ANALISIS ALGORITMA DBSCAN DALAM MENENTUKAN PARAMETER EPSILON PADA PENGELOMPOKAN
DATA NUMERIK
TESIS
HERWIN E.T SIMANJUNTAK 177038018
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN
2019
ANALISIS ALGORITMA DBSCAN DALAM MENENTUKAN PARAMETER EPSILON PADA PENGELOMPOKAN
DATA NUMERIK
TESIS
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Magister Teknik Informatika
HERWIN E.T SIMANJUNTAK 177038018
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN
2019
PERNYATAAN
ANALISIS ALGORITMA DBSCAN DALAM MENENTUKAN PARAMETER EPSILON PADA PENGELOMPOKAN
DATA NUMERIK
TESIS
Saya mengakui bahwa tesis ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Herwin E.T Simanjuntak NIM. 177038018Medan
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai sivitas akademika Universitas Sumatera Utara, saya yang bertanda tangan di bawah ini:
Nama : Herwin E.T Simanjuntak
NIM : 177038018
Program Studi : S-2 Teknik Informatika Jenis Karya Ilmiah : Tesis
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive Royalti Free Right) atas tesis saya yang berjudul:
ANALISIS ALGORITMA DBSCAN DALAM MENENTUKAN PARAMETER EPSILON PADA PENGELOMPOKAN
DATA NUMERIK
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non- Eksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media, memformat, mengelola dalam bentuk database, merawat dan mempublikasikan tesis saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis dan sebagai pemegang dan/atau sebagai pemilik hak cipta.
Demikian pernyataan ini dibuat dengan sebenarnya.
Medan, 24 Juli 2019
Herwin E.T Simanjuntak NIM. 177038018
Telah diuji pada Tanggal: 23 Juli 2019
PANITA PENGUJI TESIS
Ketua : Prof. Dr. Muhammad Zarlis Anggota : 1. Dr. Sawaluddin, M.IT
2. Prof. Dr. Tulus
3. Dr. Zakarias Situmorang, M.IT
RIWAYAT HIDUP
DATA PRIBADI
Nama Lengkap : Herwin E.T Simanjuntak, S.Kom Tempat dan Tanggal Lahir : Parbaju Julu, 18 Juli 1984
Alamat Rumah : Parbaju Julu, Kec. Tarutung, Kab. Tapanuli
Utara
HP : 081310410214
Instansi Tempat Bekerja : Kementerian Agama RI
Institut Agama Kristen Negeri (IAKN) Tarutung Alamat Kantor : Jl. Raya Tarutung – Siborongborong KM. 11
Kec. Sipoholon. Kab. Tapanuli Utara
DATA PENDIDIKAN
SD : Negeri 175742 Tamat Tahun 1996
SLTP : Negeri 2 Tarutung Tamat Tahun 1999
SLTA : Negeri 1 Sipoholon Tamat Tahun 2002 S1 : Teknik Informatika STMIK SMRaja XII Tamat Tahun 2008 S2 : Teknik Informatika USU Tamat Tahun 2019
UCAPAN TERIMAKASIH
Sudah selayaknya penulis mengucapkan dengan kerendahan hati puji dan syukur kehadapan Tuhan Yang Maha Esa, yang sudah melimpahkan kasih setia dan karunia-Nya, sehingga penulis dapat menyelesaikan penulisan tesis ini dengan baik.
Dan tidak lupa juga dalam ingatan Penulis, untuk mengucapkan terima kasih yang tak terhingga kepada pihak yang telah memberi dukungan diantaranya:
1. Bapak Prof. Dr. Runtung Sitepu, S.H., M.Hum, selaku Rektor Universitas Sumatera Utara atas kesempatan yang telah diberikan kepada penulis untuk dapat mengikuti dan menyelesaikan pendidikan Program Magister Teknik Informatika Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
2. Bapak Prof. Dr. Opim Salim Sitompul selaku Dekan Fakultas Ilmu Komputer dan Teknologi Informasi (Fasilkom-TI) Universitas Sumatera Utara, yang sudah banyak memberikan bimbingan dan arahan.
3. Bapak Prof. Dr. Muhammad Zarlis selaku Ketua Program Studi Magister Teknik Informatika dan Bapak Syahril Efendi, S.Si., M.IT selaku Sekretaris Program Studi Teknik Informatika. Beserta seluruh Staf Pengajar Program Studi Magister Teknik Informatika Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
4. Bapak Prof. Dr. Muhammad Zarlis selaku Pembimbing Utama, demikian juga kepada Bapak Dr. Sawaluddin, M.IT. selaku Pembimbing Kedua yang dengan penuh kesabaran menuntun dan membimbing penulis hingga tesis ini dapat selesai dengan baik.
5. Bapak Prof. Dr. Tulus dan Bapak Dr. Zakarias Situmorang, M.Kom, sebagai Dosen Pembanding yang telah memberikan saran dan masukan serta arahan yang baik pada tesis ini.
6. Istri saya tercinta Mega Trisnawati Hutabarat, A.Md, dimana sudah banyak memberikan doa dan dukungan kepada penulis selama proses perkuliahan di Universitas Sumatera Utara.
7. Ayahanda tercinta Leonardo Simanjuntak, Ibunda tercinta Tiamija Hutabarat, serta abang dan adikku tersayang serta seluruh keluarga besar yang selalu memberi doa dan dukungan kepada penulis.
8. Seluruh staf pegawai Program Studi Magister S2 Teknik Informatika Fakultas Ilmu Komputer dan Teknik Informatika, serta teman-teman seperjuangan mahasiswa/i Kom-A 2017.
9. Dan seluruh pihak yang tidak dapat disebutkan satu persatu dalam tesis ini, sekali lagi terima kasih atas segala bantuan dan doa yang telah diberikan.
Penulis menyadari bahwa penelitian pada tesis ini masih jauh dari kata sempurna,dikarenakan oleh keterbatasan, kemampuan dan pengetahuan penulis. Besar harapan penulis, semoga penelitian ini cukup bermanfaat bagi penulis khususnya dan pembaca pada umumnya. Sekali lagi penulis mengucapkan terima kasih, semoga Tuhan Yang Maha Kuasa membalas semua kebaikan yang telah diberikan. Amin.
Medan, 24 Juli 2019 Penulis,
Herwin E.T Simanjuntak, S.Kom NIM: 177038018
ABSTRAK
DBSCAN adalah algoritma dasar untuk teknik clustering berbasis kepadatan.
Penelitian ini memberikan survei algoritma pengelompokan berbasis kepadatan dengan algoritma ditingkatkan yang diusulkan yang secara otomatis memilih parameter input bersama dengan implementasinya dan perbandingan dengan algoritma DBSCAN yang ada. Pada clustering pengukuran kemiripan antar objek dilakukan dengan mengukur jarak untuk setiap pasang objek. Pengukuran ini dapat dilakukan dengan metode Euclidean Distance, Canberra Distance, Manhattan Distance dan MinkowskiDistance. Algoritma pengelompokan membutuhkan parameter input yang sulit untuk ditentukan tetapi memiliki pengaruh yang signifikan terhadap hasil, menemukan ukuran dalam bentuk cluster dan efisien bahkan untuk set data besar.
DBSCAN akan mendeteksi cluster serta menentukan bagaimana menentukan parameter epsilon secara otomatis dengan cara yang akurat untuk menentukan parameter input dan menemukan cluster dengan kepadatan yang berbeda-beda terhadap dataset Iris dengan membandingkan pengukuran terhadap metode Euclidean Distance dan Canberra Distance. Pada penelitian ini dilakukan pengujian terhadap dataset Iris dengan hasil percobaan yang dilakukan terhadap metode Euclidean Distance dan Canberra Distance yang terlihat dengan pembentukan cluster yang dihasilkan terlihat pada Canberra Distance sebanyak 10 cluster dengan jumlah cluster 150. KinerjaCanberra Distance lebih baik jika dibandingkan dengan Euclidean Distance yang dihasilkan, terlihat pada cluster 6 yang dihasilkan Canberra Distance yang telah melakukan penstabilan clustering pada pembentukan clustering.
Kata Kunci: Clustering, DBSCAN, Euclidean Distance, Canberra Distance, Iris.
ABSTRACT
DBSCAN is the basic algorithm for density-based clustering techniques. This study provides a survey of density-based grouping algorithms with a proposed improved algorithm that automatically selects input parameters along with their implementation and comparison with existing DBSCAN algorithms. In clustering, the measurement of similarity between objects is done by measuring the distance for each pair of objects.
