7
BAB II
LANDASAN TEORI
2.1 Studi LiteraturPenelitian yang berkaitan dengan klasifikasi kalimat tanya berdasarkan Taksonomi Bloom telah dilakukan oleh Selvia Ferdiana Kusuma dengan menggunakan algoritma J48 menghasilkan tingkat akurasi sebesar 83.11 %. Dataset yang digunakan pada penelitian tersebut sebanyak 900 data dengan jumlah kelas 6, sehingga setiap kelas memiliki 150 dataset [7]. Selain itu Selvia juga melakukan perbandingan dengan 3 algoritma klasifikasi yaitu SVM, KNN, dan J48 namun algoritma klasifikasi yang memiliki tingkat akurasi paling tinggi adalah algoritma J48. Hasil dari masing-masing algoritma ditunjukkan seperti Tabel 2.1.
Tabel 2.1 Hasil Penelitian Selvia Ferdiana Kusuma
Metode Akurasi
SVM 82.00%
KNN 82.78%
J48 83.11%
2.2 Text Mining
Seperti hal nya data mining, text mining adalah proses penemuan akan informasi atau trend baru yang sebelumnya tidak terungkap dengan memproses dan menganalisa data dalam jumlah besar. Dalam menganalisa sebagian atau keseluruhan unstructured text, text mining mencoba untuk mengasosiasikan satu bagian text dengan yang lainnya berdasarkan aturan-aturan tertentu. Hasil yang di harapkan adalah informasi baru yang tidak terungkap jelas sebelumnya [8].
Menurut [9], Saat ini text mining telah mendapat perhatian dalam berbagai bidang, antara lain:
1) Aplikasi keamanan
Banyak paket perangkat lunak text mining dipasarkan terhadap aplikasi keamanan, khususnya analisis plain text seperti berita internet.
2) Aplikasi biomedis
Berbagai aplikasi text mining dalam literatur biomedis telah disusun. Salah satu contohnya adalah PubGene yang mengkombinasikan text mining biomedis
8
dengan visualisasi jaringan sebagai sebuah layanan Internet. 3) Perangkat Lunak dan Aplikasi
Departemen riset dan pengembangan perusahaan besar, termasuk IBM dan Microsoft, sedang meneliti teknik text mining dan mengembangkan program untuk lebih mengotomatisasi proses pertambangan dan analisis. Perangkat lunak
text mining juga sedang diteliti oleh perusahaan yang berbeda yang bekerja di
bidang pencarian dan pengindeksan secara umum sebagai cara untuk meningkatkan performansinya.
4) Aplikasi Media Online
Text mining sedang digunakan oleh perusahaan media besar, seperti
perusahaan Tribune, untuk menghilangkan ambigu informasi dan untuk memberikan pembaca dengan pengalaman pencarian yang lebih baik, yang meningkatkan loyalitas pada site dan pendapatan. Selain itu, editor diuntungkan dengan mampu berbagi, mengasosiasi dan properti paket berita, secara signifikan meningkatkan peluang untuk menuangkan konten.
5) Aplikasi Pemasaran
Text Mining juga mulai digunakan dalam pemasaran, lebih spesifik dalam
analisis manajemen hubungan pelanggan. 6) Aplikasi Akademik
Masalah text mining penting bagi penerbit yang memiliki database besar untuk mendapatkan informasi yang memerlukan pengindeksan untuk pencarian. Hal ini terutama berlaku dalam ilmu sains, di mana informasi yang sangat spesifik sering terkandung dalam teks tertulis.
2.3 Preprocessing Data
Sebelum diolah lebih lanjut data teks terlebih dahulu dilakukan proses
preprocessing. Teknik preprocessing adalah langkah awal sebelum melakukan
klasifikasi. Tujuan dari preprocessing adalah merepresentasikan sebuah kalimat ataupun sebuah dokumen menjadi sebuah vektor fitur dengan cara memecah teks menjadi satuan kata [10]. Berikut tahapan dalam pemilihan fitur, antara lain:
9 2.3.1 Case Folding
Case folding merupakan tahap penyamaan case dalam sebuah dokumen
atau teks agar memudahkan dalam pencarian [11]. Tahap Case folding dapat dilihat pada Gambar 2.2.
