PELATIHAN PENELITIAN
DATA ENTRY
DAN
EVIEWS APPLICATION
MAMAN SETIAWAN
KERJASAMA
HIMPUNAN MAHASISWA EKONOMI DAN STUDI PEMBANGUNAN DAN
LABORATORIUM PENELITIAN, PENGABDIAN PADA
MASYARAKAT DAN PENGKAJIAN EKONOMI (LP3E)
FAKULTAS EKONOMI UNIVERSITAS PADJADJARAN
Kata Pengantar
Makalah/modul ini disampaikan pada acara ”Pelatihan Penelitian” yang dilaksanakan oleh Himpunan Mahasiswa Ekonomi Studi Pembangunan Fakultas Ekonomi Universitas Padjadjaran pada tanggal 6-8 Mei 2005 di Kampus Unpad Jl. Dipati Ukur No. 35. Adapun makalah/modul ini membahas tentang entri data serta aplikasi program eviews dalam suatu proses pengolahan data dalam penelitian. Peserta dalam acara ini berasal dari mahasiswa berbagai jurusan bidang studi ilmu dan berasal dari berbagai universitas negeri dan swasta di Bandung. Akhir kata semoga makalah/modul ini memberikan kontribusi atau sumbangan dalam suatu proses kegiatan penelitian.
Bandung, Mei 2005
Pengantar
Pengolahan data statistik memiliki peranan penting di dalam suatu penelitian karena dari hasil pengolahan data statistik ini muncul suatu kesimpulan penelitian. Pengolahan data mencangkup perhitungan data analisis model penelitian. Sebelum dilakukan kesimpulan penelitian, agar hasil penelitian menjadi akurat harus dilakukan uji validitas pada data dan model.
Training ini akan berusaha membahas bagaimana proses dari memasukan data hingga seorang peneliti bisa menggunakan hasil estimasi sebagai kesimpulan penelitian. Proses pengolahan data akan dilakukan dengan menggunakan software Eviews 3.1.
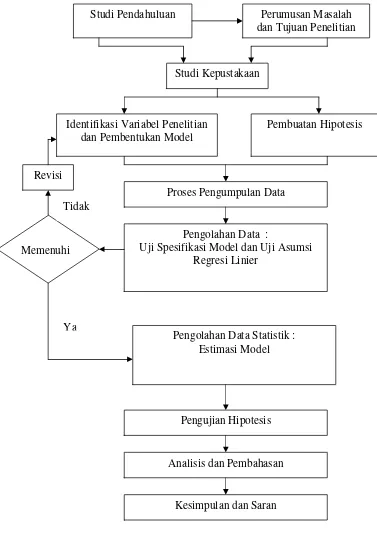
Pada dasarnya tahap penelitian bisa digambarkan sebagai berikut :
Gambar 1
Langkah-Langkah Penelitian
Studi Pendahuluan Perumusan Masalah
dan Tujuan Penelitian
Studi Kepustakaan
Identifikasi Variabel Penelitian dan Pembentukan Model
Pembuatan Hipotesis
Proses Pengumpulan Data
Pengolahan Data :
Uji Spesifikasi Model dan Uji Asumsi Regresi Linier
Pengolahan Data Statistik : Estimasi Model
Pengujian Hipotesis
Analisis dan Pembahasan
Kesimpulan dan Saran Memenuhi
Setelah model dan hipotesisnya terbentuk, tahap yang paling penting kemudian ialah proses pengolahan data dan model sehingga dari hasil hasil estimasi model nantinya bisa didapatkan kesimpulan akhir.
