PUSTAKA
[AGR00] Agrawal, Rakesh and Srikant, Ramakrishnan (2000), Mining Sequential Pattern, IBM Almaden Research Center, 650 Harry Road, San Jose, CA 95120
[CHE98] Cheng, J., Bell, D. A., Liu, W. (1998) Learning Bayesian Network from Data: an Efficient Approach Based on Information Theory. Faculty of Informatics, University of Ulster, U.K.
[CHE01[a]] Cheng, J., Bell, D. A., Liu, W. (2001) Learning Bayesian Network from Data: An Information-Theory Based Approach. Faculty of Informatics, University of Ulster, U.K.
[CHE01[b]] Cheng, J. (2001) Belief Network PowerConstrutor (Evaluation Copy) Version 2.2 Beta.
http://www.cs.ualberta.ca/~jcheng/bnpc.html
[COO92] Cooper, G. F., Herskovits, E. (1992). A Bayesian Method for Induction of Probabilistic Networks from Data. Machine Learning.
[CRA95] Hogg Craig (1995). Introduction to Mathematical Statistics, Prentice Hall
[DEO74] Deo, Narshing, Graph Theory with Applications to Engineering and Computer Science, Prentice-Hall Internation, 1974
[FAY96] Fayyad, U., Piatetsky-Shapiro, G., Smyth, P. (1996). From Data Mining to Knowledge Discovery in Database. AAAI. Al Magazine : 37-54. [HAN06] Han, Jia Wei, and Kamber, Micheline (2006). Data Mining: Concepts
and Techniques, University of Illionis at Urbana-Champaign
[JEN96] Jensen, Finn V. (1996). Bayesian Network, British Library Cataloguing in Publication Data
[LAU88] Lauritzen, Steffen L., Spiegelhalter, David J. (1988). Local computation with probabilities on grafical stuctures and their application to expert systems, Journal of the Royal Statistical Society
[MIT01] Mittal, Ankush (2001). Dynamic Bayesian Framework for Extracting Temporal Structure in Video. IEEE Transactions on Dependable and Secure Computing vol 5. No 1, January-March 2008.
[NEA04] Neapolitan, Richard E. (2004). Learning Bayesian Networks, Prentice Hall.
[PEA01] Pearl, Judea, (2001) Causality: Models, Reasoning, and Interference, Cambridge University Press, New York.
[SRI08] Srivasta, Abhinav, 2008. Credit Card Fraud Detection Using Hidden Markov Model, IEEE Transactions on Dependable and Secure Computing vol 5. No 1, January-March 2008.
LAMPIRAN A
BAYESIAN NETWORK DAN TEORI INFORMASI
Pada bagian ini, diuraikan beberapa konsep dasar yang berhubungan dengan BN, dan proses konstruksi strukstur BN. Selanjutnya akan diperkenalkan kondisi Markov, serta dua buah konsep yang paling fundamental yang akan digunakan yaitu konsep d-separation dan konsep faithfulness yang akan diuraikan dari sudut pandang informasi teori.A.1. Konsep Dasar
Pada saat mengkonstruksi struktur BN, terlebih dahulu perlu dipahami beberapa konsep dasar yang akan digunakan. Konsep dasar tersebut akan digunakan dalam menganalisis struktur BN, agar struktur yang dikonstruksi memberikan model yang benar. Konsep dasar tersebut mengacu pada [NEA04] dan [CHE98] yang mencakup beberapa definisi yang diberikan selanjutnya.
Berikut dijelaskan tentang struktur graf BN, yang merupakan graf berarah tanpa siklus berarah atau disebut directed acyclic graph (DAG). Penjelasan mengacu pada [NEA04].
Definisi L.1. Sebuah directed graph G adalah pasangan (V,E) bisa didefinisikan sebagai sebuah pasangan berurut yang terdiri dari himpunan terbatas V dari beberapa simpul, dan sebuah hubungan ketetanggaan yang tidak refleksif E pada V. Dengan hubungan ketetanggaan yang tidak refleksif tersebut, maka simpul x ∈ E akan memenuhi (x,x) ∉ E, artinya suatu simpul tidak bisa sebagai titik awal dan sekaligus juga sebagai titik akhir. Graf G notasikan sebagai (V,E). Untuk setiap (x,y) ∈ E maka dikatakan bahwa ada sebuah arc (busur berarah) dari simpul x ke simpul y. Pada graf tersebut, busur direpresentasikan dengan panah dari x ke y, dengan x sebagai titik awal dan y sebagai titik akhir. Dikatakan juga bahwa simpul x dan simpul y adalah adjacent (bertetangga). X disebut sebagai parent dari y, dan y disebut sebagai child dari x. Dengan menggunakan konsep parent dan child secara rekursif, maka dapat dibuat juga konsep ancestor dan descendent. Sebuah simpul yang tidak memiliki parent disebut dengan root.
Definisi L.2. Pada learning Bayesian network, perlu untuk menemukan sebuah path yang menghubungkan dua simpul tanpa mempertimbangkan arah dari busur‐busur pada path. Untuk membedakannya dengan path berarah (directed path) yang menghubungan dua simpul dengan busur‐busur satu arah, maka path tersebut dikatakan sebagai adjacency path atau chain. Definisi ini bisa digunakan juga untuk graf berarah, graf tidak berarah, dan graf campuran. Chain dinyatakan dengan memperlihatkan garis tak berarah di antara simpul‐ simpul dalam chain. Sebagai contoh misalkan chain [G,A,B,C] dinotasikan dengan G⎯A⎯B⎯C. Jika memperhatikan arah dari edge, maka harus digunakan panah. Misalnya untuk memperlihatkan arah dari chain tersebut, dinyatakan dengan G←A→B→C.
