TESIS
PENDEKATAN LEVEL DATA DAN
ALGORITMA UNTUK PENANGANAN
KETIDAKSEIMBANGAN KELAS PADA
PREDIKSI CACAT SOFTWARE BERBASIS
NAΪVE BAYES
Oleh:
Aries Saifudin
3712101122
PROGRAM STUDI TEKNIK INFORMATIKA
PROGRAM PASCA SARJANA (S2) MAGISTER KOMPUTER
SEKOLAH TINGGI MANAJEMEN INFORMATIKA DAN KOMPUTER ERESHA
JAKARTA
ii
PERSETUJUAN TESIS
Nama : Aries Saifudin
NPM : 3712101122
Konsentrasi : Software Engineering
Judul tesis : Pendekatan Level Data dan Algoritma untuk Penanganan Ketidakseimbangan Kelas pada Prediksi Cacat Software Berbasis Naϊve Bayes
Telah disetujui untuk disidangkan pada Sidang Tesis pada Program Pasca Sarjana (S2) Magister Komputer, Program Studi Teknik Informatika Sekolah Tinggi Manajemen Informatika dan Komputer Eresha.
iii
PENGESAHAN TESIS
Nama : Aries Saifudin
NPM : 3712101122
Konsentrasi : Software Engineering
Judul tesis : Pendekatan Level Data dan Algoritma untuk Penanganan Ketidakseimbangan Kelas pada Prediksi Cacat Software Berbasis Naϊve Bayes
Telah disidangkan dan dinyatakan Lulus Sidang Tesis pada Program Pasca Sarjana (S2) Magister Komputer, Program Studi Teknik Informatika Sekolah Tinggi Manajemen Informatika dan Komputer Eresha pada tanggal (24-09-2014).
iv
PERNYATAAN KEASLIAN TESIS
Nama : Aries Saifudin
NPM : 3712101122
Konsentrasi : Software Engineering
Judul tesis : Pendekatan Level Data dan Algoritma untuk Penanganan Ketidakseimbangan Kelas pada Prediksi Cacat Software Berbasis Naϊve Bayes
Dengan ini saya menyatakan bahwa dalam Tesis ini tidak terdapat karya yang pernah diajukan untuk memperoleh gelar kesarjanaan di suatu Perguruan Tinggi, dan sepanjang pengetahuan saya juga tidak terdapat karya atau pendapat yang pernah ditulis atau diterbitkan oleh orang lain, kecuali yang secara tertulis diacu dalam naskah ini dan disebutkan dalam daftar pustaka.
v
Aries Saifudin, 3712101122
Pendekatan Level Data dan Algoritma untuk Penanganan
Ketidakseimbangan Kelas pada Prediksi Cacat Software Berbasis
Naϊve Bayes; di bawah bimbingan Romi Satria Wahono, B.Eng., M.Eng., PhD.
dan Dr. Rufman Iman Akbar E., M.M., M.Kom.276 + xxiv hal / 262 tabel / 55 gambar / 1 lampiran / 86 pustaka (2002 - 2014)
ABSTRAK
Memperbaiki software yang cacat setelah pengiriman membutuhkan biaya jauh lebih mahal dari pada selama pengembangan. Tetapi belum ada model prediksi cacat software yang berlaku umum. Naϊve Bayes merupakan model paling efektif dan efisien, tetapi belum dapat mengklasifikasikan dataset berbasis metrik dengan kinerja terbaik secara umum dan selalu konsisten dalam semua penelitian. Dataset dari software metrics secara umum bersifat tidak seimbang, hal ini dapat menurunkan kinerja model prediksi cacat software karena cenderung menghasilkan prediksi kelas mayoritas.
Untuk menangani ketidakseimbangan kelas secara umum dibagi menjadi dua pendekatan, yaitu pendekatan level data dan pendekatan level algoritma. Pendekatan level data ditujukan untuk memperbaiki keseimbangan kelas, dilakukan dengan resampling termasuk Random Over-Sampling (ROS) dan
Random Under-Sampling (RUS), atau mensintesis kelas minoritas menggunakan
algoritma FSMOTE (Fractal Synthetic Minority Over-sampling Technique), yaitu perbaikan dari algoritma SMOTE (Synthetic Minority Over-sampling Technique) dengan mengikuti interpolasi fraktal. Sedangkan pendekatan level algoritma ditujukan untuk membuat pengklasifikasi lebih konduktif terhadap kelas minoritas dengan menggabungkan (ensemble) pengklasifikasi tunggal agar menjadi lebih baik. Algoritma ensemble yang populer adalah boosting dan bagging. AdaBoost merupakan salah satu algoritma boosting yang telah menunjukkan dapat memperbaiki kinerja pengklasifikasi. Maka pada penelitian ini digunakan pendekatan level data menggunakan ROS, RUS, dan FSMOTE. Sedangkan pendekatan level algoritma menggunakan AdaBoost dan Bagging. Pengklasifikasi yang digunakan adalah Naϊve Bayes. Ada banyak developer dan organisasi yang mengerjakan proyek NASA, tetapi secara umum memiliki kemampuan yang sama dan cenderung membuat kesalahan yang serupa. Maka pada penelitian ini digunakan dataset dari NASA.
Hasil penelitian menunjukkan bahwa pendekatan level algoritma yang terbaik adalah Bagging. Pendekatan level data terbaik adalah FSMOTE. Ketika kedua pendekatan ini digabungkan, model yang menggabungkan FSMOTE, Bagging, dan Naϊve Bayes mengungguli akurasi semua model dalam mengklasifikasikan kelas minoritas.
Kata Kunci:
Ketidakseimbangan Kelas, Pendekatan Level Data, Pendekatan Level Algoritma, Prediksi Cacat Software
vi
Aries Saifudin, 3712101122
Data and Algorithms Level Approach for Handling Class
Imbalance on Software Defect Prediction Based on Bayes Naϊve;
under the supervision of Romi Satria Wahono, B.Eng., M.Eng., Ph.D. and Dr. Rufman Iman Akbar E., M.M., M.Kom.276 + xxiv pages / 262 tables / 55 figures / 1 attachment/ 86 references (2002 - 2014)
ABSTRACT
Fixing software defects after delivery costs much more expensive than during development. But there is no software defect prediction models that are commonly used. Naϊve Bayes is the most effective and efficient models, but have not been able to classify the dataset based metrics with best performance in general and always consistent in all studies. Generally software metrics dataset are imbalanced, it can degrade the performance of software defect prediction models because tend to generate predictions for the majority class.
To handle class imbalance is generally divided into two approaches, namely data level approach and algorithm level approach. Data level approach is intended to improve the balance of the class, which done by resampling including Random Over-Sampling (ROS) and Random Under-Sampling (RUS), or synthesize the minority class using FSMOTE (Fractal Synthetic Minority Over-sampling Technique) algorithm, which is improvement of SMOTE (Synthetic Minority Over-sampling Technique) algorithm by following the fractal interpolation. While the algorithm level approach is intended to make classifiers more conductive to the minority class. The algorithm level approach is done by combine (ensemble) single classifiers to make it better. A popular ensemble algorithm is boosting and bagging. AdaBoost is a boosting algorithm which has been shown to improve the performance of classifiers. So in this study used data level approach using ROS, RUS, and FSMOTE. While the algorithm level approach using AdaBoost and Bagging. The classifiers are used is Naϊve Bayes. There are many developers and organizations working on the NASA project, but generally have the same ability and tend to make similar mistakes. So in this study used a dataset from NASA.
The results show that the best algorithm level approach is Bagging. The best data level approach is FSMOTE. When these both approach are combined, model that combine FSMOTE, Bagging, and Naϊve Bayes outperformed the accuracy of classifying minority class than other models.
Keywords:
Class Imbalanced, Data Level Approach, Algorithm Level Approach, Software Defect Prediction
vii
KATA PENGANTAR
Dengan memanjatkan puji syukur kehadiran Tuhan Yang Maha Esa yang telah melimpahkan segala rahmat dan hidayahnya kepada penulis, sehingga tersusunlah tesis yang berjudul “Pendekatan Level Data dan Algoritma untuk Penanganan Ketidakseimbangan Kelas pada Prediksi Cacat Software Berbasis Naϊve Bayes“.
Tesis tersebut melengkapi salah satu persyaratan yang diajukan dalam rangka menempuh ujian akhir untuk memperoleh gelar Magister Komputer (M.Kom.) pada Program Pasca Sarjana (S2), Program Studi Teknik Informatika di Sekolah Tinggi Manajemen Informatika dan Komputer Eresha.
Penulis sungguh sangat menyadari, bahwa penulisan tesis ini tidak akan terwujud tanpa adanya dukungan dan bantuan dari perbagai pihak. Maka, dalam kesempatan ini penulis menghaturkan penghargaan dan ucapan terima kasih yang sebesar-besarnya kepada:
1. Bapak Ir. Damsiruddin Siregar, M.M.T., selaku Ketua STMIK Eresha. 2. Bapak Romi Satria Wahono, B.Eng., M.Eng., Ph.D. selaku Pembimbing
Utama dalam penelitian ini.
3. Bapak Dr. Rufman Iman Akbar E., MM., M.Kom. selaku Pembimbing Pendamping dalam penelitian ini.
4. Yulianti (isteriku) tercinta yang selalu mendo’akan dan memberikan dukungan dalam penyelesaian tesis ini.
Akhir kata penulis mohon maaf atas kekeliruan dan kesalahan yang terdapat dalam tesis ini dan berharap semoga tesis ini dapat memberikan manfaat bagi khasanah pengetahuan teknologi informasi di Indonesia.
viii
DAFTAR ISI
Hal.
