Paper Analisis Desain dan Algoritma
ANALISIS ALGORITMA INSERTION SORT
DAN ALGORITMA PENCOCOKAN STRING KNUTH-MORRIS-PRATT
Katya Lindi Chandrika1), Ni’matul Rochmaniyah2), Trias Nur Ilmiani3) 1)2)3)Teknik Informatika Universitas Negeri Malang
Jl. Semarang No. 5, Malang – Jawa Timur
email: [email protected]1), [email protected]2), [email protected]3)
Abstrak—Dalam kehidupan sehari-hari pengguna komputer seringkali dihadapkan pada masalah pengurutan data dan pencarian string. Mengingat pentingnya kedua hal tersebut maka pada makalah ini dilakukan analisis mengenai efisiensi algoritma yang digunakan. Semakin efisien suatu algoritma, maka pada saat dieksekusi dan dijalankan akan menghabiskan waktu yang lebih cepat. Algoritma yang diimplementasikan pada makalah ini adalah algoritma insertion sort untuk pengurutan dan algoritma Knuth-Morris-Pratt untuk pencarian string. Analisis yang dilakukan adalah analisis teoritis dan eksperimental. Analisis teoritis dari algoritma insertion sort untuk best case adalah O(n) (linier) dan untuk worst case O(n2) (kuadratik). Pada analisis eksperimental menunjukkan bahwa waktu dan banyaknya data yang diurutkan berbanding lurus sehingga memiliki kompleksitas linier dan pada worst case waktu akan bertambah apabila data yang diurutkan lebih banyak, sehingga kompleksitas waktunya kuadratik. Untuk algoritma KMP secara teori memiliki kompleksitas linier yaitu O(n), dan untuk hasil eksperimentalnya adalah waktu yang dibutuhkan dengan banyaknya teks dan pola adalah berbanding lurus. Hal ini menunjukkan bahwa kompleksitas waktu algoritma KMP adalah linier, sehingga dapat dikatakan bahwa analisis teoritis dan analisis eksperimental pada algoritma insertion sort dan algoritma Knuth-Morris-Pratt menghasilkan kompleksitas waktu yang sama.
Kata kunci—sorting, insertion sort, string matching, Knuth-Morris-Pratt
I.
Pendahuluan
Seringkali pengguna komputer (user) dihadapkan pada kondisi dimana data pada sebuah array tidak terurut dengan baik. Sementara pada beberapa pengolahan data, data terurut merupakan suatu kebutuhan yang harus dipenuhi. Dengan data yang terurut, pengambilan atau pengaksesan data akan menjadi lebih efisien dan cepat. untuk itu diperlukan suatu algoritma yang dapat mengurutkan elemen-elemen array.
Terdapat beberapa jenis algoritma pengurutan diantaranya insertion sort, selection sort, shell sort, bubble sort, heapsort, quicksort, mergesort dan radix sort. Untuk dapat mengetahui efisiensi pada algoritma pengurutan, maka akan dilakukan analisis pada salah satu jenis algoritma yaitu
insertion sort. Insertion sort adalah algoritma pengurutan sederhana. cara kerja dari insertion sort ini adalah mengambil elemen pada iterasi ke-n lalu meletakannya pada tempat yang sesuai (Budiarsyah, 2013)
Sementara itu pada kasus lain, pencarian string adalah hal yang sering dilakukan oleh user dalam pemrosesan teks. Misal untuk mencari sebuah kata pada Microsoft word atau editor, atau dalam kasus lain yang lebih besar lagi, yaitu pencarian kata kunci pada search engine, seperti google, Yahoo, dan sebagainya.
Proses pencarian string ini disebut juga dengan pencocokan string (string matching atau pattern matching). Ada berbagai algoritma string matching yang sering digunakan, salah satu diantaranya adalah Knuth-Morris-Pratt. Cara kerja algoritma Knuth-Morris-Pratt ini adalah dengan mencocokan suatu pola kata tertentu terhadap suatu kalimat atau teks panjang.
Sebelumnya terdapat penelitian yang dilakukan oleh Ekaputri dan Sinaga (2006) pada makalah aplikasi algoritma pencarian string Knuth-Morris-Pratt dalam Permainan Word Search, bahwa algoritma Knuth-Morris-P ratt memiliki waktu pencocokan string yang singkat. Sementara untuk algoritma insertion sort pada makalah kompleksitas algoritma pengurutan selection sort dan insertion sort oleh B. Tjaru (2010), menyatakan bahwa algoritma insertion sort efisien untuk data berukuran kecil dan merupakan algoritma yang stabil.
