20
Pengolahan Data Awal
Pemodelan
BAB III
METODOLOGI PENELITIAN
3.1. Tahapan Penelitian
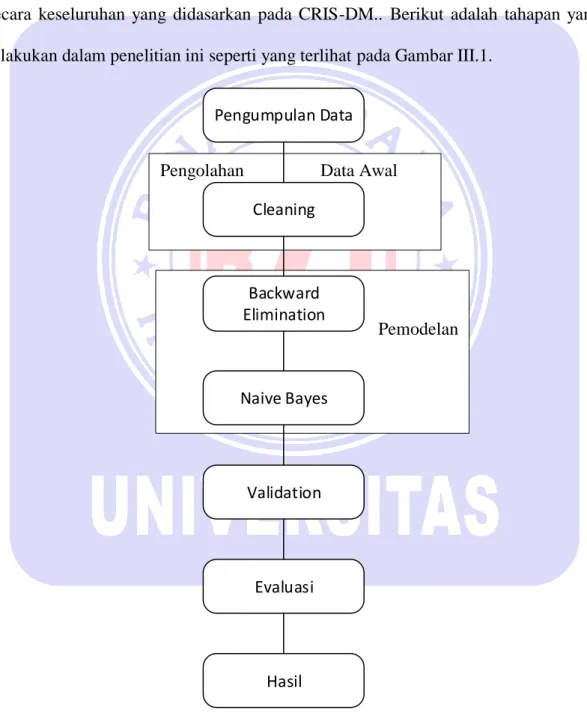
Pada bagian ini, akan disajikan gambaran mengenai metodologi penelitian secara keseluruhan yang didasarkan pada CRIS-DM.. Berikut adalah tahapan yang dilakukan dalam penelitian ini seperti yang terlihat pada Gambar III.1.
Pengumpulan Data Cleaning Backward Elimination Naive Bayes Validation Evaluasi Hasil Sumber : (Rumawati, 2018)
3.2. Instrument Penelitian
Instrument merupakan suatu alat yang dipergunakan sebagai alat untuk mengukur suatu obyek ukur atau mengumpulkan data dari suatu variable. Berdasarkan permasalahan yang telah diuraikan pada bab sebelumnya, maka bahan dan peralatan yang diperlukan untuk penelitian ini meliputi :
a . Bahan
Sumber data- data yang digunakan dalam penelitian ini merupakan data sekunder yang diperoleh dari Website PIKOBAR .
b. Peralatan
Peralatan dalam penelitian ini meliputi kebutuhan perangkat lunak dan kebutuhan perangkat keras. Dibawah ini merupakan kebutuhan dari sistem, diantaranya:
Table III.1. Spesifikasi Perangkat Lunak dan Perangkat Keras
Sumber : (Hamzah, 2020)
3.3. Metode Pengumpulan Data
Metode pengumupulan data, populasi dan sampel penelitian yang didapatkan sebagai berikut :
A. Pengumpulan Data
Data yang digunakan untuk training data dan testing data pada penelitian ini merupakan data sekunder yang telah dikumpulkan pada Website PIKOBAR. Untuk menguji model klasifikasi yang tepat pada
PERANGKAT LUNAK PERANGKAT KERAS
Microsoft Office Word Professional Plus 2016
Intel® Core ™ i3-2120 CPU @ 3.30 GHz
Microsoft Office Excel Professional
Plus 2016 Memory (RAM) 4 Gb
Sistem operasi Microsoft Windows 10 Hardisk 1 TB RapidMiner Studio 9.6
https://pikobar.jabarprov.go.id/. Dataset tersebut telah dipublikasi dan didokumentasi .
B. Sampel
Sampel digunakan untuk pengujian terhadap model yang dihasilkan atau dapat dikatakan sebagai testing data, sedangkan training data berfungsi sebagai bahan pelatihan suatu model. Data yang didapatkan sekitar 189, yang akan dibagi menjadi dua bagian sebagai training data dan testing data.