Gambar 2.1 Tahap Case folding 2.3.2 Remove Number & Punctuation
Remove Number & Punctuation merupakan proses menghilangkan
karakter berupa nomor, tanda baca, dan spasi. Jika data mengandung karakter nomor, tanda baca, dan spasi, maka karakter tersebut akan dihapus. Tahap Remove
Number & Punctuation dapat dilihat pada Gambar 2.2.
Gambar 2.2 Tahap Remove Number & Punctuation 2.3.3 Tokenisasi
Tokenisasi adalah tahap memisahkan deretan kata yang ada pada kalimat menjadi token atau potongan kata tunggal (termmed word), selain itu tokenisasi juga membuang beberapa karakter yang dianggap sebagai tanda baca. Tahap Tokenisasi dapat dilihat pada Gambar 2.3.
Sebutkan nama-nama provinsi yang ada di
Indonesia?
sebutkan nama-nama provinsi yang ada di
indonesia? Hasil Case Folding
sebutkan nama-nama provinsi yang ada di
indonesia?
sebutkan namanama provinsi yang ada di
indonesia
Hasil Remove Number &
Punctuation
Inputan kalimat tanya
10
Gambar 2.3 Tahap Tokenisasi 2.4 Klasifikasi
Klasifikasi merupakan proses pembangunan suatu model yang mengklasifikasikan suatu objek berdasarkan atribut-atributnya. Kelas label sudah tersedia dari data sebelumnya sehingga terfokus untuk bagaimana mempelajari data yang ada agar klasifikator bisa mengklasifikasikan secara otomatis [12].
Klasifikasi terdiri atas dua model, yaitu [13] :
Pemodelan deskriptif, yaitu model klasfikasi yang dapat bertindak sebagai suatu alat yang bersifat menjelaskan untuk membedakan antara objek dengan kelas yang berbeda dari satu set data.
Pemodelan prediktif, yaitu model klasifikasi yang dapat digunakan sebagai prediktor label kelas yang belum diketahui recordnya.
2.5 Taksonomi Bloom
Taksonomi Bloom adalah struktur hierarki yang digunakan untuk mengidentifikasikan skills seseorang mulai dari tingkat yang rendah hingga yang tinggi [14]. Tentunya untuk mencapai tujuan yang lebih tinggi, level yang rendah harus terpenuhi terlebih dahulu. Dalam kerangka konsep ini, tujuan pendidikan oleh Bloom dibagi menjadi 3 domain/ranah kemampuan intelektual (intellectual
behaviours) yaitu kognitif, afektif dan psikomotorik [15].
Ranah kognitif mengurutkan keahlian berpikir sesuai dengan tujuan yang diharapkan. Proses berpikir menggambarkan tahap berpikir yang harus dikuasai oleh siswa agar mampu mengaplikasikan teori kedalam perbuatan. Ranah kognitif
sebutkan namanama provinsi yang ada di
indonesia sebutkan namanama provinsi yang ada di indonesia Hasil Tokenisasi Hasil Remove Number &
11
ini terdiri dari atas enam level, yaitu: (1) pengetahuan, (2) pemahaman, (3) penerapan, (4) analisa, (5) sintesa, dan (6) evaluasi. Secara lebih jelas, penjelasan tentang pembaharuan aspek pada ranah kognitif dijelaskan pada Tabel 2.2 [16].
