ANALISIS SENTIMEN NETIZEN TWITTER MENGGUNAKAN EKSTRAKSI TF-IDF (TERM FREQUENCY AND INVERSE DOCUMENT FREQUENCY)
DAN METODE MULTILAYER PERCEPTRON PADA PILKADA KOTA MEDAN 2020
SKRIPSI
MUNTAQIM ASBUCH 151401090
PROGRAM STUDI S-1 ILMU KOMPUTER
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2021
ANALISIS SENTIMEN NETIZEN TWITTER MENGGUNAKAN EKSTRAKSI TF-IDF (TERM FREQUENCY AND INVERSE DOCUMENT FREQUENCY)
DAN METODE MULTILAYER PERCEPTRON PADA PILKADA KOTA MEDAN 2020
SKRIPSI
Diajukan untuk melengkapi tugas akhir dan memenuhi syarat memperoleh ijazah Sarjana S-1 Ilmu Komputer
MUNTAQIM ASBUCH 151401090
PROGRAM STUDI S-1 ILMU KOMPUTER
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2021
PERNYATAAN
ANALISIS SENTIMEN NETIZEN TWITTER MENGGUNAKAN EKSTRAKSI TF-IDF (TERM FREQUENCY AND INVERSE DOCUMENT FREQUENCY)
DAN METODE MULTILAYER PERCEPTRON PADA PILKADA KOTA MEDAN 2020
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing – masing telah disebutkan sumbernya.
Medan, 16 Maret 2021
Muntaqim Asbuch 151401090
PENGHARGAAN
Puji dan syukur atas kehadirat Allah SWT yang telah memberikan rahmat dan hidayah-Nya, sehingga penulis dapat menyelesaikan penyusunan skripsi ini sebagai syarat memperoleh gelar Sarjana Komputer pada Program Studi S-1 Ilmu Komputer, Fakultas Ilmu Komputer dan Teknologi Informasi Univeristas Sumatera Utara.
Dengan segala kerendahan hati, penulis ingin menyampaikan rasa hormat dan terimakasih yang sebesar-besarnya kepada semua pihak yang telah membantu dalam penyelesaian skripsi ini. Penulis mengucapkan terimakasih kepada :
1. Bapak Dr. Muryanto Amin, S.Sos, M.Si selaku Rektor Universitas Sumatera Utara.
2. Bapak Prof. Dr. Opim Salim Sitompul, M.Sc selaku Dekan Fakultas Ilmu Komputer dan Teknologi Informasi, Universitas Sumatera Utara.
3. Bapak Dr. Poltak Sihombing, M.Kom selaku Ketua Program Studi S-1 Ilmu Komputer Universitas Sumatera Utara dan Dosen Pembimbing Akademik yang telah memberi arahan selama masa perkuliahan.
4. Bapak Herriyance S.T., M.Kom selaku Sekretaris Program Studi S1 Ilmu Komputer Universitas Sumatera Utara.
5. Bapak Dr. Syahril Efendi, S.Si., M.IT selaku Dosen Pembimbing I yang telah memberikan bimbingan, saran, dan motivasi kepada penulis dalam pengerjaan skripsi ini.
6. Bapak Jos Timanta Tarigan, S.Kom., M.Sc selaku Dosen Pembimbing II yang telah memberikan arahan, masukan dan dukungan kepada penulis dalam pengerjaan skripsi ini.
7. Seluruh dosen dan staf pegawai Program Studi S1 Ilmu Komputer Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
8. Kedua orangtua penulis tercinta Ayahanda Bukhari Usman dan Ibunda Asmah Mariani serta abangda Muhaimin Asbuch dan Adinda Farah
Nafissa tercinta atas do’a, dukungan, perhatian, kesabaran, pengorbanan dan kasih sayang tulus yang tak ternilai harganya.
9. Teman-teman seperjuangan sekaligus sahabat semasa kuliah yang selama ini Indra Maulana Tarigan, Chairul Reza, Defri Muhammad Chaniago, Yogi Irhandi Simamora telah menjadi tempat berbagi suka dan duka, yang telah memberikan motivasi, hiburan, dan dukungan yang tak ternilai kepada penulis.
10. Teman-Teman Rumoh Balam Muhammad Abrar, Taufiqqurrahman, Reza Dhia Ulhaq, Muhammad Fadli dan Kahlil Mirzani yang telah memberikan dukungan kepada penulis
11. Teman-Teman Stambuk 2015 Terkhusus KOM C 2015 yang menjadi pengingat dan memberikan motivasi kepada penulis.
12. Ansya yang telah membantu penulis dalam pelabelan data pada pengerjaan skripsi ini.
13. Dan semua pihak yang terlibat secara langsung maupun tidak langsung yang telah banyak membantu yang tidak bisa disebutkan satu-persatu.
Semoga semua kebaikan, bantuan, perhatian, serta dukungan yang telah diberikan kepada penulis mendapatkan berkat yang melimpah dari Allah SWT.
Medan, 16 Maret 2021
Penulis
ANALISIS SENTIMEN NETIZEN TWITTER MENGGUNAKAN EKSTRAKSI TF-IDF (TERM FREQUENCY AND INVERSE DOCUMENT
FREQUENCY) DAN METODE MULTILAYER PERCEPTRON PADA PILKADA KOTA MEDAN 2020
ABSTRAK
Indonesia memiliki 19,5 juta pengguna Twitter dari total 500 juta pengguna global dan terus berkembang seiring berjalannya waktu. Penggunaan Twitter sebagai wadah Kampanye secara terbuka oleh para Calon Walikota Medan dan para relawannya memicu Netizen untuk menanggapinya. Tanggapan Netizen ini terdiri dari Positif dan Negatif. Oleh karena itu, penelitian ini mencoba menganalisis tweet mengenai sentimen netizen mengenai Pilkada Kota Medan tahun 2020.
Opini atau sentiment dari Netizen Twitter tentu dapat digunakan sebagai kritik dan saran yang dapat ditampung oleh Calon Walikota dan Wakil Walikota Medan.
Netizen Twitter sering beropini tentang Calon Kepala daerah melalui Unggahannya. Opini para Netizen Twitter tersebut masih acak atau belum terklasifikasi. Untuk memudahkan proses pengklasifikasian Data opini para Netizen dibutuhkan suatu Sentimen Analisis. Analisis Sentimen ini dilakukan dengan melakukan klasifikasi tweet yang berisi sentimen Netizen terhadap Pelaksanaan Pilkada Kota Medan 2020. Metode klasifikasi yang digunakan dalam penelitian ini adalah metode Multilayer Perceptron dengan fungsi aktifasi relu dan fungsi optimasi adam yang dikombinasikan dengan fitur ekstraksi TF-IDF. Uji validitas yang diterapkan pada penelitian ini menggunakan matrik konfusi.
Penggunaan ekstraksi fitur tf-idf dan metode multilayer perceptron mampu melakukan klasifikasi analisis sentimen secara otomatis dengan akurasi sebesar 92,733%.
Kata Kunci: Analisis Sentimen, Tf-idf, Multilayer Perceptron.
SENTIMENT ANALYSIS TWITTER NETIZENS WITH TF-IDF FEATURE EXTRACTION (TERM FREQUENCY AND INVERSE DOCUMENT FREQUENCY) AND MULTILAYER PERCEPTRON
METHODS ON THE 2020 ELECTION OF MEDAN CITY
ABSTRACT
Indonesia has 19.5 million Twitter users from a total of 500 million global users and continues to grow over time. Twitter users utilize it as a forum for open campaigning by Medan mayoral candidates and their volunteers prompted Netizens to respond. Netizen's response to any tweet is Positive and Negative.
Therefore, this research tries to analyze tweets about netizen sentiment for the Medan City Elections in 2020. Opinions or sentiments from Twitter users can certainly be used as criticism and suggestions that can be accommodated by candidates for mayor and deputy mayor of Medan. Netizens of Twitter often opinion about the Regional Head Candidate through his Uploads. The opinions of the Twitter Netizens are still random or unclassified. To facilitate the process of classifying opinion data netizens needed a Sentiment Analysis. Sentiment Analysis is carried out by classification of tweets containing Netizen sentiments towards the Implementation of Medan City Elections 2020. The classification method used in this research is the Multilayer Perceptron method with the relu activation function and adam optimization function combined with TF-IDF feature extraction. The validity test applied to this research used a confusion matrix. With tf-idf feature extraction and the multilayer perceptron method will be able to automatically classify sentiment analysis with an accuracy of 92,733%.
