ANALISIS DAN PERANCANGAN
Bab ini akan membahas analisis mengenai permasalahan yang didefinisikan pada tugas akhir ini yaitu pemanfaatan pohon keputusan untuk pembelajaran kasus pola penulisan SMS. Analisis akan meliputi pembuatan model data yang tepat untuk pembelajaran pohon keputusan, metode preprocessing data, dan metode postprocessing data. Setelah itu akan dibahas mengenai model analisis, model perancangan dan perancangan antarmuka perangkat lunak yang akan dibangun.
3.1 Analisis Pola Penulisan Bahasa SMS
Bagian ini berisi uraian beberapa pola penulisan bahasa SMS yang berhasil diobservasi. Beberapa SMS yang diobservasi dapat dilihat di lampiran C. Pola-pola yang diuraikan disini adalah pola penulisan yang paling umum, karena selain pola-pola ini sebenarnya masih banyak pola-pola lain yang digunakan oleh pengguna telepon seluler.
3.1.1 Menghapus Huruf dari Kata
Menghapus huruf dari kata adalah pola penulisan bahasa SMS yang paling umum dan pertama kali dikenal oleh pengguna telepon seluler. Selain itu, pola penulisan ini adalah pola penulisan yang paling mudah diterapkan dan dimengerti oleh pengguna telepon seluler. Pola penulisan SMS ini paling umum dilakukan dengan penghapusan karakter huruf hidup (a,i,u,e,o) dari suatu kata. Namun, ada juga beberapa kata yang dihilangkan karakter huruf matinya. Contoh kata-kata yang dituliskan menggunakan pola ini dapat dilihat pada tabel III-1.
3.1.2 Pengulangan Kata atau Suku Kata dengan Angka
Pola ini muncul dalam penulisan bahasa SMS dikarenakan dalam bahasa Indonesia dikenal adanya kata ulang. Kata ulang berfungsi untuk melambangkan bahwa suatu obyek yang ditunjuk oleh kata ulang tersebut jumlahnya banyak, seperti kata-kata yang berarti banyak kata, dan sapu-sapu yang berarti banyak sapu. Selain itu, terdapat pengecualian seperti kata ulang kupu-kupu mewakili nama binatang, bukan berarti
banyak kupu. Selain untuk melambangkan kata ulang, penggunaan angka untuk melambangkan jumlah pengulangan suku kata juga sering dilakukan. Contoh kata-kata yang menggunakan pola ini dapat dilihat pada tabel III-2.
Tabel III-1 penggunaan pola menghapus huruf Kata Kata ditulis dalam
bahasa SMS
Keterangan
yang yg Karakter yang dihapus dari kata “yang” adalah karakter “a” dan “n”
kita kt Karakter yang dihapus dari kata “kita” adalah “i” dan “a”
juga jg Karakter yang dihapus dari kata “juga” adalah “u” dan “a”
Tabel III-2 penggunaan pola angka untuk pengulangan Kata Kata ditulis dalam bahasa
SMS
Keterangan
buku‐buku bk2 Kata “buku” terlebih dulu disingkat menjadi “bk”, kemudian ditambahkan karakter angka “2” di belakangnya yang melambangkan bahwa kata tersebut adalah kata ulang nama‐nama nama2 Di belakang kata “nama” ditambahkan
karakter angka “2” yang melambangkan bahwa kata tersebut adalah kata ulang pupus pu2s Karakter angka “2” disini melambangkan
pengulangan suku kata “pu” pada kata “pupus”
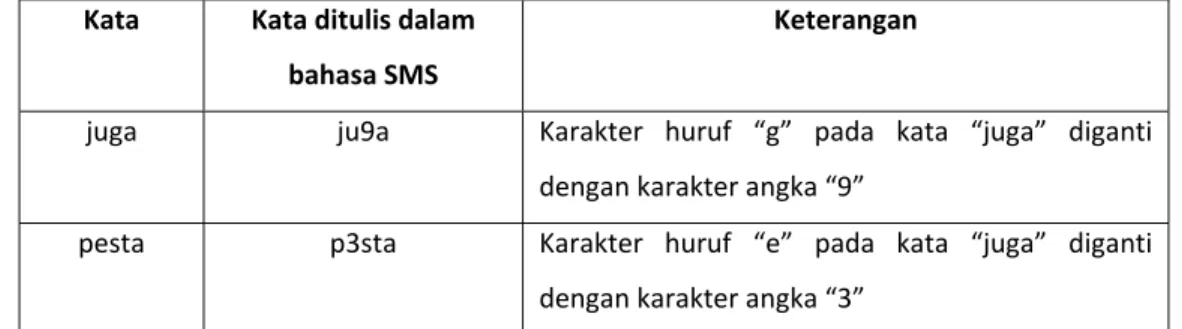
3.1.3 Substitusi Huruf dengan Angka yang Mirip
Pola ini muncul karena ada beberapa huruf yang cukup mirip bentuknya dengan angka. Namun, penggunaannya lebih didasarkan atas tren yang muncul di kalangan pengguna
telepon seluler, bukan karena kemudahan penerapannya. Mengetikkan karakter angka pada saat menuliskan SMS memerlukan usaha sedikit lebih banyak dibandingkan dengan hanya menuliskan karakter huruf, apalagi jika angka yang akan dituliskan hanya satu atau dua karakter angka saja. Contoh penggunaan pola ini ditunjukkan pada tabel III-3.
Tabel III-3 penggunaan pola penggunaan angka menggantikan huruf Kata Kata ditulis dalam
bahasa SMS
Keterangan
juga ju9a Karakter huruf “g” pada kata “juga” diganti dengan karakter angka “9”
pesta p3sta Karakter huruf “e” pada kata “juga” diganti dengan karakter angka “3”
3.1.4 Substitusi Fonetik
Pola ini muncul karena ada beberapa kata yang mengandung satu atau lebih suku kata yang bisa digantikan dengan suatu huruf atau angka yang memiliki kesamaan fonetik. Selain itu, pola ini juga digunakan untuk menggantikan penulisan kata yang melambangkan angka (misalkan penulisan “2” untuk menggantikan “dua”). Contoh penggunaan pola ini ditunjukkan pada tabel III-4.
