LANDASAN TEORI
2.1. Information Retrieval System
2.1.1. PengertianInformation Retrieval System
Information retrieval system merupakan bagian dari bidang ilmu komputer yang bertujuan untuk pengambilan informasi dari dokumen-dokumen yang didasarkan pada
isi dan konteks dari dokumen-dokumen itu sendiri. Definisi Information Retrieval System menurut Gerald J. Kowalski adalah suatu sistem yang mampu melakukan penyimpanan, pencarian, dan pemeliharaan informasi. Informasi dalam konteks yang
dibahas dalam buku ini dapat berupa informasi teks (termasuk data numerik dan
tanggal), gambar, audio, video, dan objek multimedia lainnya (J. Kowalski, G, 2000)
Definisi menurut Christoper Manning adalah proses menemukan suatu tema
utama (biasanya berupa dokumen) dari suatu data yang tidak terstruktur dalam koleksi
yang besar (tersimpan dalam komputer) untuk memenuhi kebutuhan informasi yang
relevan.
Data tidak terstruktur adalah data yang tidak memiliki susunan semantik, atau
dapat juga dikatakan data yang tidak memiliki struktur yang mudah dikenali oleh
komputer, data ini biasanya berupa teks. Walaupun dalam kenyataannya tidak ada
data yang benar-benar bersifat “tidak terstruktur”, termasuk teks, karena teks juga
memiliki struktur, seperti judul, paragraf, dan catatan kaki yang mana biasanya
struktur tersebut direpresentasikan dalam suatu dokumen dengan memberikan tanda
(markup) yang jelas untuk masing-masing struktur tersebut. Selain memfasilitasi penemuan kembali pada data yang tidak terstruktur, IR juga memfasilitasi pencarian
mengandung kata “Java” dengan badan teks yang mengandung kata
“threading”(Manning, 2008).
Sebagai suatu bidang tersendiri dalam ilmu komputer, IR memiliki beberapa sub
bidang, yaitu sebagai berikut:
1. Document routing, filtering, dan selective dissemination. Tema ini berbalik arah dengan proses IR pada umumnya. Jika proses IR yang umum adalah
membandingkan dokumen dengan query yang dimasukan user, sedangkan pada document routing, filtering, dan selective dissemination sistem akan membandingkan antar dokumen berdasarkan query untuk mendapatkan dokumen yang dapat menarik minat pengguna.
Contoh pada tema ini adalah agregator berita, misalnya dengan menggunakan
proses routing untuk memisahkan berita berdasarkan tema tertentu (bisnis, politik, olahraga, dan sebagainya).
2. Text clustering and categorization system, adalah sistem IR yang akan mengelompokkan dokumen berdasarkan kunci tertentu.
3. Summarization systematau peringkas teks, sistem ini akan membuat ringkasan dari teks yang diberikan.
Contohnya adalah snippetyang ditampilkan pada hasil pencarian web.
4. Information extraction system, topik IR ini berfungsi mengidentifikasi entitas bernama, seperti nama tempat dan tanggal. Sistem ini juga dapat
menkombinasikan informasi-informasi ke dalam rekaman terstruktur yang
mendeskripsikan hubungan antara entitas-entitas tersebut.
Misalkan untuk membuat daftar buku dan pengarangnya dari web data,ekstraksi informasi dari legal document (seperti undang-undang, peraturan pemerintah, dan sebagainya).
5. Topic detection and tracking system (sistem pendeteksi dan pelacakan topik), sistem ini berguna untuk mengidentifikasi topik peristiwa dalam berita dan
sumber-sumber informasi yang sama.
6. Expert search system (sistem pencari keahlian), sistem ini akan melakukan pengidentifikasian keahlian dari seorang anggota organisasi.