Definisi L.3. Sebuah Directed Acyclic Graph (DAG) adalah graf berarah yang tidak mengandung siklus. Struktur BN dspat digambarkan dengan graf berarah tanpa siklus atau lebih dikenal dengan sebutan directed acyclic graph (DAG).
Definisi L.4. Untuk setiap simpul pada adjacency path, jika dua busur pada suatu path dengan titik akhirnya bertemu pada sebuah simpul v, maka v disebut sebagai simpul yang collider karena kedua panah ‘bertemu’ bertemu pada simpul v. Simpul yang bukan merupakan collider disebut dengan non‐collider. Konsep collider dan non‐collider hanya mengacu pada suatu path tertentu saja, sehingga sebuah simpul bisa saja sebagai collider pada suatu path dan sekaligus sebagai non‐collider pada path lainnya.
Sebuah chain yang mengandung dua simpul seperti X-Y disebut sebagai link. Link berarah seperti X→Y merepresentaiskan sebuah busur (edge). Diberikan busur X→Y maka simpul X disebut sebagai tail dari busur, dan simpul Y disebut sebagai head dari busur. Dengan menentukan tail dan head dari suatu busur, maka bisa diturunkan beberapa kesimpulan sebagai berikut:
i. Sebuah chain X→Z→Y adalah sebuah head-to-tail meeting, kedua busur bertemu head-to-tail pada Z, dan Z adalah sebuah simpul head-to-tail pada chain.
ii. Sebuah chain X←Z→Y adalah sebuah simpul tail-to-tail meeting, kedua busur bertemu tail-to-tail pada Z, dan Z adalah sebuah simpul tail-to-tail pada chain. iii. Sebuah chain X→Z←Y adalah sebuah head-to-tail meeting, kedua busur
bertemu head-to-head pada Z, dan Z adalah sebuah simpul head-to-head pada chain.
iv. Sebuah chain X⎯Z⎯Y, dan dalam hal ini X dan Y tidak adjecent, maka disebut uncoupled meeting.
Definisi L.5. Diberikan U = {A,B,...} sebagai himpunan terbatas dari variabel dengan nilai diskrit. Diberikan P(.) sebagai sebuah fungsi joint probability terhadap variable U, dan diberikan X, Y, dan Z sebagai tiga himpunan bagian dari variabel pada U. X dan Y dikatakan conditionally independent diberikan Z jika P(x|y,z)=P(x|z) bila P(y,z)>0. X dan Y juga dikatakan independent conditional pada Z
Definisi L.6. Cut‐set dari graf terhubung G adalah himpunan busur yang bila dibuang dari G menyebabkan G tidak terhubung. Jadi cut‐set selalu menghasilkan dua buah komponen [DEO74].
Sebagai contoh, pada gambar , himpunan pasangan simpul {(A,B),(A,E),(C,E),(C,D)} adalah cut-set. Terdapat banyak cut-set dalam sebuah graf terhubung. Himpunan {(A,B),(B,E)} adalah cut-set, {(A,C),(B,E),(A,B)} adalah cut set, {(B,F)} adalah cut set. Tetapi {(A,B),(B,E),(D,E)} bukan cut set sebab himpunan bagiannya yaitu {(A,B),(B,E)} adalah cut-set.
B
A
C
D
F
E
Gambar L.1. Cut set
A.2. Kondisi Markov
Kondisi Markov merupakan hubungan antara DAG dengan distribusi probabilitas [NEA04]. BN memanfaatkan kondisi Markov untuk merepresentatikan JPD secara efisien. Misalkan P adalah JPD dari variabel acak himpunan V, dan G=(V,E) adalah sebuah DAG. (G,P) disebut sebuah BN jika (G,P) memenuhi kondisi Markov [NEA04].
Definisi L.7. Misalkan diberikan JPD P dari variabel acak dalam himpunan V dan sebuah DAG G=(V,E). (G,P) dikatakan memenuhi kondisi Markov jika untuk setiap bariabel V, {X} bebas kondisional terhadap himpunan semua nondescendant X jika diketahui himpunan semua parent dari X. Jika himpunan parent dan himpunan nondescendant dari X dinotasikan dengan PAX dan NDX maka [NEA04]
IP({X},NDX|PAX)
Sebagai contoh diberikan gambar berikut:
Gambar L.2. Sebuah DAG untuk mengilustrasikan kondisi Markov [NEA04]
Jika (G,P) memenuhi kondisi Markov untuk JPD P, maka akan dimiliki kebebasan kondisional seperti pada gambar berikut.
PA PA Kebebasan Kondisional
C {L} IP({C},{H,B,F}|{L})
B {H} IP({B},{L,C }|{H})
FA {B,L} IP({F},{H,C}|{B,L})
L {H} IP({L},{B}|{H})
Gambar L.3. Kebebasan kondisional dari DAG pada gambar lampiran 2
Berdasarkan kondisi Markov, dapat dinyatakan teorema untuk merepresentasikan JPD
Teorema L.1. Jika (G,P) memenuhi kondisi Markov, maka P sama dengan perkalain dari distribusi kondisional dari semua simpul jika diketahui nilai dari parent mereka, bilamana distribusi kondisional ini ada [NEA04].
