PERANCANGAN APLIKASI DATA MINING UNTUK ANALISIS KEMUNGKINAN PENGUNDURAN DIRI CALON MAHASISWA BARU
(STUDI KASUS STMIK SUMEDANG)
Sri Bekti Handayani N, S.T., M.Kom. Dosen Jurusan Sistem Informasi STMIK Sumedang
Email : [email protected]
Abstrak
Penerimaan mahasiswa baru merupakan aktifitas yang rutin dilakukan oleh sebuah perguruan tinggi. Setiap tahun kegiatan ini dilakukan dengan berbagai strategi untuk mendapatkan hasil yang optimal yaitu dengan penggunaan teknologi informasi dan sistem informasi. Pada kegiatan penerimaan mahasiswa baru banyak permasalahan yang terjadi, salah satunya adalah pengunduran diri calon mahasiswa baru. Berdasarkan permasalahan tersebut, maka dibuatlah perancangan aplikasi data mining clasification untuk data penerimaan mahasiswa baru di STMIK Sumedang yang bertujuan merancang pengolahan data mining dengan mengelompokan data pendaftaran mahasiswa baru berdasarkan NEM, jenis kelamin, asal sekolah, jurusan, gelombang, pilihan 1, pilihan 2, catatan, nilai, agama, lulus_jur, propinsi, kabupaten. Adapun manfaat dari penelitian ini adalah menghasilkan pengklasifikasian data berdasarkan NEM, jenis kelamin, asal sekolah, jurusan, gelombang, pilihan 1, pilihan 2, catatan, nilai, agama, lulus_jur, propinsi, kabupaten sehingga dapat digunakan untuk menganalisis kemungkinan pengunduran diri calon mahasiswa baru. Metode yang digunakan untuk membangun data mining pada penelitian ini adalah clasification
dengan menggunakan algoritma C45 yang terdiri dari Identifikasi masalah,
pengumpulan data, explore, clean, dan preprocess data, ekstraksi data, mendefinisikan tugas data mining, memilih teknik data mining yang digunakan, membuat algoritma C4.5, menginterpretasikan hasil algoritma, perancangan sistem data mining. Kesimpulan dari penelitian ini adalah bahwa pada setiap tahunnya terjadi pengunduran diri calon mahasiswa baru maka dari itu dengan klasifikasi dari kumpulan data calon mahasiswa yang ada dapat memprediksi kemungkinan terjadi pengunduran diri calon mahasiswa baru sehingga pihak manajemen perguruan tinggi dapat melakukan tindakan-tindakan yang diperlukan untuk mempertahakan calon-calon mahasiswa tersebut.
Kata kunci : data mining, PMB, C45 PENDAHULUAN
a. Latar Belakang
Penerimaan mahasiswa baru merupakan aktifitas yang rutin dilakukan oleh sebuah perguruan tinggi. Setiap tahun kegiatan ini dilakukan dengan berbagai strategi untuk mendapatkan hasil yang optimal yaitu dengan penggunaan teknologi informasi dan sistem informasi. Banyak permasalahan yang terjadi, salah satunya adalah pengunduran diri calon mahasiswa baru. Jika dapat ditanggulangi sejak dini tentunya pihak manajemen perguruan tinggi dapat melakukan tindakan-tindakan yang diperlukan
untuk mempertahakan calan-calon mahasiswa tersebut. Selama ini ada kesulitan dalam menganalisis sekumpulan data calon mahasiswa, dikarenakan item data yang bercampur dalam satu tabel. Salah satu cara untuk melakukan analisis kemungkinan pengunduran diri seorang calon mahasiswa baru adalah dengan melakukan klasifikasi dari sekumpulan data calon mahasiswa yang ada. Dengan demikian diperlukan sebuah sistem yang dapat mengolah data tersebut sehinggan membantu pihak yang berkepentingan untuk dengan informasi penerimaan mahasiswa baru tersebut untuk megumpulkan informasi-informasi tersebut berupa pengelompokan calon mahasiswa berdasarkan NEM, jenis