Kasus 1
Suatu perusahaan penjual bunga di daerah “X” ingin melihat faktor-faktor yang mempengaruhi penjualan bunga ros-nya. Perusahaan tersebut membuat model untuk tujuannya tersebut sebagai berikut :
Yt = 1 + 2 X2t + 3 X3t + 4 X4t + 5 X5t + ut
Di mana :
Y = Jumlah Penjualan Bunga Ros, (dalam lusin) X2 = Rata-rata harga bunga Ros, $/lusin
X3 = Rata-rata harga bunga mawar, $/lusin
X4 = Rata-rata tingkat pendapatan/kapita, $/week
X5 = Trend variabel dengan nilai 1,2,3, dan seterusnya, untuk periode 2001-III hingga
2005-II di daerah “X”
Untuk mengestimasi model di atas, perusahaan tersebut mengumpulkan database dari survey-survey yang telah dilakukannya selama tahun 2001 kwartal III hingga tahun 2005 kwartal II sehingga diperoleh data sebagai berikut :
Agar model tersebut di atas bisa diestimasi maka ada beberapa tahapan di eviews : 1. Entry data
2. Estimasi model dengan data yang dientry
I. Proses Entry data
Sebelum suatu model bisa diestimasi, maka data untuk variabel-nya harus tersedia dengan lengkap. Data harus dimasukan dulu ke dalam software dengan lengkap. Berikut cara entry data di Eviews :
Buka Program Eviews sehingga terlihat workfile sebagai berikut :
Sehingga muncul workfile sebagai berikut :
Karena datanya dalam bentuk kwartal maka checklist Quarterly | lalu masukan di star date : 2001:3 (tahun awal) kemudian masukan 2005:2 (tahun akhir) di end date.
Sehingga muncul workfile sebagai berikut :
Sehingga muncul kotak dialog sebagai berikut :
Isi type object dengan series (sama untuk semua variabel) , Isi name for Object dengan nama variabel : Y | Klik OK
Ulangi untuk variabel X2,X3,X4, dan X5 .
buka semua variabel yang masih kosong untuk diisi dengan data :
Tekan CTRL (tidak dilepas) bersamaan klik satu per satu variabel Y, X2, X3, X4,
danX5 | Lalu klik kanan pada mouse | pilih open as group | sehingga muncul hasil
sebagai berikut :
Klik Edit | Lalu isi setiap variabel dengan data pada tabel 1 di atas sehingga spreadsheet akhir akan terisi data sebagai berikut :
Klik name : Group 1 pada spreadsheet | Klik File | pilih save as : Data1
Bagaimana jika model tersebut memiliki model sebagai berikut :
LnYt = 1 + 2 Ln(X2t/X3t) + 3 Ln( X4t )+ 4 X5t + ut
Maka tahapan yang harus dilakuakn ialah :
1. Melakukan transformasi data di eviews dengan fasilitas Generate series
Klik Quick | Generate Series
Dikotak generate series satu per satu ditulis di sebagai berikut : LnY=Log(Y)
X2X3=X2/X3
Ln(X2X3)=Log(X2/X3) SqrtX4=Sqrt(X4)
Misalkan untuk LnY=Log(Y) : Klik Quick | Generate Series :
II. Proses Estimasi Model
Karena data sudah tersedia maka estimasi model untuk selanjutnya bisa dilakukan.
Model : Yt = 1 + 2 X2t + 3 X3t + 4 X4t + 5 X5t + ut
Caranya :
Masukan Model yang akan diestimasi ke dalam kotak dialog “equation specification”, sebagai berikut :
Penulisan persamaan di Eviews hanya variabelnya saja yang dipisahkan dengan
spasi. Variabel yang diketikan paling awal dibaca Eviews sebagai variabel dependen.
Kemudian C = 1.
