MODEL PREDIKSI FINANCIAL DISTRESS PADA PERUSAHAAN
MANUFAKTUR GO PUBLIC DI INDONESIA
Umi Zhahratun Nisa1, *), Budi Santosa2) dan Stefanus Eko Wiratno3)
1) Jurusan Teknik Industri, Institut Teknologi Sepuluh Nopember Keputih Sukolilo, Surabaya, 60111, Indonesia
e-mail: [email protected]
2) Jurusan Teknik Industri, Institut Teknologi Sepuluh Nopember 3) Jurusan Teknik Industri, Institut Teknologi Sepuluh Nopember
ABSTRAK
Financial distress adalah kondisi perusahaan sedang mengalami kesulitan keuangan dan salah satu proses sebelum perusahaan mengalami kebangkrutan. Kasus set data tak imbang (imbalanced datasets) pada model prediksi financial distress masih mendapat sedikit perhatian. Sebagian besar penelitian menggunakan jumlah sampel yang sama antara perusahaaan yang mengalami financial distress (kelas positif) dengan perusahaan yang tidak mengalami financial distress (kelas negatif). Pada kenyataannya, tidak semua kasus memiliki besar distribusi yang sama. Salah satu solusi dalam mengatasi masalah ketidakseimbangan adalah dengan melakukan resampling. Penelitian ini berupaya untuk membandingkan hasil akurasi prediksi financial distress pada perusahaan manufaktur go public di Indonesia dengan menggunakan set data tak imbangdan set data imbang. Keseimbangan data antar kedua kelas dilakukan melalui duplikasi kelas positif secara acak (random oversampling). Teknik klasifikasi yang digunakan adalah Support Vector Machine dan Linear Discriminant Analysis.
Hasil penelitian membuktikan bahwa akurasi prediksi dari kedua classifier akan lebih optimal bila menggunakan set data yang memiliki jumlah kelas positif dan negatif yang seimbang.
Kata kunci: financial distress, data mining, classification, imbalanced dataset
PENDAHULUAN
Kebangkrutan merupakan situasi yang paling tidak diinginkan oleh semua pelaku bisnis. Kebangkrutan memberikan dampak negatif tidak hanya bagi pihak manajemen perusahaan, namun juga bagi para pemegang saham, kreditur, pemasok, bahkan kestabilan perekonomian suatu negara (Sun dan Li, 2009). Apabila suatu perusahaan tidak dapat mengenali kondisi kesulitan keuangan (financial distress) serta tidak tanggap melakukan upaya perbaikan, maka akan memiliki peluang besar untuk masuk dalam kondisi kebangkrutan. Dengan demikian, diperlukan adanya suatu sistem peringatan dini pada kondisi
financial distress agar perusahaan dapat terhindar dari kebangkrutan yang lebih serius.
Beragam penelitian baik di bidang akuntansi maupun keuangan yang berupaya untuk melakukan pengembangan model prediksi financial distress. Topik prediksi financial distress
juga kian diminati di bidang statistik dan machine learning. Prediksi kebangkrutan mulai diteliti oleh Beaver (1966) yang membuat model analisis univariat dengan menggunakan rasio keuangan perusahaan dan menyimpulkan bahwa rasio keuangan dapat digunakan untuk membedakan antara perusahaan bangkrut dan tidak bangkrut. Altman (1968) menggunakan model statitistik Multiple Discriminant Analysis (MDA), yakni Z-Score model yang dapat digunakan untuk mengidentifikasi perusahaan bangkrut dengan mengkombinasikan lima rasio keuangan. Ohlson (1980) menggunakan teknik statistik berupa regresi logistik untuk mengetahui kemungkinan suatu perusahaan mengalami financial distress. Perkembangan
teknik kecerdasan buatan (artificial intelligent) dan data mining pada era 1990-an meliputi beragam metode, seperti decision tree (DT), case-based reasoning (CBR), artificial neural networks (ANNs), algoritma evolusioner genetic algorithm (GA) dan teknik baru support vector machine (SVM). Teknik tersebut banyak diaplikasikan untuk memprediksi financial distress perusahaan (Chen, 2011).