kelamin, asal sekolah, jurusan, gelombang, pilihan 1, pilihan 2, catatan, nilai, agama, lulus_jur, propinsi, kabupaten, sehingga dapat digali knowledge kemungkinan calon mahasiswa yang mengundurkan diri dengan cara tidak melakukan registrasi karena berdasarkan kriteria yang telah disebutkan di atas. Berdasarkan latar belakang yang diuraikan, maka diperlukan sistem pengolahan data pendaftaran mahasiswa baru (PMB) yang didukung data mining dengan metode clasification sehingga dapat membantu dalam menarik kesimpulan dengan cara menampilkan hasil informasi yang tergali setelah dilakukan proses clasification. Data yang telah mengalami proses clasification akan ditampilkan dalam bentuk pengelompokan data dari sekumpulan kriteria, sehingga dapat memberikan informasi hasil dari aplikasi berupa detail klasifikasi yang terbentuk
b. Ruang lingkup
Ruang lingkup dibatasi pada : a. Input :
1. Data yang dipakai adalah data NEM, jenis kelamin, asal sekolah, jurusan, gelombang, pilihan 1, pilihan 2, catatan, nilai, agama, lulus_jur, propinsi, kabupaten
2. Ruang lingkup data adalah pada jurusan Sistem Informasi STMIK Sumedang
b. Proses :
1. Hasil input akan dikelompokan berdasarkan NEM, jenis kelamin, asal sekolah, jurusan, gelombang, pilihan 1, pilihan 2, catatan, nilai, agama, lulus_jur, propinsi, kabupaten
2. Metode yang digunakan adalah clasification dengan menggunakan algoritma C45
3. Pemilihan variabel, melakukan pra-proses dengan cara mengelompokan nilai nilai, menterjemahkan nilai pilihan1,pilihan2, lulus_jur, agama, c. Output
Menampilkan data berdasarkan klasifikasi registrasi dan non registrasi c. Tujuan
Tujuan dari penelitian ini adalah :
Merancang aplikasi data mining dengan mengelompokan data pendaftaran mahasiswa baru berdasarkan NEM, jenis kelamin, asal sekolah, jurusan, gelombang, pilihan 1, pilihan 2, catatan, nilai, agama, lulus_jur, propinsi, kabupaten.
d. Metode Penelitian
Metode yang digunakan untuk membangun data mining pada penelitian ini adalah Decision Trees dengan algoritma C4.5. Adapun tahapan yang dilakukan untuk membangun data mining pada penelitian ini terdiri dari :
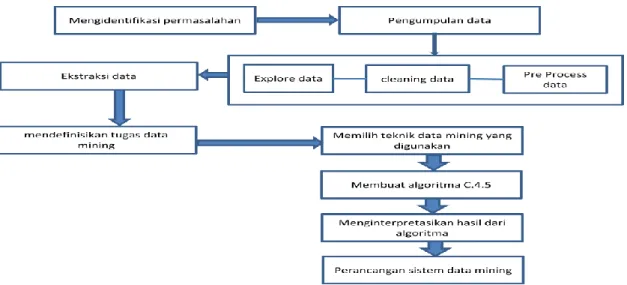
Gambar 1. Skema metode data mining a. Identifikasi Masalah
Adalah proses membangun pemahaman dalam membangun proyek data mining dengan cara memberikan jawaban dari berbagai pertanyaan
b. Pengumpulan Data
Adalah proses mendapatkan sekumpulan data yang akan digunakan untuk dianalisis. Proses pengumpulan data dilakukan dengan pencarian dari database yang berbeda berasal dari internal dan eksternal organisasi.
c. Explore, clean, dan preprocess data. Melakukan verifikasi bahwa data dalam kondisi yang baik, pembersihan data (data cleaning), pengumpulan informasi yang diperlukan untuk memodelkan, penentuan strategi untuk menangani field data yang hilang, dan pencatatan informasi urutan waktu dan perubahan yang diketahui.
d. Ekstraksi data, meliputi penentuan fitur penting untuk merepresentasikan data bergantung pada tujuan, dan menggunakan reduksi dimensionalitas atau metode-metode transformasi untuk mengurangi banyaknya variabel efektif di bawah pertimbangan, atau menemukan representasi invarian bagi data
e. Mendefinisikan Tugas Data mining
Menentukan representasi model yang sesuai dengan apa yang akan dilakukan oleh data mining, dan kemudian ditentukan algoritma untuk menemukan model.