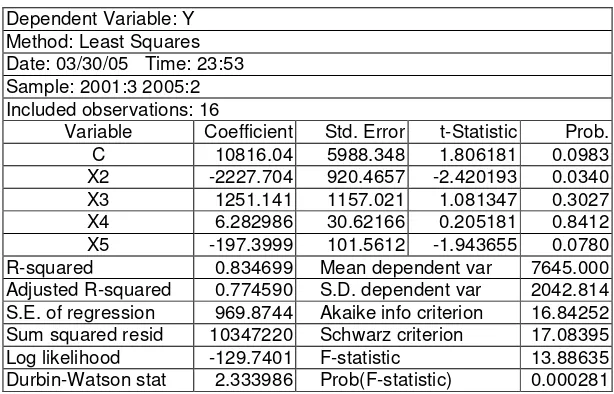
Klik View | Pilih Representation | sehingga diperoleh fungsi persamaan sebagai berikut :
Dependent Variable: Y Method: Least Squares Date: 03/30/05 Time: 23:53 Sample: 2001:3 2005:2 Included observations: 16
X3 1251.141 1157.021 1.081347 0.3027 X4 6.282986 30.62166 0.205181 0.8412 X5 -197.3999 101.5612 -1.943655 0.0780 R-squared 0.834699 Mean dependent var 7645.000 Adjusted R-squared 0.774590 S.D. dependent var 2042.814 S.E. of regression 969.8744 Akaike info criterion 16.84252 Sum squared resid 10347220 Schwarz criterion 17.08395 Log likelihood -129.7401 F-statistic 13.88635 Durbin-Watson stat 2.333986 Prob(F-statistic) 0.000281
Jika hasil diatas ditulis dihasilkan persamaaan sebagai berikut :
Y = 10816.04325 - 2227.70436*X2 + 1251.141202*X3 + 6.282986279*X4 Std. error (5988,35) (920,46) (1157,02) (30,62) -197.3999396*X5
Std. Error (101,56)
KlikName untuk menyimpan persamaan | beri nama : eq01
2.1 Pengujian Spesifikasi model
Uji Ramsey’s RESET
Ramsey membuat pengujian tentang spesifikasi error yang disebut RESET (
regression specification error test ). RESET test ini melihat suatu pola yang sistematik dari perubahan residual regresi ( uˆ ) dihubungkan dengan estimasi yi i (Yˆ ) i pada persamaan (a ) di bawah ini. Jika kita masukan Yˆ dalam persamaan (a) maka i
akan meningkatkan R2 dan jika kenaikan R2 ini secara statistik signifikan maka model persamaan (a) yang merupakan persamaan linear ialah miss-specified ( tidak memenuhi spesifikasi model ). Misal kita memiliki persamaan :
Yi = 1 + 2 Xi + u3i ..(a)
Di mana : Y= Total Cost dan X = output
Tahapan dalam RESET ini ialah :
1. Estimasi model a dengan OLS biasa kemudian didapat estimasi Yi yaitu Yˆ i
Ramsey menyarankan memasukan Yˆi2 dan Yˆi3 sebagai regressor tambahan. Sehingga kita estimasi persamaan :
Yi = 1+ 2X2 + 3X3 + 4X4 + 5X5+ 6 Yˆi
R . Dari hasil ini kita bisa mencari nilai F-statistiknya untuk mengetahui apakah kenaikan dalam R2 dari menggunakan model (a.1) itu signifikan atau tidak :
Jika nilai F-statistik yang telah dihitung itu signifikan pada tingkat misal 5% maka kita bisa menerima hipotesis bahwa model (a) itu misspecified. Sebaliknya jika nilai F-statistik yang telah dihitung itu tidak signifikan pada tingkat misal 5% maka model specified.
Caranya di eviews :
Dari hasil estimasi awal (eq.1) :
Klik View | stability test | pilih Ramsey Reset | masukan :2 (jika kita misalkan ada hubungan kuadratik)
F-statistik paling atas dari hasil estimasi ramsey test di eviews ialah sama dengan :
Jika nilai p-value F-statistik < =5% maka Ho ditolak
Ternyata p-value F-statistik = 0,52 > 0,05 maka Ho tidak ditolak sehingga bisa disimpulkan bahwa model di atas memenuhi spesifikasi (kelinieran).
2.2 Pengujian Masalah yang Terjadi dalam Regresi Linier
Pengujian Multikolinear
Multikolinier ialah kondisi dimana adanya hubungan antara variabel-variabel bebas. Jika multikolinier itu sempurna maka setiap koefisien regresi dari variabel-variabel bebasnya tidak dapat menentukan dan standar errornya tidak terbatas. Jika multikolinier kurang dari sempurna maka koefisien regresi walaupun bisa menentukan, tetapi memiliki standar error yang besar (dalam hubungan dengan koefisien mereka itu sendiri), yang berarti koefisien-koefisiennya tidak bisa diestimasi dengan akurasi yang tepat.
Cara umum untuk mendeteksi adanya multikolinear dalam model ialah dengan melihat bahwa adanya 2
R yang tinggi dalam model tetapi tingkat signifikansi t-statistiknya sangat kecil dari hasil regresi tersebut dan cenderung banyak yang tidak signifikan. Selain itu untuk menguji multikolinear, bisa dilihat matrik korelasinya. Jika masing-masing variabel bebas berkorelasi lebih besar dari 80 % maka termasuk yang memiliki hubungan yang tinggi atau ada indikasi multikolinearitas (Gujarati,2003).