Teorema tersebut menjadi dasar cara BN merepresentasikan JPD. Jika DAG pada gambar tersebut adalah BN, maka untuk semua nilai dari f,c,b,l, dan h
Cara mengkonstruksi BN adalah dengan menentukan sebuah DAG (konstruksi struktur) dan distribusi kondisional (estimasi parameter).
Jika (G,P) memenuhi kondisi Markov, maka setiap simpul dalam G bebas kondisional terhadap himpunan semua nondescendant jika diketahui parent. Selain hubungan kebebasan kondisional jika diketahui parent dari simpul, dapat juga diperoleh hubungan kebebasan kondisional lain.
Berikut diberikan contoh.
Gambar L.4. IP({D},{A|B}) dapat diperoleh dari kondisi Markov [NEA04]
Pada DAG gambar tersebut, berdasarkan kondisi Markov diketahui IP({D},{A,B}|{C})
dan IP({C},{A}|{B}). Selain itu dapat juga diperoleh kebebasan kondisional lain yaitu
IP({D},{A}|{B}). P(d|a,b) =
∑
cb
a
c
d
P
(
,
|
,
)
{distribusi probabilitas marginal}=
∑
cb
a
c
P
b
a
c
d
P
(
|
,
,
)
(
|
,
)
{chain rule} =∑
cb
c
P
b
c
d
P
(
|
,
)
(
|
)
{kebebasan kondisional} =∑
cb
c
d
P
(
,
|
)
{chain rule}= P(d|b) {distribusi probabilitas marginal} Dikatakan bahwa B memblok atau menutup kebergantungan antara A dan D.
A.2.1.
Kondisi Faithfulness dan Monotone Faithfulness
Dari kondisi Markov, hanya dapat diperoleh kebebasan tetapi tidak dapat diperoleh kebergantungan. Kondisi Markov hanya menunjukkan bahwa tidak adanya egde berarti ada kebebasan kondisional, namun adanya busur tidak berarti bahwa tidak ada kebebasan kondisional. Agar tidak adanya busur mempunya arti tidak ada kebebasan kondisional atau ada kebergantungan langsung, maka harus dipenuhi kondisi faithfulness [NEA04].
Definisi L.8. Misalkan dimiliki sebuah JPD dari variabel acak dalam himpunan V dan sebuah DAG G=(V,E). (G,P) dikatakan memenuhi kondisi faithfulness jika berdasarkan kondisi Markov, G mengandung semua dan hanya kebebasan kndisional pada P. Yaitu jika dipenuhi kedua kondisi berikut [NEA04]:
1. (G,P) memenuhi kondisi Markov (artinya G mengandung hanya kebebasan kondisional pada P).
2. Semua kebebasan kondisional pada P ada pada G, berdasarkan kondisi Markov.
Jika (G,P) memenuhi kondisi faithfulness, P dan G disebut saling faithful, dan G disebut perfect map dari P.
Teorema L.2. Misalkan dimiliki sebuah JPD P dari variabel acak dalam himpunan V dan sebuah DAG G=(V,E). (G,P) memenuhi kndisi faithfulness jika dan hanya jika semua dan hanya kebebasan kondisional pada P yang teridentifikasi oleh d‐separation pada G.
Teorema berikut menyatakan akibat bahwa jika P faithful terhadap beberapa DAG, maka P faithful terhadap kelas ekuivalen dari DAG-DAG tersebut.
Teorema L.3. Jika (G,P) memenuhi kondisi faithfulness, maka P memnuhi kondisi ini dengan semua dan hanya DAG yang ekuivalen Markov terhadap G. Selanjutnya, jika gp adalah DAG pattern yang sesuai dengan kelas ekuivalen Markov ini, d‐separation dalam gp mengidentifikasi semua dan hanya kebebasan kondisional pada P. Gp dan P dikatakan saling faithful, dan gp adalah perfect map dari P.
Distribusi P dikatakan berlaku untuk sebuah representasi DAG faithful (admit a faithful DAG representation) jika P faithful terhadap beberapa DAG (dan oleh karena
itu terhadap sebuah DAG pattern). Jika P berlaku untuk sebuah representasi DAG faithful, maka ada sebuah DAG pattern unik yang dalam hal ini P faithful. Untuk mengkonstruksi BN, maka yang akan ditemukan terlebih dahuulu adalah DAG pattern dimana P berlaku untuk sebuah representasi DAG faithful.
Contoh distribusi probabilitas yang berlaku untuk sebuah representasi DAG faithful adalah: distribusi probabilitas P dari variabel acak X, Y, dan Z hanya memiliki kebebasan kondisional IP({X}{Z}|{Y}).
Gambar L.5. Distribusi probabilitas yang hanya memiliki IP({X},{Z}|{Y}) faithful terhadap DAG pattern ini
Contoh distribusi probabilitas yang tidak berlaku untuk sebuah representasi DAG faithful adalah: distribusi probabilitas P dari variabel acak X, Y, dan Z memiliki kebebasan kondisional IP({X}{Z}) dan IP({X}{Z}|{Y}). Dengan mengambil
IP({X}{Z}) maka pada DAG, simpul Y merupakan simpul head-to-head pada chain
X-Y-Z. Namun dengan mengambil IP({X}{Z}|{Y}) maka pada DAG, simpul Y
bukan merupakan simpul head-to-head pada chain X-Y-Z. Jadi kedua kebebasan tersebut tidak dapat direpresentasikan pada DAG.
