BAB 2
LANDASAN TEORI
2.1. Suling Batak (Sulim)
Sulim adalah sejenis instrumen tiup bambu yang berasal dari daerah Batak Toba di
Sumatera Utara. Dalam klasifikasi alat musik oleh Curt Sachs dan Hornbostel, instrumen ini tergolong kepada jenis aerophone dengan spesifikasi side blown flute yang terdiri dari sebuah lobang tiupan dan 6 (enam) buah lobang nada. Dilihat dari karakteristik organologisnya, sulim hampir sama dengan jenis seruling yang ada pada etnis lain pada umumnya. Perbedaannya hanya pada penambahan lobang yang dibalut oleh sebilah kertas tipis ataupun plastik tipis pada pertengahan antara lobang tiupan dengan lobang nada. Lobang tambahan ini dapat menciptakan warna bunyi yang menjadi ciri khas tersendiri dibandingkan instrumen seruling yang lain (Sidabutar, 2013).
Ditinjau dari aspek penggunaannya, awalnya sulim hanya tergolong kepada sejenis solo instrumen atau instrumen tunggal yang biasa dipakai oleh seseorang sebagai media hiburan untuk mengungkapkan perasaannya. Dalam kehidupan sehari-hari instrument ini lazim dipakai oleh seseorang diwaktu-waktu senggang baik ketika menggembalakan kerbau, menjaga ladang/sawah, bermain ataupun saat melakukan berbagai aktivitas lainnya. Kemudian seiring dengan perkembangan zaman, dengan hadirnya opera Batak yang dari tahun 1920-an hingga 1970-an, sulim membawa pengaruh dan perubahan dalam hal pola pikir dan selera musik masyarakat Batak Toba pada masa itu.
zaman dan rasa musikal masyarakat Batak Toba pada masa itu maka terjadilah sedikit pergeseran dimana instrumen sulim dan taganing mulai dipadukan dengan instrumen-instrumen yang ada dalam ensambel gondang hasapi. Dalam ensambel ini, sulim berperan sebagai pembawa melodi penuh disamping instrumen lain yang juga pembawa melodi utama seperti hasapi inang (lute), sarune etek (oboe) dan garantung (xylophone). Selain sebagai pembawa melodi, sulim juga berperan sebagai pembawa melodi variatif yang mampu keluar dari wilayah nada pokok sebagai wujud dari improvisasi nada-nada yang dimainkan baik dari sebuah lagu maupun repertoar sesuai kemampuan pemainnya. Menurut para narasumber pemusik tradisional Batak Toba, masuknya sulim ke dalam gondang hasapi merupakan pengaruh dari ensambel musik opera Batak yang disebut dengan uning-uningan.
Sebagaimana telah disebutkan sebelumnya, sulim terbuat dari seruas bambu yang dibentuk sedemikian rupa dengan satu buah lobang penghasil bunyi di bagian atasnya dan enam buah lobang nada sebagai penghasil nada-nada yang diinginkan. Diantara lobang penghasil bunyi dengan lobang nada terdapat satu buah lobang pemecah bunyi yang ditutup dengan kertas tipis seperti yang terlihat pada Gambar 2.1.
Gambar 2.1 Suling Batak (Sidabutar, 2013)
Sulim dimainkan dengan meniup lobang penghasil bunyi yang berada pada bagian
-nada yang lain dapat dihasilkan dengan posisi lobang -nada 1 dibuka untuk -nada “G”, lobang nada 1 dan 2 dibuka untuk nada “A”, lobang nada 1, 2, dan 3 dibuka untuk nada “Bes”, lobang nada 1, 2, 3, dan 4 dibuka untuk nada “C”, lobang nada 1, 2, 3, 4, dan 5 dibuka untuk nada “D”, lobang nada 1, 2, 3, 4, 5, dan 6 dibuka untuk nada “E”, dan lobang nada 6 dibuka untuk nada “F oktaf”. Dimana lobang nada 1 sampai 6 dihitung dari bawah ke atas (lobang paling jauh dari lobang penghasil bunyi ke lobang yang paling dekat). Ketika nada-nada yang ada pada suling batak dimainkan secara berurutan akan menghasilkan tangga nada do-re-mi-fa-sol-la-si-do’ yang biasa disebut dengan tangga nada mayor.
