JURNAL DATA SCIENCE & INFORMATIKA (JDSI)
Vol. 1 No. 2 (2021) 26-31 ISSN Media Elektronik: 2808-9987
Klasifikasi Pendapaatan Puskesmas Kalijaga Permai Dengam Menggunakan Naïve Bayes
Yuni Anjani1, Odi Nurdiawan2, Dian Ade Kurnia3,Dita Rizki Amalia4,Irfan Ali5,
1Program Studi Komputer Akuntansi ,STIMIK IKMI CIREBON
2.3.4Program Studi Manajemen Informatika, STIMIK IKMI CIREBON
5Program Studi Rekayasa Perangkat Lunak, STIMIK IKMI CIREBON
1[email protected] * , 2[email protected] 3[email protected] , 4[email protected]
Abstract
Puskesmas is one of the health service agencies that has a very important role in people's lives. This research was carried out at the Kalijaga Permai Health Center in Kalijaga Village, Harjamukti District, Cirebon City.In this study, the income classification of puskesmas was carried out using one of the classification algorithms. The nave Bayes method is a simple probabilistic classifier that calculates a set of probabilities by adding up the frequency and combination of values from a given dataset.The data used is data from the Kalijaga Permai Health Center on April 26, 2021 to May 3, 2021 with a total of 330 patients, 191 patients in public rooms, 23 dental patients, 72 pediatric patients in the Midwife's room, 44 patients. The Naive Bayes method used is 80% training data and 20%
testing data from 330 data. The results obtained with the number of True Positive (TP) are 25 records. By being classified as “yes prepaid”, there are 36 False Negative (FN) records and 92,42%. accuracy is obtained.
Keywords: abstract keywords Puskesmas, Financial Reporting, Naive Bayes Abstrak
Puskesmas merupakan salah satu badan pelayanan kesehatan yang memiliki peran sangat penting dalam kehidupan masyarakat Penelitian ini dilaksanakan pada Puskesmas Kalijaga Permai di Kelurahan kalijaga Kecamatan Harjamukti Kota Cirebon.Pada penelitian ini dilakukan pengklasifikasian pendapatan puskesmas dengan menggunakan salah satu algoritma pengklasifikasian. Metode naïve bayes merupakan sebuah pengklasifikasian probabilistic sederhana yang menghitung sekumpulan probabilitas dengan menjumlah frekuensi dan kombinasi nilai dari dataset yang telah diberikan.Data yang digunakan adalah data dari Puskesmas Kalijaga Permai pada tanggal 26 April 2021 sampai dengan 3 Mei 2021 dengan jumlah pasien sebanyak 330 Jumlah pasien pada ruang umum sebanyak 191, pasien gigi sebanyak 23 ,Pasien Anak sebanyak 72 Pasien ruang Bidan sebanyak 44 Pasien.
Pada metode naive bayes yang digunakan adalah 80% data training dan 20% data testing dari 330 data. Hasil yang didapatkan dengan jumlah True Positive (TP) adalah 25 record. Dengan diklasifikasikan sebagai “ya prabayar”, False Negativ (FN) sebanyak 36 record dan didapatkan akurasi 92,42%.
Kata kunci: Puskesmas, Pelaporan Keuangan, Naive Bayes.
1. Pendahuluan
Kesehatan merupakan salah satu kebutuhan utama seseorang untuk melakukan aktivitas. Kesehatan sendiri tidak bisa lepas dari Puskesmas. Puskesmas merupakan salah satu badan pelayanan kesehatan yang memiliki peran sangat penting dalam kehidupan masyarakat. Puskesmas Kalijaga Permai di Kelurahan kalijaga Kecamatan Harjamukti Kota Cirebon,Puskesmas Kalijaga Permai merupakan salah satu intansi yang jumlah pasien yang banyak dikarenakan jumlah penduduk yang sangat luas dan di wilayah Kalijaga Permai ini, di Puskesmas Kalijaga Permai termasuk masyarakat yang berproduktif, sehingga faktor kepadatan penduduk dan keadaan infrastruktur yang harus memadai di wilayah ini maka dari itu harus menyeimbangan pelayanan kesehatan yang baik pada wilayah tersebut[1]
Pada penelitian ini dilakukan pengklasifikasian pendapatan puskesmas dengan menggunakan salah satu algoritma pengklasifikasian. Metode naïve bayes merupakan sebuah pengklasifikasian probabilistic sederhana yang menghitung sekumpulan probabilitas dengan menjumlah frekuensi dan kombinasi nilai dari dataset yang telah diberikan. Pendapatan adalah salah satu jumlah uang atau barang yang diterima oleh suatu perusahaan dari sebuha aktivitas yang dilakukannya. Pendapatan pada puskesmas. Pendapatan pada Puskesmas harus dikelola secara profesional pada tenaga kerja Puskesmas. Menurut larose, data mining merupakan suatu proses dalam menggali pola, kecenderungan, ataupun memahami hubungan dari berbagai variable melalui serangkaian pemeriksaan terhadap sekumpulan data yang dimiliki dengan menggunakan teknik statistic ataupun matematika.