Keyword: Sentiment Analysis, Tf-idf, Multilayer Perceptron
DAFTAR ISI
halaman
PERSETUJUAN ... ii
PERNYATAAN ... iii
ABSTRAK ... vi
ABSTRACT ... vii
DAFTAR ISI ... viii
DAFTAR TABEL ... xi
DAFTAR GAMBAR ... xii
DAFTAR LAMPIRAN ... xiii
PENDAHULUAN ... 1
Latar Belakang ... 1
Rumusan Masalah... 2
Batasan Masalah ... 3
Tujuan Penelitian ... 3
Manfaat Penelitian ... 4
Metodologi Penelitian... 4
Sistematika Penulisan ... 5
LANDASAN TEORI ... 7
Sentimen Analisis ... 7
Twitter API ... 7
Natural Language Processing ... 8
Text Mining ... 8
Preprocessing ... 8
Klasifikasi ... 10
Model Klasifikasi ... 10
Pengukuran Kinerja Klasifikasi ... 10
Ekstraksi Fitur TF-IDF ... 12
Algoritma Multilayer Perceptron ... 13
Python ... 15
Penelitian Relevan ... 15
ANALISIS DAN PERANCANGAN ... 17
Analisis Sistem ... 17
3.1.1 Analisis Masalah... 17
3.1.2. Analisis Kebutuhan... 18
3.1.2.1. Kebutuhan Fungsional ... 18
3.1.2.2. Kebutuhan Non-fungsional ... 18
Arsitektur Umum ... 18
Perancangan Sistem ... 20
3.3.1. Crawling Data Tweet ... 20
3.3.2. Labelisasi ... 20
3.3.3. Preprocessing ... 21
3.3.4. Data Split ... 24
3.3.5. Analisis Sentimen ... 24
3.3.5.1. Ekstraksi fitur Tf-idf ... 24
3.3.5.2. Algoritma Multilayer Perceptron ... 28
Pemodelan Sistem... 31
3.4.1. Use Case Diagram ... 31
3.4.2. Activity Diagram ... 32
3.4.3. Sequence Diagram ... 34
Flowchart ... 34
3.5.1. Flowchart Sistem ... 34
3.5.2. Flowchart Ekstraksi Fitur Tf-idf ... 36
3.5.3. Flowchart Algoritma Multilayer Perceptron ... 36
Perancangan Antarmuka ... 37
3.6.1. Halaman Login ... 38
3.6.2. Halaman Dashboard ... 38
3.6.3. Halaman Dataset ... 39
3.6.4. Halaman Text Processing ... 40
3.6.5. Halaman Klasifikasi ... 41
3.6.6. Halaman Pengujian ... 42
IMPLEMENTASI DAN PENGUJIAN ... 44
Implementasi Sistem... 44
4.1.1. Spesifikasi Kebutuhan Perangkat Keras ... 44
4.1.2. Spesifikasi Kebutuhan Perangkat Lunak ... 44
Implementasi Sistem Analisis Sentimen ... 44
4.2.1. Halaman Login ... 45
4.2.2. Halaman Dashboard ... 45
4.2.3. Halaman Dataset ... 47
4.2.4. Halaman Text Processing ... 48
4.2.5. Halaman Klasifikasi ... 48
4.2.6. Halaman Pengujian ... 49
Pengujian ... 50
4.3.1. Pengujian Klasifikasi ... 50
4.3.2. Pengujian Kinerja Klasifikasi ... 65
Hasil Pengujian ... 67
KESIMPULAN DAN SARAN ... 70
Kesimpulan ... 70
Saran ... 70
DAFTAR PUSTAKA ... 71
DAFTAR TABEL
halaman
Tabel 2.1 Matriks Konfusi untuk Klasifikasi Dua Kelas ... 11
Tabel 2.2 Perbandingan Penelitian Relevan ... 16
Tabel 3.1 Contoh Labelisasi pada teks tweet... 21
Tabel 3.2 Contoh perbandingan preprocessing pada teks tweet ... 23
Tabel 3.3 Sampel Ekstraksi fitur TF-IDF ... 26
Tabel 3.4 Keterangan Penerapan Algoritma Multilayer Perceptron... 28
Tabel 3.5 Keterangan Rancangan Halaman Login ... 38
Tabel 3.6 Keterangan Rancangan Halaman Dashboard ... 39
Tabel 3.7 Keterangan Rancangan Antarmuka Halaman Dataset ... 40
Tabel 3.8 Keterangan Rancangan Antarmuka Halaman Text Processing ... 41
Tabel 3.9 Keterangan Rancangan Antarmuka Halaman Klasifikasi ... 42
Tabel 3.10 Keterangan Rancangan Antarmuka Halaman Pengujian ... 43
Tabel 4.1 Hasil Klasifikasi Analisis Sentimen pada Pengujian ke-1 ... 51
Tabel 4.2 Matrik Konfusi Pengujian ke-1 ... 65
Tabel 4.3 Hasil Pengujian Kinerja Klasifikasi ... 67
Tabel 4.4 Hasil Perhitungan t-Test One Sample ... 69
DAFTAR GAMBAR
halaman
Gambar 2.1 Diagram Proses Klasifikasi (Sumber: Prasetyo, 2012) ... 10
Gambar 2.2 Multilayer Perceptron Architecture ... 13
Gambar 3.1 Diagram Ishikawa ... 17
Gambar 3.2 Arsitektur Umum ... 19
Gambar 3.3 API Twitter yang digunakan untuk Crawling data tweet ... 20
Gambar 3.4 Penerapan teknik train test split pada data split ... 24
Gambar 3.5 Penerapan Ekstraksi Fitur Tf-idf ... 25
Gambar 3.6 Penerapan Algoritma Multilayer Perceptron ... 28
Gambar 3.7 Arsitektur Multilayer Perceptron pada Penelitian ini ... 29
Gambar 3.8 Aksitektur Multilayer Perceptron dari sampel perhitungan ... 30
Gambar 3.9. Use Case Diagram ... 32
Gambar 3.10 Activity Diagram Sistem Analisis Sentimen ... 33
Gambar 3.11 Sequence Diagram Sistem Analisis Sentimen ... 34
Gambar 3.12 Flowchart Sistem Analisis Sentimen ... 35
Gambar 3.13 Flowchart Ekstraksi Fitur Tf-idf ... 36
Gambar 3.14 Flowchart Algoritma Multilayer Perceptron ... 37
Gambar 3.15 Rancangan Halaman Login ... 38
Gambar 3.16. Rancangan Halaman Dashboard ... 39
Gambar 3.17 Rancangan Halaman Dataset ... 40
Gambar 3.18. Rancangan Halaman Text Processing ... 41
Gambar 3.19. Rancangan Halaman Klasifikasi ... 42
Gambar 3.20 Rancangan Halaman Pengujian ... 43
Gambar 4.1 Halaman Login ... 45
Gambar 4.2 Halaman Dashboard ... 46
Gambar 4.3 Pengaturan Dataset ... 46
Gambar 4.4 Halaman Dataset ... 47
Gambar 4.5 Halaman Text Processing ... 48
Gambar 4.6 Halaman Klasifikasi... 49
Gambar 4.7 Halaman Pengujian ... 50
DAFTAR LAMPIRAN
halaman Lampiran 1 Listing Program dan Dataset ... A-1 Lampiran 2 Curriculum Vitae ... B-1
BAB 1 PENDAHULUAN
Latar Belakang
Merujuk pada data Kementerian Komunikasi dan Informasi Republik Indonesia (https://kominfo.go.id/, 2013) sesuai data dari PT Bakrie Telecom Tbk, bahwa Indonesia memiliki pengguna Twitter dengan jumlah 19,5 juta dari total 500 juta pengguna di dunia dan terus berkembang seiring berjalannya waktu.
Penggunaan Twitter sebagai wadah Kampanye secara terbuka oleh para Calon Walikota Medan dan para relawannya memicu Netizen untuk menanggapinya.
Tanggapan Netizen ini terdiri dari Positif dan Negatif.
Kontestasi Politik Indonesia mulai melebar ke ranah Sosial Media. Gagasan dan ide dari politisi pada masa ini sudah memanfaatkan media sosial sebagai wadah untuk mengemukakan pendapat. Dibalik itu tentu banyak Masyarakat (Netizen) yang menanggapi hal tersebut dengan positif maupun negatif. Proses pemilihan kepada daerah di Kota Medan dilakukan pada tahun 2020 dan sekarang sudah mulai memasuki masa kampanye. Salah satu media yang menjadi wadah kampanye bagi para Calon Walikota Medan adalah Twitter.
Opini atau sentiment dari Netizen Twitter tentu dapat digunakan sebagai kritik dan saran yang dapat ditampung oleh Calon Walikota dan Wakil Walikota Medan.
Netizen Twitter sering beropini tentang Calon Kepala daerah melalui Unggahannya.
Opini para Netizen Twitter tersebut masih acak atau belum terklasifikasi. Untuk memudahkan proses pengklasifikasian Data opini para Netizen dibutuhkan suatu Sentimen Analisis.