2.2. Tangga Nada
Tangga nada merupakan kumpulan nada-nada yang harmonis dengan aturan tertentu yang mendasarinya (Sijabat, 2009). Terdapat beberapa tangga nada yaitu tangga nada kromatik dan tangga nada mayor. Tangga nada kromatik adalah tangga nada yang terdiri dari kumpulan semua nada dalam musik. Tangga nada kromatik berisi 12 nada dari tiap oktaf. Meskipun ada 12 nada dalam satu oktaf tangga nada kromatik, tetapi hanya 7 huruf pertama dari abjad yang dipakai untuk memberi nama pada nada yaitu dari A sampai G. Kelima nada lain dalam satu oktaf tangga nada kromatik diberi nama dengan memberikan tanda kres (#) atau mol (b) setelah notasi nada. Frekuensi kedua belas nada dengan nada A = Do dapat dilihat pada tabel 2.1.
Tabel 2.1 Frekuensi nada (Sijabat, 2009)
Nada Frekuensi
A 440.00 Hz
A# / Bb (Bes) 466.16 Hz
B 493.88 Hz
C 523.25 Hz
C# / Db (Des) 554.37 Hz
D 587.33 Hz
D# / Eb (Es) 622.25 Hz
E 659.25 Hz
F 698.46 Hz
F# / Gb (Ges) 739.99 Hz
G 783.99 Hz
G# / Ab (Aes) 830.61 Hz
A 880.00 Hz
Pada Tabel 2.1 terlihat beberapa frekuensi nada dalam musik, dimana pada Tabel 2.1 menunjukkan urutan dari nada A sampai nada A pada oktaf selanjutnya. Nada-nada yang ada pada Tabel 2.1 dapat disusun menjadi tangga Nada-nada mayor dengan interval jarak antar nada yang telah dijelaskan sebelumnya.
2.3. Sinyal Suara
Sinyal suara didefenisikan sebagai kuantitas fisika yang berubah-ubah bergantung pada ruang, waktu, atau variabel-variabel lainnya (John & Dimitris, 1996). Sinyal suara terdiri dari fase-fase yang tersusun atas frekuensi dan amplitudo. Sinyal suara tercipta akibat adanya getaran yang berasal dari suatu objek. Getaran ini mengandung suatu informasi yang merambat melalui medium (udara, air) dan ditangkap melalui indra pendengar. Getaran yang yang ditangkap indra pendengar akan diubah oleh otak menjadi suatu informasi yang berguna sesuai kebutuhan pendengar.
dikarenakan dalam pembacaannya, sinyal suara tidak terpengaruh oleh cahaya, penglihatan, dan tidak memakan banyak ruang penyimpanan dalam pemrosesannya. Teknik pemrosesannya juga lebih mudah dari pemrosesan yang menggunakan video. Sekarang ini, pemrosesan sinyal suara sudah digunakan dalam berbagai segi kehidupan, seperti pada bidang keamanan, pengklasifikasian spesies, membaca keadaan cuaca dan lain sebagainya.
Kebanyakan sinyal suara yang ditemukan dalam kehidupan sehari-hari bentuknya analog. Untuk melakukan pemrosesan suara, sinyal analog harus diubah terlebih dahulu menjadi sinyal digital. Sinyal yang berbentuk digital akan lebih mudah diprogram dan dimasukkan ke dalam sistem karena tingkat toleransi dan akurasi dalam pembacaannya lebih tinggi dari analog. Sinyal digital juga sudah diterapkan di banyak disiplin ilmu yang ada sekarang ini.
2.4. Pengenalan Suara
Pengenalan suara adalah suatu sistem yang memungkinkan komputer untuk mengidentifikasi kata yang terucap atau pembicara yang mengucapkan kata berdasarkan suaranya (Rudrapal, et. al., 2012). Suara dikenali melalui ciri-cirinya, ciri-ciri tersebut didapat melalui proses dimana sinyal suara dalam bentuk digital di petakan dalam ruang dua dimensi dan sinyal suara tersebut akan memiliki pola serta nilai dengan karakteristik dan ciri tertentu. Ciri-ciri tersebut digunakan untuk membedakan antara suara yang satu dengan yang lainnya.