C. Populasi
Objek populasi dari penelitian ini adalah data orang yang terjangkit COVID-19, sedangkan subjek dari penelitian ini adalah semua daerah di Jawa Barat yang terjangkit COVID-19. Tujuan diadakan populasi adalah agar dapat menentukan besarnya zona sampel yang diambil. Dalam penelitian ini yang menjadi populasi adalah zona COVID-19 pada daerah yang terjangkit di jawa barat pada bulan April.
3.4. Metode Analisis Data
Zona yang terjangkit COVID-19 di Jawa Barat adalah data sekunder yang sudah siap untuk proses data mining. Metode yang akan diterapkan adalah metode yang belum diterapkan oleh para peneliti yang menggunakan dataset ini sebagai objek penelitian mereka sebelumnya. Metode yang akan digunakan adalah metode Klasifikasi Naive Bayes dan Backward Elimination.
3.4.1. Pengolahan Data Awal
Pada tahap ini, dibutuhkan eksplorasi terhadap data zona yang terjangkit COVID-19 di Jawa Barat. Eksplorasi bertujuan untuk memastikan semua atribut-atribut dan kelas-kelas dalam dataset tersebut valid dan dapat digunakan sebagai
objek penelitian. Sehingga tujuan untuk mengetahui hasil klasifikasi terbaik dari deteksi zona COVID-19 dapat dicapai.
1. Data Cleaning
Pada data zona yang terjangkit COVID-19 di Jawa Barat, dilakukan pemilihan atribut data yang akan digunakan dalam penelitian, maka untuk atribut data yang tidak digunakan seperti nama daerah / kota terdampak akan dihilangkan.
2. Sampling
Data yang diperoleh terdiri dari 189 data record. Untuk menguji model yang dikembangkan, data akan dibagi menjadi dua bagian, yaitu data training dan data testing. Data training digunakan untuk pengembangan model, sedangkan data testing digunakan untuk pengujian model.
Diketahui bahwa jumlah data adalah 189 dengan pembagian 70% digunakan untuk data training dan 30% digunakan untuk data testing, dengan masing-masing menghasilkan jumlah 132 dan 57 data. Hasil eksperimen di spilt validation pembagian 70% dan 30% menghasilkan akurasi yang tinggi di banding hasil akurasi yang lain.
3. Seleksi Fitur
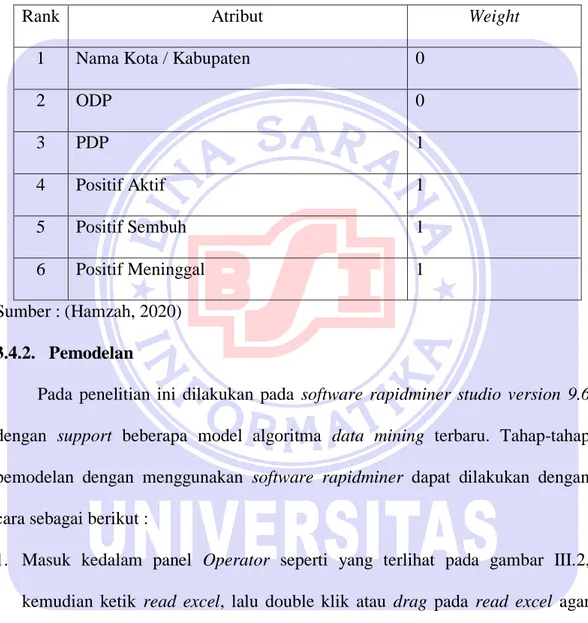
Metode seleksi yang digunakan dalam penelitian ini adalah metode seleksi fitur menggunakan backward elimination. Backward Elimination dilakukan untuk menentukan atribut – atribut yang bermutu dan berpengaruh terhadap dataset. Proses seleksi fitur dilakukan untuk menghasilkan atribut_atribut yang sangat bermutu atau memiliki weight yang paling berpengaruh. Dapat dilihat hasil seleksi fitur dari dataset zona yang terjangkit COVID-19 di Jawa Barat pada tabel yang bernilai 1 menjelaskan bahwa nilai tersebut memiliki weight
yang paling berpengaruh. Dari 6 atribut yang telah terpilih 4 atribut yang dianggap mempengaruhi tingkat akurasi. Berikut contoh hasil atribut weight yang berpengaruh seperti tabel dibawah ini :
Tabel III.2.