[2]
Pada contoh tabel diatas merupakan penelitian yang dilakukan di Puskesmas Kalijaga Permai pada tanggal 26 April 2021 sampai dengan 3 Mei 2021 dengan jumlah pasien sebanyak 330 Jumlah pasien pada ruang umum sebanyak 191, pasien gigi sebanyak 23 ,Pasien Anak sebanyak 72 Pasien ruang Bidan sebanyak 44 Pasien.
Permasalahan utama dalam akuntansi untuk pendapatan adalah kapan seharusnya Puskesmas mengakui pendapatan serta bagaimana seharusnya
puskesmas melakukan pencatatan atas pendapatan yang tidak terealisasi atas pasien yang tidak mampu atau pasien yang masih dalam pemeriksaan.
Pengklasifikasian pendapatan pada puskesmas kalijaga permai perlu dilakukan untuk memprediksi pembayaran pasien dari label pada pasien yang belum diketahui untuk itu perlu menggunakan metode Naïve Bayes dakam menentukan klasifikasi.
Untuk itu diperlukan suatu metode untuk mengevaluasi pendapatan puskesmas agar dapat menentukan kapan suatu pendapatan dari suatu puskesmas harus diakui sebagai pendapatan dalam laporan puskesmas. Jika laporan pendapatan dicatat baik maka keuntungan yang diperoleh perusahaan cukup tinggi, dan jika beban yang dicatat kurang baik, maka keuntungan yang diperoleh perusahaan akan rendah. Kekeliruan ini akan mempengarui pengambilan kebijakan oleh perusahaan yang berakibat terhadap kelangsungan perusahaan. Oleh karena itu puskesmas harus menerapkan Standar Akuntansi Keuangan dalam penyusunan pelaporan, dan pelaporan keuangannya termasuk juga pengakuan pendapatannya.
2. Metode Penelitian
Pada penelitian ini data yang diambil yaitu data kunjungan pasien pada tanggal 3 mei 2021 di Puskesmas Kalijaga Permai.
2.1 Data Mining Menggunakan Metode Naive Bayes Data Mining merupakan proses kegiatan untuk mngumpulkan data yang berukuran besar kemudian mengekstrasi data tersebut menjadi informasi yang nantinya dapat digunakan pada sebuah kasus. Naive Bayes merupakan prediksi berbasis probabilitas sederhana yang berdasarkan pada penerapan teorema Bayes dengan asumsi independensi yang kuat. Berikut persamaan teorema bayes adalah :
P = (H|X) =P(H|X)P(H) P (X) Keterangan :
X = Data dengan class yang belum diketahui
H = Hipotesis data X merupakan suatu class spesifik
P (H|X) = Probabilitas hipotesis H berdasarkan kondisi x (posteriori prob)
P (H) = Probabilitas hipotesis H (prior prob)
P (X|H) = Probabilitas X berdasarkan kondisi tersebut
P (X) = Probabilitas dari X
2.2 Klasifikasi Data
Jenis data yang diperlukan dalam penelitian ini dikelompokkan menjadi dua, yaitu data menurut sifatnya dan data menurut sumbernya.[3]
Data Menurut Sifatnya
Menurut sifatnya jenis data yang digunakan dalam tugas akhir ini yaitu:
a. Data Kualitatif.