HALAMAN JUDUL ... i
PERSETUJUAN TESIS ... ii
PENGESAHAN TESIS ... iii
PERNYATAAN KEASLIAN TESIS ... iv
ABSTRAK ... v
ABSTRACT ... vi
KATA PENGANTAR ... vii
DAFTAR ISI ... viii
DAFTAR TABEL ... xii
DAFTAR GAMBAR ... xxiii
DAFTAR LAMPIRAN ... xxvi
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Permasalahan Penelitian ... 6
1.2.1 Identifikasi Masalah ... 6
1.2.2 Ruang Lingkup Masalah ... 7
1.2.3 Rumusan Masalah ... 7
1.3 Tujuan dan Manfaat Penelitian ... 9
1.3.1 Tujuan Penelitian... 9
1.3.2 Manfaat Penelitian... 10
1.4 Hubungan antara Masalah, Rumusan, dan Tujuan Penelitian ... 11
1.5 Sistematika Penulisan ... 16
BAB II LANDASAN TEORI ... 17
2.1 Tinjauan Studi ... 17
ix
2.1.2 Model Penelitian Riquelme, Ruiz, Rodriguez, dan Moreno
(2008) ... 18
2.1.3 Model Penelitian Khoshgoftaar, Gao dan Seliya (2010) ... 19
2.1.4 Model Penelitian Wahono, Suryana, dan Ahmad (2014)... 21
2.1.5 Rangkuman Penelitian Terkait ... 23
2.2 Tinjauan Pustaka ... 26
2.2.1 Prediksi Cacat Software ... 26
2.2.2 Naϊve Bayes ... 36
2.2.3 Ketidakseimbangan Kelas (Class Imbalance)... 42
2.2.4 Pendekatan Level Data ... 44
2.2.5 Pendekatan Level Algoritma ... 54
2.2.6 Teknik Evaluasi dan Validasi ... 65
2.3 Kerangka Pemikiran Penelitian ... 71
BAB IIIMETODE PENELITIAN... 74
3.1 Analisa Kebutuhan ... 74
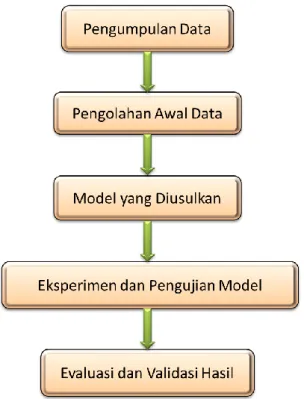
3.2 Metode Penelitian ... 74
3.2.1 Metode Pemilihan Data ... 77
3.2.2 Metode Pengumpulan Data ... 78
3.2.3 Metode Analisis Data ... 81
3.3 Perancangan Penelitian ... 91
3.3.1 Model yang Diusulkan ... 92
3.3.2 Class Diagram... 95
3.3.3 Antarmuka Pengguna ... 98
3.3.4 Pengukuran Kinerja ... 100
3.4 Teknik Analisis ... 101
3.4.1 Uji T (T Test) ... 102
x
3.4.3 Uji Peringkat Bertanda Wilcoxon (Wilcoxon Signed Rank Test) ... 105
3.4.4 Uji Friedman (Friedman Test) ... 106
3.4.5 Uji Konkordansi Kendall ... 106
3.4.6 Uji Post Hoc ... 107
BAB IVHASIL DAN PEMBAHASAN... 109
4.1 Hasil ... 109
4.1.1 Hasil Pengembangan Aplikasi ... 109
4.1.2 Hasil Pengukuran Kinerja Model ... 133
4.2 Pembahasan ... 145
4.2.1 Meningkatkan Kinerja Pengklasifikasi (Naϊve Bayes) pada Model Prediksi Cacat Software ... 145
4.2.2 Pendekatan Level Algoritma (Ensemble) ... 149
4.2.3 Pendekatan Level Data ... 182
4.2.4 Integrasi Pendekatan Level Data dan Level Algoritma ... 200
4.2.5 Pendekatan Terbaik ... 244
4.2.6 Model Terbaik ... 255
BAB V KESIMPULAN DAN SARAN... 278
5.1 Kesimpulan ... 278
5.1.1 Kesimpulan Terkait Tujuan Penelitian RO1 ... 281
5.1.2 Kesimpulan Terkait Tujuan Penelitian RO2.1 ... 282
5.1.3 Kesimpulan Terkait Tujuan Penelitian RO2.2 ... 282
5.1.4 Kesimpulan Terkait Tujuan Penelitian RO2.3 ... 283
5.1.5 Kesimpulan Terkait Tujuan Penelitian RO3.1 ... 284
5.1.6 Kesimpulan Terkait Tujuan Penelitian RO3.2 ... 284
5.1.7 Kesimpulan Terkait Tujuan Penelitian RO3.3 ... 285
5.1.8 Kesimpulan Terkait Tujuan Penelitian RO3.4 ... 285
xi
5.1.10Kesimpulan Terkait Tujuan Penelitian RO4.2 ... 286
5.1.11Kesimpulan Terkait Tujuan Penelitian RO4.3 ... 287
5.1.12Kesimpulan Terkait Tujuan Penelitian RO4.4 ... 287
5.1.13Kesimpulan Terkait Tujuan Penelitian RO4.5 ... 288
5.1.14Kesimpulan Terkait Tujuan Penelitian RO4.6 ... 289
5.1.15Kesimpulan Terkait Tujuan Penelitian RO4.7 ... 289
5.1.16Kesimpulan Terkait Tujuan Penelitian RO5 ... 290
5.1.17Kesimpulan Terkait Tujuan Penelitian RO6 ... 290
5.2 Saran ... 291
REFERENSI ... 293
LAMPIRAN-LAMPIRAN ... 302
xii
DAFTAR TABEL
Hal
Tabel 1.1 Hubungan antara Masalah, Rumusan dan Tujuan Penelitian ... 12
Tabel 1.2 Hubungan antara Masalah, Rumusan dan Tujuan Penelitian (Lanjutan) ... 13
Tabel 1.3 Hubungan antara Masalah, Rumusan, dan Tujuan Penelitian (Lanjutan) ... 14
Tabel 1.4 Hubungan antara Masalah, Rumusan dan Tujuan Penelitian (Lanjutan) ... 15
Tabel 2.1 Rangkuman Penelitian Terkait dengan Pendekatan Level Data ... 24
Tabel 2.2 Rangkuman Penelitian Terkait dengan Pendekatan Level Data dan Level Algoritma ... 25
Tabel 2.3 Contoh Umum Cacat Software ... 26
Tabel 2.4 Contoh Nyata Cacat Software ... 27
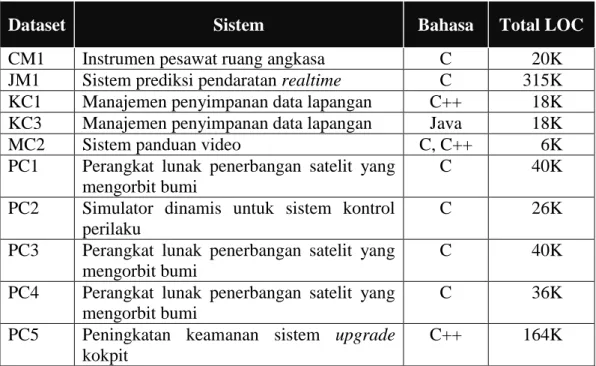
Tabel 2.5 Dekripsi Dataset NASA ... 33
Tabel 2.6 Spesifikasi Dataset NASA MDP Repository Asli (DS) ... 34
Tabel 2.7 Spesifikasi Dataset NASA MDP Repository Transformasi Pertama (DS') ... 34
Tabel 2.8 Spesifikasi Dataset NASA MDP Repository Transformasi Kedua (DS'') ... 35
Tabel 2.9 Spesifikasi Dataset PROMISE Repository Asli (DS) ... 35
Tabel 2.10 Spesifikasi Dataset PROMISE Repository Transformasi Pertama (DS') ... 36
Tabel 2.11 Spesifikasi Dataset PROMISE Repository Transformasi Kedua (DS'') ... 36
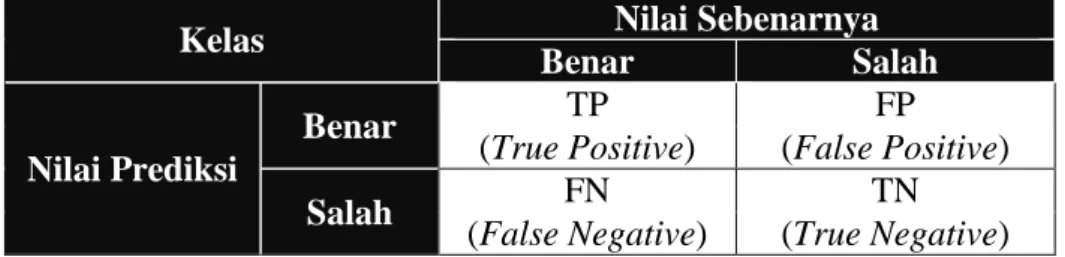
Tabel 2.12 Confusion Matrix ... 68
Tabel 3.1 Spesifikasi dan Atribut NASA MDP Repository (Original) ... 79
Tabel 3.2 Spesifikasi dan Atribut PROMISE Repository (Original) ... 80
Tabel 3.3 Spesifikasi dan Atribut PROMISE Repository (Original) (Lanjutan) ... 81
Tabel 3.4 Spesifikasi dan Atribut NASA MDP repository (D') ... 86
xiii
Tabel 3.6 Spesifikasi dan Atribut PROMISE repository (D') ... 88
Tabel 3.7 Spesifikasi dan Atribut PROMISE repository (D') (Lanjutan) ... 89
Tabel 3.8 Spesifikasi dan Atribut PROMISE repository (D'') ... 90
Tabel 3.9 Spesifikasi dan Atribut PROMISE repository (D'') (Lanjutan) ... 91
Tabel 3.10 Klasifikasi Keakuratan Pengujian Diagnostik ... 101
Tabel 4.1 Dataset untuk Menguji Aplikasi ... 110
Tabel 4.2 Dataset untuk Menguji Aplikasi Setelah Standardisasi ... 111
Tabel 4.3 Rekap Penghitungan Mean dan Standar Deviasi Bagian (Split) ke-1 .. 116
Tabel 4.4 Rekap Penghitungan Mean dan Standar Deviasi Bagian (Split) ke-2 .. 119
Tabel 4.5 Rekap Penghitungan Mean dan Standar Deviasi Bagian (Split) ke-3 .. 120
Tabel 4.6 Rekap Penghitungan Mean dan Standar Deviasi Bagian (Split) ke-4 .. 121
Tabel 4.7 Rekap Penghitungan Mean dan Standar Deviasi Bagian (Split) ke-5 .. 123
Tabel 4.8 Rekap Penghitungan Mean dan Standar Deviasi Bagian (Split) ke-6 .. 124
Tabel 4.9 Rekap Penghitungan Mean dan Standar Deviasi Bagian (Split) ke-7 .. 125
Tabel 4.10 Rekap Penghitungan Mean dan Standar Deviasi Bagian (Split) ke-8 ... 127
Tabel 4.11 Rekap Penghitungan Mean dan Standar Deviasi Bagian (Split) ke-9 ... 128
Tabel 4.12 Rekap Penghitungan Mean dan Standar Deviasi Bagian (Split) ke-10 ... 129
Tabel 4.13 Rekapitulasi Penghitungan Manual untuk Model Naïve Bayes... 131
Tabel 4.14 Hasil Klasifikasi Penghitungan Manual dengan 10-Fold Cross Validation ... 131
Tabel 4.15 Hasil Pengukuran Penerapan Dataset CM1 dari NASA MDP Repository ... 134
Tabel 4.16 Hasil Pengukuran Penerapan Dataset JM1 dari NASA MDP Repository ... 135
Tabel 4.17 Hasil Pengukuran Penerapan Dataset KC1 dari NASA MDP Repository ... 135
Tabel 4.18 Hasil Pengukuran Penerapan Dataset KC3 dari NASA MDP Repository ... 135
Tabel 4.19 Hasil Pengukuran Penerapan Dataset MC2 dari NASA MDP Repository ... 136
xiv
Tabel 4.20 Hasil Pengukuran Penerapan Dataset PC1 dari NASA MDP
Repository ... 136
Tabel 4.21 Hasil Pengukuran Penerapan Dataset PC2 dari NASA MDP
Repository ... 136
Tabel 4.22 Hasil Pengukuran Penerapan Dataset PC3 dari NASA MDP
