1 PENDAHULUAN
Latar Belakang
Biometrik adalah ilmu untuk menetapkan identitas seseorang berdasarkan ciri fisik, kimia, ataupun tingkah laku dari orang tersebut. Dewasa ini, biometrik telah menjadi suatu hal yang sangat dibutuhkan, terutama dalam bidang sistem manajemen identitas yang bertujuan untuk mengenali identitas seseorang dalam beberapa aplikasi. Beberapa ciri fisik atau tingkah laku yang sering digunakan dalam aplikasi biometrik, seperti wajah, sidik jari, DNA, telinga, gaya berjalan, bentuk geometri tangan, iris, retina, tanda tangan, dan suara (Jain
et al. 2008).
Penelitian mengenai pengenalan tanda tangan merupakan penelitian yang cukup penting. Ini disebabkan banyaknya aplikasi atau sistem yang menggunakan tanda tangan sebagai penciri identitas seseorang, seperti perbankan ataupun kependudukan. Selain itu, tanda tangan juga merupakan objek biometrik yang mudah diperoleh, baik melalui kertas maupun alat elektronik, seperti pen tablets, PDA, Tablet PC, ataupun touch screens. Walau demikian, pengenalan tanda tangan masih memiliki beberapa masalah yang menarik untuk diteliti. Hal ini berkaitan dengan besarnya variasi kelas, tingkat universality dan permanence yang rendah, serta masih tingginya kemungkinan serangan melalui pemalsuan tanda tangan (Jain
et al. 2008).
Berdasarkan informasi input tanda tangan, metode verifikasi tanda tangan terdiri atas dua kategori, yaitu metode on-line dan off-line. Metode on-line merujuk pada penggunaan fungsi waktu pada proses penandatanganan secara dinamis, seperti alur posisi atau penekanan. Metode off-line merujuk pada penggunaan citra statis pada tanda tangan (Jain
et al. 2008).
Aplikasi pengenalan tanda tangan pada dunia nyata, misalnya pada sistem perbankan, pada umumnya menggunakan citra tunggal sebagai data latih. Salah satu faktor penggunaan satu citra sebagai data latih terkait dengan banyaknya ruang yang diperlukan untuk menyimpan citra yang digunakan sebagai data latih. Faktor lainnya adalah usaha yang harus dikeluarkan oleh pengguna untuk menyediakan data latih lebih dari satu akan lebih banyak dibandingkan jika menggunakan satu data latih.
Penelitian menggunakan algoritme VFI5 untuk pengenalan citra sebelumnya telah banyak dilakukan. Penelitian tersebut antara
lain dilakukan oleh Musyaffa (2009), yaitu mengenai pengenalan tanda tangan menggunakan VFI5 dengan praproses wavelet. Penelitian tersebut menghasilkan akurasi sebesar 97,5% pada dekomposisi wavelet level 1 dan 95% pada dekomposisi wavelet level 2. Penelitian pengenalan wajah dengan citra pelatihan tunggal menggunakan VFI5 berbasis histogram juga telah dilakukan oleh Purwaningrum (2009). Akurasi yang dihasilkan pada penelitian tersebut adalah 87,78% pada percobaan menggunakan sepuluh kelas dan 96,3% pada percobaan menggunakan sembilan kelas.
Tujuan
Tujuan penelitian ini adalah melakukan pengenalan tanda tangan dengan citra pelatihan tunggal menggunakan algoritme VFI5 berbasis histogram.
Ruang Lingkup
Ruang lingkup penelitian ini adalah pengenalan citra tanda tangan berdasarkan tingkat keabuan. Data citra yang digunakan adalah citra grayscale. Citra yang digunakan diperoleh dari data skripsi Setia (2007) yang merupakan tanda tangan dari 10 orang yang berbeda dan tanda tangan tiap orang berjumlah 10 citra dengan ukuran seragam, yaitu 60 x 40 piksel. Penelitian ini juga hanya dibatasi pada analisis pengaruh pembagian citra terhadap akurasi tanpa mencari tahu jumlah dan ukuran pembagian citra yang optimum.
TINJAUAN PUSTAKA Biometrik
Biometrik adalah ilmu untuk menetapkan identitas seseorang berdasarkan ciri fisik, kimia, ataupun tingkah laku dari orang tersebut. Dewasa ini, biometrik telah menjadi suatu hal yang sangat dibutuhkan, terutama dalam bidang sistem manajemen identitas yang bertujuan untuk mengenali identitas seseorang dalam beberapa aplikasi (Jain et al. 2008).