Data kualitatif yang digunakan dalam penelitian ini meliputi gambaran umum, visi dan misi, struktur organisasi, tugas dan wewenang karyawan dan kebijakan prosedur yang diterapkan oleh UPTD Puskesmas Kalijaga Permai.
b. Data Kuantitatif
Data kuantitatif yang digunakan berupa Laporan Pendapatan Pasien, Laporan Operasional, Laporan Perubahan
Data Menurut Sumbernya
Jenis data menurut sumbernya dibedakan menjadi dua, yaitu data primer dan data sekunder. Pada penelitian ini tidak menggunakan data primer dan hanya menggunakan data sekunder. Data sekunder yang diperoleh berupa dokumen profil UPTD Puskesmas Kalijaga Permai, Laporan pendapatan pasien, Laporan Operasional, Laporan Perubahan, dan Catatan Laporan Keuangan
Tahapan Penelitian
Pada tahap penelitian ini dilakukan pertama kali adalah proses identifikasi masalah dan dilanjutkan dengan menggunakan metode naive bayes, dapat di gambarkan sebagai berikut:
Gambar 1. Tahapan Penelitian
Pada gambar diatas dapat dijelaskan sebagai berikut :
1. Identifikasi masalah: Identifikasi masalah merupakan tahap awal penelitian dan mengidentifikasi permasalahan yang muncul seperti dalam proses penentuan data pendapatan pada puskesmas Kaligaja Permai.
2. Pengumpulan data: Dalam penelitian ini penelitian mengambil data kunungan pasien pada tanggal 3 mei 2021 di Puskesmas Kalijaga Permai.
3. Seleksi data: Dalam Tahap ini dilakukan pemillihan atribut mana yang akan menjadi target penentu ,atribut yang dipakai adalah atribut jeni prabayar.
4. Mising Value: Tahap ini adalah tahap untuk mengisi nilai data jika terdapat nilai kosong 5. Perhitungan probabilitas: Perhitungan
probabilitas ini untuk mencari nilai probabilitas dari setiap variabel label.
6. Proses naive bayes: Setelah data diperoleh kemudian di proses menggunakan rapid miner dengan metode naive bayes.Selanjutnya setelah semua data di proses pada rapid miner maka akan diperoleh sebuah hasil.
3. Hasil dan Pembahasan
Hasil yang diperoleh pada penelitian ini adalah dari beberapa tahapan penelitian meliputi identifikasi masalah, pengumpulan data, pengelolaan data, perhitungan probabilitas, proses naive bayes dan kemudian didapatkan hasil dari penelitian ini.
3.1 Pengumpulan data
Metode Pengumpulan data adalah cara-cara yang dapat dipergunakan untuk mengumpulkan data, serta menguji data dari informasi yang telah dikumpulkan. Metode pengumpulan data yang diperlukan untuk memperoleh data yang akurat berupa:
a. Wawancara
Wawancara yang dilakukan adalah dengan mengajukan pertanyaan- pertanyaan kepada
bagian administrasi dan tata usaha UPTD Puskesmas kalijaga permai mengenai penerapan laporan pendapatan yang disusun berdasarkan pertanyaan yang telah disusun sebelumnya.
Informasi yang diperoleh bertujuan untuk untuk mendapatkan pemahaman penyusunan laporan pendapatan pada UPTD Puskesmas.
b. Studi Dokumenter
Studi pustaka dilakukan dengan membaca dan memahami dokumen-dokumen seperti buku, catatan dan bentuk dokumen lainnya. Dalam penelitian ini studi pustaka dilakukan dengan pencarian data dan informasi yang mendukung penyusunan Tugas Akhir ini, yaitu yang mendasari tentang penyajian laporan pendapatan.
c. Dokumenter
Dokumen yang diperoleh berupa profil UPTD Puskesmas kalijaga permai, laporan pendapatan
tahun 2021. Data yang didapat sebanyak 330 pasien pada tanggal 26 April sampai dengan 3 Mei 2021
3.2 Metode Pengolahan Data
Dari data yang diperolah pada tanggal 26 April 2021 sampai dengan 3 Mei 4.
3.3 Perhitungan Probabilitas
Dari 330 data yang digunakan terdapat dua kelas yaitu kelas C1 dengan Jenis prabayar adalah “Ya Prabayar” dan kelas C2 dengan jenis prabayar adalah
“Tidak Prabayar”.
