BAB III TINJAUAN RAM
III.1 Tinjauan UmumReliability, Availability,danMaintainability (RAM) Reliability,Availability, dan Maintainability (RAM) merupakan tiga karakteristik dalam suatu sistem yang berhubungan dengan operasionalnya. Dalam program teknik rekayasa sistem (system engineering), Reliability, Availability, dan Maintainability(RAM) merupakan salah satu tinjauan yang sangat penting untuk memastikan bahwa sistem berada pada tingkat kondisi yang diinginkan seperti tingkat keselamatan (safety), performance, lingkungan, batasan waktu, dan tujuan ekonomis. Faktor-faktor yang mempengaruhi pentingnya RAM antara lain adalah desain sistem, mutu manufaktur, lingkungan dimana sistem dioperasikan, ditangani, disimpan, desain dan pengembangan sistem pendukung, tingkat pelatihan dan kemampuan dari personel yang mengoperasikan dan memelihara sistem, ketersediaan material yang dibutuhkan untuk merepair sistem, serta tujuan diagnosa dan peralatan yang tersedia. Pencapaian tingkat RAM yang spesifik pada suatu sistem sangat penting berkaitan dengan kesiapan (readiness), keselamatan sistem (system safety), kesuksesan misi (mission success), alokasi biaya (total cost), dan dukungan logistik (logistic support).
Bab 3 ini menguraikan konsep dan landasan teori yang mendasari RAM, pendefinisian sistem dan sub sistem, serta diagram blok kehandalan (Reliability Blok Diagram/RBD). Sebagai pendukung analisis digunakan Unavailability systemdanFault Tree Analysis(FTA).
III.2 Analisis Kehandalan (Reliability Analysis)
Metode analisis kehandalan dalam tesis ini berdasarkan pada analisis kualitatif atau analisis kuantitatif dengan mengacu kepada metode diagram blok kehandalan (Reliability Block Diagram/RBD). Diagram blok kehandalan diturunkan dari diagram blok fungsional yang telah dibangun dalam bab 2.
III.2.1 Dasar-dasarReliability
Reliabilitydidefinisikan sebagai suatu peluang bahwa suatu sistem atau komponen akan berfungsi selama rentang waktu t (Ref. 4). Ekspresi hubungan secara matematis, didefinisikan sebagai variabel acak kontinyu (continous random variable) T menjadi waktu kegagalan sistem atau komponen ; T ≥0. Reliability dapat dinyatakan sebagai :
R (t) = Pr{T≥t} (3-1)
dimana R(t)≥0, R(0) = 1
Untuk nilai t yang diberikan, R(t) adalah peluang bahwa waktu kegagalan adalah lebih besar atau sama dengan t, sehingga :
F (t) = 1 – R (t) = 1 - Pr{T≥t} = Pr{T < t} (3-2) dimana F(t)≥0, F(0) = 0
F(t) adalah peluang dimana suatu kegalan terjadi sebelum waktu t. Dengan mengacu kepada R(t) sebagai suatu fungsi reliability dan F(t) sebagai fungsi distribusi kumulatif (Cumulative Distribution Function/CDF) dari distribusi kegagalan. Fungsi ketiga disebut dengan fungsi kerapatan peluang (Probability Distribution Function/PDF) dan didefinisikan sebagai :
0 f t dt( ) 1
(3-3)
Fungsi ini menjabarkan bentuk karakteristik distribusi kegagalan. PDF atau f(t) mempunyai dua komponen :
f(t)≥0 dan 0
f t d t
( )
1
Dengan demikian : 0( )
t( ')
'
F t
f t
dt
(3-4)( )
( ')
'
tR t
f t
dt
(3-5)Dengan kata lain, baik fungsi kehandalan dan CDF merepresentasikan daerah di bawah kurva yang didefinisikan oleh f(t). Karena daerah di bawah seluruh kurva adalah sama dengan 1, kehandalan dan peluang kegagalan keduanya akan didefinisikan sebagai :
0≤R(t)≤1 dan 0≤F(t)≤1
Kedua fungsi R(t) dan F(t), digunakan saat dilakukan analisis kehandalan dan peluang kegagalan. Grafik PDF atau f(t), merupakan representasi visual dari distribusi kegagalan. Karakteristik kehandalan umumnya dihitung sebagai waktu rata-rata kegagalan sistem/komponen atau Mean Time Between Failure (MTBF). (Ref. 16 ). MTTF dirumuskan seperti persamaan 3-6 (Ref. 4).