Untuk mengetahui seberapa efisien kedua algoritma tersebut seperti yang telah dilakukan oleh kedua penelitian di atas, maka pada makalah ini akan membahas mengenai analisis algoritma insertion sort dan algoritma Knuth-Morris-Pratt menggunakan kompleksitas algoritma atau big-O notation.
II.
Tinjauan Pustaka
2.1 Kompleksitas Algoritma
sebagai fungsi dari ukuran masukan n. Maka, dalam mengukur kompleksitas waktu dihitunglah banyaknya operasi yang dilakukan oleh algoritma. Idealnya, kita memang harus menghitung semua operasi yang ada dalam suatu algoritma. Namun, untuk alasan praktis, cukup menghitung jumlah operasi abstrak yang mendasari suatu algoritma. Operasi abstrak ini disebut operasi dasar.
Berikut ini adalah hal-hal yang mempengaruhi kompleksitas waktu:
1. Jumlah masukan data untuk suatu algoritma (n).
2. Waktu yang dibutuhkan untuk menjalankan algoritma tersebut.
3. Ruang memori yang dibutuhkan untuk menjalankan algoritma yang berkaitan dengan strutur data dari program.
Kompleksitas mempengaruhi performa atau kinerja dari suatu algoritma. Kompleksitas dibagi menjadi 3 jenis, yaitu worst case, best case, dan average case. Masing-masing jenis kompleksitas ini menunjukkan kecepatan atau waktu yang dibutuhkan algoritma untuk mengeksekusi sejumlah kode.
2.2 Algoritma Insertion Sort
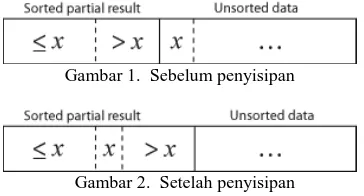
Algoritma insertion sort adalah sebuah algoritma pengurutan sederhana yang membangun array untuk diurutkan dalam sebuah list yang hampir terurut. Algoritma ini lebih efisien dari algoritma yang lebih canggih seperti quicksort, heapsort, atau merge sort. (Erzandi, 2009) Cara kerja insertion sort sebagaimana namanya. Pertama-tama, dilakukan iterasi, dimana di setiap iterasi insertion sort memindahkan nilai elemen, kemudian menyisipkannya berulang-ulang sampai ke tempat yang tepat. Begitu seterusnya dilakukan. Dari proses iterasi, seperti biasa, terbentuklah bagian yang telah di-sorting dan bagian yang belum. (Wisudawan, 2008)
Gambar 1. Sebelum penyisipan
Gambar 2. Setelah penyisipan
Pada Gambar 1 diketahui elemen tabel adalah x. Elemen x akan digeser ke kanan untuk disisipkan dengan elemen sebelumnya hingga ditemukan nilai elemen yang lebih kecil.
Variasi umum dari insertion sort, yang beroperasi pada array, dapat digambarkan sebagai berikut:
- Misalkan ada sebuah fungsi yang kemudian dimasukkan ke nilai urutan awal array.
- Pengoperasian dimulai dari urutan yang paling akhir dan setiap satu elemen akan dibandingkan dengan elemen sebelumnya (x-1) kemudian bergeser ke kanan hingga menemukan posisi yang tepat.
InsertionSort( A )
Dimana A adalah sebuah array A[1...n] for j = 2 to length[A]
key = A[ j ]
// put A[j} into the sorted sequence A[1...j-1] i = j - 1
do A[ i + 1] = A[ i ] i = i – 1
A[i+1] = key
Berdasarkan pseudocode algoritma insertion sort di atas terdapat perulangan for dimana j adalah indeks 2 hingga panjang array A. key adalah variabel yang menyimpan nilai j dari array A. i adalah lokasi atau indeks yang berada di sebelah kiri indeks j. Setelah itu masuk ke perulangan while untuk membandingkan nilai kedua indeks i dan key serta memindahkan nilai hingga ke lokasi yang tepat. Apabila i lebih besar dari 0 dan A[i] lebih besar dari key, maka akan dilakukan perpindahan ruang dengan dilakukan penambahan + 1 pada indeks i. Ini menyatakan bahwa nilai indeks i berpindah ke kanan. Sementara itu kembali indeks i untuk dilakukan komparasi (perulangan while) lagi. Jika i – 1 sama dengan 0 maka break, lalu key menempati ruang kosong yang berada di sebelah kiri.