Repository ... 137
Tabel 4.23 Hasil Pengukuran Penerapan Dataset PC4 dari NASA MDP
Repository ... 137
Tabel 4.24 Hasil Pengukuran Penerapan Dataset PC5 dari NASA MDP
Repository ... 137
Tabel 4.25 Hasil Pengukuran Penerapan Dataset CM1 dari PROMISE
Repository ... 138
Tabel 4.26 Hasil Pengukuran Penerapan Dataset JM1 dari PROMISE
Repository ... 138
Tabel 4.27 Hasil Pengukuran Penerapan Dataset KC1 dari PROMISE
Repository ... 138
Tabel 4.28 Hasil Pengukuran Penerapan Dataset KC3 dari PROMISE
Repository ... 139
Tabel 4.29 Hasil Pengukuran Penerapan Dataset MC2 dari PROMISE
Repository ... 139
Tabel 4.30 Hasil Pengukuran Penerapan Dataset PC1 dari PROMISE
Repository ... 139
Tabel 4.31 Hasil Pengukuran Penerapan Dataset PC2 dari PROMISE
Repository ... 140
Tabel 4.32 Hasil Pengukuran Penerapan Dataset PC3 dari PROMISE
Repository ... 140
Tabel 4.33 Hasil Pengukuran Penerapan Dataset PC4 dari PROMISE
Repository ... 140
Tabel 4.34 Hasil Pengukuran Penerapan Dataset PC5 dari PROMISE
Repository ... 141
Tabel 4.35 Rekap Pengukuran Akurasi Model pada NASA MDP Repository .... 141 Tabel 4.36 Rekap Pengukuran Akurasi Model pada PROMISE Repository ... 141 Tabel 4.37 Rekap Pengukuran Sensitivitas Model pada NASA MDP
xv
Tabel 4.38 Rekap Pengukuran Sensitivitas Model pada PROMISE Repository . 142 Tabel 4.39 Rekap Pengukuran F-Measure Model pada NASA MDP
Repository ... 142
Tabel 4.40 Rekap Pengukuran F-Measure Model pada PROMISE Repository .. 143
Tabel 4.41 Rekap Pengukuran G-Mean Model pada NASA MDP Repository ... 143
Tabel 4.42 Rekap Pengukuran G-Mean Model pada PROMISE Repository ... 144
Tabel 4.43 Rekap Pengukuran AUC Model pada NASA MDP Repository ... 144
Tabel 4.44 Rekap Pengukuran AUC Model pada PROMISE Repository ... 144
Tabel 4.45 Uji T (T-Test) Sampel Berpasangan Akurasi Model NB dan AB+NB ... 150
Tabel 4.46 Uji T (T-Test) Sampel Berpasangan Sensitivitas Model NB dan AB+NB ... 150
Tabel 4.47 Uji T (T-Test) Sampel Berpasangan F-Measure Model NB dan AB+NB ... 151
Tabel 4.48 Uji T (T-Test) Sampel Berpasangan G-Mean Model NB dan AB+NB ... 151
Tabel 4.49 Uji T (T-Test) Sampel Berpasangan AUC Model NB dan AB+NB .. 152
Tabel 4.50 Rekap Uji T untuk Model NB dan AB+NB ... 152
Tabel 4.51 Frekuensi Pengukuran Akurasi pada Uji Tanda ... 153
Tabel 4.52 Uji Tanda Pengukuran Akurasi ... 153
Tabel 4.53 Frekuensi Pengukuran Sensitivitas pada Uji Tanda ... 153
Tabel 4.54 Uji Tanda Pengukuran Sensitivitas ... 154
Tabel 4.55 Frekuensi Pengukuran F-Measure pada Uji Tanda ... 154
Tabel 4.56 Uji Tanda Pengukuran F-Measure ... 154
Tabel 4.57 Frekuensi Pengukuran G-Mean pada Uji Tanda ... 155
Tabel 4.58 Uji Tanda Pengukuran G-Mean ... 155
Tabel 4.59 Frekuensi Pengukuran AUC pada Uji Tanda ... 156
Tabel 4.60 Uji Tanda Pengukuran AUC ... 156
Tabel 4.61 Rekap Uji Tanda untuk Model NB dan AB+NB ... 156
Tabel 4.62 Peringkat Pengukuran Akurasi pada Uji Peringkat Bertanda Wilcoxon ... 157
Tabel 4.63 Uji Peringkat Bertanda Wilcoxon Pengukuran Akurasi ... 157
Tabel 4.64 Peringkat Pengukuran Sensitivitas pada Uji Peringkat Bertanda Wilcoxon ... 158
xvi
Tabel 4.65 Uji Peringkat Bertanda Wilcoxon Pengukuran Sensitivitas ... 158
Tabel 4.66 Peringkat Pengukuran F-Measure pada Uji Peringkat Bertanda Wilcoxon ... 158
Tabel 4.67 Uji Peringkat Bertanda Wilcoxon Pengukuran F-Measure... 159
Tabel 4.68 Peringkat Pengukuran G-Mean pada Uji Peringkat Bertanda Wilcoxon ... 159
Tabel 4.69 Uji Peringkat Bertanda Wilcoxon Pengukuran G-Mean... 159
Tabel 4.70 Peringkat Pengukuran AUC pada Uji Peringkat Bertanda Wilcoxon ... 160
Tabel 4.71 Uji Peringkat Bertanda Wilcoxon Pengukuran AUC ... 160
Tabel 4.72 Rekap Uji Peringkat Bertanda Wilcoxon untuk Model NB dan AB+NB ... 161
Tabel 4.73 Peringkat Pengukuran Akurasi pada Uji Friedman... 161
Tabel 4.74 Uji Friedman Pengukuran Akurasi ... 162
Tabel 4.75 Peringkat Pengukuran Sensitivitas pada Uji Friedman ... 162
Tabel 4.76 Uji Friedman Pengukuran Sensitivitas ... 162
Tabel 4.77 Peringkat Pengukuran F-Measure pada Uji Friedman ... 162
Tabel 4.78 Uji Friedman Pengukuran F-Measure ... 162
Tabel 4.79 Peringkat Pengukuran G-Mean pada Uji Friedman ... 163
Tabel 4.80 Uji Friedman Pengukuran G-Mean ... 163
Tabel 4.81 Peringkat Pengukuran AUC pada Uji Friedman ... 163
Tabel 4.82 Uji Friedman Pengukuran AUC ... 163
Tabel 4.83 Rekap Uji Friedman untuk Model NB dan AB+NB ... 164
Tabel 4.84 Peringkat Pengukuran Akurasi pada Uji Konkordansi Kendall... 164
Tabel 4.85 Uji Konkordansi Kendall Pengukuran Akurasi ... 164
Tabel 4.86 Peringkat Pengukuran Sensitivitas pada Uji Konkordansi Kendall ... 165
Tabel 4.87 Uji Konkordansi Kendall Pengukuran Sensitivitas ... 165
Tabel 4.88 Peringkat Pengukuran F-Measure pada Uji Konkordansi Kendall .... 165
Tabel 4.89 Uji Konkordansi Kendall Pengukuran F-Measure ... 165
Tabel 4.90 Peringkat Pengukuran G-Mean pada Uji Konkordansi Kendall ... 166
Tabel 4.91 Uji Konkordansi Kendall Pengukuran G-Mean ... 166
Tabel 4.92 Peringkat Pengukuran UAC pada Uji Konkordansi Kendall ... 166
Tabel 4.93 Uji Konkordansi Kendall Pengukuran AUC ... 166
xvii
Tabel 4.95 Rekap Uji Statistik ... 167
Tabel 4.96 Rekap Uji T untuk Model NB dan BG+NB ... 168
Tabel 4.97 Rekap Uji Tanda untuk Model NB dan BG+NB ... 169
Tabel 4.98 Rekap Uji Peringkat Bertanda Wilcoxon untuk Model NB dan BG+NB ... 169
Tabel 4.99 Rekap Uji Friedman untuk Model NB dan BG+NB ... 170
Tabel 4.100 Rekap Uji Konkordansi Kendall untuk Model NB dan BG+NB ... 170
Tabel 4.101 Rekap Uji Statistik ... 171
Tabel 4.102 Rekap P-Value pada Uji Friedman untuk Model yang Mengintegrasikan Pendekatan Level Algoritma ... 172
Tabel 4.103 Hasil Pengukuran Nilai Akurasi Model NB, AB+NB, dan BG+NB ... 173
Tabel 4.104 Peringkat Akurasi Model pada Uji Friedman ... 174
Tabel 4.105 Perbandingan Berpasangan pada Nemenyi Post Hoc ... 174
Tabel 4.106 P-value pada Nemenyi Post Hoc ... 175
Tabel 4.107 Perbedaan Signifikan pada Nemenyi Post Hoc... 175
Tabel 4.108 Hasil Pengukuran Nilai Sensitivitas Model NB, AB+NB, dan BG+NB ... 176
Tabel 4.109 Peringkat Sensitivitas Model pada Uji Friedman ... 177
Tabel 4.110 Perbandingan Berpasangan pada Nemenyi Post Hoc ... 177
Tabel 4.111 P-value pada Nemenyi Post Hoc ... 178
Tabel 4.112 Perbedaan Signifikan pada Nemenyi Post Hoc... 178
Tabel 4.113 Hasil Pengukuran Nilai G-Mean Model ... 179
Tabel 4.114 Peringkat G-Mean Model pada Uji Friedman... 180
Tabel 4.115 Perbandingan Berpasangan pada Nemenyi Post Hoc ... 180
Tabel 4.116 P-value pada Nemenyi Post Hoc ... 181
Tabel 4.117 Perbedaan Signifikan pada Nemenyi Post Hoc... 181
Tabel 4.118 Rekap Uji T untuk Model NB dan ROS+NB ... 182
Tabel 4.119 Rekap Uji Tanda untuk Model NB dan ROS+NB ... 183
Tabel 4.120 Rekap Uji Peringkat Bertanda Wilcoxon untuk Model NB dan ROS+NB ... 183
Tabel 4.121 Rekap Uji Friedman untuk Model NB dan ROS+NB ... 184
Tabel 4.122 Rekap Uji Konkordansi Kendall untuk Model NB dan ROS+NB .. 184
xviii
Tabel 4.124 Rekap Uji T untuk Model NB dan RUS+NB ... 186
Tabel 4.125 Rekap Uji Tanda untuk Model NB dan RUS+NB ... 186