0
(
)
( )
M T T F
E T
tf
t d t
(3-6) Dimana rata-rata (mean) adalah nilai yang diharapkan (expected value), dari distribusi peluang f(t), atau dapat juga menggunakan persamaan 3-7 :( )
o
M T T F
R t d t
(3-7) Selain fungsi peluang yang sudah disebutkan di atas, ada fungsi yang lain yang disebut dengan laju kegagalan (failure rate) atau hazard rate. Fungsi laju kegagalan memungkinkan untuk menetapkan jumlah kegagalan yang terjadi per unit waktu (Ref. 4).Laju kegagalan secara matematis dinyatakan dengan persamaan :
(
)
(
)
(
)
f
t
t
R
t
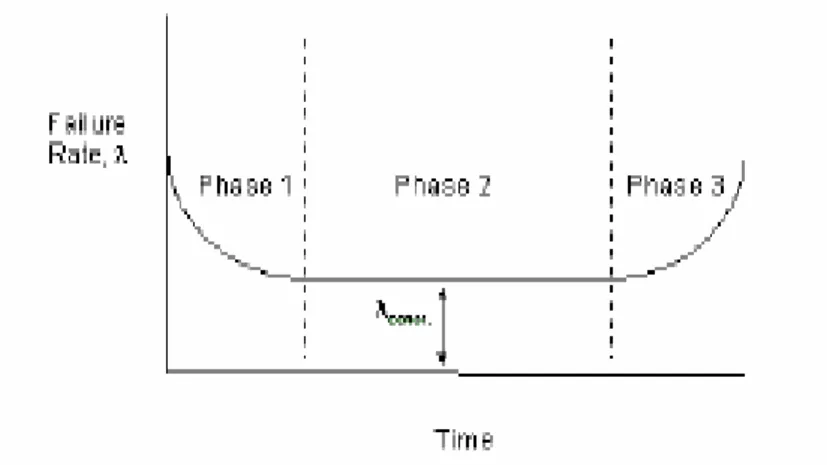
(3-8)Laju kegagalan suatu sistem pada awal periode operasi tinggi, kemudian menurun dengan nilai konstan, dan ditahap akhir meningkat kembali. Secara umum kurva laju kegagalan komponen yang berhubungan dengan waktu digambarkan dengan kurva bak mandi (bathtub curve). Tren kecenderungan kurva menurun
menggambarkan laju kegagalan komponen yang relatif tinggi pada awal dioperasikan/usia pakai (Life Cycle). Kegagalan prematur atau awal biasanya sering disebabkan oleh kesalahan dalam desain, pemasangan yang tidak tepat, pengoperasian oleh operator yang tidak terlatih dan lain-lain. Fase ini sering disebut dengan fase ’Burn-in’. Tahapan berikutnya adalah fase ’Useful Life’ atau sering disebut sebagai laju kegagalan konstan. Tahap ketiga adalah fase ’Wear-out’, dimana laju kegagalan meningkat seiring dengan meningkatnya kebutuhan pemeliharaan komponen.
Gambar III.1. Bathtub Curve (Ref. 4)
Secara singkat dapat dikatakan bahwa ketika suatu sistem bekerja, fase 1 dan 3 lebih banyak membutuhkan perawatan dan sumber daya, sedangkan fase 2 secara relatif lebih sedikit membutuhkan perawatan dan sumber daya yang dibutuhkan.
III.2.2 Sistem dan Subsistem
Pesawat merupakan suatu sistem yang kompleks, sehingga perlu digunakan cara pandang sistem (System View) untuk menggambarkan hubungan antar komponen dan memprediksi prestasi sistem dalam kondisi tertentu yang dipertimbangkan. Untuk itu diperlukan suatu pemodelan sistem yang dapat mendefinisikan atau merepresentasikan sistem sedemikian rupa, sehingga dapat menjelaskan suatu hubungan matematis atau hubungan logika tentang bagaimana suatu sistem merespon (input dan output). Karakteristik model sistem hanya mewakili beberapa fitur dan karakteristik dari sistem nyata.
Sistem didefinisikan sebagai suatu himpunan bagian yang saling berhubungan dan bekerja bersama-sama menuju suatu tujuan bersama. Elemen dari sistem terdiri dari komponen, atribut dan hubungan (relasi). Sistem dapat diklasifikasikan dalam 2 kelompok, yaitu sistem statis yang keadaannya tidak berubah terhadap waktu, dan sistem dinamis yang keadaannya berubah terhadap waktu (kontinyu, diskrit dan kombinasi). Berdasarkan definisi di atas, maka pesawat merupakan suatu sistem yang terdiri dari beberapa subsistem yang membentuk sistem, kemudian hubungan antar subsistem melahirkan suatu fungsi.