Pada Gambar 3 berikut adalah contoh dari simulasi insertion sort:
Gambar 3. Simulasi Insertion Sort
InsertionSort( A )
Dimana A adalah sebuah array A[1...n]
for j = 2 to length[A] // n
key = A[ j ] // n- 1
{put A[j} into the sorted sequence A[1...j-1] i = j – 1 //n - 1
∑� ��
�= do A[ i + 1] = A[ i ] ∑� �� −
�= i = i – 1 ∑� �� −
�= A[i+1] = key //n - 1
Pseudocode Insertion Sort beserta perhitungan kompleksitasnya
Berdasarkan input yang diberikan, running time dari program adalah jumlah dari setiap langkah yang di-eksekusi sebanyak n kali. Berikut adalah running time dari algoritma yaitu penjumlahan running time setiap statement yang di-eksekusi:
� � = �+ � − 1 + � − 1 + � − 1 +
∑�= �� + ∑�= �� − 1 + ∑�= �� − 1 +
……(1) � − 1
Dimana T(n) adalah running time, n adalah banyaknya eksekusi pada statement, dan tj adalah banyaknya shift (loncatan) atau perulangan while yang diberikan.
Best case
Best case atau kondisi terbaik yaitu dimana semua data telah terurut. Untuk setiap j = 2,3,.... n, kita dapat menemukan A[i] kurang dari atau sama dengan key dimana i memiliki nilai inisial (j – 1). Dengan kata lain, ketika i = j – 1, akan selalu didapatkan key A[i] pada waktu perluangan while berjalan.
Running time pada best case ini dapat ditunjukkan dengan an + bdimana konstanta a dan b bergantung pada statement ci. Sehingga T(n) adalah fungsi liniear dari n.
� � = � + = � � ……(4)
Worst Case
Worst case atau kondisi terburuk terjadi jika array diurutkan dalam urutan terbalik yaitu, dalam urutan menurun (besar ke kecil). Dalam urutan terbalik, selalu ditemukan A[i]lebih besar dari key
pada perulangan loop. Sehingga, harus membandingkan setiap elemen A[j] dengan seluruh urutan elemen sub-array A[1...j-1]dan juga tj = j
untuk j = 2,3,.... n. Secara ekuivalen, saat perulangan while keluar disebabkan i telah mencapai indeks 0. Oleh karena itu, tj = juntuk j = 2,3,...,ndan running time worst case dapat dihitung menggunakan persamaan sebagai berikut :
Running time pada worst case ini dapat dinyatakan sebagai �
+
�+
�,
untuk konstanta a, b dan c bergantung pada statement . Oleh karena itu, T(n) adalah fungsi kuadrat dari n.� � = � + � + = � � …… (8)
Average Case
Average case terjadi apabila data yang diurutkan acak. Key dalam A[i] adalah kurang dari setengah elemen dalam A[1…..j-1] dan lebih besar dari setengah lainnya. Hal ini berarti pada kondisi average, perulangan while harus melalui setengah jalan melalui subarray A diurutkan [1…j-1] untuk memutuskan dimana memposisikan key. Ini berarti
tj = j/2.
Meskipun running time average case adalah setengah dari waktu running time worst case, average case masih memiliki fungsi kuadrat dari n.
� � = � + � + = � � . ……(9)
2.3 Algoritma String Matching Knuth-Morris-Pratt
Pencocokan pola dan teks (string matching) adalah permasalahan dasar untuk pemrosesan teks yang dilakukan menggunakan komputer. Masalah pencocokan teks yang paling dasar namun penting adalah menemukan DNA yang sama atau urutan protein pada DNA.
Cara kerja algortima string matching ini adalah dengan mencocokan suatu pola kata tertentu terhadap suatu kalimat atau teks panjang.
Algoritma string matching dapat diklasifikasikan menjadi tiga bagian menurut arah pencariannya (Charras, C. & Lecroq, T. 1997 ) yaitu :
- From left to right.