Tabel III-4 penggunaan pola penggunaan substitusi fonetik Kata Kata ditulis dalam
bahasa SMS
Keterangan
dia dy Huruf “y” digunakan untuk mengantikan fonem “ia” pada kata “dia”
tempat t4 Angka “4” digunakan untuk menggantikan fonem “empat” pada kata “tempat”
dua‐duanya 22nya Angka “2” digunakan untuk menggantikan kata “dua”
3.2 Analisis Pemanfaatan Pohon Keputusan C4.5
Pada bab sebelumnya telah dibahas mengenai pola-pola penulisan SMS yang digunakan oleh pengguna SMS. Pola-pola ini dapat dikenali dari setiap kata yang dituliskan oleh pengguna SMS. Dikarenakan setiap kata dalam sebuah SMS mencirikan suatu pola penulisan, dan berdasarkan prinsip kerja pohon keputusan, yaitu mengklasifikasikan instans, maka dalam tugas akhir ini pohon keputusan bertugas mengklasifikasikan kata dalam SMS menjadi kelas-kelas pola penulisan.
Berikut ini akan dibahas kelas data atau kelas pola penulisan SMS dan atribut instans untuk setiap kata dalam SMS.
3.2.1 Kelas Data
Kelas kata dalam SMS yang akan digunakan didefinisikan berdasarkan pola penulisan SMS yang dibahas pada bab sebelumnya. Namun, terdapat perbedaan untuk kelas kata yang menggunakan pola substitusi fonetik. Substitusi fonetik yang dicirikan dengan substitusi fonetik oleh angka akan dibedakan kelasnya dengan substitusi fonetik oleh huruf atau suku kata. Jenis kelas kata tersebut adalah sebagai berikut:
1. Kelas 1. Dicirikan dengan adanya penggunaan pola substitusi fonetik dengan angka.
2. Kelas 2. Dicirikan dengan adanya penggunaan pola penghapusan huruf dari kata. Selain itu, kata yang tidak disingkat juga akan dimasukkan dalam kelas ini, karena metode preprocessing yang akan dijelaskan di subbab selanjutnya, tidak dapat mengenali suatu kata yang tidak disingkat. Sehingga, sebagai asumsi, kata yang tidak disingkat akan dikategorikan sebagai kelas 2.
3. Kelas 3. Dicirikan dengan adanya penggunaan angka untuk menyatakan pengulangan suku kata atau kata.
4. Kelas 4. Dicirikan dengan adanya penggunaan angka untuk mengganti huruf yang memiliki bentuk yang identik.
5. Kelas 5. Dicirikan dengan adanya penggunaan pola substitusi fonetik tanpa menggunakan angka.
3.2.2 Atribut Data
Atribut yang akan digunakan adalah atribut yang mampu mencirikan kelas kata dengan baik. Atribut-atribut yang cukup mampu mengikuti syarat tersebut adalah sebagai berikut. 1. SMS Word, yang melambangkan setiap kata dalam bahasa SMS yang ditemukan
di dalam data pelatihan
2. Keberadaan Angka, yang melambangkan keberadaan angka pada kata dalam bahasa SMS. Atribut ini akan bernilai 1 jika terdapat angka pada kata, 0 jika sebaliknya
3. Kesamaan Fonetik, yang melambangkan keberadaan fonem pengganti yang bukan angka di dalam kata. Atribut ini akan bernilai 1 jika terdapat fonem pengganti pada kata, 0 jika sebaliknya
4. Makna Angka, yang melambangkan makna keberadaan angka pada kata. Atribut akan bernilai repeater jika makna angka adalah pengulangan kata atau suku kata, phonetic jika angka menggantikan suatu fonem, identical jika angka menggantikan huruf yang bentuknya sama, dan tanpa-angka jika kata tersebut tidak mengadung karakter angka.
3.3 Analisis Representasi Data Pesan Singkat dalam C4.5
Setelah dapat mendefinisikan kelas dan atribut data pesan singkat dengan cukup lengkap, hal yang dilakukan selanjutnya adalah merepresentasikannya dalam format yang dapat diproses oleh program C4.5. Pada bagian ini akan diuraikan mengenai representasi data pesan singkat dalam program C4.5, kemudian akan ditampilkan beberapa contoh data pelatihan yang akan digunakan. Setelah itu, akan diberikan contoh representasi pohon keputusan yang dihasilkan dari beberapa contoh data pelatihan tersebut.
Data pesan singkat yang akan digunakan adalah pesan-pesan singkat yang digunakan untuk melakukan query ke basis data perpustakaan. Karena batasan tersebut, tentunya jumlah kata yang akan menjadi data pelatihan tidak akan terlalu besar, namun cukup mewakili untuk permasalahan ini. Dan juga, karena data pesan singkat berhubungan dengan perpustakaan, maka diasumsikan kata-kata yang berupa nama, baik itu nama orang maupun judul buku, nama koran dan nama majalah, tidak akan dimasukkan sebagai
data pelatihan dan juga tidak akan diproses oleh pohon keputusan nantinya. Selain itu, kata yang berupa nomor-nomor, yaitu kata yang semua karakternya adalah angka, yang bisa jadi merepresentasikan nomor identitas anggota atau suatu jumlah, tidak akan diproses hingga proses menggabungkan kata-kata yang dipecah menjadi kalimat utuh.
Pohon keputusan yang dihasilkan sebenarnya bisa dibentuk secara manual dengan pengamatan data pelatihan yang ada, karena pohon keputusan yang diharapkan untuk dihasilkan tidaklah terlalu besar. Penggunaan C4.5 dalam pembentukan pohon keputusan hanya sebagai bahan verifikasi apakah pohon yang dibentuk telah mampu melingkupi semua data pelatihan yang digunakan. Namun, jika terjadi penambahan jenis kelas kata, dan penambahan atribut data, maka pembentukan pohon dengan C4.5 akan sangat membantu memudahkan proses pembentukan pohon keputusan.