Tabel 4.126 Rekap Uji Peringkat Bertanda Wilcoxon untuk Model NB dan RUS+NB ... 187
Tabel 4.127 Rekap Uji Friedman untuk Model NB dan RUS+NB ... 187
Tabel 4.128 Rekap Uji Konkordansi Kendall untuk Model NB dan RUS+NB .. 188
Tabel 4.129 Rekap Uji Statistik ... 188
Tabel 4.130 Rekap Uji T untuk Model NB dan FSMOTE+NB ... 189
Tabel 4.131 Rekap Uji Tanda untuk Model NB dan FSMOTE+NB ... 190
Tabel 4.132 Rekap Uji Peringkat Bertanda Wilcoxon untuk Model NB dan FSMOTE+NB ... 190
Tabel 4.133 Rekap Uji Friedman untuk Model NB dan FSMOTE+NB ... 191
Tabel 4.134 Rekap Uji Konkordansi Kendall untuk Model NB dan FSMOTE+NB ... 191
Tabel 4.135 Rekap Uji Statistik ... 192
Tabel 4.136 Rekap P-Value pada Uji Friedman untuk Model yang Mengintegrasikan Pendekatan Level Data ... 193
Tabel 4.137 Hasil Pengukuran Nilai Sensitivitas Model ... 194
Tabel 4.138 Peringkat Sensitivitas Model pada Uji Friedman ... 195
Tabel 4.139 Perbandingan Berpasangan pada Nemenyi Post Hoc ... 195
Tabel 4.140 P-value pada Nemenyi Post Hoc ... 196
Tabel 4.141 Perbedaan Signifikan pada Nemenyi Post Hoc... 196
Tabel 4.142 Hasil Pengukuran Nilai G-Mean Model ... 197
Tabel 4.143 Peringkat G-Mean Model pada Uji Friedman... 198
Tabel 4.144 Perbandingan Berpasangan pada Nemenyi Post Hoc ... 198
Tabel 4.145 P-value pada Nemenyi Post Hoc ... 199
Tabel 4.146 Perbedaan Signifikan pada Nemenyi Post Hoc... 199
Tabel 4.147 Rekap Uji T untuk Model NB dan ROS+AB+NB ... 201
Tabel 4.148 Rekap Uji Tanda untuk Model NB dan ROS+AB+NB ... 201
Tabel 4.149 Rekap Uji Peringkat Bertanda Wilcoxon untuk Model NB dan ROS+AB+NB ... 202
Tabel 4.150 Rekap Uji Friedman untuk Model NB dan ROS+AB+NB ... 202
Tabel 4.151 Rekap Uji Konkordansi Kendall untuk Model NB dan ROS+AB+NB ... 203
xix
Tabel 4.152 Rekap Uji Statistik ... 203
Tabel 4.153 Rekap Uji T untuk Model NB dan RUS+AB+NB ... 204
Tabel 4.154 Rekap Uji Tanda untuk Model NB dan RUS+AB+NB ... 205
Tabel 4.155 Rekap Uji Peringkat Bertanda Wilcoxon untuk Model NB dan RUS+AB+NB ... 205
Tabel 4.156 Rekap Uji Friedman untuk Model NB dan RUS+AB+NB ... 206
Tabel 4.157 Rekap Uji Konkordansi Kendall untuk Model NB dan RUS+AB+NB ... 206
Tabel 4.158 Rekap Uji Statistik ... 207
Tabel 4.159 Rekap Uji T untuk Model NB dan FSMOTE+AB+NB ... 208
Tabel 4.160 Rekap Uji Tanda untuk Model NB dan FSMOTE+AB+NB ... 208
Tabel 4.161 Rekap Uji Peringkat Bertanda Wilcoxon untuk Model NB dan FSMOTE+AB+NB ... 209
Tabel 4.162 Rekap Uji Friedman untuk Model NB dan FSMOTE+AB+NB ... 209
Tabel 4.163 Rekap Uji Konkordansi Kendall untuk Model NB dan FSMOTE+AB+NB ... 210
Tabel 4.164 Rekap Uji Statistik ... 210
Tabel 4.165 Rekap Uji T untuk Model NB dan ROS+BG+NB ... 212
Tabel 4.166 Rekap Uji Tanda untuk Model NB dan ROS+BG+NB ... 212
Tabel 4.167 Rekap Uji Peringkat Bertanda Wilcoxon untuk Model NB dan ROS+BG+NB ... 213
Tabel 4.168 Rekap Uji Friedman untuk Model NB dan ROS+BG+NB ... 213
Tabel 4.169 Rekap Uji Konkordansi Kendall untuk Model NB dan ROS+BG+NB ... 214
Tabel 4.170 Rekap Uji Statistik ... 214
Tabel 4.171 Rekap Uji T untuk Model NB dan RUS+BG+NB ... 215
Tabel 4.172 Rekap Uji Tanda untuk Model NB dan RUS+BG+NB ... 216
Tabel 4.173 Rekap Uji Peringkat Bertanda Wilcoxon untuk Model NB dan RUS+BG+NB ... 216
Tabel 4.174 Rekap Uji Friedman untuk Model NB dan RUS+BG+NB ... 217
Tabel 4.175 Rekap Uji Konkordansi Kendall untuk Model NB dan RUS+BG+NB ... 217
Tabel 4.176 Rekap Uji Statistik ... 218
xx
Tabel 4.178 Rekap Uji Tanda untuk Model NB dan FSMOTE+BG+NB ... 219
Tabel 4.179 Rekap Uji Peringkat Bertanda Wilcoxon untuk Model NB dan FSMOTE+BG+NB ... 220
Tabel 4.180 Rekap Uji Friedman untuk Model NB dan FSMOTE+BG+NB ... 220
Tabel 4.181 Rekap Uji Konkordansi Kendall untuk Model NB dan FSMOTE+BG+NB ... 221
Tabel 4.182 Rekap Uji Statistik ... 221
Tabel 4.183 Rekap P-Value pada Uji Friedman untuk Model yang Mengintegrasikan Pendekatan Level Data dan Level Algoritma ... 223
Tabel 4.184 Hasil Pengukuran Akurasi Model ... 224
Tabel 4.185 Peringkat Akurasi Model pada Uji Friedman ... 225
Tabel 4.186 Perbandingan Berpasangan pada Nemenyi Post Hoc ... 226
Tabel 4.187 P-value pada Nemenyi Post Hoc ... 226
Tabel 4.188 Perbedaan Signifikan pada Nemenyi Post Hoc... 227
Tabel 4.189 Hasil Pengukuran Nilai Sensitivitas Model ... 228
Tabel 4.190 Peringkat Sensitivitas Model pada Uji Friedman ... 229
Tabel 4.191 Perbandingan Berpasangan pada Nemenyi Post Hoc ... 230
Tabel 4.192 P-value pada Nemenyi Post Hoc ... 230
Tabel 4.193 Perbedaan Signifikan pada Nemenyi Post Hoc... 231
Tabel 4.194 Hasil Pengukuran Nilai F-Measure Model ... 232
Tabel 4.195 Peringkat F-Measure Model pada Uji Friedman... 233
Tabel 4.196 Perbandingan Berpasangan pada Nemenyi Post Hoc ... 234
Tabel 4.197 P-value pada Nemenyi Post Hoc ... 234
Tabel 4.198 Perbedaan Signifikan pada Nemenyi Post Hoc... 235
Tabel 4.199 Hasil Pengukuran Nilai G-Mean Model ... 236
Tabel 4.200 Peringkat G-Mean Model pada Uji Friedman... 237
Tabel 4.201 Perbandingan Berpasangan pada Nemenyi Post Hoc ... 238
Tabel 4.202 P-value pada Nemenyi Post Hoc ... 238
Tabel 4.203 Perbedaan Signifikan pada Nemenyi Post Hoc... 239
Tabel 4.204 Hasil Pengukuran Nilai AUC Model ... 240
Tabel 4.205 Peringkat AUC Model pada Uji Friedman ... 241
Tabel 4.206 Perbandingan Berpasangan pada Nemenyi Post Hoc ... 242
Tabel 4.207 P-value pada Nemenyi Post Hoc ... 242
xxi
Tabel 4.209 Rekap P-Value pada Uji Friedman untuk Model NB, BG+NB,
dan FSMOTE+NB ... 244
Tabel 4.210 Hasil Pengukuran Nilai Sensitivitas Model NB, BG+NB, dan FSMOTE+NB ... 245
Tabel 4.211 Peringkat Sensitivitas Model NB, BG+NB, dan FSMOTE+NB pada Uji Friedman ... 247
Tabel 4.212 Perbandingan Berpasangan pada Nemenyi Post Hoc ... 247
Tabel 4.213 P-value pada Nemenyi Post Hoc ... 248
Tabel 4.214 Perbedaan Signifikan pada Nemenyi Post Hoc... 248
Tabel 4.215 Hasil Pengukuran Nilai G-Mean Model NB, BG+NB, dan FSMOTE+NB ... 249
Tabel 4.216 Peringkat G-Mean Model NB, BG+NB, dan FSMOTE+NB pada Uji Friedman ... 250
Tabel 4.217 Perbandingan Berpasangan pada Nemenyi Post Hoc ... 250
Tabel 4.218 P-value pada Nemenyi Post Hoc ... 251
Tabel 4.219 Perbedaan Signifikan pada Nemenyi Post Hoc... 251
Tabel 4.220 Hasil Pengukuran Nilai AUC Model NB, BG+NB, dan FSMOTE+NB ... 252
Tabel 4.221 Peringkat AUC Model NB, BG+NB, dan FSMOTE+NB pada Uji Friedman ... 253
Tabel 4.222 Perbandingan Berpasangan pada Nemenyi Post Hoc ... 253
Tabel 4.223 P-value pada Nemenyi Post Hoc ... 254
Tabel 4.224 Perbedaan Signifikan pada Nemenyi Post Hoc... 254
Tabel 4.225 Rekap P-Value pada Uji Friedman untuk Semua Model ... 255
Tabel 4.226 Hasil Pengukuran Akurasi Model ... 256
Tabel 4.227 Peringkat Akurasi Model pada Uji Friedman ... 258
Tabel 4.228 Perbandingan Berpasangan pada Nemenyi Post Hoc ... 259
Tabel 4.229 P-value pada Nemenyi Post Hoc ... 259
Tabel 4.230 Perbedaan Signifikan pada Nemenyi Post Hoc... 260
Tabel 4.231 Hasil Pengukuran Nilai Sensitivitas Model ... 261
Tabel 4.232 Peringkat Sensitivitas Model pada Uji Friedman ... 262
Tabel 4.233 Perbandingan Berpasangan pada Nemenyi Post Hoc ... 263
