Abstrak— Pertumbuhan ekonomi adalah proses perubahan
kondisi perekonomian suatu negara secara berkesinambungan menuju keadaan yang lebih baik selama periode tertentu. Pertumbuhan ekonomi global sekarang ini mengalami perlambatan, walaupun demikian ekonomi jawa timur menurut hasil penelitian dari Badan Pusat statistik Jawa Timur masih tumbuh stabil secara umum jika diukur dari PDRB (Produk Domestik Regional Bruto), tetapi hanya pada beberapa daerah saja yang mengalami pertumbuhan ekonomi. Sangat disayangkan jika dengan pertumbuhan ekonomi yang tinggi tetapi produksi (sektor) dari setiap daerah kurang maksimal. Untuk mencegah terjadinya ketimpangan antar daerah perlu dilakukan pengelompokan daerah berdasarkan sektor-sektor yang dihasilkan sehingga pembangunan daerah pun akan semakin berkembang.
Oleh karena itu, pada paper ini dilakukan metode clustering untuk mengetahui potensi daerah berdasarkan sektor-sektornya, sehingga kebijakan yang akan dilakukan kedepannya pun dapat dilakukan secara tepat. Di sisi lain, paper ini juga bertujuan untuk membandingkan metode yang terbaik dari beberapa metode dalam pengelompokan hirarki (single linkage, complete linkage, average linkage, metode ward) dan non hierarki (k-means). Perbandingan metode dinilai berdasarkan icdrate, dimana dengan 4 kelompok Ward mampu memberikan hasil pengelompokan terbaik.
Kata kunci : Pertumbuhan Ekonomi, Metode Clustering,
Ward.
I. PENDAHULUAN
ertumbuhan ekonomi adalah proses perubahan kondisi perekonomian suatu negara secara berkesinambungan menuju keadaan yang lebih baik selama periode tertentu. Pertumbuhan ekonomi dapat diartikan juga sebagai proses kenaikan kapasitas produksi suatu perekonomian yang diwujudkan dalam bentuk kenaikan pendapatan nasional. Adanya pertumbuhan ekonomi merupakan indikasi keberhasilan pembangunan ekonomi[1]. Pertumbuhan ekonomi suatu daerah dapat diukur dengan melihat PDRB (Produk Domestik Regional Bruto). PDRB ADHK (Atas Dasar Harga Konstan) adalah pertumbuhan ekonomi dari tahun ke tahun, untuk menunjukan laju pertumbuhan ekonomi secara keseluruhan atau setiap sektor dari tahun ke tahun. Di tengah perlambatan ekonomi global, ekonomi Jawa Timur tercatat masih tumbuh stabil dan mengalami percepatan dibandingkan ekonomi kawasan Sumatera atau daerah lain di Jawa. Pertumbuhan ekonomi Jawa Timur pada pada 2012 sebesar 7,27%, lebih baik dibanding 2011 sebesar 7,22%. Pencapaian ini jauh lebih tinggi dari pertumbuhan ekonomi secara nasional yang pada 2012 sebesar 6,23%[2].
Sangat disayangkan jika dengan pertumbuhan ekonomi yang tinggi tetapi produksi (sektor) dari setiap daerah kurang maksimal. Untuk mencegah terjadinya ketimpangan antar daerah maka dilakukan pengelompokan daerah berdasarkan sektor-sektor yang dihasilkan sehingga pembangunan daerah pun akan semakin berkembang.
Dalam analisis statistik, sektor-sektor yang ada dinyatakan sebagai variabel. Untuk meringkas data dengan peubah banyak, akan digunakan analisis cluster untuk mengelompokkan objek-objek berdasarkan karakteristik diantara objek-objek tersebut. Sebagai hasilnya akan terbentuk kelompok-kelompok dengan ciri khas tiap kelompok.
Karena itu, dalam paper ini penulis ingin membahas tentang analisis cluster Kabupaten/Kota di Jawa Timur dengan variabel Sembilan sektor yang ada di Jawa Timur untuk mengetahui pengelompokan kabupaten/kota sehingga pertumbuhan ekonomi Jawa Timur dapat berkembang secara signifikan.
II. TINJAUANPUSTAKA A. Analisis Multivariat
Analisis multivariat merupakan analisis beberapa variabel dalam hubungan tunggal atau banyak hubungan. Analisis multivariat juga didefinisikan sebagai analisis dimana masalah yang diteliti bersifat multidimensional dan menggunakan tiga atau lebih variabel [7]. Jika terdapat sebanyak 𝑛 objek dan 𝑝 variabel, maka observasi objek ke-i dan variabel ke-j yang dinotasikan 𝑥𝑖𝑗 dengan 𝑖 = 1,2, … , 𝑛 dan 𝑗 = 1,2, … , 𝑝 dapat ditampilkan pada Tabel 1 sebagai berikut :
Tabel 1. Hubungan Beberapa Variabel dan Beberapa Objek
Var 1 Var 2 ⋯ Var j ⋯ Var p Objek 1 𝑥11 𝑥12 ⋯ 𝑥1𝑗 ⋯ 𝑥1𝑝 Objek 2 𝑥21 𝑥22 ⋯ 𝑥2𝑗 ⋯ 𝑥2𝑝 ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ Objek i 𝑥𝑖1 𝑥𝑖2 ⋮ 𝑥𝑖𝑗 ⋮ 𝑥𝑖𝑝 ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ Objek n 𝑥𝑛1 𝑥𝑛2 ⋮ 𝑥𝑛𝑗 ⋮ 𝑥𝑛𝑝 B. Analisis Faktor
Alasisis faktor merupakan suatu teknik yang bertujuan untuk mendefinisikan struktur yang mendasar pada antar variabel. Analisis faktor dapat menggambarkan variabel yang saling berkorelasi dengan kuantitas random yang disebut sebagai faktor[6].
Analisis Cluster Kabupaten/Kota Berdasarkan
Pertumbuhan ekonomi Jawa Timur
Siti Machfudhoh, Nuri Wahyuningsih
Jurusan Matematika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Teknologi Sepuluh Nopember (ITS)
Jl. Arief Rahman Hakim, Surabaya 60111 E-mail: nuri@matematika.its.ac.id
Beberapa hal yang harus dipenuhi sebelum dilakukan analisis faktor adalah adanya korelasi antar variabel dan adanya kecukupan sampel. Pengujian dapat dilakukan dengan barlett Tess of Spericity seperti pada persamaan berikut :
Hipotesa :
𝐻0 : R = 1 (matriks korelasi sama dengan matriks identitas)
𝐻1 : R ≠ 1 (matriks korelasi tidak sama dengan matriks identitas) Statistik Uji : 6 5 2 1 | | ln R n p Bartlett dengan,
|R| : nilai determinan dari matriks korelasi n : banyaknya pengamatan
p : banyaknya variabel Kriteria pengujian :
Tolak 𝐻0 jika uji Bartlett > 𝑋 𝑝 +1 𝑝 −2 2 (∝)
2 atau P-value < ∝ maka variabel-variabel saling berkorelasi, hal ini berarti terdapat hubungan antar variabel, sehingga layak dilakukan analisis faktor.