Cara pengujian Multikolinear dengan matriks korelasi di Eviews sebagai berikut :
KlikView | PilihCorrelations
Dari matriks korelasi di atas terlihat bahwa hubungan antara variabel independennya (tidak termasuk Y) semuanya di bawah 70% sehingga bisa disimpulkan bahwa tidak terdapat masalah multikolinear di dalam model.
Pengujian Autokorelasi
Penaksiran model regresi linier mengandung asumsi bahwa tidak terdapat autokorelasi di antara disturbance terms, yaitu :
Cov ( ei, ej ) = 0 di mana i j
a. Autokorelasi ini umumnya terjadi pada data time series. Konsekuensi dari adanya autokorelasi pada model ialah bahwa penaksir tidak efisien dan uji t serta uji F yang biasa tidak valid walaupun hasil estimasi tidak bias (Gujarati, 2003).
Pengujian yang bisa digunakan untuk meneliti kemungkinan terjadinya autokorelasi adalah uji Durbin-Watson ( D-W ).
a. Metode Durbin-Watson Test
Metode Durbin Watson ini mengasumsikan adanya first order autoregressive
AR(1) dalam model.
Hipotesa dari uji tersebut ialah :
Jika d < du, H0 ditolak pada tingkat α sehingga secara statistik adanya mengandung autokorelasi negatif yang signifikan.
3. statistik terlihat bahwa adanya autokorelasi baik positif maupun negatif secara signifikan.
Tabel 3.3 Kriteria Pengujian Autokorelasi
Null Hipotesis Hasil Estimasi Kesimpulan
Ho 0 < dw < dl Tolak
Sumber: Basic Econometrics, Damodar Gujarati(2003)
Caranya Pengujian Autokorelasi di eviews :
Dependent Variable: Y Method: Least Squares Date: 03/30/05 Time: 23:53 Sample: 2001:3 2005:2 Included observations: 16
Variable Coefficient Std. Error t-Statistic Prob. C 10816.04 5988.348 1.806181 0.0983 Adjusted R-squared 0.774590 S.D. dependent var 2042.814 S.E. of regression 969.8744 Akaike info criterion 16.84252 Sum squared resid 10347220 Schwarz criterion 17.08395 Log likelihood -129.7401 F-statistic 13.88635 Durbin-Watson stat 2.333986 Prob(F-statistic) 0.000281
Jika kita uji berdasarkan tabel durbin-watson di atas maka dicari terlebih dahulu nilai dl dan du pada =1% dengan n=16 dan k’(jumlah variabel independen)=4 yaitu dl=0,532 dan 1,66. sehingga didapat :
positif tidak tentu tidak ada autokorelasi tidak tentu negatif Autokorelasi autokorelasi 0 dl=0,532 du=1,663 2 4-du= 2,337 4-dl= 3,468
karena 2,33 berada di daerah tidak ada autokorelasi maka bisa disimpulkan bahwa model tidak mengandung masalah autokorelasi.
2.3 Pengujian Homokedastisitas
Salah satu asumsi pokok dalam model regresi linear adalah homokedastisitas diartikan sebagai distribusi dari variabel gangguan ui, adalah suatu nilai konstan yang
sama σ2 untuk setiap nilai dari variabel penjelasnya, misal : Xi.
E(ui2 ) = σ2 i = 1,2,3,…,N
Jika variansnya tidak sama, maka dalam model tersebut terdapat situasi
heterokedastisitas, di mana :
Heteroskedastisitas sering terjadi pada model yang menggunakan data cross section, karena data tersebut menghimpun data yang mewakili berbagai ukuran (Sritua, 1993). Konsekuensi logis dari adanya heteroskedastisitas ialah bahwa penaksir tetap tak bias dan konsisten tetapi penaksir tadi tidak lagi efisien baik dalam sampel kecil maupun sampel besar.