f. Memilih teknik data mining yang digunakan
Memilih teknik data mining yang sesuai dengan tugas data mining yang telah didefinisikan
Melakukan pendefinisian atribut sebagai root, kemudian membuat cabang untuk tiap nilai, membagi kasus dalam cabang, dan berulang sampai cabang memiliki kelas yang sama.
h. Menginterpretasikan hasil algoritma.
dalam proses ini pola-pola yang telah diidentifikasi oleh sistem kemudian diterjemahkan ke dalam bentuk knowledge yang lebih dimengerti oleh user untuk dapat membantu mengambil keputusan, misalnya dengan menunjukkan item yang saling berasosiasi melalui tampilan yang lebih mudah untuk dimengerti.
i. Perancangan sistem data mining
Pada proses ini dilakukan perancangan basis data dan perancangan antar muka sistem data mining untuk pengguna.
PEMBAHASAN
Teori tentang belum ada : Data mining
Algoritma C.45
a. Identifikasi Masalah
Pada penelitian ini akan dibangun perancangan aplikasi data mining clasification untuk data penerimaan mahasiswa baru STMIK Sumedang. Rancangan aplikasi data mining ini memberikan bentuk informasi pengklasifikasian data calon mahasiswa baru dengan tujuan untuk menganalisis kemungkinan pengunduran diri calon mahasiswa baru yang sering terjadi selama beberapa tahun terakhir ini. Dengan menggunakan output dari aplikasi data mining ini, yang berupa item-item dari yang telah terklasifikasi (clasification), pengambil keputusan dapat mengetahui informasi “tersembunyi” yang tersimpan pada kelompok-kelompok tersebut. Klasifikasi data dapat menunjukan keputusan “Registrasi” pada calom mahasiswa baru.
b. Pengumpulan Data
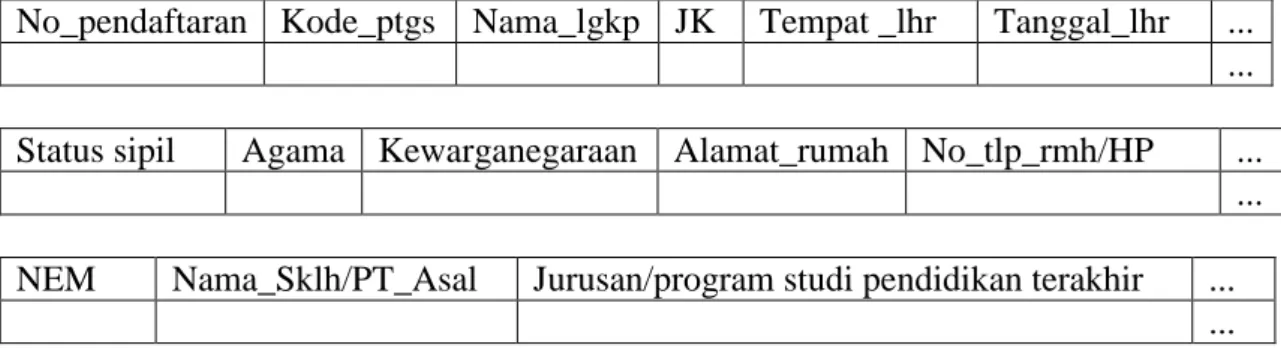
Pengumpulan data dilakukan di bagian administrasi penerimaan mahasiswa baru. Saat ini bagian administrasi penerimaan mahasiswa baru sudang menggunakan sistem komputerisasi untuk mencatat segala kegiatan penerimaan mahasiswa baru di lingkungan STMIK Sumedang. Setiap calon mahasiswa mempunya data no identitas berupa no.pendaftaran. setiap calon mahasiswa mempunyai catatan mengenai nama lengkap, tempat lahir, tanggal lahir, JK, status sipil, agama, kewarganegaraan, alamat lengkap rumah, no telpon/HP, pendidikan terakhir, NEM, nama sekolah/perguruan tinggi asal, jurusan/program studi pendidikan terakhir, pilihan 1, pilihan2, persyaratan, registrasi pembayaran, status registrasi.
Tabel 1. Format asli data calon mahasiswa
No_pendaftaran Kode_ptgs Nama_lgkp JK Tempat _lhr Tanggal_lhr ... ... Status sipil Agama Kewarganegaraan Alamat_rumah No_tlp_rmh/HP ...
... NEM Nama_Sklh/PT_Asal Jurusan/program studi pendidikan terakhir ...