Perhitungan Hasil Weight Masing-Masing Atribut
Rank Atribut Weight
1 Nama Kota / Kabupaten 0
2 ODP 0 3 PDP 1 4 Positif Aktif 1 5 Positif Sembuh 1 6 Positif Meninggal 1 Sumber : (Hamzah, 2020) 3.4.2. Pemodelan
Pada penelitian ini dilakukan pada software rapidminer studio version 9.6 dengan support beberapa model algoritma data mining terbaru. Tahap-tahap pemodelan dengan menggunakan software rapidminer dapat dilakukan dengan cara sebagai berikut :
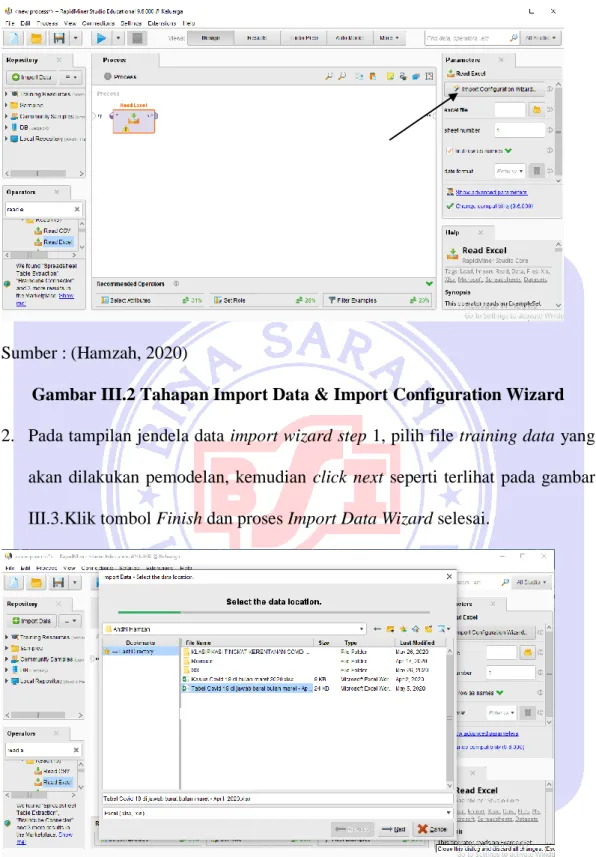
1. Masuk kedalam panel Operator seperti yang terlihat pada gambar III.2, kemudian ketik read excel, lalu double klik atau drag pada read excel agar Operator muncul di panel process. Untuk memasukan datanya klik import configuration wizard pada panel parameters.