Tabel 2.2 Aspek Kognitif Taksonomi Bloom
No Kategori Penjelasan Kata Kunci
1 Mengingat Kemampuan
menyebutkan kembali informasi/ pengetahuan yang tersimpan dalam ingatan. Contoh: Menyebutkan arti taksonomi Mengutip, menyebutkan, menjelaskan, menggambar, membilang, mengidentifikasi, mendaftar, menunjukkan, memberi label, memberi indeks, memasangkan, menamai, menandai,
membaca, menghafal, meniru, mencatat, mengulang, mereproduksi, meninjau, memilih, menyatakan, mempelajari, mentabulasi, mengkode, menelusuri, menulis 2 Memahami Kemampuan memahami instruksi dan menegaskan pengertian/ makna ide atau konsep yang telah diajarkan baik dalam bentuk lisan, tertulis, maupun
grafik/diagram. Contoh: Merangkum materi yang telah diajarkan dengan kata-kata sendiri. Memperkirakan, menjelaskan, mengkategorikan, mencirikan, merinci, mengasosiasikan, membandingkan, menghitung, mengkontraskan, mengubah, mempertahankan, menguraikan, menjalin, membedakan, mendiskusikan, menggali, mencontohkan, menerangkan, mengemukakan, mempolakan, memperluas, menyimpulkan, meramalkan, merangkum, menjabarkan 3 Menerapkan Kemampuan
melakukan sesuatu dan mengaplikasikan konsep dalam situasi tertentu. Contoh: Melakukan proses pembayaran gaji sesuai dengan sistem berlaku
Mengurutkan, melaksanakan, melakukan, melatih, membangun, membiasakan, memecahkan, memodifikasi, mempersoalkan, memproduksi, memproses, mencegah, menentukan, menerapkan, mengadaptasi, mengaitkan, mengemukakan, menggali, menggambarkan, menggunakan, menghitung,
12 mengkalkulasi, mengklasifikasikan, mengoperasikan, mengurutkan, menilai, mensimulasikan, mentabulasi, menugaskan, menyelidiki, menyesuaikan, menyusun, meramalkan 4 Menganalisis Kemampuan memisahkan konsep kedalam beberapa komponen dan menghubungkan satu sama lain untuk memperoleh pemahaman atas konsep tersebut secara utuh. Contoh:
Menganalisa penyebab meningkatnya harga pokok penjualan dalam laporan keuangan dengan memisahkan komponen-komponennya. Melatih, memaksimalkan, membagankan, memecahkan, memerinci, memerintahkan, memilih, mencerahkan, mendeteksi, mendiagnosis, mendiagramkan, menegaskan, menelaah, menemukan, mengaitkan, menganalisis, mengaudit, mengedit, mengkorelasikan, menguji, mengukur, menjelajah, menominasikan, mentransfer, menyeleksi, menyimpulkan, merasionalkan 5 Mengevaluasi Kemampuan menetapkan derajat sesuatu berdasarkan norma, kriteria atau patokan tertentu. Contoh:
Membandingkan hasil ujian siswa dengan kunci jawaban Membandingkan, membuktikan, memerinci, memilih, memisahkan, memperjelas,mempertahankan, memprediksi, memproyeksi, memutuskan, memvalidasi, menafsirkan, mendukung, mengarahkan, mengetes, mengkritik, mengukur, menilai, menimbang, menugaskan, menyimpulkan, merangkum 6 Membuat Kemampuan memadukan unsur-unsur menjadi sesuatu bentuk baru yang utuh dan koheren, atau membuat sesuatu yang orisinil. Contoh: Membuat kurikulum Memadukan, membangun, membatas, membentuk, membuat, memfasilitasi, memperjelas, memproduksi, menampilkan, menanggulangi, menciptakan, mendikte, mengabtraksi, menganimasi, mengarang, mengatur,
13 dengan
mengintegrasikan pendapat dan materi dari beberapa sumber.
menggabungkan, menggeneralisasi, menghubungkan, mengkategorikan, mengkode, mengkombinasikan, mengkreasikan, mengoreksi, mengumpulkan, meningkatkan, menyusun, merancang, merangkum, merekonstruksi, merencanakan, mereparasi, merumuskan, menyiapkan
2.6 Support Vector Machine
Support Vector Machine (SVM) adalah sistem pembelajaran yang
pengklasifikasiannya menggunakan ruang hipotesis berupa fungsi-fungsi linear dalam sebuah ruang fitur (feature space) berdimensi tinggi, dilatih dengan algoritma pembelajaran yang didasarkan pada teori optimasi dengan mengimplementasikan learning bias yang berasal dari teori pembelajaran statistik [17]. Salah satu yang menjadi kelebihan SVM adalah tidak semua data latih akan dipandang untuk dilibatkan dalam setiap iterasi pelatihannya. Data-data yang berkontribusi tersebut disebut Support Vector [18].
