1
PENDAHULUAN
Latar Belakang
Pola pengaksesan pengguna terhadap sebuah situs web biasanya tergambarkan dalam sebuah pola sekuensial. Pola sekuensial mengindikasikan bahwa transaksi biasanya terjadi secara serial terhadap waktu. Oleh karena itu, analisis terhadap pola sekuensial didasarkan pada urutan waktu atau urutan terjadinya suatu transaksi.
Salah satu metode yang digunakan untuk mendapatkan tatanan antarmuka dan isi yang strategis adalah sequential pattern mining. Metode tersebut pertama kali diperkenalkan oleh Agrawal & Srikant (1995) dan bertujuan untuk mencari kemunculan suatu item yang diikuti kemunculan item lain secara terurut berdasarkan waktu terjadinya transaksi. Metode ini dapat juga digunakan untuk mengetahui trends dari pengguna terkait pola pengaksesannya terhadap sebuah situs web.
Untuk ”memperhalus” batasan yang tegas yang terdapat pada data yang bernilai numerik maka diterapkan konsep fuzzy pada sequential
pattern mining. Pola tersebut dikarakterisasikan
oleh nilai support, yaitu persentase banyaknya transaksi yang mengikuti aturan tersebut.
Salah satu teknik web mining yang dapat digunakan untuk mengetahui pola sekuensial yaitu Totally Fuzzy. Teknik ini menggunakan metode Thresholded Sigma Count untuk mendapatkan nilai fuzzy cardinality dari tiap-tiap pengguna sebuah situs web (Fiot. C et al 2005). Pada pendekatan ini, masing-masing
fuzzy itemset diperhitungkan dalam proses
komputasi untuk mendapatkan nilai fuzzy
support.
Pemahaman terhadap user preference yang tercatat pada data log akses akan mengarahkan sebuah situs web semakin dekat dengan pengguna dan meningkatkan kualitas sebuah situs web, sehingga secara tidak langsung dapat meningkatkan besarnya kemungkinan sebuah situs web untuk tetap bertahan pada lingkungan bisnis yang kompetitif.
Tujuan Penelitian
Penelitian ini bertujuan untuk melihat trends dari pengguna yang mengakses situs web IPB.
Trends tersebut dapat dilihat berdasarkan
informasi mengenai besarnya beban akses suatu halaman pada situs web IPB. Berdasarkan informasi tersebut pada akhirnya dapat diketahui halaman-halaman yang sering dikunjungi oleh pengguna situs web IPB dan dapat digunakan untuk meningkatkan perancangan situs web berdasarkan pola pemakaian.
Ruang Lingkup Penelitian
Ruang lingkup untuk penelitian ini dibatasi pada penerapan metode Totally Fuzzy pada data log akses server web IPB dari tanggal 5 Januari 2007 hingga 18 Juni 2007. Data tersebut dikelompokkan ke dalam dua bagian, yaitu internal dan eksternal IPB. Analisa dilakukan terhadap kedua kelompok data tersebut. Penelitian ini akan menghasilkan informasi mengenai pola pengaksesan yang dilakukan oleh pengguna.
Manfaat Penelitian
Informasi yang didapatkan pada penelitian ini diharapkan dapat digunakan untuk meningkatkan performa dan perancangan situs web berdasarkan pola pemakaian, perubahan struktur dan rancangan web menjadi lebih strategis, mendapatkan pola akses pengunjung web IPB baik internal maupun eksternal yang mengakses situs web IPB (www.ipb.ac.id) dan mengetahui halaman-halaman situs web IPB yang sering dikunjungi oleh pengguna.
TINJAUAN PUSTAKA
Web mining
Web mining merupakan penerapan
teknik-teknik data mining untuk secara otomatis mengumpulkan dan mengekstrak informasi dari sebuah dokumen web. Web mining merupakan suatu teknik yang dapat membantu pengguna untuk menemukan suatu informasi dari sekumpulan data. Selain itu, web mining mengamati pola akses kunjungan pengguna pada sebuah situs web (Kamber 2006).
