TUGAS AKHIR
Sistem Ekstraksi Informasi Web
Menggunakan
Metode Pencarian Pola Otomatis
Berbasis Pencocokan Pohon
Sigit Dewanto 05/186213/PA/10559 http://nuevasystem.com
Latar Belakang Masalah
Saat ini Web merupakan sumber informasi dengan volume yang besar. Halaman web ditulis dalam HTML, yang merupakan bahasa yang digunakan untuk mengatur presentasi data (bagi manusia) dan bukan untuk mendeskripsikan data itu sendiri. Karena halaman web ditujukan untuk dibaca secara langsung oleh manusia dan bukan oleh komputer, maka data yang berada dalam halaman web tersebut sulit untuk diolah secara otomatis oleh komputer. Akan lebih memudahkan bagi manusia jika komputer dapat mengekstrak data tersebut secara otomatis dari halaman web.
Latar Belakang Masalah
Data terstruktur pada halaman web seringkali mengandung informasi yang penting. Data tersebut umumnya berasal dari basisdata dan ditampilkan dalam halaman Web menggunakan template yang tetap. Data terstruktur tersebut disebut dengan istilah data records (Zhai dan Liu, 2006).
Latar Belakang Masalah
Contoh struktur basisdata yang dimiliki oleh suatu situs web yang menyediakan informasi lowongan kerja
Latar Belakang Masalah
Tampilan data
Latar Belakang Masalah
Latar Belakang Masalah
Masalah ekstraksi data terstruktur dari halaman web telah banyak dikaji oleh para peneliti. Metode ekstraksi yang ada dapat dibagi menjadi tiga kategori, yaitu dengan pembuatan pola secara manual, pembelajaran mesin, dan pencarian pola secara otomatis (Liu, 2007).
Latar Belakang Masalah
Pendekatan pada kategori ketiga memiliki kelebihan dibanding metode lainnya karena tidak diperlukan fasefase seperti proses pembelajaran yang terpisah, validasi, dan aplikasi (Breuel, 2003). Metode pada kategori ketiga dapat dibagi lagi menjadi dua subkategori, yaitu pencarian pola berbasis pencocokan pohon dan berbasis pencocokan string (Liu, 2007). Hasil percobaan menunjukkan bahwa metode pencarian pola berbasis pencocokan pohon lebih efisien daripada yang berbasis pencocokan string (Yeonjung dkk., 2007).
Rumusan Masalah
Bagaimana merancang dan
mengimplementasikan sistem ekstraksi
informasi web (web information extraction
system) menggunakan metode pencarian pola
otomatis berbasis pencocokan pohon.
Rumusan Masalah
Bagaimana kinerja sistem ekstraksi informasi web yang dibuat menggunakan metode pencarian pola otomatis berbasis pencocokan pohon dilihat dari parameter berikut: Precision, yaitu perbandingan antara banyaknya target ekstraksi yang terekstrak dengan banyaknya hasil ekstraksi yang diberikan sistem. Recall, yaitu perbandingan antara banyaknya target ekstraksi yang terekstrak dengan banyaknya target (baik yang terekstrak maupun yang tidak terekstrak).
Batasan Masalah
Informasi yang akan diekstrak oleh sistem ekstraksi informasi yang dibuat merupakan data terstruktur. Jadi ekstraksi informasi yang dimaksud pada sistem yang dibuat adalah ekstraksi data terstruktur. Masukan sistem berupa halaman web tunggal yang merupakan list page, yaitu halaman yang mengandung satu atau lebih daftar objek. Halaman web tersebut dimasukkan secara manual ke sistem oleh pengguna. Data records yang menjadi target ekstraksi adalah data records yang strukturnya tidak bersarang (flat data records).