Terdapat beberapa kriteria agar sebuah objek biometrik dapat diterapkan pada sebuah aplikasi biometrik. Kriteria tersebut antara lain adalah universality (dimiliki oleh semua individu), uniqueness (setiap individu memiliki ciri yang berbeda), permanence (tidak mudah berubah dalam jangka waktu yang lama),
measurability (mudah diperoleh dan diproses), performance (memiliki akurasi pengenalan
yang cukup baik), acceptability (diterima oleh masyarakat), dan circumvention (sulit ditiru oleh orang lain) (Jain et al. 2008).
2 Citra Digital
Sebuah citra dapat didefinisikan sebagai sebuah fungsi dua dimensi, f(x, y), dimana x dan
y adalah koordinat spasial dan amplitudo dari f
merupakan pasangan dari koordinat (x,y) yang disebut intensity atau gray level sebuah citra. Ketika x, y dan nilai amplitudo f bernilai diskret dan terbatas, maka citra tersebut disebut citra digital (Gonzalez & Woods 2002).
Citra digital dibentuk oleh sejumlah elemen yang terbatas, dimana setiap elemen telah memiliki lokasi dan nilai yang khusus. Elemen-elemen ini sering disebut sebagai picture
elements, image elements, pels, atau pixels. Dari
beberapa istilah tersebut, pixels merupakan istilah yang paling sering digunakan untuk menunjukkan elemen citra digital (Gonzalez & Woods 2002).
Tanda Tangan
Tanda tangan merupakan salah satu bentuk biometrik yang berhubungan dengan tingkah laku seseorang. Bentuk tanda tangan seseorang dapat berubah-ubah dan sangat dipengaruhi oleh kondisi fisik dan emosional seseorang. Walaupun penggunaan tanda tangan memerlukan alat, seperti pulpen dan kertas, serta usaha dari sisi pengguna, tanda tangan banyak digunakan pada instansi pemerintahan, hukum, dan berbagai transaksi keuangan sebagai salah satu bentuk autentikasi. Dengan semakin berkembangnya alat tulis elektronik, seperti PDA dan Tablet PC, tanda tangan
on-line dapat dikembangkan sebagai salah satu
bentuk biometrik yang dapat digunakan pada alat-alat tersebut (Jain et al. 2008).
Pemrosesan Citra Digital
Pemrosesan citra digital merupakan proses yang masukan dan keluarannya adalah citra dan meliputi proses pengekstrakan atribut dari citra dan pengenalan citra. Selain itu, yang dimaksud dengan pemrosesan citra digital biasanya adalah pemrosesan citra menggunakan komputer digital (Gonzalez & Woods 2002).
Histogram
Histogram derajat keabuan sebuah citra digital pada selang [0, L-1] merupakan sebuah fungsi diskret , dimana adalah derajat keabuan yang ke-k dan adalah jumlah piksel pada citra yang memiliki tingkat keabuan
dengan . Untuk
menormalisasi histogram, hal yang biasa dilakukan adalah dengan membagi setiap nilai total jumlah piksel pada citra. Histogram merupakan dasar dari berbagai teknik
pemrosesan domain spasial pada citra. Manipulasi histogram juga sangat bermanfaat dalam perbaikan, kompresi, dan segmentasi citra (Gonzalez & Woods 2002).
Secara sederhana McAndrew (2004) mengemukakan bahwa histogram sebuah citra
grayscale merupakan sebuah grafik yang
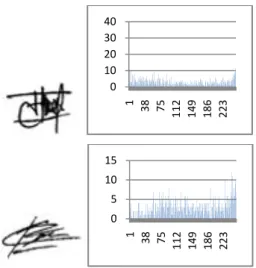
menunjukkan jumlah kemunculan tiap tingkat keabuan pada sebuah citra. Karena histogram hanya menunjukkan jumlah kemunculan tiap derajat keabuan pada sebuah citra, maka ada kemungkinan terdapat dua buah citra berbeda yang memiliki histogram yang sama. Contoh citra dan histogramnya tersaji pada Gambar 1.
Gambar 1 Citra tanda tangan yang berbeda beserta histogramnya.
Klasifikasi
Klasifikasi adalah salah satu bentuk analisis data yang digunakan untuk mengekstrak model-model yang mendeskripsikan kelas data yang penting. Tujuannya adalah untuk memprediksi kecenderungan kelas data pada masa yang akan datang. Beberapa contoh metode klasifikasi antara lain: jaringan saraf tiruan, nearest
neighbor, decision tree, dan neural network
(Han & Kamber 2006).