2.5. Sampling
2.6. Mel-Frequency Cepstral Coefficient
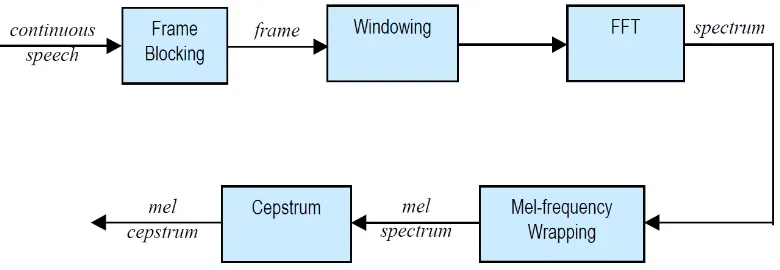
Mel Frequency Cepstrum Coefficients (MFCC) merupakan satu metode yang banyak dipakai dalam bidang speech recognition. Metode ini digunakan untuk melakukan feature extraction, sebuah proses yang mengkonversikan sinyal suara menjadi beberapa parameter. Alur pemrosesan MFCC dibuat menyerupai alur pemrosesan sistem indra manusia dalam menangkap sinyal suara agar hasil ekstraksi fiturnya mendekati persepsi yang dihasilkan indra pendengaran manusia (Davis & Mermelstein, 1980). Blok diagram untuk MFCC dapat dilihat pada Gambar 2.2.
Gambar 2.2 Block Diagram Proses MFCC (Patel & Rao, 2010)
Keunggulan dari metode ini adalah :
Mampu menangkap karakteristik suara yang sangat penting bagi pengenalan suara atau dengan kata lain mampu menangkap informasi – informasi penting yang terkandung dalam sinyal suara
Menghasilkan data seminimal mungkin tanpa menghilangkan informasi – informasi penting yang ada.
Mereplikasi organ pendengaran manusia dalam melakukan persepsi sinyal suara.
Tetapi bila dilakukan dalam periode waktu yang lebih panjang, karakteristik sinyal suara akan berubah sesuai dengan kata yang diucapkan.
2.6.1. Pre-Processing
Pre-Processing berfungsi untuk meningkatkan kualitas sinyal suara dengan mengurangi noise. Noise-noise yang ada dihilangkan dengan cara menyeimbangkan amplitudo pada sebuah sinyal suara. Sebelum itu dilakukan terlebih dahulu pengidentifikasian titik awal dan titik akhir dari sinyal suara untuk mengetahui keberadaan noise yang ada pada bagian sinyal suara (Tan & Jantan, 2004). Keberadaan noise pada sinyal suara dideteksi berdasarkan nilai dan variabel yang sudah ditentukan. Sinyal suara yang terdeteksi sebagai noise akan dipotong dan dihilangkan dari bagian sinyal suara (Tan & Jantan, 2004). Pre-Emphasis merupakan salah satu jenis filter untuk mengurangi noise-noise yang terdapat pada sinyal suara tersebut. Tujuan dari Pre-Empahsis ini adalah :
a. Mengurangi noise ratio pada sinyal suara sehingga dapat meningkatkan kualitas sinyal suara.
b. Menyeimbangkan amplitudo dari sinyal suara.
Bentuk paling umum digunakan dalam Pre-Emphasis adalah sebagai berikut. y[n] = s[n] –α s[n - 1] , 0.9 ≤α ≤ 1.0 (2.1) Dimana : y[n] = sinyal hasil pre-emphasis
s[n] = sinyal sebelum pre-emphasis
2.6.2. Frame Blocking
Penentuan jumlah data pada setiap frame dihitung menggunakan persamaan :
J(f) = ((I – N)/M) + 1 (2.2)
Dimana : J(f) = jumlah frame I = sample rate N = frame size
M = jumlah overlapping
Karena sinyal suara terus mengalami perubahan akibat adanya pergeseran artikulasi dari organ produksi suara, sinyal harus diproses secara short segments (short frame). Panjang frame yang biasanya digunakan untuk pemrosesan sinyal adalah antara 10-30 milidetik. Panjang frame yang digunakan, sangat mempengaruhi keberhasilan dalam analisa spektral, di satu sisi, ukuran frame harus diperpanjang sepanjang mungkin untuk dapat menunjukkan resolusi frekuensi yang baik, tetapi dalam slain sisi, ukuran frame juga harus cukup pendek untuk dapat menunjukkan resolusi waktu yang baik (Ridwan, 2011). Proses kerja frame blocking dapat dilihat pada Gambar 2.3.