Terdapat beberapa metode untuk mengidentifikasi adanya heteroskedastisitas, antara lain: metode grafik, metode Park, metode rank Spearman, metode Lagrangian Multiflier (LM test) dan white heteroscedasticity test.
a. Uji Heteroskedastisitas dengan metode White’s General Heterocedasticity
Metode pengujian dengan metode White ini tidak menggunakan asumsi normalitas sehingga sangat mudah untuk diimplementasikan dan sangat cocok dengan model logit yang berdistribusi Logistic (Gujarati,2003). Jika suatu model logit ialah sebagai berikut :
Yi = 1 + 2 X2i + 3 X3i + ui ..(b)
Maka proses pengujian dengan metode white ini ialah dengan melakukan regresi tambahan sebagai berikut : indepeden tersebut, serta dari interaksi variabel independennya (cross product(s) of the regressors). Dari hasil regresi ini tujuannya adalah untuk mendapatkan nilai R2 yang akan digunakan dalam pengujian hipotesis.
Pengujian hipotesis yang dilakukan ialah : H0 : Tidak ada heteroskedastis (homokedastis)
Pengujian :
Pada regresi persamaan (b.1) di atas didapat bahwa jumlah sampel (n) dikalikan dengan nilai R2 akan sama (asymtot) dengan distribusi Chi-Square dengan degree of freedom (DF) ialah sama dengan jumlah regressor (tidak termasuk konstanta) di dalam regresi tambahan, yaitu:
n . R2 ~ 2 df …..(b.2)
dari persaman b.1 di atas maka didapat df = 5 Tahap 4 :
Pengujian :
Jika nilai 2 dari persamaan b.1 lebih besar dari nilai 2 tabel maka H0 ditolak yang
artinya terdapat heteroskedastis di dalam model tetapi jika 2 dari persamaan b.1 lebih kecil dari nilai 2 tabel maka H0 diterima yang artinya tidak terdapat heteroskedastis
di dalam model dan juga bisa dikatakan bahwa koefisien –koefisien pada regresi tambahan :
2 = 3 = 4 = 5 = 6 = 0
Caranya Pengujian Homoskedastisitas di eviews :
Dari hasil estimasi model (eq.01) :
didapat hasil estimasi model white sebagai berikut :
Dari hasil estimasi didapat bahwa : Obs*R-squared =13,91 dengan p-value=0,45. : Obs*R-squared = n.R2 = 13,91.
Uji hipotesis :
Ho : Tidak ada heteroskedastisitas H1 : Ada heteroskedastisitas Pengujian :
Karena p-value= 0,45 > =5% maka Ho tidak ditolak, sehingga bisa disimpulkan bahwa tidak ada heteroskedastisitas di dalam model.
III. Analisis Model Regresi
Pengujian Statistik
Uji Koefisien Determinasi ( R ) 2
Koefisien determinasi ( R2 ), digunakan untuk mengukur seberapa besar variabel-variabel bebas dapat menjelaskan variabel-variabel terikat. Koefisien ini menunjukan seberapa besar variasi total pada variabel terikat yang dapat dijelaskan oleh variabel bebasnya dalam model regresi tersebut. Nilai dari koefisien determinasi ialah antara 0 hingga 1. Nilai R2 yang mendekati 1 menunjukan bahwa variabel dalam model tersebut dapat mewakili permasalahan yang diteliti, karena dapat menjelaskan variasi yang terjadi pada variabel dependennya. Nilai R2 sama dengan atau mendekati 0 ( nol ) menunjukan variabel dalam model yang dibentuk tidak dapat menjelaskan variasi dalam variabel terikat. Penghitungan R2 diperoleh dari :
−
Nilai koefisien determinasi akan cenderung semakin besar bila jumlah variabel bebas dan jumlah data yang diobservasi semakin banyak. Oleh karena itu, maka digunakan ukuran adjusted R2 (R2), untuk menghilangkan bias akibat adanya penambahan
Dalam analisis data time series, jika koefisisen determinasi ( 2
R ) > Durbin Watson ( DW ) statistik maka itu menandakan regresi mengalami spurious regression.