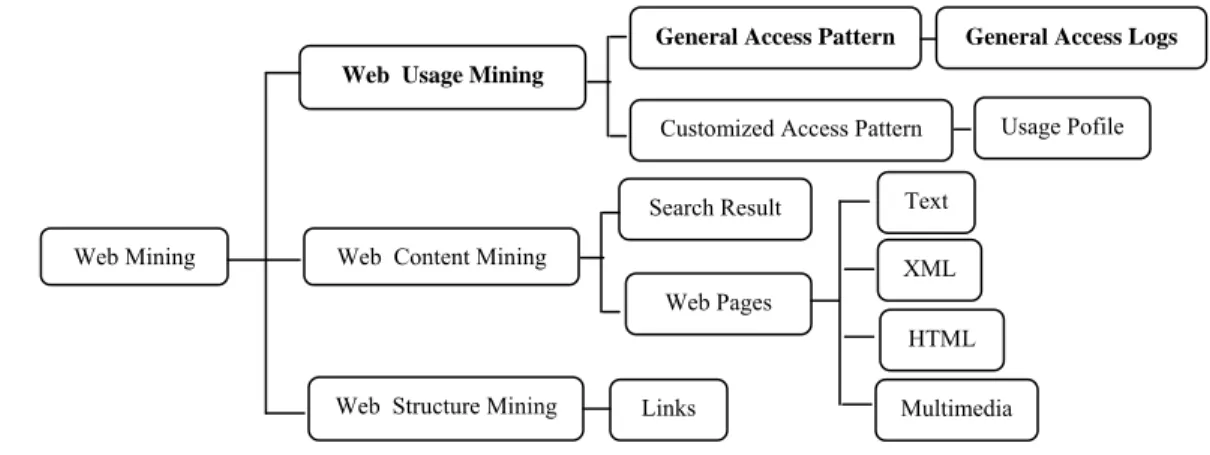
Secara umum web mining diklasifikasikan ke dalam tiga kategori berdasarkan jenis data yang diekstrak, yaitu web usage mining, web content
mining, dan web structure mining. Arsitektur web mining ditunjukkan pada Gambar 1.
2 Deskripsi mengenai masing-masing kategori
tersebut, yaitu : 1. Web usage mining
Web usage mining berusaha menemukan
nilai data berdasarkan pola tingkah laku
web surfer.
2. Web content mining
Menggambarkan proses penemuan informasi yang berasal dari konten, data atau dokumen sebuah web.
3. Web structure mining
Web structure mining mencoba
menemukan sebuah model pada struktur
link sebuah web.
Salah satu bagian dari web usage mining adalah General Access Pattern Tracking (GAPT). Gagasan utama pada GAPT adalah melihat secara umum trends pengguna yang mengakses situs web tersebut.
Informasi yang diperoleh dapat digunakan untuk perancangan ulang sebuah situs web sehingga memudahkan proses pengaksesan yang dilakukan oleh pengguna.
Knowledge Discovery from Data (KDD) Knowledge Discovery from Data (KDD)
adalah suatu proses mengekstrak ilmu pengetahuan atau informasi yang berasal dari kumpulan data dalam jumlah besar (Kamber 2006). Data mining adalah proses penemuan pengetahuan yang menarik dari kumpulan data yang tersimpan pada basis data, data warehouse dan media penyimpanan informasi lainnya.
Tahapan-tahapan proses KDD diilustrasikan pada Gambar 2.
Gambar 2 Tahapan proses KDD (Han & Kamber 2006).
Deskripsi mengenai tahapan-tahapan tersebut adalah sebagai berikut :
1. Pembersihan data
Pembersihan terhadap data dilakukan untuk menghilangkan noise dan data yang tidak konsisten.
2. Integrasi data
Integrasi data dilakukan untuk menggabungkan data yang berasal dari berbagai sumber.
3. Seleksi data
Proses seleksi data merupakan proses pengambilan data yang relevan dengan proses analisis yang dilakukan.
4. Transformasi data
Data ditransformasikan atau digabungkan ke dalam bentuk yang sesuai untuk
di-mining dengan cara melakukan peringkasan
atau operasi agregasi. 5. Data mining
Merupakan proses yang penting dan merupakan tahapan ketika metode-metode
Data Mining
Knowledge
Gambar 1 Arsitektur web mining.