Sebagaimana telah dinyatakan sebelumnya, bahwa dalam keadaan faithfulness, sebuah busur diantara dua simpul mempunyai arti ada kebergantungan langsung di antara kedua simpul tersebut, sesuai dengan teorema berikut.
Teorema L.4. Misalkan dimiliki sebuah distribusi probabilitas gabungan dari P dari variabel acak dalam himpunan V dan sebuah DAG G=(V,E). Maka jika P berlaku untuk sebuah representasi DAG faithful, gp adalah DAG pattern yang faithful terhadap P jika dan hanya jika dipenuhi kedua kondisi berikut [NEA04]:
1. X dan Y adjacent dalam gp jika dan hanya jika tidak ada subset S V yang dalam hal ini IP({X}{Y}|S). Yakni, X dan Y adjacent jika dan hanya jika ada kebergantungan langsung antara X dan Y.
2. X‐Z‐Y adalah sebuah head‐to‐head meeting dalam gp jika dan hanya jika Z S mengimplementasikan ¬IP({X}{Y}|S).
Beberapa model DAG dapat berupa DAG faithful atau berupa monotone DAG faithful. Untuk menjelaskan hubungan antara DAG faithful dan monotone DAG faithful, berikut ini diberikan sebuah model probabilistik [CHE].
Gambar L.6. DAG faithful
Pada graf tersebut, diberikan struktur BN yang lengkap, yang tersusun oleh struktur DAG dan empat tabel CP untuk empat simpul. Dengan menggunakan persamaan (II.2) maka dapat ditentukan mutual information dari pasangan simpul dari tabel CP. Dengan menggunakan nilai pada CP tabel dapat ditentukan mutual information antara simpul B dan simpul C, sehingga didapat I(A,C|A,D)=0,0A8 dan I(B,C|D)=0. Hal ini jelas sebuah kontradiksi dengan keadaan yang seharusnya, sebab dengan menggunakan {A,D} sebagai condition-set, akan berakibat pada terbentuknya sebuah open path B-D-C. Sedangkan jika menggunakan {D} sebagai condition-set, akan berakibat pada terbentuknya dua open path yaitu B-D-C dan B-A-C.
Jika model tersebut termasuk pada jenis monotone DAG-faithful, I(B,C|D) seharusnya bernilai lebih besar dari I(B,C|A,D). Sebagai catatan, model tersebut bahkan bukanlah sebuah DAG-faithful karena kebebasan antara B dan C jika diketahui {D} tidak bisa diekspesikan oleh struktur DAG. Namun jika dilakukan sedikit perubahan pada parameter CP tabel, sebagai contohnya, nilai CP tabel untuk simpul C diubah menjadi sama dengan nilai CP tabel untuk simpul B, maka akan dihasilkan nilai I((B,C|D)
lebih besar dari 0 tetapi masih tetap bernilai lebih kecil dari I(B,C|A,D). Sekarang akan didapatkan model yang merupakan DAG-faithful, karena B dan C tidak bebas jika diketahui {D}, tetap bukan model yang monontone DAG-faithful.
Dari penjelasan di atas bisa ditarik dua kesimpulan. Pertama, ada beberapa model yang meupakan DAG-faithful, namun bukan monotone DAG-faithful. Kedua, perbedaan antara model DAG-faithful dan monotone DAG-faithful tidak hitam putih. Pada contoh di atas, jika seandainya nilai I(B,C|D) lebih besar dari pada nilai threshold maka model akan menjadi faithful, dan sebaliknya bukanlah DAG-faithful. Hal ini menunjukkan adanya daerah ‘kabur’
LAMPIRAN B
ALGORITMA TPDA
∏
Berikut ini adalah penejesalan algortima TPDA ∏ yang lengkap. Penjelasan mengacu kepada [CHE01].
B.1. Algoritma TPDA
∏
Penjelasan diberikan berdasarkan gambar berikut.
(d) (c) (b) (a) C B E D A C B E D A C B E D A C B E D A
Gambar L.7. Skema pembentukan struktur BN dengan TPDA ∏
Fase I: Drafting
1. Inisiasi graf G(V,E) dalam hal ini V={seluruh atribut dari data set}, E={}. Inisiasi sebuah list kosong L.
2. Untuk setiap pasang simpul (vi,vj) dalam hal ini vi,vj ∈ V dan i ≠ j , hitung mutual
information I(vi,vj) dengan menggunakan equation (A). Terhadap seluruh pasang
simpul dengan mutual information lebih besar dari sebuah nilai tertentu yang kecil yaitu ε, urutkan seluruh simpul tersebut dari besar ke kecil berdasarkan nilai mutual information, kemudian simpan pasangan simpul tersebut pada list L. Buat sebuah pointer p yang menunjuk pada pasangan simpul yang pertama pada L. 3. Ambil dua pasang simpul yang pertama dari list L dan buang dari list L.
berikutnya. (Pada algoritma tersebut, arah dari busur ditentukan oleh urutan simpul).
4. Ambil pasangan simpul dari L yang ditunjuk oleh pointer p. Jika tidak ada lintasan terbuka (open path) antara kedua simpul tersebut, tambahkan busur yang berkorespondensi ke E, dan buang pasangan simpul tersebut dari L (open path adalah adjacency path yang dalam hal ini seluruh simpul adalah aktif).
5. Pindahkan pointer p ke pasangan simpul berikutnya, lalu kembali ke langkah 4 kecuali jika p menunjuk pada akhir list L.
