i
IDENTIFIKASI OTOMATIS “SPECTRA SIGNATURE” SENYAWA AKTIF
DALAM TANAMAN OBAT MEMPERGUNAKAN METODE “DYNAMIC TIME
WARPING”(DTW)
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Jurusan Teknik Informatika
Oleh :
Wiliams Andrian
NIM : 065314050
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
AUTOMATIC IDENTIFICATION "SPECTRA SIGNATURE" ACTIVE COMPOUND IN MEDICINE PLANT USING "DYNAMIC TIME
WARPING" METHOD (DTW)
A THESIS
Presented as Partial Fulfillment of the Requirements
To Obtain the Sarjana Komputer Degree In Department of Informatics Engineering
By :
Wiliams Andrian
NIM : 065314050
INFORMATICS ENGINEERING STUDY PROGRAM
INFORMATICS ENGINEERING DEPARTMENT
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
2012
iv
v
!
" # !
$ !
" % & ' (
vi
viii
ABSTRAK
Tugas akhir ini bertujuan untuk membangun sebuah sistem yang dapat
mengidentifikasi secara otomatis “spectra signature” senyawa aktif dalam
tanaman obat (penelitian dilakukan dengan membandingkan “spectra signature”
yang sama dengan yang ada didalam sistem). Identifikasi dilakukan dengan
mempergunakan metode “Dynamic Time Warping”(DTW). Penelitian ini
menggunakan data hasil analisis elusidasi struktur dengan spektrofotometri “Mass
Spectrometer” yang berjumlah 200 data. Berdasarkan hasil penelitian yang
dilakukan dengan mempergunakan metode DTW diperoleh akurasi 87,5%.
Kata kunci = “Spectra Signature”, “Dynamic Time Warping”(DTW), elusidasi
struktur, spektrofotometri,“MasSpectrometer”
ix
ABSTRACT
This thesis aims to build a system that can automatically identify "spectra
signature" active compounds in medicinal plant (research done by comparing
similar "spectra signature" in the system). Identification performed by using the
"Dynamic Time Warping" (DTW) method. This research uses data from the result
of elucidation structure analysis spectrophotometric "Mass Spectrometer" with
200 data. Based on the results of research conducted using the DTW method
obtained 87.5% accuracy.
Keywords = “Spectra Signature”, “Dynamic Time Warping”(DTW), elucidation
x
KATA PENGANTAR
Puji syukur kepada Tuhan Yang Maha Esa yang telah memberikan segala
karunia-Nya sehingga penulis dapat menyelesaikan skripsi dengan judul “Identifikasi Otomatis “Spectra Signature” Senyawa Aktif Dalam Tanaman Obat Mempergunakan Metode Dynamic Time Warping (DTW)”. Dalam kesempatan ini, penulis ingin mengucapkan terima kasih yang sebesar-besarnya kepada semua
pihak yang turut memberikan dukungan, semangat dan bantuan hingga selesainya
skripsi ini:
1. Romo Dr. Cyprianus Kuntoro Adi, S.J., M.A., M.Sc. selaku dosen
pembimbing, terimakasih atas segala bimbingan dan kesabaran dalam
mengarahkan dan membimbing penulis dalam menyelesaikan tugas akhir
ini.
2. Ibu P.H. Prima Rosa, S.Si., M.Sc selaku Dekan Fakultas Sains dan
Teknologi Universitas Sanata Dharma Yogyakarta.
3. Ibu Ridowati Gunawan, S.Kom., M.T. selaku kaprodi Teknik Informatika.
4. Bapak Albert Agung Hadhiatma S.T., M.T. dan Bapak Eko Hari Parmadi
S.Si., M.Kom. selaku dosen penguji.
5. Seluruh staff pengajar Prodi Teknik Informatika Fakultas Sains dan
Teknologi Universitas Sanata Dharma.
6. Kedua orang tua dan adik saya yang tercinta, yang telah memberi
dukungan kepada penulis baik spiritual maupun material.
xii DAFTAR ISI
HALAMAN JUDUL ... i
HALAMAN JUDUL (INGGRIS) ... ii
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iv
PERNYATAAN KEASLIAN KARYA ... vi
PERNYATAAN PERSETUJUAN ... vii
1.5 Sistematika Penulisan. ... 5
BAB II : LANDASAN TEORI ... 7
xiii
2.2. Mass Spectrometer ... 8
2.3. Knowledge Discovery in Database (KDD) ... 11
2.4. Dynamic Time Warping ... 13
2.5. Rumus menghitung nilai kemiripan spektra dan contoh penerapan nya 23 2.6. Kompleksitas Waktu. ... 26
BAB III : METODOLOGI ... 28
3.1. Data Mass Spectrometer. ... 28
3.2. Preprocessing... 29
BAB IV : IMPLEMENTASI DAN ANALISA HASIL ... 34
4.1. Hasil dan Analisis. ... 34
4.2. Implementasi Antar-Muka yang Digunakan Dalam Sistem ... 39
4.3. Kompleksitas Waktu Asimptotik. ... 41
BAB V : PENUTUP ... 45
5.1. Kesimpulan ... 45
5.2. Saran ... 46
xiv
DAFTAR GAMBAR
Gambar 2.1. contoh grafik spektra massa ... 8
Gambar 2.2. Diagram hasil output Mass Spectrometer ... 10
Gambar 2.3. Proses KDD ... 11
Gambar 2.4 Node dalam batasan lokal ... 15
Gambar 2.5. Grafik vektor r... 17
Gambar 2.6. Grafik vektor t ... 17
Gambar 2.7. vektor r dan t setelah menggunakan forward DP ... 20
Gambar 2.8.Dynamic Time Warping ... 22
Gambar 2.9. Kelemahan DTW ... 23
Gambar 2.10. kemiripan dan perbedaan untuk atribut yang sederhana ... 24
Gambar 3.1. Diagram hasil output Mass Spectrometer ... 28
Gambar 3.2. Preprocessing ... 29
Gambar 3.3. Proses Modeling. ... 30
Gambar 3.4.Proses Testing menggunakan Algoritma dynamic time warping untuk identifikasi spectra signature senyawa aktif yang baru ... 32
Gambar 4.1. Spektra dengan kemiripan 100% ... 35
Gambar 4.2. Spektra dengan kemiripan 78,725% ... 36
Gambar 4.3. Spektra dengan kemiripan 55% ... 37
Gambar 4.4. Spektra dengan kemiripan 26% ... 38
Gambar 4.5.. Implementasi Halaman Depan ... 39
Gambar 4.6. Implementasi Halaman Pengenalan Spektra ... 40
xv
DAFTAR TABEL
Tabel 2 .1 Hasil perhitungan DTW menggunakan forward DP ... 20
1
BAB I
PENDAHULUAN
1.1 Latar Belakang.
Indonesia kaya akan sumber daya hayati dan merupakan salah satu negara
megabiodiversity terbesar di dunia. Indonesia memiliki sekitar 17% jumlah
spesies yang ada di dunia (Hembing, 2007). Hutan tropis yang sangat luas beserta
keanekaragaman hayati yang ada di dalamnya merupakan sumber daya alam yang
tak ternilai harganya. Indonesia juga dikenal sebagai gudangnya tanaman obat
(herbal) sehingga mendapat julukan live laboratory (Hembing, 2007). Kita boleh
berbangga dengan kekayaan herbal yang tidak dimiliki oleh negara lain. Sekitar
30.000 jenis tanaman obat dimiliki Indonesia (Hembing, 2007). Dengan kekayaan
flora tersebut, tentu Indonesia memiliki potensi untuk mengembangkan produk
herbal yang kualitasnya setara dengan obat modern. Akan tetapi, sumber daya
alam tersebut belum dimanfaatkan secara optimal bagi kepentingan masyarakat.