This measurement can be done by Euclidean Distance, Canberra Distance, Manhattan Distance, and Minkowski Distance methods. Grouping algorithms require input parameters that are difficult to determine but have a significant effect on results, find sizes in cluster form and are efficient even for large data sets. DBSCAN will detect clusters and determine how to determine epsilon parameters automatically in an accurate way to determine input parameters and find clusters with different densities on the Iris dataset by comparing measurements to the Euclidean Distance and Canberra Distance methods. In this study, the Iris dataset was tested with the results of experiments conducted on the Euclidean Distance and Canberra Distance methods as seen in the formation of clusters seen in the Canberra Distance in 10 clusters with 150 clusters. Canberra Distance performance is better than Euclidean Distance generated, seen in cluster 6 produced by Canberra Distance which has stabilized clustering in the formation of clustering.
Keywords: Clustering, DBSCAN, Euclidean Distance, Canberra Distance, and Iris.
i DAFTAR ISI
HALAMAN JUDUL PERSETUJUAN PERNYATAAN
PERSETUJUAN PUBLIKASI PANITIA PENGUJI
RIWAYAT HIDUP
UCAPAN TERIMA KASIH ABSTRAK
ABSTRACT
DAFTAR ISI ... i
DAFTAR GAMBAR ... iii
DAFTAR TABEL ... iv
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang... 1
1.2 Rumusan Masalah ... 3
1.3 Batasan Masalah ... 4
1.4 Tujuan Penelitian... 4
1.5 Manfaat Penelitian ... 4
BAB II LANDASAN TEORI ... 5
2.1 Data Mining ... 5
2.2 Analisis Algoritma ... 6
2.3 Clustering ... 9
2.4 Subspace Clustering ... 11
2.5 DBSCAN ... 11
2.6 Metode Euclidean Distance ... 15
2.7 Metode Canberra Distance ... 16
ii
BAB III METODE PENELITIAN ... 18
3.1 Pendahuluan ... 18
3.2 Pelaksanaan Penelitian ... 19
3.3 Desain Sitem ... 22
3.4 Rancangan Penelitian... 22
BAB IV HASIL DAN PEMBAHASAN ... 26
4.1 Hasil Implementasi ... 26
4.1.1 Pengujian pada Iris dataset ... 26
4.1.2 Hasil cluster Euclidean Distance ... 29
4.1.3 Hasil cluster Canberra Distance ... 35
4.2 Pembahasan ... 41
BAB V KESIMPULAN DAN SARAN ... 44
5.1 Kesimpulan ... 44
5.2 Saran ... 44
DAFTAR PUSTAKA ... 46
iii
DAFTAR GAMBAR
Nomor Judul Halaman
Gambar 2.1 Core dan border ... 12
Gambar 2.2 Konsep Kepadatan ... 13
Gambar 3.1 Density Based Cluster ... 19
Gambar 3.2 Rancangan Penelitian ... 24
Gambar 4.1 Penentuan Atribut DBSCAN ... 27
Gambar 4.2 Rancangan Model DBSCAN ... 27
Gambar 4.3 Grafik Hasil Pengujian pada iris dataset ... 29
Gambar 4.4 Plot Pengelompokan Euclidean Distance ... 34
Gambar 4.5 Plot Pengelompokan Canberra Distance ... 40
Gambar 4.6 Penentuan Metode Euclidean Distance ... 42
Gambar 4.7 Penentuan Metode Euclidean Distance ... 43
iv
DAFTAR TABEL
Nomor Judul Halaman
Tabel 3.1 Iris Dataset ... 20
Tabel 4.1 Hasil pengujian pada Iris dataset ... 28
Tabel 4.2 Hasil Cluster Euclidean Distance ... 29
Tabel 4.3 Hasil Cluster Canberra Distance ... 35
BAB 1 PENDAHULUAN
1.1. LatarBelakang
Clustering adalah langkah awal dan mendasar dalam analisis data. Ini adalah klasifikasi pola yang tidak diawasi kedalam kelompok atau kita dapat mengatakan kelompok. Secara intuitif, pola dalam kluster yang valid lebih mirip satu sama lain dan berbeda jika dibandingkan dengan pola yang dimiliki kluster lain. Clustering berguna dalam beberapa bidang seperti analisis pola, situasi pembelajaran mesin juga klasifikasi pola dan banyak bidang lainnya. Teknik clustering telah digunakan pada banyak bidang, seperti kecerdasan buatan, biologi, data mining, machine learning, marketing, pengenalan pola dan lain-lain (Yadav, J dan Sharma, M.2013)
Clustering merupakan sebuah proses untuk mengelompokan data ke dalam beberapa cluster atau kelompok sehingga data dalam satu cluster memiliki tingkat kemiripan yang maksimum dan data antar cluster memiliki kemiripan yang minimum.
Ada dua pendekatan utama yang digunakan dalam mengembangkan metode clustering yaitu clustering dengan pendekatan partisi dan clustering dengan pendekatan hirarki.
Clustering dengan pendekatan partisi atau sering disebut dengan partition-based clustering adalah pengelompokkan data dengan memilah-milah data yang dianalisis kedalam cluster-cluster yang ada. (Poteras, et al. 2014).
Clustering merupakan bagian dari metode pembelajaran tak terawasi (unsuperviced learning) karena tidak memerlukan pendefinisian cluster terlebih dahulu (Nisha dan Kaur, P.J. 2015). Pada clustering pengukuran kemiripan antar objek dilakukan dengan mengukur jarak untuk setiap pasang objek. Pengukuran ini dapat dilakukan dengan metode Euclidean Distance, Manhattan Distance dan MinkowskiDistance.
2
2
Algoritma DBSCAN memiliki dua parameter penting, yakni epsilon dan minPts yang bernilai random. Menurut Eko P (2012), Density-Based Spatial Clustering of Aplications with noise (DBSCAN) merupakan algoritma pengelompokan yang didasarkan pada kepadatan (density) data. Konsep kepadatan yang dimaksud dalam DBSCAN adalah jumlah data yang berada dalam radius Epsilon (ɛ) dari setiap data. Jika jumlah data tersebut dalam radius ɛ lebih dari atau sama dengan MinPts (jumlah minimal data dalam radius ɛ), data tersebut masuk dalam kategori kepadatan yang diinginkan, jumlah data radius tersebut termasuk data itu sendiri. Konsep kepadatan tersebut memunculkan tiga macam status dari setiap data, diantaranya inti (core), batas (border), dan noise (noise).
Hampir semua algoritma pengelompokan terkenal membutuhkan parameter input yang sulit untuk ditentukan tetapi memiliki pengaruh yang signifikan terhadap hasil pengelompokan. Selain itu, untuk banyak data setnyata bahkan tidak ada pengaturan parameter global dan hasil algoritma pengelompokan menggambarkan struktur pengelompokan intrinsic secara akurat. DBSCAN adalah algoritma dasar untuk teknik clustering berbasis kepadatan. Penelitian ini memberikan survey algoritma pengelompokan berbasis kepadatan dengan algoritma ditingkatkan dan diusulkan yang secara otomatis memilih parameter input bersama dengan implementasinya dan perbandingan dengan algoritma DBSCAN yang ada. Hasil percobaan menunjukkan bahwa algoritma yang diusulkan dapat mendeteksi kelompok kepadatan bervariasi dengan bentuk dan ukuran yang berbeda dari sejumlah besar data yang mengandung noise dan outlier, hanya membutuhkan satu parameter input dan memberikan output yang lebih baik dari pada algoritma DBSCAN. (Gaonkar, 2012)
DBSCAN memiliki cara kerja clustering yang hampir mirip dengan DENCLUE.
Secara signifikan, DBSCAN bekerja dengan efisien dalam membentuk arbitrary-shaped cluster. Pengelompokan dilakukan terhadap titik dengan ketetanggaannya yang berada di dalam jarak (ɛ) tertentu yang harus memenuhi jumlah titik minimum (minPts).
Pembentukan ketetanggaan dapat ditentukan melalui pemilihan fungsi jarak antara dua buah titik. DBSCAN menggunakan konsep titik pusat (core point), titik batas (border point), dan noise. Titik yang memiliki sejumlah titik tetangga dan memenuhi jumlah titik minimum, serta berada dalam jarak tertentu disebut sebagai titik pusat, sedangkan titik batas memiliki jumlah titik tetangga namun tidak memenuhi jumlah titik minimum. Titik batas tersebut biasanya merupakan titik di dalam ketetanggaan dari titik
3
3
pusat. Kriteria suatu titik dikatakan sebagai noise yaitu pada saat titik tersebut tidak termasuk titik pusat maupun titik batas, selain itu titik tersebut tidak memenuhi konsep directly density-reachable dari suatu titik pusat (Ester et al.1996).