Fase II: Thickening
6. Pindahkan pointer p ke pasangan simpul yang pertama yang ada pada list L. 7. Ambil pasangan simpul (simpul1, simpul2) dari L pada posisi yang ditunjuk oleh
pointer p. Panggil prosedur find_cut_set(current graph, simpul1, simpul2) untuk menemukan sebuah cut set yang dapat membuat simpul1 dan simpul2 menjadi d-separated pada graf terkini. Gunakan CI test untuk memeriksa apakah simpul1 dan simpul2 adalah bebas kondisional jika diketahui cut-set. Jika benar, lanjutkan ke langkah 8. Jika salah, hubungkan pasangan simpul dengan cara menambahkan sebuah busur ke E.
8. Pindahkan pointer p ke pasangan simpul berikutnya dan kembali ke langkah 7 dengan syarat p tidak menunjuk ke akhir L.
Pada fase I, masih ada beberapa pasang simpul pada L hanya karena sudah terdapat lintasan terbuka di antara pasangan simpul tersebut. Pada fase II, digunakan CI test dan d-separation untuk memeriksa apakah pasangan simpul tersebut seharusnya terhubung atau tidak. Karena hanya ada satu CI test yang digunakan untuk memeriksa keterhubungan tersebut, maka tidak bisa dipastikan apakah keterhubungan tersebut adalah benar-benar perlu, tetapi bisa dipastikan bahwa tidak akan ada lagi busur yang hilang pada akhir fase II tersebut.
Pada fase II algoritma memeriksa seluruh pasangan simpul yang tersisa pada L, yaitu pasangan simpul yang memiliki mutual information lebih besar dari ε dan tidak terhubung langsung. Dengan setiap pasangan simpul pada L, algoritma pertama sekali akan menggunakan prosedur find_cut_set untuk mendapatkan sebuah cut-set yang
dapat membuat dua simpul d-separated lalu menggunakan CI test untuk memeriksa apakah dua simpul adalah bebas kondisional jika diketahui cut-set. Prosedur find_cut_set mencoba untuk menemukan minimum cut-set (cut-set dengan jumlah simpul paling sedikit) dengan menggunakan metode heuristik. Hal ini dilakukan karena condition-set dengan ukuran yang kecil dapat mengakibatkan CI test lebih handal dan efisien. Setelah dilakukan CI test, sebuah busur ditambahkan jika dua simpul tidak bebas kondisional. Pada fase ini juga ada kemungkinan terjadinya wrongly added arc (busur yang seharusnya tidak muncul, namun ditambahkan) , karena bebarapa busur yang seharusnya ada namun kemungkinan masih belum ada sampai berakhirnya fase ini, dan dengan adanya missing arc tersebut dapat mencegah ditemukannya cut-set yang tepat. Karena satu-satunya penyebab gagalnya menambahkan sebuah busur adalah karena simpul tersebut bebas, pada fase II tidak terjadi kehilangan busur dari model yang sesungguhnya, jika model tersebut adalah DAG-faithful.
Pada contoh, graf setelah fase II ditunjukkan pada gambar (7.c). Busur(D,E) ditambahkan sebab D dan E tidak bebas kondisional pada {B}, yang merupakan cut-set terkecil antara simpul D dan E pada graf terkini. Busur (A,C) tidak ditambahkan karena hasil CI test mengindikasikan bahwa A dan C adalah bebas jika diketahui cut-set {B}. Busur (A,D), (C,D), dan (A,E) tidak ditambahkan karena alasan yang sama. Pada gambar (7.c) terlihat bahwa graf yang dihasilkan setelah fase II berisikan semua busur dari model yang sesungguhnya, yaitu merupakan sebuah I-map dari model yang sesungguhnya.
Fase III: Thinning
9. Untuk setiap busur (simpul1, simpul2) pada E, jika ditemukan adanya lintasan lain selain busur tersebut di antara kedua simpul, buang sementara busur tersebut dari E dan panggil prosedur find_cut_set(current graph, simpul1, simpul2) untuk menemukan cut-set yang bisa menyebabkan simpul1 dan simpul2 d-separated pada graf terkini. Gunakan CI test untuk memeriksa apakah simpul1 dan simpul2 adalah bebas kondisional jika diketahui cut-set. Jika benar, buang busur tersebut secara permanen dari E, sebaliknya jika salah tambahkan busur tersebut kembali ke E.
Seperti telah dijelaskan bahwa pada fase I dan fase II ada kemungkinan ditemukan wrongly added arc, maka pada fase III ini yang dilakukan adalah memastikan adanya busur yang wrongly added dan selanjutnya membuang busur tersebut. Sama seperti fase II, hanya ada satu CI test yang dilakukan untuk memastikannya, namun pada fase ini keputusan yang telah dilakukan adalah benar. Alasannya adalah bahwa graf terkini adalah sebuah I-map dari model yang sesungguhnya, yang tidak ditemukan hingga pada akhir fase II. Pada fase III busur yang wrongly added berhasil dibuang, sehingga pada akhir fase ini graf yang dihasilkan adalah graf yang sesungguhnya [CHE97].