Baru sekitar 1200 species tanaman obat yang dimanfaatkan dan diteliti sebagai
obat tradisional (Hembing, 2007). Padahal tanaman obat mengandung senyawa
aktif tertentu yang bertanggung jawab terhadap efek farmakologis yang dapat
dimanfaatkan dalam pengobatan tradisional. Senyawa aktif dalam tanaman obat
berperan penting dalam dunia kesehatan.
Obat yang berasal dari bahan alam memiliki efek samping yang lebih
rendah dibandingkan obat-obatan kimia, karena efek obat herbal bersifat alamiah.
ilmiah menunjukan bahwa tanaman-tanaman tersebut mengandung zat-zat atau
senyawa aktif yang terbukti bermanfaat bagi kesehatan (Hembing, 2007).
Tanaman obat memiliki beberapa kelebihan, antara lain : efek sampingnya
relatif rendah, dalam suatu ramuan dengan komponen berbeda memiliki efek
saling mendukung, pada satu tanaman memiliki lebih dari satu efek farmakologi
serta lebih sesuai untuk penyakit-penyakit metabolik dan degeneratif .
Tanaman obat juga memiliki kelebihan dalam memberi efek komplementer
(saling melengkapi) beberapa zat aktif dalam satu tanaman, contohnya seperti
pada herba timi (Tymus serpyllum atau T.vulgaris) sebagai salah satu ramuan obat
batuk. Herba timi diketahui mengandung minyak atsiri (yang antara lain terdiri
dari : tymol dan kalvakrol) serta flavon polimetoksi. Tymol dalam timi berfungsi
sebagai ekspektoran (mencairkan dahak) dan kalvakrol sebagai anti bakteri
penyebab batuk; sedangkan flavon polimetoksi sebagai penekan batuk non
narkotik, sehingga pada tanaman tersebut sekurang-kurangnya ada 3 komponen
aktif yang saling mendukung sebagai antitusif. Demikian pula efek diuretik pada
daun kumis kucing karena adanya senyawa flavonoid, saponin dan kalium (Katno,
2008 ) .
Selama ini penelitian mengenai senyawa aktif dari tanaman obat sampai
dengan identifikasi struktur senyawa aktif dirasa masih kurang (Muhtadi, 2010).
Beberapa faktor yang mempengaruhi kurangnya penelitian mengenai senyawa
aktif yang terkandung dalam tanaman obat adalah keterbatasan alat, lamanya
3
Salah satu cara untuk mengidentifikasi senyawa aktif dari suatu tanaman obat
adalah dengan metode elusidasi struktur (Tim Penyusun Modul Fakultas Farmasi
USD, 2007). Elusidasi struktur dilakukan dengan menginterpretasi spektra yang
dihasilkan dari analisis spektroskopi senyawa tersebut. Elusidasi struktur sendiri
merupakan salah satu dasar dalam studi farmakologi, formulasi, dan kimia
medisinal yang membahas mengenai perbaikan sifat dan aktivitas suatu obat serta
interaksinya dengan senyawa lain dilihat dari struktur kimianya. Hasil yang
didapat dari elusidasi struktur senyawa aktif pada tanaman obat akan menjadi
dasar pemahaman molekuler bagi penelitian lebih lanjut untuk membangun bukti
ilmiah tentang efek farmakologis dan toksisitas tanaman obat (evidence based
herbal medicine). Proses analisis spektra sendiri membutuhkan banyak waktu dan
keahlian tertentu.
Spektrometri digunakan untuk identifikasi senyawa aktif dari tanaman obat
dengan cara melakukan interpretasi spektra sehingga dapat dilakukan elusidasi
struktur. Metode spektrometri yang digunakan untuk elusidasi struktur adalah
Spektrometri Massa, Spektrometri Infra Red, dan Spektrometri Nuclear Magnetic
Resonance (Fessenden,1986). Penelitian ini menggunakan spektra hasil
Spektrometer Massa untuk kemudian dibandingkan dengan database spektra
massa. Spektrometri Massa dipilih karena dapat memberi informasi tentang bobot
molekul suatu senyawa dan fragmen-fragmen dari senyawa tersebut. Dari
informasi tersebut dapat dielusidasi struktur senyawa yang bersangkutan.
Untuk memudahkan proses, menghemat biaya, dan mempersingkat waktu
metode “Dynamic Time Warping”(DTW) untuk identifikasi “spectra signature”
senyawa aktif. DTW telah banyak digunakan salah satu nya untuk mencocokkan
kata (Rath, Toni, dan Manmatha, 2002).
1.2 Rumusan Masalah.
Berdasarkan latar belakang diatas, masalah dapat dirumuskan berikut :
1. Bagaimana pendekatan dengan metode Dynamic Time Warping (DTW)
dapat mengenali “spectra signature” senyawa aktif dalam tanaman
obat secara cepat?
2. Bagaimana cara menguji tingkat keberhasilan identifikasi senyawa aktif
dalam tanaman obat?
1.3 Tujuan Penelitian.
Sistem yang akan dibuat bertujuan untuk mempermudah identifikasi
“spectra signature” senyawa aktif dalam tanaman obat dengan
memperbandingkan data senyawa yang ada di database dan melihat efektifitas
Dynamic Time Warping (DTW) untuk identifikasi otomatis senyawa aktif dalam
tanaman obat.
1.4 Batasan Masalah.
Sistem yang akan dikerjakan, mempunyai beberapa batasan sebagai berikut :
1. Masukan data ke sistem hanya hasil analisis elusidasi struktur dengan
spektrofotometri “Mass Spectrometer” yang sudah digitalkan dan
mempunyai format data dengan extensi *.gif
5
3. Program dibuat dengan bahasa pemrograman Matlab
1.5 Sistematika Penulisan.
Untuk memudahkan dalam penyusunan dan pemahaman isi dari skripsi ini,
maka digunakan sistematika penulisan sebagai berikut :
BAB I : PENDAHULUAN.