3.3.1 Deklarasi Kelas dan Atribut Data Pesan Singkat
Deklarasi kelas dan atribut data pesan singkat dilakukan berdasarkan format standar untuk program C4.5 yang telah dijelaskan pada bab sebelumnya. Namun, ada suatu perbedaan dimana nilai untuk atribut SMS-Word nantinya tidak akan diproses oleh algoritma. Hal ini dilakukan untuk mempermudah proses pembentukan pohon keputusan oleh algoritma. Karena SMS-Word adalah atribut dengan kemungkinan nilai paling banyak, yaitu semua kata yang muncul dalam semua pesan singkat yang dijadikan data pelatihan. Mengacuhkan satu atribut pernah dilakukan sebelumnya pada pembelajaran data pelatihan zoo menggunakan C4.5, yaitu dengan mengacuhkan atribut name, yang nilainya adalah nama semua binatang yang diklasifikasikan. Gambar III-1 berikut ini adalah deklarasi kelas dan atribut data dalam format C4.5:
1,2,3,4,5.
SMSWORD: ignore. ANGKA:0,1. FONETIK:0,1.
MAKNA-ANGKA:repeater,identical,phonetic,tanpa-angka.
Gambar III-1 Deklarasi kelas dan atribut data pesan singkat
Angka 1 hingga 5 di bagian atas deklarasi merepresentasikan kelas kata (kelas kata telah didefinisikan sebelumnya berjumlah lima). SMSWORD adalah atribut SMS Word, nilai atributnya ignore, yang berarti atribut SMS Word tidak akan diproses oleh algoritma. ANGKA adalah representasi dari atribut Keberadaan Angka, nilai atributnya adalah 0 dan 1. FONETIK adalah representasi dari atribut Kesamaan Fonetik, nilai atributnya adalah 0 dan 1. Terakhir yaitu, MAKNA-ANGKA adalah representasi dari atribut Makna Angka, nilai atributnya adalah repeater, identical, phonetic, dan tanpa-angka.
3.3.2 Representasi Data Pesan Singkat
Untuk merepresentasikan contoh data pesan singkat dalam format program C4.5, diberikan contoh beberapa data pelatihan pada tabel III-5.
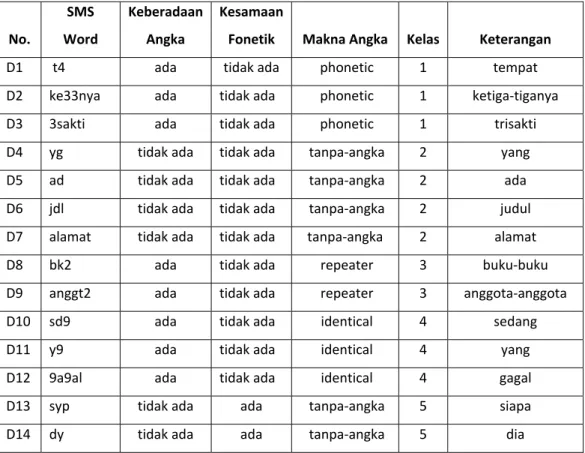
Tabel III-5 data kata dalam pesan singkat
No. SMS Word Keberadaan Angka Kesamaan
Fonetik Makna Angka Kelas Keterangan
D1 t4 ada tidak ada phonetic 1 tempat
D2 ke33nya ada tidak ada phonetic 1 ketiga‐tiganya
D3 3sakti ada tidak ada phonetic 1 trisakti
D4 yg tidak ada tidak ada tanpa‐angka 2 yang
D5 ad tidak ada tidak ada tanpa‐angka 2 ada
D6 jdl tidak ada tidak ada tanpa‐angka 2 judul D7 alamat tidak ada tidak ada tanpa‐angka 2 alamat
D8 bk2 ada tidak ada repeater 3 buku‐buku
D9 anggt2 ada tidak ada repeater 3 anggota‐anggota
D10 sd9 ada tidak ada identical 4 sedang
D11 y9 ada tidak ada identical 4 yang
D12 9a9al ada tidak ada identical 4 gagal
D13 syp tidak ada ada tanpa‐angka 5 siapa
Representasi data tersebut dalam format program C4.5 diperlihatkan pada gambar III-2. t4,1,0,phonetic,1 ke33nya,1,0,phonetic,1 3sakti,1,0,phonetic,1 yg,0,0,tanpaangka,2 ad,0,0,tanpaangka,2 jdl,0,0,tanpaangka,2 alamat,0,0,tanpaangka,2 bk2,1,0,repeater,3 anggt2,1,0,repeater,3 sd9,1,0,identical,4 y9,1,0,identical,4 9a9al,1,0,identical,4 syp,0,1,tanpaangka,5 dy,0,1,tanpaangka,5
Gambar III-2 Representasi data pesan singkat dalam format C4.5
3.4 Analisis Metode Data Preprocessing
Sebelum dilakukan preprocessing terhadap data pesan singkat terlebih dahulu dilakukan pemecahan kalimat pesan singkat menjadi sejumlah kata-kata yang nantinya akan dipreprocessing. Kata-kata yang diambil untuk dipreprocessing oleh proses ini adalah kata-kata yang bukan nama, dan nomor. Setiap kata yang dihasilkan oleh proses pemecahan kata ini selanjutnya akan dipreprocessing. Algoritma untuk proses inidapat dilihat pada gambar III-3.