Salah satu tugas penting dalam data mining adalah klasifikasi yang bertujuan untuk menghasilkan model sehingga dapat menggolongkan data training ke dalam suatu kelas seakurat mungkin (Gong dan Huang, 2012). Prediksi financial distress perusahaan merupakan permasalahan klasifikasi yang bersifat biner, dimana perusahaan yang mengalami financial distress dilambangkan dengan nilai 1 (kelas positif), sedangkan perusahaan yang tidak mengalami financial distress dilambangkan dengan nilai -1 (kelas negatif). Sebagian besar penelitian terkait dengan financial distress menggunakan jumlah sampel yang sama, baik pada kelas positif maupun kelas negatif. Namun pada kenyatannya, kasus perusahaan yang mengalami financial distress lebih jarang ditemui dibandingkan dengan perusahaan yang tidak mengalami financial distress. Apabila dalam suatu set data penelitian prediksi memiliki jumlah anggota kelas positif (interest class) yang jauh lebih sedikit dibandingkan dengan kelas negatif, maka set data tersebut merupakan set data tak imbang (imbalanced datasets).
Algoritma yang digunakan dalam kasus klasifikasi selalu bertujuan untuk meminimumkan tingkat kesalahan atau presentase prediksi kesalahan dari label kelas. Apabila algoritma klasifikasi diterapkan secara tidak hati-hati pada set data training yang imbalanced, maka akan menghasilkan informasi akurasi prediksi yang bias, yakni kelas mayoritas mempunyai akurasi yang lebih tinggi dibandingkan kelas minoritas. Oleh karena itu, diperlukan suatu tindakan khusus pada kasus imbalanced dataset agar classifier yang digunakan dapat memberikan hasil prediksi yang akurat.
Secara garis besar, terdapat dua pendekatan yang dapat digunakan untuk mengatasi masalah imbalanced datasets, yaitu pada level data dan level agoritma. Pendekatan pada level data (sampling approach), merupakan langkah berupa resampling set data yang ada, baik berupa oversampling maupun undersampling (Ganganwar, 2012). Pendekatan kedua, yakni berbasis algoritma, dilakukan dengan cara menciptakan algoritma baru atau mengatur sedemikian rupa algoritma classifier yang sudah ada untuk meningkatkan kinerja dalam mengolah imbalanced datasets (Liu, et al., 2011). Kedua pendekatan tersebut dapat diterapkan pada penelitian prediksi financial distress yang memiliki permasalahan set data tak imbang.
Faktor lain yang juga mempengaruhi akurasi prediksi financial distress adalah fitur atau variabel yang digunakan dalam penelitian (Lin, Liang dan Chen, 2011). Adanya perbedaan variabel prediktor yang digunakan dalam suatu penelitian akan memberikan keragaman hasil. Sebagian besar penelitian prediksi financial distress perusahaan menekankan pada variabel keuangan, padahal terdapat variabel lain seperti non keuangan dan makroekonomi yang mempengaruhi kondisi tersebut (Tirapat dan Nittayagasetwat, 1999). Dengan demikian, diperlukan suatu langkah berupa pemilihan variabel, sehingga dapat memanfaatkan sejumlah variabel penting dalam suatu set data dan mengeliminasi variabel yang tidak relevan (Zhou, Lai dan Yen, 2012). Salah satu langkah yang dapat dilakukan dalam tahap seleksi variabel adalah menggunakan metode LP-SVM (Santosa, 2007).