Bab ini berisi tentang latar belakang masalah, perumusan masalah, batasan
masalah, tujuan, metode penulisan dan keterangan mengenai sistematika
penulisan.
BAB II : LANDASAN TEORI.
Bab ini berisikan berisikan tentang penjelasan tentang spectra dan spectra
signature, Mass Spectrometer, Knowledge Discovery in Database (KDD) dan
Dynamic Time Warping.
BAB III : METODOLOGI.
Bab ini berisi tentang data spektra massa, preprocessing, proses modeling
dan testing.
BAB IV : IMPLEMENTASI DAN ANALISA HASIL.
Bab ini berisi implementasi antarmuka sistem, analisa hasil pengujian
sistem, kompleksitas waktu algoritma Dynamic Time Warping
BAB V : PENUTUP
Bab ini berisi kesimpulan dan saran-saran yang dapat dipertimbangkan
7
BAB II
LANDASAN TEORI
Pada landasan teori ini akan dijelaskan akan dijelaskan secara singkat hal –
hal yang berkaitan dengan spectra dan spectra signature, Mass Spectrometer,
Knowledge Discovery in Database, Dynamic Time Warping dan penghitungan
nilai kemiripan spectra signature.
2.1. Spectra dan Spectra Signature.
Spektra massa adalah alur kelimpahan atau jumlah relatif fragmen
bermuatan positif yang berlainan (%T) dengan nisbah massa atau muatan (m/e
atau m/z) dari fragmen-fragmen itu. (Fessenden, 1986). Suatu spektra massa
dipaparkan sebagai suatu grafik batangan. Tiap peak menyatakan suatu fragmen
molekul. Fragmen tersebut disusun mulai dari m/e atau m/z kecil ke m/e atau m/z
besar. Itensitas puncak sebanding dengan kelimpahan negatif fragmen-fragmen
yang bergantung pada stabilitas relatif fragmen tersebut. Menurut perjanjian
puncak tertinggi dalam suatu spektrum disebut puncak dasar dan diberi nilai
intensitas 100%. Sedangkan puncak-puncak yang lebih kecil, intensitasnya diukur
relatif terhadap puncak dasar. (Tim Penyusun Modul Fakultas Farmasi USD,
2007). Spectra Signature adalah identitas dari suatu spektra dalam suatu senyawa.
Spectra signature dapat diperoleh dengan hasil analisis elusidasi struktur dengan
spektrofotometri Mass Spectrometer(MS), Nuclear Magnetic Resonation(NMR),
Infrared Resonation(IR) (Fessenden, 1986). Di bawah ini contoh grafik spektra
massa :
Gambar 2.1. contoh grafik spektra massa (http://webbook.nist.gov/chemistry)
2.2. Mass Spectrometer
Spektrometer massa adalah suatu alat yang dapat menyeleksi
molekul-molekul gas bermuatan berdasarkan massa atau beratnya. Umumnya spektrum
massa diperoleh dengan mengubah senyawa suatu sampel menjadi ion-ion yang
bergerak cepat yang dipisahkan berdasarkan perbandingan massa terhadap muatan
(Khopkar, 1990). Proses ionisasi menghasilkan partikel-partikel bermuatan
positif, dimana massa terdistribusi adalah spesifik terhadap senyawa induk. Selain
untuk penentuan stuktur molekul, spektum massa dipakai untuk penentuan
analisis kuantitatif (Sastrohamidjojo, 2001).
Prinsip Spektroskopi Massa
Prinsip Spektroskopi Massa yaitu dengan menggunakan alat spektrometer;
suatu zat uji menghasilkan berkas ion, memilah ion tersebut menjadi spektrum
yang sesuai dengan perbandingan massa terhadap muatan dan merekam
9
dipelajari karena ion negatif yang dihasilkan dari sumber tumbukan umumnya
sedikit (Khopkar, 1990).
Analisis Kualitatif
Analisis kuantitatif adalah pekerjaan yang bertujuan untuk mengetahui
kadar suatu senyawa dalam sampel. Spektroskopi massa memungkinkan kita
mengidentifikasi suatu senyawa yang tidak diketahui, dengan mengkalibrasi
terhadap senyawa yang telah diketahui seperti uap merkuri atau perfloro kerosin
(Khopkar, 1990).
Analisis Kuantitatif
Analisis kualitatif adalah pekerjaan yang bertujuan untuk mengetahui
senyawa-senyawa yang terkandung dalam sampel uji. Spektroskopi massa dapat
digunakan untuk analisis kuantitatif suatu campuran senyawa-senyawa yang dekat
hubungannya. Analisis ini dapat digunakan untuk analisis campuran, baik
senyawa organik ataupun anorganik yang bertekanan uap rendah. Karena pola
fragmentasi senyawa campuran adalah aditif sifatnya, suatu senyawa campuran
dapat dianalisis jika berada dalam kondisi yang sama. Persyaratan dasar
analisisnya adalah setiap senyawa harus mempunyai paling tidak satu puncak
yang spesifik, kontribusi puncak harus aditif dan sensitif, harus reproducible serta
adanya senyawa referensi yang sesuai. Dengan spektrometer massa beresolusi
tinggi, senyawa polimer dengan berat molekul tinggi juga dapat
dianalisis(Khopkar, 1990).
Kegunaan Spektroskopi Massa:
i. Spektroskopi massa dapat digunakan untuk menentukan berat molekul dengan
sangat teliti sampai empat angka dibelakang desimal.
ii. Spektroskopi massa dapat digunakan untuk mengetahui rumus molekul tanpa
melalui analisis unsur
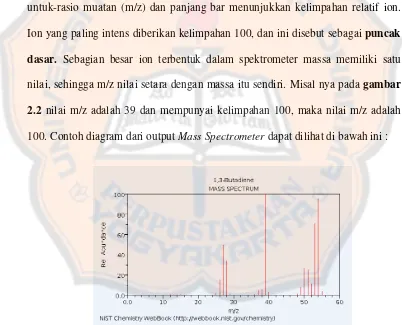
Sebuah spektrum massa biasanya akan ditampilkan sebagai grafik batang
vertikal, di mana setiap baris mewakili sebuah ion mempunyai massa
tertentu-untuk-rasio muatan (m/z) dan panjang bar menunjukkan kelimpahan relatif ion.
Ion yang paling intens diberikan kelimpahan 100, dan ini disebut sebagai puncak dasar. Sebagian besar ion terbentuk dalam spektrometer massa memiliki satu nilai, sehingga m/z nilai setara dengan massa itu sendiri. Misal nya pada gambar 2.2 nilai m/z adalah 39 dan mempunyai kelimpahan 100, maka nilai m/z adalah 100. Contoh diagram dari output Mass Spectrometer dapat dilihat di bawah ini :
11
2.3. Knowledge Discovery in Database (KDD)
Knowledge Discovery in Database adalah proses penting identifikasi yang
valid, baru, berguna dan pola yang sangat dimengerti dalam data (Sankar dan
Mitra, 2004).