• Baca satu persatu kata yang muncul di dalam pesan singkat yang diterima • Jika kata yang dibaca bukan NAMA dan NOMOR, maka
o Masukkan kata tersebut dalam list PREPROCESSING_CANDIDATE, beri nomor index ke-i
o i = i + 1
• Jika kata yang dimasukkan adalah NAMA dan NOMOR, maka
o Masukkan kata tersebut dalam list POSTPROCESSING_CANDIDATE, beri nomor index ke-i
o i = i + 1
• Kirim list PREPROCESSING_CANDIDATE ke proses preprocessing
Pertanyaan yang tentu muncul adalah bagaimana memroses kata-kata dalam SMS sehingga dari setiap kata dapat dibentuk instans yang memiliki nilai atribut yang sesuai dengan format yang telah ada, dan kemudian dapat diklasifikasikan kelasnya oleh pohon keputusan yang sebelumnya telah terbentuk. Proses pengenalan nilai atribut seharusnya dilakukan oleh guru, yaitu orang yang membuat sistem pembelajaran ini. Namun, untuk mengotomasi proses pengenalan ini, sebaiknya proses ini diprogram. Teknik pemrograman yang digunakan cukup teknik yang biasa, yang perlu dilakukan hanyalah membuat program yang mampu mengenali pola penulisan SMS. Jika terjadi kesalahan dalam pengenalan pola, nilai atribut yang dimiliki instans akan tidak konsisten dengan data yang lain, sehingga instans yang terbentuk tentunya menjadi instans yang dikenali sebagai instans yang tidak terdefinisi. Sebagai contohnya,
{sd9, 0, 0, identical}
Dalam hal ini, seharusnya nilai atribut kedua, yaitu keberadaan angka seharusnya 1, atau nilai atribut makna angka seharusnya tanpa-angka, namun karena kesalahan pengenalan pola, nilai atribut tersebut menjadi 0. Tentunya instans ini tidak konsisten terhadap pohon keputusan yang telah terbentuk sebelumnya. Namun, pohon keputusan dapat menangani masalah ini. Cara pertama yaitu dengan bertanya pada guru mengenai kelas data tersebut, untuk kemudian dibentuk pohon keputusan yang baru dengan tambahan data tersebut. Sedangkan cara kedua, memberi label ”tidak dikenali” pada data tersebut. Cara pertama tidak mungkin dilakukan jika guru tidak dapat mengidentifikasi kelas dari instans tersebut. Dan karena instans tersebut memiliki nilai atribut yang membuatnya tidak mungkin diklasifikasikan, maka guru tidak mungkin bisa mengidentifikasikan kelas dari instans tersebut. Dengan bagitu cara kedua menjadi pilihan.
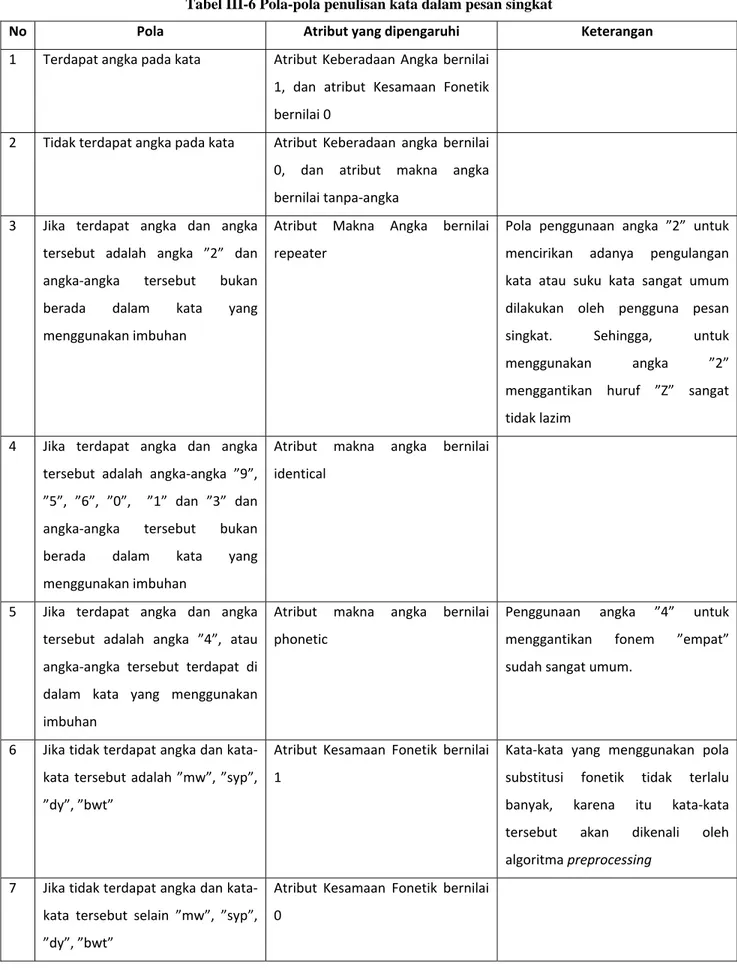
Preprocessing data ini dilakukan dengan mengenali pola-pola yang muncul dalam
penulisan pesan singkat. Pola-pola yang dapat ditemukan dalam pesan singkat disajikan dalam tabel III-6. Dari pola-pola yang diuraikan pada tabel III-6 dapat dibuat suatu algoritma preprocessing. Algoritma preprocessing dapat dilihat pada gambar III-4.
Tabel III-6 Pola-pola penulisan kata dalam pesan singkat
No Pola Atribut yang dipengaruhi Keterangan
1 Terdapat angka pada kata Atribut Keberadaan Angka bernilai 1, dan atribut Kesamaan Fonetik bernilai 0
2 Tidak terdapat angka pada kata Atribut Keberadaan angka bernilai 0, dan atribut makna angka bernilai tanpa‐angka
3 Jika terdapat angka dan angka tersebut adalah angka ”2” dan angka‐angka tersebut bukan berada dalam kata yang menggunakan imbuhan
Atribut Makna Angka bernilai repeater
Pola penggunaan angka ”2” untuk mencirikan adanya pengulangan kata atau suku kata sangat umum dilakukan oleh pengguna pesan singkat. Sehingga, untuk menggunakan angka ”2” menggantikan huruf ”Z” sangat tidak lazim
4 Jika terdapat angka dan angka tersebut adalah angka‐angka ”9”, ”5”, ”6”, ”0”, ”1” dan ”3” dan angka‐angka tersebut bukan berada dalam kata yang menggunakan imbuhan
Atribut makna angka bernilai identical
5 Jika terdapat angka dan angka tersebut adalah angka ”4”, atau angka‐angka tersebut terdapat di dalam kata yang menggunakan imbuhan
Atribut makna angka bernilai phonetic
Penggunaan angka ”4” untuk menggantikan fonem ”empat” sudah sangat umum.