Gambar 2.3 Contoh Frame Blocking (Ridwan, 2011)
2.6.3. Windowing
Input yang dimasukkan dalam melakukan pemrosesan suara berbentuk sinyal yang magnitudenya bervariasi pada awal maupun akhir frame atau biasa disebut fenomena kebocoran sinyal. Hal tersebut menghambat pemrosesan sinyal dan menghasilkan keluaran yang kurang akurat. Untuk itu windowing dilakukan dengan meminimalkan gangguan pada awal dan akhir frame (Gupta, et. al., 2013). Metode ini memiliki banyak jenis diantaranya Blacman window, Rectangular window, Bartlett window, Hanning window, Hamming Window, Tukey window.
Setiap jenis window mempunyai karakteristik masing-masing, diantara berbagai jenis window tersebut, Blackman window menghasilkan sidelobe level yang paling tinggi (kurang dari -58 dB). Tetapi Blackman window ini juga menghasilkan noise paling besar (kurang dari 1,73 BINS), Oleh karena itu Blackman window jarang sekali digunakan baik untuk speaker recognition maupun speech recognition.
Jenis window yang paling sering di gunakan dalam pengolahan suara adalah hamming windowing. Hamming windowing digunakan untuk menjaga kontinuitas titik awal dan titik akhir sinyal suara dalam frame (Chakraborty, et. al., 2014). Hamming windowing memiliki sidelobe yang paling kecil dan mainlobe yang paling besar sehingga hasil windowing akan lebih dalam menghasilkan efek diskontinuitas (Rizkia, 2016).
(2.3)
Dimana : w(n) = windowing
N = jumlah data yang berasal dari sinyal
2.6.4. Fast Fourier Transform (FFT)
Fast Fourier Transform adalah pengembangan dari algoritma Discrete Fourier Transform (DFT). Jika algoritma Discrete Fourier Transform (DFT) digunakan untuk mentransformasikan sinyal domain waktu ke sinyal domain frekuensi dalam perhitungan MFCC, beban pada waktu komputasi akan terlalu besar ketika dijalankan secara real-time (Jaybhaye & Srivastava, 2015). Waktu komputasi yang terlalu besar disebabkan karena DFT membutuhkan N2 perkalian bilangan kompleks. Karena itu digunakan FFT karena memiliki pemrosesan yang lebih cepat dan lebih optimal dibandingkan dengan DFT.
Fast Fourier Transform (FFT) digunakan untuk mengkonversi setiap frame N sampel dari domain waktu menjadi domain frekuensi (Chavan & Sable, 2013). Untuk pemrosesan sinyal suara, hal ini sangatlah menguntungkan karena data pada frekuensi dapat diproses dengan lebih mudah dibandingkan data pada domain waktu, karena pada domain frekuensi, keras lemahnya suara tidak seberapa berpengaruh.
Perhitungan nilai hasil Fast Fourier Transform dapat dilihat persamaan :
∑ (2.4)
Dimana : F(k) = hasil FFT F(n) = sinyal masukan
N = jumlah sample
n = indeks sample input dalam domain waktu m = indeks sample output dalam domain frekuensi
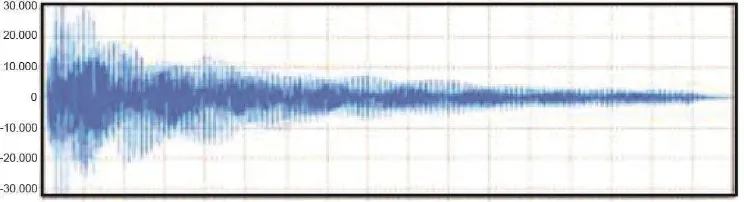
Gambar 2.4 Sinyal dalam domain waktu (Huda, 2011)
Pada Gambar 2.4 merupakan bentuk sinyal suara masih dalam domain waktu. Sinyal suara tersebut belum melewati proses transformasi yang dilakukan oleh FFT.
