Abstract— Strong’s Concordance is a concordance used as a tool for pointing the word to the real language so the meaning can be known from God’s word, which will be told. In this research strong’s concordance numbering is done into Indonesian New Testament Bible, which until now it has not been found in Indonesian New Testament Bible with strong’s concordance. Strong’s concordance numbering is done using one of Natural Language Processing (NLP) theory and one of Web Mining theory. Strong’s concordance numbering begins with making a phenomenological strong numbering based on appearance of the word. Then, in the next step alignment phenomenological is used among the words on the English Bible using word alignment. The third phenomenological is using n-gram phenomenological with mutual information calculation to search the word’s meaning, which consist of more than one word. The fourth phenomenological is done by stemming in Indonesian New Testament Bible corpus, which will be used as a new corpus to search on the step one until step three. The purpose of stemming is to get the root of the word. Besides that four phenomenological, another phenomenological is also done as proper name searching, strong number searching which has only one frequency and gathering strong number data which include in conjunction, preposition, and pronoun.
Manuscript received October 14, 2009.
Gunawan is with Department of Electrical Engineering, Faculty of Industrial Technology, Institut Teknologi Sepuluh Nopember, Surabaya 60111 Indonesia (email: [email protected]).
Devi Dwi Purwanto, Herman Budianto, and Indra Maryati is with Department of Computer Science, Sekolah Tinggi Teknik Surabaya, Surabaya 60284 Indonesia (email: {devi, herman}@stts.edu, [email protected]).
I. INTRODUCTION
IBLE is a collection of God’s word which is used as a guide of Christian life. The Bible is also the most translated books, that is into 2179 languages and dialects. From the results of translation into many languages, it is found that Bible is lack of proper translation. This is caused by differences in vocabulary or language differences between one another. From here the emergence of the idea of using strong numbers.
In this study conducted by making a web application that can help a person in understanding the Bible. This web application is used to find similarity verse and find the original Greek word of the strong numbers before it is translated.
II. STRONG’S CONCORDANCE
A. Introduction to Concordance
Concordance is an alphabetical list of the principal words used in a book or body of work, with their immediate contexts. Because of the time and expense difficulty involved in creating a concordance in the pre-computer era, only works of special importance, such as the Bible, Qur'an, or the works of Shakespeare, had concordances prepared for them. Even with the use of computers, producing a concordance may require much manual work [1].
Strong’s Concordance or Strong's Exhaustive Concordance of the Bible is a concordance of the Bible that was constructed under the direction of Dr. James Strong (1822–1894) and first published in 1890 [9]. The purpose of this concordance is not provide the content or description of the Bible, but to provide the index to the Bible. This allows the reader to find the words to see the verse in the Bible. This index also allows the reader to find a phrase to compare how the
Gunawan
Department of Electrical Engineering, Faculty of Industrial Technology
Institut Teknologi Sepuluh Nopember, Surabaya 60111, Indonesia
Email: [email protected]
Strong’s Concordance Formulation for Indonesian
New Testament Bible
Devi Dwi Purwanto, Herman Budianto, and Indra Maryati
Department of Computer Science, Sekolah Tinggi Teknik Surabaya
Surabaya 60284, Indonesia
Email: [email protected], [email protected], [email protected]
)
same topics discussed in different parts of the Bible. The use of Strong's numbers does not consider figures of speech, metaphors, idioms, common phrases, cultural references, references to historical events, or alternate meanings used by those of the time period to express their thoughts in their own language at the time.
B. Concordance Advantages
Concordance is usually used as a tool in linguistics that used in the text or corpus of learning which are well documented. Well documented means to have a clear structure, which can be used to connect two different language corpus. There are four advantages of Concordance:
1) Comparing the use of different words from the same basic word.
2) Researching keywords.
3) Examining the frequency of words used in the numbers so that it can be used to provide the index to the Bible. There are four advantages of Strong’s Concordance:
1) Finding and researching phrases and idioms. 2) Finding translations of E.G. terminology
subsentential in two different language corpus. 3) Helping to know the truth of the Bible in its
original language so that no one misunderstand what the God’s word.