Gambar 2.3 Proses KDD (Sankar dan Mitra, 2004)
Proses KDD dapat dijelaskan pada tahapan di bawah ini :
1. Data cleaning and preprocessing
Data cleaning and preprocessing meliputi proses dasar seperti pembersihan
noise dan penanganan data hilang.
2. Data condensation and projection
Data condensation and projection meliputi proses menemukan ciri-ciri dan
contoh yang berguna untuk menggambarkan data tersebut dan menggunakan
metode pengurangan dimensi atau transformasi.
3. Data integration and wrapping
Data integration and wrapping meliputi proses penggabungan beberapa,
beraneka ragam sumber data dan memberikan penjelasan tentang data
tersebut (pembukusan) untuk kemudahan penggunaan di masa depan.
4. Choosing the data mining function(s) and algorithm(s)
Choosing the data mining function(s) and algorithm(s) meliputi proses
memutuskan tujuan (misal klasifikasi, kemunduran, meringkaskan,
pengelompokkan, menemukan aturan gabungan dan fungsi ketergantungan,
atau gabungan dari tujuan yang sudah disebutkan diatas) dari model yang
akan ditemukan oleh algoritma penambangan data dan metode seleksi
(Misal neural networks, decision trees, statistical models, fuzzy model) yang
akan digunakan untuk mencari pola dari data.
5. Data mining
Data mining meliputi pencarian pola yang menarik dalam bentuk gambaran
tertentu atau sejumlah gambaran.
6. Interpretation and visualization
Interpretation and visualization meliputi proses menerjemahkan pola yang
telah ditemukan, serta gambaran yang mungkin dari pola yang sudah di
ekstrak.
7. Using discovered knowledge
Using discovered knowledge meliputi proses menggabungkan pengetahuan
yang ada kedalam performa sistem, sistem akan bekerja berdasarkan
13
Di dalam tugas akhir menggunakan pendekatan pengelompokkan.
Pengelompokkan digunakan ketika tidak diketahuinya bagaimana data harus
dikelompokkan. Jumlah kelompok diasumsikan sendiri tanpa ditentukan terlebih
dahulu. Keluaran pendekatan ini adalah data yang sudah dikelompokkan (Karl,
2007). Pengelompokkan dilakukan dengan menggunakan algoritma Dynamic
Time Warping.
2.4. Dynamic Time Warping
Dynamic time warping (DTW) merupakan metode yang dipergunakan untuk
menghitung jarak atau kemiripan dua sequence yang memiliki panjang berbeda
dalam waktu atau kecepatan. Dynamic Time Warping memperbolehkan komputer
untuk menemukan pencocokan yang optimal antara 2 buah sequence (deret
waktu) dengan berbagai pembatasan. Biaya total kemiripan dapat ditemukan oleh
algoritma ini yang menunjukkan indikasi bagus dari contoh data masukan dan
standar yang cocok, sehingga dynamic time warping dapat dipilih menjadi
pencocokan template yang baik.
Algoritma Dynamic Time Warping telah banyak digunakan dalam berbagai
hal yaitu pengenalan suara (Sakoe.dan Chiba, 1978), mengklasifikasikan 15 siulan
dolpin menjadi 5 kelompok (Buck dan Tyack, 1993). pencocokkan tulisan dan
tanda tangan online (Tappert, Suen, dan Wakahara, 1990), mencocokkan kata
(Rath, Toni, dan Manmatha, 2002). pengenalan bahasa isyarat (Kuzmanic dan
Zanchi, 2007), pengenalan gerak (Corradini, 2001), penambangan data dan
pengelompokkan time series (Niennattrakul dan Ratanamahatana, 2007),
Huang, dan Tan, 2006), sequence alignment protein dan teknik kimia (Vial, et. al.,
2008), pengenalan musik dan sinyal (Muller, Mattes, dan Kurth, 2006),
Di bawah ini akan dijelaskan bagaimana algoritma Dynamic Time Warping
bekerja (Jang, 2005) :
Jarak antara dua titik x = [x 1, x 2, ..., x n] dan y = [y 1, y 2, ..., y n] yang memiliki n-dimensi dapat dihitung melalui Euclidean distance :
dist( x , y ) = | x - y | = [ (x 1 - y 1 ) 2 + (x 2 - y 2 ) 2 + ... + (x n - yn) 2] 1 / 2 (2-1)
Namun, jika panjang x berbeda dari y, maka kita tidak dapat menggunakan rumus di atas untuk menghitung jarak. Sebaliknya, untuk menghitung jarak perlu
metode yang lebih fleksibel yang dapat menemukan pemetaan terbaik dari
elemen-elemen pada x ke y.
Tujuan dari dynamic time warping adalah untuk mencari pemetaan yang
terbaik dengan jarak minimum dengan menggunakan dynamic programming
(DP). Metode ini disebut "time warping" karena baik x dan y adalah vektor dari deret waktu dan perlu penciutan atau peregangan waktu untuk mencari pemetaan
terbaik (Jang, 2005).
Misalkan t dan r adalah 2 vektor dengan panjang m dan n. Tujuan DTW adalah untuk menemukan pemetaan {(p1, q1), (p2, q2), ..., (pk, qk)} sedemikian
sehingga jarak pada pemetaan Si = 1 k | t (p i) - r (q i) | minimal, DTW memiliki
15
1) Kondisi batas: (p1, q1) = (1, 1), (pk, qk) = (m, n).
2) Batasan lokal : Untuk setiap node (i, j), kemungkinan terhubungnya node
dibatasi oleh (i-1, j), (i, j-1), (i-1, j-1) . Batasan lokal ini menjamin bahwa
jalan pemetaan tidak berkurang secara tetap dalam argumen pertama dan
kedua. Selain itu, untuk setiap elemen dalam t, harus mampu ditemukan setidaknya satu unsur terkait di r, dan sebaliknya
Gambar 2.4 Node dalam batasan lokal (Jang, 2005)
Bagaimana dapat menemukan jalan pemetaan optimal di DTW? Pilihan
yang jelas adalah menggunakan forward DP, yang dapat diringkas dalam tiga
langkah berikut:
1) Fungsi nilai optimal : Tentukan D (i, j) sebagai jarak DTW antara t (1: i)
dan r (1: j), dengan jalan pemetaan dari (1, 1) ke (i, j).
2) Rekursi: D (i, j) = | t (i) - r (j) | + min (D (i-1, j), D (i-1, j-1), D (i, j-1 )),
dengan kondisi awal D (1, 1) = | t (1) - r (1) |.