Batasan Masalah
Data records yang menjadi target ekstraksi adalah contiguous data records. Keluaran sistem (informasi yang diekstrak) merupakan flat data records yang telah dijajarkan data itemsnya (telah dibagi dalam kolomkolom). Fitur yang dimiliki sistem selain ekstraksi data records adalah pencarian data records hasil ekstraksi berdasarkan kriteria yang dimasukkan oleh pengguna. Pengguna akan mengecek relevansi antara data records hasil ekstraksi dengan domain aplikasi secara manual. Jika ada data records atau bagian dari data records tersebut yang tidak relevan dengan domain aplikasi maka pengguna dapat menghilangkan data records atau bagian dari data records tersebut.
Batasan Masalah
Pelabelan kolomkolom pada data records akan dilakukan secara manual oleh pengguna. Namanama kolom pada data records akan distandarisasi agar data records yang diperoleh dari sumbersumber yang berbeda dapat diintegrasikan. Data records hasil ekstraksi bersama dengan label kolomnya akan disimpan ke dalam basisdata relasional.
Jenis Halaman yang Mengandung
Data Records
List pages
Jenis Halaman yang Mengandung
Data Records
Detail pages
Jenis Data Records
flat data records dan nested data records
Jenis Data Records
contiguous dan noncontiguous data records
Kelemahan Ekstraksi Data Records Menggunakan Metode Wrapper Induction Ekstraksi data records menggunakan metode wrapper induction memiliki kelemahan jika diterapkan untuk banyak situs web karena memerlukan proses pelabelan manual. Selain itu, jika template yang digunakan oleh suatu situs berubah maka wrapper yang dihasilkan menjadi tidak valid dan proses pelabelan harus dilakukan lagi.
Ekstraksi Data Records Menggunakan Metode Pencarian Pola Otomatis Ekstraksi pola secara otomatis dikaji para peneliti karena kelemahan dari metode wrapper induction. Ekstraksi pola secara otomatis dimungkinkan karena data records dalam suatu situs web umumnya dikodekan menggunakan suatu template yang tetap. Encoding template tersebut dapat ditemukan dengan mencari polapola yang berulang dalam halaman web. Baik pencocokan string maupun pencocokan pohon dapat digunakan untuk mencari pola tersebut.
Data Extraction Based on Partial Tree Alignment (DEPTA)
Pohon Tag
Tree Mapping dan Tree Matching
Dua Asumsi yang Digunakan dalam
Identifikasi Data Records
Identifikasi Data Regions Menggunakan
Algoritma MDR
Identifikasi Data Records dalam Data
Penjajaran Data Items pada Data Records
Penyisipan Unaligned Nodes
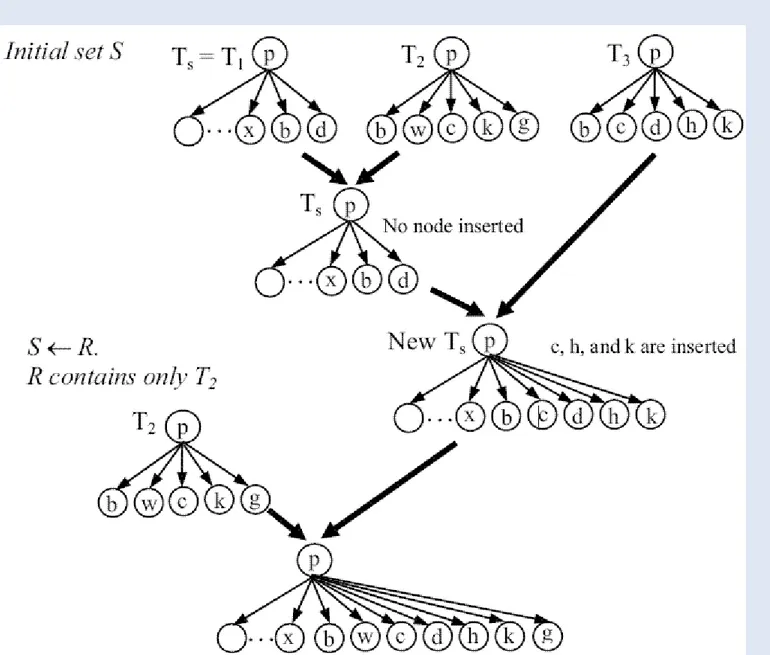
Ilustrasi Partial Tree Alignment
Tabel Hasil Ekstraksi
1 1 1 1 1 T3 1 1 1 1 1 T2 1 1 1 … T1 g k h d c n b x … (Liu, 2007)
ANALISIS
DAN
Analisis Sistem
Hal yang perlu diperhatikan mengenai hasil ekstraksi data terstruktur menggunakan metode pencarian pola otomatis: Semua data terstruktur akan diekstrak, baik yang relevan dengan domain aplikasi maupun yang tidak. Keluaran yang dihasilkan merupakan data records dalam bentuk tabel tanpa nama kolom.