Dari arah yang paling alami, dari kiri ke kanan, yang merupakan arah untuk membaca.
- From right to left
Dari arah kanan ke kiri, arah yang biasanya menghasilkan hasil terbaik secara partikal. - In a specific order
Dari arah yang ditentukan secara spesifik oleh algoritma tersebut, arah ini menghasilkan hasil terbaik secara teoritis.
Pada paper ini, akan dibahas salah satu contoh dari algoritma string matching from left to right yaitu Algoritma Knuth-Morris-Pratt.
Di dalam algoritma Knuth-Morris-Pratt atau lebih dikenal dengan KMP, terdapat dua komponen penting, yaitu:
a. Fungsi prefix, fungsi ini memproses pola untuk menemukan prefix pada pola dengan pola itu sendiri. Fungsi ini juga berfungsi untuk mempermudah pencarian pola di dalam string agar lebih efisien.
b. Komponen kedua adalah fungsi KMP itu sendiri yang berguna untuk menyocokkan pola dengan teks yang diberikan.
Berikut ini adalah langkah – langkah yang dilakukan algoritma KMP dalam proses pencocokkan string yaitu :
1. Masukkan Query kata yang akan dicari. Dengan permisalan P = Pattern atau pola susunan kata yang dijadikan sebagai contoh atau pola teks yang akan dicari T = Teks atau judul dokumen 2. Algoritma KMP mulai mencocokkan pattern
atau pola susunan kata yang dijadikan sebagai contoh pada awal teks.
3. Dari kiri ke kanan, algoritma ini akan mencocokkan karakter per karakter pattern atau pola yang dijadikan sebagai contoh dengan karakter di teks yang bersesuaian, sampai salah satu kondisi berikut dipenuhi :
- Karakter di pattern atau pola susunan kata yang dijadikan sebagai contoh dan di teks yang dibandingkan tidak cocok (mismatch). - Semua karakter di pattern atau pola susunan
kata yang dijadikan sebagai contoh cocok. Kemudian algoritma akan memberitahukan penemuan di posisi ini
4. Algoritma kemudian menggeser pattern atau pola susunan kata yang dijadikan sebagai contoh berdasarkan tabel next, lalu mengulangi langkah no. 2 sampai pattern atau pola susunan kata yang dijadikan sebagai contoh berada di ujung teks
Seperti yang telah disebutkan sebelumnya, algoritma ini memiliki dua komponen penting yaitu fungsi prefix dan fungsi KMP. Kedua fungsi ini memiliki banyak kesamaan, karena keduanya mencocokkan string dengan pola P. Fungsi prefix mencocokkan P dengan P sendiri, sedangkan fungsi KMP mencocokkan P dengan T, dimana T
sebelumnya dilakukan pengisian array prefix yang berfungsi untuk mempermudah proses pencocokkan. Pengisian array prefix ini dilakukan pada fungsi Prefix.
Fungsi prefix
i 0 1 2 3 4 5
Pola (i) a b c a b y
Prefix(i) 0 0 0 1 2 0
Gambar 4. Iterasi pada Fungsi Prefix
Fungsi prefix bekerja mengisi informasi panjang karakter terpanjang yang menjadi awalan dan akhiran pada pola P. Anggap bahwa array sehingga i=2. Dilakukan pencocokkan pada karakter ke j=0 dan i=2, sehingga nilai π[2] = 0. Inkremen pada i sehingga i=3. Karakter j=0 dan i=3 match, sehingga nilai π[3] adalah j+1 yaitu π[3] = 1. Selanjutnya karakter j=1 dan i=4 match, nilai
π[4] = 2. Terakhir karakter j=2 dan i=5 mismatch, dilakukan pengurangan nilai j sebesar 1 sehingga j=1. Tukar nilai j dengan nilai π[j], menjadi j=0,
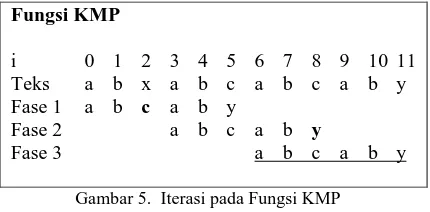
Gambar 5. Iterasi pada Fungsi KMP
inkremen pada i. Fase kedua mismatch terjadi pada P[5] dan T[8], shift ke kiri sebanyak satu sehinga P[4] dapatkan nilai π[4]=2, ubah indeks P[2], lakukan pengecekan antara T[8] dan P[2] dan seterusnya sampai batas pola P. Dari Gambar 4 dapat diketahui bahwa jika terjadi mismatch, pergeseran dilakukan ke karakter atau kumpulan karakter selanjutnya.