3) Nilai akhir : D (m, n)
Dalam prakteknya, perlu dibangun sebuah matriks D dengan dimensi m × n
pertama dan isi nilai dari D (1, 1) dengan menggunakan kondisi awal. Kemudian
dengan menggunakan rumus rekursif, isi seluruh matriks satu elemen pada suatu
waktu, dengan mengikuti kolom demi kolom atau baris demi baris. Jawaban akhir
akan tersedia sebagai D (m, n), dengan kompleksitas komputasi O (mn).
Selain dapat digunakan dalam forward DP dapat juga digunakan untuk backward
DP, dapat diringkas dalam tiga langkah berikut :
1) Fungsi nilai optimal : Tentukan D (i, j) sebagai DTW jarak antara t (i: m)
dan r (j: n), dengan jalan pemetaan dari (i, j) untuk (m, n).
2) Rekursi : D (i, j) = | t (i) - r (j) | + min (D (i +1, j), D (i +1, j +1), D (i, j + 1
)), dengan kondisi awal D (m, n) = | t (m) - r (n) |
3) Nilai akhir : D (1, 1)
Dibawah ini akan dijelaskan contoh perhitungan DTW dengan menggunakan
forward DP yang sudah dimodifikasi oleh penelitian-penelitian sebelumnya:
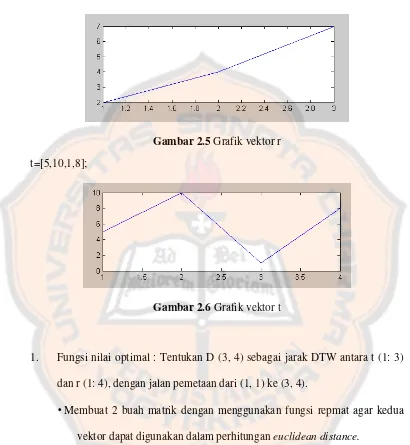
Misalkan terdapat 2 buah vektor yaitu dengan vektor r dan vektor t, maka nilai
17
r=[2,4,7];
Gambar 2.5 Grafik vektor r t=[5,10,1,8];
Gambar 2.6 Grafik vektor t
1. Fungsi nilai optimal : Tentukan D (3, 4) sebagai jarak DTW antara t (1: 3)
dan r (1: 4), dengan jalan pemetaan dari (1, 1) ke (3, 4).
•Membuat 2 buah matrik dengan menggunakan fungsi repmat agar kedua
vektor dapat digunakan dalam perhitungan euclidean distance.
tes1=repmat(r',1,N)
tes1 =
2 2 2 2
4 4 4 4
7 7 7 7
tes2 = repmat(t,M,1)
tes2=
5 10 1 8
5 10 1 8
5 10 1 8
•Menghitung euclidean distance dengan menggunakan dua buah matrik
yang sudah dibuat diatas
•Membuat matrik kosong untuk menampung nilai dari forward DP
D=zeros(size(d));
•Inisialisasi awal yaitu membuat jalan pemetaan D(1, 1)
D(1,1)=d(1,1);
•Proses looping untuk mengisi nilai dari D(2,1) sampai D(3,1)
19
D(m,1)=d(m,1)+D(m-1,1);
end
D(2,1)=d(2,1)+D(1,1)=1+9=10
D(3,1)=d(3,1)+D(2,1)=4+10=14
•Proses looping untuk mengisi nilai dari D(1,2) sampai D(1,4)
for n=2:N
• Proses rekursi untuk mengisi nilai dari D(2,2) sampai D(3,4)
D(3,2)= d(3,2)+min(D(2,2),min(D(2,1),D(3,1)))=9+min(45,10,14)=19
D(3,3)= d(3,3)+min(D(2,3),min(D(2,2),D(3,2)))=36+min(54,45,19)=55
D(3,4)= d(3,4)+min(D(2,4),min(D(2,3),D(3,3)))=1+min(70,54,55)=55
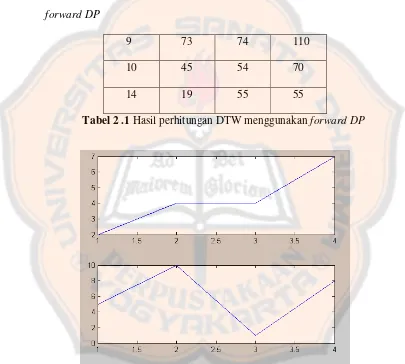
Dibawah ini adalah tabel hasil perhitungan DTW dengan menggunakan
forward DP
9 73 74 110
10 45 54 70
14 19 55 55
Tabel 2.1 Hasil perhitungan DTW menggunakan forward DP
Gambar 2.7 vektor r dan t setelah menggunakan forward DP
21
Dengan menggunakan forward DP diperoleh nilai akhir yang optimum untuk
vektor t dan r yaitu 55. Berdasarkan penelitian yang telah ada sebelum nya
Dynamic Time Warping mempunyai kelebihan dan kekurangan yaitu :
a. Kelebihan DTW
DTW memiliki kelebihan yaitu pada perhitungan jarak antara input stream
dan template sehingga dipilih menjadi metode yang dipakai dalam tugas
akhir. Lebih dari membandingkan nilai input pada saat arus t untuk template
stream pada waktu t, sebuah algoritma pencarian digunakan bahwa ruang
pemetaan dari urutan waktu input stream untuk yang dari template stream,
sehingga total jarak diminimalkan. Jarak pada pemetaan yang tidak selalu
linier misalnya, ditemukan bahwa waktu t1 di input stream sesuai dengan
waktu t1+5 dalam template stream, sedangkan t2 dalam input stream sesuai
dengan t2-3 dalam template stream. Ruang pencarian dibatasi dengan
batas-batas yang wajar, seperti fungsi pemetaan dari input waktu ke waktu
template harus tetap dan tidak berkurang atau dengan kata lain, urutan
peristiwa antara masukan dan template yang tidak berkurang.
Gambar 2.8Dynamic Time Warping
(http://www.cse.unsw.edu.au/~waleed/phd/html/node38.html)
Gambar 2.8menunjukkan bahwa sumbu horizontal mewakili waktu input stream, dan sumbu vertikal menunjukkan urutan waktu dari template stream.
Jalan menunjukkan bahwa hasil dalam jarak minimal antara input dan
template stream. Di daerah yang diarsir merupakan ruang pencarian untuk
input waktu ke fungsi pemetaan template waktu .
Setiap jalan yang tetap dan tidak berkurang di dalam ruang adalah sebuah
alternatif untuk dipertimbangkan. Menggunakan teknik dynamic
programming, pencarian jarak minimum jalan dapat dilakukan dalam waktu
polinomial : O (N2V) di mana N adalah panjang urutan, dan V adalah
jumlah template yang harus dipertimbangkan (Kadous, 2002)
b. Kekurangan DTW
DTW mempunyai masalah ketika 2 sequence berbeda di sumbu Y.