III.2.3 Metode Diagram Blok Kehandalan (Reliability Block Diagram/RBD)
Dalam analisisReliability, teknik yang paling banyak dipakai adalah menentukan kehandalan sistem dalam bentuk kehandalan komponennya. Metode diagram kehandalan merupakan metode yang menerapkan fungsi atau persamaan hukum-hukum logika kegagalan tiap-tiap komponen dan direpresentasikan dalam bentuk diagram blok. Diagram blok kehandalan bisa disusun secara seri, paralel ataupun standby. Pada sistem dengan beberapa komponen yang kompleks, diagram blok kehandalan merupakan diagram blok fungsional yang menggambarkan hubungan antar komponen dalam membentuk fungsi kerja dari sistem dan subsistem yang ada di pesawat secara keseluruhan. Diagram menyatakan suatu proses yang terjadi antara komponen-komponen utama terdiri dari masukan (input), proses rangkaian dan keluaran (output). Pembuatan diagram blok kehandalan dari sistem pesawat, dapat diturunkan dari prinsip kerja komponen dan sistem yang ada di pesawat, dengan asumsi sebagai penyederhanaan dari diagram blok fungsional. Penyusunan reliability block diagram dari komponen/sistem Pesawat C-130 Hercules selengkapnya dapat dilihat pada Lampiran B.
AnalisisReliability Block Diagrammengikuti pendekatan umum sebagai berikut : a. Menetapkan kriteria kegagalan
b. Menentukan Diagram BlokReliability c. Menganalisis modus kegagalan d. PerhitunganReliability sistem
III.2.4 Markov Model untuk Sistem yang Dapat Diperbaiki (Repairable Systems)
Dalam suatu analisis sering diasumsikan bahwa kegagalan komponen dan properti repair adalah saling independen. Pada kenyataannya, ini bukanlah keadaan yang sesungguhnya. Interaksi banyaknya komponen yang gagal (kegagalan independen), akan lebih efektif menggunakan proses markov, dimana laju kegagalan dan laju repair menggunakan pendekatan sebagai waktu independen. Teknik analisis markov, mengasumsikan bahwa laju kegagalan (λ) dan laju repair (μ) adalah konstan (Constant failure rate and constant repair rate). Untuk kasus distribusi lain (misalnya proses kegagalan Weibull atau waktu repair Log Normal), metode simulasi Monte Carlo lebih tepat digunakan.
Formulasi Markov didesain untuk semua kemungkinan tingkat keadaaan (t.k.) sistem (State). Tingkat keadaan didefinisikan menjadi suatu kombinasi sebagian dari komponen yang beroperasi dan yang gagal. Sebagai contoh jika sistem terdiri dari tiga komponen, maka ada 8 kombinasi t.k. yang berbeda untuk komponen yang beroperasi dan gagal. Tabel III.1 menyatakan t.k. markov (Markov state) untuk sistem dengan tiga komponen. Di mana O menunjukkan komponen yang beroperasi dan X adalah komponen yang gagal. Secara umum, sistem dengan N komponen akan mempunyai 2N tingkat keadaan, sehingga jumlah t.k. meningkat lebih cepat dibandingkan jumlah komponen.
Tabel III.1 Peluang Tingkat Keadaan Markov Sistem dengan 3 Komponen State (Tingkat Keadaan)
Komponen 1 2 3 4 5 6 7 8
a O X O O X X O X
b O O X O X O X X
c O O O X O X X X
Dalam melakukan analisis maka harus diketahui, mana t.k. yang berhubungan dengan kegagalan sistem. Hal ini tergantung kepada konfigurasi komponen yang digunakan, yaitu seri, paralel, atau kombinasi keduanya. Objek dari analisis Markov adalah menghitung Pi(t), yaitu peluang bahwa sistem dalam kondisi t.k i pada waktu t. Untuk menentukan Pi (t), diturunkan suatu set persamaan
differensial, satu untuk tiap t.k. sistem. Terkadang mengacu kepada persamaan transisi t.k. karena persamaan mengijinkan Pi (t) untuk ditentukan dalam bentuk laju dimana transisi dibuat dari satu t.k. ke t.k. lainnya. Laju transisi terdiri dari superposisi dari laju kegagalan komponen, laju repair atau keduanya. Dalam analisis Markov, peluang perubahan tingkat keadaan hanya bergantung pada tingkat keadaan itu sendiri. Jadi peluang kegagalan atau peluang reparasi tidak bergantung pada sejarah masa lalu sistem.