Algoritme klasifikasi pada dasarnya terdiri atas dua komponen, yaitu pelatihan (training) dan klasifikasi (classification/prediction). Pada tahapan pelatihan dibentuk sebuah model domain dari contoh yang ada. Selanjutnya pada tahapan klasifikasi, model yang telah dibentuk pada tahap pelatihan digunakan untuk memprediksi kelas dari suatu instance yang baru (Guvenir et al. 1998).
Citra Pelatihan Tunggal (Single Training Image)
Dewasa ini, banyak sekali penelitian yang menggunakan algoritme pengenalan citra
0 10 20 30 40 1 38 75 112 149 186 223 0 5 10 15 1 38 75 112 149 186 223
3 dengan mekanisme pembelajaran. Sayangnya,
mekanisme tersebut memerlukan data latih yang cukup banyak. Menurut Than et al. (2006), penggunaan satu citra sebagai data latih akan menyebabkan penurunan akurasi rata-rata sebesar 30% dibandingkan penggunaan citra lebih dari satu atau bahkan sama sekali gagal dalam melakukan pengenalan. Beberapa contoh metode klasifikasi tersebut antara lain: Linear Discriminative Analysis (LDA), Support Vector Machine (SVM), dan laplacianfaces.
Beberapa kelebihan yang diharapkan jika menggunakan satu citra sebagai data latih, yaitu lebih mudah mengambil sampel, menghemat tempat penyimpanan data, serta menghemat waktu komputasi. Oleh karena itu, diperlukan sebuah metode yang dapat bekerja dengan baik dan menghasilkan akurasi yang tetap tinggi walau hanya dengan citra pelatihan tunggal. VFI5 (Voting Feature Intervals)
Menurut Guvenir et al. (1998), VFI5 merupakan algoritme klasifikasi yang memberikan deskripsi melalui sekumpulan interval. Pengklasifikasian dari sebuah instance baru didasarkan pada vote di antara klasifikasi yang dibuat oleh nilai dari tiap fitur secara terpisah. VFI5 merupakan algoritme klasifikasi yang bersifat supervised learning dan
non-incremental sehingga semua data training dapat
diproses dalam satu waktu. Tiap-tiap sampel
training direpresentasikan sebagai nilai-nilai
fitur sebuah vektor nominal (diskret) atau linear (kontinu) disertai sebuah label yang merepresentasikan kelas sampel.
Dari data training, algoritme VFI5 membentuk interval untuk tiap fitur. Sebuah interval dapat berupa interval titik ataupun selang (range). Interval selang didefinisikan sebagai suatu kumpulan nilai yang berurutan dari sebuah fitur yang diberikan, sedangkan interval titik didefinisikan sebagai fitur bernilai tunggal. Untuk interval titik, hanya sebuah nilai yang digunakan untuk mendefinisikan sebuah interval. Untuk tiap interval, diambil sebuah nilai tunggal yang merupakan votes dari tiap-tiap kelas pada interval tersebut. Oleh karena itu, sebuah interval dapat merepresentasikan beberapa kelas dengan menyimpan vote dari tiap kelas.
Keunggulan algoritme VFI5 adalah algoritme ini cukup kokoh (robust) terhadap fitur yang tidak relevan namun mampu memberikan hasil yang baik pada real-world
datasets yang ada. VFI5 mampu menghilangkan
pengaruh yang kurang menguntungkan dari fitur
yang tidak relevan dengan mekanisme voting-nya sehingga akurasivoting-nya tetap terjaga (Güvenir 1998).
Algoritme VFI5 terdiri atas dua tahap, yaitu pelatihan dan klasifikasi.
1 Pelatihan
Hal pertama yang harus dilakukan dalam tahap pelatihan adalah menemukan titik-titik akhir (end points) dari tiap kelas c pada tiap fitur f. Titik akhir dari kelas c yang diberikan merupakan nilai yang terkecil dan terbesar pada dimensi fitur linear (kontinu) f untuk beberapa
instance pelatihan dari kelas c yang sedang
diamati. Sedangkan titik akhir dari dimensi fitur nominal (diskret) f, merupakan nilai-nilai yang berbeda satu sama lain, untuk beberapa instance pelatihan dari kelas c yang sedang diamati. Titik akhir dari fitur f kemudian disimpan dalam array EndPoints[f].
Batas bawah pada interval selang adalah -∞ sedangkan batas atas interval selang adalah +∞.