23
seperti perbedaan rata-rata, perbedaan skala (skala amplitudo) atau
cenderung linear dapat secara efisien dihilangkan (Keogh and Pazzani 1998,
Agrawal et. al. 1995). Bagaimanapun juga 2 sequence dapat mempunyai
perbedaan local pada sumbu Y, misal nya lembah pada sequence pertama
lebih dalam daripada lembah sequence kedua. Pada gambar 2.9 terdapat 2 sequence mirip yang akan menghasilkan garis lurus satu ke satu. Jika
identitas lokal dalam hal ini lembah dirubah sedikit maka DTW akan
menerjemahkan perbedaan dalam time axis dan dan menghasilkan 2 garis
berbeda.
Gambar 2.9 Kelemahan DTW (Keogh dan Pazzani, 1998)
2.5. Rumus menghitung nilai kemiripan spektra dan contoh penerapan nya Dalam proses identifikasi spectra signature akan digunakan rumus untuk
Gambar 2.10 kemiripan dan perbedaan untuk atribut yang sederhana (Ning Tan, Steinbach, dan Kumar, 2006)
Pada gambar 2.10 untuk mencari nilai kemiripan atau s dapat menggunakan 3
jenis tipe atribut yaitu :
1. Nominal
Pada tipe atribut nominal nilai kemiripan atau s mempunyai kemiripan 1 atau mirip
jika p sama dengan q dan mempunyai kemiripan 0 atau tidak mirip jika p tidak
sama dengan q.
2. Ordinal
Tipe atribut ordinal nilai kemiripan atau s dapat dicari dengan menggunakan
rumus di bawah ini :
Dari rumus diatas nilai kemiripan atau s dapat dicari dengan memasukkan
nilai dari variabel-variabel yang dibutuhkan seperti p, q dan n dimana p dan
q adalah nilai atribut dari dua buah obyek data, dan n adalah bilangan
25
3. Interval atau rasio
Tipe atribut interval atau rasio dapat dicari dengan menggunakan rumus di
bawah ini :
Nilai kemiripan atau s dapat dicari dengan memilih salah satu dari rumus
diatas sesuai dengan kebutuhan dan memasukkan variabel-variabel yang
dibutuhkan seperti d, min_d, dan max_d. Variabel d adalah nilai perbedaan
atau ketidakmiripan, variabel min_d adalah nilai minimum perbedaan dan
variabel max_d adalah nilai maksimum perbedaan.
Penelitian ini menggunakan rumus dengan tipe atribut interval atau rasio.
Tipe atribut interval atau rasio dipilih karena paling cocok dan mewakili untuk
dipakai di dalam program. Di bawah ini adalah contoh pemakaian rumus di dalam
program :
Dimana s adalah nilai kemiripan yang ingin dicari, d adalah nilai masukan
user yang telah diolah oleh program dan menghasilkan nilai yang mendekati
dengan database yang ada, min_d adalah nilai minimum dari algoritma Dynamic
Time Warping, dan max_d adalah nilai maksimum yang dihasilkan program dari
uji coba 200 data dengan menggunakan algoritma Dynamic Time Warping. Dari
rumus diatas dapat diterapkan dalam data seperti contoh dibawah ini :
Misalkan nilai d adalah 3534, min_d adalah 0 dan max_d adalah 17673
maka akan menghasilkan nilai kemiripan sebagai berikut
Dari hasil diatas di dapatkan nilai kemiripan spectra signature sejumlah
0,801. Hasil tersebut akan dikalikan 100% sehingga menjadi 80,1%.
2.6. Kompleksitas Waktu.
Dalam praktek nya, kompleksitas waktu dihitung berdasarkan jumlah
operasi abstrak yang mendasari suatu algoritma, dan memisahkan analisisnya dari
implementasi (Suryadi, 1995). Kompleksitas waktu asimptotik biasanya diberi
dengan Notasi “O” disebut notasi “O-Besar” atau (Big-O). Dalam penelitian ini
analisa kompleksitas waktu hanya untuk algoritma Dynamic Time Warping,
karena Algoritma Dynamic Time Warping merupakan alogritma utama dalam
27
Keterangan :
1) Untuk n yang besar, pertumbuhan T(n) sebanding dengan n2. Pada
kasus ini, T(n) tumbuh seperti n2 tumbuh.
2) T(n) tumbuh seperti n2 tumbuh saat n bertambah. Kita katakan bahwa T(n) berorde n2 dan kita tuliskan T(n) = O(n2).
28
BAB III
METODOLOGI
Pada metodologi ini akan dibahas hal-hal mengenai data Mass
Spectrometer, preprocessing, proses modeling dan proses testing.
3.1. Data Mass Spectrometer.
Spektra dari Mass Spectrometer merupakan spektra yang menunjukkan
berat molekul dari suatu senyawa. Dari Mass Spectrometer diperoleh senyawa
berupa molekulnya dan fragmen-fragmen ion yang terjadi. Data yang mungkin
muncul berupa nilai berat molekul dari senyawa yang dimaksud,
fragmen-fragmen yang terbentuk dari Mass Spectrometer itu sendiri. Berdasarkan gambar 3.1 sumbu x menunjukkan berat molekul, sumbu y menunjukkan nilai dari kelimpahan, peak yang berada di awal sampai dengan satu peak sebelum terakhir
menunjukkan fragmen ion dari molekul, peak yang berada di akhir menunjukkan
berat molekul dari molekul.
29
Spektra dari Mass Spectrometer biasa digunakan untuk :
1. Menentukan struktur molekul
2. Menentukan isotop-isotop stabil dalam penelitian reaksi-reaksi biologi
3. Menentukan analisis kualitatif dan kuantitatif terhadap komponen yang
telah diisolasi dan dimurnikan
Penelitian ini menggunakan 200 spektra dari hasil elusidasi struktur Mass
Spectrometer. Data spektra senyawa aktif dari tanaman obat diperoleh dengan
mengunduh gambar spektra yang berekstensi .gif dari database yang disediakan
oleh http://webbook.nist.gov/chemistry.
3.2. Preprocessing.
Preprocessing dilakukan untuk membersihkan noise dengan proses seperti
berikut :
Gambar 3.2 Preprocessing
Data yang diunduh dari http://webbook.nist.gov/chemistry berupa gambar
spektra yang berekstensi *.gif. Data tersebut di preprocessing untuk
menghilangkan noise atau bagian-bagian yang tidak diperlukan. Pada saat
preprocessing dilakukan pemotongan pada bagian kiri, kanan, atas dan bawah
gambar spektra serta dilakukan skala ulang pada gambar spektra agar skala
gambar spektra setelah preprocessing sama dengan skala sebelum preprocessing.
Dari hasil preprocessing menghasilkan data digital atau dalam bentuk matrik.