Web Mining
Web Usage Mining
Web Content Mining
Web Structure Mining
General Access Pattern
Customized Access Pattern Search Result
Web Pages
Links
General Access Logs
Usage Pofile Text
XML HTML Multimedia
3 cerdas diaplikasikan untuk mengekstrak
pola-pola dari kumpulan data. 6. Evaluasi pola
Merupakan suatu proses untuk mengidentifikasikan pola-pola tertentu pada data yang menarik dan mempresentasikan pengetahuan.
7. Representasi pengetahuan
Penggunaan visualisasi dan teknik representasi untuk menunjukkan penemuan pengetahuan hasil proses mining kepada pengguna.
Association Rule Mining
Aturan Asosiasi (association rule) atau analisis afinitas (affinity analysis) berkenaan dengan studi 'apa bersama apa'. Pada dasarnya aturan ini digunakan untuk menggambarkan keterkaitan antar item pada sekumpulan data (Santoso 2007).
Secara umum aturan asosiasi dapat dipandang sebagai proses yang terdiri dari 2 tahap (Kamber 2006), yaitu :
1. Menemukan kumpulan frequent item. Sebuah itemset dikatakan frequent item jika memiliki frekuensi kemunculan minimal sama dengan nilai minimum support.
2. Membangkitkan aturan asosiasi dari itemset yang dikatakan frequent item. Aturan ini harus memenuhi nilai minimum support. • Support
Support bagi suatu aturan asosiasi adalah proporsi banyaknya kejadian pada basis data dimana proporsi sekumpulan item A dan proporsi sekumpulan item B terdapat pada sebuah transaksi. Definisi dari support, yaitu sebagai berikut :
support(A→B) = P(A U B) (1) Pola Sekuensial
Pola sekuensial adalah daftar urutan dari sekumpulan item. Sebuah pola sekuensial dikatakan maksimal jika tidak mengandung pola sekuensial lainnya (Wang et al 2005). Sebuah pola sekuensial dengan item disebut dengan
k-sequence. Panjang pada sebuah pola sekuensial
adalah jumlah item yang terdapat pada pola sekuensial tersebut dan dilambangkan dengan |s|. Sebuah subsequence s’ dari s dilambangkan dengan s’ ⊆ s. Misalkan, sebuah pola sekuensial
a = <a1a2...an> merupakan subsequence dari b = <b1b2...bm> jika terdapat integer i1 < i2 < ...in, 1 ≤ ik ≤ m, sehingga a1 ⊆ b1, a2 ⊆ b2, ...., an ⊆ bm.
Diberikan basis data transaksi D dan ambang batas minimum support ε, maka dapat didefinisikan sequential pattern mining adalah mencari nilai frequent sequence yang maksimal di antara semua pola sekuensial yang mempunyai nilai support lebih besar atau sama dengan ε. Dalam hal ini, waktu terjadinya transaksi juga akan dipertimbangkan dalam pencarian pola sekuensial.
Himpunan Fuzzy
Logika fuzzy merupakan generalisasi dari logika klasik yang hanya memiliki dua nilai keanggotaan, yaitu 0 dan 1. Dalam logika fuzzy nilai kebenaran suatu pernyataan berkisar dari sepenuhnya benar ke sepenuhnya salah. Inti dari himpunan fuzzy, yaitu fungsi keanggotaan yang menggambarkan hubungan antara domain himpunan fuzzy dengan nilai derajat keanggotaan. Hal yang membedakan antara himpunan boolean dan fuzzy, yaitu elemen pada himpunan fuzzy memiliki nilai derajat keanggotaan t (Cox 2005).
Hubungan pada himpunan fuzzy bersifat fungsional karena mengembalikan sebuah derajat keanggotaan untuk nilai yang terdapat pada domain x. Definisi dari derajat keanggotaan sebuah himpunan fuzzy f adalah sebagai berikut :
t = f(s,x) (2)
Peubah Linguistik
Peubah linguistik merupakan sebuah himpunan fuzzy yang membentuk aturan tertentu untuk sebuah variabel dan digunakan pada aturan fuzzy sebagai bagian dari hubungan fuzzy (Cox 2005).