III.3 Maintainability Analysis
Maintainability didefinisikan sebagai jumlah kegiatan perawatan korektif dalam selang waktu tertentu dibagi dengan jumlah waktu perawatan total yang diperlukan untuk memperbaiki sistem. Dari definisi tersebut terlihat bahwa maintainability berbanding terbalik dengan Mean Time To Repair (MTTR). Dengan demikian dalam hubungannya untuk meningkatkan availability, kedua faktor reliability dan maintainability harus diperbaiki. Hal ini mengasumsikan bahwa hal-hal lain yang mungkin menyebabkan waktu penundaan (delay time) yang berlebihan dapat dihilangkan.
III.3.1 Dasar-dasarMaintainability
Tujuan dari analisis maintainability adalah meningkatkan efisisensi dan safety serta mengurangi biaya pemeliharaan peralatan berdasarkan kondisi, prosedur dan sumber daya yang telah ditetapkan. Persyaratanmaintainability antara lain :
a. Penentuan definisi perencanaan yang meliputi seluruh dokumentasi perencanaan untuk program yang ditentukan.
b. Dikhususkan bagi kategori top-level dengan produk/sistem yang dapat diaplikasikan.
c. Didesain melalui proses iteratif dari analisi fungsional, alokasi persyaratan, trade-off dan optimasi, sintesis dan pemilihan komponen.
Untuk menentukan waktu repair, tentukan T sebagai variabel acak kontinyu yang merepresentasikan waktu repair suatu unit kegagalan yang mempunyai fungsi kerapatan kegagalan h(t). Fungsi distribusi kumulatif dirumuskan (Ref. 4) :
0
P r{
T
t
}
H t
( )
th t
( ')
d t
'
(3-9) Persamaan yang menyatakan bahwa waktu suatu repair akan diselesaikan dalam waktu t (MTTR), selanjutnya dirumuskan dalam persamaan :0
( )
t{1
( )}
M T T R
th t d t
H t
d t
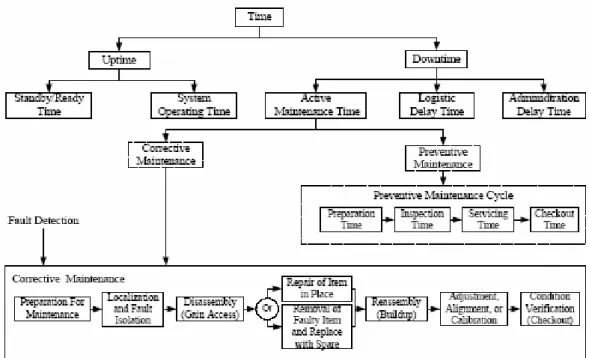
(3-10) Maintainabilitymempunyai lingkup definisi yang paling luas, dapat diukur dalam bentuk kombinasi dari beberapa faktor yang berbeda. Dari perspektif sistem, pemeliharaan diasumsikan menjadi 2 kategori :a. Pemeliharaan Korektif (Corrective Maintenance), yaitu melakukan pemeliharaan tidak terjadwal, untuk mengembalikan suatu sistem/produk ke kondisi semula setelah terjadi kegagalan, termasuk kemungkinan melakukan modifikasi.
b. Pemeliharaan Preventif (Preventive Maintenance), yaitu melakukan pemeliharaan terjadwal untuk menjaga suatu sistem pada tingkat performa yang diinginkan melalui serangkaian tindakan sistematis seperti, inspeksi, deteksi, servicing, atau pencegahan kegagalan melalui penggantian komponen secara periodik.
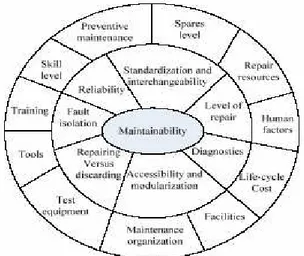
Ada beberapa konsep yang harus diikuti sebagai bagian dari aktifitas desain yang mendukung untuk mengurangi wakturepair. Lingkaran dalam pada gambar III.2 merupakan fitur desain inherent maintainability dan lingkaran luar merupakan fitur sekunder yang mempengaruhi totaldowntimesistem. Faktor-faktor sekunder yang mempengaruhi maintainability difokuskan pada pemeliharaan dan suplai komponen yang dibutuhkan untuk mendukung proses repair. Memelihara suplai komponen pada tingkat yang tepat merupakan bagian dari proses logistik.