Selanjutnya, untuk kecukupan sampel dilakukan uji Kaizer-Meyer-Olkin (KMO). Dimana diharapkan nilai KMO lebih besar dari 0.5 agar dapat dilakukan analisis faktor[5]. Hipotesa:
𝐻0 ∶ Data Layak untuk dianalisis 𝐻1 ∶ Data tidak layak dianalisis Statistik Uji :
j i ij j i ij j i ij a r r KMO 2 2 2 dengan, 2 ijr
: korelasi antara variabel i dan j 2ij
a
: korelasi parsial antara variabel i dan j Kriteria pengujian:𝐻0 ditolak jika nilai KMO < 0.5
Jadi dapat disimpulkan bahwa data tidak cukup untuk dilakukan analisis faktor.
C. Calinski-Harabasz Pseudo F-statistic
Pseudo F-statistic adalah salah satu metode yang umum digunakan untuk menentukan banyaknya kelompok yang optimum. Rumus Pseudo-F ditulis dalam persamaan berikut[6]: c n R c R F Pseudo 2 2 1 1 dengan, SST SSW SST R2 𝑆𝑆𝑇 = 𝑥𝑖𝑗𝑘− 𝑥 𝑘 2 𝑝 𝑘=1 𝑐 𝑗 =1 𝑛𝑐 𝑖=1 𝑆𝑆𝑊 = 𝑥𝑖𝑗𝑘− 𝑥 𝑗𝑘 2 𝑝 𝑘=1 𝑐 𝑗 =1 𝑛𝑐 𝑖=1 D. Metode Hierarki
Metode hierarki merupakan metode pengelompokan yang hasilnya disajikan secara bertingkat atau berjenjang dari n, n − 1 , … ,1 kelompok[3]. Fungsi jarak yang seringkali digunakan adalah jarak Euclid, yang didefinisikan sebagai jarak antara observasi ke-i dan ke-k. Rumus jarak Euclid dari objek ke-i menuju objek ke-h dirumuskan pada persamaan:
𝑑 𝑖, ℎ = 𝑝𝑘=1 𝑥𝑖𝑘− 𝑥ℎ𝑘 2 ;
𝑖 = 1,2, … , 𝑛
𝑘 = 1,2, … , 𝑝 ; 𝑖 ≠ ℎ ( 2 )
Beberapa macam metode hierarki penggabungan (agglomerative) berdasarkan linkage diantaranya sebagai berikut[7] :
1. Single Linkage
Metode ini membentuk kelompok-kelompok dari individu dengan menggabungkan jarak paling pendek terlebih dahulu atau kemiripan yang paling besar. Pada awalnya, dipilih jarak terpendek dalam 𝐷 = 𝑑𝑖,ℎ yang sudah dihitung sebelumnya dengan jarak Euclid dan menggabungkan objek-objek yang bersesuaian untuk membentuk suatu 𝑐 kelompok. Dirumuskan pada persamaan:
𝑑(𝑖ℎ)𝑔 = 𝑚𝑖𝑛 𝑑𝑖𝑔, 𝑑ℎ𝑔 dengan,
2. Complete Linkage
Complete linkage membentuk kelompok-kelompok dari individu dalam cluster berada paling jauh satu sama lainnya. Langkah pertama yaitu menghitung jarak antar objek dengan menggunakan jarak Euclid seperti pada persamaan (2) dan didapatkan jarak untuk objek i dengan objek lain h yang dinotasikan dengan 𝐷 = 𝑑𝑖,ℎ kemudian dipilih jarak terjauh dan menggabungkan objek-objek yang bersesuaian. Metode ini dirumuskan sebagai berikut :
𝑑(𝑖ℎ)𝑔= 𝑚𝑎𝑥 𝑑𝑖𝑔, 𝑑ℎ𝑔 ( 3 ) 3. Average Linkage
Metode ini memperlakukan jarak antara dua cluster sebagai jarak rata-rata antara semua pasangan individu. Sama dengan 2 metode sebelumnya, langkah pertama yaitu menghitung jarak antar objek dengan rumus jarak Euclid dan didapatkan jarak antara objek i dengan objek h, 𝐷 = 𝑑𝑖,ℎ . Untuk memperoleh penggabungan (aglomerasi) objek satu dengan lainnya dirumuskan sebagai berikut : 𝑑(𝑖ℎ)𝑔 = 𝑑𝑖 𝑔 𝑖𝑔
𝑁(𝑖ℎ )𝑁𝑔 ( 4 ) 4. Ward’s Method
Pengelompokan metode Ward adalah memperkecil total jumlah eror kuadrat dalam kelompok. Jika cluster sebanyak 𝑐 maka 𝑆𝑆𝐸 merupakan jumlahan dari 𝐸𝑆𝑆𝑐.
𝐸𝑆𝑆 = 𝐸𝑆𝑆1+ 𝐸𝑆𝑆2+ ⋯ + 𝐸𝑆𝑆𝑐
Saat semua cluster bergabung menjadi satu kelompok dari 𝑁 item, maka nilai ESS dirumuskan :
𝐸𝑆𝑆 = (𝒙𝑗− 𝒙 )′(𝒙 𝑗 − 𝒙 ) 𝑛
𝑗 =1
E. Metode Non Hierarki
Berlawanan dengan metode hierarki, prosedur pengelompokan non hierarki ini tidak dilakukan secara bertahap dan jumlah kelompoknya juga ditentukan terlebih dahulu. Metode yang tergolong pengelompokan non hierarki diantaranya k-means.
Pengelompokan dengan menggunakan metode k-means didasarkan pada nilai fungsi keanggotaannya. Fungsi keanggotaannya didasarkan pada jarak minimum antar objek dengan pusat cluster (centroid).
Algoritma k-means bertujuan untuk meminimasi fungsi objektif yang merupakan fungsi error kuadrat. Misal ada n objek dan p variabel. Jarak antara objek ke-i dan kelompok ke-l dihitung menggunakan jarak Euclid kuadrat dirumuskan persamaan: 𝐷[𝑖, 𝑙] = 𝑝 𝑋 𝑖, 𝑗 − 𝑋 𝑙, 𝑗 2 𝑗 =1 ; 𝑖 = 1,2, … , 𝑛 𝑗 = 1,2, … , 𝑝 ( 5 ) dengan,
𝑋(𝑖, 𝑗) : nilai antara objek ke-i terhadap variabel ke-j 𝑋 𝑙, 𝑗 : rata-rata variabel ke-j terhadap kelompok ke-l 𝐷[𝑖, 𝑙(𝑖)]:jarak Euclid antara objek ke-i dan rata-rata cluster dari cluster objek (centroid).