Peubah linguistik dikarakterisasikan oleh
quintaple (x, T(x), X, G, M) dengan x adalah
nama peubah, T(x) adalah kumpulan dari
linguistic term, X adalah nilai interval x, G
adalah aturan sintak yang membangkitkan term dalam T(x), M adalah aturan semantik yang bersesuaian dengan nilai linguistik M(A), dengan M(A) menunjukkan fungsi keanggotaan untuk himpunan fuzzy dalam X. Sebagai contoh, jika frekuensi pengaksesan dipresentasikan
4 sebagai peubah linguistik, maka himpunan dari
linguistic term T(frekuensi akses) menjadi : T(frekuensi akses) = {rendah, sedang, tinggi}
Setiap term dalam T(frekuensi akses) dikarakterisasikan oleh himpunan fuzzy dalam X.
Fuzzy C-Means
Fuzzy C-Means merupakan salah satu
metode pengklasteran data, dimana objek dikelompokkan ke dalam k kelompok atau klaster. Untuk melakukan teknik klastering ini, nilai k harus ditentukan terlebih dahulu. Pada teknik ini digunakan ukuran ketidakmiripan dalam mengelompokkan objek-objek tersebut. Ketidakmiripan bisa diterjemahkan dalam konsep jarak (Cox 2005).
Pada Fuzzy C-Means, setiap data bisa menjadi anggota dari beberapa klaster. Sesuai dengan konsep fuzzy yang berarti samar, maka batas-batas klaster dalam Fuzzy C-Means adalah
soft. Dalam Fuzzy C-Means, pusat klaster
dihitung dengan mencari nilai rata-rata dari semua titik dalam suatu klaster dengan diberi bobot berupa tingkat keanggotaan (degree of
belonging) dalam klaster tersebut. Fuzzy Cardinality
Terdapat tiga metode untuk mengkomputasikan nilai fuzzy cardinality (Fiot
et al. 2005), yaitu :
1. Menghitung semua elemen yang memiliki nilai derajat keanggotaan tidak sama dengan nol.
2. Hanya memperhitungkan elemen yang memiliki nilai derajat keanggotaan lebih besar dari nilai ambang batas (threshold) yang telah didefinisikan.
3. Menambahkan nilai derajat keanggotaan dari masing-masing elemen. Metode perhitungan ini disebut juga Sigma Count. 4. Menambahkan nilai derajat keanggotaan
dari masing – masing elemen yang memiliki nilai lebih besar dari nilai ambang batas (threshold) yang telah ditentukan. Metode penghitungan ini disebut juga Thresholded
Sigma Count.
Fuzzy Candidate Sequence
Untuk membangkitkan suatu elemen kandidat pola sekuensial fuzzy maka harus terlebih dahulu dilakukan proses validasi, yaitu untuk memeriksa apakah dua buah fuzzy item yang terdapat pada sebuah fuzzy itemset tidak menunjuk pada sebuah atribut yang sama (Fiot
et al 2005).
Langkah awal yang harus dilakukan adalah menghitung nilai fuzzy support bagi masing-masing item dan hanya item yang memiliki nilai support lebih besar dari nilai minimum
support yang akan disimpan sebagai frequent sequence dengan nilai k berukuran satu.
Kandidat pola sekuensial dengan ukuran k, dikatakan sebagai k-sequence, diperoleh dengan mengkombinasikan frequent sequence dengan ukuran k-1. Proses tersebut akan berhenti jika tidak memungkinkan lagi untuk membangkitkan kandidat pola sekuensial dengan ukuran k+1.
File Log Akses
Pengelolaaan server web secara efektif membutuhkan feedback atau aktivitas kinerja
server serta permasalahan-permasalahan yang
mungkin terjadi. Feedback ini dapat berupa informasi mengenai pengguna-pengguna yang mengakses situs web, apa yang diakses dan statusnya serta waktu pengaksesan. Informasi tersebut tersimpan pada server web terutama data log akses (Purnomo & Anindito 2006).
Common Log Format (CLF) untuk setiap
baris data pada log akses, yaitu :
remotehost rfc931 authuser [date] ”request” status bytes
Tabel 1 Deskripsi format data log akses
Field Deskripsi
Remotehost Nama host atau alamat IP dari
pengguna yang mengakses situs web.
rfc931 User name dari pengguna pada remote system seperti yang
dispesifikasikan pada RFC931.