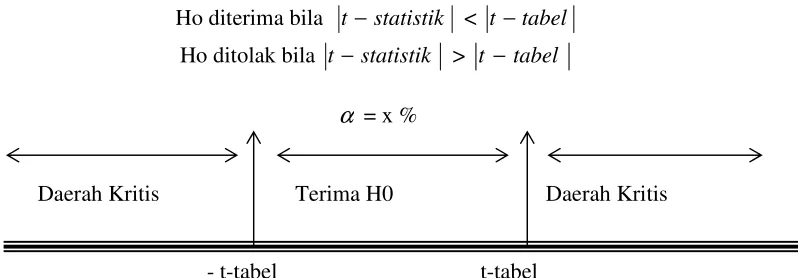
Uji t- Statistik
Uji t-statistik digunakan untuk menguji pengaruh variabel-variabel bebas terhadap variabel tak bebas secara parsial. Uji t-statistik biasanya berupa pengujian hipotesa : Ho = Variabel bebas tidak mempengaruhi variabel tak bebas
H1 = Variabel bebas mempengaruhi variabel tak bebas
Dengan menguji dua arah dalam tingkat signifikansi =
α
dan df = n – k ( n = jumlah observasi, k = jumlah parameter ) maka hasil pengujian akan menunjukan :Ho diterima bila t− statistik < t−tabel Gambar Pengujian t – Statistik
Nilai t-statistik didapatkan dengan rumus :
t
Di mana βt ialah koefisien variabel dan Sβt ialah standar error dari variabel.
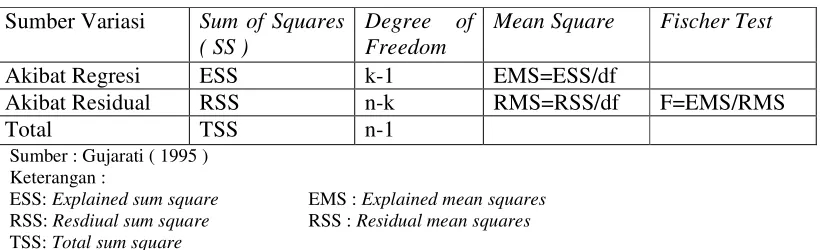
Analisis Variansi/Uji F-Statistik
Uji F-statistik ialah untuk menguji pengaruh variabel bebas terhadap variabel tak bebas secara keseluruhan. Uji F-statistik biasanya berupa :
Ho = Variabel bebas tidak mempengaruhi variabel tak bebas H1 = Variabel bebas mempengaruhi variabel tak bebas
Untuk mendapatkan Nilai F-statistik, digunakan tabel ANOVA ( analysis of variance)
seperti diperlihatkan pada tabel di bawah ini :
Tabel ANOVA Sumber Variasi Sum of Squares
( SS )
Degree of Freedom
Mean Square Fischer Test
Akibat Regresi ESS k-1 EMS=ESS/df
Akibat Residual RSS n-k RMS=RSS/df F=EMS/RMS
Total TSS n-1 telah diketahui, di mana :
k jumlah parameter ) maka hasil pengujian akan menunjukan :
Ho diterima bila F −statistik < F −tabel
Lihat Hasil Estimasi Eq 1.
Dependent Variable: Y Method: Least Squares Date: 03/30/05 Time: 23:53 Sample: 2001:3 2005:2 Included observations: 16
Variable Coefficient Std. Error t-Statistic Prob. C 10816.04 5988.348 1.806181 0.0983 Adjusted R-squared 0.774590 S.D. dependent var 2042.814 S.E. of regression 969.8744 Akaike info criterion 16.84252 Sum squared resid 10347220 Schwarz criterion 17.08395 Log likelihood -129.7401 F-statistic 13.88635 Durbin-Watson stat 2.333986 Prob(F-statistic) 0.000281
Menjadi lebih mudah dibaca jika kita buat tampilan sebagai berikut :
Tabel Hasil Estimasi Model
Dependent Variable: Y
Variable Coefficient Std. Error t-Statistic Prob. C 10816.04 5988.348 1.806181 * Adjusted R-squared 0.774590 Prob(F-statistic) *** Keterangan :
*** = signifikan pada = 1% TS = Tidak signifikan ** = signifikan pada = 5%
* = Signifikan pada = 10%
Nilai R2 artinya bahwa sebesar 83,5 %variabel penjualan buang ros bisa dijelaskan oleh variabel bunga ros itu sendiri, variabel bunga mawar,pendapat/kapita, dan trend waktu sedangkan sisanya sebesar 16,5% bisa dijelaskan oleh variabel lain diluar model.