Pil_jurusan Biaya_pendaftaran UPP SPP Persyaratan Status_tes ... ... Nilai Ket_lulus No_rek NPM Jur_lulus Jaket Buku_panduan ...
...
Stat_transfer Dispensasi Thn_akademik NamaProp NamaKab Registrasi Sumber : data PMB STMIK Sumedang 2014
Dari data-data tersebut, kolom yang diambil sebagai variabel keputusannya adalah kolom Registrasi, sedangkan kolom yang diambil sebagai variabel penentu dalam pembentukan pohon keputusan adalah kolom NEM, JK, Nama_Sklh/PT_Asal, Pilihan_1, Pilihan_2, Nilai, agama, Jur_lulus, NamaProp, NamaKab.
c. Melakukan Pra Proses
Dari hasil pengumpulan data, selanjutnya dilakukan proses ekstraksi data yaitu penentuan fitur penting untuk merepresentasikan data bergantung pada tujuan, dan menggunakan reduksi dimensionalitas atau metode-metode transformasi untuk mengurangi banyaknya variabel efektif di bawah pertimbangan, atau menemukan representasi invarian bagi data. Sehingga didapatkan data-data yang terpilih dengan format, sbb :
Tabel 2 Format data calon mahasiswa hasil pemilihan
NEM JK Nama_Sklh/PT_Asal Jurusan/program studi pend.terakhir ... ... Pil_jur Nilai Agama Jur_lulus NamaProp NamaKab Registrasi
Dari hasil ekstraksi data, kemudian dilakukan pra-proses sebagai berikut : 1) Pengelompokan berdasarkan NEM
Tabel 3. Pengelompokan berdasarkan NEM NEM Klasifikasi 0 – 5 1 5 – 6 2 6 – 7 3 7 – 8 4 8 – 9 5 9- 10 6
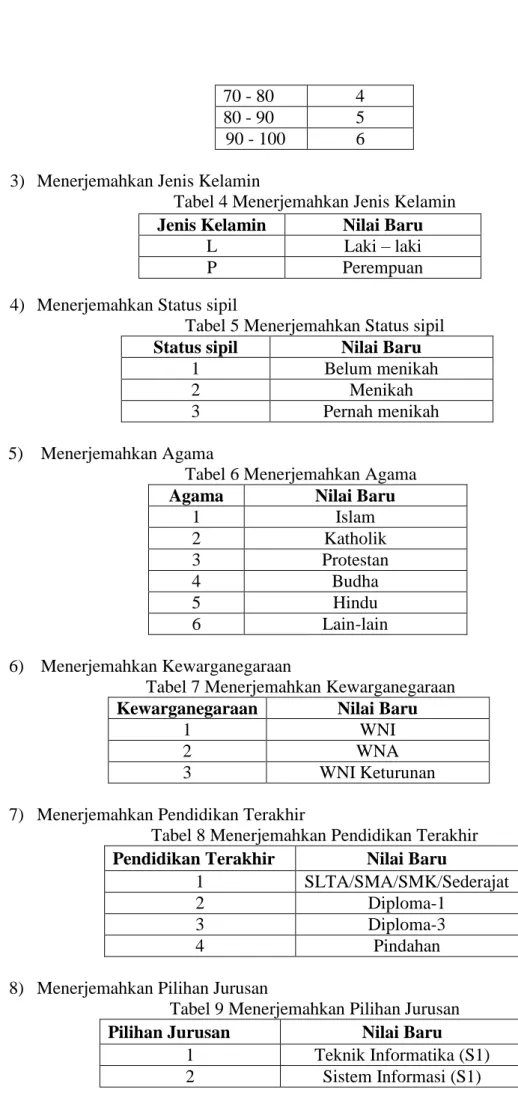
2) Pengelompokan berdasarkan Nilai
Tabel 4 Pengelompokan berdasarkan Nilai NEM Klasifikasi
0 - 50 1
0 - 60 2
70 - 80 4
80 - 90 5
90 - 100 6
3) Menerjemahkan Jenis Kelamin
Tabel 4 Menerjemahkan Jenis Kelamin
4) Menerjemahkan Status sipil
Tabel 5 Menerjemahkan Status sipil Status sipil Nilai Baru
1 Belum menikah
2 Menikah
3 Pernah menikah
5) Menerjemahkan Agama
Tabel 6 Menerjemahkan Agama
Agama Nilai Baru
1 Islam 2 Katholik 3 Protestan 4 Budha 5 Hindu 6 Lain-lain 6) Menerjemahkan Kewarganegaraan
Tabel 7 Menerjemahkan Kewarganegaraan Kewarganegaraan Nilai Baru
1 WNI
2 WNA
3 WNI Keturunan
7) Menerjemahkan Pendidikan Terakhir
Tabel 8 Menerjemahkan Pendidikan Terakhir Pendidikan Terakhir Nilai Baru
1 SLTA/SMA/SMK/Sederajat
2 Diploma-1
3 Diploma-3
4 Pindahan
8) Menerjemahkan Pilihan Jurusan
Tabel 9 Menerjemahkan Pilihan Jurusan
Pilihan Jurusan Nilai Baru
1 Teknik Informatika (S1)
2 Sistem Informasi (S1)
Jenis Kelamin Nilai Baru
L Laki – laki
3 Manajemen Informatika (D3)
9) Menerjemahkan Persyaratan
Tabel 10 Menerjemahkan Persyaratan Persyaratan
