6
BAB II
LANDASAN TEORI
2.1. Tinjauan Pustaka
Dalam penulisan ini didapatkan beberapa teori atau materi dari berbagai sumber. Hal ini dimaksudkan untuk memudahkan dalam pengerjaannya, karena dengan suatu materi yang tepat diharapkan menghasilkan penelitian yang baik dan bermanfaat.
2.1.1. COVID-19
“COVID-19 adalah penyakit yang disebabkan oleh Novel Coronavirus (2019-nCoV), jenis baru coronavirus yang diidentifikasi untuk pertama kalinya di Wuhan, Cina, dinamai "penyakit coronavirus 2019" (COVID-19) - " CO "untuk corona," VI "untuk virus dan" D "untuk penyakit dalam bahasa Inggris” (Dejongh, 2020).
COVID-19 adalah penyakit menular yang disebabkan oleh jenis coronavirus yang baru ditemukan. Ini merupakan virus baru dan penyakit yang sebelumnya tidak dikenal sebelum terjadi wabah di Wuhan, Tiongkok, bulan Desember 2019. Gejala-gejala COVID-19 yang paling umum adalah demam, rasa lelah, dan batuk kering. Beberapa pasien mungkin mengalami rasa nyeri dan sakit, hidung tersumbat, pilek, sakit tenggorokan atau diare, Gejala-gejala yang dialami biasanya bersifat ringan dan muncul secara bertahap. Beberapa orang yang terinfeksi tidak menunjukkan gejala apa pun dan tetap merasa sehat. Sebagian besar (sekitar 80%) orang yang terinfeksi berhasil pulih tanpa perlu perawatan khusus. Sekitar 1 dari 6 orang yang terjangkit COVID-19 menderita sakit parah dan kesulitan bernapas. Orang-orang lanjut usia (lansia) dan orang-orang dengan kondisi medis yang sudah ada sebelumnya seperti tekanan darah
tinggi, gangguan jantung atau diabetes, punya kemungkinan lebih besar
serius. Mereka yang mengalami demam, batuk dan kesulitan bernapas sebaiknya mencari pertolongan medis. Orang dapat tertular COVID-19 dari orang lain yang terjangkit virus ini. COVID-19 dapat menyebar dari orang ke orang melalui percikan-percikan dari hidung atau mulut yang keluar saat orang yang terjangkit COVID-19 batuk atau mengeluarkan napas. Percikan-percikan ini kemudian jatuh ke benda-benda dan permukaan-permukaan di sekitar. Orang yang menyentuh benda atau permukaan tersebut lalu menyentuh mata, hidung atau mulutnya, dapat terjangkit COVID-19. Penularan COVID-19 juga dapat terjadi jika orang menghirup percikan yang keluar dari batuk atau napas orang yang terjangkit COVID-19. Oleh karena itu, penting bagi kita untuk menjaga jarak lebih dari 1 meter dari orang yang sakit. WHO terus mengkaji perkembangan penelitian tentang cara penyebaran COVID-19 dan akan menyampaikan temuan-temuan terbaru. (WHO, 2020).
2.1.2. Data Mining
Data mining dapat dikatakan sebagai proses mengekstrak pengetahuan dari sejumlah besar data yang tersedia. Pengetahuan yang dihasilkan dari proses data mining harus baru, mudah dimengerti, dan bermanfaat. Dalam data mining, data disimpan secara elektronik dan diproses secara otomatis oleh komputer menggunakan teknik dan perhitungan tertentu (Nofriansyah, Erwansyah, 2016). “Data mining merupakan konsep gabungan penambangan atau penemuan informasi baru dengan mencari pola atau aturan tertuntu dari sejumlah data yang sangat besar”(Setiawan, 2016).
“Adapun tahapan data mining dapat menggunakan metodologi Cross_industry Standard Process for Data Mining (CRISP-DM)” (Listriani, 2016).