Hitung P(X|Ci) untuk kelas C1 dan C2:
P(Jenis Prabayar="Ya prabayar") =164/330
=0,496
P(Jenis Prabayar="tidak prabayar") =166/330
=0,503
Perhitungan probabilitas poli ruang anak:
X=
poli ruangan="Anak", Harga="10.000", Asuransi="BPJS", PENYELESAIAN I
menghitung P(X|Ci) untuk class= 1, 2
P(Poli ruangan="Anak|jenis prabayar="ya prabayar"
=54/164 = 0,329
P(Poli ruangan="Anak|jenis prabayar="tidak prabayar" =18/166 = 0,108
P(Harga="10.000|jenis prabayar="ya prabayar"
=50/165 = 0,304
P(Harga="10.000|jenis prabayar="tidak prabayar"
=22/166 = 0,132
P(Asuransi="BPJS|jenis prabayar="ya prabayar"
=54/164 = 0,329
P(Asuransi="BPJS|jenis prabayar="tidak prabayar"
=18/166 = 0,108 3.4 Proses Naive Bayes
Proses naive bayes dilakukan setelah proses pengelolaan data awal sejumlah 330 data dan selajutnya data diolah menggunakan rapid miner, tahap ini penentuan data training dan data testing.
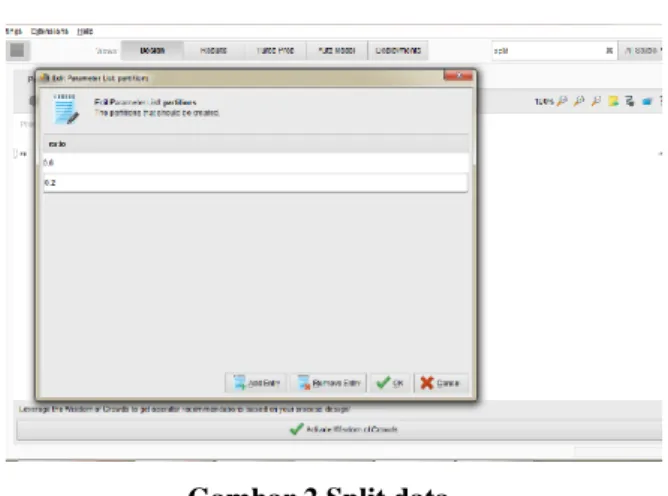
Data training yang digunakan sebesar 80% dan data testing yang digunakan adalah 20%.
Gambar 2 Split data
Gambar 3 Proses rapid miner
Pada proses rapid miner terdapat dua data yaitu data training dan data testing yang fungsi data training adalah untuk melatih suatu algoritma dan fungsi data testing adalah untuk mengetahui apakah model sudah akurat di validasi. Tujuan pada penelitian ini merupakan untuk mengetahui nilai akurasi dari algortima naive bayes yang digunakan untuk mengklasifikasi pendapatan puskesmas kalijaga permai. Dari Hasil Nave Bayes di dapatkan confusion Matrix dengan data testing 20% 66 data artinya dalam perhitungan dalam rapid mener jika menemui angka decimal maka akan di bulatkan kebawah sehingga data testing yang akan kami tampilkan sebanyak 66 data Hasil dari pengujian model yang dilakukan adalah untuk mengukur tingkat akurasi pada pengujian tools rapid miner dengan jumlah data 330 record dengan data training 80% dan data testing 20%. Berikut gambar yang didapat:
Gambar 4 Performance Vector
Berdasarkan gambar diatas menunjukan bahwa tingkat akurasi dengan menggunakan algoritma naive bayes dengan jumlah 330 data yang dihasilkan dari proses data training dan data testing dengan data training 80% dengan total 264 data dan data testing 20% dengan total 66 data. Diperoleh akurasi sebesar 92.42%. Fungsi dari data training dan data testing yaitu data training digunakan untuk melatih algoritma sedangkan data testing digunakan untuk mengetahui performa algoritma yang sudah dilatih sebelumnya ketika menemukan data baru yang belum pernah dilihat sebelumnya. Pada hasil performance vector didapatkan akurasi 92.42%
dengan rincian sebagai berikut:
a. Prediksi Tdk Prabayar dan ternyata true tdk prabayar sebesar 36
b. Prediksi tdk prabayar dan ternyata true ya prabayar sebesar 3
c. Prediksi ya prabayar dan ternyata true tdk prabayar sebesar 2
d. Prediksi ya prabayar dan true ya prabayar sebesar 25
e. Dengan classrecal tru tdk prabayar 94,74%
dan class recall true ya prabayar sebesar 82,29%.