Spesifikasi Sistem
1. Mampu mengekstrak flat data records dari halaman web yang dimasukkan oleh pengguna. 2. Memberikan antarmuka bagi pengguna untuk menyaring lebih lanjut baik tabel maupun data records pada tabel hasil ekstraksi agar data records hasil ekstraksi sesuai dengan domain aplikasi.
Spesifikasi Sistem
3. Memberikan antarmuka bagi pengguna untuk memberikan nama kolom pada tabel hasil ekstraksi. 4. Memberikan fasilitas pencarian data records bagi pengguna.
IMPLEMENTASI
DAN
Pembangunan Sistem
Komponen SDE diimplementasikan menggunakan Java dan hasil implementasinya berupa aplikasi yang berjalan di atas konsol. Komponen web application dan web client merupakan aplikasi berbasis web yang diimplementasikan menggunakan framework CakePHP, JavaScript, HTML, dan CSS. DBMS yang digunakan adalah MySQL 5.
Perbedaan Antara SDE dengan DEPTA
1.Dalam pembangunan pohon tag, DEPTA menggunakan urutan tag pembuka dan informasi visual sedangkan SDE menggunakan parser HTML. 2.DEPTA memanfaatkan informasi visual dalam pembangunan pohon tag, pencocokan pohon, dan pengecekan gap di antara kandidat data records sedangkan SDE tidak menggunakan informasi visual.
Perbedaan Antara SDE dengan DEPTA
3.Dalam perhitungan skor kemiripan antarkandidat data records, DEPTA hanya memperhitungkan tagtag yang di dalamnya terdapat teks sedangkan SDE memperhitungkan seluruh tag dalam data records. 4.DEPTA mampu mengekstrak noncontiguous data records sedangkan SDE tidak.
Perbedaan Antara Pohon DOM dengan
Pohon Tag
Pengujian
SDE dijalankan dengan masukan halaman web dari 20 situs web. Dari setiap situs diambil 2 halaman web berbeda yang mengandung data terstruktur. Dari 20 situs tersebut, 14 di antaranya adalah situs penyedia informasi lowongan pekerjaan di Indonesia dan 6 situs lainnya merupakan situs penyedia informasi lowongan pekerjaan internasional.
Pengujian
Untuk setiap halaman web masukan, SDE akan dijalankan hingga jumlah data records dan data items aktual yang terekstrak maksimum. Setelah dijalankan, parameterparameter berikut akan dicatat: jumlah data records target yang ada pada tiap halaman (data records aktual) jumlah data records aktual yang terekstrak dengan benar jumlah data records aktual yang tidak terekstrak dengan benar
Pengujian
jumlah data records aktual yang tidak terekstrak (tidak teridentifikasi oleh SDE) jumlah data records yang terekstrak oleh SDE jumlah data items target yang ada pada data records aktual yang terekstrak dengan benar (data items aktual) jumlah data items aktual yang terjajarkan dengan benar dari data records aktual yang terekstrak dengan benar
Pengujian
jumlah data items aktual yang terjajarkan dengan salah dari data items aktual yang terekstrak dengan benar jumlah data items aktual yang tidak terjajarkan (tidak teridentifikasi) dari data records aktual yang terekstrak dengan benar jumlah data items yang terjajarkan dari data records aktual yang terekstrak dengan benar
Pengujian
Setelah parameterparameter tersebut dicatat, maka kemudian dihitung nilai precision dan recall dari ekstraksi data records dan penjajaran data items.