Sentimen Analisis atau penggalian opini adalah studi komputasi opini, sentimen, emosi, penilaian, dan sikap seseorang terhadap entitas suatu produk, layanan, organisasi, individu, masalah, peristiwa, topik serta atribut yang berkaitan(Liu, 2018). Proses penggalian opini dapat dilakukan dengan metode text mining dan machine learning. Salah satu algoritma text mining adalah ekstraksi fitur Tf-idf. Adapun salah satu algortima machine learning adalah Artificial Neural Network atau sering dikenal dengan nama Multilayer Perceptron.
Pada tahun 2015 Chandani, Vinita e.t al melakukan penelitian tentang Komparasi Algoritma Klasifikasi Machine Learning dan Feature Selection pada Analisis Sentimen Review Film. Dari Penelitian ini didapatkan Hasil komparasi algoritma yang terbaik adalah algoritma Support Vector Machine dengan akurasi 81.10% serta Area Under Curve sebesar 0.904 (Chandani, 2015).
Tahun 2020 Amalia, Chindy, dan Sibaroni, Yuliant melakukan penelitian dengan topik Analisis Sentimen pada data tweet dengan Pembobotan Delta Tf-Idf Menggunakan Model Jaringan Saraf Tiruan. Hasil dari penelitian ini menyatakan bahwa Pembobotan Delta TFIDF lebih baik dibandingkan dengan TFIDF biasa, terlihat dari hasil akurasi seluruh skenario, Delta TFIDF mendapatkan hasil akurasi tertinggi yaitu 70.6% dan TFIDF sebesar 68.5% (Amalia, 2020).
Berdasarkan Latar Belakang yang telah disajikan di atas, penulis tertarik melakukan penelitian dengan topik “Sentimen Analisis Netizen Twitter menggunakan ekstraksi Tf-idf (Term Frequency and Inverse Document Frequency) dan Metode Multilayer Perceptron pada Pilkada Kota Medan 2020.”
Rumusan Masalah
Berikut ini beberapa rumusan masalah yang mengacu pada latar belakang yang telah penulis uraikan.
1. Bagaimana ekstraksi fitur Tf-idf dan Metode Multilayer Perceptron mampu melakukan klasifikasi secara otomatis pada tweet netizen terhadap Pilkada Kota Medan 2020 pada twitter berupa sentimen positif dan negatif dengan tepat?
2. Bagaimana Kinerja Klasifikasi ekstraksi fitur Tf-idf dan Metode Multilayer Perceptron dalam mengklasifikasi sentimen tweet netizen mengenai Pilkada Kota Medan 2020 pada twitter?
3. Apakah Akurasi Kinerja Klasifikasi ekstraksi fitur Tf-idf dan Metode Multilayer Perceptron dalam mengklasifikasi sentimen tweet netizen mengenai Pilkada Kota Medan 2020 pada twitter lebih dari 90%?
Batasan Masalah
Agar penelitian ini sesuai dengan Rumusan Masalah dan lebih terarah sesuai kemampuan penulis. Maka Batasan masalah dari penelitian ini sebagai berikut:
1. Menggunakan ekstraksi fitur TF-IDF (Term Frequency-Inverse Document Frequency) dan Metode Multilayer Perceptron untuk pengklasifikasian pada penelitian ini.
2. Data yang akan digunakan merupakan Tweet berbahasa Indonesia.
3. Pengambilan tweet menggunakan teknik crawling dengan library tweepy pada Python dan API Twitter.
4. Tweet yang digunakan adalah tweet pengguna twitter yang mengandung kata kunci Akhyar Salman, Bobby Aulia, #BobbyAulia atau
#AkhyarSalman.
5. Data yang digunakan minimal 500 data tweet dan data yang bernilai positif berjumlah 50%, data yang bernilai negatif berjumlah 50%, serta random state berjumlah 45.
6. Tweet yang digunakan hanya berbentuk teks.
7. Pembangunan Sistem menggunakan Bahasa Pemrogramman Python 3.9.0.
8. Menggunakan Library: flask, pandas, re, sastrawi, mysql.connector, json, scikit-learn.
9. Sistem ini hanya menampilkan hasil klasifikasi sentimen tweet netizen twitter berupa sentimen positif atau negatif dan juga menghitung kinerja klasifikasi dari metode yang disebutkan di atas.
Tujuan Penelitian
Berikut Tujuan dari penelitian ini:
1. Untuk Memperoleh Gelar Sarjana dibidang Ilmu Komputer.
2. Untuk mengklasifikasikan sentimen positif dan negatif dari netizen twitter mengenai Pilkada Kota Medan 2020 secara otomatis.
3. Mengukur Kinerja Klasifikasi Ekstraksi fitur TF-IDF dan Metode Multilayer Perceptron dalam melakukan klasifikasi sentimen pada twitter.
Manfaat Penelitian
Dari penelitian ini didapatkan beberapa manfaat yaitu agar memperoleh sebuah sistem untuk identifikasi sentimen netizen twitter terhadap Pilkada Kota Medan 2020 berupa tweet positif dan negatif, serta untuk menghitung kinerja ekstraksi fitur tf-idf (Term Frequency - Inverse Document Frequency) dan metode Multilayer Perceptron (MLP) dalam melakukan klasifikasi tweet Netizen, juga dapat menjadi referensi pada penelitian berikutnya.
Metodologi Penelitian
Tahapan-tahapan metodologi penelitian:
1. Studi Literatur
Pada tahapan ini penulis melakukan riset dan memperbanyak literasi yang berkaitan dengan penelitian tentang Sentimen Analisis, Algoritma TF-IDF (Term Frequency and Inverse Document Frequency dan Metode Multilayer Perceptron.
2. Analisa Data
Pada tahapan ini penulis melakukan pengumpulan serta menganalisa data yang terkait dengan penelitian ini seperti crawling data tweet serta labelisasi.
3. Perancangan Sistem
Pada tahapan ini penulis akan menganalisis masalah agar mengetahui hal-hal yang dibutuhkan pada penelitian ini, dan selanjutnya sistem dirancang dengan merancang sistem menggunakan use case diagram, squence diagram activity diagram,, flowchart, serta perancangan antarmuka sistem.
4. Implementasi
Pada tahapan ini perancangan diimplementasikan dalam bahasa pemrograman Python.
5. Pengujian
Pada tahapan ini akan dilakukan pengujian kinerja sistem serta kebenaran dari hasil analisis sentimen yang dilakukan menggunakan ekstraksi fitur tf-idf (Term Frequency and Inverse Document Frequency) dan Metode Multilayer Perceptron.
6. Dokumentasi
Pada tahapan ini dilakukan dokumentasi serta penulisan laporan dan kesimpulan akhir dari hasil akhir analisa dan pengujian yang berbentuk skripsi.
Sistematika Penulisan
Sistematika penulisan skripsi ini terdiri dari bagian utama yang diterangkan seperti berikut:
BAB 1 PENDAHULUAN
Bab ini terdiri dari latar belakang dari penelitian yang dilakukan, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metodologi penelitian serta sistematika penulisan skripsi ini.
BAB 2 LANDASAN TEORI
Bab ini berisi tentang penjelasan singkat tentang definisi sentimen analisis, twitter, text mining, ekstraksi fitur tf-idf, algortima Multilayer Perceptron, dan Python.
BAB 3 ANALISIS DAN PERANCANGAN
Bab ini terdiri dari penjelasan mengenai analisis dari perancangan desain sistem yang akan dibangun mulai dari masalah yang ada pada sistem yang akan dibangun, hal-hal yang diperlukan dalam perancangan sistem serta perancangan interface sistem.
BAB 4 IMPLEMENTASI DAN PENGUJIAN
Bab ini terdiri dari penjelasan implementasi sistem dan pengujian terhadap sistem yang telah diimplementasikan serta pembahasan hasil pengujian.
BAB 5 KESIMPULAN DAN SARAN
Bab ini berisi mengenai kesimpulan dari hasil penelitian yang sudah dilakukan serta saran untuk penelitian berikutnya.
BAB 2
LANDASAN TEORI
Sentimen Analisis
Menurut Bing Liu (2018) bahwa Sentimen Analisis atau penggalian opini adalah studi komputasi opini, sentimen, emosi, penilaian, dan sikap orang terhadap entitas seperti produk, layanan, organisasi, individu, masalah, peristiwa, topik serta atribut yang berkaitan.
Tentu Sentimen Analisis ini dapat digunakan sebagai acuan dalam mengklasifikasikan Opini masyarakat tentang Politisi atau Calon Kepala daerah tertentu. Opini masyarakat yang dimaksud adalah opini yang tersebar di Internet atau Sosial Media seperti Facebook, Twitter, dan lainnya.