III.3.2 Down Time Analysis
Downtime merupakan total waktu yang dibutuhkan (ketika sistem tidak beroperasi) untuk merepair dan mengembalikan sistem kepada status operasi sepenuhnya. Dalam prakteknyadow timemempunyai paling tidak dua komponen. Komponen pertama adalah waktu tunggu datangnya sukucadang melalui rantai suplai (logistic downtime). Komponen kedua adalah waktu repair, yang terdiri dari waktu maintenance. Sedangkan Mean Downtime (MDT) didefinisikan sebagai selang waktu tak beroperasi rata-rata, yaitu jumlah waktu yang diperlukan untuk memperbaiki produk sampai mencapai kondisi yang dapat dirawat. Gambar III.3 dan III.4 menggambarkan hubungan variasi faktordowntime dalam konteks total waktu serta pernjelasan dari elemen dan aktifitasdowntime.
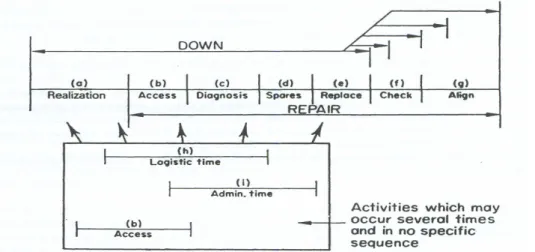
Gambar III.4 Elemen Down Time dan Repair Time (Ref. 6)
a. Realization Time, waktu yang hilang sebelum kondisi kegagalan menjadi kenyataan. Elemen ini termasuk pada availability, akan tetapi bukan merupakan bagian darirepair time.
b. Access Time,termasuk waktu dari realisasi bahwa suatu kegagalan terjadi, untuk membuat kontak antara displai dan titik pengujian serta menemukan kegagalan, yang berhubungan dengan peralatan uji dan faktor desain. c. Diagnosis Time, mengacu pada penemuan kegagalan dan termasuk
pengaturan peralatan uji, pengecekan, interpretasi dari informasi yang didapat, verifikasi kesimpulan dan keputusan tindakan korektif.
d. Spare Part Procurement, penyiapan komponen berupa ’Tool Box’, baik kanibalisasi atau mengambil komponen identik dari bagian sistem lain. Waktu untuk memindahkan komponen dari suatu depot atau gudang kepada sistem tidak termasuk, karena merupakan bagian darilogistic time. e. Replacement Time, pembongkaran sistem LRA (Least Replaceable
Assembly) dan sambungan/wiring, sebagai bagian dari penggantian. LRA adalah item yang dapat diganti setelah diagnosis kesalahan tidak berlanjut. Waktu penggantian sebagian besar tergantung pada pemilihan LRA dan fitur desain mekanis, seperti pemilihanconnector.
f. Checkout Time, kondisi dimana kegagalan sudah teratasi dan sistem mulai beroperasi. Pengembalian sistem ke operasi sebelum penyelesaian pengecekan merupakan aktivitas repair, dan tidak secara keseluruhan merupakan bagian daridowntime.
g. Alignment Time, hasil dari memasukkan suatu modul baru kedalam pengaturan sistem yang mungkin disyaratkan. Seperti kasus checkout, beberapa atau seluruhalignmenttidak termasukdowntime.
h. Logistic Time, waktu yang dikonsumsi untuk menunggu spares, penambahan peralatan dan sumber daya manusia yang dibutuhkan sistem. i. Administrative Time,adalah suatu fungsi organisasi pengguna sistem. Jenis
aktifitas termasuk pelaporan kegagalan (berdampak pada downtime), alokasi tugas-tugas repair, pergantian sumber daya manusia yang melakukan pengaturan demarkasi,official breaks,disputes, dan lain-lain.