Menurut Listriani, Setyaningrum, & A, (2016:122), “Dalam CRISP-DM, sebuah proyek data mining memiliki siklus hidup yang terbagi dalam enam fase”, yaitu :
1. Fase pemahaman bisnis (Bussiness Understanding Phase) 2. Fase Pemahaman Data (Data Understanding Phase) 3. Fase Pengolahan Data (Data Preparation Phase) 4. Fase pemodelan (Modelling Phase)
5. Fase Evaluasi (Evaluation Phase)
6. Fase Penyebaran (Deployment Phase).
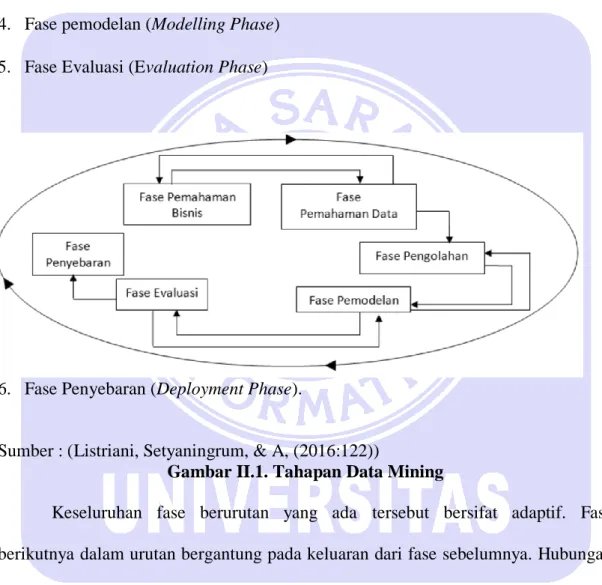
Sumber : (Listriani, Setyaningrum, & A, (2016:122))
Gambar II.1. Tahapan Data Mining
Keseluruhan fase berurutan yang ada tersebut bersifat adaptif. Fase berikutnya dalam urutan bergantung pada keluaran dari fase sebelumnya. Hubungan penting antar fase digambarkan dengan panah. Sebagai contoh, jika proses berada pada pemodelan, proses mungkin harus kembali kepada fase pengolahan untuk perbaikan atau berpindah maju kepada fase evaluasi.
Dalam penggunaan metode ini, keenam fase ini dapat dijelaskan sebagai berikut : 1. Fase Pemahaman Bisnis (Business Understanding Phase)
a. Penentuan tujuan proyek dan kebutuhan secara detail dalam lingkup bisnis atau unit penelitian secara keseluruhan.
b. Menerjemahkan tujuan dan batasan menjadi formula dari permasalahan data mining.
c. Menyiapkan strategi awal untuk mencapai tujuan. 2. Fase Pemahaman Data (Data Understanding Phase)
a. Mengumpulkan data, jika data berasal dari lebih dari satu database maka dilakukan proses integrasi data atau Data Integration.
b. Mengembangkan analisis penyelidikan data untuk mengenali lebih lanjut data pencarian pengetahuan awal.
c. Mengevaluasi kualitas data, memeriksa data dan membersihkan data yang tidak valid atau proses Data Cleaning.
d. Jika diinginkan, pilih sebagian kecil grup data yang mungkin mengandung pola dari permasalahan.
3. Fase Pengolahan Data (Data Preparation Phase)
a. Siapkan data awal, kumpulan data yang akan digunakan untuk keseluruhan fase berikutnya atau proses Data Selection.
b. Pilih kasus dan variabel yang akan dianalisis, sesuai dengan analisis yang akan dilakukan.
c. Lakukan perubahan pada variabel jika diperlukan.
d. Siapkan data awal sehingga siap untuk perangkat permodelan atau Data Transfomation.
a. Pilih dan aplikasikan teknik permodelan yang sesuai. b. Kalibrasi aturan model untuk mengoptimalkan hasil.
c. Dapat menggunakan beberapa teknik yang sama untuk permasalahan yang sama.
d. Dapat kembali ke fase pengolahan data jika diperlukan untuk menjadikan data ke dalam bentuk kebutuhan tertentu.
5. Fase Evaluasi (Evaluation Phase)
a. Mengevaluasi satu atau lebih model yang digunakan dalam fase pemodelan atau proses Evaluation Pattern.
b. Menetapkan apakah model tadi sudah sesuai dengan tujuan pada fase awal. c. Menentukan apakah terdapat permasalahan penting dari bisnis atau
penelitian yang tidak tertangani dengan baik.
d. Mengambil keputusan berkaitan dengan hasil penggunaan dari data mining.