Tabel 4.234 P-value pada Nemenyi Post Hoc ... 263
xxii
Tabel 4.236 Hasil Pengukuran Nilai F-Measure Model ... 265 Tabel 4.237 Peringkat F-Measure Model pada Uji Friedman... 266 Tabel 4.238 Perbandingan Berpasangan pada Nemenyi Post Hoc ... 267 Tabel 4.239 P-value pada Nemenyi Post Hoc ... 267 Tabel 4.240 Perbedaan Signifikan pada Nemenyi Post Hoc... 268 Tabel 4.241 Hasil Pengukuran Nilai G-Mean Model ... 269 Tabel 4.242 Peringkat G-Mean Model pada Uji Friedman... 270 Tabel 4.243 Perbandingan Berpasangan pada Nemenyi Post Hoc ... 271 Tabel 4.244 P-value pada Nemenyi Post Hoc ... 271 Tabel 4.245 Perbedaan Signifikan pada Nemenyi Post Hoc... 272 Tabel 4.246 Hasil Pengukuran Nilai AUC Model ... 273 Tabel 4.247 Peringkat AUC Model pada Uji Friedman ... 274 Tabel 4.248 Perbandingan Berpasangan pada Nemenyi Post Hoc ... 275 Tabel 4.249 P-value pada Nemenyi Post Hoc ... 275 Tabel 4.250 Perbedaan Signifikan pada Nemenyi Post Hoc... 276
xxiii
DAFTAR GAMBAR
Hal Gambar 2.1 Model yang Diusulkan Pelayo dan Dick (2007) ... 18 Gambar 2.2 Model yang Diusulkan Riquelme, Ruiz, Rodriguez, dan Moreno
(2008) ... 19 Gambar 2.3 Model yang Diusulkan Khoshgoftaar, Gao dan Seliya (2010) ... 21 Gambar 2.4 Model yang Diusulkan Wahono, Suryana, dan Ahmad (2014) ... 22 Gambar 2.5 Model Pencegahan Cacat Software ... 28 Gambar 2.6 Contoh Kode Sumber Program Java ... 30 Gambar 2.7 Model Grafis untuk Klasifikasi ... 37 Gambar 2.8 Model Grafis Naϊve Bayes dengan Asumsi Masukan Bebas ... 38 Gambar 2.9 Flowchart Algoritma Naïve Bayes ... 42 Gambar 2.10 Flowchart Algoritma ROS (Random Over-Sampling)... 46 Gambar 2.11 Flowchart Algoritma RUS (Random Under-Sampling) ... 47 Gambar 2.12 Ilustrasi Sintesis Sampel SMOTE ... 49 Gambar 2.13 Ilustrasi Sintesis Sampel FSMOTE ... 49 Gambar 2.14 Flowchart Algoritma Utama FSMOTE ... 51 Gambar 2.15 Flowchart Algoritma Sistesis FSMOTE ... 52 Gambar 2.16 Flowchart Algoritma AdaBoost Berbasis Naïve Bayes ... 61 Gambar 2.17 Flowchart Algoritma Bagging Berbasis Naïve Bayes ... 64 Gambar 2.18 Pembagian Dataset untuk 10-Fold Cross Validation ... 67 Gambar 2.19 Kerangka Pemikiran Penelitian ... 72 Gambar 3.1 Tahapan Penelitian ... 75 Gambar 3.2 Flowchart Model yang Diusulkan ... 93 Gambar 3.3 Kerangka Kerja Model yang Diusulkan ... 94 Gambar 3.4 Class Diagram Aplikasi Prediksi Cacat Software ... 95 Gambar 3.5 Class Diagram Paket Model ... 96 Gambar 3.6 Class Diagram Paket View ... 97 Gambar 3.7 Class Diagram Paket Controller ... 98 Gambar 3.8 Class Diagram Paket Softwaredefectprediction ... 98 Gambar 3.9 Antarmuka Aplikasi untuk Mengukur Kinerja Model ... 99 Gambar 3.10 Antarmuka Hasil Pengukuran Kinerja Semua Model ... 100
xxiv
Gambar 4.1 Tampilan Aplikasi untuk Pengukuran Kinerja Model Naïve
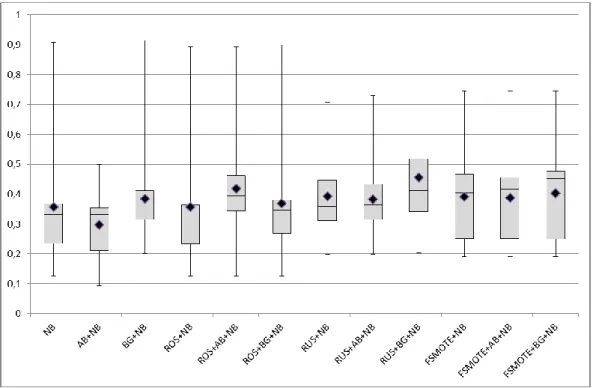
Bayes ... 133 Gambar 4.2 Diagram Perbandingan Akurasi Model Prediksi Cacat Software .... 145 Gambar 4.3 Diagram Perbandingan Sensitivitas Model Prediksi Cacat
Software ... 146 Gambar 4.4 Diagram Perbandingan F-Measure Model Prediksi Cacat
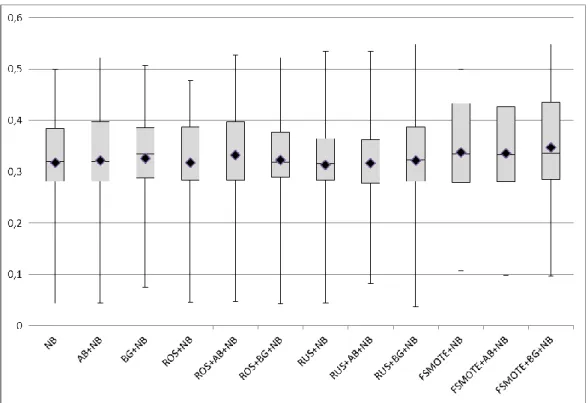
Software ... 147 Gambar 4.5 Diagram Perbandingan G-Mean Model Prediksi Cacat Software ... 148 Gambar 4.6 Diagram Perbandingan AUC Model Prediksi Cacat Software ... 149 Gambar 4.7 Perbandingan Akurasi Model Menggunakan Diagram Demsar ... 175 Gambar 4.8 Perbandingan Sensitivitas Model Menggunakan Diagram
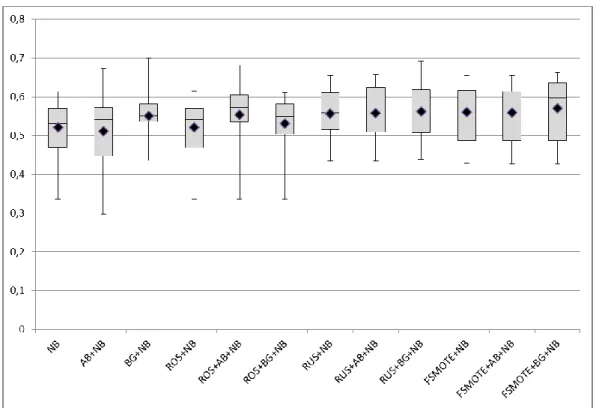
Demsar ... 178 Gambar 4.10 Perbandingan G-Mean Model Menggunakan Diagram Demsar .... 181 Gambar 4.11 Perbandingan Sensitivitas Model Menggunakan Diagram
Demsar ... 196 Gambar 4.12 Perbandingan G-Mean Model Menggunakan Diagram Demsar .... 199 Gambar 4.13 Perbandingan Akurasi Model Menggunakan Diagram Demsar .... 227 Gambar 4.14 Perbandingan Sensitivitas Model Menggunakan Diagram
Demsar ... 231 Gambar 4.15 Perbandingan F-Measure Model Menggunakan Diagram
Demsar ... 235 Gambar 4.16 Perbandingan G-Mean Model Menggunakan Diagram Demsar .... 239 Gambar 4.17 Perbandingan AUC Model Menggunakan Diagram Demsar ... 243 Gambar 4.19 Perbandingan Sensitivitas Model NB, BG+NB, dan
FSMOTE+NB Menggunakan Diagram Demsar ... 248 Gambar 4.20 Perbandingan G-Mean Model NB, BG+NB, dan FSMOTE+NB
Menggunakan Diagram Demsar ... 251 Gambar 4.21 Perbandingan AUC Model NB, BG+NB, dan FSMOTE+NB
Menggunakan Diagram ... 254 Gambar 4.22 Perbandingan Akurasi Model Menggunakan Diagram Demsar .... 260 Gambar 4.23 Perbandingan Sensitivitas Model Menggunakan Diagram
Demsar ... 264 Gambar 4.24 Perbandingan F-Measure Model Menggunakan Diagram
xxv
Gambar 4.25 Perbandingan G-Mean Model Menggunakan Diagram Demsar .... 272 Gambar 4.26 Perbandingan AUC Model Menggunakan Diagram Demsar ... 276
xxvi
DAFTAR LAMPIRAN
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Kualitas software biasanya diukur dari jumlah cacat yang ada pada produk yang dihasilkan (Turhan & Bener, Software Defect Prediction: Heuristics for Weighted Naive Bayes, 2007, p. 244). Cacat adalah kontributor utama untuk limbah teknologi informasi dan menyebabkan pengerjaan ulang proyek secara signifikan, keterlambatan, dan biaya lebih berjalan (Anantula & Chamarthi, 2011). Potensi cacat tertinggi terjadi pada tahap pengkodean sebesar 1,75 cacat per titik fungsi, kedua pada desain sebesar 1,25 cacat per titik fungsi, ketiga pada persyaratan sebesar 1 cacat, keempat pada dokumentasi sebesar 0,6 cacat per titik fungsi, dan pada kesalahan perbaikan sebesar 0,4 cacat per titik fungsi (Jones, 2013, p. 3). Sejumlah cacat yang ditemukan di akhir proyek secara sistematis menyebabkan penyelesaian proyek melebihi jadwal (Lehtinen, Mäntylä, Vanhanen, Itkonen, & Lassenius, 2014, p. 626). Secara umum, biaya masa depan untuk koreksi cacat yang tidak terdeteksi di rilis produk mengkonsumsi sebagian besar dari total biaya pemeliharaan (In, Baik, Kim, Yang, & Boehm, 2006, p. 86), sehingga perbaikan cacat harus dilakukan sebelum rilis.
Untuk mencari cacat software biasanya dilakukan dengan debugging, yaitu pencarian dengan melibatkan semua source code, berjalannya, keadaannya, dan riwayatnya (Weiss, Premraj, Zimmermann, & Zeller, 2007, p. 1). Hal ini membutuhkan sumber daya yang banyak, dan tidak efisien karena menggunakan asumsi dasar bahwa penulis kode program tidak dapat dipercaya.
Dengan mengurangi jumlah cacat pada software yang dihasilkan dapat meningkatkan kualitas software. Secara tradisional, software berkualitas tinggi adalah software yang tidak ditemukan cacat selama pemeriksaan dan pengujian, serta dapat memberikan nilai kepada pengguna dan memenuhi harapan mereka (McDonald, Musson, & Smith, 2008, pp. 4-6). Pemeriksaan dan pengujian dilakukan terhadap alur dan keluaran dari software. Jumlah cacat yang ditemukan dalam pemeriksaan dan pengujian tidak dapat menjadi satu-satunya ukuran dari kualitas software. Pada banyak kasus, kualitas software lebih banyak dipengaruhi
2
penggunanya, sehingga perlu diukur secara subyektif berdasarkan pada persepsi dan harapan customer.