Di Indonesia, penelitian mengenai prediksi kondisi financial distress yang menggunakan imbalanced datasets cukup terbatas. Mayoritas penelitian tersebut menggunakan proporsi jumlah sampel yang berimbang antar dua kelas. Faktanya, data perusahaan yang mengalami financial distress di Indonesia memiliki jumlah yang jauh lebih sedikit dibandingkan perusahaan yang tidak mengalami financial distress. Oleh sebab itu, diperlukan adanya penelitian yang membahas mengenai penyeimbangan data pada kasus
Penelitian prediksi kondisi financial distress perusahaan yang ada selama ini juga seringkali menggunakan indikator financial distress melalui perhitungan variabel rasio keuangan dari laporan keuangan tahunan. Indikator financial distress sendiri biasanya lebih dari satu tahun. Menurut Sun, He dan Li (2011), memprediksi dalam masa satu tahun merupakan periode yang relatif panjang, sedangkan prediksi pada periode yang lebih pendek, misal setengah tahun, masih sedikit mendapat perhatian. Penelitian yang menggunakan variabel prediktor non keuangan dan makroekonomi telah banyak dilakukan (Almilia, 2004; Hidayat, 2009; Iramani, 2008), namun sebagian besar belum menggunakan teknik machine learning. Penggunaan teknik klasifikasi data mining yang melibatkan ketiga variabel tersebut juga masih jarang dilakukan di Indonesia.
Berdasarkan penjelasan di atas, maka diperlukan suatu penelitian berupa model prediksi kondisi financial distress di Indonesia menggunakan teknik klasifikasi data mining
yang melibatkan variabel keuangan, non keuangan dan makroekonomi. Guna mengetahui berbagai variabel yang signifikan mempengaruhi model prediksi tersebut, diperlukan langkah pemilihan variabel. Selanjutnya, sampel yang digunakan dalam penelitian ini adalah perusahaan manufaktur yang sudah go public di Indonesia. Selain dikarenakan kemudahan dalam mendapatkan data (accessibility), hal ini juga dilatarbelakangi adanya karakteristik
imbalanced datasets pada perusahaan manufaktur go public di Indonesia. Perusahaan tersebut mengacu pada klasifikasi Jakarta Stock Industrial Classification (JASICA) serta memiliki laporan keuangan semester yang lengkap selama periode amatan Januari 2010 – Juni 2011. Perusahaan amatan diasumsikan memiliki umur dan besar aset yang sama. Penelitian ini menggunakan teknik sampling sebagai penyeimbang, yang kemudian diprediksi dengan menggunakan teknik Support Vector Machines dan teknik Linear Discriminant Analysis.
METODE
Beberapa tahap dalam penelitian ini antara lain: identifikasi dan perumusan masalah, pengumpulan data, pengolahan data, analisis dan interpretasi, serta kesimpulan dan saran. Adapun penjelasan dari setiap tahapan tersebut adalah sebagai berikut:
1. Tahap Identifikasi dan Perumusan Masalah
Pada tahap ini dilakukan identifikasi masalah yakni financial distress pada perusahaan manufaktur go public di Indonesia pada Januari 2010 – Desember 2011. imana kelas positif (perusahaan yang mengalami financial distress) berjumlah sebanyak 20 perusahaan, sedangkan perusahaan yang tidak mengalami financial distress berjumlah 100 perusahaan. Indikator adanya financial distress adalah perusahaan memiliki total aset kurang dari total kewajiban atau memiliki Earning Per Share negatif.