6 Jika tidak terdapat angka dan kata‐ kata tersebut adalah ”mw”, ”syp”, ”dy”, ”bwt”
Atribut Kesamaan Fonetik bernilai 1
Kata‐kata yang menggunakan pola substitusi fonetik tidak terlalu banyak, karena itu kata‐kata tersebut akan dikenali oleh algoritma preprocessing
7 Jika tidak terdapat angka dan kata‐ kata tersebut selain ”mw”, ”syp”, ”dy”, ”bwt”
Atribut Kesamaan Fonetik bernilai 0
• Baca satu persatu karakter pada kata yang diambil dari list PREPROCESSING_CANDIDATE jika ditemukan angka maka,
a. Beri nilai 1 pada atribut Keberadaan Angka, dan 0 pada atribut Kesamaan Fonetik
b. Jika angka adalah ”9”, ”5”, ”0”, ”1”, ”6” atau ”3” dan kata tersebut tidak mengandung imbuhan maka,
i. Beri nilai ”identical” pada atribut Makna Angka
c. Jika angka adalah angka ”2” dan kata tersebut tidak mengandung imbuhan maka,
i. Beri nilai ”repeater” atribut Makna Angka
d. Jika angka adalah angka ”4” atau kata tersebut mengandung imbuhan {untuk pengecekan, semua kemungkinan imbuhan yang muncul dalam SMS dan kemungkinan penulisannya akan disimpan pada file eksternal, dan secara dinamis dapat ditambahkan} maka,
i. Beri nilai ”phonetic” atribut Makna Angka • Jika tidak ditemukan angka maka,
a. Beri nilai 0 pada atribut Keberadaan Angka, dan nilai tanpa-angka pada atribut Makna Angka
b. Jika kata-kata tersebut termasuk dalam sub_phonetic {file eksternal yang menyimpan kata-kata yang menggunakan substitusi fonetik} maka,
i. Beri nilai 1 pada atribut Kesamaan Fonetik
ii. Selain itu, beri nilai 0 pada atribut Kesamaan Fonetik
Gambar III-4 Algoritma Preprocessing
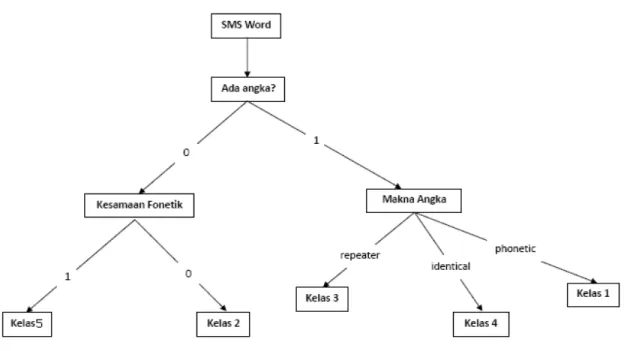
3.5 Inferensi Pohon Keputusan
Berdasarkan hasil pembentukan pohon keputusan dari data pelatihan pesan singkat yang diberikan pada bab III, didapatkan pohon keputusan yang dapat dilihat pada gambar III-5. Proses inferensi/penelusuran pohon keputusan dimulai dari simpul akar yang berupa SMS
Word. Apapun nilai atribut SMS Word pada instans akan diteruskan ke simpul yang
mengevaluasi apakah ada angka di dalam kata (SMS Word). Jika tidak ada, evaluasi akan dilanjutkan ke simpul sebelah kiri, yang akan mengevaluasi apakah ada kesamaan fonetik pada kata, jika ada, instans akan digolongkan sebagai kelas 5, jika tidak akan digolongkan sebagai kelas 2. Jika hasil evaluasi keberadaan angka menyatakan terdapat angka, penelusuran akan dilakukan ke simpul kanan dari simpul evaluasi keberadaan angka. Selanjutnya akan dievaluasi makna angka yang terdapat pada kata, jika maknanya repeater maka instans akan digolongkan kelas 3, identical akan digolongkan kelas 4 dan terakhir phonetic akan digolongkan kelas 1.
Gambar III-5 Pohon Keputusan yang terbentuk
Sebagai contoh instans {yg,0,0,tanpaangka}, inferensi akan dimulai dari simpul akar yang mengevaluasi nilai atribut SMS Word yang bernilai yg, inferensi akan langsung dilanjutkan ke simpul evaluasi keberadaan angka. Instans {yg,0,0,tanpaangka} memiliki nilai 0 untuk atribut keberadaan angka, maka inferensi akan dilanjutkan ke simpul sebelah kiri yang akan mengevaluasi kesamaan fonetik. Instans {yg,0,0,tanpaangka} memiliki nilai 0 untuk atribut kesamaan fonetik, maka inferensi akan dilanjutkan ke simpul sebelah kanan yang berupa daun dari pohon keputusan, sehingga akan langsung disimpulkan bahwa instans tergolong kelas 2.
3.6 Analisis Metode Data Postprocessing
Berbeda dengan metode preprocessing yang cukup sulit, metode postprocessing jauh lebih mudah. Berdasarkan kelas yang telah diidentifikasi oleh pohon keputusan, proses ini bisa dilakukan lebih mudah. Namun, tidak menutup kemungkinan justru pada saat
postprocessing ini terjadi kesalahan dalam transformasi kata SMS menjadi kata formal. Postprocessing untuk setiap kelas dilakukan secara berbeda. Beberapa contoh cara
III-7 tersebut dapat dibuat suatu algoritma postprocessing. Algoritma postprocessing dapat dilihat pada gambar III-6.