Sumber : (Hamzah, 2020)
Gambar III.2 Tahapan Import Data & Import Configuration Wizard 2. Pada tampilan jendela data import wizard step 1, pilih file training data yang
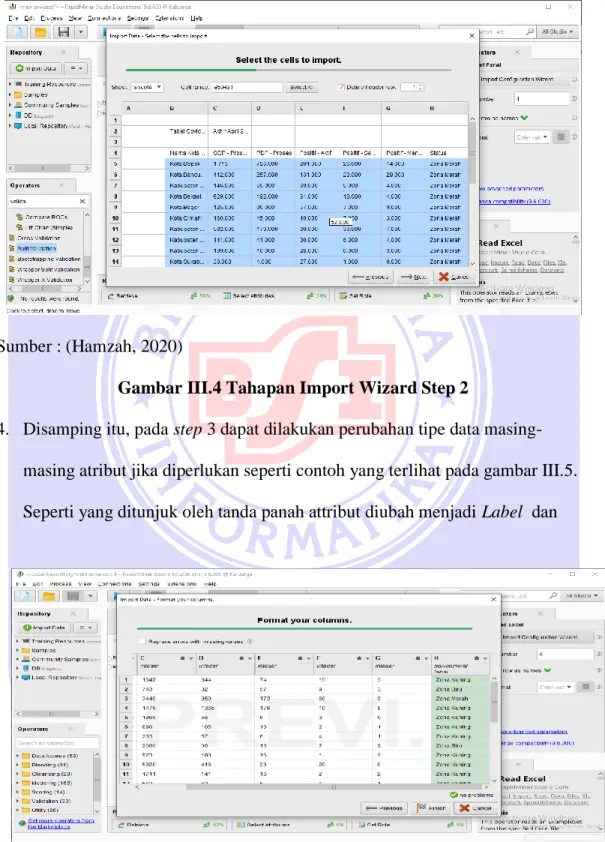
akan dilakukan pemodelan, kemudian click next seperti terlihat pada gambar III.3.Klik tombol Finish dan proses Import Data Wizard selesai.
Sumber : (Hamzah, 2020)
3. Pada step 2, pilih sheet yang akan digunakan kemudian klik next seperti terlihat pada gambar III.4.
Sumber : (Hamzah, 2020)
Gambar III.4 Tahapan Import Wizard Step 2
4. Disamping itu, pada step 3 dapat dilakukan perubahan tipe data masing-masing atribut jika diperlukan seperti contoh yang terlihat pada gambar III.5. Seperti yang ditunjuk oleh tanda panah attribut diubah menjadi Label dan
Sumber : (Hamzah, 2020)
Gambar III.5 Tahapan Import Wizard Step 3
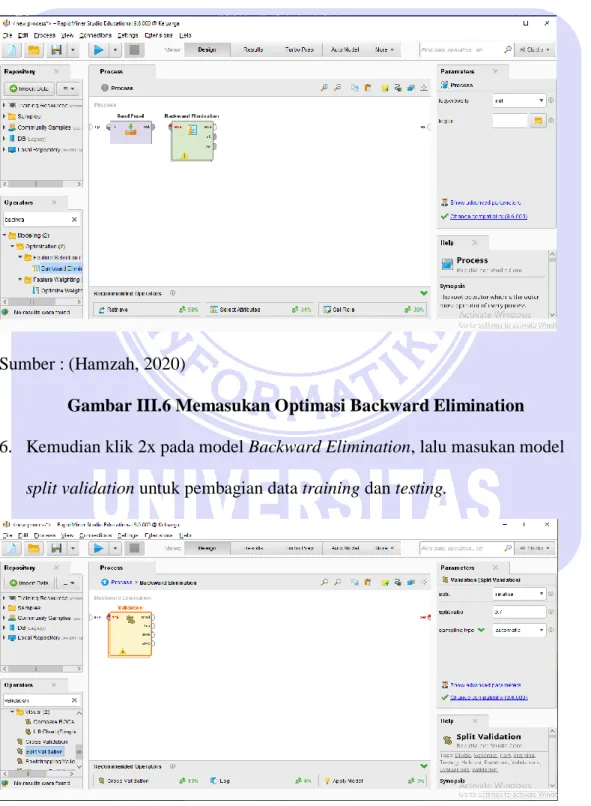
5. Langkah selanjutnya adalah memasukan model yang akan digunakan untuk pemodelan klasifiksi data mining dengan cara masuk ke panel operator, kemudian pilih Modeling, Optimization and Backward Elimination seperti terlihat pada gambar III.6.
