Analisis Metode FCM untuk Pengelompokan Data Masyarakat Miskin 1. Data Masukan
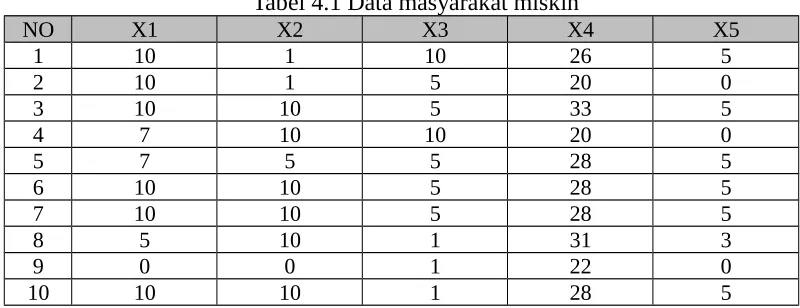
Data yang akan dikelompokkan adalah data masyarakat yang telah dimiliki sebelumnya, misalkan data yang telah ada seperti terlihat pada Tabel 4.1 berikut ini :
Tabel 4.1 Data masyarakat miskin
NO X1 X2 X3 X4 X5
1 10 1 10 26 5
2 10 1 5 20 0
3 10 10 5 33 5
4 7 10 10 20 0
5 7 5 5 28 5
6 10 10 5 28 5
7 10 10 5 28 5
8 5 10 1 31 3
9 0 0 1 22 0
10 10 10 1 28 5
Jumlah data yang akan dijadikan sebagai contoh sebanyak 10 data kasus, sedangkan masing-masing kolom dijelaskan sebagai :
X1 : Pekerjaan X2 : Rumah tinggal
X3 : Kepemilikan investasi X4 : Jumlah tanggungan X5 : Penghasilan sebulan
Sedangkan untuk parameter inputan FCM ditentukan sebagai berikut :
jumlah cluster = c = 3;
pangkat = w = 2;
maksimum iterasi = MaxIter = 50;
error terkecil yang diharapkan = = 10-3;
fungsi obyektif awal = P0 = 0;
iterasi awal = t = 1;
2. Analisis proses
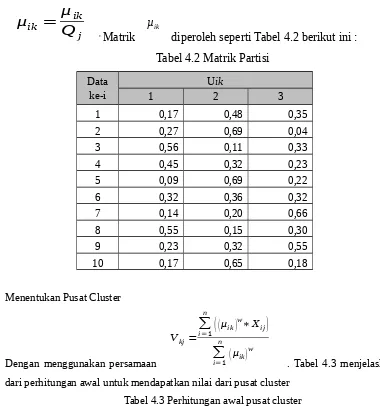
a. Tentukan matrik partisi U dengan menggunakan persamaan Qj=
∑
k=1c
μik
dan
μ
ik=
μ
ikQ
j , Matrik µikdiperoleh seperti Tabel 4.2 berikut ini : Tabel 4.2 Matrik Partisi
Data ke-i
Uik
1 2 3
1 0,17 0,48 0,35
2 0,27 0,69 0,04
3 0,56 0,11 0,33
4 0,45 0,32 0,23
5 0,09 0,69 0,22
6 0,32 0,36 0,32
7 0,14 0,20 0,66
8 0,55 0,15 0,30
9 0,23 0,32 0,55
10 0,17 0,65 0,18
b. Menentukan Pusat Cluster
Dengan menggunakan persamaan
Vkj=
∑
i=1
n
(
(μik)w∗X ij)
∑
i=1
n (μik)w
. Tabel 4.3 menjelaskan hasil dari perhitungan awal untuk mendapatkan nilai dari pusat cluster
Tabel 4.3 Perhitungan awal pusat cluster
k/j
∑
i=1
n
(
µik)
w
∑
i=1
n
(
µik)
wx Xij1 2 3 4 5
1 1,0505 8,36070 9,54830 5,19950 29,62850 3,27050 2 1,48920 13,04400 6,15300 9,02000 36,73680 4,50850 3 0,96230 8,86910 8,26410 5,32850 27,07790 4,35900
Pusat cluster diperoleh dari kelanjutan hasil perhitungan Tabel 4.3 dengan memberikan hasil seperti Tabel 4.4 berikut ini :
Tabel 4.4 Pusat cluster
k/j
∑
i=1
n
(
µik)
wx X ij∑
i=1
n
1 2 3 4 5 1 7,958782 9,089291 4,949548 28,204188 3,113279 2 8,759065 4,131749 6,056943 24,668815 3,027464 3 9,216564 8,587862 5,537254 28,138730 4,529772
c. Fungsi objektif pada iterasi pertama P1 dapat dihitung dengan menggunakan
persamaan ... . Detail perhitungan fungsi objektif ini dapat dilihat pada Tabel 4.5 berikut ini :
Tabel 4.5 Perhitungan fungsi objektif
Data
1 2,991972 7,501458 10,1553486 20,648779 2 10,687647 20,676202 0,23237734 31,596227 3 9,896599 1,335755 2,91303198 14,145386 4 21,112030 8,605876 6,00844307 35,726349 5 0,172089 9,499617 0,88644199 10,558148 6 0,880632 6,749712 0,32121919 7,951563 7 0,168558 2,083244 1,36643634 3,618239 8 9,986161 2,570046 4,57985663 17,136064 9 11,095288 13,890904 71,8395046 96,825697 10 0,699273 32,336737 0,75929213 33,795303