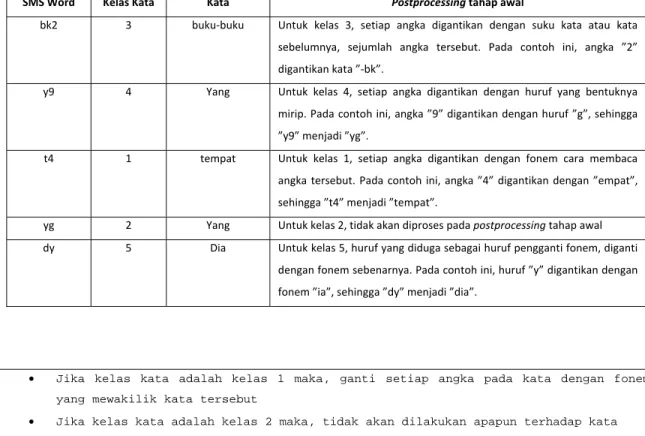
Tabel III-7 Metode Postprocessing tahap awal
SMS Word Kelas Kata Kata Postprocessing tahap awal
bk2 3 buku‐buku Untuk kelas 3, setiap angka digantikan dengan suku kata atau kata sebelumnya, sejumlah angka tersebut. Pada contoh ini, angka ”2” digantikan kata ”‐bk”.
y9 4 Yang Untuk kelas 4, setiap angka digantikan dengan huruf yang bentuknya mirip. Pada contoh ini, angka ”9” digantikan dengan huruf ”g”, sehingga ”y9” menjadi ”yg”.
t4 1 tempat Untuk kelas 1, setiap angka digantikan dengan fonem cara membaca angka tersebut. Pada contoh ini, angka ”4” digantikan dengan ”empat”, sehingga ”t4” menjadi ”tempat”.
yg 2 Yang Untuk kelas 2, tidak akan diproses pada postprocessing tahap awal dy 5 Dia Untuk kelas 5, huruf yang diduga sebagai huruf pengganti fonem, diganti
dengan fonem sebenarnya. Pada contoh ini, huruf ”y” digantikan dengan fonem ”ia”, sehingga ”dy” menjadi ”dia”.
• Jika kelas kata adalah kelas 1 maka, ganti setiap angka pada kata dengan fonem yang mewakilik kata tersebut
• Jika kelas kata adalah kelas 2 maka, tidak akan dilakukan apapun terhadap kata • Jika kelas kata adalah kelas 3 maka, angka {pasti angka ”2”} diganti dengan suku
kata atau kata sebelum angka tersebut.
• Jika kelas kata adalah kelas 4 maka, setiap angka yang muncul pada kata digantikan dengan huruf yang sesuai atau bentuknya mirip
• Jika kelas kata adalah kelas 5 maka, setiap huruf yang menggantikan fonem kata {dari data contoh, huruf yang menggantikan fonem adalah ”y” untuk fonem ”ia” dan ”w” untuk fonem ”ua” atau ”au”}, diganti dengan fonem sebenarnya
Gambar III-6 Algoritma postprocessing
Setelah postprocessing tahap awal dilakukan terhadap kata, maka selanjutnya adalah mencari kata tersebut di dalam daftar kata. Daftar kata ini dibangun dengan kata-kata yang muncul pada data training, bukan dengan memasukkan semua kata yang ada dalam daftar kata. Semua kata yang memiliki huruf depan yang sama akan disimpan dalam struktur penyimpanan yang sama. Representasi dari struktur penyimpanan daftar kata ini dapat dilihat pada gambar III-7. Sedangkan algoritma pencarian kata dalam daftar kata dapat dilihat pada gambar III-8.
APAKAH ANGGOTA ALAMAT
Gambar III-7 Struktur penyimpanan daftar kata huruf “A”
1. Buka struktur penyimpanan daftar kata untuk kata-kata yang memiliki huruf depan sama dengan huruf awal kata SMS.
2. Cari kata yang mengandung sisa huruf di belakang kata SMS dari struktur penyimpanan tersebut. Pencocokan karakter sisa dari kata SMS harus berurutan. {kataSMS[1] = kata[i] AND kataSMS[2] = kata[i+1]}.
Semua huruf di kata SMS harus terkandung di dalam kata, jika tidak terkandung, maka kata tersebut dikategorikan sebagai kata yang tidak cocok.kata-kata yang cocok dimasukkan ke dalam list CANDIDATE_WORD
3. Setiap kata yang terdapat pada list CANDIDATE_WORD dihitung perbandingan panjangnya dengan kata SMS {panjang kataSMS/panjang kata di list}. Kata yang memiliki nilai perbadingan paling besar, dipilih sebagai pengganti kata SMS 4. Kemudian masukkan kata ke dalam list POSTPROCESSING_CANDIDATE dan diberi index
yang sesuai dengan index kata tersebut pada PREPROCESSING_CANDIDATE
Gambar III-8 Algoritma pencarian kata dari daftar kata
Setelah setiap kata dalam pesan singkat ditemukan padanannya, dilakukan penggabungan kata-kata tersebut menjadi kalimat yang utuh. Penggabungan menjadi kalimat ini dilakukan dilakukan dengan mengambil kata-kata yang telah diproses sebelumnya dari list POSTPROCESSING_CANDIDATE. Pengambilan kata dilakukan secara berurutan menurut nomor indeks yang diberikan di list POSTPROCESSING_CANDIDATE. Hasilnya berupa keluaran program yang berupa kalimat yang utuh dan bahasanya tidak lagi menggunakan bahasa pesan singkat.
3.6.1 Perhitungan Akurasi Pengubahan SMS
Untuk menguji kebenaran algoritma, digunakan beberapa data contoh sms. Setiap data memiliki nilai akurasi tersendiri, yang dihitung dengan membandingkan jumlah kata yang sama dan memiliki posisi yang sama dari teks sms hasil transformasi dengan teks sms pembanding. Detail penghitungan nilai akurasi dapat dilihat di rumus (1).
m n si
Dengan n adalah jumlah kata dari teks sms hasil transformasi yang sama dan menepati posisi yang sama. Sedangkan m adalah jumlah kata yang terdapat di teks sms pembanding.
3.7 Model Analisis Perangkat Lunak
3.7.1 Kebutuhan Perangkat Lunak
Kebutuhan perangkat lunak ini adalah sebagai berikut:
1. Mampu mentransformasikan pesan singkat (SMS) yang dituliskan dengan gaya penulisan kata pesan singkat yang bermacam-macam menjadi pesan singkat dengan penulisan kata yang mengikuti tata penulisan kata yang baku. 2. Mampu menghitung akurasi perubahan dari pesan singkat.