(umum/lanjutan/pindahan Nilai Baru
1 FC STTB/Ijazah 3lbr
2 FC KTP 1Lbr
3 Pas Photo berwarna 3x4 dan 2x3 @4lbr
4 Surat Izin dari Atasan (Karyawan 5 FC Ijazah Pendidikan Terakhir
3lembar
6 FC Transkrip Nilai 3lembar
7 FC Kartu Hasil Studi Tiap Semester 1lembar
8 FC KTM 3 lembar
9 Surat Ket Pindah dari PT asal d. Rancangan DAD Kerja[n] Daftar_Atribut 1 Training Analisis Sub_Kerja[n] 3 Pembentukan Aturan 2 Testing Kasus Tree Atribut, gain atribut atribut kasus Atribut, nilai, entropy
kasus Node Node Nilai atribut klasifikasi aturan kasus node
Gambar 2. Diagram aliran data level 1 Rancangan basis data
a. Tabel D_atribut
Create table D_atribut (
nama_atrribut varchar(30) NOT NULL, is_aktif char(1) default ‘Y’,
Is_hasil char(1) default ‘T’, ket varchar(15) default ‘’, Primary key (nama_atribut) );
b. Tabel Kasus Create table kasus
( nem char(1), JK varchar(6), Nama_Sklh varchar(25), jurusan varchar(15), Pil_jur, nilai varchar(3), agama varchar(25), jur_lulus varchar(10),
Namaprop varchar(25), namakab varchar(25), registrasi varchar(10) );\
c. Tabel Tree
Create table tree (
id_node integer, node varchar(30), nilai varchar(30), Induk varchar(30), is_atribut char(1) default ‘Y’ ); d. Tabel Kerja[0]
Create table kerja0 (nama_atribut varchar(30), gain numeric(15,2) ); e. Tabel sub_kerja[0] s.d sub_kerja[n]
Create table subkerja0 (
nama_atribut varchar(30), nilai varchar(3), entropy numeric (15,2), Result_1 varchar(30), result_2 varchar(30), jml_kasus integer );
2.4 Rancangan Algoritma
Mulai
1. Hapus tabel tree
2. atribut_hasil = nama_atribut dalam tabel 3. atribut is_hasil = ‘Y’
1. Q1 select distinct atribut_hasil dari tabel kasus 2. jml_hasil = 0 Q1 Eof ? 1. Level – 0 2. jml node = 0 1. Hasil[jml_hasil] =’result_’+j.Fields[0] 2. Tampil[jml_hasil] = Q1 3. inc(i)
Buat node Selesai
Star
1. entropy = 0
2. V_jml kasus : jumlah record dari tabel Kasus yang memenuhi syarat dari node sampai dengan
cabang yang sedang aktif 3. 1=0
i=jml_hasil-1?
1. buat tabel kerja[level]\ 2. buat tabel sub_kerja[level]
Q[level] : nama_atribut dari daftar_atributyang hasil = T dan telah
dipakai pada node-node induknya
P1
1. Q[level]=jumlah record dari tabel kasus yang memenuhi syarat dari node sampai dengan cabang yang sedang aktif dan atribut_hasilnya : hasil[i]
2. entropy := entropy+ (-Q[level].Field[0].Asinteger/ v_jml_kasus*log2 (Q[level].Field[0].Asinteger/v_jml_kasus)) 3. inc(i)
ya tidak
Gambar 4. Algoritma pembentukan node 1
P2
P1
Q[level].Eof?