7. Question answering system (sistem tanya jawab), adalah sistem yang mengintegrasikan informasi dari berbagai sumber untuk memberikan jawaban
yang singkat dari pertanyaan tertentu. Sistem ini kadang juga digabungkan
Jika sistem IR yang umum adalah mengembalikan dokumen yang relevan
kepada user berdasarkan query yang diinputkan, namun pada sistem tanya
jawab yang dikembalikan adalah berupa kalimat singkat untuk menjawab
pertanyaan user.
8. Multimedia information retrieval system, adalah tema IR yang mengembangkan teknik-teknik IR pada data multimedia seperti gambar, video,
musik, dan pidato. Contoh dari sub-bidang ini adalah pencarian gambar,
pencarian musik, video, dan sebagainya (Butcher, S, 2010).
2.2. Pencocokan String (String Matching) 2.2.1. Pengertian Pencocokan String
Pencocokan string merupakan bagian terpenting dari sebuah proses pencarian string
(string searching) dalam sebuah dokumen. Hasil dari pencarian sebuah string dalam dokumen tergantung dari teknik atau cara pencocokan string yang digunakan. Pencocokan string diartikan sebagai sebuah permasalahan untuk menemukan pola susunan karakter stringdi dalam stringlain atau bagian dari isi teks (Syaroni, 2005).
Pencarian string yang juga bisa disebut pencocokan string (string matching) merupakan algoritma untuk melakukan pencarian semua kemunculan string pendek
pattern [ 0…n-1] yang disebut pattern di string yang lebih panjang teks [0…m-1] yang disebut teks (Charras, 1997).
2.2.2. Kerangka Kerja Pencocokan String
Persoalan pencarian string dirumuskan sebagai berikut:
1. Sebuah teks, yaitu sebuah (long) stringyang panjangnya n karakter. 2. Pattern, yaitu sebuah stringdengan panjang m.
Dengan sebuah nilai karakter (m<n) yang akan dicari dalam teks. Dalam algoritma
pencocokan string, teks diasumsikan berada di dalam memori, sehingga bila kita mencari string di dalam sebuah arsip, maka semua isi arsip perlu dibaca terlebih dahulu kemudian disimpan di dalam memori. Jika pattern muncul lebih dari sekali di dalam teks, maka pencarian hanya akan memberikan keluaran berupa lokasi pattern
2.2.3. Kerangka Pikir Pencocokan String
Algoritma string matching dapat diklasifikasikan menjadi 3 bagian menurut arah pencariannya, yakni:
1. From left to right
Dari arah yang paling alami, dari kiri ke kanan, yang merupakan arah untuk
membaca. Algoritma yang termasuk kategori ini adalah algoritma brute force, algoritma knuth-morris-pratt. Untuk contoh pencarian kata menggunakan algoritma from left to rightdapat dilihat pada Tabel 2.1.
Tabel 2.1. Pencarian Kata Menggunakan Algoritma Knuth-Morris-Pratt
i 0 1 2 3 4 5 6
Pattern(i) A R A R I E F Prefix(i) 0 0 1 2 0 0 0
i 0 1 2 3 4 5 6 7 8 9 10 11 12
Pattern A R A R I E F
Text A R A R E F A R A R I E F
FASE 1 A R A R I E F
FASE 2 A R A R I E F
FASE 3 A R A R I E F
FASE 4 A R A R I E F
2. From right to left
Dari arah kanan ke kiri, arah yang biasanya menghasilkan hasil terbaik secara
partikal. Algoritma yang termasuk kategori ini adalah algoritma boyer-moore. Contoh pencarian menggunakan algoritma boyer-moore dapat dilihat pada
Tabel 2.2.
Tabel 2.2 Pencarian Kata Menggunakan Algoritma Boyer-Moore
I 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
Pattern A R I E F
Text A R A R I F A R I F A R I E F
FASE 2 A R I E F
FASE 3 A R I E F
FASE 4 A R I E F
3. In a specific order
Dari arah yang ditentukan secara spesifik oleh algoritma tersebut, arah ini
menghasilkan hasil terbaik secara teoritis. Algoritma yang termasuk kategori ini
adalah algoritma colossi dan algoritma crochemore-perrin. Untuk contoh dari algoritma in a specific orderdapat dilihat pada Tabel 2.3.