Twitter API
Twitter merupakan salah satu platform sosial media yang diciptakan oleh Jack Dorsey pada tahun 2006 dan mulai aktif sejak Juli 2006 dengan url http://www.twitter.com yang masih aktif hingga sekarang. Twitter bersifat Application Programming Interface yang membuat para developer dapat mengembangkan aplikasi sesuai dengan kebutuhan. Hal-hal mengenai twitter API dapat diakses melalui https://developer.twitter.com/. Adapun beberapa jenis twitter API sebagai berikut:
1. Twitter Streaming API
Menurut Monarizqa (2014) mengatakan bahwa Twitter Streaming API berguna untuk pengambilan data. Dengan API ini kita bisa mendapatkan informasi secara realtime dengan volume yang sangat tinggi.
2. Twitter REST API
API ini terbagi menjadi Twitter REST dan Twiter Search. Twitter REST berguna untuk pengambilan core data dan core twitter objects. Twitter search berguna dalam melakukan pencarian tentang trend maupun mencari instance objek Twitter.
Natural Language Processing
Natural Language Processing (NLP) merupakan cabang dari artificial intelegence, dan bahasa (linguistik) yang berkenaan tentang interaksi antara komputer dan bahasa manusia, seperti bahasa Inggris atau bahasa lainnya. NLP berguna untuk membuat mesin yang dapat memahami bahasa manusia serta dapat memberikan respon sesuai yang diinginkan (Alamanda, 2016).
Text Mining
Dalam jurnal (Herwijayanti, 2018) menjelaskan bahwa Text mining adalah proses analisa terhadap data teks yang sumber datanya dari dokumen. Konsep text mining digunakan untuk melakukan klasifikasi dokumen tekstual agar dokumen- dokumen tersebut dapat diklasifikasikan sesuai dengan topik yang diinginkan.
Dengan menggunakan text mining, suatu dokumen text dapat diketahui kategorinya melalui kata-kata yang terkandung dalam dokumen teks tersebut.
Preprocessing
Preprocessing merupakan proses mempersiapkan data yang belum terstruktur menjadi data yang terstruktur sehingga dapat digunakan untuk proses berikutnya (Luthfi, 2017). Preprocessing dilakukan untuk menyeleksi data yang akan diproses pada sistem agar menghasilkan data yang baik dan terstruktur dengan jelas. Berikut ini tahapan-tahapan dari text processing:
a. Cleansing
Cleansing merupakan tahapan untuk menghilangkan tweet dari kata yang tidak dibutuhkan agar meminimalisir gangguang. Kata yang dihapus yaitu katakunci, emoji, hashtag (#), username (@username), url (http://alamat.com), dan surel ([email protected]) (Aditya, 2015).
b. Tokenizing
Tokenizing bertugas untuk memisahkan deretan kata pada suatu kalimat, paragraf atau halaman menjadi suatu potongan kata tunggal (termmed word).
Tokenizing juga dapat menghilangkan karakter yang dianggap sebagai tanda baca (Susilowati, 2015).
c. Case-folding
Case-folding merupakan tahapan untuk melakukan penyamaan case dalam suatu dokumen. Hal ini dilakukan untuk mempermudah proses pencarian (Susilowati, 2015).
d. Stopword Removal
Stopword didefinisikan sebagai term irrelevant atau tidak memiliki hubungan dengan subyek utama dari basis data walaupun kata tersebut sering muncul dalam suatu dokumen. Adapun beberapa contoh stopwords dalam bahasa Indonesia yaitu:
yang, dari, dia, juga, kami, kamu, saya, aku, ini, itu, tersebut, pada, atau, dan, dengan, adalah, yaitu, ke, seperti, kemudian, tak, tidak, jika, maka, ada, di, pada, pun, lain, saja, namun, hanya dan sebagainya (Susilowati, 2015).
e. Stemming
Stemming adalah bagian dari proses yang terdapat pada information retrieval system yang mengubah kata-kata dalam suatu dokumen menjadi kata-kata akarnya (root word) dengan memperhatikan aturan-aturan tertentu. Kata-kata yang mempunyai banyak varian morfologik sering muncul di dalam dokumen. Oleh Karena itu, kata-kata yang tidak termasuk stop-words diubah menjadi stemmed word (term) yang layak. Kata tersebut distem agar memperoleh bentuk akarnya dengan menghapus awalan atau akhiran. Sehingga diperoleh kelompok kata yang memiliki makna sama namun berbeda bentuk sintaktis satu dengan lainnya.
Kelompok tersebut dapat diwakilkan oleh satu kata tertentu seperti kata mengatakan, dikatakan, katakan dapat dikatakan sama atau satu kelompok dan dapat direpresentasikan oleh satu kata umum kata (Susilowati et al., 2015).
Klasifikasi
Klasifikasi adalah suatu proses untuk menilai objek data agar dapat dimasukkan dalam kelas tertentu dari beberapa kelas yang tersedia. Terdapat dua proses utama yang dilakukan dalam klasifikasi, yaitu (Prasetyo, 2012) :
1. Pembuatan model menjadi purwarupa agar disimpan dalam bentuk memori.
2. Penggunaan model tersebut digunakan untuk melakukan pengenalan /klasifikasi/ prediksi pada suatu objek data lain supaya diketahui di kelas mana objek data tersebut dalam model yang sudah disimpan sebelumnya.
Model Klasifikasi
Model Klasifikasi merupakan suatu kondisi ketika terdapat sebuah model menerima input, kemudian mampu mengolah inputan tersebut, dan mampu memberikan solusi sebagai outpot dari proses pengolahan. Diagram proses klasifikasi ditunjukan pada gambar 2.1 berikut :
Gambar 2.1 Diagram Proses Klasifikasi (Sumber: Prasetyo, 2012) Pengukuran Kinerja Klasifikasi
Suatu sistem yang melakukan klasifikasi diharapkan dapat melakukan klasifikasi semua dataset dengan tepat, tetapi tidak dapat dihindari bahwa kinerja suatu sistem tidak akan mencapai 100% kebenarannya, sehingga sebuah sistem
klasifikasi juga harus diukur kinerjanya. Biasanya, pengukuran kinerja klasifikasi dilakukan dengan confusion matrix.
Confusion matrix merupakan tabel pencatat hasil kinerja klasifikasi. Tabel 2.1 merupakan contoh dari confusion matrix yang melakukan klasifikasi hanya ada dua kelas yaitu kelas 0 dan 1. Setiap sel dalam matrix menyatakan jumlah record/data dari kelas i yang hasil prediksinya masuk ke kelas j. Misalnya, sel f : adalah jumlah data dalam kelas l yang secara benar dipetakan ke kelas l, dan fij adalah data dalam kelas 1 yang dipetakan secara salah ke kelas 0.
Tabel 2.1 Matriks Konfusi untuk Klasifikasi Dua Kelas
𝑓𝑖𝑗 Kelas Hasil Prediksi (j)
Kelas = 1 Kelas = 0
Kelas Asli (i) Kelas = 1 𝑓11 𝑓10
Kelas = 0 𝑓01 𝑓00
Berdasarkan confusion matrix di atas kita dapat mengetahui jumlah data dari masing-masing kelas yang diprediksi secara benar, yaitu (𝑓11+ 𝑓00), dan data yang diklasifikasikan secara salah, yaitu (𝑓10+ 𝑓01). Kuantitas matriks konfusi dapat diringkas menjadi beberapa nilai, yaitu akurasi presisi, recall, dan f1-score. Dengan mengetahui jumlah data yang diklasifikasikan dengan tepat, kita dapat mengetahui akurasi hasil prediksi, dan dengan mengetahui jumlah data yang diklasifikasikan tidak tepat, kita dapat mengetahui laju eror dari prediksi yang dilakukan. Dua kuantitas ini digunakan sebagai acuan kinerja klasifikasi. Untuk menghitung akurasi digunakan rumus:
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 𝑓11+𝑓00
𝑓11+𝑓10+𝑓01+𝑓00× 100% …….(1) 𝑓11+ 𝑓00 = Jumlah data yang diprediksi dengan tepat 𝑓11+ 𝑓10+ 𝑓01+ 𝑓00 = Jumlah Prediksi yang dilakukan
Untuk menghitung presisi digunakan formula 𝑃𝑟𝑒𝑠𝑖𝑠𝑖 = 𝑓11
𝑓11+𝑓10× 100% ………(2) 𝑓11 = Jumlah Data kelas 1 yang diprediksi tidak tepat 𝑓11+ 𝑓10 = Jumlah Prediksi Kelas 1
Untuk menghitung recall digunakan rumus 𝑅𝑒𝑐𝑎𝑙𝑙 = 𝑓11
𝑓11+𝑓01× 100% ………(3) 𝑓11 = Jumlah Data kelas 1 yang diprediksi dengan tepat 𝑓11+ 𝑓01 = Jumlah Data Kelas 1
Untuk menghitung f1-score digunakan formula 𝑓1 − 𝑆𝑐𝑜𝑟𝑒 = 2∗𝑟𝑒𝑐𝑎𝑙𝑙∗𝑝𝑟𝑒𝑠𝑖𝑠𝑖
𝑟𝑒𝑐𝑎𝑙𝑙+𝑝𝑟𝑒𝑠𝑖𝑠𝑖 × 100%...(4)
Algoritma klasifikasi berupaya agar mendapatkan akurasi tinggi. Biasanya, model yang dibangun mampu memprediksi dengan tepat pada semua data yang dijadikan data latih, tetapi ketika model berhadapan dengan data uji, barulah kinerja model dari algoritma klasifikasi dapat dihitung (Prasetyo, 2012).