Pada fase ini, algoritma pertama sekali mencoba menemukan busur yang menghubungkan satu pasangan simpul yang juga dihubungkan oleh lintasan lainnya. Hal ini juga berarti bahwa tidak mungkin ada kebebasan antara pasangan simpul tersebut karena adanya busur berarah di di antara kedua simpul tersebut. Selanjutnya algoritma membuang busur tersebut dan menggunakan prosedur find_cut_set untuk menemukan sebuah cut_set. Setelah itu, CI test digunakan untuk memeriksa apakah kedua simpul tersebut bebas kondisional pada cut-set. Jika benar, busur tersebut akan dibuang secara permanen, dan sebalikanya jika tidak busur tersebut akan ditambahkan kembali karena ternyata cut-set tidak bisa memblok aliran informasi yang mengalir di antara ke dua simpul tersebut. Prosedur ini terus dikerjakan hingga semua pasangan simpul selesai diperiksa.
Graf yang dihasilkan pada akhir fase III ditunjukkan pada gambar (7.d), yang merupakan struktur sesungguhnya dari graf. Busur (B,E) dibuang karena B dan E adalah bebas kondisional jika diketahui {C,D}. Pada akhir fase ini, struktur BN yang benar berhasil dikonstruksi.
B.2. Menentukan Minimum Cut Set
Pada fase II dan fase III diperlukan prosedur find_cut_set(current_graph, simpul1, simpul2) untuk menentukan cut-set di antara dua simpul, dan kemudian menggunakan cut-set tersebut sebagai himpunan kondisi saat melakukan CI test untuk menguji kebebasan kondisional antara simpul1 dan simpul2. Pada saat digunakan, prosedur cut-set akan selalu memeriksa graf terkini.
Penggunaan cut-set sebagai condition-sets pada CI test berdampak pada berkurangnya kardinalitas dari cut-set, dan mengakibatkan berkurangnya jumlah CI test yang harus dilakukan. Dari persamaan (2) dapat dilihat bahwa banyaknya penggunaan CI test akan menyebabkan mahalnya proses komputasi dan akan menjadi tidak akurat jika data yang diproses tidak cukup besar. Hal inilah yang menjadi alasan perlunya dilakukannya proses pencarian minimum cut-set.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
procedure find_cut_set(current_graph, nodeA, node2)
begin
Find all the adjacency paths between nodeA and node2;
Store the open paths in open-path-set, store the closed paths in closed-path-set;
do
while (there are open paths that have only one node) do
Store the nodes of each such path in the cut-set; Remove all the blocked paths by these nodes from the open-path-set and closed-path-set;
From the closed-path-set, find paths opened by the nodes in block set and move them to the open-path-set, shorten such paths by removing the nodes that are also in the cut-set;
end while
if (there are open paths) do
Find a node that can block the maximum number of the remaining paths and put it in the cut-set;
Remove all the blocked paths by the node from the open-path-set and the closed-path-set;
From the closed-path-set, find paths opened by this node and move them to the open-path-set, shorten such paths by removing the nodes that are also in the cut-set;
end if
until (there is no open path)
end procedure
Gambar L.8. Algoritma minimum cut-set
Pada saat dijalankan prosedur find_cut_set(current_graph, simpulA, simpul2) pertama sekali akan mencari adjacency path antara simpul dan simpul2, dan menempatkan path-path tersebut kedalam dua kelompok himpunan yaitu open-path-set dan closed-path-set. Lalu setiap non-collider yang terhubung pada simpul dan simpul2 disimpan kedalam cut set, karena mereka digolongkan ke pada cut set yang valid. Sesudah itu, digunakan metode heuristic secara berulang untuk menemukan simpul yang dapat
memblok sejumlah maksimum path dan menyimpannya kedalam cut set, sampai semua lintasan terbuka diblok.
LAMPIRAN C
SEQUENTIAL PATTERN MINING
Sequential pattern mining adalah proses menganalisis data untuk menemukan pola urutan waktu terjadinya peristiwa. Dalam market basket analysis, data yang dianalisis adalah data transaksi belanja yang dilakukan oleh seluruh pelanggan, untuk menemukan pola belanja. Pola yang ditemukan selanjutnya bisa dimanfaatkan lebih lanjut dan digunakan untuk strategi penjualan seperti promosi produk, penempatan produk dalam rak, dan pembuatan katalog produk.
Sequential pattern mining diperkenalkan pertama kali oleh Rakesh Agrawal dan Ramakrishnan Srikant pada tahun 1995 [AGR00], berdasarkan sebuah penelitian terhadap data transaksi belanja yang dilakukan oleh pelanggan.
Definisi L.9. Diberikan himpunan dari sequence, yang setiap sequence berisi sebuah list elemen dan setiap elemen berisi himpunan item, dan diberikan juga spesifikasi user untuk nilai min_sup, sequential pattern mining akan menemukan semua subsequences yang frequent, yaitu subsequences yang frekuensi kejadiannya tidak kurang dari min_ sup [HAN06].
Beberapa contoh yang ada pada sequetial pattern dengan mengekstrasi pola pembelian yang sequential, adalah [AGR00]:
b. 60% pelanggan biasanya menyewa film “Star Wars”, kemudian “Empire Strikes Back” dan kemudian “Return of The Jedi” (penyewaan tidak harus berurutan). c. (Satu elemen dari sequence dapat memiliki beberapa item), 60% dari pelanggan
membeli “fitted sheet dan flat sheet dan pillow”, diikuti oleh “comforter”, diikuti oleh “drapes dan ruffles” (elemen dari sequential pattern tidak harus suatu item sederhana).