Tabel 2.3. Pencarian Kata Menggunakan Algoritma Colossi
nd= 3
Fase 1
Bergeser 3 karakter (shift[2])
Bergeser 2 karakter (shift[1])
Beberapa konsep string matchingantara lain:
1. Approximate string matching, yaitu sebuah pencarian terhadap pola-pola
string (mengandung beberapa proses yaitu menghitung jumlah karakter yang berbeda, penyisipan dan penghapusan karakter) sehingga mendekati pola atau
patterndari stringyang dicari.
2. Algorima pencarian string adalah sebuah proses pencarian tempat dari suatu atau beberapa stringyang ditemukan dalam sebuah kumpulan stringatau teks. Jalan paling sederhana adalah dengan cara membaca karakter satu persatu dan
melakukan perhitungan kesalahan posisi yang ada dari string yang dicari (Charras, 1997).
2.2.4. Macam Algoritma Pencocokan String
Secara garis besar string matchingdibedakan menjadi 2 yaitu:
1. Exact string matching.
Exact string matching, merupakan pencocokan string secara tepat dengan susunan karakter dalam string yang dicocokkan memiliki jumlah maupun urutan karakter dalam string yang sama. Bagian algoritma ini bermanfaat jika
pengguna ingin mencari string dalam dokumen yang sama persis dengan
stringmasukan.
Beberapa algoritma exact string matchingyang mengemuka antara lain: a. Brute Force
Analisis dengan metode Brute Force adalah membandingkan karakter per karakter sampai ditemukannya pola yang dicari dari awal string sampai dengan akhir string.
b. Knuth-Morris-Pratt
Metode yang akan digunakan dalam penelitian ini dan akan dijelaskan
c. Boyer-Moore
Algoritma boyer-moore adalah algoritma yang mempertimbangkan string
matching dengan efisiensi tinggi dari aplikasi. Algoritma ini melakukan
pencocokan karakter yang dimulai dari kanan ke kiri.
2. Inexact string matching atauFuzzy string matching.
Fuzzy string matchingmerupakan pencocokan stringsecara samar, maksudnya pencocokan stringdimana stringyang dicocokkan memiliki kemiripan dimana keduanya memiliki susunan karakter yang berbeda (mungkin jumlah atau
urutannya) tetapi string-string tersebut memiliki kemiripan baik kemiripan tekstual/ penulisan (approximate string matching) atau kemiripan ucapan (phonetic string matching). Metode fuzzy string matching diarahkan untuk mencari nilai dari beberapa string yang mendekati dan tidak hanya menghasilkan cocok atau tidak cocok (Syaroni, 2005).
Konsep Fuzzy String Matching:
1. Fuzzy String Matching adalah salah satu metode pencarian string yang menggunakan proses pendekatan terhadap pola dari stringyang dicari. 2. Melakukan pencarian terhadap string yang sama dan juga string yang
mendekati dengan string lain yang terkumpul dalam sebuah penampung atau kamus.