2.6.1 Konsep SVM
Dalam Konsep SVM berusaha menemukan fungsi pemisah (hyperplane) terbaik diantara fungsi yang tidak terbatas jumlahnya. Hyperplane pemisah terbaik antara kedua kelas dapat ditemukan dengan mengukur margin hyperplane tersebut dan mencari titik maksimalnya. Adapun data yang berada pada bidang pembatas disebut support vector [19]. Pada dasarnya, konsep dasar dari algoritma SVM yaitu: 𝑚𝑖𝑛1 2|𝑤| 2 (2.1) s.t yi(xi . 𝑤 + 𝑏) − 1 ≥ 0
14 Keterangan:
xi adalah dataset
yi adalah output dari data xi , dan
w, b adalah parameter yang dicari nilainya. 2.6.2 SVM Linear
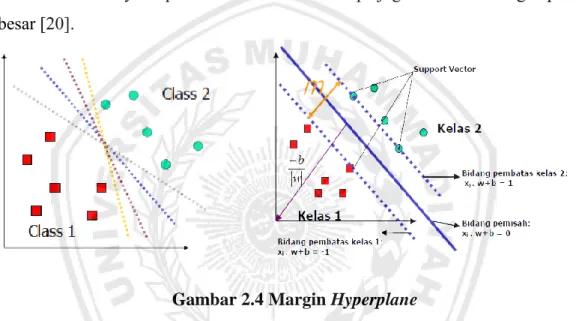
Linearly separable data merupakan data yang dapat dipisahkan secara
linier. Pada gambar dapat dilihat sebagai alternatif bidang pemisah yang dapat memisahkan semua dataset sesuai dengan kelasnya. Namun, bidang pemisah terbaik tidak hanya dapat memisahkan data tetapi juga memiliki margin paling besar [20].
Gambar 2.4 Margin Hyperplane
Adapun data yang berada pada bidang pembatas ini disebut support
vector. Dalam contoh di atas, dua kelas dapat dipisahkan oleh sepasang bidang
pembatas yang sejajar. Bidang pembatas pertama membatasi kelas pertama sedangkan bidang pembatas kedua membatasi kelas kedua, sehingga diperoleh
𝑥𝑖. 𝑤 + 𝑏 ≥ +1 𝑓𝑜𝑟 𝑦𝑖 = +1
(2.2) 𝑥𝑖. 𝑤 + 𝑏 ≤ −1 𝑓𝑜𝑟 𝑦𝑖 = −1
w adalah normal bidang dan b adalah posisi bidang relatif terhadap pusat koordinat.
2.6.3 Multi Class SVM
Ada dua pilihan untuk mengimplementasikan multi class SVM yaitu dengan menggabungkan beberapa SVM biner atau menggabungkan semua data
15
yang terdiri dari beberapa kelas ke dalam sebuah bentuk permasalahan optimasi. Pada SVM terdapat metode untuk mengklasifikasikan data yang memiliki lebih dari dua kelas, salah satunya adalah metode one-against-all. Dengan menggunakan metode one-against-all, dibangun k buah model SVM biner (k adalah jumlah kelas). Setiap model klasifikasi ke-i dilatih dengan menggunakan keseluruhan data, untuk mencari solusi permasalahan (2.16). Jika hasil dari klasifikasi data baru tersebut menyatakan bahwa data tersebut bukan kelas i maka data baru tersebut di masukkan ke dalam fungsi hasil pelatihan berikutnya, sampai hasil dari klasifikasi menyatakan bahwa data baru tersebut adalah kelas i.
min1 2 (𝑤 𝑖)𝑇𝑤𝑖 + 𝐶 ∑ 𝜉 𝑡𝑖 𝑡 𝑠. 𝑡 (𝑤𝑖)𝑇 ∅(𝑥𝑡) + 𝑏𝑖 ≥ 1 − 𝜉 𝑡𝑖 → 𝑦𝑡= 𝑖, (2.16) (𝑤𝑖)𝑇 ∅(𝑥𝑡) + 𝑏𝑖 ≥ −1 + 𝜉𝑡𝑖 → 𝑦𝑡≠ 𝑖, 𝜉𝑡𝑖 ≥ 0 2.7 Karakteristik SVM
Karakteristik SVM dapat diringkas menjadi seperti berikut [21]:
1. SVM menyimpan sebagian kecil data latih untuk digunakan kembali pada saat prediksi, sebagian data yang masih disimpan merupakan support vector. 2. SVM membutuhkan komputasi pelatihan dan prediksi yang rumit karena data yang digunakan dalam proses pelatihan dan prediksi lebih besar dibandingkan dimensi sesungguhnya.
3. Untuk set data berjumlah besar SVM membutuhkan memori yang sangat besar untuk alokasi matriks kernel yang digunakan.
4. Penggunaan matriks kernel mempunyai keuntungan lain, yaitu kinerja set data dengan dimensi besar tetapi jumlah datanya sedikit akan lebih cepat karena ukuran data pada dimensi baru berkurang banyak.
2.8 Ekstraksi Fitur
Fitur adalah sebuah karakteristik pembeda yang dapat digunakan untuk mengklasifikasikan suatu soal [22]. Pada penelitian ini mengunakan 2 jenis fitur untuk proses pengklasifikasian yaitu, fitur sintaktik dan Bag-of-Words (BoW).