6. Fase Penyebaran (Deployment Phase)
Menggunakan model yang dihasilkan dan dipresentasikan atau proses knowledge presentation.
Pada dasarnya menurut (Yuliga Mahena, Muhammad Rusli, 2015) aplikasi data mining digunakan untuk melakukan empat macam fungsi, yaitu:
1. Fungsi Klasifikasi (Classification).
Data mining dapat digunakan untuk mengelompokan data data yang jumlahnya besar menjadi data-data yang lebih kecil.
2. Fungsi Segmentasi (Segmentation).
Data mining juga digunakan untuk melakukan segmentasi (pembagian) terhadap data berdasarkan karakteristik tertentu.
Pada fungsi asosiasi ini, data mining digunakan untuk mencari hubungan antara karakteristik tertentu.
4. Fungsi Pengurutan (Sequencing).
Pada fungsi ini, data mining digunakan untuk mengidentifikasikan perubahan pola yang terjadi dalam jangka waktu tertentu.
Data mining sering juga disebut sebagai knowledge discovery in database (KDD). KDD adalah kegiatan yang meliputi pengumpulan, pemakaian data, historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Yang didefinisikan sebagai proses penemuan pola-pola baru dari kumpulan-kumpulan data sangat besar, meliputi metode-metode yang merupakan irisan dari artifical intelligince, machine learning, statistics dan database systm (Sulastri, 2017).
Tahapan dari proses Knowledge Discovery in Database (KDD) adalah (Muzakir & Wulandari, 2016) :
1. Data Cleaning
Memperbaiki data yang salah, menghapus data yang rusak dan tidak konsisten. 2. Data Intregration
Mengintegrasi data dari berbagai macam sumber dan menyatukan agar mudah dipilih dan diproses nantinya.
3. Data Selection
Memilih data yang dibutuhkan pada database dan digunakan untuk proses analisis.
4. Data Transformasion
Mengubah dan menggabungkan data-data dari berbagai macam bentuk menjadi satu bentuk yang sama agar mudah diproses.
5. Data Mining
Tahap untuk menerapkan metode dalam proses modeling data yang akan digunakan pada proses data mining.
6. Pattren Evaluation
Melakukan evaluasi akan patern yang telah diproses, aspek-aspek yang dievaluasi adalah hasil output yang didapat setelah proses data mining dilakukan.
7. Knowledge Presentasion
Melakukan penyajian hasil dari proses data mining yang sudah diproses. 2.1.3. Klasifikasi
Klasifikasi data adalah suatu proses yang menentukan property-property yang sama pada sebuah himpunan obyek di dalem sebuah basis data mengklasifikasikannya ke dalam kelas-kelas yang berbada menurut model klasifikasi yang ditetepakan. Tujuan dari klasifikasi adalah untuk menemukan model dari training set yang membedakan atribut ke dalam kategori atau kelas yang sesuai, model tersebut kemudian digunakan untuk mengklasifikasikan atribut yang kelasnya belom diketahui sebelumnya (Sudarsono, 2015).
2.1.4. Naïve Bayes
Naive Bayes merupakan sebuah pengklasifikasian probabilistik sederhana yang menghitung sekumpulan probabilitas dengan menjumlahkan frekuensi dan kombinasi nilai dari dataset yang diberikan. Algoritma mengunakan teorema Bayes dan mengasumsikan semua atribut independen atau tidak saling ketergantungan yang diberikan oleh nilai pada variabel kelas (Purwanto & Darmadi, 2018).
“ Naïve Bayes Classifier merupakan salah satu algoritma dalam teknik data mining yang menerapkan teori Bayes dalam klasifikasi” (Junianto and Riana, 2017).
“Naïve Bayes Classifier merupakan pengklasifikasian statistik yang dapat digunakan untuk memprediksi probabilitas keanggotaan suatu class. Naïve Bayes Classfier terbukti memiliki akurasi dan kecepatan yang tinggi saat diaplikasikan ke dalam database dengan data yang besar kelas lainnya” (Agustina, 2017).