Gambar 2.5 Sinyal dalam domain frekuensi (Huda, 2011)
Pada Gambar 2.5 merupakan bentuk sinyal suara yang sudah dalam domain waktu. Sinyal suara tersebut telah melewati proses transformasi yang dilakukan oleh FFT. Konsep metode Fast Fourier Transfrom (FFT) secara keseluruhan dapat dilihat pada gambar 2.6.
Algoritma FFT ini bekerja dengan cara memecah N-titik menjadi dua (N/2) – titik, kemudian dipecah lagi pada tiap (N/2) – titik menjadi dua (N/4) – titik, begitu seterusnya sampai hanya terdapat 1 titik (Fadhlullah, 2015).
2.6.5. Mel Filtering
Persepsi manusia terhadap frekuensi dari signal suara tidak mengikuti skala linear, frekuensi yang sebenarnya (dalam Hz) dalam sebuah signal akan diukur manusia secara subjektif dengan menggunakan Mel scale. Mel frequency scale adalah skala pendengaran yang serupa dengan skala frekuensi telinga manusia (mirip dengan bagaimana telinga manusia merasakan suara). Skala ini kira-kira linier di bawah 1 kHz dan logaritmik di atas 1 kHz (Dhonde & Jagade,2015).
Mel filtering umumnya dilakukan dengan menggunakan filterbank. Filterbank adalah salah satu bentuk dari filter yang dilakukan dengan tujuan untuk mengetahui ukuran energi dari frequency band tertentu dalam sinyal suara. Filterbank dapat diterapkan baik pada domain waktu maupun domain frekuensi, tetapi untuk keperluan MFCC, filterbank harus diterapkan dalam domain frekuensi.
Filterbank menggunakan representasi konvolusi dalam melakukan filter terhadap signal konvolusi dapat dilakukan dengan melakukan multiplikasi antara spektrum signal dengan koefisien filterbank. Berikut ini adalah rumus yang digunakan dalam perhitungan filterbanks.
(2.5)
Dimana : = koefisien filterbank pada frekuensi j(1 ≤ i ≤ M ) = magnitude spectrum pada frekuensi j
2.6.6.Discrete Cosine Transform
untuk spectrum yaitu mengubah mel-spectrum kembali ke dalam domain waktu. Nilai cepstrum biasanya disebut dengan vektor akustik. Setiap sinyal suara masukan ditransformasikan menjadi urutan vektor akustik (Muda, et. al., 2010). Vektor akustik ini akan digunakan untuk mendapatkan informasi dari suatu sinyal suara. Konsep dasar dari DCT adalah mendekorelasikan mel spectrum sehingga menghasilkan representasi yang baik dari property spektral local (Kurniawan,2017). Hal inilah yang menyebabkan seringkali DCT menggantikan inverse fourier transform dalam proses MFCC Feature Extraction. Berikut adalah formula yang digunakan untuk menghitung DCT.
Cn = ∑ (2.6)
Dimana : Sk = mel-spectrum Cn = cepstral-coefficient
K = jumlah koefesien yang diharapkan
2.7. Hidden Markov Model
Hidden Markov Model (HMM) adalah sebuah metode pengenalan suara dengan cara pencocokan pola yang hasilnya dianggap sebagai output dari suatu sistem. Sebuah sistem pengenalan suara terdiri dari dua tahap pengenalan yaitu pengenalan sinyal suara data latih dan pengenalan sinyal suara data uji.
identifikasinya diambil berdasarkan total jarak terkecil antara titik koordinat dari vektor akustik data uji dengan centeroid data latih yang ada di codebook. Proses perbandingan ini dilakukan kepada codebook tiap model HMM. Sinyal suara data latih yang sudah berbentuk model HMM dengan besaran jarak terkecil merupakan sinyal suara data latih yang memiliki kemiripan dengan sinyal suara data uji dan akan menghasilkan keputusan bahwa sinyal suara data uji sama dengan sinyal suara data latih tersebut.
