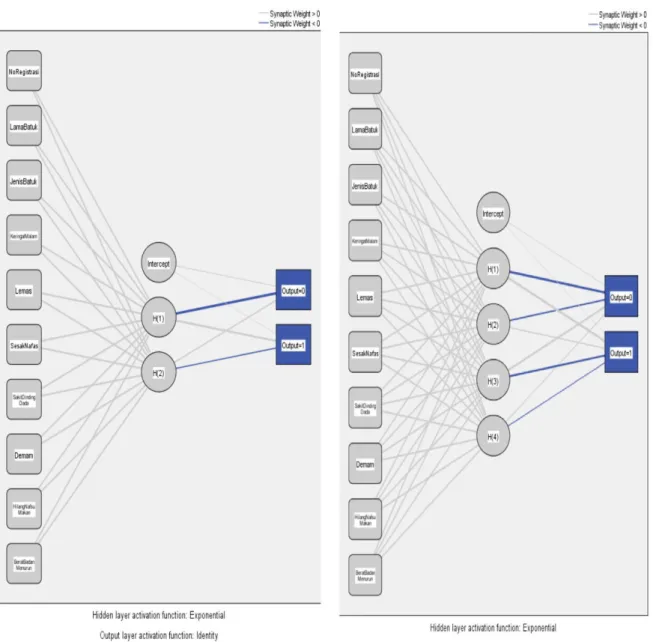
Gambar 2. Hasil Prediksi Data Training RBF
Gambar 3.Network Diagram RBF Training Diagram network yang terbentuk terdiri dari 10 input / predictors (tidak termasuk bias), 4 Hidden layer (tidak termasuk bias) dan 2 output (bernilai 0 dan 1).Setelah melampaui beberapa tahapan lanjutan, berikut ini gambaran dari hasil network testing:
4. Simpulan
Penelitian ini dibuat untuk memprediksi penyakit Tuberculosis menggunakan algoritma Radial Basis Function (RBF) untuk mengetahui akurasi dalam mendeteksi penyakit. Untuk mengukur tingkat akurasi tersebut digunakan metode pengujian Counfusion Matrix dan Kurva ROC. Berdasarkan pengukuran tingkat akurasi algoritma tersebut, diketahui bahwa algoritma RBF memiliki tingkat akurasi yang lebih tinggi. Dengan demikian, algoritma RBF dapat digunakan untuk prediksi penyakit Tuberculosis. 5. Referensi
Bramer, M. (2007). Principles of Data Mining. London: Springer.
Eldin, Ahmed. (2011). A Data Mining Approach for the Prediction of Hepatitis C Virus protease Cleavage Sites. Cairo : International Journal of Advanced
ISBN: 978-602-61242-4-1
Computer Science and Applications Vol 2 John Wiley & Sons, Inc.
No.12. Ozyilmaz, Lale & Yildirim, Tulay. (2003). Gorunescu, Florin. (2011). Data Mining: Artificial Neural Network for Diagnosis of
Concepts and Techniques. Verlag berlin Hepatitis Disease.
Heidelberg: Springer Riduwan. (2008). Metode dan Teknik Menyusun Han, J., & Kamber, M. (2007). Data Mining Tesis. Bandung: Alfabeta.
Concepts and Techniques. San Santosa, B. (2007). Data Mining Teknik Fransisco: Mofgan Kaufan Publisher. Pemanfaat Data Untuk Keperluan Bisnis. Karlik. (2011). Hepatitis Disease Diagnosis Yogyakarta: Graha Ilmu.
Using Backpropagation and the Naive Shukla, A., Tiwari, R., & Kala, R. (2010). Real Bayes Classifiers. Turkey : Journal of Life Application of Soft Computing. Taylor Science and Technology Vol. 1 No. 1. and Francis Groups, LLC.
Kumar, D. Senthil & Sathyadevi, G & Sivanesh, UCI (Universitas California, Invene) Machine S. (2011). Decision Support System for Learning Repository dengan alamat Medical Diagnosis Using Data Mining. website
India : International Journal of Computer http://archive.ics.uci.edu/ml/machine- Science Issues, Vol 8, Issue 3, No. 1. learning-databases/hepatitis/
Kumar, Varun & Sharathi, Vijay & Devi,
Gayathri (2012). Hepatitis Prediction UCI (Universitas California, Invene) Machine Model based on Data Mining Algorithm Learning Repository dengan alamat and Optimal Feature Selection to Improve website
Predictive Accuracy. Vellore : http://archive.ics.uci.edu/ml/machine- International Journal of Computer learning-databases/00225/
Applications (0975-8887) Volume 51 -
No. 19. Vercellis, C. (2009). Business Intelligent: Data Kusrini, & Luthfi, E. T. (2009). Algoritma Data Mining and Optimization for Decision
Mining. Yogyakarta: Andi Publishing. Making. Southern Gate: John Willey & Larose, D. T. (2005). Discovering Knowledge in Sons Inc.
Databases. New Jersey: John Willey & Witten, H. I., Eibe, F., & Hall, A. M. (2011). Data
Sons Inc. Mining Machine Learning Tools and
Liao. (2007). Recent Advances in Data Mining Techiques. Burlington: Morgan Kaufmann of Enterprise Data: Algorithms and Publisher.
Application . Singapore: World Scientific Wu, X., & Kumar, V. (2009). The Top Ten
Publishing. Algorithms in Data Mining. Boca Raton:
Myatt, Glenn J. (2007). Making Sense of Data: CRC Press. A Practical Guide to Exploratory Data
Analysis and Data Mining. New Jersey:
KNiST, 30 Maret 2016