Ekstraksi Fitur TF-IDF
Ekstraksi adalah suatu proses mengubah term dari suatu teks menjadi nilai numerik yang dapat dibaca oleh komputer. Salah satu Algoritma yang dapat digunakan adalah tf-idf. Ekstraksi dengan fitur tf-idf (Term Frequency and Inverse Document Frequency) adalah salah satu proses dari teknik ekstraksi fitur dengan proses memberikan nilai pada masing-masing kata yang ada pada data training.
Untuk mengetahui seberapa penting sebuah kata mewakili sebuah kalimat, akan diberi nilai perhitungan. Pemberian nilai pada tf-idf tergantung besarnya frekuensi kemunculan kata pada dokumen (Pravina, 2019).
Pada ekstraksi dengan fitur tf-idf rumus yang digunakan untuk menghitung nilai (W) dari masing-masing dokumen terhadap kata kunci dengan formula pada persamaan 5 (Melita, 2018):
𝑊𝑑𝑡= 𝑇𝐹𝑑𝑡∗ (𝐼𝐷𝐹𝑓𝑡+ 1)……… (5) Keterangan:
𝑊𝑑𝑡 = nilai dokumen ke-d pada kata ke-t
𝑇𝐹𝑑𝑡 = jumlah kata yang dicari dalam suatu dokumen 𝐼𝐷𝐹𝑓𝑡 = Inverse Document Frequency (log (𝑁
𝑑𝑓)) N = jumlah dokumen
df = jumlah dokumen yang mengandung kata yang dicari
Algoritma Multilayer Perceptron
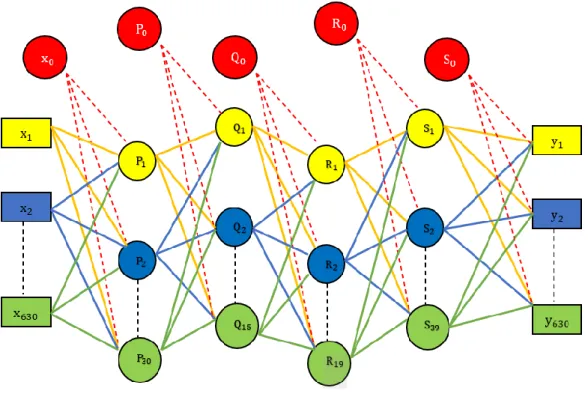
Multilayer Perceptron (MLP) biasanya disebut dengan metode backpropagation banyak lapisan. Algoritma ini menggunakan error output dalam mengubah nilai bobot yang disebut dengan backward. Untuk mendapatkan nilai error, maka langkah awal yang dikerjakan adalah tahap forward propagation (Guntoro et.al, 2019). Contoh multilayer perceptron architecture disajikan pada gambar 2.2 berikut :
Gambar 2.2 Multilayer Perceptron Architecture
Pada gambar di atas terdapat satu hidden layer dengan empat neuron, dan satu output layer dengan tiga neuron. Berikut ini adalah persamaan dari algoritma Multilayer Perceptron (Guntoro et.al, 2019) :
1. Inisialisasi bobot dengan bilangan acak kecil.
2. Jika kondisi penghentian belum terpenuhi, maka lakukan langkah 2 hingga 8.
3. Untuk setiap pasang data pelatihan, lakukan langkah 3 hingga 8.
4. Tiap unit masukan menerima sinyal dan meneruskan ke unit tersembunyi diatasnya.
5. Hitung semua keluaran di unit tersembunyi 𝑧𝑗 (𝑗 = 1, 2, … . , 𝑝)
𝑧_𝑛𝑒𝑡𝑗 = 𝑣𝑗0 + ∑𝑛𝑖=1𝑥𝑖𝑣𝑗𝑖………...(6)
𝑧𝑖 = 𝑓(𝑧_𝑛𝑒𝑡𝑗) = 1
1+ 𝑒−𝑧_𝑛𝑒𝑡𝑗 ………...(7) 6. Hitung semua keluaran jaringan di unit keluaran 𝑦𝑘 (𝑘 = 1,2, … . , 𝑚)
𝑦_𝑛𝑒𝑡𝑘 = 𝑤𝑘0+ ∑𝑝𝑗=1𝑧𝑗𝑤𝑘𝑗…………...(8) 𝑦𝑘 = 𝑓(𝑦_𝑛𝑒𝑡𝑘) = 1
1+ 𝑒−0,0347 = 0,5 ……...(9) 7. Hitung faktor δ unit keluaran berdasarkan kesalahan di setiap unit keluaran
𝑦𝑘 (𝑘 = 1,2, … . , 𝑚)
𝛿𝑘= (𝑡𝑘− 𝑦𝑘)𝑓′(𝑦𝑛𝑒𝑡𝑘) = (𝑡𝑘− 𝑦𝑘)𝑦𝑘(1 − 𝑦𝑘),
𝑡𝑘 = 𝑇𝑎𝑟𝑔𝑒𝑡 ………...(10) δk adalah unit kesalahan yang akan dipakai dalam perbaikan bobot layer dibawahnya. Hitung perubahan bobot 𝑤𝑘𝑗 dengan laju pemahaman α.
∆𝑤𝑘𝑗 = 𝛼𝛿𝑘𝑍𝑗, 𝑘 = 1,2, … . , 𝑚; 𝑗 = 1, 2, … . , 𝑝………...(11) 8. Hitung faktor δ unit tersembunyi berdasarkan kesalahan di setiap unit
tersembunyi 𝑍𝑗 (𝑗 = 1)
𝛿_𝑛𝑒𝑡𝑗 = ∑𝑚𝑘=1𝛿𝑘𝑤𝑘𝑗…...(12) Faktor δ unit tersembunyi.
𝛿𝑗 = 𝛿_𝑛𝑒𝑡𝑗𝑓′(𝑍_𝑛𝑒𝑡𝑗) = 𝛿_𝑛𝑒𝑡𝑗𝑧𝑗(1 − 𝑧𝑗)………...(13) Hitung suku perubahan 𝑣𝑗𝑖
∆𝑣𝑗𝑖 = 𝛼𝛿𝑗𝑥𝑖, 𝑗 = 1,2, … . , 𝑝; 𝑖 = 1, 2, … . , 𝑛………...(14) 9. Hitung semua perubahan bobot. Perubahan bobot garis yang menuju ke unit
keluaran, yaitu:
𝑤𝑘𝑗(𝑏𝑎𝑟𝑢) = 𝑤𝑘𝑗(𝑙𝑎𝑚𝑎) + ∆𝑤𝑘𝑗, (𝑘 = 1,2, … . , 𝑚; 𝑗 = 1, 2, … . , 𝑝) …... (15) Perubahan bobot garis yang menuju ke unit tersembunyi, yaitu:
𝑣𝑗𝑖(𝑏𝑎𝑟𝑢) = 𝑣𝑗𝑖(𝑙𝑎𝑚𝑎) + ∆𝑣𝑗𝑖, (𝑗 = 1,2, … . , 𝑝; 𝑖 = 1, 2, … . , 𝑛) ……... (16)
Python
Python merupakan salah satu bahasa pemrograman yang bersifat object orientation programming serta open source. Python disempurnakan untuk software quality, developer productivity, program portability, dan component integration (Lutz, 2010). Python digunakan untuk mengembangkan berbagai macam perangkat lunak, seperti internet scripting, user interfaces, product customization, systems programming, numberic programming dan sebagainya.
Penelitian Relevan
Berikut ini beberapa penelitian relevan tentang Analisis Sentimen Pada Pilkada Kota Medan 2020 di Twitter menggunakan ekstraksi TF-IDF (Term Frequency and Inverse Document Frequency) dan Metode Multilayer Perceptron.
Pada tahun 2015 Vinita Chandanimelakukan penelitian dengan topik Komparasi Algoritma Klasifikasi Machine Learning dan Feature Selection pada Analisis Sentimen Review Film. Dari Penelitian ini didapatkan Hasil komparasi algoritma yang terbaik adalah algoritma Support Vector Machine dengan akurasi 81.10% serta Area Under Curve sebesar 0.904 (Chandani, 2015).