Mengusulkan dalam peningkatan pengelompokkan DBSCAN berdasarkan pada algoritma genetika dan kerangka pemrograman komputasi parallel MapReduce karena efek clustering danefisiensi rendah dari DBSCAN yang disebabkan oleh parameter pemecahan. Algoritma yang diusulkan memiliki akurasi pengelompokkan yang lebih tinggi dan efisien di sbanding perbandingan garis dasar. Perkembangan akan terjadi apabila peningkatan banyaknya dataset yang diuji. Algoritma DBSCAN memberikan implementasi yang lebih akurat dalam perhitungan tertentu. (Xiaojuan, 2017)
DBSCAN merupakan algoritma dasar untuk teknik clustering berbasis kepadatan. Salah satu keuntungan menggunakan teknik-teknik ini adalah bahwa metode tidak memerlukan jumlah cluster untuk diberikan sebelumnya atau mereka tidak membuat asumsi tentang kepadatan atau varian dalam cluster yang mungkin ada dalam kumpulan data. Ini dapat mendeteksi kelompok yang berbagai bentuk dan ukuran dari sejumlah data besar yang mengandung noise dan outlier. (Glory, 2012).
Pada penelitian yang dilakukan oleh (Rahmah, 2015) penentuan nilai Eps optimal secara otomatis pada algoritme DBSCAN dapat diimplementasikan menggunakan bahasa pemograman R dengan runtime sebesar 1.72 detikuntuk system dan 32.39 detik untuk user.
Modifikasi DBSCAN dalam penentuan nilai Eps optimal secara otomatis pada data titik panas lahan gambut tahun 2013 dengan menggunakan bahasa pemograman R menghasilkan nilai radius (jarakmaksimal) titik-titik anggota cluster dari pusat cluster (Eps) sebesar 0.1118034 dan jumlah minimum titik-titik yang menjadi anggota cluster dalam radius Eps (MinPts) sebesar 3.
1.2. RumusanMasalah
Dari latar belakang yang telah di jelaskan sebelumnya hamper semua algoritma pengelompokan membutuhkan parameter input yang sulit untuk ditentukan tetapi memiliki pengaruh yang signifikan terhadap hasil, menemukan ukuran dalam bentuk cluster dan efisien bahkan untuk set data besar. DBSCAN akanmen deteksi cluster serta menentukan bagaiman amenentukan parameter epsilon dengan cara yang akurat untuk menentukan parameter input dan menemukan cluster dengan kepadatan yang berbeda-
4
4
beda terhadap dataset Iris dengan membandingkan pengukuran terhadap metode Euclidean Distance dan Canberra Distance.
1.3. BatasanMasalah
Berdasarkan permasalahan yang terdapat dalam penelitian ini, maka dengan ini dibutuhkannya sebuah batasan masalah. Batasan masalah membuat penelitian menjadi lebih terarah sehingga tujuan penelitiandapat tercapai.
Adapun batasan pada penelitian ini adalah sebagai berikut:
1. Penulishanya mengklasifikasi dataset Iris sebagai alat penguji ananalisa algoritma.
2. Penentuan nilai epsilon padaal goritma yang diuji tersedia pada pemrograman RapidMiner.
3. Dalam penelitian ini penulisanya menggunakan teknik data mining dengan metode Algoritma DBSCAN.
1.4. TujuanPenelitian
Pada latar belakang dan masalah yang telah dijabarkan sebelumnya maka tujuan dari penelitian ini adalah untuk mendeteksi cluster dengan metode penentuan dan penerapan nilai Epsilondan MinPts pada algoritma DBSCAN sehingga berpengaruh langsung terhadap jumlah clustering yang dihasilkan, Modifikasi terhadap parameter input yang ditentukan dan dengan membandingkan pendeteksian hasil clusterter hadap metode Euclidean Distance dan Canberra Distance mampu membuat proses pengelompokan optimal.
1.5. ManfaatPenelitian
Adapun manfaat penelitian dari tesisinia dalah:
1. Memberikan sumbangan bagihasil studi dan penelitian selanjutnya dan mengembangkan penelitian ini.
2. Menambah pemahaman dan pengetahuan penulis mengenai metode data mining 3. Mengetahui penggunaan Algoritma DBSCAN (Density-Based Spatial
Clustering of Applications with Noise).
BAB 2
LANDASAN TEORI
Pada bab ini akan diuraikan seluruh landasan teori yang berhubungan dengan penelitian.
Konsep-konsep yang akan di jelaskan dalam penelitian ini seperti Data Mining, Clustering, DBSCAN (Density-Based Spatial Clustering of Applications with Noise).
2.1. Data Mining
Menurut Gorunescu (2011), salah satu definisi dari data mining adalah proses pencarian pola yang terdapat pada basis data berukuran besar dengan menggunakan teknik komputasi dari ilmu statistik, machine learning dan pengenalan pola. Sementara itu menurut Tan (2006), data mining adalah proses untuk mendapatkan informasi yang berguna dari gudang basis data yang besar. Data mining juga dapat diartikan sebagai pengekstrakan informasi baru yang diambil dari bongkahan data besar yang membantu dalam pengambilan keputusan. Istilah data mining kadang disebut juga knowledge discovery.
Dalam data mining, pengelompokan data juga bisa dilakukan, tujuannya adalah agar kita dapat mengetahui pola universal data-data yang ada. Anomali data transaksi juga perlu dideteksi untuk dapat mengetahui tindak lanjut berikutnya yang dapat diambil. Semua hal tersebut bertujuan mendukung kegiatan operasional perusahaan sehingga tujuan akhir perusahaan diharapkan dapat tercapai.
Data mining merupakan salah satu tahapan penting di dalam proses Knowledge Discover in Database (KDD). Terminologi dari KDD dan data mining adalah berbeda.
KDD adalah keseluruhan proses di dalam menemukan pengetahuan yang berguna dari suatu kumpulan data sedangkan data mining adalah salah satu tahapan pada KDD dan fokus pada upaya untuk menemukan pengetahuan yang berguna dengan menggunakan algoritma (Fayyad et al., 1996).
6
Menurut Han et al. (2006) proses KDD terdiri dari tujuh tahapan yaitu :
1. Data Cleaning : membersihkan data dari noise dan data yang tidakkonsisten 2. Data Integration : menggabungkan data dari berbagai sumberdata
3. Data Selection : menyeleksi data yang relevan pada database untuk di masukkan ke dalam prosesanalisis
4. Data Transformation : data ditranformasikan ke dalam bentuk yang sesuai untuk proses datamining
5. Data Mining : proses pemilihan metode data mining yang sesuai untuk melakukan ekstraksi poladata
6. Pattern Evaluation : melakukan evaluasi terhadap pola data yang dihasilkan dari proses datamining
7. Knowledge Presentation : menampilkan hasil dari proses data mining dalam bentuk yang dapat dimengerti oleh manusia
2.2. Analisis Algoritma
Sebagai salah satu dasar dari ilmu komputer, algoritma merupakan hal yang sangat penting untuk dikuasai oleh orang-orang yang berkecimpung di dunia ilmu komputer, dari peneliti sampai ke praktisi. Tentunya penguasaan akan algoritma tidak cukup hanya sampai pada tahap mengetahui dan menggunakan algoritma yang tepat untuk menyelesaikan masalah. Seorang yang mengerti ilmu komputer juga mampu merancang dan mengembangkan sebuah algoritma berdasarkan masalah-masalah yang ditemui.
Tulisan ini bertujuan untuk memberikan pengertian mendasar mengenai perancangan (desain) dan pengembangan algoritma, agar pembaca dapat tidak hanya menggunakan algoritma yang sudah ada, tetapi juga merancang dan mengembangkan algoritma sesuai dengan masalah yang akan diselesaikan.
Program komputer umumnya dibangun dengan menggunakan beberapa algoritma untuk menyelesaikan sebuah permasalahan. Misalnya sebuah program pencarian teks akan memerlukan algoritma khusus untuk membaca dan menelusuri file, algoritma lain untuk mencari teks yang tepat di dalam file, dan satu algoritma lagi untuk menampilkan hasil pencarian ke pengguna.
Dalam mendefinisikan algoritma, dapat didefinisikan tiga hal utama dengan jelas, yaitu:
7
1. Masalah, yaitu sebuah persoalan yang ingin diselesaikan oleh sebuah algoritma. Pengurutan sekumpulan nilai yang bernilai acak.
2. Masukan, yaitu contoh data atau keadaan yang menjadi permasalahan.
3. Keluaran, yaitu bentuk akhir dari data atau keadaan setelah algoritma diimplementasikan ke masukan. Keluaran merupakan hasil ideal yang diinginkan dan dianggap telah menyelesaikan masalah.
Data masukan yang diinginkan merupakan rangkaian data, tanpa memperdulikan jenis data misalnya angka, huruf, teks, dan lain sebagainya. Contoh dari nilai masukan adalah 2, 5, 1, 3, 4 ataupun “Amin”, “Bia”, “Cinta”, “Doni”.Data keluaran yang diinginkan, yaitu masukan yang terurut 1,2,3,4,5 dan “Amin”, “Bia”, “Cinta”, “Doni”.
