Fuzzy Clustering lecture Babuska
Teks penuh
Gambar
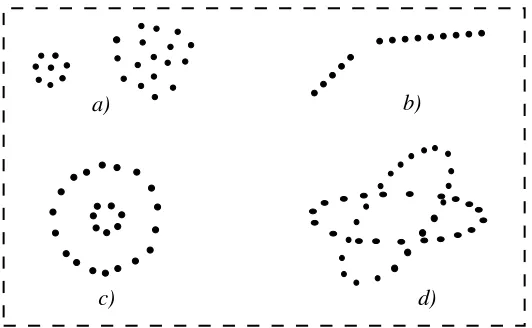
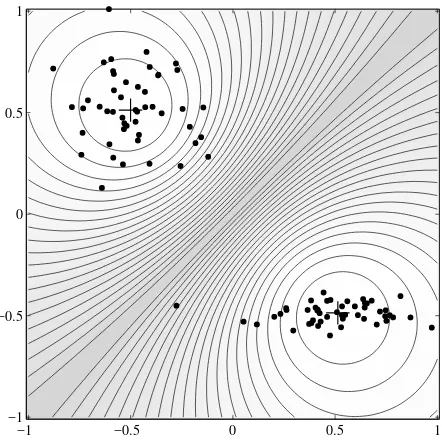
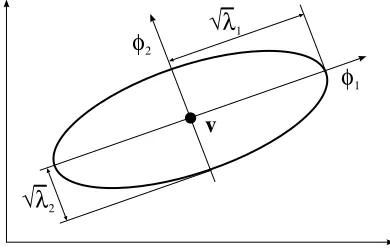
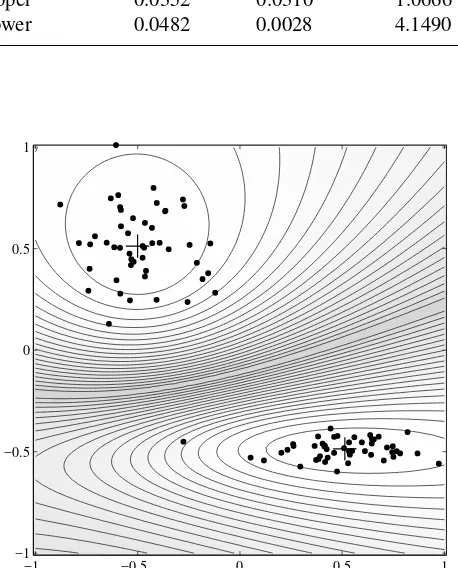
Garis besar
Dokumen terkait
Based on the comprehensive study of image segmentation technology, this paper analyzes the advantages and disadvantages of the existing fuzzy clustering algorithms; integrates the
Abstract — The Multiple Prototype Fuzzy Clustering Model (FCMP), introduced by Nascimento, Mirkin and Moura-Pires (1999), proposes a framework for partitional fuzzy clustering
Zhang, An efficient hybrid data clustering method based on K-harmonic means, and Particle Swarm Optimization, Expert Systems with Applications (36), pp. Liu, Fuzzy C-Mean Clustering
This research focused on creation of the application system of document clustering of search results documents through clustering algorithms of Ant Colony Optimization, Forgy
– To avoid finding patterns in noise – To compare clustering algorithms – To compare two sets of clusters – To compare two clusters.. Determining the clustering tendency of
Figure 2 explains that the Silhouette Index validation test for data on livestock meat production in 34 provinces in Indonesia with 2 clusters using the Fuzzy C- Means Clustering method
To recap, as previous shape-based clustering algorithms have focused upon only objects with specific geometric clusters, the proposed FCGS algorithm’s performance in handling arbitrary
To answer these questions, this paper explores three dimensions of utility for clustering: accuracy of predicted clusters to known clusters, computation time, and a qualitative