2. Tahap Pengumpulan Data
Penelitian ini merupakan penelitian dengan data sekunder. Laporan keuangan semester perusahaan nmatan didapatkan dari Bursa Efek Indonesia (www.idx.co.id), sedangkan variabel makroekonomi didapatkan dari Bank Indonesia (www.bi.go.id) dan
International Financial Statistics (IFS). 3. Tahap Pengolahan Data
Setelah data terkait obyek amatan didapatkan, maka langkah selanjutnya adalah melakukan pre-processing data. Tahap preprocessing yang pertama kali dilakukan adalah mengidentifikasi dan melakukan operasionalisasi variabel. Adapun variabel yang digunakan dalam penelitian ini adalah:
Tabel 1 Kandidat Variabel Keuangan
Nama Variabel Keterangan
CF_SL Cash Flow / Sales
CF_TA Cash Flow / Total Aset
WC_TA Working Capital/Total Assets
WC_SL Working Capital / Sales
CA_TA Current Assets / Total Assets
QA_SL Quick Assets / Sales
QA_TA Quick Assets / Total Assets
CL_SL Current Liabilities / Sales
EB_TA EBIT / Total Assets
NI_TA Net Income/ Total Assets
NI_TE Net Income / Total Equity
NI_SL Net Income / Sales
EB_SL EBIT/Sales
COG_SL Sales-CoGS / Sales
COG_IN CoGS / Inventory
SL_AR Sales/Accounts Receivable
SL_TA Sales / Total Assets
TL_TA Total Liabilities / Total Assets
TL_TE Total Liabilities / Total Equity
CA_CL Current Assets / Current Liabilities
QA_TL Quick Assets/Total Liabilities
Sedangkan variabel lainnya, yakni variabel non keuangan dan makroekonomi adalah:
Tabel 2 Kandidat Variabel Non Keuangan
Nama Variabel Keterangan
Board Size Jumlah Dewan Komisaris
Shares Concentration Konsentrasi Kepemilikan Saham
Stock Price Changes Perubahan Harga Saham
Tabel 3 Kandidat Variabel Makroekonomi
Nama Variabel Keterangan
Interest Rate Perubahan Tingkat Suku Bunga
Inflation Rate Perubahan Indeks Harga Konsumen
Exchange Rate Perubahan Suku Bunga
Money Supply Perubahan Jumlah Uang yang Beredar
Langkah preprocessing selanjutnya adalah melakukan transformasi data dengan cara
scaling kedalam rentang [-1 1]. Tahap terakhir dalam preprocessing adalah menyeleksi variabel yang paling signifikan dengan menggunakan metode Linear Programming Support Vector Machines.
Setelah tahap preprocessing selesai, langkah selanjutnya adalah tahap processing data. Dalam tahap ini, data awal yang tersedia dibagi kedalam dua kelompok, yakni data
training sebesar 70% dari total data, dipilih secara acak, dan sisanya digunakan sebagai data testing. Setelah itu, guna menyeimbangkan karakter set data yang imbalanced, maka dilakukan upaya sampling data dengan cara random oversampling. Pada penelitian ini, data dari kelas positif diduplikasi sebesar 300%, 400% dan 500%
dari total data kelas positif. Dengan demikian, diketahui bahwa terdapat empat macam set data yang dapat dijadikan sebagai input dalam membangun model prediksi.
Teknik yang digunakan dalam penelitian ini adalah Support Vector Machines (SVM) dan Linear Discriminant Analysis (LDA). Teknik SVM pada penelitian ini menggunakan jenis kernel linear serta RBF dengan rentang nilai parameter P sebesar 2-1, 20, 21, 22, 23, dan parameter C sebesar 1, 10, 100, 1000, dan 10000.
Langkah terakhir adalah menghitung akurasi dari setiap model prediksi yang telah dibuat dengan menggunakan confussion matrix. Parameter akurasi yang digunakan dalam penelitian ini adalah sensitivity, spesificity, precision dan overall accuracy. Pengukuran tersebut akan menghasilkan informasi berupa tipe set data dan teknik klasifikasi yang memiliki akurasi terbaik. Adapun confussion matrix untuk mengukur perusahaan yang mengalami financial distress dapat dilihat dalam Tabel 4 berikut:
Tabel 4 Confussion Matrix
Predicted Class
Financial Distress Non Financial Distress
Actual Class
Financial Distress TP FN
Non Financial Distress FP TN
Sumber: Chen, 2011
Setelah data uji dimasukkan ke dalam confussion matrix, nilai-nilai yang telah dimasukkan dihitung dengan pengukuran sebagai berikut:
Sensitivity, yakni proporsi jumlah perusahaan yang mengalami financial distress
yang berhasil diprediksi dengan benar. Cara menghitungnya adalah
Specificity, yakni proporsi jumlah perusahaan yang tidak mengalami financial distress yang berhasil diprediksi dengan benar.