3.3. Proses Modeling dan Testing.
Proses modeling dibutuhkan untuk mempermudah dan mempercepat proses
identifikasi dari spectra signature. Proses modeling dilakukan dengan cara seperti
di lihat di gambar 3.3 di bawah ini :
31
Misalkan S adalah Spektra, NJ adalah Nilai Jarak dan M adalah Model maka
S1,S2,S3,…,S200 adalah spektra-spektra standar yang ada di dalam database,
NJ1,NJ2,NJ3,…,NJ200 adalah nilai jarak dari hasil perbandingan antar spektra
standar yang ada di dalam database dan M1,M2,M3,…,M10 adalah model dari
kelompok spektra-spektra standar pada database. Proses modeling merupakan
proses modifikasi dari K-Means Clustering menjadi K-Median Clustering. Proses
modeling dapat dijelaskan dengan langkah-langkah seperti dibawah ini :
1. Membandingkan 1 data dengan semua data untuk menghitung jarak
atau kedekatan atau kemiripan. Dari proses perhitungan didapatkan
output berupa nilai jarak atau kemiripan (DTW).
2. Mengurutkan jarak atau nilai kemiripan dari nilai terkecil sampai nilai
terbesar.
3. Membagi data jarak atau nilai kemiripan menjadi 10 kelompok.
4. Memilih wakil atau model untuk tiap kelompok. Dari proses
pemilihan wakil atau model didapatkan output berupa 10 spektra.
5. Proses iterasi
a. Menghitung kemiripan (DTW) seluruh data terhadap 10 model.
Dari proses perhitungan menghasilkan output berupa nilai
kemiripan atau jarak.
b. Mengelompokkan data dengan cara mengambil nilai yang paling
dekat dengan model kemudian data dikelompokkan dalam model
c. Mencari median dari tiap model. Dari proses pencarian median di
dapatkan spektra (wakil baru).
d. Lakukan proses a hingga keanggotaan tiap kelompok tidak berubah
atau tetap.
e. Memilih model untuk masing-masing kelompok.
Proses testing dibutuhkan untuk mengidentifikasi data yang baru. Dalam
mengenali suatu senyawa aktif baru, sistem akan menghitung kemiripan senyawa
aktif yang baru dalam hal ini adalah menghitung jarak dengan model-model yang
telah ada. Hasil perhitungan jarak yang paling dekat adalah yang dipilih untuk
menuju proses selanjutnya. Senyawa aktif baru yang telah diketahui kemiripannya
dengan suatu model, kemudian dibandingkan kembali dengan data-data senyawa
standar yang telah ada.
Proses perbandingan dilakukan dengan menghitung kemiripan (menghitung
jarak) dan menghitung indeks kemiripannya dengan senyawa-senyawa standar
yang telah ada.
33
Misalkan M adalah Model, S adalah Spektra dan Sm adalah spektra masukan yang
ingin dicari maka M1,M2,M3,…,M10 adalah model dari kelompok
spektra-spektra standar pada database dan S1,S2,S3,…,S20 adalah spektra-spektra-spektra-spektra
standar yang ada di dalam database. Berdasarkan gambar 3.3 maka dapat dijelaskan dalam langkah seperti di bawah ini:
1. Bandingkan senyawa aktif yang baru dengan 10 model yang ada dan hitung
jarak yang paling dekat
2. Mencari kemiripan senyawa yang di identifikasi dengan senyawa-senyawa
yang ada di dalam model dengan menghitung jarak yang paling dekat dan
indeks kemiripannya.
34
BAB IV
IMPLEMENTASI DAN ANALISA HASIL
Pada bab ini akan dibahas hal-hal mengenai analisis hasil identifikasi dan
hasil tampilan antar muka sistem beserta penjelasan penggunaan tombol dan
keterangan untuk setiap bagian sistem yang penting.
4.1. Hasil dan Analisis.
Dalam proses identifikasi spectra signature senyawa aktif, dilakukan uji
coba dengan menggunakan 200 data di dalam database. Dalam proses pengujian
data menghasilkan 97 data yang mempunyai nilai kemiripan 100%, 78 data yang
mempunyai nilai kemiripan antara 80-99% dan 25 data lain nya menghasilkan
nilai kemiripan di bawah 80%. Dari perhitungan tersebut maka akurasi program
secara keseluruhan dapat di hitung menjadi : Akurasi = (175/200) * 100% =
87,5%.
35
1. Spektra dengan kemiripan 100%
Berdasarkan hasil pengujian didapatkan bahwa spektra Brucine mempunyai
tingkat kemiripan 100%
Gambar 4.1. Spektra dengan kemiripan 100%
2. Spektra dengan kemiripan 70%
Berdasarkan hasil pengujian didapatkan bahwa spektra Arginine mempunyai
tingkat kemiripan 78,725%
37
3. Spektra dengan kemiripan 50%
Berdasarkan hasil pengujian didapatkan bahwa spektra Amylester kyseliny
dusicne mempunyai tingkat kemiripan sebesar 55%
Gambar 4.3. Spektra dengan kemiripan 55%
4. Spektra dengan kemiripan 20%
Berdasarkan hasil pengujian didapatkan bahwa spektra Chlordane
mempunyai tingkat kemiripan sebesar 26%
39
4.2. Implementasi Antar-Muka yang Digunakan Dalam Sistem 1. Halaman Depan.
Halaman ini merupakan halaman pertama saat program dijalankan. Pada
halaman ini mempunyai 2 menu utama yaitu menu pengenalan spektra dan menu
bantuan. Implementasi halaman depan dapat dilihat pada gambar 4.5 berikut ini.
Gambar 4.5Implementasi Halaman Depan
2. Halaman Pengenalan Spektra
Halaman ini merupakan halaman untuk mengubah masukan pengguna
berupa gambar yang berekstensi *.gif menjadi gambar yang paling mirip. Dalam
halaman ini terdapat sebuah axes area yang akan menampilkan masukan user
hasil dari load file dari tombol ambil data, sebuah axes area untuk menampilkan
hasil dari proses program, sebuah input area berupa text area yang akan
digunakan untuk mengambil nilai dari masukan pengguna, dua buah output area
berupa text area yang akan digunakan untuk menampilkan hasil dari proses
tombol proses yang berfungsi untuk mengolah data yang telah dimasukkan oleh
pengguna, satu tombol bersihkan yang berfungsi untuk membersihkan data yang
sudah diproses sebelumnya, satu tombol kembali befungsi untuk kembali ke
halaman awal, satu tombol tutup untuk menutup program. Implementasi halaman
depan dapat dilihat pada gambar 4.6 berikut ini
Gambar 4.6 Implementasi Halaman Pengenalan Spektra
3. Halaman bantuan
Halaman bantuan digunakan untuk membantu pengguna agar dapat
mempergunakan sistem dengan lancar. Halaman ini menjelaskan tombol-tombol
yang digunakan dalam program. Implementasi Halaman Bantuan dapat dilihat
41
Gambar 4.7. Halaman Bantuan
4.3. Kompleksitas Waktu Asimptotik.
Dengan mengacu pada teorema dan aturan penghitungan kompleksitas
waktu asimptotik yang tertera pada Bab II, maka kompleksitas waktu asimptotik
algoritma Dynamic Time Warping adalah sebagai berikut :
[row,M]=size(r); O(1)
if (row > M) O(1)
M=row; O(1) O(1)
r=r'; O(1)
end;
[row,N]=size(t); O(1)
if (row > N) O(1)
N=row; O(1) O(1)
t=t'; O(1)
end;
43
Waktu kompleksitas dari algoritma Dynamic Time Warping adalah :
= O(mn)
45
BAB V
PENUTUP
5.1. Kesimpulan
a) Pada identifikasi “spectra signature” senyawa aktif dalam tanaman
obat mempergunakan metode Dynamic Time Warping, dengan jumlah
total sampel data 200 spektra. Proses modeling awal dilakukan dengan
membagi 200 data ke dalam 10 model. Setelah semua data masuk
kedalam model yang telah ada maka dilakukan proses iterasi yang
konvergen atau data tidak berubah.