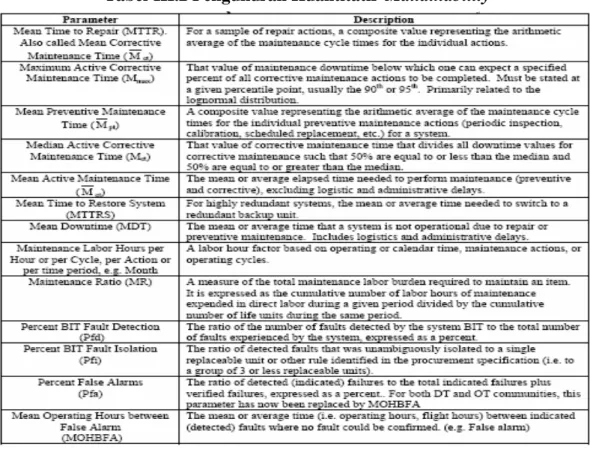
Banyak parameter digunakan untuk maintainability, seperti maximum time to repair (MTTR), danmaintenance ratio (MR). Tabel III.2 berisi daftar beberapa pengukuran kuantitatif yang berkaitan dengan waktu. Maintainabilitymerupakan suatu fungsi menemukan kegagalan dimana diagnosis itu penting, pengukurannya seperti, efektifitas pengujian, deteksi kesalahan, dan laju kesalahan sinyal/indikator. Selain itu faktor ekonomis dan kemudahan pemeliharaan yang secara tidak langsung diukur dengan aksessibilitas, keakuratan diagnosa, tingkat standarisasi, dan hal-hal yang berkaitan dengan faktor manusia.
III.4 AvailabilityAnalysis
Pengukuranreliabilitymemang memberikan petunjuk yang jelas tentang frekuensi kesuksesan komponen/sistem dalam menjalankan fungsinya, akan tetapi interval waktu produk tak dapat dipakai setelah kegagalan tidak dapat diukur. Konsep availability dikembangkan untuk mengatasi keterbatasan ini, dengan mengukur jumlah waktu produk dalam keadaan operasional.
III.4.1 Dasar-dasarAvailability
Availability adalah peluang suatu sistem/komponen untuk melaksanakan fungsinya berdasarkan periode waktu yang ditetapkan ketika dioperasikan dan di maintainsesuai tatacara yang telah ditentukan (Ref. 4). Seperti halnya reliability, availability menentukan peluang suatu sistem yang dinyatakan dalam satu dari dua kondisi, yaitu : ‘uptime (on)’ dan ‘downtime (off)’. Uptime berarti bahwa sistem masih berfungsi dandowntimeberarti bahwa sistem tidak berfungsi, dalam hal ini diperbaiki atau diganti tergantung pada apakah sistem dapat diperbaiki atau tidak. Kondisi sistem dinyatakan dalam variabel biner :
1, Jika sistem beroperasi pada waktu t X(t) =
0, sebaliknya
Ada 4 hal penting dalam mengukur tingkatavailability, yaitu : fungsiavailability, batasanavailability, rata-rata fungsi availability, dan batasan rata-rataavailability. Keempat hat tersebut berdasarkan pada fungsi X(t), yang menyatakan status sistem dapat direpair dalam waktu t. A t( )P X t( ( ) 1)
III.4.2 Inherent Availability(Ai)
Inherent Availability adalah peluang bahwa suatu sistem, ketika dioperasikan sesuai dengan kondisi yang ditentukan serta ideal (tools, sukucadang, dan personel pemeliharaan tersedia), akan beroperasi dengan baik pada waktu yang ditentukan. Termasuk tindakan preventif atau pemeliharaan terjadwal, waktu tunda logistik, dan waktu tunda administrasi.
Inherent Availabilitydidasarkan kepada distribusi kegagalan dan distribusi waktu repair, atau dapat dipandang sebagai suatu parameter desain peralatan, yang menghubungkan antarareliabilitydan maintainability.
( ) i t MTBF A LimA t MTBF MTTR (3-11)
III.4.3 Achieved Availability(Aa)
Achieved Availability adalah peluang bahwa suatu sistem atau peralatan, ketika digunakan sesuai dengan kondisi yang ditetapkan yaitu dukungan lingkungan yang ideal (tools, sukucadang, dan personel pemeliharaan tersedia), akan beroperasi dengan baik disetiap waktu.
a MTBM A MTBM M (3-12)
Dimana : MTBM adalah pemeliharaan terjadwal dan tidak terjadwal, M adalah waktu rata-rata pemeliharaan aktif.