1. masukkan ke tabel kerja[level] (atribut:Q[level].Field[0] gain:gain )
2. Q[level]Next
1. Gain : 0 2. Q[level+1]:jenis nilai dari
Q[level].nama_atribut
Q[level +1].Eof?
1. V_sub_jml_kasus: jml data yang jenisNilai=Q[level+1].Jenis_nilai 3. Q[level+1].next 1. Sub_entropy=0 2. i=0 V_sub_jml_kasus>0 ? 1. Gain:=Gain-(v_sub_jml_kasus/ v_jml_kasus*sub_entropy
2. Masukkan ke tabel sub_kerja[level] ( atribut:Q[level].Field[0]
nilai:Q[level+1].Field[0] entropy : sub_entropy )
i=jml_hasi-1? 1. Q[level+2=jml data yang
jenisnilai=Q[level+1].jenis_nilai dengan atribut_hasil=hasil[i] 2. sub_entropy=sub_entropy-(Q[level+2]..fields(0).Asinteger/ v_sub_jml_kasus*log2(Q[level+2].Fields( 0).Asinteger/v_sub_jml_kasus)) 3. inc(i) ya tidak tidak ya tidak ya ya tidak
P2
1. Q[level]=cari nama_atribut dari tabel kerja[level] dengan nilai gain tertinggi 2. i_node.add(jml_node+1) Q[level].empty? 1. terpilih=Q[level].Fields[0] 2. atribut.terpakai.add(terpilih) Level=0?
1. Masukkan ke tabel tree ( Id_node:jml_node+’ Node:atribut_terpakai[level] Nilai:nilai_atribut_terpakai[level-1] Induk:id_node[level-1]) 2. inc(jml_node) P3
1. masukkan ke tabel tree ( id_node:jml_node+ Node:’tidak terklasifikasi Nilai : nilai_atribut_terpakai[level-1] Induk : id_node[level-1] Is_atribut=’T’) 2. inc(jml_node) 3. nilai_atribut_terpakai.add(“,”) 4. atribut_terpakai.add(“)
1. masukkan ke tabel tree (id_node:jml_node+’ Node:atribut_terpakai[level) 2. inc(jml_node)
Q[level]=cari data dari Sub_kerja[level] Nama_atributnya : Atribut_terpakai[level] Q[level].empty ? Nilai_atribut_terpa kai.add(“”) tidak tidak ya ya tidak ya
Gambar 6. Algoritma pembentukan node 3
Q[level].Fileds[jml_kasus]= Q[level].Fileds[hasil[i]?
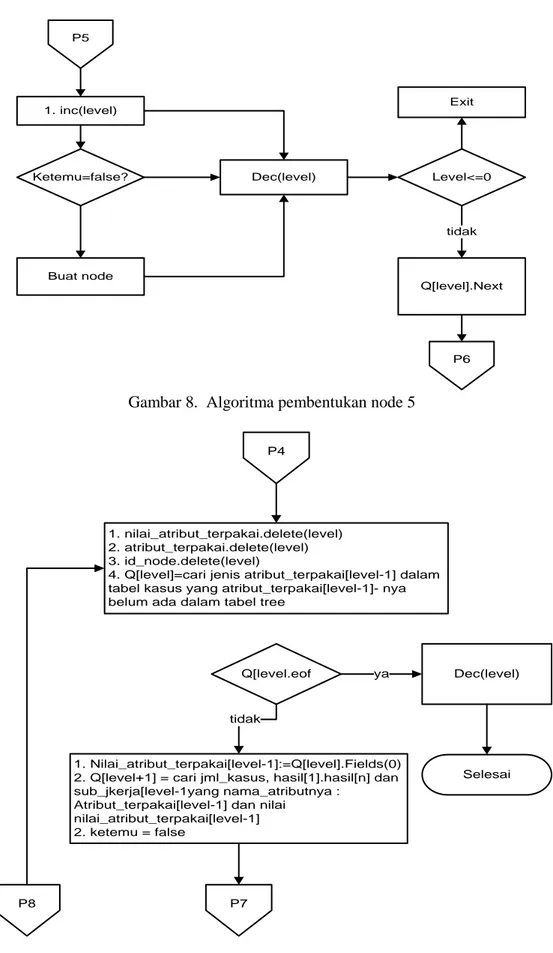
1. Masukkan ke tabel tree ( id_node:jml_node+1 Node:tam[il[i] Nilai:nilai_atribut_terpakai[level] Induk:id_node[level] Is_atribut=’T’) 2. inc(jml_node) 3. ketemu=true Inc() P5 i<=jml_hasil-1 Dan Ketemu=false? 1. Nilai_atribut_terpakai[level]= Q[level].Fileds[nilai 2. i=0 Ketemu=false P3 Q[level].eof P6 P4 ya tidak tidak ya tidak