Fungsi prefix akan membutuhkan waktu sebesar O(m), sedangkan pencarian pola pada teks atau string membutuhkan waktu O(n), sehingga kompleksitas waktu algoritma KMP adalah O(m+n) dan membutuhkan space sebesar O(m).
Dalam penyelesaian string matching menggunakan algoritma KMP akan menghasilkan best case, worst case dan average case sebagai berikut:
Best Case
Kompleksitas terbaik dari algoritma ini dinotasikan dengan O(m+n). Hal ini akan terjadi ketika pattern sama dengan karakter teks yang dicocokkan.
Worst Case
Kompleksitas terburuk dari algoritma ini dinotasikan dengan O(m*n). kasus terburuk terjadi apabila terdapat pattern tidak pernah sama dengan teks yang dicocokkan.
Misal dengan menggunakan pola “aaaa” diterapkan pada "aaabcaaabce". Untuk pola ini array π adalah: | 0 | 1 | 2 | 0 | 0 | 1 | 2 | 3 | 4 | 5 | 0 |
Perhatikan bahwa pada indeks 3, ketika ketidakcocokan terjadi, dan pada indeks tersebut bernilai 0 yang artinya ketidaksesuaian terjadi. Berdasarkan hasil diatas, ketidaksesuaian dapat dilakukan paling banyak 2 kali, atau dengan kata lain, kita hanya dapat melakukan banyak ketidaksesuaian sebagai jumlah karakter cocok sejauh ini.
Jadi setiap kali ketidakcocokan terjadi pada indeks i, jumlah maksimum ketidaksesuaian pada indeks i dapat terjadi paling banyak sama dengn jumlah karakter yang cocok sejauh ini. (pada indeks i-1)
.
Average Case
Kompleksitas rata-rata dari algoritma ini dinotasikan dengan O(n). Kasus rata - rata terjadi apabila jumlah iterasi = jumlah perbandingan yang sukses + jumlah perbandingan yang gagal.
Running time <= n+n Running time <= 2*n
Sehingga kompleksitas = O(n).
III.
Implementasi
Pada paper ini, pengujian algoritma insertion sort dan KMP diimplementasikan menggunakan bahasa pemrograman C++. Di dalam pengujian penulis menggunakan hardware dengan spesifikasi sebagai berikut:
Processor Intel(R) Celeron(R) CPU B820 @ 1.70GHz
RAM 4096MB
Sistem Operasi Windows 7 Professional 32-bit
Tabel 1. Spesifikai Hardware untuk Pengujian
Source Code Algoritma Insertion Sort
1. void insertion_sort (int A[]) { 2. int length = sizeof(A)/sizeof(int); 3. for (int j = 2; j < length; j++) { 4. int key = A[j];
5. int i = j - 1;
6. while (i > 0 && A[i] > key) { 7. A[i+1] = A[i];
8. i--; 9. }
10. A[i+1] = key; 11. }
12.}
Source Code Algoritma KMP
1. void prefix (string p) { 2. int m = p.length(); 3. pi[0] = 0; 4. pi[1] = 0; 5. int k = 0;
6. for (int q = 2; q < m; q++) { 7. while (k != 0 && p[k] != p[q-1]) 8. k = pi[k];
9. if (p[k] == p[q-1]) 10. k = k + 1; 11. pi[q] = k; 12. }
13.} 14.