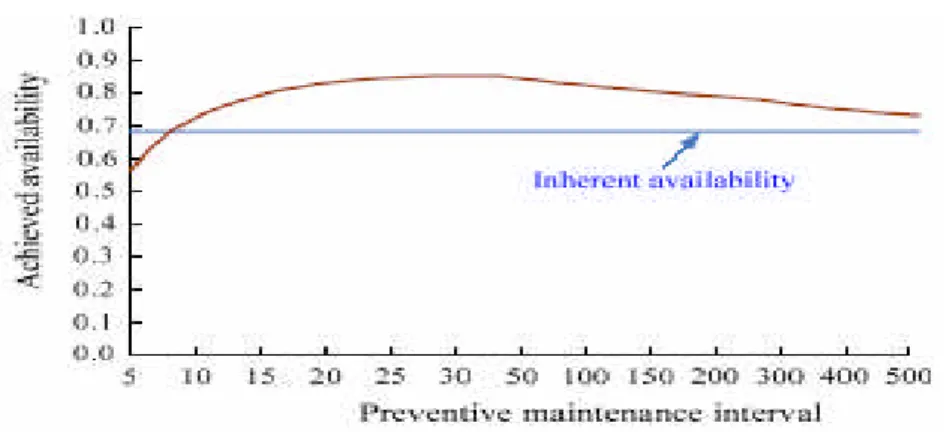
Jika preventive maintenance dilakukan terlalu sering dapat berdampak negatif pada Aa, meskipun itu meningkatkan MTBF. Gambar III.5 menunjukkan perubahan Aa sebagai suatu fungsi interval pemeliharaan preventif untuk suatu kasus yang spesifik. Interval pemeliharaan preventif yang terlalu singkat menaikkan frekuensi downtime sehingga availability lebih rendah dari inherent availability. Peningkatan interval pemeliharaan preventif, maka Aa akan mencapai titik maksimum dan secara umum mendekati Ai.
III.4.4 Operasional Availability(Ao)
Pengukuran yang tepat sebagai dampak dimasukkannya faktor desain dan sistem pendukung pada availability adalah operasional availability (A0). Operational availability didefinisikan sebagai peluang bahwa suatu sistem, ketika digunakan sesuai kondisi yang ditetapkan dalam lingkungan operasional sesungguhnya, akan beroperasi dengan baik (Ref. 16). Persamaan yang berhubungan dengan A0 diberikan seperti table III.3. Persamaan ini disebut dengan persamaan kondisi tunak (steady state) untukoperasional availability. Persamaansteady statehanya terjadi pada waktu yang sangat lama atau ketika sistem mencapai kondisisteady. Jika berhubungan dengan durasi waktu yang sangat singkat, seperti 3 atau 7 hari misi, makaavailability tidak akan mencapai kondisisteady. Simulasi digunakan untuk menghitung operasional availability. Setelah suatu sistem digunakan, jumlah jam dimana sistem dinyatakan ‘Up’ (mampu melaksanakan semua fungsi/misi yang disyaratkan) dan total jumlah jam yang hilang untuk menjadikan system ‘Up’ dalam setiap interval kalender dapat diukur.
Operasional availabilitydapat dinyatakan dengan persamaan berikut (Ref. 8) :
o MTBM A MTBM MDT (3-13) atau :
Dimana : Mean Downtime (MDT) adalah rata-rata downtime pemeliharaan, termasuk waktu pemeliharan (M ), waktu penundaan logistik, dan waktu penundaan administratif
Total Time adalah waktu total yang dibutuhkan sistem untuk Up selama interval kalender yang diberikan. (Total Time = Uptime + Downtime)
Uptime A0 =
Total Time
Tabel III.3 Perbandingan Inherent Availability (Ai) dan Operasional Availability (A0) (Ref. 8)
III.5 Unavailability System
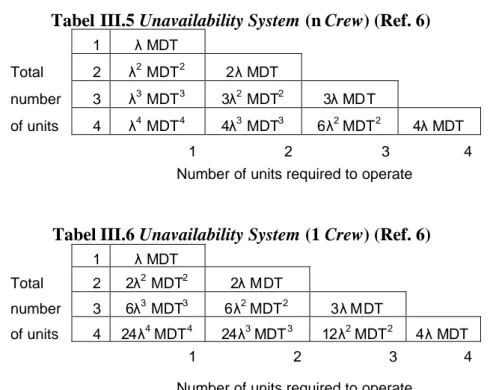
Teknik analisis Markov juga dapat diterapkan untuk menghitung unavailability sistem pada kondisi tunak (steady state), dengan memperhitungkan pemulihan dari kondisi tingkat keadaan sistem yang gagal. Unavailability sistem adalah peluang berada pada tingkat keadaan yang gagal. Unavailability system dapat diformulasikan dari ringkasan hasil dan pendekatan (approximation) untuk lingkup kasus redundan dan repair. Kasus ncrew repairMDTsystemadalah unit MDT dibagi dengan jumlah item yang diperlukan untuk gagal. Tabel III.5 didapatkan dengan mengalikan laju kegagalan (λ) sistem dengan MDT/(jumlah kegagalan). Untuk kasus single repair crew MDT sistem akan sama seperti unit MDT. Tabel III.6 didapatkan dengan mengalikan laju kegagalan sistem (1crew) dengan MDT.