Kita telah mengetahui dengan jelas makna dari algoritma, sehingga pertanyaan selanjutnya adalah algoritma seperti apa yang dapat dikatakan sebagai algoritma yang baik? Pada umumnya kita tidak ingin menggunakan algoritma yang salah untuk menyelesaikan masalah karena hal ini dapat menyebabkan masalah tidak diselesaikan dengan optimal, atau lebih buruknya, tidak diselesaikan sama sekali.
Sebuah algoritma yang baik memiliki sifat-sifat berikut:
1. Benar, di mana algoritma menyelesaikan masalah dengan tepat, sesuai dengan definisi masukan / keluaran algoritma yang diberikan.
2. Efisien, berarti algoritma menyelesaikan masalah tanpa memberatkan bagian lain dari apliikasi. Sebuah algoritma yang tidak efisien akan menggunakan sumber daya (memori, CPU) yang besar dan memberatkan aplikasi yang mengimplementasikan algoritma tersebut.
3. Mudah diimplementasikan, artinya sebuah algoritma yang baik harus dapat dimengerti dengan mudah sehingga implementasi algoritma dapat dilakukan siapapun dengan pendidikan yang tepat, dalam waktu yang masuk akal.
Pada prakteknya, tentunya ketiga hal tersebut tidak dapat selalu tercapai.
Kebenaran dari sebuah algoritma umumnya selalu dapat dicapai, setidaknya untuk nilai- nilai masukan umum, tetapi efisiensi dan kemudahan implementasi tidak selalu didapatkan. Begitupun, tentunya kita harus tetap berusaha mencapai ketiga hal tersebut dalam merancang sebuah algoritma.
8
Apabila sesuatu algoritma diberi untuk sesuatu masalah dan ditentukan sebagai betul, langkah seterusnya ialah menentukan jumlah sumber, seperti masa dan ruang, yang diperlukan oleh algoritma tersebut. Langkah ini dikenali sebagai analisis algoritma. Analisis yang dilakukan ke atas algoritma dari segi:
1. Effectiveness
Mudah difahami sesuatu algoritma
Mudah dilakukan semakan(tracing), biarpun manual.
Langkah-langkah adalah tersusun atau organize.
2. Correctness
Algoritma yang dihasilkan akan mengeluarkan output yang diharapkan atau dikehendaki dan betul.
3. Termination
Langkah-langkah penyelesaian bagi algoritma mempunyai ‘terminator’ yang telah ditentukan.
Termination atau pemberhentian akan berlaku seperti dirancang dan bukan disebabkan oleh masalah seperti looping dan out of memory atau unfinite value.
4. Efficiency
Mengikur sejauh mana komputer menggunakan sumber yang diperlukan oleh algoritma.
5. Complexity
Satu analisis algoritma yang bersifat kualitatif.
Ia merujuk kepada kesukaran dalam perlaksanaan dan kesannya bagi satu algoritma.Juga diukur dalam bentuk masa, iaitu masa yang sedikit diambil menggambarkan kurang kompleksitinya
Sebelum merepresentasikan suatu algoritma utk memperoleh solusi dari suatu masalah, ditentukan dahulu model penyelesaiannya. Ada banyak model utk menyelesaikan masalah. Tetapi ada satu model yang terbaik. Sehingga penguasaan teknik variasi disain atau model harus dikuasai sebaik-baiknya.
9
Setelah menetapkan model, lalu dibuat representasi atau menyatakan algoritma.
Di sini harus dibuat barisan langkah-langkah atau instruksi secara teruut guna menyelesaikan suatu masalah. Pernyataan ini harus dibuat secara singkat, berhingga, terstruktur. Menyatakan algoritma dpt dgn dua cara yaitu: diagram atau pseudococe (bahasa semu)
Indikasi dari suatu algoritma yang valid adalah jika penyelesaiannya memenuhi solusi yang sebenarnya. Penyelesaian yg diperoleh harus memecahkan masalah bukan menimbulkan masalah baru. Perhitungan, prosedur, solusi harus selalu benar utk semua jenis kemungkinan masukan.
2.3 Clustering
Clustering adalah salah satu topik penelitian yang penting dalam bidang machine learning dan data mining. Clustering telah berkembang menjadi teknik yang populer dalam bidang pengenaalan pola, pemrosesan citra dan data mining (Aranganayagi, 2007). Teknik clustering klasik seperti metode k-means, melakukan partisi data menjadi k cluster (MacQueen, 1967) dan sangat peka terhadap nilai awal dari masing-masing pusat cluster (Cuietal, 2015).
Menurut Tan (2006) clustering adalah mengelompokkan objek (data) yang didasarkan hanya pada informasi yang terdapat dalam objek tersebut dan hubungan antar objek tersebut. Pengelompokan data tersebut biasanya dilakukan berdasarkan kesamaan nilai antar data (Xia et al. 2008).
Prinsip dasar dari clustering adalah mengukur jarak atau kemiripan antar objek pada suatu basis data. Clustering termasuk dalam metode pembelajaran tak terawasi (unsuperviced learning) (Nisha, 2015). Clustering bertujuan agar objek- objek pada satu kelompok adalah hanya terdiri dari objek-objek yang memiliki kemiripan satu sama lain dan berbeda dengan objek pada kelompok yang lain.
(Gothai, 2010) mengatakan bahwa tujuan utama dari proses clustering adalah untuk mengelompokkan data-data yang memiliki kemiripan diantara data-data yang tidak mirip, dengan kata lain kualitas dari proses clustering dapat diukur berdasarkan kemampuan suatu algoritma untuk dapat mengelompokkan data berdasarkan kemiripan datanya.
Terdapat berbagai jenis algoritma clustering yang dapat digunakan, tetapi secara umum
10
algoritma-algoritma tersebut dapat dikelompokkan menjadi beberapa kategori sebagai berikut (Rokach, 2005).
1. Partitioning Methods.
Pada metode ini diberikan himpunan dari n objek. Metode partisi akan mengelompokkan k partisi dari data. Dimana setiap partisi merepresentasikan sebuah cluster dan k ≤ n. Setiap objek yang ada merupakan bagian dari sebuah cluster.
Beberapa algoritma yang sering dipakai, yang termasuk dalam kategori partitioning methods adalah algoritma K-Means dan K-Medoids.
2. Hierarchical Methods.
Pada metode berbasis hirarki ini akan dibangkitkan hierarchical decomposition (dekomposisi berurutan) dari himpunan data objek.Berbeda dengan metode partitioning yang mengelompokkan data kedalam kelompok-kelompok. Metode hierarchical mengelompokkan data ke dalam hirarki atau tree dari cluster. Representasi data dalam bentuk hirarki adalah diperlukan untuk keperluan penyajiandan visualisasi data. Secara umum metode Hierarchical terdiri dari dua metode clustering yaitu metode Aglomerative dan metode Divisiv. Salah satu contoh algoritma dari metode Hierarchical adalah algoritma BIRCH (Balanced Iterative Reducing and Clustering UsingHierarchies).
3. Density-Based Methods.
Metode Density-Based merupakan metode yang dikembangkan berdasarkan density (kepadatan) tertentu. Metode ini menganggap cluster sebagai suatu area yang berisi objek-objek yang padat/sesak, yang dipisahkan oleh area yang memiliki kepadatan rendah (merepresentasikan noise). Beberapa algoritma yang termasuk di dalam Density- Based adalah DBSCAN (Density Based Spatial Clustering of Application with Noise) dan OPTICS (Ordering Points to Identify the ClusteringStructure).
4. Grid-Based Methods.
Pendekatan Grid-Based Methods menempatkan ruang objek ke dalam jumlah berhingga sel yang membentuk struktur grid, sehingga dikatakan juga bahwa metode ini menggunakan multiresolution pada struktur data grid (jaringan). Salah satu algoritma yang mendasarkan pada metode ini adalah STING (Statistical InformationGrid).
11
2.4 Subspace Clustering
Bottom up subspace clustering yang dimulai dari semua subruang satu dimensi yang mengakomodasi setidaknya satu cluster dengan menggunakan strategi pencarian yang mirip dengan algoritma pertambangan set item yang sering. CLIQUE merupakan perwakilan dari bottom up subspace clustering.
CLIQUE (Kailing, 2009) mengidentifikasi kelompok padat dalam domain dari dimensi maksimum. Setelah subruang yang tepat ditemukan, tugas ini adalah untuk menemukan cluster dalam proyeksi yang sesuai. Titik data dipisahkan sesuai dengan lembah fungsi kepadatan. Cluster adalah serikat unit kepadatan tinggi yang terhubung dalam subruang, kemudian akan menghasilkan deskripsi klaster dalam bentuk ekspresi DNF yang diminimalkan untuk kemudahan pemahaman. Ini menghasilkan hasil identik terlepas dari urutan catatan masukan disajikan dan tidak menganggap bentuk matematika tertentu untuk distribusidata.