Pengujian merupakan proses pengembangan perangkat lunak yang paling mahal dan banyak memakan waktu, karena sekitar 50% dari jadwal proyek digunakan untuk pengujian (Fakhrahmad & Sami, 2009, p. 206). Software yang cacat menyebabkan biaya pengembangan, perawatan dan estimasi menjadi tinggi, serta menurunkan kualitas software (Gayatri, Nickolas, Reddy, & Chitra, 2009, p. 393). Biaya untuk memperbaiki cacat akibat salah persyaratan (requirement) setelah fase pengembangan (deployment) dapat mencapai 100 kali, biaya untuk memperbaiki cacat pada tahap desain setelah pengiriman produk mencapai 60 kali, sedangkan biaya untuk memperbaiki cacat pada tahap desain yang ditemukan oleh pelanggan adalah 20 kali (Strangio, 2009, p. 389). Hal ini karena cacat software dapat mengakibatkan business process tidak didukung oleh software yang dikembangkan, atau software yang telah selesai dikembangkan harus dilakukan perbaikan atau dikembangkan ulang jika terlalu banyak cacat.
Aktifitas untuk mendukung pengembangan software dan proses menajemen
project adalah wilayah penelitian yang penting (Lessmann, Baesens, Mues, &
Pietsch, 2008, p. 485). Karena pentingnya kesempurnaan software yang dikembangkan, maka diperlukan prosedur pengembangan yang sempurna juga untuk menghindari cacat software. Prosedur yang diperlukan adalah strategi pengujian yang efektif dengan menggunakan sumber daya yang efisien untuk mengurangi biaya pengembangan software.
Prosedur untuk meningkatan kualitas software dapat dilakukan dengan berbagai cara, tetapi pendekatan terbaik adalah pencegahan cacat, karena manfaat dari upaya pencegahannya dapat diterapkan kembali pada masa depan (McDonald, Musson, & Smith, 2008, p. 4). Untuk dapat melakukan pencegahan cacat, maka harus dapat memprediksi kemungkinan terjadinya cacat.
Kemampuan untuk memprediksi daerah rawan cacat dari modul sistem/subsistem, dapat berdampak pada jadwal, biaya, dan kepuasan pelanggan (Kumar, Sharma, & Kumar, 2013, p. 204). Sehingga memprediksi waktu penyelesaian pengembangan software tertentu merupakan hal yang sulit untuk dilakukan (Weiss, Premraj, Zimmermann, & Zeller, 2007, p. 1) karena dipengaruhi oleh jumlah cacat yang dihasilkan pada saat pengembangan. Prediksi cacat software merupakan hal penting untuk mengurangi waktu pengujian dengan
3
mengalokasikan sumber daya pengujian secara efektif (Turhan & Bener, Analysis of Naive Bayes’ Assumptions on Software Fault Data: An Empirical Study, 2009, p. 1).
Saat ini prediksi cacat software berfokus pada memperkirakan jumlah cacat dalam software, menemukan hubungan cacat, dan mengklasifikasikan kerawanan cacat dari komponen software, biasanya ke dalam kelompok rawan dan tidak rawan (Song, Jia, Shepperd, Ying, & Liu, 2011, p. 356). Klasifikasi adalah pendekatan yang populer untuk memprediksi cacat software (Lessmann, Baesens, Mues, & Pietsch, 2008, p. 485) atau untuk mengidentifikasi kegagalan software (Gayatri, Nickolas, Reddy, & Chitra, 2009, p. 393). Untuk melakukan klasifikasi diperlukan data yang diperoleh dari riwayat pengembangan sebelumnya.
Software metrics merupakan data yang dapat digunakan untuk mendeteksi
modul software apakah memiliki cacat atau tidak (Chiş, 2008, p. 273). Salah satu metode yang efektif untuk mengidentifikasi modul software dari potensi rawan kegagalan adalah dengan menggunakan teknik data mining yang diterapkan pada
software metrics yang dikumpulkan selama proses pengembangan software
(Khoshgoftaar, Gao, & Seliya, 2010, p. 137). Software metrics yang dikumpulkan selama pengembangan disimpan dalam bentuk dataset.
Dataset NASA (National Aeronautics and Space Administration) yang telah tersedia untuk umum merupakan data metrik perangkat lunak yang sangat populer dalam pengembangan model prediksi cacat software, karena 62 penelitian dari 208 penelitian telah menggunakan dataset NASA (Hall, Beecham, Bowes, Gray, & Counsell, 2011, p. 18). Berdasarkan wawancara secara online di researchgate.net, Martin John Shepperd menyatakan bahwa ada banyak developer dan organisasi yang mengerjakan proyek NASA. Hal ini tentu memiliki banyak masalah asumsi, tetapi secara umum memiliki kemampuan yang sama dan cenderung membuat kesalahan yang serupa. Dataset NASA yang tersedia untuk umum telah banyak digunakan sebagai bagian dari penelitian cacat software (Shepperd, Song, Sun, & Mair, 2013, p. 1208). Dataset NASA tersedia dari dua sumber, yaitu NASA MDP (Metrics Data Program) repository dan PROMISE (Predictor Models in Software Engineering) Repository (Gray, Bowes, Davey, Sun, & Christianson, 2011, p. 98). Menggunakan dataset NASA merupakan pilihan yang terbaik, karena mudah diperoleh dan kinerja dari metode yang digunakan menjadi mudah untuk dibandingkan dengan penelitian sebelumnya.
4
Metode prediksi cacat menggunakan probabilitas dapat menemukan sampai 71% (Menzies, Greenwald, & Frank, 2007, p. 2), lebih baik dari metode yang digunakan oleh industri. Jika dilakukan dengan menganalisa secara manual dapat menemukan 35% sampai 60% (Shull, et al., 2002, p. 254). Hasil tersebut menunjukkan bahwa menggunakan probalitas merupakan metode terbaik untuk menemukan cacat software.
Berdasarkan hasil penelitian yang ada, tidak ditemukan satu metode terbaik yang berguna untuk mengklasifikasikan berbasis metrik secara umum dan selalu konsisten dalam semua penelitian yang berbeda (Lessmann, Baesens, Mues, & Pietsch, 2008, p. 485). Tetapi model Naϊve Bayes merupakan salah satu algoritma klasifikasi paling efektif (Tao & Wei-hua, 2010, p. 1) dan efisien (Zhang, Jiang, & Su, 2005, p. 1020), secara umum memiliki kinerja yang baik (Hall, Beecham, Bowes, Gray, & Counsell, 2011, p. 13), serta cukup menarik karena kesederhanaan, keluwesan, ketangguhan dan efektifitasnya (Gayatri, Nickolas, Reddy, & Chitra, 2009, p. 395). Maka dibutuhkan pengembangan prosedur penelitian yang lebih dapat diandalkan sebelum memiliki keyakinan dalam menyimpulkan perbandingan penelitian dari model prediksi cacat software (Myrtveit, Stensrud, & Shepperd, 2005, p. 380). Pengembangan prosedur penelitian dapat dilakukan dengan memperbaiki kualitas data yang digunakan atau dengan memperbaiki model yang digunakan.
Jika dilihat dari software metrics yang digunakan, secara umum dataset kualitas software bersifat tidak seimbang (imbalanced), karena kebanyakan cacat dari software ditemukan dalam persentase yang kecil dari modul software (Seiffert, Khoshgoftaar, Hulse, & Folleco, 2011, p. 1). Jumlah dari dataset yang rawan cacat (fault-prone) jauh lebih kecil dari pada dataset yang tidak rawan cacat (nonfault-prone). Klasifikasi data dengan pembagian kelas yang tidak seimbang dapat menimbulkan penurunan kinerja yang signifikan yang dicapai oleh algoritma belajar (learning algorithm) pengklasifikasi standar, yang mengasumsikan distribusi kelas yang relatif seimbang dan biaya kesalahan klasifikasi yang sama (Sun, Mohamed, Wong, & Wang, 2007, p. 3358). Ketepatan parameter tidak dapat digunakan untuk mengevaluasi kinerja dataset yang tidak seimbang (Catal, 2012, p. 195). Membangun model kualitas perangkat lunak tanpa melakukan pengolahan awal terhadap data tidak akan menghasilkan model prediksi cacat software yang efektif, karena jika data yang digunakan tidak
5
seimbang maka hasil prediksi cenderung menghasilkan kelas mayoritas (Khoshgoftaar, Gao, & Seliya, 2010, p. 138). Karena cacat software merupakan kelas minoritas, maka banyak cacat yang tidak dapat ditemukan.
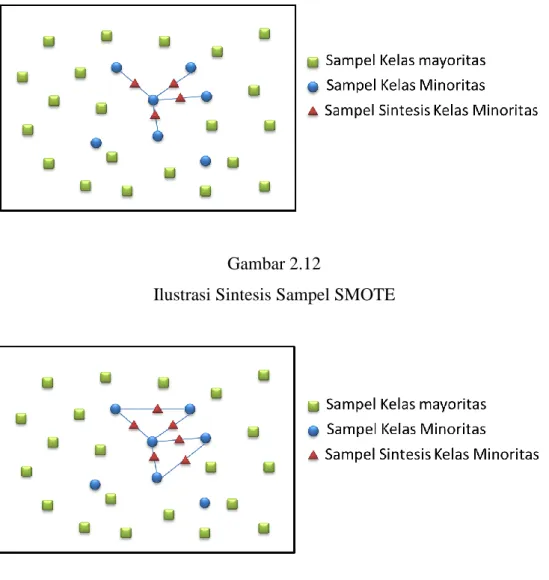
Ada tiga pendekatan untuk menangani dataset tidak seimbang (unbalanced), yaitu pendekatan pada level data, level algoritmik, dan menggabungkan atau memasangkan (ensemble) metode (Yap, et al., 2014, p. 14). Pendekatan pada level data mencakup berbagai teknik resampling, memanipulasi data latih untuk memperbaiki kecondongan distribusi kelas, seperti Random Over-Sampling (ROS) dan Random Under-Sampling (RUS), dan SMOTE (Synthetic Minority
Over-sampling Technique) (Chawla, Bowyer, Hall, & Kegelmeyer, 2002, p. 328).
FSMOTE (Fractal Synthetic Minority Over-sampling Technique) adalah metode
resampling yang ditujukan untuk memperbaiki SMOTE dengan mensintesis data
latih mengikuti teori interpolasi fraktal, sehingga data yang dihasilkan lebih representatif, dan menghasilkan kinerja lebih baik dari pada SMOTE (Zhang, Liu, Gong, & Jin, 2011, p. 2210). Pada tingkat algoritmik, metode utamanya adalah menyesuaikan operasi algoritma yang ada untuk membuat pengklasifikasi (classifier) agar lebih konduktif terhadap klasifikasi kelas minoritas (Zhang, Liu, Gong, & Jin, 2011, p. 2205). Sedangkan pada pendekatan menggabungkan atau memasangkan (ensemble) metode, ada dua algoritma ensemble-learning paling populer, yaitu boosting dan bagging (Yap, et al., 2014, p. 14). Algoritma boosting telah dilaporkan sebagai meta-teknik untuk mengatasi masalah ketidakseimbangan kelas (class imbalance) (Sun, Mohamed, Wong, & Wang, 2007, p. 3360). Pada pendekatan algoritma dan ensemble memiliki tujuan yang sama, yaitu memperbaiki algoritma pengklasifikasi tanpa mengubah data, sehingga dapat dianggap ada 2 pendekatan saja, yaitu pendekatan level data dan pendekatan level algoritma (Peng & Yao, 2010, p. 111). Dengan membagi menjadi 2 pendekatan dapat mempermudah fokus objek perbaikan, pendekatan level data difokuskan pada pengolahan awal data, sedangkan pendekatan level algoritma difokuskan pada perbaikan algoritma atau menggabungkan (ensemble).