P5 1. inc(level) Ketemu=false? Dec(level) Buat node Level<=0 Exit Q[level].Next P6 tidak
Gambar 8. Algoritma pembentukan node 5
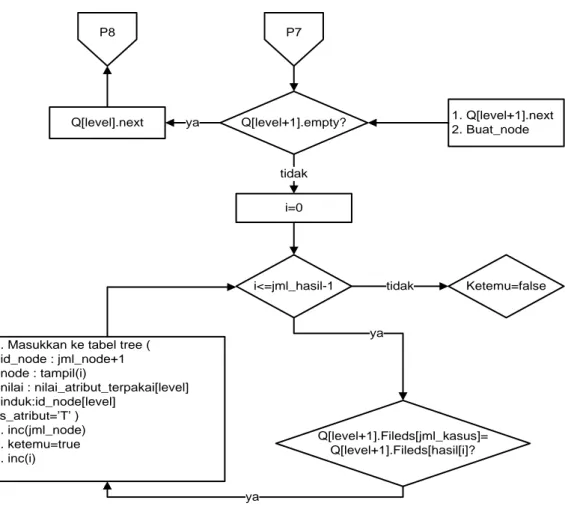
P4
1. nilai_atribut_terpakai.delete(level) 2. atribut_terpakai.delete(level) 3. id_node.delete(level)
4. Q[level]=cari jenis atribut_terpakai[level-1] dalam tabel kasus yang atribut_terpakai[level-1]- nya belum ada dalam tabel tree
Q[level.eof Dec(level)
Selesai 1. Nilai_atribut_terpakai[level-1]:=Q[level].Fields(0)
2. Q[level+1] = cari jml_kasus, hasil[1].hasil[n] dan sub_jkerja[level-1yang nama_atributnya :
Atribut_terpakai[level-1] dan nilai nilai_atribut_terpakai[level-1] 2. ketemu = false
P8 P7
ya
tidak
P8 P7
Q[level].next Q[level+1].empty? 1. Q[level+1].next
2. Buat_node
i=0
i<=jml_hasil-1
1. Masukkan ke tabel tree ( id_node : jml_node+1 node : tampil(i) nilai : nilai_atribut_terpakai[level] induk:id_node[level] is_atribut=’T’ ) 2. inc(jml_node) 3. ketemu=true 4. inc(i) Ketemu=false Q[level+1].Fileds[jml_kasus]= Q[level+1].Fileds[hasil[i]? ya tidak ya tidak ya
Gambar 10. Algoritma pembentukan node 7
PENUTUP a. Kesimpulan
Kesimpulan yang diambil adalah untuk penerapan aplikasi pada kasus analisis mahasiswa di jurusan sistem informasi STMIK Sumedang, dientry 35 record data calon mahasiswa tahun ajaran 2012/2013 ke dalam database kasus. Dari keseluruhan data tersebut 5 tidak registrasi dan sisanya melakukan registrasi.
b. Saran
Data yang pada penerimaan mahasiswa baru masih belum lengkap sesuai harapan untuk melengkapi klasifikasi dalam memprediksi kemungkinan yang lainnya. Adapun data yang dibutuhkan antara lain data orang tua, alternatif pilihan jurusan, dsb.
DAFTAR PUSTAKA
[1] Daniel T. Larose , 2005, Discovery knowledge in data, Wiley.
[2] Earl Cox, 2005, Fuzzy Modelling And Genetic Algorithms For Data Mining And Exploration, Morgan Kaufmann.