List dari titik akhir pada tiap dimensi fitur linear
diurutkan. Jika fitur tersebut merupakan fitur linear, terdapat dua jenis interval, interval titik dan interval selang. Jika fitur tersebut merupakan fitur nominal, hanya ada satu jenis interval, yaitu interval titik.
Selanjutnya, banyaknya instance pelatihan setiap kelas c dengan fitur f untuk setiap interval
i dihitung dan direpresentasikan sebagai interval_class_count[f,i,c]. Pada setiap instance
pelatihan, dicari interval i, yang merupakan interval nilai fitur f dari instance pelatihan e (ef) tersebut berada. Apabila interval i adalah interval titik dan ef sama dengan batas bawah interval tersebut (yang sama dengan batas atas untuk interval titik), jumlah kelas instance tersebut (ef) pada interval i ditambah 1. Apabila interval i merupakan interval selang dan ef berada pada interval tersebut maka jumlah kelas
instance ef pada interval i ditambah 1. Proses inilah yang menjadi vote pelatihan untuk kelas c pada interval i.
Agar tidak mengalami efek perbedaan distribusi setiap kelas, vote kelas c untuk fitur f pada interval i harus dinormalisasi dengan membagi vote tersebut dengan hasil penjumlahan tiap-tiap instance kelas c yang direpresentasikan dengan class_count[c]. Hasil normalisasi ini dinotasikan sebagai
interval_class_vote[f,i,c]. Selanjutnya,
nilai-nilai interval_class_vote[f,i,c] dinormalisasi sehingga hasil penjumlaham vote beberapa kelas di setiap fitur sama dengan 1. Tujuan normalisasi ini adalah agar setiap fitur
4 mempunyai kekuatan voting yang sepadan pada
proses klasifikasi dan tidak dipengaruhi oleh ukuran fitur tersebut. Pseudocode algoritme pelatihan dapat dilihat pada Gambar 2.
2 Klasifikasi
Tahap klasifikasi dimulai dengan inisialisasi
vote dengan nilai nol pada tiap-tiap kelas. Pada
tiap-tiap fitur f, dicari interval i yang sesuai dengan nilai ef, dimana ef merupakan nilai fitur f dari instance tes e. Jika ef hilang atau tidak diketahui, fitur tersebut tidak diikutsertakan dalam voting dengan memberikan vote nol pada setiap kelas yang hilang.
Tiap-tiap fitur f mengumpulkan vote-vote-nya dalam sebuah vektor feature_vote[f,C1], ...,
feature_vote[f,Cj], ..., feature_vote[f,Ck] , dimana feature_vote[f,Cj] adalah vote fitur f untuk kelas Cj dan k adalah banyak kelas. Sebanyak d vektor feature vote dijumlahkan sesuai dengan fitur dan kelasnya masing-masing untuk memperoleh total vektor vote vote[C1], ..., vote[Ck] . Kelas dari instance tes e adalah Kelas yang memiliki jumlah vote terbesar.
Pseudocode algoritme prediksi (klasifikasi)
VFI5 dapat dilihat pada Gambar 3.
Gambar 2 Algoritme pelatihan (training) VFI5 (Demiröz 1997).
5 Penerapan VFI5 Berbasis Histogram
Menurut Purwaningrum (2009), penerapan VFI5 berbasis histogram adalah penggunaan nilai dari histogram sebagai fitur pada algoritme VFI5. Pada penerapan VFI5 berbasis histogram, selang histogram yang memiliki nilai 0-255 akan dibagi ke dalam beberapa interval. Jumlah piksel yang memiliki nilai derajat keabuan pada interval tertentu kemudian dijumlahkan. Jumlah piksel pada interval-interval tersebutlah yang akan digunakan sebagai fitur pada algoritme VFI5.
Pada tahap pelatihan, dilakukan normalisasi dengan cara merasiokan jumlah piksel setiap citra data latih dengan jumlah piksel citra seluruh data latih pada tiap intervalnya. Nilai hasil perhitungan inilah yang disebut sebagai
vote untuk citra pada masing-masing kelas
(Purwaningrum 2009). Penjelasan lebih rinci dapat dilihat pada Tabel 1 dan Tabel 2.
Tabel 1 Jumlah piksel pada setiap interval data latih
kelas 1 kelas 2
interval 1 a c
interval 2 b d
Pada tahap klasifikasi, seluruh vote dari tiap interval akan dikalikan dengan fitur dari interval yang sama. Misalkan fitur citra uji pada interval 1 dan 2 adalah f dan g. Maka hasil perkalian
vote dengan fitur citra uji tersaji pada Tabel 3.