F. Internal Cluster Dispersion Rate (icdrate)
Perbandingan metode pengelompokan dapat diukur dengan menghitung rata-rata persebaran internal cluster terhadap partisi secara keseluruhan. Metode ini sering digunakan dalam menaksir akurasi dari algoritma pengelompokan. Semakin kecil nilai icdrate, semakin baik hasil pengelompokannya. Perhitungan internal cluster dispersion rate (icdrate) sebagai berikut :
𝑖𝑐𝑑𝑟𝑎𝑡𝑒 = 1 − 𝑅2
G. Multivariate Analisis of Varians (MANOVA)
MANOVA adalah teknik yang digunakan untuk membandingkan rata-rata dua populasi atau lebih. Uji MANOVA dilakukan setelah data memenuhi asumsi-asumsi [2] :
1. Matriks varians kovarians antar perlakuan identik/homogen.
2. Setiap populasi memiliki distribusi multivariat normal (Multivariate Normal Distribution).
Uji pengaruh perlakuan (Uji MANOVA) : Hipotesis : 𝐻0 ∶ 𝝁1= 𝝁2= ⋯ = 𝝁𝑐= 0 𝐻1 ∶ minimal 1 pasang 𝝁𝑗 ≠ 0 (𝑗 = 1,2, … , 𝑐) Statistik uji : 𝑛𝑗−𝑔−𝑖 𝑔−𝑖 1− Λ∗ Λ∗ > 𝐹𝑛𝑐−1,𝑛−𝑛𝑐(𝛼); Dimana Λ∗= 𝑾 𝑩+𝑾 Kriteria pengujian : 𝐻0 ditolak jika 𝐹ℎ𝑖𝑡𝑢𝑛𝑔 > 𝐹𝑛𝑐−1,𝑛−𝑛𝑐(𝛼).,
maka terdapat perbedaan perlakuan antar kelompok. Tabel 2 MANOVA
Sumber variasi Df Sum of squares
Perlakuan K-1 𝑩 Residual 𝒏𝒋− 𝑲 𝑲 𝒋=𝟏 𝑾 Total 𝒏𝒋− 𝟏 𝑲 𝒋=𝟏 𝑩 + 𝑾
H. Pertumbuhan Ekonomi Jawa Timur
Jawa Timur sebagai salah satu provinsi Indonesia mempuyai daerah yang sangat potensial dalam pembangunan nasional, mempunyai wilayah yang luasnya terdiri dari 47.157.72 km2 berupa daratan dan 2.833,85 km2
lautan. Jawa Timur terdiri dari 38 kabupaten/kotamadya, yakni 29 kabupaten dan 9 kotamadya. Jawa Timur merupakan daerah berpotensi untuk perkembangan sehingga keadaan ekonomi Jawa Timur sangat berpengaruh terhadap perekonomian nasional. Perkembangan pertumbuhan ekonomi Jawa Timur hampir sama dengan pertumbuhan ekonomi nasional.
Pertumbuhan ekonomi tingkat provinsi dapat dihitung dari PDRB, yang dilihat dari tiga sisi yaitu produksi, pendapatan dan pengeluaran. Penyajian pendapatan regional dibedakan atas dasar harga berlaku dan konstan. Dimana pendekatan produksi meliputi sektor pertanian, sektor pertambangan dan penggalian, sektor industri, sektor listrik,gas, dan air bersih, sektor bangunan, sektor perdagangan, hotel dan restoran, sektor pengangkutan dan komunikasi, sektor keuangan, persewahan, dan jasa perusahaan, dan sektor jasa-jasa.
III. PEMBAHASAN A. Deskripsi Statistik
Secara statistik pada tahun 2012, deskripsi mengenai Pertumbuhan Ekonomi beserta sektor-sektor yang mempengaruhinya di provinsi Jawa Timur dapat diketahui berdasarkan ukuran pemusatan dan ukuran penyebarannya. Dengan menggunakan ukuran pemusatan ini maka akan diketahui secara rata-rata pertumbuhan ekonomi dan faktor-faktornya di Jawa Timur.
Tabel 3. Deskripsi Statistik PDRB ADHK (dalam jutaan rupiah) Jawa Timur yang Diterbitkan pada Tahun 2012
Variabel Minimum Maximum Rata-rata Standar Deviasi SP 37142.38 96688943.00 3869778.98 15504935.75 SPP 0.00 1390418.79 204132.88 321645.13 SIP 26862.10 19143125.16 2254515.16 4653348.51 SLGA 5831.85 2044665.98 126339.51 331805.43 SK 11309.30 6195947.16 359704.49 1076840.45 SPHR 194033.67 98748718.00 5252765.64 6095469.77 SPK 15640.32 12512795.31 715899.60 2087283.30 SKPJ 73848.63 6089076.15 502907.43 978905.57 SJ 0.00 8223401.82 770159.03 1322919.68
Diantara beberapa keberagaman tertinggi ditunjukkan oleh tabel 3, keberagaman tertinggi ditunjukkan oleh sektor pertanian yaitu sebesar 15504935,75432 dimana terdapat kabupaten /kota dengan nilai sangat kecil dan sangat besar pada sektor pertanian.
B. Analisis Faktor
Sebelum mengelompokkan objek berdasarkan faktor-faktor, perlu dilakukan reduksi variabel. Hal ini ditujukan untuk mengatasi adanya korelasi antar variabel yang dapat mengganggu proses pembentukan kelompok.
Adanya korelasi antar variabel dapat diketahui melalui pengujian independensi dengan tes Barlett.
Hipotesa:
𝐻0∶ 𝜌 = 𝐼 (matriks korelasi sama dengan matriks identitas)
𝐻1∶ 𝜌 ≠ 𝐼 (matriks korelasi tidak sama dengan identitas)
Statistik Uji : 𝑋ℎ𝑖𝑡𝑢𝑛𝑔2 = 454,963
𝜒𝑡𝑎𝑏𝑒𝑙2 = 𝑋0,05,72 2 2 = 50,99846
Karena 𝑋ℎ𝑖𝑡𝑢𝑛𝑔2 > 𝜒𝑡𝑎𝑏𝑒𝑙2 atau 454,963 > 50,9984,dan 𝑝 − 𝑣𝑎𝑙𝑢𝑒 < 𝛼 seperti yang ditunjukkan pada Tabel 4. maka 𝐻0 diterima sehingga antar variabel prediktor bersifat dependen, dan dapat dilakukan analisis faktor.
Tabel 4. Uji Kelayakan Analisis Faktor
Keterangan Nilai
KMO measure of sampling adequacy 0.861
Bartlett’s Test 454.963
Sebelumnya melakukan analisis faktor perlu dilakukan pemeriksaan kecukupan sampel untuk dikatakan bahwa analisis faktor layak dilakukan.
Hipotesa :
𝐻0 : Jumlah data cukup secara statistik 𝐻1 : Jumlah data tidak cukup secara statistik Statistik uji :
KMO = 0,861
Karena nilai KMO >0,5 maka 𝐻0 diterima, jadi data cukup secara statistik, dan layak dianalisis.