Precision Ekstraksi Data Records
yang tidak memperhitungkan data records yang tidak relevan: precision = COR / (COR + WRG) yang memperhitungkan data records yang tidak relevan: precision = COR / FOU
Recall Ekstraksi Data Records
Precision Penjajaran Data Items
Recall Penjajaran Data Items
KESIMPULAN
DAN
Kesimpulan
Metode pencarian pola otomatis berbasis pencocokan pohon telah dapat diterapkan dalam sistem ekstraksi informasi web. Nilai ratarata precision yang memperhitungkan data records yang tidak relevan pada sistem ekstraksi informasi web yang dibangun cukup rendah, yaitu 37,26%. Nilai ratarata precision yang tidak memperhitungkan data records yang tidak relevan dan nilai ratarata recall ekstraksi data records pada sistem ekstraksi informasi web yang dibangun cukup tinggi, yaitu 94,29% dan 94,19%. Nilai ratarata precision dan recall penjajaran data items pada sistem ekstraksi informasi web yang dibangun cukup tinggi, yaitu 96,92% dan 99,94%.
Kesimpulan
Data records aktual terekstrak dengan salah oleh sistem ekstraksi informasi web yang dibangun apabila struktur data records aktual berbeda dengan asumsi yang digunakan dalam metode ekstraksi yang digunakan atau hanya terdapat satu data record aktual yang berdiri sendiri (terpisah dari data records lain yang sejenis). Data records aktual tidak terekstrak (tidak teridentifikasi) oleh sistem ekstraksi informasi web yang dibangun apabila tingkat kemiripan (similarity treshold) antara data records tidak terpenuhi.
Kesimpulan
Data items aktual terjajarkan dengan salah karena metode ekstraksi data terstruktur yang digunakan hanya mencocokkan struktur pohon tag dan string pada data items tanpa memahami makna data items.
Saran
Informasi visual dapat dimanfaatkan untuk meningkatkan precision dan recall ekstraksi data records sekaligus mengurangi waktu komputasi sebagaimana ditunjukkan oleh Zhai dan Liu (2006)[1] Perlu dilakukan penyimpanan untuk pola data records aktual yang sudah ditemukan agar dapat digunakan dalam ekstraksi data records dari halaman web dengan encoding template yang sama tanpa harus mencari pola lagi..
Saran
Perlu diintegrasikan perkakas (tools) ekstraksi informasi berbasis pengolahan bahasa alami untuk meningkatkan nilai precision ekstraksi data records dan penjajaran data items, juga agar proses pelabelan kolom dapat dilakukan secara otomatis.
Referensi
Breuel, T. M., 2003, Information Extraction from HTML Documents by
Structural Matching, Proceedings of the 2nd International Workshop on Web
Document Analysis (WDA2003), Edinburgh, Scotland, UK.
Liu, B., 2007, Web Data Mining: Exploring Hyperlinks, Contents, and Usage
Data, Springer.
Yeonjung, K., Jeahyun, P., Taehwan, K., dan Joongmin, C., 2007, Web
Information Extraction by HTML Tree Edit Distance Matching, Proceedings
of the International Conference on Convergence Information Technology (ICCIT.2007).
Referensi
Zhai, Y. dan Liu, B., 2006, Structured Data Extraction from the Web Based
on Partial Tree Alignment, IEEE Transactions on Knowledge and Data Eengineering, Vol. 18, No. 12.