4) Helping people in interpreting the Bible. III. NATURAL LANGUAGE PROCESSING
Natural Language processing (NLP) is the process of transforming information which is expressed in speech and written language of the people to be input to the computer through the software in order to obtain certain information. In this research will explain about statiscal NLP and text retrieval. Both of them will explain below.
A. Statistical NLP
Statistical NLP perform statistical analysis on the existing corpus, with the assumption that a large collection of texts (corpus) can describe the nature of the language of a language is used in a statistical information corpus. There are 3 statistical methods used to obtain statistical information on the corpus. Word Alignment
Word alignment is one of the tasks in NLP used to identify the relationship between the translation or translation of pairs word in two different corpus
language. Word alignment is usually done after the sentence alignment is completed. Sentence alignment itself is a process to identify pairs of sentence in which a sentence is the result of the translation of other However, not all of English language can be translated into French language. One word in English can be two words in French.
Fig. 1. Example of Word Aligment [2]
To identify the translational relationship between the two languages, chi-square approach to the 2x2 matrix is used. The approximate formula is:
N-Gram
N-gram is a static model of operation associated with the modeling language that includes provision of value in the word or phrase in which modeling is based on the type of application will be made. One theory to formulate the modeling language is Markov Models, a modeling language which the formulation is based on the theory of this n-grams.
The purpose of the use of n-grams in this research is to study the available corpus we can learn from each candidate of strong numbers against the emergence of word pairs, this is because there are many words that will form to a word new meaning. For grouping the pair used n = 2 ("bigram") and n = 3 ("trigrams") are commonly used.
Mutual Information
In this research, grouping n-gram based on the letter can not be used so that only the grouping of words that can be used. The candidate will carry out calculations using mutual information to know which candidate most likely to the strong numbers.
B. Text Retrieval
Text retrieval is a method used to assist users in finding some useful information in a large collection of texts. In text retrieval, text search on the representation of a dictionary is known as indexing. The process of indexing includes tokenization, stopword removal, stemming, and term weight. Anyhow, this research will use stopword removal and stemming.
Stop Removal
Removal process is done by matching words with stoplist. If there are words that are matched on stoplist, the word is not included in the next process. Examples of words included in the stopword is and, the, or, and others which depend on the context of the corpus. Stemming
Stemming is mapping process from the decomposition of various forms of words such prefik, sufik, or a combination of prefik and sufik, to a basic word form (stem). Stemming algorithm is used in this research is Potter Stemmer for Indonesian. Illustration of the algorithm which can be seen in fig. 3.
Stemming algorithm in fig. 3 it can be overcomed in the form of particles suffixes, suffix indicating ownership pronoun, the prefix (affix), suffixes (postfix), and the combination of prefixes and suffixes. Before doing the removal process in Potter Stemmer, calculations measure is performed. This in conflation is to avoid performed on the base. Porter Stemmer algorithm is selected because it has a morphological structure similar to Indonesian which is composed of a combination or suffixes and prefixes.
Fig. 3. Illustration of Porter Stemmer [2]
IV. VECTOR SPACE MODEL
To make similarity of the Bible use Vector Space Model. Vector space model is typically used in applications such as Google's search engine. In vector space model TF (term frequency) is calculated and IDF (inverse document frequency). Calculations of TF can be done by using one of the formula below [3].
Inverse document frequency is working to reduce the value of coordinates of the terms contained in many documents. Because not all axes in vector space is important, there is also a document that has noise. IDF itself can be calculated with different variations [3] such as:
Fig. 4. Illustration of 2-Dimensional Similarity [3]
From fig. 4, vector dj is a document used as a search. While q is a query search. To determine the association rate, the cosine angle is used, where a close similarity value to 1 will be more similar to his query. Similarity formula [3] is:
(2) phases in Strong's numbering process. Each process will be explained below.