Hasil perkalian tersebut kemudian dijumlahkan pada sesuai dengan kelasnya masing-masing. Kelas dari citra uji tersebut adalah kelas dengan jumlah vote terbesar. Tabel 2 Vote yang diperoleh
kelas 1 kelas 2 interval 1
interval 2
Tabel 3 Klasifikasi data uji
kelas 1 kelas 2 interval 1
interval 2
Penelitian-Penelitian Sebelumnya Setia (2007)
Setia (2007) melakukan sebuah penelitian pengenalan tanda tangan menggunakan Hidden
Markov Model (HMM). Tahapan pertama pada
penelitian ini adalah pengambilan data tanda tangan. Data tanda tangan yang digunakan berjumlah 200 buah yang berasal dari 10 orang yang berbeda. Tanda tangan dilakukan pada sebuah kertas yang dibatasi dengan kotak berukuran 1,7 x 1,2 cm. Tanda tangan tersebut kemudian dikonversi menjadi citra digital 300 dpi berformat BMP dan mode RGB dengan menggunakan scanner. Tanda tangan dari tiap orang kemudian dibagi menjadi dua, yaitu 10 citra untuk data latih dan 10 citra untuk data uji.
Semua citra yang dihasilkan pada tahap sebelumnya kemudian dikonversi ke dalam citra 8 bit berformat PCX berukuran 60 x 40 piksel. Setelah itu, posisi tanda tangan yang sebelumnya tidak teratur mengalami pengeditan sehingga semua tanda tangan berada pada posisi yang sama. Tahap selanjutnya adalah proses
cropping dan resizing. Bagian yang dianggap
kurang penting dibuang dan kemudian di-resize sehingga mengalami perubahan ukuran menjadi 30 x 45 piksel.
Setelah pemrosesan data selesai, maka dilakukan normalisasi yang dilanjutkan dengan pelatihan dan pengujian. Rata-rata akurasi pada penilitian ini adalah 75% pada pelatihan 8 state, 73% pada pelatihan 6 state, dan 53% pada pelatihan 4 state.
Purwaningrum (2009)
Purwaningrum (2009) membuat sebuah penelitian baru mengenai pengenalan wajah dengan citra latih tunggal menggunakan algoritme VFI5. Penelitian yang dilakukan ini berbasis histogram. Data yang digunakan merupakan citra wajah dari sepuluh orang dengan sepuluh ekspresi berbeda. Dari penelitian ini didapatkan nilai akurasi tertinggi sebesar 87,78% dengan jumlah kelas sebanyak sepuluh serta 96,3% dengan jumlah kelas sebanyak sembilan. Pada penelitian tersebut juga didapatkan pula bahwa 256, 128, 64, 32, 16, dan 8 merupakan enam variasi jumlah interval yang menghasilkan nilai akurasi tertinggi. Jika dibandingkan dengan metode pengenalan yang menjadikan nilai piksel sebagai masukannya, maka penelitian ini memiliki beberapa kelebihan, yaitu:
tidak terpengaruh oleh rotasi terhadap citra. Hal ini terjadi karena histogram suatu citra tidak tergantung pada posisi dari suatu piksel, namun hanya pada nilai derajat keabuannya;
penambahan ukuran citra tidak menambah jumlah fitur yang dijadikan sebagai masukan
6 pada algoritme VFI5. Alasannya adalah
banyaknya interval yang digunakan bukan banyaknya jumlah piksel.
Musyaffa (2009)
Dengan menggunakan data penelitian yang dilakukan oleh Setia, Musyaffa (2009) melakukan penelitian pengenalan tanda tangan menggunakan algoritme VFI5 setelah sebelumnya dilakukan praproses menggunakan wavelet. Pada penelitian ini Musyaffa tidak melakukan pengeditan, cropping, serta resizing pada data citra sehingga data yang digunakan adalah citra berformat PCX berukuran 60 x 40 piksel. Jumlah yang digunakan pada penelitian ini pun hanya berjumlah sepuluh buah dengan rasio data latih dan data uji sebesar 3:2 atau dengan kata lain 6 buah citra untuk data latih dan 4 buah citra untuk data uji.