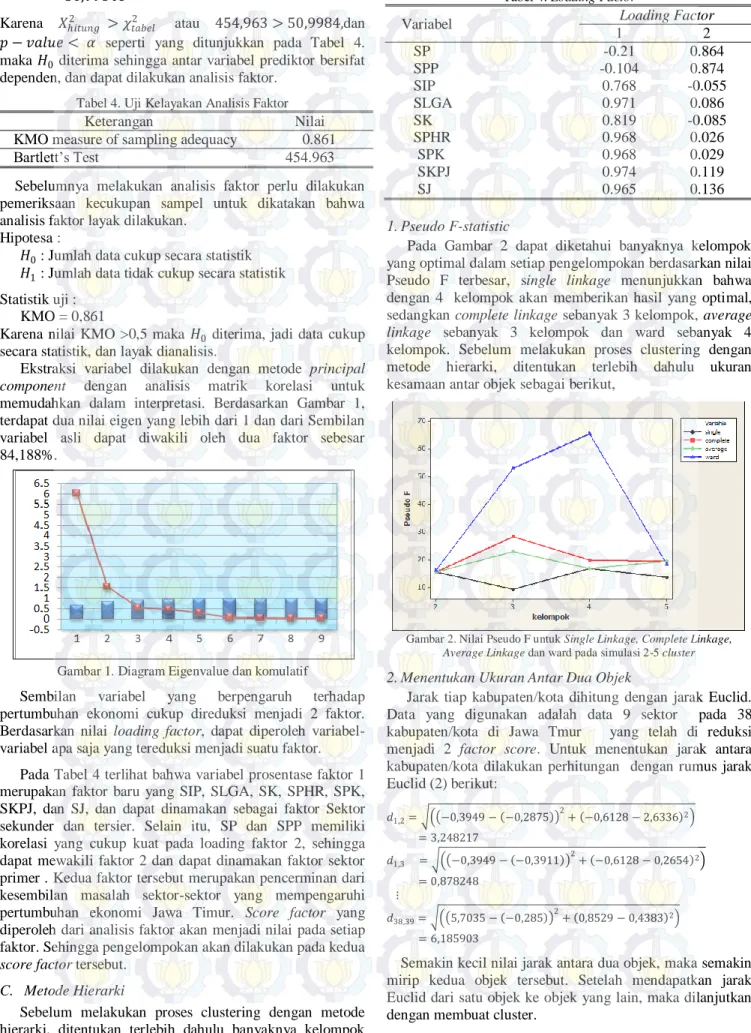
Ekstraksi variabel dilakukan dengan metode principal component dengan analisis matrik korelasi untuk memudahkan dalam interpretasi. Berdasarkan Gambar 1, terdapat dua nilai eigen yang lebih dari 1 dan dari Sembilan variabel asli dapat diwakili oleh dua faktor sebesar 84,188%.
Gambar 1. Diagram Eigenvalue dan komulatif
Sembilan variabel yang berpengaruh terhadap pertumbuhan ekonomi cukup direduksi menjadi 2 faktor. Berdasarkan nilai loading factor, dapat diperoleh variabel-variabel apa saja yang tereduksi menjadi suatu faktor.
Pada Tabel 4 terlihat bahwa variabel prosentase faktor 1 merupakan faktor baru yang SIP, SLGA, SK, SPHR, SPK, SKPJ, dan SJ, dan dapat dinamakan sebagai faktor Sektor sekunder dan tersier. Selain itu, SP dan SPP memiliki korelasi yang cukup kuat pada loading faktor 2, sehingga dapat mewakili faktor 2 dan dapat dinamakan faktor sektor primer . Kedua faktor tersebut merupakan pencerminan dari kesembilan masalah sektor-sektor yang mempengaruhi pertumbuhan ekonomi Jawa Timur. Score factor yang diperoleh dari analisis faktor akan menjadi nilai pada setiap faktor. Sehingga pengelompokan akan dilakukan pada kedua score factor tersebut.
C. Metode Hierarki
Sebelum melakukan proses clustering dengan metode hierarki, ditentukan terlebih dahulu banyaknya kelompok
yang optimal pada masing-masing metode hirarki ini didasarkan pada nilai statistik Pseudo F yang optimal.
Tabel 4. Loading Factor
Variabel Loading Factor
1 2 SP -0.21 0.864 SPP -0.104 0.874 SIP 0.768 -0.055 SLGA 0.971 0.086 SK 0.819 -0.085 SPHR 0.968 0.026 SPK 0.968 0.029 SKPJ 0.974 0.119 SJ 0.965 0.136 1. Pseudo F-statistic
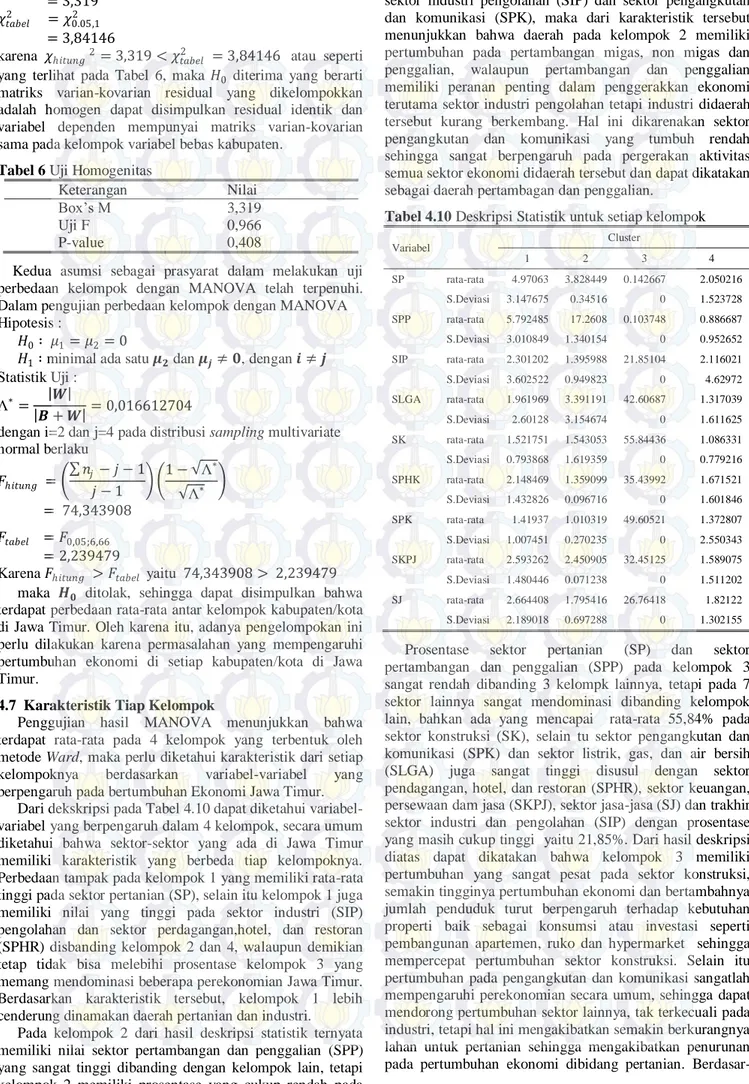
Pada Gambar 2 dapat diketahui banyaknya kelompok yang optimal dalam setiap pengelompokan berdasarkan nilai Pseudo F terbesar, single linkage menunjukkan bahwa dengan 4 kelompok akan memberikan hasil yang optimal, sedangkan complete linkage sebanyak 3 kelompok, average linkage sebanyak 3 kelompok dan ward sebanyak 4 kelompok. Sebelum melakukan proses clustering dengan metode hierarki, ditentukan terlebih dahulu ukuran kesamaan antar objek sebagai berikut,
Gambar 2. Nilai Pseudo F untuk Single Linkage, Complete Linkage,
Average Linkage dan ward pada simulasi 2-5 cluster
2. Menentukan Ukuran Antar Dua Objek
Jarak tiap kabupaten/kota dihitung dengan jarak Euclid. Data yang digunakan adalah data 9 sektor pada 38 kabupaten/kota di Jawa Tmur yang telah di reduksi menjadi 2 factor score. Untuk menentukan jarak antara kabupaten/kota dilakukan perhitungan dengan rumus jarak Euclid (2) berikut: 𝑑1,2= −0,3949 − −0,2875 2+ −0,6128 − 2,6336 2 = 3,248217 𝑑1,3 = −0,3949 − −0,3911 2 + −0,6128 − 0,2654 2 = 0,878248 ⋮ 𝑑38,39= 5,7035 − −0,285 2+ 0,8529 − 0,4383 2 = 6,185903
Semakin kecil nilai jarak antara dua objek, maka semakin mirip kedua objek tersebut. Setelah mendapatkan jarak Euclid dari satu objek ke objek yang lain, maka dilanjutkan dengan membuat cluster.