CLIQUE mulai dari mengidentifikasi subruang yang mengandung cluster. Pada fase ini dapat menemukan unit yang padat, dengan menentukan unit pertama padat 1dimensi dengan membuat lulus atas data. Setelah menetapkan (k-1)-dimensi unit padat, calon unit k-dimensi ditentukan dengan menggunakan prosedur generasi calon diberikan di bawah ini. Sementara prosedur saja dijelaskan secara dramatis mengurangi jumlah unit yang diuji untuk menjadi padat, kita mungkin masih memiliki tugas komputasi tidak layak di tangan untuk data dimensi tinggi. Sebagai dimensi dari subruang dianggap meningkat, ada ledakan dalam jumlah unit yang padat, dan jadi kita perlu memangkas set unit padat ini kemudian digunakan untuk membentuk unit calon di tingkat berikutnya dari algoritma generasi satuan padat. Setelah mengidentifikasi subruang mengandung klaster, diikuti dengan mengidentifikasi cluster dan generasi deskripsi minimal untuk cluster.
2.5 DBSCAN (Density-Based Spatial Clustering of Applications with Noise).
DBSCAN adalah salah satu algoritma clustering density-based. Algoritma memperluas wilayah dengan kepadatan yang tinggi ke dalam cluster dan menempatkan cluster irregular pada database spasial dengan noise. Metode ini mendefiniskan cluster sebagai
12
maximal set dari titik-titik yang density-connected. DBSCAN memiliki 2 parameter yaitu Epsilondan MinPts :
a. epsilon: jika nilai eps yang dipilih terlalu kecil, sebagian besar data tidak akan dikelompokkan. Ini akan dianggap outlier karena tidak memenuhi jumlah poin untuk membuat wilayah padat. Di sisi lain, jika nilai yang dipilih terlalu tinggi, cluster akan bergabung dan sebagian besar objek akan berada di cluster yang sama. Eps harus dipilih berdasarkan jarak dataset (kita dapat menggunakan grafik k-distance untuk menemukannya), tetapi secara umum nilai eps kecil lebih disukai.
b. minPoints: Sebagai aturan umum, minPoints minimum dapat diturunkan dari sejumlah dimensi (D) dalam kumpulan data, karena minPoints ≥ D + 1. Nilai yang lebih besar biasanya lebih baik untuk set data dengan noise dan akan membentuk kelompok yang lebih signifikan. Nilai minimum untuk minPoints harus 3, tetapi semakin besar set data, semakin besar nilai minPoints yang harus dipilih.
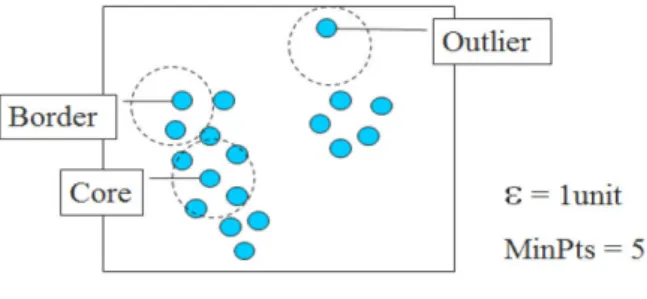
Neighborhood yang terletak di dalam radius () disebut -neighorhood dari objek data. Jika-neighborhood dari suatu objek berisi paling sedikit suatu angka yang minimum, MinPts dari suatu objek, objek tersebut disebut core object. Neighborhood dari border points berisi jauh lebih sedikit items daripada neighborhood dari core points. Suatu border point bisa jadi termasuk ke dalam lebih dari 1 core object. Berikut ini gambar yang menunjukkan mana yang merupakan border point dan mana yang merupakan core point contoh dengan menggunakan MinPts=5 dan Eps=1.
Gambar 2.1.Core dan Border
Menurut definisi, ada 2 jenis titik (points) dalam suatu cluster: di dalam cluster (core points) dan di tepian cluster (border points) di mana neighborhood dari border points berisi jauh lebih sedikit items daripada neighborhood dari core points
13
(Ester et al., 1996). Suatu border point bisa jadi termasuk ke dalam lebih dari 1 cluster.
Gambar 2.2 Konsep Kepadatan
Adapun cara DBSCAN dalam menemukan cluster adalah menelusuri cluster- cluster dengan memeriksa - neighborhood(Eps-neighborhood) dari tiap-tiap point dalam database. Jika - neighborhood dari point p mengandung lebih dari MinPts, cluster baru dengan p sebagai core object diciptakan. Kemudian DBSCAN secara iteratif mengumpulkan secara langsung objekobjek density-reachable dari core object tersebut, dimana mungkin melibatkan penggabungan dari beberapa cluster-cluster yang density-reachable.
Aplikasi pengelompokan spasial berbasis kepadatan dengan noise (DBSCAN) adalah algoritma pengelompokan data yang terkenal yang umum digunakan dalam penambangan data dan pembelajaran mesin. Berdasarkan seperangkat titik, DBSCAN mengelompokkan titik yang berdekatan satu sama lain berdasarkan pengukuran jarak (biasanya jarak Euclidean) dan jumlah minimum poin. Hal ini juga menandai titik-titik yang berada di daerah dengan kepadatan rendah.
Estimasi parameter adalah masalah untuk setiap tugas penambangan data.
Untuk memilih parameter yang baik kita perlu memahami bagaimana mereka digunakan dan memiliki setidaknya pengetahuan dasar sebelumnya tentang set data yang akan digunakan. Seperti halnya dalam parameter Epsilon: jika nilai eps yang dipilih terlalu kecil, sebagian besar data tidak akan dikelompokkan. Ini akan dianggap outlier karena tidak memenuhi jumlah poin untuk membuat wilayah padat. Di sisi lain, jika nilai yang dipilih terlalu tinggi, cluster akan bergabung dan sebagian besar objek akan berada di cluster yang sama. Eps harus dipilih berdasarkan jarak dataset (kita dapat menggunakan grafik k-distance untuk menemukannya), tetapi secara umum nilai eps kecil lebih disukai. Sementara pada minPoints: Sebagai aturan umum, minPoints minimum dapat diturunkan dari sejumlah dimensi (D) dalam kumpulan data, karena minPoints ≥ D + 1. Nilai yang lebih besar biasanya lebih baik untuk set data dengan
14
noise dan akan membentuk kelompok yang lebih signifikan. Nilai minimum untuk minPoints harus 3, tetapi semakin besar set data, semakin besar nilai minPoints yang harus dipilih.
Algoritma DBSCAN harus digunakan untuk menemukan asosiasi dan struktur dalam data yang sulit ditemukan secara manual tetapi dapat relevan dan berguna untuk menemukan pola dan memprediksi tren. Pada dasarnyaMetode pengelompokan biasanya digunakan dalam biologi, kedokteran, ilmu sosial, arkeologi, pemasaran, pengenalan karakter, sistem manajemen dan sebagainya.
Mari berfikir dalam penggunaan praktis DBSCAN. Misalkan kita memiliki e- commerce dan kami ingin meningkatkan penjualan kami dengan merekomendasikan produk yang relevan kepada pelanggan kami. Kami tidak tahu persis apa yang dicari pelanggan kami, tetapi berdasarkan kumpulan data yang dapat kami prediksi dan rekomendasikan produk yang relevan untuk pelanggan tertentu. Kami dapat menerapkan DBSCAN pada kumpulan data kami (berdasarkan pada basis data e- commerce) dan menemukan kluster berdasarkan pada produk yang telah dibeli oleh pengguna. Dengan menggunakan kluster ini kita dapat menemukan kesamaan antara pelanggan, misalnya, pelanggan A telah membeli 1 pena, 1 buku dan 1 gunting dan pelanggan B telah membeli 1 buku dan 1 gunting, maka kami dapat merekomendasikan 1 pena kepada pelanggan B. Ini hanyalah sedikit contoh penggunaan DBSCAN, tetapi dapat digunakan di banyak aplikasi di beberapa area.
Bagaimana kita dapat dengan mudah mengimplementasikannya? DBSCAN adalah algoritma yang terkenal, oleh karena itu, sesungguhnya tidak perlu khawatir untuk mengimplementasikannya sendiri. Anda dapat menggunakan salah satu perpustakaan / paket yang dapat ditemukan di internet. Berikut adalah daftar tautan yang dapat Anda temukan implementasi DBSCAN: Matlab, R, R, Python, Python.