Bagging dan Boosting telah berhasil meningkatkan akurasi pengklasifikasi tertentu untuk dataset buatan dan yang sebenarnya. Bagging adalah metode
ensemble yang sederhana namun efektif dan telah diterapkan untuk banyak
aplikasi di dunia nyata (Liang & Zhang, Empirical Study of Bagging Predictors on Medical Data, 2011, p. 31). Bagging merupakan metode ensemble yang
6
banyak diterapkan pada algoritma klasifikasi, dengan tujuan untuk meningkatkan akurasi pengklasifikasi dengan menggabungkan pengklasifikasi tunggal, dan hasilnya lebih baik daripada random sampling (Alfaro, Gamez, & Garcia, 2013, p. 1). Secara umum algoritma Boosting lebih baik dari pada Bagging, tetapi tidak merata baik. AdaBoost secara teoritis dapat secara signifikan digunakan untuk mengurangi kesalahan dari beberapa algoritma pembelajaran yang secara konsisten menghasilkan kinerja pengklasifikasi yang lebih baik. AdaBoost diterapkan pada Naϊve Bayes dapat meningkatkan kinerja sebesar 33,33% dan menghasilkan hasil yang akurat dengan mengurangi nilai kesalahan klasifikasi dengan meningkatkan iterasi (Korada, Kumar, & Deekshitulu, 2012, p. 73). Beberapa penelitian tersebut telah menunjukkan bahwa metode ensemble (AdaBoost dan Bagging) dapat memperbaiki kinerja pengklasifikasi.
Untuk mencari solusi terbaik terhadap masalah ketidakseimbangan kelas (class imbalance), maka pada penelitian ini akan dilakukan pengukuran kinerja pada pendekatan level data, dan pendekatan level algoritma. Pada pendekatan level data dilakukan resampling, yaitu Random Over-Sampling (ROS), Random
Under-Sampling (RUS), dan FSMOTE. Algoritma pengklasifikasi yang
digunakan adalah Naϊve Bayes. Sedangkan pada pendekatan level algoritma digunakan ensemble dengan algoritma AdaBoost dan Bagging. Diharapkan didapat pendekatan level data dan algoritma terbaik untuk menyelesaikan permasalahan ketidakseimbangan kelas.
1.2 Permasalahan Penelitian 1.2.1 Identifikasi Masalah
Berdasarkan uraian pada latar belakang dapat diidentifikasi beberapa permasalahan (Research Problem disingkat RP), yaitu:
RP1 Memperbaiki software yang cacat setelah pengiriman membutuhkan biaya jauh lebih mahal dari pada selama pengembangan, pengujian software menghabiskan sampai 50% jadwal proyek, tetapi belum ada model prediksi cacat software yang berlaku umum.
RP2 Naϊve Bayes merupakan model paling efektif dan efisien, tetapi belum dapat mengklasifikasikan dataset berbasis metrik dengan kinerja terbaik secara umum dan selalu konsisten dalam semua penelitian.
7
RP3 Dataset dari software metrics secara umum bersifat tidak seimbang, hal ini dapat menurunkan kinerja model prediksi cacat software karena cenderung menghasilkan prediksi kelas mayoritas.
1.2.2 Ruang Lingkup Masalah
Ruang lingkup masalah digunakan untuk membatasi pokok pembahasan agar lebih terfokus dan dapat mencapai tujuan penelitian. Pada penelitian ini digunakan dataset NASA (National Aeronautics and Space Administration) dari NASA MDP (Metrics Data Program) repository dan PROMISE (Predictor
Models in Software Engineering) Repository sebagai software metrics. Aplikasi
dikembangkan menggunakan bahasa Java dan menggunakan IDE (Integrated
Development Environment) NetBeans. Pengolahan data awal menggunakan teknik resampling, yaitu Random Over-Sampling (ROS), Random Under-Sampling
(RUS), dan FSMOTE. Algoritma klasifikasi yang digunakan adalah Naϊve Bayes. Optimasi menggunakan algoritma ensemble AdaBoost dan Bagging.
1.2.3 Rumusan Masalah
Berdasarkan uraian sebelumnya, pada penelitian ini akan diterapkan pendekatan level data dan level algoritma untuk meningkatkan kinerja pengklasifikasi (Naϊve Bayes) dengan menggunakan dataset yang tidak seimbang. Maka pada penelitian ini dibuat rumusan masalah (Research Question disingkat RQ) sebagai berikut:
RQ1 Dapatkah kinerja pengklasifikasi (Naϊve Bayes) ditingkatkan untuk memperbaiki model prediksi cacat software?
RQ2 Pendekatan level algoritma (ensemble):
RQ2.1 Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan dengan algoritma AdaBoost pada model prediksi cacat software? RQ2.2 Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan
dengan algoritma Bagging pada model prediksi cacat software? RQ2.3 Algoritma ensemble manakah antara AdaBoost dan Bagging yang
dapat meningkatkan kinerja Naϊve Bayes menjadi lebih baik pada model prediksi cacat software?
8
RQ3.1 Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan dengan ROS (Random Over-Sampling) pada model prediksi cacat software?
RQ3.2 Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan dengan RUS (Random Under-Sampling) pada model prediksi cacat software?
RQ3.3 Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan dengan FSMOTE pada model prediksi cacat software?
RQ3.4 Pendekatan level data yang manakah antara ROS, RUS, atau FSMOTE yang menghasilkan kinerja terbaik pada model prediksi cacat software?
RQ4 Integrasi pendekatan level data dan level algoritma:
RQ4.1 Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan dengan ROS dan AdaBoost pada model prediksi cacat software? RQ4.2 Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan
dengan RUS dan AdaBoost pada model prediksi cacat software? RQ4.3 Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan
dengan FSMOTE dan AdaBoost pada model prediksi cacat software?
RQ4.4 Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan dengan ROS dan Bagging pada model prediksi cacat software? RQ4.5 Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan
dengan RUS dan Bagging pada model prediksi cacat software? RQ4.6 Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan
dengan FSMOTE dan Bagging pada model prediksi cacat software?
RQ4.7 Integrasi pendekatan level data dan level algoritma manakah yang dapat menghasilkan kinerja Naϊve Bayes terbaik pada model prediksi cacat software?
RQ5 Pendekatan mana yang lebih baik antara pendekatan level data dan level algoritma (ensemble) pada model prediksi cacat software?
RQ6 Dari semua model yang menggunakan pendekatan level data dan level algoritma serta kombinasi keduanya, manakah yang menghasilkan kinerja terbaik?
9
1.3 Tujuan dan Manfaat Penelitian
Dalam tujuan dan manfaat penelitian akan dibahas mengenai tujuan yang ingin dicapai dalam penelitian ini dan manfaat yang dapat diperoleh dengan adanya penelitian ini.
1.3.1 Tujuan Penelitian
Tujuan pada penelitian (Research Objective disingkat RO) ini adalah menerapkan pendekatan level data (ROS, RUS, dan FSMOTE) dan pendekatan level algoritma ensemble (Bagging atau AdaBoost) untuk mengurangi pengaruh ketidakseimbangan kelas dalam dataset, agar kinerja pengklasifikasi (Naϊve Bayes) pada prediksi cacat software dapat meningkat dalam memprediksi kerawanan cacat. Berikut ini adalah penjabaran dari tujuan penelitian:
RO1 Meningkatkan kinerja pengklasifikasi (Naϊve Bayes) untuk memperbaiki dan membangun model prediksi cacat software.
RO2 Pendekatan level algoritma (ensemble) dibagi ke dalam tiga subrumusan masalah, yaitu:
RO2.1 Meningkat kinerja Naϊve Bayes dengan mengintegrasikan dengan algoritma AdaBoost pada model prediksi cacat software.
RO2.2 Meningkat kinerja Naϊve Bayes dengan mengintegrasikan dengan algoritma Bagging pada model prediksi cacat software.
RO2.3 Mengidentifikasi algoritma ensemble terbaik ketika diintegrasikan dengan Naϊve Bayes pada model prediksi cacat software.
RO3 Pendekatan level data (ROS, RUS, atau FSMOTE) dibagi ke dalam empat subrumusan masalah, yaitu:
RO3.1 Mengintegrasikan Naϊve Bayes dengan ROS (Random
Over-Sampling) untuk meningkatkan kinerja model prediksi cacat
software.
RO3.2 Mengintegrasikan Naϊve Bayes dengan RUS (Random
Under-Sampling) untuk meningkatkan kinerja model prediksi cacat
software.
RO3.3 Mengintegrasikan Naϊve Bayes dengan FSMOTE untuk meningkatkan kinerja model prediksi cacat software.
10
RO3.4 Mengidentifikasi pendekatan level data terbaik ketika diintegrasikan dengan Naϊve Bayes pada model prediksi cacat software.
RO4 Integrasi pendekatan level data dan level algoritma dibagi ke dalam tujuh subrumusan masalah, yaitu:
RO4.1 Mengintegrasikan Naϊve Bayes dengan ROS dan AdaBoost untuk meningkatkan kinerja model prediksi cacat software.
RO4.2 Mengintegrasikan Naϊve Bayes dengan RUS dan AdaBoost untuk meningkatkan kinerja model prediksi cacat software.
RO4.3 Mengintegrasikan Naϊve Bayes dengan FSMOTE dan AdaBoost untuk meningkatkan kinerja model prediksi cacat software.
RO4.4 Mengintegrasikan Naϊve Bayes dengan ROS dan Bagging untuk meningkatkan kinerja model prediksi cacat software.
RO4.5 Mengintegrasikan Naϊve Bayes dengan RUS dan Bagging untuk meningkatkan kinerja model prediksi cacat software.
RO4.6 Mengintegrasikan Naϊve Bayes dengan FSMOTE dan Bagging untuk meningkatkan kinerja model prediksi cacat software.
RO4.7 Mengidentifikasi integrasi pendekatan level data dan level algoritma terbaik ketika digunakan pada model prediksi cacat software.
RO5 Mengidentifikasi integrasi pendekatan level data atau level algoritma yang dapat menghasilkan kinerja Naϊve Bayes terbaik ketika digunakan pada model prediksi cacat software.
RO6 Mengidentifikasi model yang memiliki kinerja terbaik dari model yang menggunakan pendekatan level data dan level algoritma serta kombinasi keduanya.