Tahun 2020 Amalia, Chindy, dan Sibaroni, Yuliant melakukan penelitian dengan judul Analisis Sentimen Data Tweet Menggunakan Model Jaringan Saraf Tiruan Dengan Pembobotan Delta Tf-Idf. Hasil dari penelitian ini menyatakan bahwa Pembobotan Delta TFIDF lebih baik dibandingkan dengan TFIDF biasa, terlihat dari hasil akurasi seluruh skenario, Delta TFIDF mendapatkan hasil akurasi tertinggi yaitu 70.6% dan TFIDF sebesar 68.5% (Amalia, 2020).
Tahun 2019 Faqi Syadid melakukan penelitian dengan topik Analisis Sentimen Komentar Netizen Terhadap Calon Presiden Indonesia 2019 Dari Twitter Menggunakan Algoritma Term Frequency-Invers Document Frequency (TF-IDF) dan Metode Multi Layer Perceptron (MLP) Neural Network. Hasil dari penelitian ini mengatakan bahwa term frequency-invers document frequency dan metode multilayer perceptron dapat diimplementasikan untuk analisis sentimen dan didapatkan nilai akurasi tertinggi pada skenario 3 mencapai 88% (Faqi Syadid, 2019).
Berikut ini tabel perbandingan antara Penelitian terdahulu dan Penelitian yang akan penulis lakukan:
Tabel 2.2 Perbandingan Penelitian Relevan
NO. JUDUL PENELITIAN
PENELITI TAHUN METODE PERBANDINGAN
1 Analisis Sentimen Review Film
Vinita Chandani
2015 Komparasi Algoritma Klasifikasi Machine Learning dan Feature
Selection
Dataset dan Metode yang
berbeda
2 Analisis Sentimen Data Tweet
Amalia, Chindy,
dan Sibaroni,
Yuliant
2020 Model
Jaringan Saraf Tiruan
Dengan Pembobotan
Delta Tf-Idf
Dataset dan Metode yang
berbeda
3 Analisis Sentimen Komentar Netizen Terhadap
Calon Presiden Indonesia 2019 Dari Twitter
Faqi Syadid
2019 TF-IDF dan ANN (Multilayer Perceptron)
Dataset, Jumlah Hidden
Layer, Teknik Pembagian Data (Data Split), Teknik Preprocessing
serta Perhitungan Akurasi dan Presisi yang
berbeda
BAB 3
ANALISIS DAN PERANCANGAN
Analisis Sistem
Analisis sistem adalah langkah awal dari pembangunan sebuah sistem yang berguna untuk mengidentifikasi hal-hal yang dibutuhkan pada sistem, masalah, dan kendala yang ada pada sistem supaya sistem dapat berjalan dengan baik. Ada dua tahapan dalam analisis sitem, yaitu analisis masalah dan analisis kebutuhan sistem.
3.1.1 Analisis Masalah
Pada penelitian ini, permasalahan yang didapat adalah bagaimana mengimplementasikan ekstraksi fitur TF-IDF dan metode multilayer perceptron dalam pembangunan sistem analisis sentimen netizen twitter terhadap pilkada kota Medan 2020.
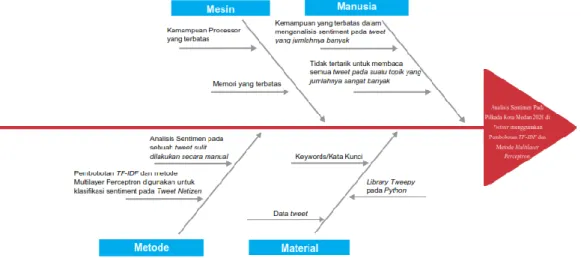
Untuk mengidentifikasi masalah tersebut, penulis menggunakan diagram ishikawa atau disebut juga sebagai diagram tulang ikan. Diagram ishikawa merupakan diagram yang menggambarkan relasi sebab dan akibat dari permasalahan yang akan diselesaikan oleh sistem. Diagram ishikawa dari sistem ini ditunjukkan pada Gambar 3.1 dibawah ini.
Gambar 3.1 Diagram Ishikawa
3.1.2. Analisis Kebutuhan
Pada pembangunan suatu sistem diperlukan tahapan analisis kebutuhan sistem.
Analisis kebutuhan sistem terdiri dari 2 bagian yang terdiri dari kebutuhan fungsional dan kebutuhan non-fungsional.
3.1.2.1. Kebutuhan Fungsional
Kebutuhan fungsional pada sistem yang akan dibangun pada penelitian ini adalah sebagai berikut :
1. Sistem menghasilkan output berupa hasil klasifikasi analisis sentimen tweet netizen terhadap pilkada kota medan 2020 berupa positif dan negatif yang dicrawling menggunakan Library Tweepy pada Python.
2. Klasifikasi sentimen tweet menggunakan ekstraksi fitur Tf-idf dan metode multilayer perceptron sebagai algortima klasifikasi.
3.1.2.2. Kebutuhan Non-fungsional
Kebutuhan non-fungsional pada sistem yang akan dibangun pada penelitian ini meliputi:
1. Sistem memiliki tampilan yang berbentuk GUI.
2. Sistem dapat digunakan secara online.
3. Sistem memiliki panduan penggunaan.
Arsitektur Umum
Arsitektur umum merupakan skema perancangan sistem yang mendeskripsikan alur secara keseluruhan. Berikut Arsitektur Umum yang akan digunakan pada penilitian ini dapat dilihat pada Gambar 3.2 dibawah ini:
Gambar 3.2 Arsitektur Umum
Arsitektur umum pada gambar 3.2 dapat dilihat langkah awalnya yaitu mengumpulkan data tweet netizen dari Twitter. Dari data tersebut dijadikan data training yang sudah diklasifikasikan sesuai dengan sentimennya. Kemudan data test diambil sebagai data yang akan diproses. Tahap berikutnya data test akan mengalami proses preprocess text yaitu Cleansing, Tokenisasi, Case Folding, Penghilangan Stopword, dan Stemming. Berikutnya Data tersebut akan diberi bobot dengan ekstraksi fitur TF-IDF. Hasil ekstraksi fitur Term TF-IDF digunakan sebagai bobot klasifikasi dengan ANN atau Multilayer Perceptron. Hasil klasifikasi tersebut menjadi acuan dari Hasil Akhir Sentimen Analisis.
Perancangan Sistem
Pada bagian perancangan sistem ini akan dijelaskan mekanisme perancangan sistem yang sesuai dengan penelitian ini.
3.3.1. Crawling Data Tweet
Crawling Data Tweet merupakan proses pengambilan data tweet yang akan digunakan sebagai dataset yang terdiri dari data uji dan data latih. Proses Crawling ini menggunakan Library tweepy pada Python. Proses pengambilan data ini memerlukan API twitter. Berikut ini API dari twitter penulis.
Adapun data tweet yang diambil dengan Library tweepy pada python adalah data yang tersedia sejak tanggal 1 September 2020 sampai 9 Desember 2020. Data yang diperoleh dari hasil crawling tersebut berjumlah 2167 tweet dengan kata kunci Bobby Aulia, Akhyar Salman, Pilkada Kota Medan, Medan Aman, Medan Berkah, Menantu Jokowi, Medan Kolaborasi serta Hashtag #BobbyAulia, #AkhyarSalman,
#MedanAman, dan #MedanBerkah.
3.3.2. Labelisasi
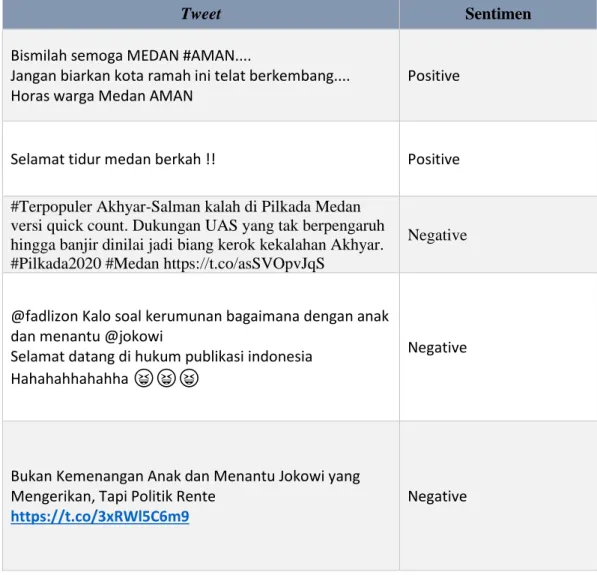
Labelisasi merupakan tahap pemberian label terhadap dataset yang telah dicrawling. Dari 2167 data tweet yang didapatkan, data yang dapat digunakan setelah proses pelabelan sebanyak 630 data. Label yang diberikan hanya berupa positive dan negative dengan jumlah masing-masing 50%. Berikut ini contoh data tweet yang diberikan label pada tabel 3.1 dibawah ini.
access_token = "1075956364554321920-ui8rfqgI3zAgVzXyUn34KjuupB3VVA"
access_token_secret = "M38dzZHRv2IKyIjDwI9yBln9burk3B0sTesM2IUIYNvPO"
consumer_key = "hUGbKq9lH1p6vvacnAvYHSlyk"
consumer_secret = "S1okxjt01weAPdmnqZEOAn4WhOHhErR1nS47WaKaVFgfPY3502"
Gambar 3.3 API Twitter yang digunakan untuk Crawling data tweet
Tabel 3.1 Contoh Labelisasi pada teks tweet
Tweet Sentimen
Bismilah semoga MEDAN #AMAN....