Kunci dari algoritma DBSCAN adalah bahwa untuk setiap titik dari sebuah cluster, neighborhood dari radius yang diberikan harus mengandung setidaknya jumlah minimum poin, yaitu, kepadatan neighborhood harus melebihi beberapa threshold ditetapkan (Ye, Gao and Zeng, 2003).
Secara umum algoritma DBSCAN memiliki 5 langkah, yaitu : 1. Pilih point p awal secara acak)
2. Ambil semua point yang density reachable terhadap titik p 3. Jika p adalah core point maka cluster terbentuk
4. Jika p adalah border point, tidak ada yang merupakan hubungan density- reachable dari p dan DBSCAN akan mengunjungi point selanjutnya dari database.
5. Lanjutkan proses sampai semua point telah diproses
15
2.6 Metode Euclidean Distance
Euclidean Distance atau jarak Euclidean adalah perhitungan jarak dari dua buah titik dalam Euclidean space. Euclidean space diperkenalkan oleh Euclid, seorang matematikawan dari Yunani sekitar tahun 300 B.C.E. untuk mempelajari hubungan antara sudut dan jarak. Euclidean ini berkaitan dengan Teorema Phytagoras dan biasanya diterapkan pada 1, 2 dan 3 dimensi.
1 dimensi : Semisal ingin menghitung jarak Euclidean 1 dimensi. Titip pertama adalah 4, titik kedua adalah -10. Caranya adalah kurankan -10 dengan 4. sehingga menghasilkan -14. Cari nilai absolut dari nilai -14 dengan cara mempangkatkannya sehingga mendapat nilai 196. Kemudian diakarkan sehingga mendapatkan nilai 14.
Sehingga jarak euclidean dari 2 titik tersebut adalah 14.
2 dimensi : Caranya hampir sama. Misalkan titik pertama mempunyai kordinat (3,5). Titik kedua ada di kordinat (5,-3). Caranya adalah kurangkan setiap kordinat titik kedua dengan titik yang pertama. Yaitu, (5-3,-3-5) sehingga menjadi (2,-8). Kemudian pangkatnya sehingga memperoleh (4,64). Kemudian tambahkan semuanya sehingga memperoleh nilai 64+4 = 68. Hasil ini kemudian diakarkan menjadi 8.25. Sehingga jarak euclideannya menjadi 8.25.
Jarak Euclidean adalah jarak yang diukur lurus dari titk koordinat yang satu ke titik koordinat yang lain. Meskipun cara ini kurang realistis, tetapi pada umumnya sering digunakan karena cara ini mudah dimengerti dan mudah dimodelkan. Aplikasi dari jarak Euclidean pada umumnya bisa kita jumpai pada beberapa model konveyor, sistem transportasi dan distribusi.
Jarak Euclidean merupakan jarak yang diukur lurus dari pusat fasilitas yang satu ke fasilitas yang lain. Meskipun cara ini kurang realistis, tetapi pada umumnya sering digunakan karena cara ini mudah dimengerti dan mudah dimodelkan. Aplikasi dari dari jarak Euclidean pada umumnya bisa kita jumpai pada beberapa model konveyor, sistem transportasi dan distribusi. Formulasi dari jarak Euclidean sebagai berikut:
16
Dimana :
xi = koordinat x untuk fasilitas i yi = koordinat y untuk fasilitas i dij = jarak antar fasilitas i dan j
2.7 Metode Canberra Distance
Untuk setiap nilai 2 vektor yang akandicocokkan, Canberra Distancemembagi absolute selisih 2 nilaidengan jumlah dari absolute 2 nilaitersebut. Hasil dari dua nilai yangdicocokkan lalu dijumlahkan untukmendapatkan Canberra Distance.
Jikakoordinatnol-nol((0,0)) diberikandefinisi dengan 0/0=0. Canberra Distance ini sangat peka terhadapsedikit perubahan dengan kedua koordinat mendekati nol.
Metrik Canberra mirip dengan jarak Manhattan (yang sendiri merupakan bentuk khusus dari jarak Minkowski). Perbedaannya adalah bahwa perbedaan absolut antara variabel dari dua objek dibagi dengan jumlah nilai variabel absolut sebelum dijumlahkan. Persamaan umum diberikan dalam bentuk:
Ini adalah bentuk yang sedikit dimodifikasi dibandingkan dengan bentuk asli yang diberikan oleh Lance & Williams (1966) dan disarankan oleh Adkins (referensi dalam Lance & Williams 1967). Dalam persamaan dCAD adalah jarak Canberra antara dua objek i dan j, k adalah indeks variabel dan n adalah jumlah total variabel y.
Dalam bentuk asli data metrik Canberra tidak boleh ditandatangani. Bentuk yang dimodifikasi menurut Adkins (dalam Lance & Williams 1967) memiliki sifat bahwa hasilnya menjadi satu ketika variabel-variabelnya bertanda berlawanan. Ini berguna dalam kasus khusus di mana tanda-tanda mewakili perbedaan dalam bentuk dan bukan dalam derajat (Lance & Williams 1967). Bagaimanapun, ini terutama digunakan untuk nilai> 0. Metrik ini mudah bias untuk ukuran di sekitar asal dan sangat sensitif untuk nilai yang mendekati 0, di mana ia lebih sensitif terhadap proporsional daripada perbedaan absolut (Lance & Williams 1967). Fitur ini menjadi lebih jelas dalam ruang dimensi yang lebih tinggi, yang masing-masing merupakan peningkatan jumlah variabel. Hal ini pada gilirannya kurang dipengaruhi daripada jarak Manhattan oleh variabel dengan nilai-nilai tinggi (Krebs 1989). Sebagai pengukuran yang sangat
17
sensitif, ini berlaku untuk mengidentifikasi penyimpangan dari pembacaan normal (mis.
Emran & Ye 2001).
Algoritma mengontrol apakah matriks input data berbentuk persegi panjang atau tidak. Jika tidak, fungsi mengembalikan FALSE dan matriks keluaran yang ditentukan, tetapi kosong. Ketika matriks berbentuk persegi panjang, jarak Canberra dihitung. Oleh karena itu dimensi array masing-masing dari matriks keluaran dan judul untuk baris dan kolom ditetapkan. Sebagai hasilnya adalah matriks persegi, yang dicerminkan sepanjang nilai-nilai hanya diagonal untuk satu bagian segitiga dan diagonal dihitung. Ketika kesalahan terjadi selama perhitungan, fungsi mengembalikan FALSE.
18 BAB 3
METODE PENELITIAN
3.1. Pendahuluan
Manusia yang terampil membagi objek ke dalam kelompok-kelompok (dikenal sebagai pengelompokan), menempatkan objek tertentu kepada kelompok-kelompok (dikenal sebagai klasifikasi), dan kemudian melakukan prediksi untuk objek tertentu.
Penggunaan pengelompokan dalam penelitian ini untuk memahami anggota objek untuk setiap set data. Ini prototipe cluster dapat digunakan sebagai dasar untuk sejumlah analisis data atau pengolahan data kelompok analisis data yang technique.
Clustering benda hanya berdasarkan informasi yang ditemukan dalam data set yang menggambarkan objek dan hubungan mereka. Grup obyek harus sama satu sama lain Namun pada kenyataannya, ada banyak situasi di mana obyek cukup daripada yang bisa ditempatkan di lebih dari satu cluster. Dalam kasus ini, subruang klaster harus digunakan untuk memecahkan masalah.
Penelitian ini untuk mengidentifikasi objek tertentu dan tempat dalam cluster terkait, untuk memastikan hubungan metode yang digunakan DBSCAN sebagai teknik pengelompokan dasar. Konsep cluster kepadatan terhubung mendasari algoritma DBSCAN (Density-Based Spatial Clustering of Applications with Noise). Kami mengusulkan teknik ditingkatkan untuk mengatasi tantangan clustering di data mining pendidikan, yaitu sebagai Damira (multidimensi data mining subruang Pendekatan Clustering). Penelitian data mining dimulai dari kepadatan berbasis., dengan mudah mengidentifikasi sekelompok poin dan juga mengidentifikasi outlier yang terbentuk (Ester et al, 1996). Sebagai cluster titik-titik memiliki kepadatan mendekati poin dari yang lain. Sementara titik di luar kelompok disebut sebagai kebisingan.
19
Gambar 3.1. Density Based Cluster (Ester, 1996) 3.2. Pelaksanaan Penelitian
Proses penelitian ini terdapat beberapa kegiatan, yaitu kegiatan-kegiatan yang terdapt pada penelitian, yaitu observasi lapangan, pengumpulan data dan analisa data.
3.2.1. Observasi
Observasi yang dilakukan pada penelitian ini adalah hal yang paling penting. Karena penulis dpat mengetahui tingkat visibilitas yang digunakan. Data-data yang telah dikumpulkan telah menjadi titik pantauan dalam observasi ini sehingga mendapatkan hasil yang diinginkan.