Rumus untuk menghitungnya adalah:
Precision, proporsi jumlah perusahaan yang mengalami financial distress yang diidentifikasi dengan benar. Rumus untuk menghitungnya :
Overall Accuracy, yakni proporsi antara jumlah prediksi benar dengan jumlah keseluruhan obyek. Rumus untuk menghitungnya:
4. Tahap Analisis dan Interpretasi
Tahap ini merupakan tahap analisis dari pengolahan data yang dilakukan sebelumnya. Analisis hasil terdiri dari analisis penyeleksian variabel data, analisis hasil pengujian dengan Support Vector Machines, analisis hasil pengujian dengan Linear Discriminant Analysis, dan analisis perbandingan evaluasi kinerja dari kedua teknik tersebut.
5. Tahap Kesimpulan dan Saran
Tahap ini merupakan penarikan kesimpulan atas keseluruhan hasil dari langkah-langkah sebelumnya, serta memberikan saran untuk penelitian mendatang dan pihak-pihak yang berkepentingan.
HASIL DAN PEMBAHASAN
Berikut adalah beberapa hasil dari tahap preprocessing dan processing data: 1. Seleksi Variabel
Berdasarkan Tabel 1 hingga Tabel 3 dapat diketahui bahwa variabel awal yang digunakan dalam penelitian terdiri atas 21 variabel keuangan, 3 variabel non
keuangan, serta 4 variabel makroekonomi. Penelitian ini menggunakan laporan keuangan periode semesteran tahun 2010 hingga tahun 2011. Dengan demikian terdapat 112 variabel total selama empat periode penelitian. Guna mendapatkan informasi yang lebih dalam mengenai variabel yang signifikan mempengaruhi kondisi
financial distress, dilakukan seleksi variabel dengan metode LP-SVM. Berikut adalah hasil seleksi variabel berdasarkan metode LP-SVM:
Tabel 5 Hasil Seleksi Variabel
2010 2011
Sem I Sem II Sem I Sem II
WC_TA CF_TA QA_SL CL_SL CA_TA QA_TA QA_TA NI_SL
NI_TE NI_TA EB_TA GP_SL
COG_IN SL_AR SL_TA SL_AR
SL_AR CA_CL TL_TA TL_TA
CA_CL QA_TL SC BS
BS SC RT
SC RT
RT
Berdasarkan Tabel 5 diatas dapat diketahui bahwa terdapat 30 variabel yang akan menjadi input data dalam tahap konstruksi model selanjutnya. Berdasarkan Tabel 5 tersebut dapat diketahui bahwa varaibel yang siginifikan berpengaruh adalah varaibel keuangan dan non keuangan, sedangkan variabel makroekonomi tidak berpengaruh. 2. Membagi set data training dan data testing
Penelitian ini pada dasarnya membandingkan hasil prediksi pada kasus imbalanced data sets pada data aslinya dan balanced datasets melalui proses random oversampling.
3. Hasil pengujian dengan Teknik Support Vector Machines
Setiap set data, dilakukan uji SVM dengan menggunakan kernel linear dan kernel RBF. Hasil pengujian tersebut kemudian diukur dengan confussion matrix. Berikut adalah ringkasan hasil dari keempat set data tersebut dengan teknik SVM.
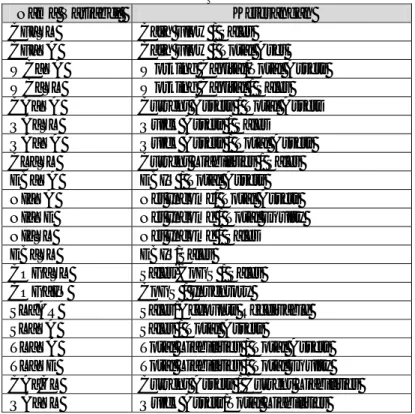
Tabel 6 Perbandingan Parameter Akurasi pada Empat Macam Set Data
Set Data Kernel P C Sensitivity Specificity Precision Overall
Accuracy Imbalanced RBF 4 1 0.5 0.7941 0.125 0.777 Oversampling 300% RBF 4 10 1 0.7419 0.7419 0.851 Oversampling 400% Linear 1 1 1 0.833 0.8571 0.9167 Oversampling 500% Linear 1 1 1 0.8333 0.8571 0.9167
Berdasarkan Tabel 6 diatas, dapat diketahui bahwa dari parameter akurasi memiliki nilai tertinggi dengan menggunakan set data yang telah diseimbangkan sebesar 400%.