Sumber : (Hamzah, 2020)
Gambar III.6 Memasukan Optimasi Backward Elimination 6. Kemudian klik 2x pada model Backward Elimination, lalu masukan model
Sumber : (Hamzah, 2020)
Gambar III.7 Memasukan Model Split Validation
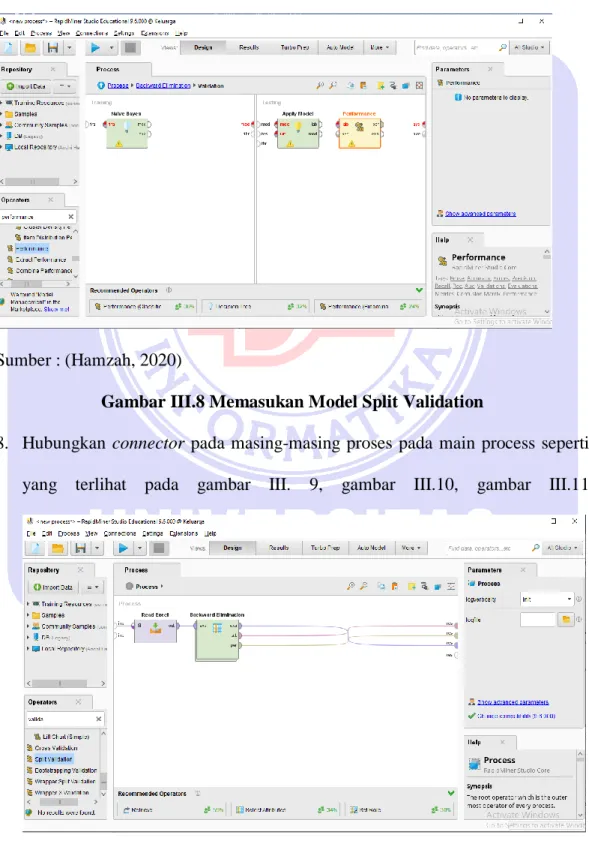
7. Kemudian klik 2x lagi pada split validation untuk memasukan model naïve bayes, apply model dan performance untuk pengujian dataset.
Sumber : (Hamzah, 2020)
Gambar III.8 Memasukan Model Split Validation
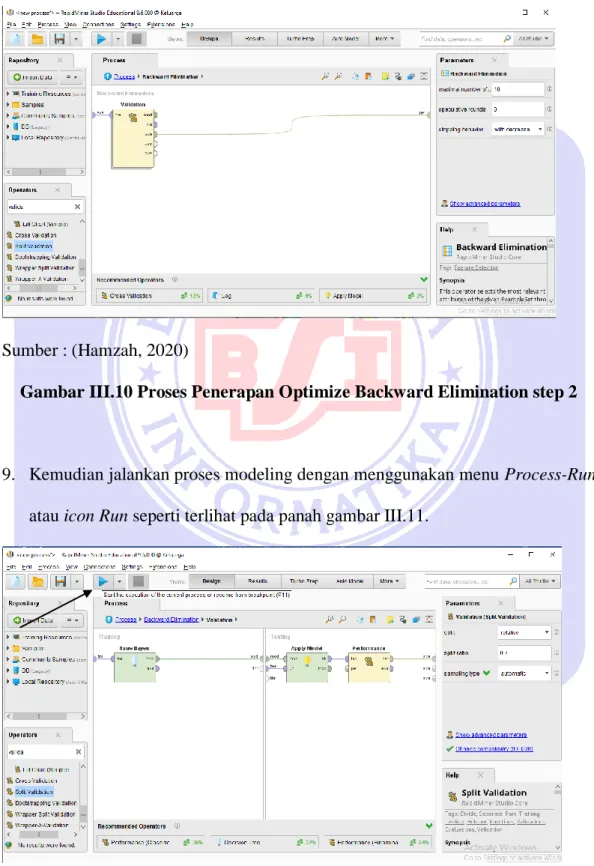
8. Hubungkan connector pada masing-masing proses pada main process seperti yang terlihat pada gambar III. 9, gambar III.10, gambar III.11
Sumber : (Hamzah, 2020)
Gambar III.9 Proses Penerapan Optimize Backward Elimination step 1
Sumber : (Hamzah, 2020)
Gambar III.10 Proses Penerapan Optimize Backward Elimination step 2
9. Kemudian jalankan proses modeling dengan menggunakan menu Process-Run atau icon Run seperti terlihat pada panah gambar III.11.