b) Proses testing dilakukan dengan uji coba dengan 200 data dari dalam
database.
c) Dengan menggunakan algoritma DTW dapat diperoleh akurasi
program sebesar 87,5% dan kompleksitas waktu O(mn). Berdasarkan
hasil pengujian maka dapat disimpulkan bahwa Dynamic Time
Warping merupakan metode pengenalan pola yang baik untuk spectra
signature. Hal ini didukung dengan hasil-hasil pengujian yang telah
dilakukan.
5.2. Saran
Perlu penelitian lebih lanjut untuk memperbaiki sistem sehingga:
a) Sistem dapat mengenali masukan dari hasil elusidasi struktur dengan
Spektrofotometri “Nuclear Magnetic Resonance” dan “Infrared
Resonation”
47
DAFTAR PUSTAKA
Aberer,Karl.,http://lsirwww.epfl.ch/courses/dis/2007ws/lecture/week%2014%20D
atamining-Clustering-Classification-Wrap-up.pdf, 2007, diakses tanggal
10 Mei 2012.
Agrawal, R., Lin, K. I., Sawhney, H. S., & Shim, K., Fast similarity search in the
presence of noise, scaling, and translation in times-series databases.
1995. In VLDB, September.
Anonim, http://webbook.nist.gov/chemistry,diakses tanggal 17 Mei 2012
Corradini,A., Dynamic time warping for offline reconition of a small gesture
vocabulary, 2001, in RATFG-RTS '01: Proceedings of the IEEE ICCV
Workshop on Recognition, Analysis, and Tracking of Faces and Gestures
in Real-Time Systems (RATFG-RTS'01). Washington, DC, USA.
Ellis, Dynamic Time Warp (DTW) in Matlab,
http://www.ee.columbia.edu/~dpwe/resources/matlab/dtw, 2003, di
akses tanggal 14 September 2009.
Feng,Hao and Wah, Chan Choong, http://www.sciencedirect.com/science, 2002,
diakses tanggal 14 September 2009.
Fessenden,Ralp J., Fesseden, Joan S., Organic Chemistry, 1986, University of
Montana.
Jang, R., http://neural.cs.nthu.edu.tw/jang/books/audioSignalProcessing 2009,
diakses tanggal 14 September 2009.
J.Keogh, Eamon., J.Pazzani, Michael, Derivative Dynamic Time Warping, 1998.
K.Pal,Sankar., Mitra,Pabitra., Pattern Recognition Algorithms for Data Mining
:Scalability, Knowledge Discovery and Soft Granular Computing, 2004,
Chapman & HAll/CRC Press, Boca Raton,Florida.
Kadous, Mohammed Waleed,
http://www.cse.unsw.edu.au/%7Ewaleed/phd/html/node38.html, 2002,
di akses tanggal 14 September 2009.
Katno,S.Pramono,ObatTradisional,http://cintaialam.tripod.com/keamanan_obat%
20tradisional.pdf, 2008, diakses tanggal 13 September 2009.
Khopkar, S.M., Konsep Dasar Kimia Analitik, 1990, 275-286,389-400, UI Press,
Jakarta.
Kuzmanic,A and Zanchi,V., Hand shape classification using dtw and lcss as
similarity measures for vision-based gesture recognition system, in
EUROCON, 2007. The International Conference on "Computer as a
Tool", 2007, pp. 264-269.
Muhtadi, Menggali Potensi Tanaman Obat,
49
Muller,M., Mattes,H., dan Kurth,F., An efficient multiscale approach to audio
synchronization,2006, pp. 192-197.
Muller, M.,DTW-based motion comparison and retrival, 2007, pp.211-226.
Niennattrakul, V and Ratanamahatana, C. A., On clustering multimedia time
series data using k-means and dynamic time warping, in Multimedia and
Ubiquitous Engineering, 2007. MUE '07.International Conference on,
2007, pp. 733-738.
Ning Tan, P., Steinbach, M., Kumar, V., ,2006, Introduction to Data Mining,
Pearson Addison Wesley, Boston.
Sakoe, H dan Chiba, S., "Dynamic Programming algorithm optimization for
spoken word recognition," Accoustic, Speech and signal
Processing,1978.
Sastrohamidjojo, H., Spektroskopi, 2001,415, Liberty, Yogyakarta.
Silverstein, R.M., Penyelidikan Spektrometrik Senyawa Organik, 1991, Edisi 4,
diterjemahkan oleh Hartomo, 249-278, Erlangga, Jakarta.
Suryadi., Pengantar Analisis Algoritma,1995, Gunadharma, Jakarta.
R.Buck,John.,L.Tyack,Peter, A quantitative measure of similarity for tursiops
truncatus signature whistles, 1993, J.Acoust. Soc. Am.,Vol.94, No.5.
Rath, Toni M., Manmatha R., Word Image Matching Using Dynamic Time
Warping, 2002, University of Massachusetts.
Tappert, C.C., Suen, C.Y., Wakahara,T., The state of the art in online handwriting
recognition,"Pattern Analysis and Machine Intelligence,1990.
Tim Penyusun Modul Universitas Sanata Dharma, Spektroskopi, 2007,
Yogyakarta.
Vial,J., Nocairi,H., Sassiat,P.,Mallipatu,S., Cognon,G., Thiebaut,D., Teillet,B.,
dan Rutledge,D., Combination of dynamic time warping and
multivariate analysis for the comparison of comprehensive
two-dimensional gas chromatogramsapplication to plant extracts, Journal of
Chromatography A, September 2008.
Wijayakusuma, H., Kekayaan dan Pengembangan Tanaman Obat Indonesia, 2007.
Zhang, Z.,Huang, K dan Tan, T.,Comparison of similarity measures for trajectory
clustering in outdoor surveillance scenes, 2006,in ICPR '06:
Proceedings of the 18th International Conference on Pattern
Recognition (ICPR'06). Washington, DC, USA: IEEE Computer