3. Single Linkage
Berdasarkan hasil nilai Pseudo F yang telah dilakukan sebelumnya maka didapat kelompok yang paling optimal pada single linkage yaitu dengan 4 kelompok. Maka, didapat keanggotaan kabupaten /kota pada setiap kelompok diantaranya sebagai berikut,
Kelompok 1 : Pacitan, Sampang, Lumajang, Tulungagung, Blitar, Kediri, Sumenep, Jombang, Trenggalek, Situbondo, Nganjuk, Bangkalan, Probolinggo, Mojokerto, Pasuruan, Madiun, Bondowoso, Pamekasan, kota Blitar, kota Pasuruan, kota Batu, kota Probolinggo, kota Mojokerto, kota Madiun, Magetan, Ngawi, Lamongan, sidoarjo, kota Kediri, kota Malang, Malang, Gresik, Jember, dan Banyuwangi.
Kelompok 2 : Tuban dan Bojonegoro. Kelompok 3 : Ponorogo.
Kelompok 4 : Surabaya. 4. Complete Linkage
Langkah-langkah proses clustering dengan metode complete linkage hampir sama seperti single linkage. Yang membedakan yaitu proses clustering pada complete linkage berdasarkan jarak maksimum atau terjauh dengan menggunakan persamaan (3). Banyaknya kelompok yang memiliki nilai statistik Pseudo F terbesar dengan menggunakan complete linkage adalah sebanyak 3 kelompok. Maka dengan melihat anggota dari masing-masing cluster didapatkan :
Kelompok 1 : Pacitan, Sampang, Sumenep, Tulungagung, Blitar, Lumajang, Kediri, Jombang, Trenggalek, Situbondo, Nganjuk, Bangkalan, Probolinggo, Mojokerto, Pasuruan, Madiun, Bondowoso, Pamekasan, kota Blitar, kota Pasuruan, kota Batu, kota Probolinggo, kota Mojokerto, kota Madiun, Magetan, Ngawi, Lamongan, sidoarjo, kota Kediri, kota Malang, dan Ponorogo.
Kelompok 2 : Malang, Gresik, Jember, Banyuwangi, Tuban, dan Bojonegoro.
Kelompok 3 : Surabaya.
Pada pengelompokan diatas terlihat bahwa kelompok 2 terbentuk dari kelompok 2 pada Single Linkage dan beberapa anggota kelompok 1. Selain itu, seperti pada metode sebelumnya kota Surabaya membentuk cluster sendiri.
5. Average Linkage
Nilai Pseudo F tertinggi pada metode average linkage menunjukkan bahwa kelompok optimalnya adalah 3 seperti pada Gambar 2. Dimana, kelompok 1 terdiri dari 35 kabupaten/kota, kelompok 2 terdiri dari 2 kabupaten/kota dan kelompok 3 terdiri dari 1 kabupaten/kota yaitu Surabaya sendiri seperti pada clustering sebelumnya.
Hasil Pengelompokan dengan Average Linkage menunjukkan bahwa memang pengelompokan dengan Average Linkage hampir sama dengan single Linkage, tetapi kabupaten Ponorogo bergabung pada kelompok 1. Seperti yang terlihat pada hasil berikut,
Kelompok 1: Pacitan, Sampang, Sumenep, Tulungagung, Blitar, Lumajang, Kediri, Jombang, Trenggalek, Situbondo, Nganjuk, Bangkalan, Probolinggo, Mojokerto, Pasuruan, Madiun, Bondowoso, Pamekasan, kota Blitar, kota Pasuruan, kota Batu, kota Probolinggo, kota Mojokerto, kota Madiun, Magetan, Ngawi,
Lamongan, sidoarjo, kota Kediri, kota Malang, Malang, Gresik, Jember, Ponorogo dan Banyuwangi.
Kelompok 2 : Tuban dan Bojonegoro. Kelompok 3 : Surabaya.
6. Ward’s Method
Berdasarkan nilai pseudo F terbesar menghasilkan nilai optimal adalah dengan kelompok sebanyak 4. Dimana masing-masing kelompok terdiri dari 7, 2, 1 dan 28 kabupaten/kota yang memiliki tingkat kesamaan yang tinggi dalam tiap kelompok dan perbedaan yang tinggi antar kelompok. Kabupaten/kota yang tergolong dalam tiap kelompok, diantaranya sebagai berikut.
Kelompok 1 : Pacitan, sampang, Sumenep, Malang, Gresik, Jember, dan banyuwangi.
Kelompok 2 : Bojonegoro dan Tuban. Kelompok 3 : Kota Surabaya
Kelompok 4 : Ponorogo, sidoarjo, Tulungagung, kota Malang, kota Blitar, kota Pasuruan, Lumajang, Trenggalek, Kediri, Blitar, Jombang, Situbondo, Nganjuk, Bangkalan, Probolinggo, Mojokerto, Pasuruan, Madiun, Bondowoso, Pamekasan, kota Batu, kota Probolinggo, kota Mojokerto, kota Madiun, Magetan, Ngawi, Lamongan, dan kota Kediri.
D. Nonhierarchical Clustering
Prosedur pengelompokan nonhierarki tidakdilakukan secara bertahap, dimana salah satu metode nonhierarki adalah k-means.