3.5 Proses C.45
Untuk menguji algoritma mana yang lebih cocok, penulis melakukan perhitungan juga dengan menggunakan algoritma Decision Tree. Berikut hasil perhitungannya.
3.6 Pembahasan
Berdasarkan dari penelitian diatas maka dari beberapa tahapan metode penelitian didapatkan dari tahap identifikasi masalah yaitu data yang diperoleh merupakan data pendapatan perhari dan permasalahan yang dihadapi adalah diperlukannya pengklasifikasian untuk memprediksi pasien yang membayar dan tidak membayar. Selanjutnya pada tahap pengelolaan data terdapat 3 metode yang digunakan yaitu wawancara, studi dokumentar dan dokumentar. Tahap wawancara dilakukan untuk mendapatkan informasi dari pasien apakah mengunakan asuransi berupa BPJS atau tidak. Tahap studi dokumentar dilakukan untuk memahami dokumen-dokumen atau catatan pada puskesmas Kalijaga Permai, selanjutnya tahap dokumentar merupakan tahapan pendokumentasian jumlah pendapatan pasien perhari. Selanjutnya pada tahap pengelolaan data, data yang diambil adalah data pendapatan perhari pada tanggal 26 April 2021 sampai dengan 3 Mei 2021 dari beberapa atribut yang digunakan yaitu nama, poli ruangan, harga dan asuransi. Pada tahap perhitungan probabilitas yang akan di hitung yaitu probabilitas prior poli ruangan anak, bidan, gigi dan umum. Tahapan selanjutnya yaitu proses rapid miner dengan nilai akurasi algoritma klasifikasi naive bayes classifier adalah 92,42%.Hasil C.45 menunjukan nilai accuracy 84,08%, precision 94,80%, dan recall 93,62%. Dari perbandingan nilai akurasi kedua operator tesebut, penulis lebih memilih menggunakan metode Naive Bayes karena nilai akurasi C.45 yang mencapai 84,08% meskipun dari hasil C.45 lebih kecil di bandingkan Naive Bayes , maka dari itu saya mengambil akurasi hasil yang lebih besar dari ke dua jenis klasifikasi dengan mengambil klasifikasi naïve bayes dengan hasil acurasi 92,42%.
4. Kesimpulan
Pengelolaan pendapatan pada puskesmas Kalijaga Permai ini menggunakan metode naive bayes untuk mengklasifikasi suatu data yang diperoleh pada tanggal 26 April 2021 sampai dengan 3 Mei 2021.
Permasalahan yang dihadapi pada penelitian ini adalah puskesmas harusnya mengakui pendapatan
dan pengelolaan pencatatan pada suatu pendapatan yang tidak terealisasi atas pasien yang tida mampu atau pasien dalam pemeriksaan. Perlu adanya pengklasifikasian data untuk memprediksi pembayaran pasien di Puskesmas Kalijaga Permai.
Data yang didapat pada tanggal 26 April 2021 sampai dengan 3 Mei 2021 sebanyak 330 data yang dihasilkan dari proses data training dan data testing dengan data training 80% dengan total 264 data dan data testing 20% dengan total 66 data. Diperoleh akurasi sebesar 92,42%.
Daftar Pustaka
[1] Ira and C. I. Merina, “Laporan Keuangan Badan Layanan Umum Pada Puskesmas,” no. 13, pp.
65–73, 2020.
[2] L. Yuwono, M. E. Fadillah, M. Indrayani, W. Maesarah, A. Ramadhan, and S. F. Panjaitan,
“Klasifikasi Pendapatan Pedagang Kaki Lima Dan Pelaku Usaha Online Akibat Dampak Covid-19 Menggunakan Metode Naive Bayes,” vol. 2, no. 1, pp. 1–6, 2021.
[3] Mulyawan, G. Dwilestari, A. Bahtiar, F. M.
Basysyar, and N. Suarna, “Classification of human development index using particle swarm optimization based on support vector machine algorithm,” IOP Conf. Ser. Mater. Sci. Eng., vol.
1088, no. 1, p. 012033, 2021, doi: 10.1088/1757- 899x/1088/1/012033.