Kunci dari konsep pencarian ini adalah bagaimana memutuskan bahwa sebuah
string yang dicari memiliki kesamaan dengan string tertampung di kamus, meskipun tidak sama persis dalam susunan karakternya. Untuk memutuskan string hasil pencarian jika ditemukan stringhasil pendekatan (aproksimasi) (Dewanto, 2007)
2.3. Algoritma Knuth-Morris-Pratt
Algoritma Knuth-Morris-Pratt (KMP) mencari kehadiran sebuah kata w dalam teks s
dengan melakukan observasi awal (preprocessing) yaitu ketika muncul ketidaksamaan kata ini mempunyai informasi mengenai kapan kesamaan selanjutnya bermula,
dengan cara mengecek ulang kata sebelumnya. Algoritma ini dibuat oleh Knuth dan
Pratt dan sendiri oleh J. H. Morris pada tahun 1977, namun ketiganya
Algoritma Knuth-Morris-Pratt (KMP) merupakan algoritma yang digunakan untuk melakukan proses pencocokan string. Algoritma ini merupakan jenis Exact String matching Algorithm yang merupakan pencocokan string secara tepat dengan susunan karakter dalam stringyang sama Contoh : kata algoritmik akan menunjukkan kecocokan hanya dengan kata algoritmik. Pada algoritma Knuth-Morris-Pratt(KMP), disimpan informasi yang digunakan untuk melakukan pergeseran lebih jauh, tidak
hanya satu karakter seperti algoritma Brute Force. Algoritma ini melakukan pencocokan dari kiri ke kanan (Fadillah, 2008).
2.3.1. Fungsi Pinggiran Pada Algoritma Knuth-Morris-Pratt
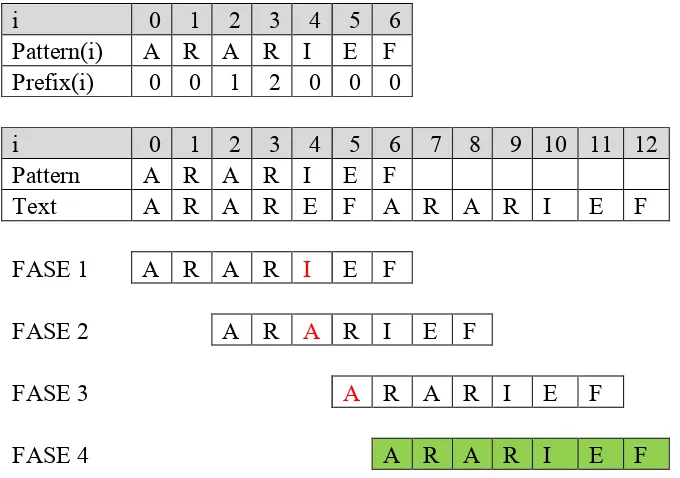
Fungsi pinggiran Prefix(i) didefinisikan sebagai ukuran awalan terpanjang dari Pattern
yang merupakan akhiran dari Pattern[1…i]. Sebagai contoh, tinjau Pattern(i) =
ararief. Nilai untuk setiap karakter di dalam Pattern dapat dilihat pada Tabel 2.4. (Wibowo, 2012).
Tabel 2.4. Fungsi Pinggiran
I 0 1 2 3 4 5 6
Pattern(i) A R A R I E F
Prefix(i) 0 0 1 2 0 0 0
2.3.2. Pencarian Dengan Algoritma Knuth-Morris-Pratt
Secara sistematis, langkah-langkah yang dilakukan algoritma Knuth-Morris-Pratt
pada saat mencocokkan string.
1. Algoritma Knuth-Morris-Prattmulai mencocokkan patternpada awal teks. 2. Dari kiri ke kanan, algoritma ini akan mencocokkan karakter per karakter pattern
dengan karakter di teks yang bersesuaian, sampai salah satu kondisi berikut
dipenuhi:
a. Karakter di patterndan di teks yang dibandingkan tidak cocok (missmatch). b. Semua karakter di patterncocok. Kemudian algoritma akan memberitahukan
penemuan di posisi ini.
Untuk menggambarkan rincian algoritma, akan diberikan, contoh kasus, dimana
kata P = “ARARIEF” dan kalimat T = “ARAREFARARIEF”. Pada waktu tertentu,
algoritma dalam keadaan yang ditentukan oleh dua variabel bilangan bulat:
1. m yang menunjukkan posisi dalam T yang merupakan awal dari perbandingan
prospektif untuk P.
2. i indeks di P yang menunjukkan karakter saat ini sedang dipertimbangkan.