Gambar III.11 Proses Penerapan Optimize Backward Elimination step 3
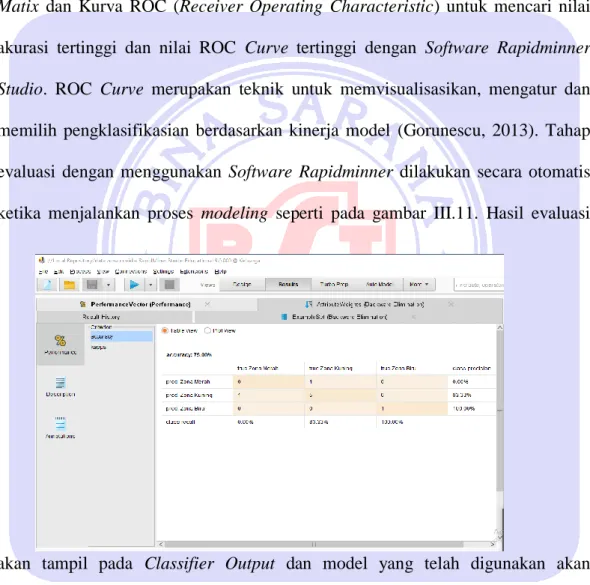
3.4.3. Evaluasi
Pada tahap ini akan ditampilkan evaluasi terhadap kualitas dan efektifitas dari model yang diterapkan. Proses evaluasi akan menggunakan metode Confusion Matix dan Kurva ROC (Receiver Operating Characteristic) untuk mencari nilai akurasi tertinggi dan nilai ROC Curve tertinggi dengan Software Rapidminner Studio. ROC Curve merupakan teknik untuk memvisualisasikan, mengatur dan memilih pengklasifikasian berdasarkan kinerja model (Gorunescu, 2013). Tahap evaluasi dengan menggunakan Software Rapidminner dilakukan secara otomatis ketika menjalankan proses modeling seperti pada gambar III.11. Hasil evaluasi
akan tampil pada Classifier Output dan model yang telah digunakan akan tersimpan di Result List seperti terlihat pada Gambar III.12.
Sumber : (Hamzah, 2020)
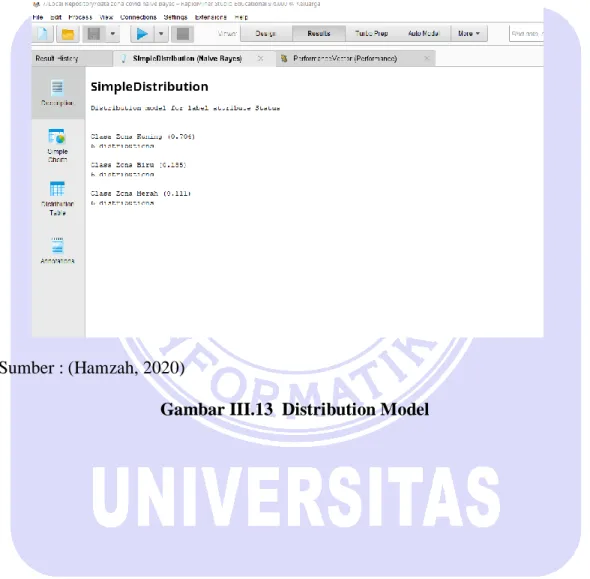
10. Kemudian akan muncul tampilan SimpleDistribution atau seperti terlihat pada panah gambar III.13.
Sumber : (Hamzah, 2020)