1. Membagi item-item (objek) kedalam k cluster. Berdasarkan nilai Pseudo F didapat kelompok optimal yaitu 3 yang dijadikan sebagai pusat (centroid). Centroid ditentukan sebarang objek. Nilai centroid dari tiap cluster adalah :
𝑐1= (0.2117; −3.3067) 𝑐2= −0.2875; 2.6335 𝑐3= (5.7036; 0.8529) dengan,
𝑐1 (centroid cluster 1) adalah nilai kedua variabel dari objek Kab Tuban.
𝑐2 (centroid cluster 2) adalah nilai kedua variabel dari objek Kab Ponorogo.
𝑐3 (centroid cluster 3) adalah nilai kedua variabel dari objek Kota Surabaya.
Dari proses ini diperoleh anggota tiap cluster sebagai berikut :
Kelompok 1 : Pacitan, Sampang, Sumenep, Banyuwangi, Jember, Bojonegoro, Tuban, Gresik, dan Malang. Kelompok 2 : Ponorogo, Trenggalek, Tulungagung,
Blitar, Kediri, Lumajang, Bondowoso, Situbondo, Probolinggo, Pasuruan, sidoarjo, Mojokerto, Jombang, Nganjuk, Madiun, Magetan, Ngawi, Lamongan, Bangkalan, Pamekasan, kota Kediri, kota Blitar, kota Malang, kota Probolinggo, kota Pasuruan, kota Mojokerto, kota Madiun, dan kota Batu.
Kelompok 3 : Surabaya.
2. Selanjutnya menghitung kembali centroid baru yang merupakan rataan kedua variabel pada tiap cluster. Nilai centroid baru dari tiap cluster adalah :
𝑐1∗= 0.0825; −1.3728 𝑐2∗= (−0.2297; 0.3822)
𝑐3∗= (5.7036; 0.8529)
Dari proses ini diperoleh anggota tiap cluster sebagai berikut :
Kelompok 1 : Pacitan, Banyuwangi, Bojonegoro, Tuban, Jember, Gresik, dan Malang.
Kelompok 2 : Ponorogo, Trenggalek, Tulungagung, Blitar, Kediri, Lumajang, Bondowoso, Situbondo, Probolinggo, Pasuruan, sidoarjo, Mojokerto, Jombang, Nganjuk, Madiun, Magetan, Ngawi, Lamongan, Bangkalan, Sampang, Sumenep, Pamekasan, kota Kediri, kota Blitar, kota Malang, kota Probolinggo, kota Pasuruan, kota Mojokerto, kota Madiun, dan kota Batu.
Kelompok 3 : Surabaya.
Karena terdapat dua objek pada cluster 1 yang berpindah ke cluster 2 maka harus mencari centroid baru.
3. Menghitung kembali centroid baru yang merupakan rataan kedua variabel pada tiap cluster yang baru terbentuk. Nilai centroid baru dari tiap cluster adalah :
𝑐1∗∗= 0.1985; −1.628 𝑐2∗∗= (−0.236; 0.3248) 𝑐3∗∗= (5.7036; 0.8529)
dari nilai centroid rataan masing-masing kelompok yang baru didapatkan anggota sebagai berikut :
Kelompok 1 : Banyuwangi, Jember, Bojonegoro, Tuban, Gresik, dan Malang.
Kelompok 2 : Ponorogo, Trenggalek, Tulungagung, Blitar, Pacitan, Kediri, Lumajang, Bondowoso, Situbondo, Probolinggo, Pasuruan, sidoarjo, Mojokerto, Jombang, Nganjuk, Madiun, Magetan, Ngawi, Lamongan, Bangkalan, Sampang, Sumenep, Pamekasan, kota Kediri, kota Blitar, kota Malang, kota Probolinggo, kota Pasuruan, kota Mojokerto, kota Madiun, dan kota Batu.
Kelompok 3 : Surabaya.
Dari hasil pengelompokan yang baru ternyata masih ada satu anggota atau objek yang berpindah kelompok, sehingga harus dilakukan pembentukan centroid baru. 4. Menghitung kembali centroid baru yang merupakan
rataan kedua variabel pada tiap cluster yang baru terbentuk. Nilai centroid baru dari tiap cluster adalah :
𝑐1∗∗∗= 0.2974; −1.7975 𝑐2∗∗∗= (−0.2411; 0.2946) 𝑐3∗∗∗= (5.7036; 0.8529)
Dari nilai centroid rataan ketiga seperti pada Lampiran G masing-masing kelompok yang baru didapatkan anggota sebagai berikut :
Kelompok 1 : Banyuwangi, Jember, Bojonegoro, Tuban, Gresik, dan Malang.
Kelompok 2 : Ponorogo, Trenggalek, Tulungagung, Blitar, Pacitan, Kediri, Lumajang, Bondowoso, Situbondo, Probolinggo, Pasuruan, sidoarjo, Mojokerto, Jombang, Nganjuk, Madiun, Magetan, Ngawi, Lamongan, Bangkalan, Sampang, Sumenep, Pamekasan, kota Kediri, kota Blitar, kota Malang, kota Probolinggo, kota Pasuruan, kota Mojokerto, kota Madiun, dan kota Batu.
Kelompok 3 : Surabaya. E. Pemilihan Metode Terbaik
Kebaikan hasil pengelompokan dapat dilihat dari penyebaran internal dalam kelompok atau disebut dengan
internal cluster dispersion rate (icdrate). Semakin kecil nilai icdratenya.
Berdasarkan Tabel 5 dapat diketahui banyak kelompok yang optimum untuk setiap metode memberikan keragaman yang berbada dengan metode lainnya. Adanya keragaman antar kelompok merupakan kriteria yang dapat menentukan tingkat kebaikan suatu metode pengelompokan.
Tabel 5 Pemilihan Metode Terbaik
Metode BKO Icdrate
Single Linkage 4 0,18693
Complete Linkage 3 0.22449
Average Linkage 3 0.27404
Ward 4 0,14760
K-Means 3 0.22344
Jika diperhatikan, maka metode Ward yang dapat memberikan hasil pengelompokan terbaik diantara keempat metode lainnya. Hal ini ditunjukkan dengan nilai icdratenya yang terkecil yaitu sebesar 0.1476.
Secara visual, dapat diketahui bahwa peta yang dihasilkan dari metode ward seperti pada Gambar 3.
Gambar 3. Pengelompokan Kabupaten/Kota Jawa Tmur dengan Ward
F. Evaluasi Hasil Pengelompokan
Evaluasi dilakukan dengan MANOVA, dimana harus memenuhi variabel dependen berdistribusi multiaviat normal dan matrik varian-kovarian bersifat homogen. Dalam tugas akhir ini, pemeriksaan berdistribusi normal multivariat pada variabel dependen dapat diketahui dengan uji asumsi variabel dependen berdistribusi multivariate normal.