Dalam setiap langkah, kita membandingkan T [m + i] dengan P [i] dan jika
mereka sama. Hal ini digambarkan, pada awal menjalankan, seperti Gambar 2.1.
m 0 1 2 3 4 5 6 7 8 9 10 11 12
T A R A R E F A R A R I E F
P A R A R I E F
i 0 1 2 3 4 5 6
Gambar 2.1. Iterasi metode Knuth-Morris-PrattPertama
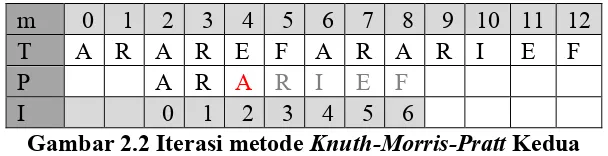
Kita lanjutkan dengan membandingkan karakter berturut-turut P untuk karakter
dari T, bergerak dari satu ke yang berikutnya apakah mereka cocok. Namun, pada
langkah kelima, kita mendapatkan T[4] adalah ‘E’ dan P[4] = ‘I’, tidak cocok. Karena
itu kita beralih ke karakter berikutnya, menetapkan jumlah pergeseran dari nilai fungsi
pinggiran, dapat dilihat dari gambar 1 bahwa karakter terakhir yang cocok adalah P[4]
= ‘R’ yang memiliki nilai fungsi pinggiran = 2 sebagaimana dilihat pada Gambar 2.2.
m 0 1 2 3 4 5 6 7 8 9 10 11 12
T A R A R E F A R A R I E F
P A R A R I E F
I 0 1 2 3 4 5 6
Gambar 2.2 Iterasi metode Knuth-Morris-PrattKedua
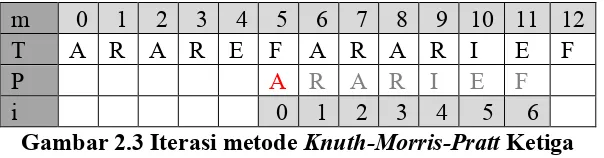
Sistem kembali memiliki ketidaksesuaian pada P[2] (T[4]). Daripada mulai mencari
lagi di T[3], sistem mencatat bahwa tidak ada ‘A’ terjadi antara posisi 2 dan 4 di T
kecuali pada 2; oleh karena itu, setelah memeriksa karakter yang sebelumnya, kita
tahu tidak ada peluang untuk menemukan awal yang cocok jika kita memeriksa
mereka lagi. Oleh karena itu kita beralih ke karakter berikutnya, menetapkan m = 5
m 0 1 2 3 4 5 6 7 8 9 10 11 12
T A R A R E F A R A R I E F
P A R A R I E F
i 0 1 2 3 4 5 6
Gambar 2.3 Iterasi metode Knuth-Morris-PrattKetiga
Pencarian ini masi gagal karena terjadi ketidak sesuaian di P[1] (T[5]). Sehingga
kita kembali ke awal P dan mulai mencari di karakter berikutnya T: m = 6, reset i = 0.
Langkah selanjutnya dapat dilihat dari Gambar 2.4.
M 0 1 2 3 4 5 6 7 8 9 10 11 12
T A R A R E F A R A R I E F
P A R A R I E F
I 0 1 2 3 4 5 6
Gambar 2.4 Iterasi metode Knuth-Morris-PrattKeempat
Kali ini kita dapat menyelesaikan seluruh pencocokan, yang karakter pertama
adalah T[6] (Mulyana, 2014).
Berikut adalah pseudocodealgoritma KMP pada fase pra-pencarian: procedure preKMP (
input p : array[0..n-1] of char, input n : integer,
input/ output kmpNext : array[0..n] of integer )
Dan berikut adalah pseudocode algoritma KMP pada fase pencarian:
procedure KMPSearch(
input m, n : integer,
input P : array[0..n-1] of char, input T : array[0..m-1] of char,
Deklarasi:
Untuk menghitung fungsi pinggiran dibutuhkan waktu O(m), sedangkan pencarian
string membutuhkan waktu O(n), sehingga kompleksitas waktu algoritma KMP adalah O(m+n) (Guntur, 2008).