Pt 141,380754
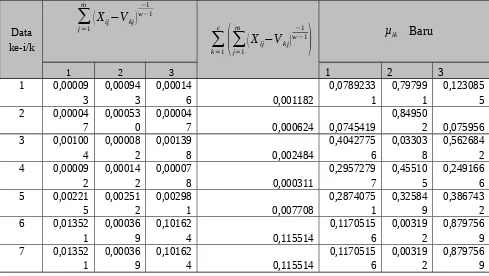
d. Perbaiki derajat keanggotaan baru, seperti yang terlihat pada Tabel 4.6 berikut ini : Tabel 4.6 Perbaikan derajat keanggotaan baru ( µik Baru)
Data
1 0,00009 3
0,00094 3
0,00014
6 0,001182
0,0789233 2 0,00004
7
0,00053 0
0,00004
7 0,000624 0,0745419
0,84950
2 0,075956 3 0,00100
4
0,00008 2
0,00139
8 0,002484
0,4042775 4 0,00009
2
0,00014 2
0,00007
8 0,000311
0,2957279 5 0,00221
5
0,00251 2
0,00298
1 0,007708
0,2874075 6 0,01352
1
0,00036 9
0,10162
4 0,115514
0,1170515 7 0,01352
1
0,00036 9
0,10162
4 0,115514
8 0,00091 8
0,00007 7
0,00038
6 0,001380
0,6647266 9 0,00002
3
0,00005 4
0,00001
8 0,000095
0,2397748 10 0,00170
8
0,00017 1
0,00182
1 0,003700
0,4616855
(0,0001) dan iterasi = 1< MaxIter (=50) maka dilakukan kembali tahapan algoritma pengclusteran data diatas.
3. Data Keluaran
Penentuan kelompok dari data ditentukan ketika iterasi berhenti, misalkan Tabel 4.7 berikut ini adalah data akhir hasil iterasi yang terbentuk. Penentuan kelompok diperoleh dengan membandingkan nilai tiap cluster dari data.
Tabel 4.7 Pengelompokan data Data
ke-i/k
µik Cluster
1 2 3 1 2 3
1 0,0789233
1 0,797991
0,123085
5 *
2 0,0745419 0,849502 0,075956 * 3 0,4042775
6 0,033038
0,562684
2 *
4 0,2957279
7 0,455105
0,249166
6 *
5 0,2874075
1 0,325849
0,386743
2 *
6
0,11705156 0,003192
0,879756
9 *
7
0,11705156 0,003192
0,879756
9 *
8 0,6647266
5 0,055523
0,279750
4 *
9 0,2397748
3 0,573203
0,187022
4 *
10 0,4616855
8 0,046143
0,492171
5 *
Dari Tabel 4.7 terlihat bahwa anggota dari tiap cluster yang terbentuk yaitu : Cluster 1 : { 8 }
Analisis Case Based Reasoning Untuk Penentuan Masyarakat Miskin
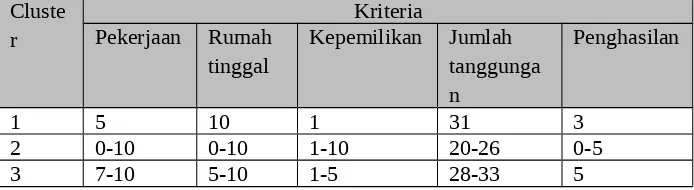
Hasil yang diperoleh dari perhitungan FCM dalam bentuk kelompok-kelompok akan digunakan sebagai dasar pengetahuan penentuan posisi dari data kasus baru. Misalkan pada hasil perhitungan di atas yang telah diperoleh dapat dilakukan interval nilai kriteria yang ada, seperti Tabel 4.8 berikut ini :
Tabel 4.8 Interval kelompok Cluste
r
Kriteria Pekerjaan Rumah
tinggal
Kepemilikan Jumlah tanggunga n
Penghasilan
1 5 10 1 31 3
2 0-10 0-10 1-10 20-26 0-5
3 7-10 5-10 1-5 28-33 5
Jika pada contoh ini mempunyai kasus baru dengan data-data sebagai berikut :
Pekerjaan : 5
Rumah tinggal : 5 Kepemilikan : 0 Jumlah tanggungan : 5 Penghasilan : 3
dari kasus ini akan ditentukan keberadaannya pada kelompok dengan menghitung selisih antara pusat cluster dengan data kasus, rincian perhitungan dapat dilihat pada Tabel 4.9 berikut ini :
Tabel 4.9 Perhitungan selisih kasus
Pusat Cluster – Data Kasus Baru Hasil
1 2 3 4 5
1 2,958782 4,089291 4,949548 23,204188 2,113279 37,315088 2 3,759065 0,868251 6,056943 19,668815 2,027464 30,644037 3 4,216564 3,587862 5,537254 23,138730 3,529772 40,010184