15.bool kmp (string p, string t) { 16. int n = t.length();
17. int m = p.length(); 18. prefix(p);
19. int q = 0;
20. for (int i = 1; i < n; i++) { 21. while (q > 0 && p[q] != t[i]) 22. q = pi[q];
23. if (p[q] == t[i]) 24. if (++q == m) 25. return true; 26. }
Pada pengujian kedua algoritma, masing-masing nomor dilakukan sebanyak 20 kali dan dilakukan perhitungan rata-rata untuk menghasilkan waktu pemrosesan algoritma. Hasil pengujian kedua algoritma dapat dilihat pada tabel berikut ini: Tabel 2. Hasil Pengujian Algoritma Insertion Sort
No T P t
Tabel 3. Hasil Pengujian Pertama Algoritma KMP
No T P t Tabel 4. Hasil Pengujian Kedua Algoritma KMP
Grafik 1. Kompleksitas Insertion Sort
Grafik Insertion Sort diatas menunjukkan bahwa algoritma tersebut memiliki kompleksitas yang linier pada kondisi best case dan kuadratik pada kondisi worst case. Hal ini dapat dilihat pada grafik diatas bahwa saat kondisi best case, berapapun data yang dimasukkan akan tetap membutuhkan running time yang sama. Sedangkan pada saat kondisi worst case, semakin banyak data yang dimasukkan, maka running time yang dibutuhkan juga akan semakin lama.
Grafik 2. Kompleksitas KMP (Pengujian Pertama)
Grafik 3. Kompleksitas KMP (Pengujian Kedua)
Grafik 2 merupakan hasil pengujian algoritma KMP dengan variabel tetap yaitu jumlah pola 10. Berdasarkan grafik diatas, dapat dilihat bahwa dalam kondisi best case maupun worst case, algoritma KMP mengalami peningkatan running time jika nilai T (Teks) dan P (Pola) mengalami kenaikan jumlah. Semakin banyak jumlah pola yang dicari di dalam teks dengan jumlah besar, maka running time juga semakin tinggi.
Sedangkan pada Grafik 3 merupakan hasil pengujian algoritma KMP dengan variabel tetap yaitu teks dengan panjang 10000. Hasil yang ditunjukkan sama yaitu terjadi peningkatan running time jika jumlah pola yang dicari semakin banyak.
IV.
Kesimpulan
Pada analisa teoritis algoritma insertion sort memiliki kompleksitas linier untuk best case, sedangkan untuk worst case adalah kuadratik. Begitupun pada analisis eksperimental seperti ditunjukkan pada grafik 1, menunjukkan bahwa banyaknya data yang diurutkan berbanding lurus dengan waktu, sehingga kompleksitas untuk best case adalah linier. Sedangkan worst case adalah terjadi peningkatan waktu apabila data yang diurutkan lebih banyak sehingga kompleksitasnya kuadratik.
Sementara untuk algoritma KMP string matching pada analisis teoritis memiliki kompleksitas linier. Begitupun pada analisa eksperimental Algoritma KMP waktu proses pencarian yang dibutuhkan berbanding lurus dengan panjang teks dan pola. Hal ini menunjukkan bahwa kompleksitas waktu algortima KMP linier. 0
10 100 1000 10000 10000
Berdasarkan hasil analisa di atas, dapat disimpulkan bahwa analisis teoritis dan analisis eksperimental pada algoritma insertion sort dan algoritma Knuth-Morris-Pratt menghasilkan kompleksitas waktu yang sama.
V.
Referensi
[1] Cormen, Thomas H, dkk. 2009. Introduction to Algorithms Third Edition. London: MIT Press.
[2] Lamhot Sitorus. Algoritma dan Pemrograman. : Penerbit Andi
[3] Fanani, Ikhsan. 2007. Penggunaan “Big O Notation” untuk Menganalisa Efisiensi Algoritma. Bandung : ITB.
[4] Erzandi, Muhammad O. 2007. Algoritma Pengurutan dalam pemrograman.Bandung : ITB.
[5] Saptadi, Hendra dan Sari, Desi W. 2012. Analisi Algoritma Insertion Sort, Merge Sort dan Implementasinya dalam Bahasa Pemrograman C+ + . Palembang : Universitas Sriwijaya.
[6] Harry Octavianus Purba.2016.Algortima String Matching Pada Mesin Pencarian. Bandung: Sekolah Teknik Elektro dan Informatika.
[7] Budiarsyah, Dibi K. 2013. “Analisis Kompleksitas Waktu Untuk Beberapa Algoritma Pengurutan”. Bandung : Institut Teknologi Bandung.
[8] Y. A. S. Gahayu Handari Ekaputri, Aplikasi Algoritma Pencarian String Knuth-Morris-Pratt, pp. 2-3, July 2006.