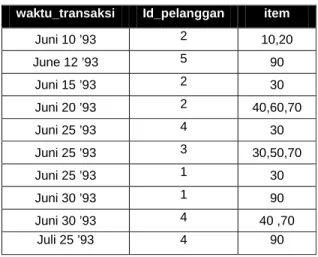
Diberikan sebuah basis data D yang berisikan transaksi pelanggan. Masing-masing transaksi terdiri dari field berikut yaitu: id_pelanggan, waktu_transaksi, dan item, dan ketiga field tersebut menerangkan transaksi yang terjadi. Agar lebih jelas, diberikan contoh berikut:
waktu_transaksi Id_pelanggan item
Juni 10 ’93 2 10,20 June 12 ’93 5 90 Juni 15 ’93 2 30 Juni 20 ’93 2 40,60,70 Juni 25 ’93 4 30 Juni 25 ’93 3 30,50,70 Juni 25 ’93 1 30 Juni 30 ’93 1 90 Juni 30 ’93 4 40 ,70 Juli 25 ’93 4 90
Gambar L.9. Basis data transaksi pelanggan yang asli
Sebagai batasan, tidak ada pelanggan yang melakukan lebih dari satu transaksi dengan waktu_transaksi yang sama, dan juga tidak diperhitungkan kuantitas item yang dibeli pada saat transaksi karena setiap item adalah variabel biner yang merepresentasikan item dibeli atau tidak (boolean association rule). Mengani boolean assciation rule dijelaskan pada lampiran.
Masalah utama dari mining sequential pattern adalah untuk menemukan maximal sequences diantara semua sequence-sequence yang memenuhi min_sup, dengan nilai min_sup dispesifikasikan oleh pengguna. Setiap maximal sequence direpresentasikan sebagai sequential pattern. Sequence yang memenuhi min_sup disebut large sequence.
C.1. Algoritma Sequential Pattern
Secara umum, pada algoritma sequential pattern mining dikembangkan oleh Rakesh dan Agrawal, terdapat lima fase, yaitu : i) sort phase, ii) litemset phase, iii) transformation phase, iv) sequence phase, dan v) maximal phase [AGR00]. Pada bagian berikut akan dijelaskan masing-masing fase tersebut.
Fase A : Sort Phase
Fase ini secara lengkap mengubah basis data transaksi pelanggan yang asli menjadi basis data sequence pelanggan. Data yang terdapat pada basis data D pada gambar L.9 diurutkan berdasarkan id_pelanggan sebagai major key dan waktu_transaksi sebagai minor key. Sehingga dapat ditunjukkan dengan basis data gambar yang diberikan berikut:
id_pelanggan waktu_transaksi item
1 1 29 Juni ‘93 30 Juni ‘93 30 90 2 2 2 10 Juni ‘93 15 Juni ‘93 20 Juni ‘93 10,20 30 40,60,70 3 25 Juni ‘93 30,50,70 4 4 4 25 Juni ‘93 30 Juni ‘93 25 Juli ‘93 30 40,70 90 5 12 Juni ‘93 90
Gambar L.10. Basis data yang diurutkan berdasarkan id_pelanggan dan waktu_transaks
Selanjutnya data pada gambar tersebut diubah menjadi sequence pelanggan yang merupakan hasil akhir dari tahap ini. Agar lebih jelas, contoh basis data sequence pelanggan diberikan pada gambar berikut:
id_pelanggan sequence pelanggan
1 〈(30) (90)〉
2 〈(10,20) (30) (40,60,70)〉 3 〈(30,50,70)〉
4 〈(30) (40,70) (90)〉
5 〈(90)〉
Gambar L.11. Basis data sequence pelanggan
Fase 2 : Litemset Phase
Fase ini adalah untuk menemukan himpunan dari semua litemset L (large itemset yang merupakan itemset yang memenuhi min_sup) dan juga menemukan himpunan dari semua large 1-sequence.
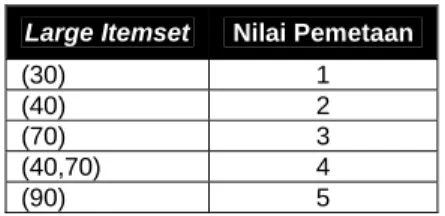
Himpunan dari litemset dipetakan ke bilangan integer yang saling berkelanjutan. Pada contoh basis data yang telah diberikan seperti pada gambar L.12, dengan nilai min_sup adalah 25% atau sama dengan 2 itemset, maka yang merupakan large itemset
adalah (30), (40), (70), (40 70), dan (90). Hasil pemetaan yang mungkin untuk himpunan ini dapat ditunjukkan dalam:
Large Itemset Nilai Pemetaan
(30) 1 (40) 2 (70) 3 (40,70) 4 (90) 5
Gambar L.12. Large itemset
Alasan dari pemetaan ini adalah agar litemset diperlakukan sebagai entitas tunggal, sehingga dapat dibandingkan secara bersamaan dua litemset dalam waktu yang konstan dan mengurangi waktu yang digunakan untuk memeriksa apakah suatu sequence terdapat dalam basis data sequence pelanggan.
Fase 3 : Transform Phase
Dalam pengubahan sequence pelanggan, tiap transaksi digantikan oleh himpunan dari semua litemset yang terdapat dari transaksi itu sendiri. Jika transaksi tidak berisi litemset maka tidak disimpan dalam transformed sequence. Jika suatu sequence pelanggan tidak memiliki litemset, maka sequence tersebut dibuang dari transformed database. Tetapi sequence itu masih berguna untuk menghitung jumlah pelanggan. Sequence pelanggan sekarang direpresentasikan oleh list dari himpunan litemset. Setiap himpunan litemset di representasikan oleh {lA, l2, ..,ln}, yang dalam hal ini li
adalah suatu litemset.