Persamaan Theorema Bayes (Zacharski, 2012) : ( | ) ( | ) ( )
( ) Keterangan:
B : Data dengan class yang belum diketahui A : Hipotesis data merupakan suatu class spesifik
P(A|B) : Probabilitas hipotesis A berdasaran kondisi B (posterior probabilitas) P(A) : Probabilitas hipotesis A (prior probabilitas)
P(B|A) : Probabilitas B Berdasarkan kondisi pada hipotesis A P(B) : Probabilitas B
Rumus diatas disesuaikan untuk Naïve Bayes sebagai berikut : ( | ) ( | ) ( )
( )
P(B) harus dimaksimumkan karena nilainya sama untuk semua kelas, sehingga rumus diatas disederhanakan lagi ke dalam bentuk seperti dibawah ini: ( | ) ( | ) ( )
Asumsi sederhana dalam Naïve Bayes adalah semua atribut kondisinya independen. Jadi tahapan rumusan kelas bagi data tes adalah berdasarkan rumus berikut:
( | ) ∏ ( | )
* ( | ) ( )+
Sebagai contoh bila ada data baru dan nilai posterior probabilitasnya P(A2|B)
memiliki nilai paling besar di antara semua posterior probabilitas P(Ak|B) untuk
sejumlah k kelas, maka data tersebut termasuk ke dalam kelas A2.
2.1.5. Backward Elimination
Menurut (Samosir, Siagian, & Bangun, 2014) Metode backward merupakan langkah mundur, semua variabel X diregresikan dengan variabel Y . Pengeliminasian variabel X didasarkan pada nilai F(parsial) terkecil dan turut tidaknya variabel X pada model juga diten- tukan oleh nilai F(tabel). Metode backward merupakan metode regresi yang baik karena dalam metode ini dijelaskan perilaku variabel respon dengan sebaik-baiknya dengan memilih variabel penjelas dari sekian banyak variabel penjelas yang tersedia dalam data, adapun Langkah-langkah Backward Elimination adalah :
1. Mulai semua variabel pada model F- statistik parsial dihitung setiap variabel pada model.
2. Menentukan variabel dengan F-statistik parsial terkecil dan menguji Fmin. 3. Mulai semua variabel pada model F- statistik parsial dihitung setiap variabel
pada model.
4. Menentukan variabel dengan F-statistik parsial terkecil dan menguji Fmin. 5. Jika Fmin tidak signifikan, dalam kasus ini, variabel dihilangkan dari model. 6. Menentukan variabel dengan F- statistik parsial .
7. Pada sisi lain, variabel dengan F- statistik terkecil adalah variabel indikator. Bagaimanapun, p-value diasosiasikan dengan Fmin tidak cukup membenarkan model yang tidak inklusi (noninclusion) menurut kriteria (lebih dari bit). Maka dari itu, prosedur menghasilkan dan melaporkan model sebagai berikut: y= ß0
+ ß1(single epithelial cell size) + ß2(normal nucleoli) + ß3(marginal adhesion) + e
8. Menghitung F-test parsial.
2.1.6. Rapidminer
Rapidminer adalah salah satu software untuk pengolahan data mining. Pekerjaan yang dilakukan oleh rapidminer text mining adalah berkisar dengan analisis teks, mengekstrak pola-pola dari dataset yang besar dan mengkombinasikannya dengan metode statistika, kecerdasan buatan, dan database. Tujuan dari analisis teks ini adalah untuk mendapatkan informasi bermutu tertinggi dari teks yang diolah. RapidMiner menyediakan prosedur data mining dan machine learning, di dalamnya termasuk: ETL (extraction, transformation, loading), data preprocessing, visualisasi, modelling dan evaluasi. Proses data mining tersusun atas operator-operator yang nestable, dideskripsikan dengan XML, dan dibuat dengan GUI. Penyajiannya dituliskan dalam bahasa pemrograman Java. (Mochammad Faid, Moh. Jasri, Titasari Rahmawati, 2019)
2.1.7. Evaluasi dan Validasi
“Validasi adalah proses mengevaluasi akurasi dari sebuah model, validasi mengacu untuk mendapatkan prediksi dengan menggunakan model yang ada kemudian membandingkan hasil yang diperoleh dengan hasil yang diketahui” (Gorunescu, 2013).