A. With frequency search approach
The first stage is done by counting the frequency of appearance of words in the verse found in strong numbers. After the appearance calculated stopword removal is performed later by difiltering certain threshold. Stopword removal is intended because the word often appears in the paragraph in the Indonesian New Testament Bible. Threshold that has been tested and is considered a good minimum is found in strong numbers in 2 verses and have a greater frequency equal to 0.6.
B. With Word Alignment
In this second phase frequency calculations performed with the help of mutual information which can be expected better results than the results of the first stage. How it works almost the same as the first phase of which initially provided two corpus. The difference is the method of calculating the frequency.
The calculation is done by making a matrix of size 2x2. Examples of cases with the calculation of mutual information can be seen in fig. 5. After the value of mutual information is obtained, the greater the value the candidate is suspected as the main candidate.
Fig. 5. Example of MI Calculation
C. With N-Gram
The third stage is to combine 2 words, which combination is based on the theory of n-grams. From the combination of these 2 words, it is found that candidates who will be filtered on the condition that the value of the first mutual information is greater than the value of the second mutual information. And O11 values is greater than 1 and O11 values greater than O12.
D. With Stemmed Corpus
The fourth stage is to conduct stemming the Indonesian New Testament corpus. This stage is needed because of the differences between English grammar and Indonesian grammar that can make different frequency strong numbers and words candidate. Corpus stemming results will be used as a corpus in the process of stage I-III.
E. Search Back to Phase I
The fifth stage is a strong candidate search again in phase I, where the first candidate threshold is greater than the second threshold candidate. In addition to search for candidates based on the proper name, strong numbers are included in conjunctions, prepositions, and pronouns. manufacture other features of similarity. General architecture for strong numbering from the 5 phases covers preprocess, process, candidate, filtering, and manual check. The architecture for windows application show in figure 6.
has been known before, and do manual check for strong number that has frequency equal to 1. In the last phase, we will get the strong numbers.
Fig. 6. Architecture for Windows Application
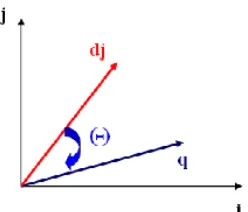
Architecture for similarity search and web-based Bible is user input will be sent via the Internet, then do the processing of queries based on user input, both for the search feature and the feature similarity (resemblance). The data used in this application is obtained from the strong numbers on the application made earlier. From the results of the query, processing will pass to the user via the internet. Output for the query similarity is a ranking of the list of the most similar passage is sorted in descending. The architecture for web application show in figure 7.
Fig. 7. Architecture for Web Application
VII. TESTING
Applications strong numbering with five phases in the research has been able to provide the proper strong numbers in Indonesian Bible. This can be ascertained from the handling of strong numbers to the back of the word. With the preparation method is obtained that the Indonesian New Testament with strong numbers with a success rate of 61.03%.
Stemming can be used to help improve the accuracy of numbering. Because stemming can improve the 7.50% results of strong numbering than the strong numbering without stemming.
The main difficulty for strong numbers to perfect accuracy is the fact that there are 1839 strong numbers or 33.29% which is only used once in the New Testament.
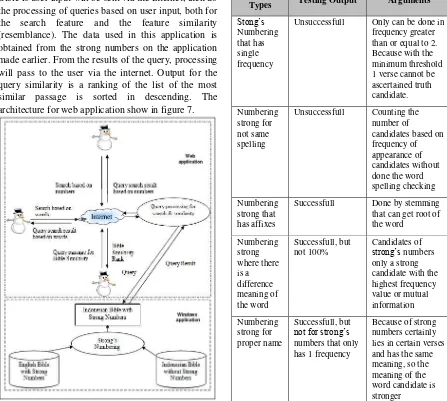
Testing is done with several types of cases and can be seen in table 1 below.