Basis data yang telah ditransformasikan ini disebut DT. Basis data DT dapat saja
dibuat secara fisik atau on-the-fly pada saat dilakukan pembacaan sequence pelanggan. Pada percobaan ini basis data DT diimplementasikan secara fisik. Basis
id_pelanggan Sequence Asli Transformed Sequence
Pelanggan Setelah Pemetaan
1 〈 (30) (90) 〉 〈 {(30)} {(90)} 〉 〈 {1} {5} 〉
2 〈 (10,20) (30) (40,60,70) 〉 〈 {(30)} {(40) (70) (40,70)} 〉 〈 {1} {2, 3, 4} 〉
3 〈 (30,50,70) 〉 〈 {(30) (70)} 〉 〈 {1, 3} 〉
4 〈 (30) (40,70) (90) 〉 〈 {(30)} {(40) (70) (40,70)} {(90)} 〉 〈 {1} {2, 3, 4} {5} 〉
5 〈 (90) 〉 〈 {(90)} 〉 〈 {5} 〉
Gambar L.13. Basis data yang telah ditransformasi
Sebagai contoh, selama pengubahan sequence pelanggan dengan id_pelanggan = 2, maka transaksi (10 20) dibuang karena tidak berisi litemset dan transaksi (40 60 70) digantikan oleh himpunan dari litemset {(40), (70), (40 70)}.
Fase 4 : Sequence Phase
Dalam Sequence Phase, himpunan litemset dapat digunakan untuk menemukan sequence yang diinginkan dengan membuat multiple pass dari suatu data. Dalam setiap proses, dimulai dengan menemukan himpunan elemen digunakan untuk membangkitkan large sequence potensial, yang disebut kandidat sequences. Support untuk kandidat sequence ditemukan dalam pemrosesan data, akhir dari proses yaitu dengan menentukan kandidat sequence yang large yang akan menjadi himpunan elemen untuk proses selanjutnya dan kemudian mengeliminasi kandidat sequence yang tidak large. Pada proses awal, semua 1-sequence dengan min_sup diperoleh dari litemset phase, bentuk dari himpunan elemen.
Pada tahap ini digunakan algoritma khusus untuk menemukan sequence. Tipe algoritma dan contohnya dijelaskan pada bagian lampiran.
Tahap 5 : Maximal Phase
Maximal phase adalah tahap menemukan maximal sequences diantara himpunan large sequences. Tahap ini dikombinasikan dengan sequence phase untuk mengurangi waktu yang terbuang dalam menghitung non-maximal sequence.
Setelah menemukan himpunan dari semua large sequence S dalam sequence phase. Algoritma di bawah ini dapat digunakan untuk menemukan maximal sequence, panjang dari sequence yang terpanjang adalah n, kemudian :
A 2 3 4 5 for (k=n;k>1;k--) do foreach k-sequence sk do
DELETE FROM S all subsequences of sk end foreach
end for
Gambar L.14. Menentukan maximal sequence
Dengan min_sup = 25%, yakni minimum support untuk 2 pelanggan, maka dua sequence berikut yaitu 〈(30) (90)〉 dan 〈(30) (40 70)〉 adalah maximal diantara sequence yang memenuhi min_sup, dan merupakan hasil akhir sequential pattern yang diinginkan. Hasil dari sequential pattern diperlihatkan pada gambar berikut :
Sequential pattern dengan support > 25%
〈 (30) (90) 〉 〈 (30) (40 70) 〉
Gambar L.15. Hasi dari sequential pattern mining
Sequential pattern 〈(30) (90)〉 didukung oleh pelanggan 1 dan 4, seperti yang ditunjukkan pada gambar L.11. Pelanggan dengan id_pelanggan = 4 membeli item (40,70) diantara item 30 dan 90, namun juga mendukung pola 〈(30) (90)〉 karena pola yang dicari tidak perlu harus pada item yang berdampingan. Sequential pattern 〈(30) (40 70)〉 didukung oleh pelanggan 2 dan 4. pelanggan 2 membeli 60 bersama 40 dan 70, namun juga mendukung pola tersebut karena (40 70) adalah merupakan subset dari pola (40 60 70).
Pada contoh hasil tersebut, sequence yang tidak memenuhi min_sup adalah 〈(10,20) (30)〉. Sequence 〈(10 20) (30)〉 hanya didukung oleh pelanggan 2 dan tidak memenuhi minimum support. Kemudian sequence 〈(30)〉, 〈(40)〉, 〈(70)〉, 〈(90〉, 〈(30) (40)〉, 〈(30) (70)〉 dan 〈(40,70)〉, memenuhi minimum support, tetapi tidak maksimal karena terdapat pada pola sequence lainnya. Agar lebih jelas dalam menemukan hasil dari sequential pattern mining, dapat dilihat berdasarkan basis data customer sequence yang ditunjukkan di gambar L.15.
![Gambar L.2. Sebuah DAG untuk mengilustrasikan kondisi Markov [NEA04]](https://thumb-ap.123doks.com/thumbv2/123dok/4216874.3109614/6.918.255.715.662.748/gambar-l-dag-untuk-mengilustrasikan-kondisi-markov-nea.webp)
![Gambar L.4. IP({D},{A|B}) dapat diperoleh dari kondisi Markov [NEA04]](https://thumb-ap.123doks.com/thumbv2/123dok/4216874.3109614/7.918.168.727.711.1023/gambar-l-ip-d-diperoleh-kondisi-markov-nea.webp)