“Mengevaluasi akurasi dari model klasifikasi sangat penting, akurasi dari sebuah model mengindikasikan kemampuan model tersebut untuk memprediksi class target” (Vercellis, 2009).
Menurut (Alfisahrin, 2014) Untuk mengevaluasi model digunakan metode Confusion Matrix dan Kurva ROC (Receiver Operating Characteristic).
1. Confusion Matrix
“Evaluasi kinerja model klasifikasi didasarkan pada pengujian objek yang diprediksi dengan benar dan salah, hitungan ini ditabulasikan Confusion Matrix” (Gorunescu, 2013).
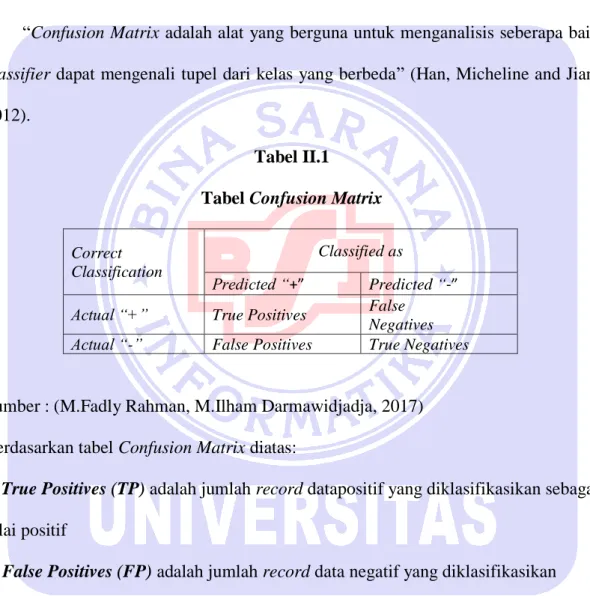
“Confusion Matrix adalah alat yang berguna untuk menganalisis seberapa baik classifier dapat mengenali tupel dari kelas yang berbeda” (Han, Micheline and Jian, 2012).
Tabel II.1
Tabel Confusion Matrix
Correct Classification
Classified as
Predicted “+” Predicted “-”
Actual “+” True Positives False Negatives Actual “-” False Positives True Negatives
Sumber : (M.Fadly Rahman, M.Ilham Darmawidjadja, 2017) Berdasarkan tabel Confusion Matrix diatas:
a. True Positives (TP) adalah jumlah record datapositif yang diklasifikasikan sebagai nilai positif
b. False Positives (FP) adalah jumlah record data negatif yang diklasifikasikan sebagai nilai positif
c. False Negatives (FN) adalah jumlah record data positif yang diklasifikasikan sebagai nilai positif
d. True Negatives (TN) adalah jumlah record data negatif yang diklasifikasikan sebagai nilai negative
sebagai berikut :
a. Accuracy, presentase jumlah record data yang diklasifikasikan (prediksi) secara benar oleh algoritma
Rumus : (TP + TN) / Total data = Accuracy
b. Misclassification (Error) Rate, presentase jumlah record data yang diklasifikasikan (prediksi secara salah oleh algoritma.
Rumus : (FP + FN) / Total data = Misclassification Rate 2. Kurva ROC
“Kurva ROC banyak digunakan untuk menilai hasil prediksi, kurva ROC adalah teknik untuk memvisualisasikan, mengatur, dan memilih pengklasifikasian berdasarkan kinerja algoritma. Untuk klasifikasi data mining, nilai AUC dapat dibagi menjadi beberapa kelompok” (Gorunescu, 2013):
0.90 – 1.00 = Excellent Classification 0.80 – 0.90 = Good Classification 0.70 – 0.80 = Fair Classification 0.60 – 0.70 = Poor Classification 0.50 – 0.60 = Failure 2.2. Penelitian Terkait
Dalam penelitian (Gorontalo & Bayes, 2017) klasifikasi nasabah asuransi jiwa menggunakan algoritma naïve bayes berbasis backward elimination, membuktikan bahwa Naïve Bayes dan Backward Elimination lebih baik daripada hanya menggunakan metode naïve bayes saja. Hasil akurasi yang didapatkan menggunakan Naïve Bayes yaitu 83,02% sedangkan Naïve Bayes dan Backward Elimination 85,89%. Dapat disimpulkan bahwa menggunakan metode Naïve Bayes dan Backward Elimination tingkat akurasi yang dihasilkan tinggi.