Hipotesis :
𝐻0 : Residual berdistribusi normal multivariat 𝐻1 : Residual tidak berdistribusi normal multivariat Statistik Uji :
𝑑𝑖2 = ( 𝜀 𝑖− 𝜀 )𝑇Σ−1( 𝜀 𝑖 − 𝜀 ) ; 𝑖 = 1,2, . . ,38
Diperoleh kondisi 𝑑𝑖2≤ 𝜒𝑡𝑎𝑏𝑒𝑙2 = 1.386 terhadap 32 sampel atau 84.21% dari sampel keseluruhan, atau dengan kata lain 𝑑𝑖2≤ 𝜒𝑡𝑎𝑏𝑒𝑙2 = 𝜒𝑞,1
2 2
terhadap lebih dari 50% sampel, maka 𝐻0 diterima sehingga residual data dikatakan berdistribusi normal multivariat.
Selain berdistribusi multivariate normal, homogenitas matrik varians-kovarians juga harus dipenuhi dengan Box’M.
Hipotesis : 𝐻0∶ 1= 2
𝐻1 ∶ minimal ada satu 𝑖 dan 𝑗 yang berbeda, dengan 𝑖 ≠ 𝑗 Statistik Uji : 𝑋ℎ𝑖𝑡𝑢𝑛𝑔2 = −2(1 − 𝑐 1) 12 𝑣𝑗ln 𝑆𝑖 − 2 𝑗 =1 1 2ln 𝑆𝑝𝑜𝑜𝑙 𝑣𝑗 2 𝑗 =1
= 3,319 𝜒𝑡𝑎𝑏𝑒𝑙2 = 𝜒0.05,12 = 3,84146
karena 𝜒ℎ𝑖𝑡𝑢𝑛𝑔2= 3,319 < 𝜒𝑡𝑎𝑏𝑒𝑙2 = 3,84146 atau seperti yang terlihat pada Tabel 6, maka 𝐻0 diterima yang berarti matriks varian-kovarian residual yang dikelompokkan adalah homogen dapat disimpulkan residual identik dan variabel dependen mempunyai matriks varian-kovarian sama pada kelompok variabel bebas kabupaten.
Tabel 6 Uji Homogenitas
Keterangan Nilai
Box’s M 3,319
Uji F 0,966
P-value 0,408
Kedua asumsi sebagai prasyarat dalam melakukan uji perbedaan kelompok dengan MANOVA telah terpenuhi. Dalam pengujian perbedaan kelompok dengan MANOVA Hipotesis :
𝐻0∶ 𝜇1= 𝜇2= 0
𝐻1∶ minimal ada satu 𝝁𝟐 dan 𝝁𝒋≠ 𝟎, dengan 𝒊 ≠ 𝒋 Statistik Uji :
Λ∗= 𝑩 + 𝑾 𝑾 = 0,016612704
dengan i=2 dan j=4 pada distribusi sampling multivariate normal berlaku 𝐹ℎ𝑖𝑡𝑢𝑛𝑔 = 𝑛𝑗 − 𝑗 − 1 𝑗 − 1 1 − Λ∗ Λ∗ = 74,343908 𝐹𝑡𝑎𝑏𝑒𝑙 = 𝐹0,05;6,66 = 2,239479 Karena 𝐹ℎ𝑖𝑡𝑢𝑛𝑔 > 𝐹𝑡𝑎𝑏𝑒𝑙 yaitu 74,343908 > 2,239479 maka 𝑯𝟎 ditolak, sehingga dapat disimpulkan bahwa terdapat perbedaan rata-rata antar kelompok kabupaten/kota di Jawa Timur. Oleh karena itu, adanya pengelompokan ini perlu dilakukan karena permasalahan yang mempengaruhi pertumbuhan ekonomi di setiap kabupaten/kota di Jawa Timur.
4.7 Karakteristik Tiap Kelompok
Penggujian hasil MANOVA menunjukkan bahwa terdapat rata-rata pada 4 kelompok yang terbentuk oleh metode Ward, maka perlu diketahui karakteristik dari setiap kelompoknya berdasarkan variabel-variabel yang berpengaruh pada bertumbuhan Ekonomi Jawa Timur.
Dari dekskripsi pada Tabel 4.10 dapat diketahui variabel-variabel yang berpengaruh dalam 4 kelompok, secara umum diketahui bahwa sektor-sektor yang ada di Jawa Timur memiliki karakteristik yang berbeda tiap kelompoknya. Perbedaan tampak pada kelompok 1 yang memiliki rata-rata tinggi pada sektor pertanian (SP), selain itu kelompok 1 juga memiliki nilai yang tinggi pada sektor industri (SIP) pengolahan dan sektor perdagangan,hotel, dan restoran (SPHR) disbanding kelompok 2 dan 4, walaupun demikian tetap tidak bisa melebihi prosentase kelompok 3 yang memang mendominasi beberapa perekonomian Jawa Timur. Berdasarkan karakteristik tersebut, kelompok 1 lebih cenderung dinamakan daerah pertanian dan industri.
Pada kelompok 2 dari hasil deskripsi statistik ternyata memiliki nilai sektor pertambangan dan penggalian (SPP) yang sangat tinggi dibanding dengan kelompok lain, tetapi kelompok 2 memiliki prosentase yang cukup rendah pada
sektor industri pengolahan (SIP) dan sektor pengangkutan dan komunikasi (SPK), maka dari karakteristik tersebut menunjukkan bahwa daerah pada kelompok 2 memiliki pertumbuhan pada pertambangan migas, non migas dan penggalian, walaupun pertambangan dan penggalian memiliki peranan penting dalam penggerakkan ekonomi terutama sektor industri pengolahan tetapi industri didaerah tersebut kurang berkembang. Hal ini dikarenakan sektor pengangkutan dan komunikasi yang tumbuh rendah sehingga sangat berpengaruh pada pergerakan aktivitas semua sektor ekonomi didaerah tersebut dan dapat dikatakan sebagai daerah pertambagan dan penggalian.