3.2.2. Data yang Digunakan
Pada langkah awal dalam analisis data ini akan ditentukan beberapa atribut yang digunakan sebagai parameter dalam pengklasifikasian data sampel. Atribut menyatakan suatu parameter yang dibuat sebagai kriteria dalam pembentukan pohon. Pada ilmu statistik khususnya pada sampel terdapat penjelasan mengenai beberapa metode pengambilan sampel. Sampel yang baik yaitu yang dapat menggambarkan (mewakili) populasinya. Untuk memperoleh sampel yang baik diperlukan metode yang baik dalam pemilihan anggota sampel. Sampel nonrandom merupakan salah satu metode pengambilan sampel dimana pemilihan sampel dengan cara ini menggunakan pengetahuan dan opini dari peneliti terhadap obyek yang akan diteliti. Sedangkan dalam sebuah model DBSCAN (Density-Based Spatial Clustering of Applications with Noise) berisi aturan yang membagi sejumlah populasi yang homogen menjadi lebih kecil (heterogen).
Dataset yang akan digunakan pada penelitian ini bersumber UCI machine learning repository, repository UCI machine learning repository memiliki cukup
20
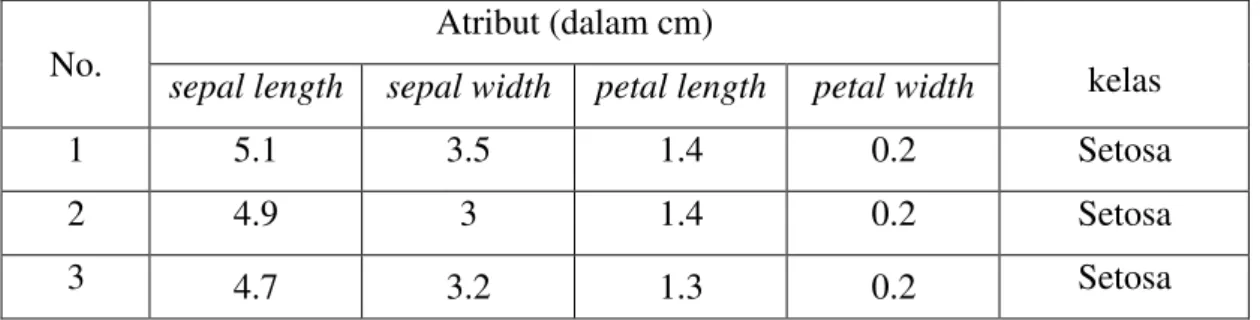
banyak koleksi dataset yang digunakan pada penelitian tentang clustering, dataset tersebut antara lain adalah Iris Dataset yang memiliki jumlah data sebanyak 150 data, jumlah atribut sebanyak 4 atribut dan jumlah kelas sebanyak 3 kelas.
Set data bunga Iris atau set data Iris Fisher adalah set data multivariat yang diperkenalkan oleh ahlistatistik dan biolog Inggris Ronald Fisher dalam makalahnya tahun 1936. Penggunaan pengukuran berganda dalam masalah taksonomi sebagai contoh analisis diskriminan linier . Kadang-kadang disebut set data Iris Anderson karena Edgar Anderson mengumpulkan data untuk menghitung variasi morfologis bunga Iris dari tiga spesies terkait. Dua dari tiga spesies dikumpulkan di Semenanjung Gaspé "semuanya berasal dari padang rumput yang sama, dan dipetik pada hari yang sama dan diukur pada saat yang sama oleh orang yang sama dengan peralatan yang sama".
Set data terdiri dari 50 sampel dari masing-masing dari tiga spesies Iris ( Iris setosa , Iris virginica dan Iris versicolor ). Empat fitur diukur dari masing-masing sampel: panjang dan lebar sepal dan kelopak , dalam sentimeter. Berdasarkan kombinasi keempat fitur ini, Fisher mengembangkan model diskriminan linier untuk membedakan spesies dari satu sama lain.Bunga iris sangat terkenal di dunia machine learning untuk percobaan klasifikasinya. Bunga Iris memiliki 3 spesies/varietas yaitu Versicolor, Virginica dan Setosa. Lalu masing-masing spesies memiliki Sepal Length, Sepal Width, Petal Length dan Petal Width dalam centimeter yang berbeda-beda.
Pemilihan Iris dataset dalam penelitian ini karena dataset tersebut telah banyak digunakan pada berbagai penelitian dalam bidang clutering seperti yang digunakan Li, P et al. (2017), Sun, L dan Guo, C (2014), Wang, Y dan Chen, L (2016). Data dari Iris dataset dapat dilihat pada tabel 3.1. berikut:
Tabel 3.1. Iris dataset
No.
Atribut (dalam cm)
kelas sepal length sepal width petal length petal width
1 5.1 3.5 1.4 0.2 Setosa
2 4.9 3 1.4 0.2 Setosa
3 4.7 3.2 1.3 0.2 Setosa
21
No.
Atribut (dalam cm)
kelas sepal length sepal width petal length petal width
50 5 3.3 1.4 0.2 Versicolor
51 7 3.2 4.7 1.4 Versicolor
52 6.4 3.2 4.5 1.5 Versicolor
⁞ ⁞ ⁞ ⁞ ⁞ ⁞
70 5.6 2.5 3.9 1.1 Versicolor
71 5.9 3.2 4.8 1.8 Versicolor
72 6.1 2.8 4 1.3 Versicolor
73 6.3 2.5 4.9 1.5 Versicolor
⁞ ⁞ ⁞ ⁞ ⁞ ⁞
101 6.3 3.3 6 2.5 Virginica
102 5.8 2.7 5.1 1.9 Virginica
103 7.1 3 5.9 2.1 Virginica
104 6.3 2.9 5.6 1.8 Virginica
105 6.5 3 5.8 2.2 Virginica
⁞ ⁞ ⁞ ⁞ ⁞ ⁞
122 5.6 2.8 4.9 2 Virginica
123 7.7 2.8 6.7 2 Virginica
124 6.3 2.7 4.9 1.8 Virginica
125 6.7 3.3 5.7 2.1 Virginica
⁞ ⁞ ⁞ ⁞ ⁞ ⁞
148 6.5 3 5.2 2 Virginica
4 4.6 3.1 1.5 0.2 Setosa
5 5 3.6 1.4 0.2 Setosa
⁞ ⁞ ⁞ ⁞ ⁞ ⁞
10 4.9 3.1 1.5 0.1 Setosa
11 5.4 3.7 1.5 0.2 Setosa
12 4.8 3.4 1.6 0.2 Setosa
13 4.8 3 1.4 0.1 Setosa
22
149 6.2 3.4 5.4 2.3 Virginica
150 5.9 3.0 5.1 1.8 Virginica
3.3. Desain Sistem
Pada penelitian ini, keperluan hardware dan software sebagai bagian dari proses desain sistem meliputi:
a. Perangkat Keras (Hardware) 1. Notebook Acer
2. Processor Intel AtomTM N570 @1.66GHz 1.67 GHz 3. RAM 2 GB DDR3
4. Harddisk 500 GB
5. Monitor dengan reolusi 1024 x 600 pixel (32 bit true color) 6. Mouse dan keyboard
b. Perangkat Lunak (Software) 1. Sistem Operasi Windows 7
Sistem Operasi Windows 7 merupakan sistem operasi berbasis grafis yang dirancang oleh Microsoft berfingsi pada computer pribadi, termasuk computer rumah, bisnis, laptop, dan lain sebagainya. Windows 7 merupakan sistem dasar yang mendukung pada setiap proses penelitian ini.
2. RapidMiner
RapidMiner merupakan software untuk pengelolaan data mining. RapidMiner melakukan pekerjaan text mining berkisar dengan analisis teks, mengekstrak pola-pola dari data set yang besar dan mengkombinasikannya dengan metode statistika, kecerdasan buatan, dan database.
3.4. Rancangan Penelitian
Pada penelitian yang dilakukan, membutuhkan suatu tahap dalam mendapatkan hasil dari tujuan penelitian. Setiap langkah penelitian digambarkan menggunakan flowchart.
Penelitian ini dilakukan pertama kali yaitu penginputan dataset irisyang telah tersedia.
Kemudian menentukan parameter inputyaitu Eps dan MinPts. Parameter Eps digunakan untuk menentukan radius (jarak maksimal) titik-titik anggota cluster dari pusat cluster.