Dalam penelitian (Sulaehani, 2016) Prediksi keputusan klien telemarketing untuk deposito pada bank menggunakan algoritma naïve bayes berbasis backward elimination, membuktikan hasil analisis dapat dibandingkan metode algoritma Naïve Bayes dan Backward Elimination lebih baik daripada hanya menggunakan metode Naïve Bayes saja. Hasil accuracy yang didapatkan dengan menggunakan Naïve Bayes yaitu 89,08% sedangkan Naïve Bayes dan Backward Elimination 90,69%. Dapat disimpulkan bahwa metode Naïve Bayes dan Backward Elimination tingkat accuracy yang dihasilkan tinggi.
2.3. Tinjauan Objek Penelitian
PIKOBAR merupakan aplikasi Pusat Informasi dan Koordinasi Wabah Penyakit dan Bencana Jawa Barat. berbagai kemudahan mengakses ragam informasi terkait perkembangan penanganan bencana dan wabah penyakit di Jawa Barat dalam genggaman tangan. PIKOBAR dikembangkan oleh Jabar Digital Service atau Unit Pelayanan Teknis Pelayanan Digital, Data, dan Informasi Geospasial di bawah Dinas Komunikasi dan Informatika Pemerintah Provinsi Jawa Barat.
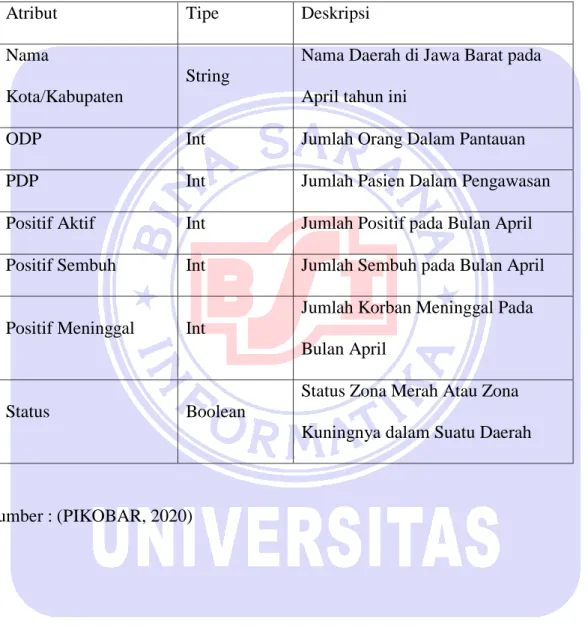
Pada table II.2 dapat dilihat set atribut berisi informasi yang berkaitan dengan kondisi Nama Kota/Kabupaten, ODP, PDP, Positif Aktif, Positif Sembuh, Positif Meninggal dan Status. Pada Tabel II.2 dapat dilihat pengelompokan setiap atribut berdasarkan kategori penilaian yang digunakan dalam dataset untuk mengklasifikasikan resiko tingkat kerentanan COVID-19 .
Tabel II.2.
Fitur dan Deskripsi Dataset COVID-19
Atribut Tipe Deskripsi
Nama
Kota/Kabupaten
String
Nama Daerah di Jawa Barat pada April tahun ini
ODP Int Jumlah Orang Dalam Pantauan
PDP Int Jumlah Pasien Dalam Pengawasan
Positif Aktif Int Jumlah Positif pada Bulan April Positif Sembuh Int Jumlah Sembuh pada Bulan April
Positif Meninggal Int
Jumlah Korban Meninggal Pada Bulan April
Status Boolean
Status Zona Merah Atau Zona Kuningnya dalam Suatu Daerah