2.3.4. Kelebihan Algoritma Knuth-Morris-Pratt
Pada algoritma Knuth-Morris-Pratt ini akan menyimpan informasi yang digunakan untuk melakukan jumlah pergeseran. Algoritma menggunakan informasi tersebut
untuk membuat pergeseran yang lebih jauh, tidak hanya satu karakter. Algoritma
Knuth-Morris-Pratt ini menjanjikan karena memiliki waktu pencarian yang linier, baik dalam kasus terbaik atau terburuk (Rizki, 2008).
Implementasi algoritma Knuth-Morris-Pratt akan meningkatkan kemampuan dalam pencarian query dalam dokumen. Algoritma Knuth-Morris-Pratt cocok untuk pencarian stringdengan alphabet sedikit seperti biner (Yusup, 2011).
Adapun kelebihan Algoritma Knuth-Morris-Pratt telah digunakan dalam penelitian-penelitian. Penelitian oleh Mulyana (2014) yang menerapkan algoritma
yang berperan pada saat pencarian yang dilakukan. Sedangkan dalam hal kecepatan,
sangat tergantung pada spesifikasi perangkat keras pengujian. Hal lain yang dapat
diukur adalah skalabilitas waktu pencarian atau kompleksitas waktu.
Penelitian oleh Wibowo (2012) yang menerapkan algoritma Knuth-Morris-Pratt
pada pembuatan aplikasi untuk mendeteksi kebenaran perintah SQL Query
menggunakan metode Knuth-Morris-Pratttelah dihasilkan dari pengujian dan analisa kuisioner yang diberikan kepada user dan dosen bahwa pencocokan ataupun pendeteksian kebenaran perintah SQL Query dengan menggunakan algoritma Knuth-Morris-Pratt dapat diimplementasikan.
Penelitian yang dilakukan oleh Fadillah (2008) dalam pengenalan pola sidik jari
menggunakan algoritma Knuth-Morris-Pratt yang telah dihasilkan dari analisa bahwa akurasi algoritma Knuth-Morris-Pratt dalam pengenalan pola sidik jari memberikan nilai toleransi nol dalam hal noise, dikarenakan dengan adanya noisesedikitnya akan memberikan perubahan pola warna, hal ini juga akan menyebabkan perubahan nilai
intensitas warna yang dikonversi pada citra yang baru dan akan adanya
ketidaksesuaian dengan nilai string yang ada pada database, dan sidik jaripun tidak dapat dikenali.
2.4. Eclipse
Eclipse adalah sebuah IDE (Integrated Development Environment) untuk mengembangkan perangkat lunak dan dapat dijalankan di semua platform. Adapun sifat-sifat dari Eclipse adalah sebagai berikut:
1. Multi-platform
Target sistem operasi Eclipse adalah Microsoft Windows, Linux, Solaris, AIX,
HP-UX dan Mac OS X.
2. Multi-language
Eclipse dikembangkan dengan bahasa pemrograman Java, akan tetapi Eclipse
mendukung pengembangan aplikasi berbasis bahasa pemrograman lainnya,
seperti C/C++, Cobol, Python, Perl, PHP, dan lain sebagainya.
Selain sebagai IDE untuk pengembangan aplikasi, Eclipse pun bisa digunakan
untuk aktivitas dalam siklus pengembangan perangkat lunak, seperti
dokumentasi, tes perangkat lunak, pengembangan web, dan lain sebagainya.
Eclipse pada saat ini merupakan salah satu IDE favorit dikarenakan gratis dan
open source, yang berarti setiap orang dapat melihat kode pemrograman perangkat lunak ini. Selain itu, kelebihan dari Eclipse yang membuatnya populer adalah
kemampuannya untuk dapat dikembangkan oleh pengguna dengan komponen yang