Tabel 4.10 Deskripsi Statistik untuk setiap kelompok
Variabel Cluster 1 2 3 4 SP rata-rata 4.97063 3.828449 0.142667 2.050216 S.Deviasi 3.147675 0.34516 0 1.523728 SPP rata-rata 5.792485 17.2608 0.103748 0.886687 S.Deviasi 3.010849 1.340154 0 0.952652 SIP rata-rata 2.301202 1.395988 21.85104 2.116021 S.Deviasi 3.602522 0.949823 0 4.62972 SLGA rata-rata 1.961969 3.391191 42.60687 1.317039 S.Deviasi 2.60128 3.154674 0 1.611625 SK rata-rata 1.521751 1.543053 55.84436 1.086331 S.Deviasi 0.793868 1.619359 0 0.779216 SPHK rata-rata 2.148469 1.359099 35.43992 1.671521 S.Deviasi 1.432826 0.096716 0 1.601846 SPK rata-rata 1.41937 1.010319 49.60521 1.372807 S.Deviasi 1.007451 0.270235 0 2.550343 SKPJ rata-rata 2.593262 2.450905 32.45125 1.589075 S.Deviasi 1.480446 0.071238 0 1.511202 SJ rata-rata 2.664408 1.795416 26.76418 1.82122 S.Deviasi 2.189018 0.697288 0 1.302155
Prosentase sektor pertanian (SP) dan sektor pertambangan dan penggalian (SPP) pada kelompok 3 sangat rendah dibanding 3 kelompk lainnya, tetapi pada 7 sektor lainnya sangat mendominasi dibanding kelompok lain, bahkan ada yang mencapai rata-rata 55,84% pada sektor konstruksi (SK), selain tu sektor pengangkutan dan komunikasi (SPK) dan sektor listrik, gas, dan air bersih (SLGA) juga sangat tinggi disusul dengan sektor pendagangan, hotel, dan restoran (SPHR), sektor keuangan, persewaan dam jasa (SKPJ), sektor jasa-jasa (SJ) dan trakhir sektor industri dan pengolahan (SIP) dengan prosentase yang masih cukup tinggi yaitu 21,85%. Dari hasil deskripsi diatas dapat dikatakan bahwa kelompok 3 memiliki pertumbuhan yang sangat pesat pada sektor konstruksi, semakin tingginya pertumbuhan ekonomi dan bertambahnya jumlah penduduk turut berpengaruh terhadap kebutuhan properti baik sebagai konsumsi atau investasi seperti pembangunan apartemen, ruko dan hypermarket sehingga mempercepat pertumbuhan sektor konstruksi. Selain itu pertumbuhan pada pengangkutan dan komunikasi sangatlah mempengaruhi perekonomian secara umum, sehingga dapat mendorong pertumbuhan sektor lainnya, tak terkecuali pada industri, tetapi hal ini mengakibatkan semakin berkurangnya lahan untuk pertanian sehingga mengakibatkan penurunan pada pertumbuhan ekonomi dibidang pertanian.
Berdasar-kan karakteristik tersebut kelompok 3 dapat dinamaBerdasar-kan daerah pusat perekonomian jawa timur.
Terlihat pada prosentase hasil deskripsi statistik, bahwa kelompok 4 memang kurang mendominasi pada setiap sektor yang ada, bahkan cenderung rendah dibeberapa sektor seperti sektor listrik, gas, dan air bersih (SLGA), sektor konstruksi (SK) dan sektor keuangan, persewaan, dan jasa (SKPJ) yang memiliki prosentase terendah dibanding 3 kelompok lain. Walaupun demikian, kelompok 4 memiliki nilai rata-rata yang tidak jauh beda dengan kelompok 1, seperti sektor industri dan pengolahan (SIP), sektor perdagangan, hotel, dan restoran (SPHR) dan sektor pengangkutan dan komunikasi (SPK). sehingga masyarakatnya pun lebih dominan pada penghasilan ekonomi dari sektor tersebut. Dari hasil terskripsi diatas kelompok 4 sesuai dengan karakteristiknya dapat dinamakan sebagai daerah sedang pada perdagangan, industri dan jasa.
IV. KESIMPULAN
Hasil analisis dan pmbahasan yang telah dilakukan dalam tugas akhir ini dapat disimpulkan sebagai berikut: 1. Hasil analisis cluster dari 38 kabupaten/kota berdasarkan
PDRB ADHK dapat dikelompokkan menjadi 4 kelompok. 2. Hasil pengelompokan digolongkan menjadi beberapa
daerah berikut:
a. Kelompok 1 daerah pertanian dan industri : Pacitan, Sampang, sumenep, Malang, Gresik, Jember, dan Banyuwangi.
b. Kelompok 2 pertambangan dan penggalian: Bojonegoro dan Tuban.
c. Kelompok 3 daerah pusat perekonomian : Kota Surabaya
d. Kelompok 4 daerah sedang pada perdagangan, industri dan jasa : Ponorogo, sidoarjo, Tulungagung, kota Malang, kota Blitar, kota Pasuruan, Lumajang, Trenggalek, Kediri, Blitar, Jombang, Situbondo, Nganjuk, Bangkalan, Probolinggo, Mojokerto, Pasuruan, Madiun, Bondowoso, Pamekasan, kota Batu, kota Probolinggo, kota Mojokerto, kota Madiun, Magetan, Ngawi, Lamongan, dan kota Kediri.
3. Karakteristik dari setiap cluster yaitu :
a. Kelompok 1 : daerah dengan sektor pertanian (SP) tinggi, tetapi memiliki sektor pertambangan dan penggalian (SPP) dan sektor perdagangan, hotel, dan restoran (SPHR) rendah.
b. Kelompok 2 : daerah dengan sektor pertambangan dan penggalian (SPP) tinggi, sektor pertanian (SP) sedang dan tetapi memiliki pendapatan rendah pada sektor industri pengolahan (SIP), sektor perdagangan, hotel, dan restoran (SPHR), sektor pengangkutan dan komunikasi (SPK) dan sektor jasa-jasa (SJ).
c. Kelompok 3 : daerah rendah pada sektor perdagangan (SP) dan sektor pertambangan dan penggalian (SPP), tetapi sangat tinggi pada 7 sektor lainnya yaitu sektor sektor konstruksi (SK), industri pengolahan (SIP), sektor listrik, gas, dan air bersih (SLGA), sektor perdagangan, hotel, dan restoran (SPHR), sektor pengangkutan dan komunikasi (SPK), sektor keuangan, persewaan dan jasa perusahaan (SKPJ) dan sektor jasa-jasa (SJ).
d. Kelompok 4 : daerah rendah pada sektor listrik, gas, dan air bersih (SLGA), sektor konstruksi (SK) dan sektor keuangan, persewaan dan jasa perusahaan (SKPJ), dan sedang pada sektor industri pengolahan
(SIP), sektor perdagangan, hotel, dan restoran (SPHR) dan sektor pengangkutan dan komunikasi (SPK).
V. DAFTAR PUSTAKA
[1] Anonim. 2013. “Pertumbuhan Ekonomi”
http://id.wiki-pedia.org/wiki. Diakses tanggal 22 Agustus 2013.
[2] Adhi, Robert. 2013. “Pertumbuhan Ekonomi Jatim Melampaui
Nasional”http://bisniskeuangan.kompas.com. Diakses tanggal 22 Agustus 2013
[3] Lazulfa, Indana. 2013. “Analisis Cluster Kabupaten/Kota di Jawa Timur Berdasarkan Tingkat Pencemaran Udara”. FMIPA ITS.
[4] Rochmi, Arinda. 2011. “Pengelompokan kabupaten/kota di Jawa Timur Berdasarkan Kesamaan Nilai Faktor-Faktor yang Mempengaruhi Tingkat Pengangguran Terbuka dengan Metode Hirarkhi dan Non Hirarkhi”. FMIPA ITS.
[5] Turrohmah, Hamimah. 2012. “Analisis Faktor Terhadap Pertumbuhan Ekonomi Jawa Timur”. FMIPA ITS
[6] Santoso, Singgih. 2010. “Statistik Multivariat, Konsep dan Aplikasi dengan SPSS”. Jakarta: PT Elex Media Komputindo.
[7] Kuncoro, M . 2003. “Metode Riset Untuk Bisnis dan Ekonomi”. Jakarta: Erlangga.