Table 1
Strong’s Numbering Testing
Testing
Types Testing Output Arguments
Stong’s
Numbering that has single frequency
Unsuccessfull Only can be done in frequency greater than or equal to 2. Because with the minimum threshold 1 verse cannot be ascertained truth candidate. Numbering
strong for not same spelling
Unsuccessfull Counting the number of
candidates based on frequency of appearance of candidates without done the word spelling checking Numbering
strong that has affixes
Successfull Done by stemming that can get root of the word
Numbering strong where there is a difference meaning of the word
Successfull, but not 100%
Candidates of
strong’s numbers only a strong candidate with the highest frequency value or mutual information Numbering
strong for proper name
Successfull, but
not for strong’s
numbers that only has 1 frequency
Table 1 Continues
Testing
Types Testing Output Arguments
Numbering strong for phase
Successfull, but not 100%
The right candidate phrase does not have the value of the highest mutual information Numbering
strong for a different number of words between the Indonesian Bible with English Bible
Successfull, depends on mutual information
The numbering is not depending on the number of words, but depends on the frequency value or the value of mutual information
VIII. CONCLUSION
With the New Testament Bible in Indonesian language that is equipped with strong numbers, learning the Bible becomes easier and available online. Because of the strong numbers it can be discovered the word, so that it can reduce misunderstandings in the interpretation. Another conclusion can be drawn from the observations at each phases of strong numbering on establish and testing of applications as follows.
1) Word Alignment can help in solving the problem of strong numbers, by knowing how strong the link between the number of English Bible and Indonesian Bible.
2) Numbering strong problem-solving which creates difficulties can be solved by using n-gram calculation, because it can find a link between two or more words.
3) Numbering strong real benefits to the web application is the similarity and search the Bible that can be done by doing a word search based on strong numbers.
4) Although stopword has strong numbers, the calculation results and similarity search, still will cause inaccuracy.
In addition to these four, the program proved to make strong numbers in the New Testament Bible in Indonesian language that previously only in the English Bible into Greek.
REFERENCES [1] Concordance (publishing),
http://en.wikipedia.com/wiki/concordance, May 15th 2008
[2] Z. Talla, Fadillah, “A Study of Stemming Effects on Information Retrieval in Bahasa Indonesia”,
http://info.science.uva.nl/pub/theory/illc/researchreports/MoL-2003-02.text.pdf, 2003
[3] Gunawan, “Vector Space Model: Term Weight, Inverted File Indexing, dan Similarity”,
www.hansmichael.com, 2007
[4] Henry, Matthew, “Tafsiran Injil Markus”, Momentum, 2007 [5] Metode Terjemahan Alkitab,
http://www.sttip.com/metode%20penerjemahan%20alkitab.ht m, August 20 th 2008
[6] Harlian, Milkha Ch., “Machine Learning Text”, Texas, 2006 [7] F.Brown, Peter, “A Statistical Approach to Machine
Translation”,
www.aclweb.org/anthology-new/J/J90-2002.pdf, 2002
[8] Mihalcea, Rada, “An Evaluation Exercise for Word Alignment”, Denton, 2003
[9] Strong’s Concordance,
http://en.wikipedia.com/wiki/concordance, May 1st 2008
[10] Chakrabarti , Soumen, “Mining the Web Discovering
![Fig. 1. Example of Word Aligment [2]](https://thumb-ap.123doks.com/thumbv2/123dok/3666484.1803184/2.595.305.524.234.340/fig-example-word-aligment.webp)
![Fig. 3. Illustration of Porter Stemmer [2]](https://thumb-ap.123doks.com/thumbv2/123dok/3666484.1803184/3.595.307.519.74.320/fig-illustration-of-porter-stemmer.webp)
![Table 1 [3] Indexing, dan SimilarityGunawan, “Vector Space Model: Term Weight, Inverted File Continues”,](https://thumb-ap.123doks.com/thumbv2/123dok/3666484.1803184/6.595.70.294.73.294/table-indexing-similaritygunawan-vector-space-weight-inverted-continues.webp)