Authuser Username yang melakukan
otentifikasi seperti yang dispesifikasikan pada RFC931. [date] Informasi tanggal dan waktu
saat melakukan request HTTP pewaktuan lokal.
5
Field Deskripsi
”request” Informasi HTTP request dari
pengguna.
Status Angka numerik yang
menyatakan kode status dari HTTP yang dikirimkan kepada pengguna.
Bytes Panjang bytes dari data yang
dikirimkan kepada pengguna. Sumber : http://www-group.slac.stanford.edu
/techpubs/logfiles/info.html
Totally Fuzzy
Diberikan sebuah basis data transaksi D yang berisi data yang mencatat transaksi yang dilakukan customer. Misalkan T adalah sekumpulan transaksi. Masing-masing transaksi meliputi tiga informasi : customer-id, waktu terjadinya transaksi, dan sekumpulan item. Sebuah itemset, (i1,i2,...,ik), merupakan
himpunan bagian I = {i1,i2,..,im}. Sebuah pola
sekuensial s merupakan himpunan item yang tidak kosong, yang dilambangkan dengan <s1s2...sp>. Secara umum, support bagi sebuah
pola sekuensial adalah persentase customer yang memiliki s pada transaksi yang dilakukannya.
Sebuah fuzzy item didefinisikan sebagai hubungan antara sebuah item dengan sebuah
fuzzy set yang bersesuaian. Sebuah fuzzy item
dinotasikan dengan (x,α) dimana x merupakan sebuah item dan α merupakan fuzzy set dari item yang bersangkutan. Misalkan, (/php/tutor.htm,
lot) adalah sebuah fuzzy item dengan lot
merupakan sebuah fuzzy set yang didefinisikan oleh suatu derajat keanggotaan (membership
degree) pada pengaksesan item /php/tutor.htm.
Sebuah fuzzy itemset adalah himpunan fuzzy
item. Sebuah fuzzy itemset dinotasikan dengan
(X,A) dengan X menunjukkan kumpulan item dan A kumpulan dari fuzzy set dari item yang bersangkutan. Sebuah fuzzy sequence S = <s1... sn> adalah sebuah pola sekuensial yang terdapat
pada fuzzy itemset, misalkan [(/php/tutor.htm,
lot) (/php/faq.php, little) (/php/functions.php, lot)].
Cara untuk mengkomputasikan nilai fuzzy
cardinality pada algoritma Totally Fuzzy adalah
dengan menggunakan metode Thresholded
Sigma Count (Fiot. C et al 2005). Nilai derajat
keanggotaan μα suatu atribut t pada domain x
dinotasikan dengan μα(t[x]) dan nilai ambang
batas (threshold) dinotasikan dengan ω. Nilai derajat keanggotaan αa pada algoritma Totally Fuzzy didefinisikan sebagai berikut :
(3) Formulasi penghitungan nilai Support
Totally Fuzzy (STF) bagi seorang customer c,
yaitu :
(4)
Nilai fuzzy support Fsupp bagi sebuah fuzzysequence dikomputasikan sebagai rasio jumlah customer yang memiliki pola sekuensial fuzzy
tertentu pada transaksi yang dilakukannya dibandingkan dengan jumlah total customer C pada basis data.
(5)
Derajat nilai sebuah fuzzy support STF(c,gS)
mengindikasikan bahwa pada transaksi yang dilakukan oleh seorang customer c terdapat
fuzzy sequence gS. Derajat nilai fuzyy support
dikomputasikan dengan menggunakan algoritma
CalcTotallySupport seperti yang ditunjukkan
pada Gambar 3.
CalcTotallySupport
– Input : gS, candidate k-sequence;
Output : Fsupp fuzzy support for the sequence gS;
Fsupp, nbSupp,m 0;
For each customer client c Є C do
m FindTotallySeq(g-S, Tc)
[the customer support degree is aggregated to
the current support]
nbSupp += m;
End for
Fsupport nbSupport/T; Return Fsupp;
Gambar 3 Algoritma CalcTotallySupport. Untuk menentukan sebuah frequent sequence, nilai minimum support ditentukan terlebih dahulu oleh pengguna. Sebuah pola sekuensial
fuzzy dikatakan frequent sequence jika
memenuhi kondisi bahwa support (s) > minSupp.