1.3.2 Manfaat Penelitian
Hasil penelitian ini dapat dimanfaatkan untuk mengembangkan perangkat lunak prediksi cacat software yang dapat digunakan untuk mempermudah pengembang software dalam menghasilkan software berkualitas. Selain itu, penelitian ini diharapkan dapat memberikan sumbangan ilmu yang berhubungan dengan pengembangan dan penerapan model untuk menangani ketidakseimbangan kelas pada prediksi cacat software.
11
1.4 Hubungan antara Masalah, Rumusan, dan Tujuan Penelitian
Pada pembahasan sebelumnya telah dibahas identifikasi masalah, rumusan masalah, dan tujuan penelitian. Identifikasi masalah ditujukan untuk menentukan masalah yang akan dibahas, disebut juga sebagai masalah penelitian (Research
Problem (RP)). Rumusan masalah disebut juga sebagai pertanyaan penelitian
(Research Question (RQ)) ditujukan untuk memberikan konteks atau mengarahkan peneliti untuk menjawabnya. Sedangkan tujuan penelitian (Research Objective (RO)) ditujukan untuk menentukan sasaran yang ingin dicapai pada penelitian. Hubungan ketiganya pada penelitian ini ditunjukkan pada Tabel 1.1, Tabel 1.2, Tabel 1.3, dan Tabel 1.4.
12 Tabel 1.1
Hubungan antara Masalah, Rumusan dan Tujuan Penelitian
Masalah Penelitian
(Research Problems (RP)) (Research Questions (RQ)) Rumusan Masalah (Research Objectives (RO)) Tujuan Penelitian
RP1
Memperbaiki software yang cacat setelah
pengiriman membutuhkan biaya jauh lebih mahal dari pada selama pengembangan, pengujian software menghabiskan sampai 50% waktu pengembangan, tetapi belum ada model prediksi cacat software yang berlaku umum.
RQ1
Dapatkah kinerja pengklasifikasi (Naϊve Bayes) ditingkatkan untuk memperbaiki model prediksi cacat software?
RO1
Meningkatkan kinerja
pengklasifikasi (Naϊve Bayes) untuk memperbaiki dan
membangun model prediksi cacat software.
RP2
Naϊve Bayes merupakan model paling efektif dan efisien, tetapi belum dapat mengklasifikasikan dataset berbasis metrik dengan kinerja terbaik secara umum dan selalu konsisten dalam semua penelitian.
RQ2.1
Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan dengan algoritma AdaBoost pada model prediksi cacat software?
RO2.1
Meningkat kinerja Naϊve Bayes dengan mengintegrasikan dengan algoritma AdaBoost pada model prediksi cacat software.
RQ2.2
Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan dengan algoritma Bagging pada model prediksi cacat software?
RO2.2
Meningkat kinerja Naϊve Bayes dengan mengintegrasikan dengan algoritma Bagging pada model prediksi cacat software.
RQ2.3
Algoritma ensemble manakah antara AdaBoost dan Bagging yang dapat meningkatkan kinerja Naϊve Bayes menjadi lebih baik pada model prediksi cacat software?
RO2.3
Mengidentifikasi algoritma
ensemble terbaik ketika
diintegrasikan dengan Naϊve Bayes pada model prediksi cacat software.
13 Tabel 1.2
Hubungan antara Masalah, Rumusan dan Tujuan Penelitian (Lanjutan)
Masalah Penelitian
(Research Problems (RP)) (Research Questions (RQ)) Rumusan Masalah (Research Objectives (RO)) Tujuan Penelitian
RP3
Dataset dari software metrics secara umum bersifat tidak seimbang, hal ini dapat menurunkan kinerja model prediksi cacat software karena cenderung menghasilkan prediksi kelas mayoritas.
RQ3.1
Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan dengan ROS (Random
Over-Sampling) pada model prediksi cacat
software?
RO3.1
Mengintegrasikan Naϊve Bayes dengan ROS (Random Over-Sampling) untuk meningkatkan kinerja model prediksi cacat software.
RQ3.2
Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan dengan RUS (Random
Under-Sampling) pada model prediksi cacat
software?
RO3.2
Mengintegrasikan Naϊve Bayes dengan RUS (Random Under-Sampling) untuk
meningkatkan kinerja model prediksi cacat software.
RQ3.3
Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan dengan FSMOTE pada model prediksi cacat software?
RO3.3
Mengintegrasikan Naϊve Bayes dengan FSMOTE untuk meningkatkan kinerja model prediksi cacat software.
RQ3.4
Pendekatan level data yang manakah antara ROS, RUS, atau FSMOTE yang menghasilkan kinerja terbaik pada model prediksi cacat software?
RO3.4
Mengidentifikasi pendekatan level data terbaik ketika diintegrasikan dengan Naϊve Bayes pada model prediksi cacat software.
14 Tabel 1.3
Hubungan antara Masalah, Rumusan, dan Tujuan Penelitian (Lanjutan)
Masalah Penelitian
(Research Problems (RP)) (Research Questions (RQ)) Rumusan Masalah (Research Objectives (RO)) Tujuan Penelitian
RQ4.1
Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan dengan ROS dan AdaBoost
pada model prediksi cacat software? RO4.1
Mengintegrasikan Naϊve Bayes dengan ROS dan AdaBoost untuk meningkatkan kinerja model prediksi cacat software.
RQ4.2
Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan dengan RUS dan AdaBoost pada model prediksi cacat software?
RO4.2
Mengintegrasikan Naϊve Bayes dengan RUS dan AdaBoost untuk meningkatkan kinerja model prediksi cacat software.
RQ4.3
Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan dengan FSMOTE dan
AdaBoost pada model prediksi cacat software? RO4.3
Mengintegrasikan Naϊve Bayes dengan FSMOTE dan AdaBoost untuk meningkatkan kinerja model prediksi cacat software.
RQ4.4
Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan dengan ROS dan Bagging pada model prediksi cacat software?
RO4.4
Mengintegrasikan Naϊve Bayes dengan ROS dan Bagging untuk meningkatkan kinerja model prediksi cacat software.
RQ4.5 Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan dengan RUS dan Bagging pada model prediksi cacat software?
RO4.5 Mengintegrasikan Naϊve Bayes dengan RUS dan Bagging untuk meningkatkan kinerja model prediksi cacat software.
RQ4.6
Seberapa meningkat kinerja Naϊve Bayes jika diintegrasikan dengan FSMOTE dan Bagging
pada model prediksi cacat software? RO4.6
Mengintegrasikan Naϊve Bayes dengan FSMOTE dan Bagging untuk meningkatkan kinerja model prediksi cacat software.
15 Tabel 1.4
Hubungan antara Masalah, Rumusan dan Tujuan Penelitian (Lanjutan)
Masalah Penelitian
(Research Problems (RP)) (Research Questions (RQ)) Rumusan Masalah (Research Objectives (RO)) Tujuan Penelitian
RQ4.7
Integrasi pendekatan level data dan level algoritma manakah yang dapat
menghasilkan kinerja Naϊve Bayes terbaik pada model prediksi cacat software?
RO4.7 Mengidentifikasi integrasi pendekatan level data dan level algoritma terbaik ketika digunakan pada model prediksi cacat software
RQ5
Pendekatan mana yang lebih baik antara pendekatan level data dan level
algoritma (ensemble) pada model prediksi cacat software?
RO5
Mengidentifikasi integrasi pendekatan level data atau level algoritma yang dapat menghasilkan kinerja Naϊve Bayes terbaik ketika digunakan pada model prediksi cacat software
RQ6
Dari semua model yang menggunakan pendekatan level data dan level
algoritma serta kombinasi keduanya, manakah yang menghasilkan kinerja terbaik?
RO6
Mengidentifikasi model yang memiliki kinerja terbaik dari model yang menggunakan pendekatan level data dan level algoritma serta kombinasi keduanya.
16
1.5 Sistematika Penulisan
Agar karya ilmiah ini mudah dipelajari dan dipahami, maka dibagi menjadi lima bab dan setiap bab dibagi menjadi beberapa subbab sesuai topik pembahasan. Sistematika penulisan pada penelitian ini adalah:
Bab I Pendahuluan, membahas mengenai latar belakang penelitian, permasalahan penelitian, tujuan dan manfaat penelitian, dan sistematika penelitian.
Bab II Landasan Teori, berisi tentang tinjauan studi, yaitu membahas tentang penelitian sebelumnya yang mendasari penelitian ini. Dan tinjauan pustaka, yaitu membahas tentang landasan secara teoritis yang diambil dari textbook. Serta kerangka pemikiran yang digunakan dalam penelitian ini.
Bab III Metodologi Penelitian, berisi tentang perencanaan penelitian yang terdiri dari analisa kebutuhan, metode pengumpulan data, model yang diusulkan, dan teknik analisis yang dilakukan dalam penelitian prediksi cacat software.
Bab IV Hasil dan Pembahasan, berisi hasil penerapan model prediksi cacat software pada dataset NASA dari NASA MDP repository dan PROMISE repository, dan pengujiannya. Pengujian dilakukan menggunakan uji statistik terhadap pengukuran kinerja model prediksi cacat software yang diusulkan.
Bab V Kesimpulan dan Saran, berisi kesimpulan dari model yang diusulkan berdasarkan hasil pengujian, dan saran yang ditujukan untuk pengembangan model prediksi cacat software lebih lanjut.
17
BAB II
LANDASAN TEORI
2.1 Tinjauan Studi
Penelitian tentang prediksi cacat software telah lama dilakukan, dan sudah banyak hasil penelitian yang dipublikasikan. Sebelum memulai penelitian, perlu dilakukan kajian terhadap penelitian sebelumnya, agar dapat mengetahui metode, data, maupun model yang sudah pernah digunakan. Tinjauan studi ini akan digunakan sebagai landasan penelitian agar dapat mengetahui state of the art tentang penelitian prediksi cacat software yang membahas tentang ketidakseimbangan (imbalanced) kelas.
2.1.1 Model Penelitian Pelayo dan Dick (2007)
Pada penelitian yang dilakukan oleh Pelayo dan Dick (Pelayo & Dick, 2007, pp. 69-72) menyatakan bahwa untuk meningkatkan kehandalan software merupakan tugas yang sulit, karena kompleksitas dan kecanggihan software yang luar biasa. Sejumlah peneliti telah menerapkan machine learning untuk memprediksi cacat software, yaitu dengan memprediksi modul yang akan mengalami kegagalan selama operasi. Namun, kecondongan (skewness) dalam dataset prediksi cacat biasanya merusak algoritma pembelajaran. Pengklasifikasi sering tidak menghasilkan prediksi kelas minoritas. Masalah ini telah dikenal dalam machine learning dan sering disebut belajar dari ketidakseimbangan (imbalanced) dataset. Penelitian ini difokuskan pada teknik SMOTE, yaitu metode untuk melakukan over-sampling kelas minoritas. Tujuannya untuk mengetahui apakah teknik SMOTE dapat meningkatkan pengenalan terhadap modul yang cacat. Hasil dari eksperimen menunjukkan bahwa setelah dilakukan teknik SMOTE didapat dataset yang lebih seimbang, dan akurasi pengklasifikasi G-Mean rata-rata meningkat sebesar 23% dari empat dataset yang digunakan.