16 2.8.1 Fitur Sintaktik
Fitur sintaktik adalah fitur dari sebuah soal yang diekstrak berdasarkan susunan kata pada soal tersebut [22]. Berikut merupakan contoh ekstraksi fitur sintaktik yang ditunjukkan pada Tabel 2.3. Contoh soal yang yang akan diekstraksi fitur adalah
Tabel 2.3 Ekstraksi Fitur Sintaktik
tulislah faktor penghambat yang dihadapi untuk melaksanakan berbagai aktivitas ekonomi yang dominan berkembang di daerah tempat tinggalmu
Hasil Ekstraksi Kata WH Kata Kerja Kata Perbandingan Kata Definisi Kata Kausalitas Kata Penyebutan Kata
Preposisi Kata Penjelas Kata Pilihan Kata Tujuan
0 1 0 0 0 0 1 0 0 0
Kata
Cara Waktu Kata Tambahan Kata Mengingat Kata Memahami Kata Menerapkan Kata Menganalisis Kata Mengevaluasi Kata Kata Membuat
0 0 1 1 1 1 0 0 0
2.8.2 Fitur Bag-of-Words (BoW)
Semua dokumen dapat dipresentasikan secara sederhana menggunakan
Bag-of-words (BoW). BoW adalah sebuah model yang merepresentasikan objek secara global
misalnya kalimat teks atau dokumen sebagai bag (multiset) kata tanpa memperdulikan tata bahasa bahkan urutan kata untuk menjaga keanekaragamannya [23]. Dengan kata lain, BoW merupakan kumpulan kata-kata unik dalam teks dokumen untuk membentuk urutan yang berbeda kemudian dihitung frekuensi kemunculannya. Contoh sederhana pembentukan Bag-of-Words untuk teks dokumen sebagai berikut:
Tabel 2.4 Ekstraksi Fitur Bag-of-Words
tulislah faktor penghambat yang dihadapi untuk melaksanakan berbagai aktivitas ekonomi yang dominan berkembang di daerah tempat tinggalmu
Hasil Ekstraksi
tulislah faktor Penghambat Yang dihadapi untuk melaksanakan berbagai
1 1 1 2 1 1 1 1
aktivitas ekonomi Dominan berkembang Di daerah tempat tinggalmu
1 1 1 1 1 1 1 1
2.9 Metode Pengujian
Dalam melakukan pengujian pada sebuah sistem klasifikasi diperlukan metode pendukung pengujian untuk melakukan klasifikasi pada set data yang bertujuan agar kinerja dari sistem klasifikasi menghasilkan akurasi yang tepat. Umumnya, pengukuran
17
kinerja klasifikasi dilakukan menggunakan confusion matrix.
Confusion matrix adalah alat pengukuran yang dapat digunakan untuk
menghitung jumlah data uji yang benar diklasifikasikan dan jumlah data uji yang salah diklasifikasikan. Tabel confusion matrix ditunjukkan pada tabel berikut ini [24]:
Tabel 2.5 Confusion Matrix
Aktual Prediksi
Positif Negatif
Positif TP FN
Negatif FP TN
Keterangan dari tabel confusion matrix sebagai berikut:
TP (True Positive) merupakan banyaknya jumlah data yang kelas aktualnya adalah kelas positif dengan kelas prediksinya merupakan kelas positif.
FN (False Negative) merupakan banyaknya jumlah data yang kelas aktualnya adalah kelas positif dengan kelas prediksinya merupakan kelas negatif.
FP (False Positive) merupakan banyaknya jumlah data yang kelas aktualnya adalah kelas negatif dengan kelas prediksinya merupakan kelas positif.
TN (True Negative) merupakan banyaknya jumlah data yang kelas aktualnya adalah kelas negatif dengan kelas prediksinya merupakan kelas negatif. 2.9.1 Akurasi
Nilai akurasi adalah proporsi jumlah prediksi data yang benar diklasifikasikan dari kesulurah dataset [7].
Akurasi = TP + TN (2.7)
TP + TN + FP + FN 2.9.2 Presisi
Presisi adalah tingkat ketepatan hasil klasifikasi terhadap suatu kejadian.
Presisi = TP (2.8) TP + FP
2.9.3 Recall
18
kejadian dari seluruh kejadian yang seharusnya dikenali.
Recall = TP (2.9)