3. Mampu melakukan penambahan kata di dalam daftar kata. 4. Mampu melakukan penambahan kata di dalam kamus fonetik. 5. Mampu melakukan penambahan kata di dalam kamus nama. 3.7.2 Use Case SMSRenderer
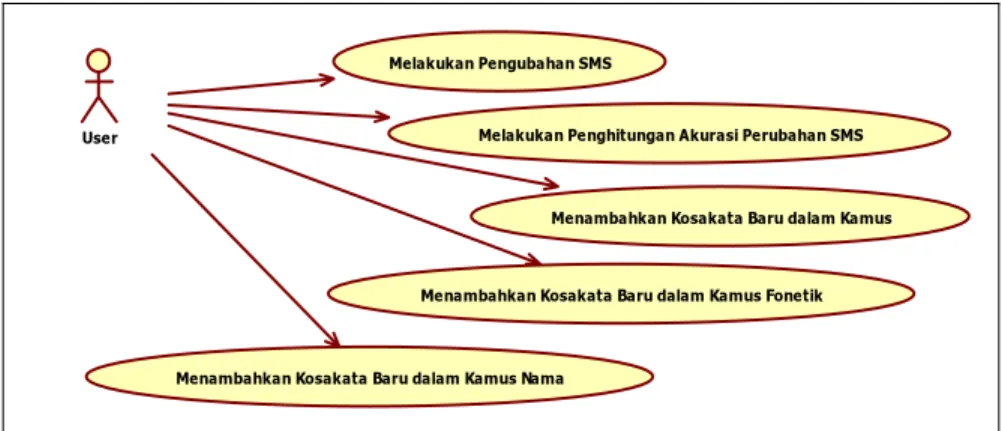
Perangkat lunak SMSRenderer bertujuan untuk mentransformasikan SMS dengan gaya penulisan kata yang berbeda-beda menjadi sebuah SMS yang penulisannya mengikuti tata penulisan kata yang baku. Perangkat lunak ini memiliki lima proses utama yaitu transformasi pesan singkat (SMS), perhitungan akurasi hasil transformasi SMS, penambahan kosakata baru dalam daftar kata, penambahan kosakata baru dalam kamus fonetik, penambahan kosakata baru dalam kamus nama.
Use Case menggambarkan SMSRenderer sebagai sebuah system Black Box dimana user
tidak mengetahui yang terjadi di dalam system tersebut. Gambar III-9 merupakan use case dari perangkat lunak SMSRenderer.
User
Melakukan Pengubahan SMS
Melakukan Penghitungan Akurasi Perubahan SMS
Menambahkan Kosakata Baru dalam Kamus
Menambahkan Kosakata Baru dalam Kamus Fonetik
Menambahkan Kosakata Baru dalam Kamus Nama
Gambar III-9 Use Case SMSRenderer
3.7.3 Identifikasi Kelas Objek
Perangkat lunak SMSRenderer memiliki kelas-kelas sebagai berikut: 1. Parser
Kelas ini berfungsi untuk melakukan proses pemecahan SMS (pesan singkat) menjadi tabel kata.
2. Preprocessor
Kelas ini berfungsi untuk melakukan proses untuk mempersiapkan masing-masing kata di tabel string (kata) yang dibentuk oleh kelas Parser sebelum diproses lebih lanjut. Kelas ini mengimplementasikan algoritma preprocessing
yang dibahas pada bab III. 3. Classification
Kelas ini berfungsi untuk melakukan proses klasifikasi dari masing-masing kata yang terdapat dalam pesan singkat (SMS). Kelas ini mengimplementasikan aturan produksi pohon keputusan yang dibentuk dari pelatihan sejumlah data pelatihan. 4. Postprocessor
Kelas ini berfungsi untuk melakukan proses postprocessing pada masing-masing
kata yang terdapat dalam pesan singkat. Kelas ini mengimplementasikan algoritma postprocessing yang dibahas pada bab III.
5. Dictionary
Kelas ini berfungsi untuk melakukan pencarian kata pada pesan singkat di dalam daftar kata. Kelas ini mengimplementasikan algoritma pencarian dalam daftar kata yang dibahas pada bab III.
6. AccuracyTester
Kelas ini berfungsi untuk membandingkan pesan singkat hasil transformasi dengan pesan singkat pembanding yang didapatkan dari umpan balik pengguna perangkat lunak.
7. NameDictionary
Kelas ini berfungsi untuk mengambil kata-kata yang berupa nama dari sebuah file eksternal yang merupakan kamus nama.
8. PhoneticDictionary
Kelas ini berfungsi untuk mengambil kata-kata yang berupa kata substitusi fonetik dari sebuah file eksternal yang merupakan kamus kata substitusi fonetik.
9. DictionaryMaker
Kelas ini berfungsi untuk menambahkan kata-kata yang selain nama ke dalam file eksternal daftar kata.
10. NameDictionaryMaker
Kelas ini berfungsi untuk menambahkan kata-kata yang berupa nama ke dalam kamus dan file eksternal kamus nama.
11. PhoneticDictionaryMaker
Kelas ini berfungsi untuk menambahkan kata-kata yang berupa kata substitusi fonetik ke dalam kamus dan file eksternal kamus kata substitusi fonetik.
12. SMSRendererInterface
Kelas ini berfungsi untuk memudahkan interaksi antara pengguna dengan perangkat SMSRenderer ini.
Proses yang terjadi di dalam sistem adalah sebagai berikut: 1. Pentransformasian pesan singkat (SMS)
2. Penghitungan Akurasi Perubahan SMS
4. Menambahkan kosakata baru dalam kamus fonetik 5. Menambahkan kosakata baru dalam kamus nama.
Detil dari proses tersebut dapat dilihat pada lampiran E. Skenario Use Case dan lampiran
G Sequence Diagram Aplikasi SMSRenderer yang akan dibuat ini menggunakan sebuah
basis pengetahuan mengenai kata yang disingkat dalam pesan singkat, maka dapat disimpulkan bahwa aplikasi ini adalah aplikasi sistem berbasis pengetahuan. Oleh karena itu, dalam dokumentasi aplikasi ini akan ada dokumen spesifikasi sistem berbasis pengetahuan, yang berisi Introduction, SMSRenderer Function, Constraints, dan Miscellaneous Issues. Detil dari dokumen spesifikasi SMSRenderer dapat dilihat pada
lampiran D Dokumen Spesifikasi SMSRenderer.