Jangan biarkan kota ramah ini telat berkembang....
Horas warga Medan AMAN
Positive
Selamat tidur medan berkah !! Positive
#Terpopuler Akhyar-Salman kalah di Pilkada Medan versi quick count. Dukungan UAS yang tak berpengaruh hingga banjir dinilai jadi biang kerok kekalahan Akhyar.
#Pilkada2020 #Medan https://t.co/asSVOpvJqS
Negative
@fadlizon Kalo soal kerumunan bagaimana dengan anak dan menantu @jokowi
Selamat datang di hukum publikasi indonesia Hahahahhahahha 😆😆😆
Negative
Bukan Kemenangan Anak dan Menantu Jokowi yang Mengerikan, Tapi Politik Rente
https://t.co/3xRWl5C6m9
Negative
Tabel 3.1 diatas merupakan beberapa sampel dari dataset yang akan digunakan pada penelitian ini tanpa berpihak kepada salah satu paslon. Adapun dataset keseluruhan dapat dilihat pada Lampiran 1.
3.3.3. Preprocessing
Pada penelitian ini tahapan preprocessing menggunakan library Sastrawi pada Python. Tahap ini dilakukan untuk menghindari segala gangguan data saat dilakukan proses pembobotan dan klasifikasi. Adapun preprosessing yang digunakan pada penelitian ini meliputi cleansing, tokenizing, case-folding, penghilangan stopword serta stemming. Berikut ini penjelasannya.
1. Cleansing
Pada penelitian ini proses cleansing dilakukan untuk menghilangkan teks tweet yang dianggap tidak penting. Berikut ini bagian-bagian yang dihilangkan dari teks tweet:
• Hashtag
• Mention
• Link
• Tanda Baca
• RT (retweet)
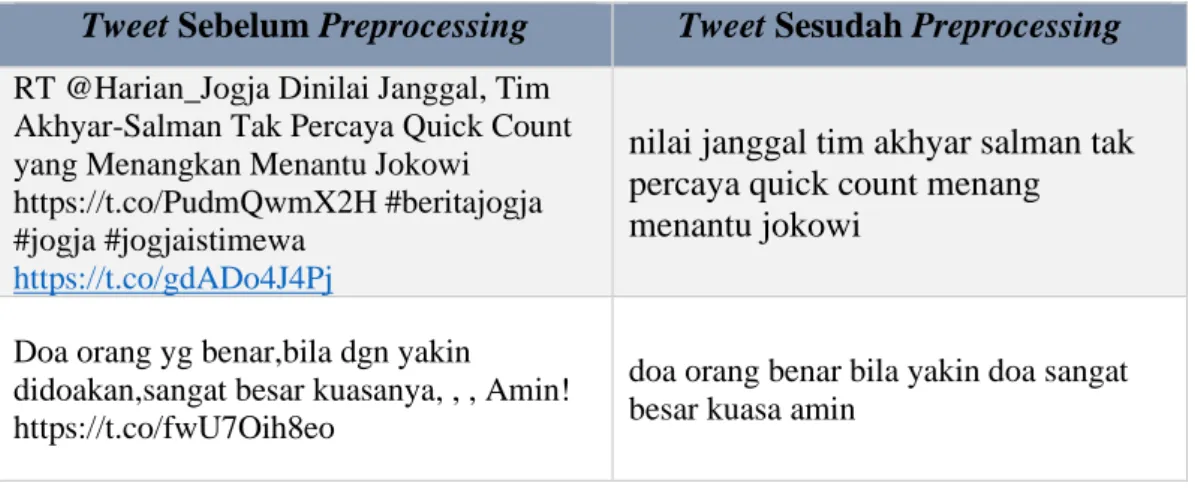
Contoh: RT @Harian_Jogja Dinilai Janggal, Tim Akhyar-Salman Tak Percaya Quick Count yang Menangkan Menantu Jokowi https://t.co/PudmQwmX2H
#beritajogja #jogja #jogjaistimewa https://t.co/gdADo4J4Pj.
Hasil : Dinilai Janggal Tim Akhyar Salman Tak Percaya Quick Count yang Menangkan Menantu Jokowi.
2. Tokenizing
Pada tahap ini akan dilakukan pemotongan string input berdasarkan tiap kata- kata yang tersususn. Berikut ini contoh dari tokenisasi.
Contoh: Dinilai Janggal Tim Akhyar Salman Tak Percaya Quick Count yang Menangkan Menantu Jokowi.
Hasil: [Dinilai] [Janggal] [Tim] [Akhyar] [Salman] [Tak] [Percaya] [Quick]
[Count] [yang] [Menangkan] [Menantu] [Jokowi].
3. Case-folding
Pada tahap ini dilakukan merubah semua huruf kapital menjadi huruf kecil, hanya huruf a-z yang dapat diubah.
Contoh: Dinilai Janggal Tim Akhyar Salman Tak Percaya Quick Count yang Menangkan Menantu Jokowi.
Hasil: dinilai janggal tim akhyar salman tak percaya quick count yang menangkan menantu jokowi.
4. Penghilangan Stopword
Tahap ini dilakukan untuk menghilangkan kata depan, kata ganti, kata sambung dan kata yang tidak ada hubungannya dengan analisis sentimen.
Contoh: dinilai janggal tim akhyar salman tak percaya quick count yang menangkan menantu jokowi.
Hasil: dinilai janggal tim akhyar salman tak percaya quick count menangkan menantu jokowi.
5. Stemming
Pada tahap ini akan diubah kata berimbuhan menjadi kata dasarnya.
Contoh: dinilai janggal tim akhyar salman tak percaya quick count menangkan menantu jokowi.
Hasil: nilai janggal tim akhyar salman tak percaya quick count menang menantu jokowi.
Setelah melakukan beberapa proses diatas maka tahap preprocessing selesai dilakukan. Berikut ini tabel 3.2 perbandingan hasil preprocessing.
Tabel 3.2 Contoh perbandingan preprocessing pada teks tweet Tweet Sebelum Preprocessing Tweet Sesudah Preprocessing RT @Harian_Jogja Dinilai Janggal, Tim
Akhyar-Salman Tak Percaya Quick Count yang Menangkan Menantu Jokowi
https://t.co/PudmQwmX2H #beritajogja
#jogja #jogjaistimewa https://t.co/gdADo4J4Pj
nilai janggal tim akhyar salman tak percaya quick count menang menantu jokowi
Doa orang yg benar,bila dgn yakin didoakan,sangat besar kuasanya, , , Amin!
https://t.co/fwU7Oih8eo
doa orang benar bila yakin doa sangat besar kuasa amin
3.3.4. Data Split
Pada penelitian ini data set akan dibagi menjadi data uji serta data latih. Dalam hal ini teknik yang digunakan adalah train test split. Adapun dalam penelitian ini menggunakan modul atau library scikit learn pada python untuk mengimplementasi teknik train test split. Berikut ini penerapan teknik train test split pada gambar 3.4 di bawah ini.
Dari gambar 3.4 dapat dilihat bahwa data uji dan data latih dibagi menjadi 70% data latih dan 30% data uji dengan random state berjumlah 45. Data uji dan data latih ini akan dibagi secara random. Setiap melakukan pengujian dengan data yang sama, maka data uji akan memiliki data yang berbeda sebanyak 45 data dari setiap pengujian.
3.3.5. Analisis Sentimen
Pada tahap ini terdiri dari dua proses yaitu ekstraksi fitur tf-idf dan klasifikasi menggunakan algoritma multilayer perceptron.
3.3.5.1. Ekstraksi fitur Tf-idf
Pada Proses ekstraksi fitur tf-idf dilakukan untuk mengubah term menjadi bilangan numerik yang akan diproses sebagai data uji dan data latih. Adapun pada penelitian ini ekstraksi fitur tf-idf menggunakan modul sklearn pada python. Berikut ini source code yang digunakan untuk melakukan ekstraksi fitur tf-idf dapat dilihat pada Gambar 3.5.
import sklearn
import sklearn.model_selection
from sklearn.model_selection import train_test_split X = []
y = []
for l in myresult:
X.append(l[0]) y.append(l[1])
X_train, X_test, y_train, y_test = train_test_split(X,y, test _size=0.3, train_size=0.7, random_state=45)
Gambar 3.4 Penerapan teknik train test split pada data split
Pengubahan term ini dilakukan sesuai dengan jumlah dokumen teks pada dataset.