4. Hasil Pengujian dengan Teknik Linear Discriminant Analysis
Selain menggunakan teknik SVM, teknik yang digunakan dalam memprediksi kondisi
financial distress pada penelitian ini adalah dengan LDA. Empat macam set data diuji dengan teknik tersebut, dan hasilnya dipaparkan dalam Tabel 7 sebagai berikut:
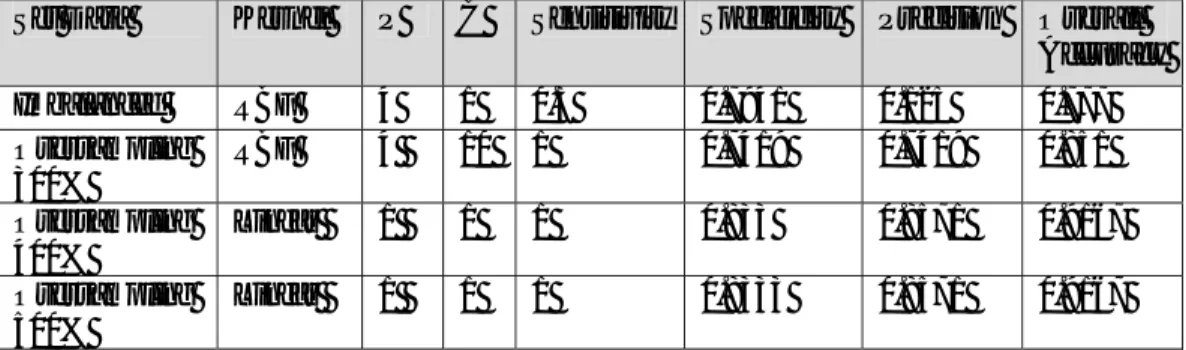
Tabel 7 Hasil Pengujian dengan Teknik LDA
Macam Set Data Sensitivity Specificity Precision Overall
Accuracy
Imbalanced Dataset 1 0.0625 0.1176 0.1667
Oversampling300% 1 1 1 1
Oversampling 400% 1 0.6 0.714286 0.8
Oversampling 500% 1 0.5667 0.73469 0.80303
Berdasarkan Tabel 7, hasil pengujian dengan teknik LDA memiliki akurasi tertinggi pada set data yang diseimbangkan dengan random oversampling 300%, sedangkan akurasi terendah didapatkan pada perhitungan dengan set data yang imbalanced. 5. Hasil Perbandingan dari kedua Teknik
Secara umum perbandingan rata-rata overall accuracy pada kedua teknik tersebut dipaparkan dalam Tabel 8 berikut ini:
Tabel 8 Perbandingan Rata-Rata Overall Accuracy dari SVM dan LDA
No Macam Set Data SVM LDA
1 Imbalanced Dataset 0.497 0.1667 2 Oversampling 300% Dataset 0.698 1 3 Oversampling 400% Dataset 0.775 0.8 4 Oversampling 500% Dataset 0.774 0.8
KESIMPULAN DAN SARAN
Adapun kesimpulan dari penelitian ini antara lain:
1. Penelitian ini merupakan studi komparasi prediksi financial distress pada perusahaan manufaktur go public di Indonesia, dengan menggunakan teknik SVM dan LDA. 2. Penelitian ini menggunakan set data awal yang merupakan imbalanced dataset, dan set
data yang diduplikasi dengan random oversampling sebesar 300%, 400% dan 500%. 3. Berdasarkan hasil seleksi, variabel yang siginifikan mempengaruhi financial distress
perusahaan manufaktur pada periode amatan penelitian adalah variabel keuangan dan non-keuangan, sedangkan variabel makroekonomi tidak memiliki kontribusi.