23
Parameter MinPts digunakan untuk memberikan batasan jumlah titik-titik yang menjadi anggota cluster dalam radius Eps dengan menentukan atribut-atribut dari data yang akan dikelompokkan misalnya sepal length, sepal width, petal length, dan petal width untuk kebutuhan pelatihan dan pengujian metode yang digunakan. Selanjutnya yaitu pada langkah analisis cluster, data yang diuji merupakan tugas pemberian nilai awal yang dilakukan saat deklarasi variabel atau obyek, serta pelatihan awal menggunakan algoritma DBSCAN. Tujuannya agar dalam pelatihan ini dengan memperhatikan nilai output dan jumlah cluster yang dihasilkan.
Setelah melakukan tahapan pelatihan maka selanjutnya yaitu langkah pengujian data, yang bertujuan agar mendapatkan clustering yang lebihbaik. Metode penentuan nilai Epsilon pada algoritma DBSCAN (Density-Based Spatial Clustering of Applications with Noise)akan berpengaruh langsung terhadap jumlah clustering yangdihasilkan. Hasil dari pengolahan data kemudian dianalisis hasilnya yang kemudian dapat diambil kesimpulan dari hasil yang didapat.
Adapun rancangan dari penelitian ini dapat dilihat sebagai berikut :
24
Adapun rancangan dari penelitian ini dapat dilihat sebagai berikut:
Gambar 3.2. Rancangan Penelitian
Algoritma DBSCAN memiliki dua parameter masukan, yaitu Eps dan MinPts.
Parameter Eps digunakan untuk menentukan radius (jarak maksimal) titik-titik anggota cluster dari pusat cluster. Parameter MinPts digunakan untuk memberikan batasan jumlah titik-titik yang menjadi anggota cluster dalam radius Eps tersebut. Dibutuhkan penerapan k-dist plot untuk menemukan nilai parameter Eps yang sesuai dengan tingkat kepadataan data karena setiap nilai Eps pada algoritme DBSCAN diadopsi untuk menemukan semua kelompok sehubungan dengan tingkat kepadatan yang sesuai (Elbatta 2012).
25
Langkah-langkah yang digunakan untuk menemukan Eps yang sesuai pada setiap tingat kepadatan adalah (Elbatta 2012):
1. Menghitung k-dist untuk setiap titik dan mempartisi k-dist plot.
2. Jumlah kepadatan diberikan secara langsung oleh k-dist plot.
3. Memilih parameter Eps secara otomatis untuk setiap kepadatan.
26 BAB 4
HASIL DAN PEMBAHASAN
4.1. Hasil Implementasi
Pada percobaan ini akan dilakukan pengujian terhadap kinerja dari Density Based Spatial Clustering Algorithm with Noise (DBSCAN) adalah merupakan algoritma clustering yang didasari pada tingkat kepadatan (density) data. Pemahaman konsep density yang disebut dalam DBSCAN merupakan jumlah data yangberada dalam radius MinPts (Jumlah minimal data dalam radius ε), data tersebut masuk dalam kategori kepadatan yang diinginkan, jumlah data dalam radius tersebut termasuk data inti itu sendiri., pengukuran kinerja dilakukan dengan membandingkan nilai dari Euclidean Distance dan Canberra Distance yang dihasilkan. Nilai Cluster yang akan digunakan bervariasi sesuai dengan ketentuan dari Epslilon dan MinPts. Dataset yang digunakan dalam melakukan percobaan ini adalah Iris dataset yang diperoleh dari UCI Machine Learning repository.
4.1.1. Pengujian pada Iris dataset
Pada tahap ini dilakukan pengujian kinerja dari algoritma DBSCAN dan pengukuran kinerja dilakukan dengan membandingkan nilai dari Euclidean Distance dan Camberra Distance yang dihasilkan dari algoritma.
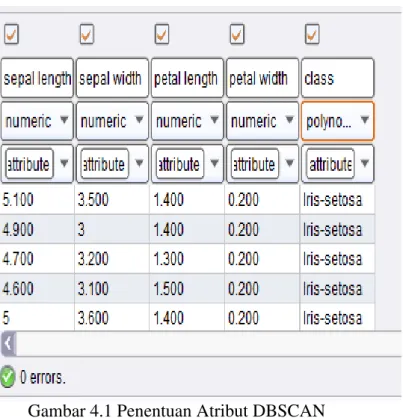
a. Penentuan Atribut Data
Sebelum melakukan pengujian terhadap model clustering, maka tahap yang perlu dilakukan adalah pemilihan atribut.
27
Gambar 4.1 Penentuan Atribut DBSCAN
Pada gambar 4.1 menunjukkan proses penentuan atribut dan label pada algoritma DBSCAN dengan menggunakan data numerik sebagai atribut-atributnya yang kegunaannya untuk memodelkan jumlah keberhasilan pada jumlah data.
b. Model Rancangan DBSCAN
Gambar 4.2 Rancangan Model DBSCAN
Pada gambar 4.2 diatas menunjukkan prosedur kerjaDBSCAN Rapidminer. Langkah pertama adalah memasukkan dataset yang memiliki format .excel (Read Excel), kemudian dilakukan Normalize dengan melakukan normalisasi data terlebih dahulu.
Hasil Normalize kemudian dimasukkan ke metode DBSCAN untuk data training dan
28
Fungsi Filter Example dapat mengurangi jumlah sampel dalam dataset tetapi tidak berpengaruh pada jumlah atribut. Berikut adalah Hasil pengujian data pada metode DBSCAN untuk Iris Dataset pada pengujian terhadap metode Euclidean Distance dan Camberra Distance yang disajikan pada tabel 4.1
Tabel. 4.1. Hasil Pengujian pada Iris Dataset
No.
Euclidean Distance
Camberra Distance
Jumlah Cluster
Jumlah Cluster
1 5 43
2 49 42
3 94 7
4 2 3
5 - 2
6 - 2
7 - 4
8 - 14
9 - 3
10 - 25
11 - 3
12 - 2
total 150 150
29
Gambar 4.3. Grafik Hasil Pengujian pada Iris Dataset
Gambar 4.3 menunjukkan grafik hasil clustering yang diukur berdasarkan nilai dari Euclidean Distance dan Camberra Distance yang dihasilkan dari algoritma DBSCAN.
Pembentukan cluster yang paling banyak terjadi pada metode Euclidean Distance yang mencapai 97 jumlah cluster. Tetapi, hanya terdapat 4 kali proses pembentukan cluster yang terjadi terhadap metode Euclidean Distance sedangkan pada Camberra Distance mencapai 10 kali proses clustering walaupun jumlah cluster yang tidak seimbang.
4.1.2. Hasil Cluster Euclidean Distance
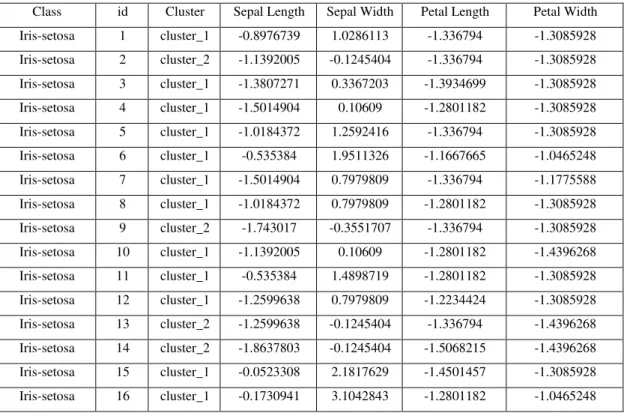
Pada penelitian ini dilakukan pengelompokan dataset iris menggunakan metode Density Based Spatial Clustering Algorithm with Noise (DBSCAN). Pada penelitian denganmetode DBSCAN ini digunakan minimalpoints (Minpts) 2 dan epsilon (Eps) 0,9.Hasil dari Cluster dapat dilihat pada Tabel 4.2, sedangkan Plot pengelompokan menggunakanEuclidean Distance dapat dilihat pada Gambar 4.5.
Tabel 4.2 Hasil Cluster Euclidean Distance
Class Id Cluster Sepal Length Sepal Width Petal Length Petal Width Iris-setosa 1 cluster_1 -0.897673879 1.028611281 -1.33679402 -1.308592819 Iris-setosa 2 cluster_1 -1.139200483 -0.124540379 -1.33679402 -1.308592819 Iris-setosa 3 cluster_1 -1.380727088 0.336720285 -1.393469855 -1.308592819 Iris-setosa 4 cluster_1 -1.50149039 0.106089953 -1.280118186 -1.308592819 Iris-setosa 5 cluster_1 -1.018437181 1.259241613 -1.33679402 -1.308592819 Iris-setosa 6 cluster_1 -0.535383973 1.951132609 -1.166766516 -1.046524832
0 10 20 30 40 50 60 70 80 90 100
1 2 3 4 5 6 7 8 9 10
Euclidean Distance Jumlah Cluster Camberra Distance Jumlah Cluster