Dari hasil uji F-statistik didapat bahwa nilai F-statistik signifikan pada =1%, hal ini mengindikasikan bahwa secara keseluruhan, semua variabel independen mampu menjelaskan variabel dependennya yaitu penjualan bunga ros.
sedangkan variabel tingkat harga bunga mawar dan tingkat pendapatan/kapita tidak signifikan mempengaruhi penjualan bunga ros.
Cara Membaca hasil estimasi Regresi :
Untuk variabel X2=-2227,704 artinya ialah bahwa jika Variabel X2 naik sebesar 1 unit akan menyebabkan penurunan pada penjualan bungan ros sebesar 2227,705 unit, ceteris paribus. Hal ini mengindikasikan bahwa tingkat harga memiliki hubungan negatif dengan penjualan bunganya itu sendiri.
Untuk variabel X3 = 1251,141 artinya ialah bahwa jika variabel X3 naik sebesar 1 unti akan menyebabkan kenaikan penjualan bungan Ros sebesar 1251,141 unit,ceteris paribus. Hal ini mengindikasikan bahwa antara bunga Ros dan mawar merupakan
barang substitusi.
Untuk variabel X4 = 6,29 artinya ialah bahwa jika variabel X4 naik sebesar 1 unit akan menyebabkan kenaikan penjualan bunga ros sebesar 6,29 unit, ceteris paribus. Hal ini mengindikasikan bahwa semakin tinggi tingkat pendapatan per kapita masyarakat maka masyarakat cenderung akan banyak membeli bunga Ros.
Penulisan Pelaporan Penelitian
DAFTAR ISI
ABSTRAK i
ABSTRACT ii
PEDOMAN PENGGUNAAN TESIS iii
KATA PENGANTAR v
1.1 Latar belakang penelitian 2
1.2 Identifikasi Masalah 6
1.3 Kegunaan Penelitian 6
1.4 Metodologi 7
1.5 Lingkup Penelitian 7
1.6 Sistematika Pembahasan 8
BAB II TINJAUAN PUSTAKA 9
2.1 Teori-teori Pendukung Penelitian 9
2.2 Kajian Beberapa Studi Empiris 42
2.3 Sintesis Penelitian ( State of the Art ) 43
BAB III METODE PENELITIAN 45
3.1 Langkah Penelitian 45
3.2 Identifikasi Variabel Penelitian dan Pembentukan Model 46
3.3 Objek Penelitian dan Perumusan Hipotesa 55
3.4 Hipotesis 58
3.5 Pengumpulan dan Pengolahan Data 59
3.7 Analisis Regresi 65
3.7.1 Persamaan Regresi Berganda Biasa 65
3.7.2 Pengujian Masalah yang terjadi dalam Regresi Linier 66
3.7.3 Pengujian Statistik 69
BAB IV PENGOLAHAN DATA 83
4.1 Variabel-variabel Penelitian 85
4.4 Pengujian Asumsi OLS Klasik 99
4.5 Uji Spesifikasi Model 102
BAB V ANALISA 103
5.1 Analisis Hubungan antara Variabel dependen dengan variabel independennya
103
5.1.1 Analisis Statistik 103
5.1.2 Analisis Ekonomi
BAB VI KESIMPULAN DAN SARAN 119
6.1 Kesimpulan Umum dari Hasil Bab V 119
6.2 Saran 123
DAFTAR PUSTAKA
Daftar Pustaka
1. Arief, Sritua (1993), Metodology Penelitian Ekonomi, UIP, Jakarta.
2. Greene H. (2000), William, Econometric Analysis,Prentice Hall, New Jersey. 3. Gujarati N., Damodar (1995), Basic Econometrics , McGraw-Hill.
4. Intriligator, Michael (1980), Econometrics Models, Techniques, and Applications, Prentice-Hall Inc., New Delhi.
5. Lubis, Hari (2003), “Metodologi Penelitian“, Diktat Kuliah, Departemen Teknik Industri, ITB.