2.8. Penelitian Terdahulu
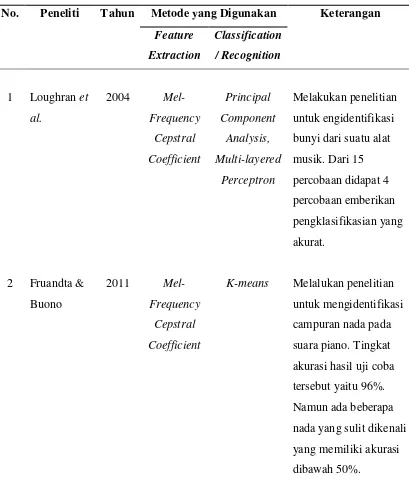
Penelitian tentang pemrosesan suara alat musik telah banyak dilakukan menggunakan berbagi macam metode pengekstrakan dan pengklasifikasian. Loughran et al. (2004) melakukan penelitian untuk mengidentifikasi bunyi dari suatu alat musik. Alat musik yang digunakan pada penelitian ini ialah piano, biola, dan flute. Peneliti menggunakan algoritma MFCC pada pengekstrakannya dan algoritma PCA dan MLP untuk pengklasifikasiannya. Dari 15 percobaan didapat 4 percobaan memberikan pengklasifikasian yang akurat.
Fruandta & Buono (2011) melalukan penelitian untuk mengidentifikasi campuran nada pada suara piano menggunakan codebook dengan clustering algorithm K-means. Metode ekstraksi fitur yang digunakan adalah algoritma MFCC. Dalam tahap uji coba, dilakukan pengujian pada 12 nada tunggal dan 66 nada campuran yang masing masing memiliki 5 suara. Adapun tingkat akurasi hasil uji coba tersebut yaitu 96%. Namun, ada beberapa nada yang sulit dikenali, yaitu CC#, CD, CF, dan A#B yang memiliki akurasi masing-masing dibawah 50%.
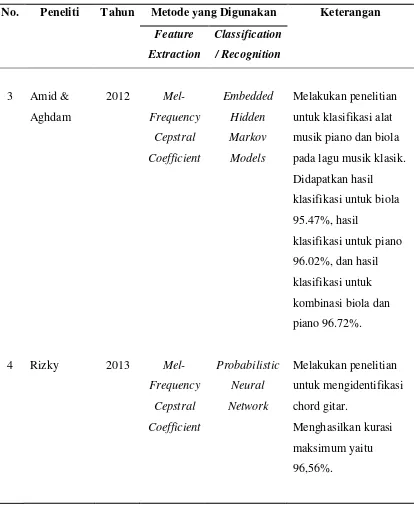
Rizky (2013) melakukan penelitian untuk mengidentifikasi chord gitar. Penelitian ini menggunakan 8.280 data suara gitar dari 24 chord yang berbeda. Algoritma pengekstrakannya adalah MFCC dan algoritma pengklasifikasiannya adalah PNN yang menghasilkan akurasi maksimum yaitu 96.56%.
Jadhav (2015) melakukan penelitian untuk mengidentifikasi alat musik dari rekaman audio monofonik menggunakan metode MFCC dan Timbral ADs sebagai ekstaksi fiturnya dan metode K-NN, SVM, dan BT untuk pengklasifikasiannya. Analisis dilakukan dengan mempelajari hasil yang diperoleh dari semua kemungkinan kombinasi metode ekstraksi fitur dan pengklasifikasi. Tingkat akurasi tertinggi pada saat menggunakan ekstraksi fitur MFCC didapat ketika dikombinasikan dengan metode pengklasifikasian K-NN yaitu 90%, 77%, dan 75.33% masing-masing untuk pengidentifikasian lima, sepuluh, dan lima belas alat musik. Tingkat akurasi tertinggi pada saat menggunakan ekstraksi fitur Timbral ADs didapat ketika dikombinasikan dengan metode pengklasifikasian BT yaitu 88%, 84%, dan 73.33% masing-masing untuk pengidentifikasian lima, sepuluh, dan lima belas alat musik.
Tabel 2.2 Penelitian Terdahulu
Tabel 2.2 Penelitian Terdahulu (Lanjutan)
Tabel 2.2 Penelitian Terdahulu (Lanjutan)