Tabel III.5Unavailability System(nCrew) (Ref. 6)
1 λ MDT
Total 2 λ2MDT2 2λ MDT
number 3 λ3MDT3 3λ2 MDT2 3λ MDT
of units 4 λ4MDT4 4λ3 MDT3 6λ2MDT2 4λ MDT
1 2 3 4
Number of units required to operate
Tabel III.6Unavailability System(1Crew) (Ref. 6)
1 λ MDT
Total 2 2λ2 MDT2 2λ MDT
number 3 6λ3 MDT3 6λ2MDT2 3λ MDT
of units 4 24λ4MDT4 24λ3MDT3 12λ2MDT2 4λ MDT
1 2 3 4
Number of units required to operate
Akan tetapi, penting untuk diingat bahwa kedua tabel diatas dikembangkan atas dasar asumsi bahwa system MDT adalah sama dengan unit MDT, karena pada kenyataanya kasusnya akan berbeda. Terkadang kegagalan sistem adalah skenario yang berbeda secara total untuk unit kegagalan yang direparasi.
III.6 Fault Tree Analysis(FTA)
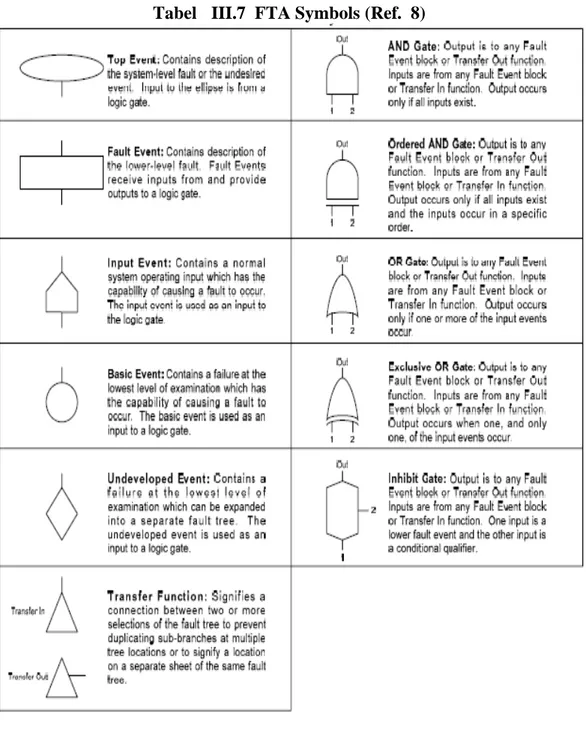
Analisis pohon kesalahan (Fault Tree Analysis/FTA) adalah suatu metode grafis untuk menggambarkan kombinasi kejadian-kejadian (events) yang memicu suatu kegagalan sistem. Dalam terminologi pohon kesalahan modus kegagalan sistem disebut sebagai kejadian puncak (Top Event). FTA secara khusus melibatkan tiga kemungkinan logis dan dua simbol utama. Input dibawah gate merepresentasikan kegagalan. Ouput (at the top)gate merepresentasikan suatu propagasi kegagalan tergantung pada bentuk dasargate. Tiga tipegateadalah :
Or Gate : Setiap input yang menyebabkan output terjadi
And gate : Semua input yang dibutuhkan terjadi agar output terjadi Voted Gate : Sama dengan and gate, menggambarkan dua atau lebih
input dibutuhkan agar output terjadi.
Failure Rate“And Gate” : sebenarnya adalahVoted gate sebagai contoh 2 dari 3.
λ1 x λ2 x ……..λn (MDT1+ MDT2+ ………..MDTn) (3-15)
Failure Rate “OR Gate” : Menambahkan laju kegagalan pada input, dimana peningkatan dari output OR gate akan menjadi input yang meningkat bagi gate yang lain
λ1+ λ2+ ……..λn (3-16)
MDT “And Gate” : Adalah perkalian dari individu MDT dibagi dengan penjumlahannya
(MDT1x MDT2x ……..MDTn)
(MDT1+ MDT2+ ……..MDTn)
MDT “OR Gate” : Jika MDT dari dua inputgatedibawahnya tidak identik maka diperlukan untuk menghitung MDT ekuivalen. Pembobotan rata-rata dari dua MDT oleh laju kegagalan
(MDT1 xλ1) + (MDT2xλ2) + ………… + (MDTnxλn) (λ1+λ2+ ……..λn)
(3-17)