Keterhubungan antarkelas pada SMSRenderer dapat dilihat pada tabel III-8
Tabel III-8 Tabel Keterhubungan Antar Kelas
Proses Kelas yang terlibat Pentransformasian pesan singkat (SMS) Parser Preprocessor Classification Postprocessor Dictionary NameDictionary PhoneticDictionary Penghitungan Akurasi Perubahan SMS AccuracyTester Menambahkan kosakata baru dalam daftar kata DictionaryMaker Menambahkan kosakata baru dalam kamus fonetik PhoneticDictionaryMaker PhoneticDictionary Menambahkan kosakata baru dalam kamus nama NameDictionaryMaker NameDictionary
3.8 Model Perancangan Perangkat Lunak
3.8.1 Perancangan Arsitektural
Bagian ini membahas perancangan arsitektural dari sistem perangkat lunak SMSRenderer ini agar fungsi utama yang dimiliki perangkat lunak dapat berjalan dengan baik. Arsitektur sistem dapat dilihat pada gambar III-10.
3.8.2 Perancangan Kelas
Bagian ini membahas perancangan kelas yang dibuat berdasarkan model analisa yang telah dilakukan. Kelas diagram tahap perancangan dapat dilihat pada lampiran F Diagram Kelas SMSRenderer. Perincian dari kelas-kelas yang ada pada perangkat lunak SMSRenderer dapat dilihat pada tabel III-9. Sedangkan pembahasan operasi-operasi utama yang terlibat dalam masing kelas serta masukan dan keluaran masing-masing operasi tersebut dijelaskan dalam lampiran H.
3.8.3 Perancangan Struktur Data
Struktur data utama yang digunakan di dalam perangkat lunak SMSRenderer ini ditunjukkan oleh gambar III-11.
Class SMSPreprocessor SMSWord : String angka :boolean fonetik:boolean maknaAngka: String processed:boolean word:String trueWord:String SMSParser sms : String[]
Gambar III-11 Struktur Data SMSRenderer
3.8.4 Perancangan Antarmuka
Berikut ini layar saji yang dirancang untuk memudahkan interaksi antara aplikasi ini dengan pengguna.
3.8.4.1 Layar Saji Utama
Pada layar saji utama ini pengguna melakukan semua operasi utama pada perangkat lunak ini.
Tabel III-9 Kelas-kelas pada Perangkat Lunak SMSRenderer No. Nama Kelas Kelas Analisis Operasi Utama
1. SMSParser Parser ‐parser()
2. SMSPreprocessor Preprocessor ‐isAdaAngka() ‐isAdaImbuhan() ‐isPhonetic() ‐isStrAngka() ‐isStrNama() ‐preprocessor() 3. SMSClassification Classification ‐klasifikasi() 4. SMSPostprocessor Postprocessor ‐angkaToFonem()
‐angkaToHuruf() ‐hurufToFonem() ‐prosesKelasSatu() ‐prosesKelasTiga() ‐prosesKelasEmpat() ‐prosesKelasLima() ‐postprocessor() 5. SMSDictionary Dictionary ‐isStringSama()
‐openFileDict() ‐searchDictionary() ‐
searchWordInDictionary() 6. SMSAccuracyTester AccuracyTester ‐compareSMS()
7. NameDictionaryLoader NameDictionary ‐loadNameDict() 8. PhoneticDictionaryLoader PhoneticDictionary ‐loadPhoneticDict() 9. SMSDictionaryMaker DictionaryMaker ‐loadSmsDict()
‐makeSmsDict() ‐cleanVector()
10. NameDictionaryMaker NameDictionaryMaker ‐loadNameDict() ‐makeNameDict() 11. PhoneticDictionaryMaker PhoneticDictionaryMaker ‐loadPhoneticDict()
‐makePhoneticDict() 12. SMSRendererUI SMSRendereInterface
Pengguna dapat memasukkan teks pesan singkat yang akan ditransformasikan kemudian melakukan pengubahan pesan singkat. Setelah itu pengguna dapat menghitung akurasi pesan singkat yang dibentuk. Selain itu operasi penambahan kata dalam daftar kata juga dapat dilakukan melalui layar saji ini. Tampilan layar saji ini dapat dilihat pada gambar III-12.
Gambar III-12 Layar Saji Utama
3.8.4.2 Layar Saji Buka Berkas SMS
Layar saji buka berkas SMS digunakan untuk menerima masukan nama berkas SMS yang berupa teks biasa yang akan ditransformasikan. Layar ini merupakan salah satu kelas dasar yang sudah tersedia di dalam bahasa Java 1.5. Tampilan layar saji ini dapat dilihat pada gambar III-13.
3.8.4.3 Layar Saji Buka Berkas SMS Pembanding
Layar saji buka berkas SMS Pembanding digunakan untuk menerima masukan nama berkas SMS Pembanding yang berupa teks biasa yang akan digunakan untuk membandingkan akurasi pesan singkat hasil transformasi perangkat lunak ini. Layar ini
merupakan salah satu kelas dasar yang sudah tersedia di dalam bahasa Java 1.5. Tampilan layar saji ini dapat dilihat pada gambar III-14.
3.8.4.4 Layar Saji Buka Berkas SMS Contoh
Layar saji buka berkas SMS Pembanding digunakan untuk menerima masukan nama berkas SMS Contoh yang berupa teks biasa yang akan digunakan untuk membentuk daftar kata yang akan dipergunakan oleh perangkat lunak ini. Layar ini merupakan salah satu kelas dasar yang sudah tersedia di dalam bahasa Java 1.5. Tampilan layar saji ini dapat dilihat pada gambar III-15.
Gambar III-13 Layar Saji Buka Berkas SMS
Gambar III-14 Layar Saji Buka Berkas SMS Pembanding