4. Baik pada teknik SVM maupun LDA, hasil akurasi terbaik dihasilkan dari set data yang imbang antara jumlah kelas positif dan kelas negatif.
Saran untuk penelitian selanjutnya yang membahas mengenai imbalanced datasets
adalah dapat menggunakan metode lain yang lebih mutakhir, sehingga hasil penelitian dapat dijadikan perbandingan. Bagi pihak-pihak yang berkepentingan seperti pemerintah, manajemen perusahaan dan pemegang saham, dapat menggunakan informasi tersebut agar dapat dijadikan bahan pertimbangan sebelum mengambil keputusan.
DAFTAR PUSTAKA
Almilia, L. S. (2004). Analisis Faktor-Faktor yang Mempengaruhi Kondisi Financial Distress Suatu Perusahaan yang Terdaftar di Bursa Efek Jakarta. Jurnal Riset Akuntansi Indonesia, Vol. 7, No.2, p. 1-22.
Altman, E. I. (1968). Financial Ratios Discriminant Analysis and The Prediction of Corporate Bankriptcy. Journal of Finance, Vol. 23, p. 589-609.
Beaver, W. (1966). Financial Ratios as Predictors of Failure, Journal of Accounting Research, Vol. 4,p. 71-111.
Chen, M.-Y. (2011). Bankruptcy Prediction in Firms with Statistical and Intelligent Techniques and a Comparison of Evolutionary Approaches, Computers and Mathematics with Aplications, Vol. 62, p. 4514-4524.
Ganganwar, V. (2012). An Overview of Classification Algorithms for Imbalanced Datasets.
International Journal of Emerging Technology and Advanced Engineering,Vol. 2, No. 4, p. 42-47.
Gong, R. dan Huang, S. H. (2012). A Kolmogorov-Smirnov Statistic Based Segmentation Approach to Learning from Imbalanced Datasets: With Application in Property Refinance Prediction. Expert Systems with Applications, Vol. 39, p. 6192-6200.
Hidayat, W. (2009). Analisis Financial Distress Perusahaan Manufaktur yang Listed Sebagai Dampak Krisis Ekonomi Asia. Jurnal Akuntansi, Manajemen Bisnis dan Sektor Publik, Vol. 5, No. 3, p. 304-323.
Iramani. (2008). Model Prediksi Financial Distress Perusahaan Go Public di Indonesia (Studi pada Sektor Manufaktur). Jurnal Aplikasi Manajemen, Vol. 6, No. 1.
Lin, F., Liang, D., dan Chen, E. (2011). Financial Ratio Selection for Business Crisis Prediction. Expert Systems with Applications, Vol. 38, p. 15094-15102.
Liu, Y., Yu, X., Huang, J. X., dan An, A. (2011). Combining Integrated Sampling with SVM Ensembles for Learning from Imbalanced Datasets. Information Processing and Management, Vol. 47, p. 617-631.
Ohlson, J. (1980). Financial Ratios and Probabilistic Prediction of Bankruptcy, Journal of Accounting Research, Vol. 18, p. 109-131.
Santosa, B. (2007). Data Mining: Teknik Pemanfaatan Data untuk Keperluan Bisnis, Graha Ilmu, Yogyakarta.
Sun, J. dan Li, H. (2009). Financial Distress Early Warning Based on Group Decision Making. Computers and Operations Research, Vol. 36, p. 885-906.
Tirapat, S. dan Nittayagasetwat, A. (1999). An Investigation of Thai Listed Firms' Financial Distress Using Macro and Micro Variables. Multinational Finance Journal, Vol. 3, No. 2, p. 103-125.
Zhou, L., Lai, K. K., dan Yen, J. (2012). Empirical Model Based on Features Ranking Techniques for Corporate Financial Distress Prediction. Computers and Mathematics with Applicatuions, Vol 64, p. 2484-2496.