Di sini yang menjadi X (input node) merupakan teks yang telah dipreprocessing dari data dataset dan menjadi Y (output node) merupakan sentimen yang berupa positive dan negative. Berikut ini merupakan tahapan ekstaksi fitur tf-idf yang dilakukan dari beberapa sampel pada penelitian ini.
A = "selamat buat warga medan atas terpilih nya pemimpin kota medan sukses selalu buat pak akhyar berjiwa besar medan aman salut"
B = "jangan berkerumun jakarta jadi tersangka kalau berkerumun kota single medan aman"
C = "paling mengkhawatirkan dari kemenangan anak dan menantu jokowi adalah politik rente"
D = "sekjen pdip hasto kristiyanto mengklaim kemenangan gibran bobby pilkada serentak 2020 berdasarkan hitung cepat quick count membuktikan isu dinasti politik tak berpengaruh suara putera menantu jokowi itu"
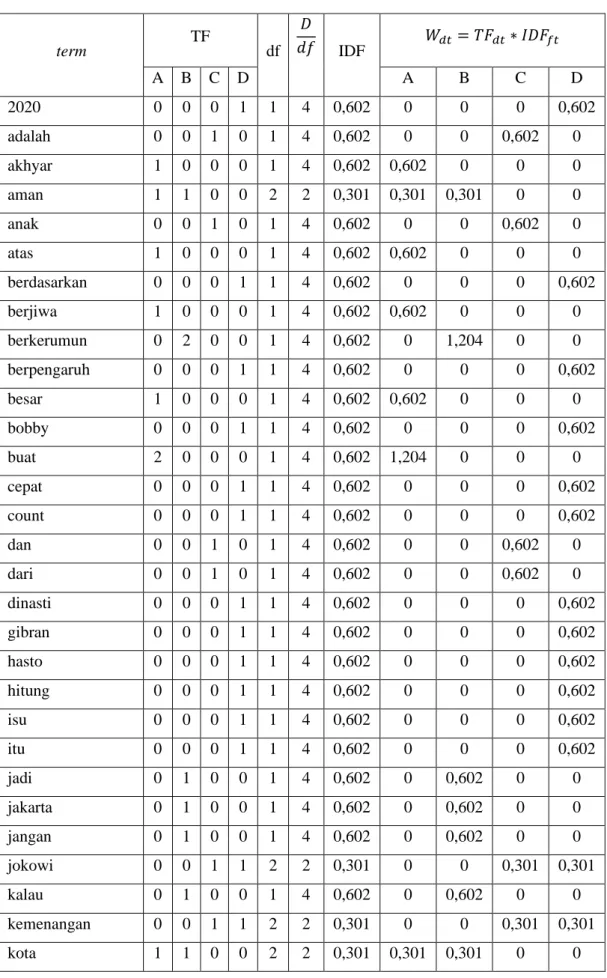
Dari 4 dokumen diatas maka akan diekstrak nilai tf-idf menggunakan persamaan 5.
Hasil ekstraksi tersebut akan disajikan pada tabel 3.3 di bawah ini.
import sklearn
from sklearn import sklearn.model_selection
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
X = []
y = []
for l in myresult:
X.append(l[0]) y.append(l[1])
X_train, X_test, y_train, y_test = train_test_split(X,y, test _size=0.3, train_size=0.7, random_state=45)
vectorizer = TfidfVectorizer(min_df=0.0, max_df=1.0, sublinea r_tf=True, use_idf=True, stop_words='english')
X_train_tf = vectorizer.fit_transform(X_train) X_test_tf = vectorizer.transform(X_test)
Gambar 3.5 Penerapan Ekstraksi Fitur Tf-idf
Tabel 3.3 Sampel Ekstraksi fitur TF-IDF
term TF
df 𝐷
𝑑𝑓 IDF 𝑊𝑑𝑡= 𝑇𝐹𝑑𝑡∗ 𝐼𝐷𝐹𝑓𝑡
A B C D A B C D
2020 0 0 0 1 1 4 0,602 0 0 0 0,602
adalah 0 0 1 0 1 4 0,602 0 0 0,602 0
akhyar 1 0 0 0 1 4 0,602 0,602 0 0 0
aman 1 1 0 0 2 2 0,301 0,301 0,301 0 0
anak 0 0 1 0 1 4 0,602 0 0 0,602 0
atas 1 0 0 0 1 4 0,602 0,602 0 0 0
berdasarkan 0 0 0 1 1 4 0,602 0 0 0 0,602
berjiwa 1 0 0 0 1 4 0,602 0,602 0 0 0
berkerumun 0 2 0 0 1 4 0,602 0 1,204 0 0
berpengaruh 0 0 0 1 1 4 0,602 0 0 0 0,602
besar 1 0 0 0 1 4 0,602 0,602 0 0 0
bobby 0 0 0 1 1 4 0,602 0 0 0 0,602
buat 2 0 0 0 1 4 0,602 1,204 0 0 0
cepat 0 0 0 1 1 4 0,602 0 0 0 0,602
count 0 0 0 1 1 4 0,602 0 0 0 0,602
dan 0 0 1 0 1 4 0,602 0 0 0,602 0
dari 0 0 1 0 1 4 0,602 0 0 0,602 0
dinasti 0 0 0 1 1 4 0,602 0 0 0 0,602
gibran 0 0 0 1 1 4 0,602 0 0 0 0,602
hasto 0 0 0 1 1 4 0,602 0 0 0 0,602
hitung 0 0 0 1 1 4 0,602 0 0 0 0,602
isu 0 0 0 1 1 4 0,602 0 0 0 0,602
itu 0 0 0 1 1 4 0,602 0 0 0 0,602
jadi 0 1 0 0 1 4 0,602 0 0,602 0 0
jakarta 0 1 0 0 1 4 0,602 0 0,602 0 0
jangan 0 1 0 0 1 4 0,602 0 0,602 0 0
jokowi 0 0 1 1 2 2 0,301 0 0 0,301 0,301
kalau 0 1 0 0 1 4 0,602 0 0,602 0 0
kemenangan 0 0 1 1 2 2 0,301 0 0 0,301 0,301
kota 1 1 0 0 2 2 0,301 0,301 0,301 0 0
kristiyanto 0 0 0 1 1 4 0,602 0 0 0 0,602
medan 3 1 0 0 2 2 0,301 0,903 0,301 0 0
membuktikan 0 0 0 1 1 4 0,602 0 0 0 0,602
menantu 0 0 1 1 2 2 0,301 0 0 0,301 0,301
mengkhawatirkan 0 0 1 0 1 4 0,602 0 0 0,602 0
mengklaim 0 0 0 1 1 4 0,602 0 0 0 0,602
nya 1 0 0 0 1 4 0,602 0,602 0 0 0
pak 1 0 0 0 1 4 0,602 0,602 0 0 0
paling 0 0 1 0 1 4 0,602 0 0 0,602 0
pdip 0 0 0 1 1 4 0,602 0 0 0 0,602
pemimpin 1 0 0 0 1 4 0,602 0,602 0 0 0
pilkada 0 0 0 1 1 4 0,602 0 0 0 0,602
politik 0 0 1 1 2 2 0,301 0 0 0,301 0,301
putera 0 0 0 1 1 4 0,602 0 0 0 0,602
quick 0 0 0 1 1 4 0,602 0 0 0 0,602
rente 0 0 1 0 1 4 0,602 0 0 0,602 0
salut 1 0 0 0 1 4 0,602 0,602 0 0 0
sekjen 0 0 0 1 1 4 0,602 0 0 0 0,602
selalu 1 0 0 0 1 4 0,602 0,602 0 0 0
selamat 1 0 0 0 1 4 0,602 0,602 0 0 0
serentak 0 0 0 1 1 4 0,602 0 0 0 0,602
single 0 1 0 0 1 4 0,602 0 0,602 0 0
suara 0 0 0 1 1 4 0,602 0 0 0 0,602
sukses 1 0 0 0 1 4 0,602 0,602 0 0 0
tak 0 0 0 1 1 4 0,602 0 0 0 0,602
terpilih 1 0 0 0 1 4 0,602 0,602 0 0 0
tersangka 0 1 0 0 1 4 0,602 0 0,602 0 0
warga 1 0 0 0 1 4 0,602 0,602 0 0 0
Nilai rata-rata hasil ekstraksi fitur TF-IDF 0,182 0,099 0,093 0,260