Hasil yang didapat pada penelitian ini adalah akurasi sebesar 97,5% dan 95% pada dekomposisi wavelet menggunakan level 1 dan 2. Dari hasil tersebut dapat dikatakan bahwa metode yang dilakukan oleh Musyaffa lebih baik dibandingkan yang dilakukan oleh Setia. Di samping itu, Musyaffa (2009) juga mengemukakan bahwa akurasi akan mengalami penurunan seiring dengan meningkatnya level dekomposisi wavelet. Hal tersebut disebabkan berkurang jumlah fitur yang digunakan pada proses klasifikasi.
Analisis Ragam
Analisis ragam adalah suatu metode untuk menguraikan keragaman total data menjadi komponen-komponen yang mengukur berbagai sumber keragaman. Tujuannya adalah untuk menguji kesamaan beberapa nilai tengah secara sekaligus (Walpole 1992).
METODE PENELITIAN
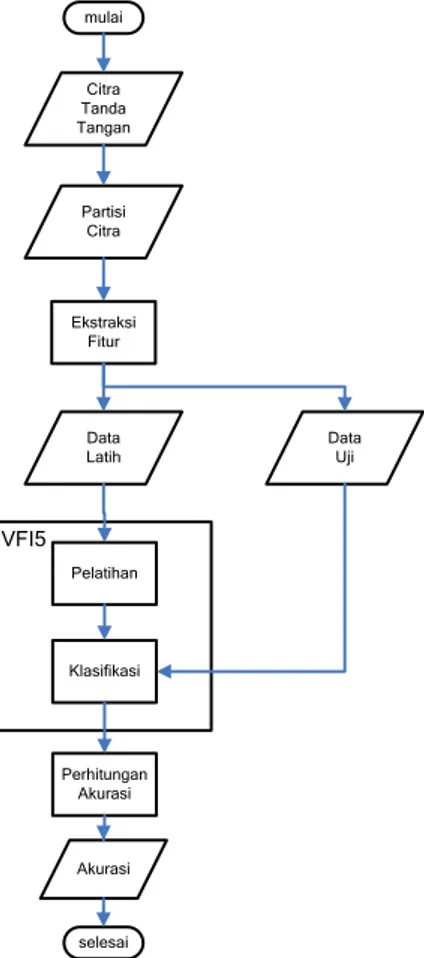
Metodologi yang digunakan pada penelitian ini terdiri atas beberapa tahap. Tahapan-tahapan tersebut dapat dilihat pada Gambar 4.
Data
Data pada penelitian ini merupakan data yang sama dengan yang digunakan pada penelitian Setia (2007). Bentuk awal data pada penelitian ini adalah citra 8 bit berformat PCX dengan ukuran 60 x 40 piksel. Citra yang digunakan pada penelitian ini terdiri atas 10 kelas dengan masing-masing kelas terdiri atas 10 citra. Semua citra yang ada kemudian diubah menjadi citra berformat JPG dengan ukuran 60 x 40 piksel. Pengubahan format ini bertujuan agar data lebih mudah dibaca pada bahasa
pemrograman C#. Data tanda tangan yang digunakan pada penelitian ini tersaji pada Lampiran 1dan Lampiran 2.
VFI5 mulai Citra Tanda Tangan Partisi Citra Ekstraksi Fitur Data Uji Data Latih Pelatihan Klasifikasi Perhitungan Akurasi Akurasi selesai
Gambar 4 Tahapan proses klasifikasi. Partisi Citra
Data yang telah mengalami perubahan format selanjutnya akan dibagi ke dalam beberapa bagian dengan cara dipotong menjadi beberapa partisi. Ukuran partisi citra pada penelitian ini untuk setiap percobaan adalah seragam. Penelitian ini akan mencoba beberapa bentuk dan ukuran partisi citra. Adapun cara pembagian atau pemotongan citra adalah panjang dan lebar dibagi dengan suatu bilangan
m dan n sedemikian sehingga menghasilkan
partisi citra dengan ukuran yang sama. Bilangan
m dan n merupakan bilangan yang habis
membagi panjang dan lebar citra dengan m = 1, 2, 3, 4, 5 dan n = 1, 2, 4. Dengan menggunakan pembagi berupa bilangan m dan n, maka akan dihasilkan partisi sebanyak 1, 2, 3, 4, 5, 6, 8, 10, 12, 16, dan 20 dengan total variasi bentuk sebanyak 15 macam.
Bentuk partisi yang lebih jelas dapat dilihat pada Gambar 3. Baris pertama merupakan partisi dengan jumlah partisi horizontal (n) = 1 dan berturut-turut hingga baris ketiga adalah 2

![[sejarah Peminatan] KI-KD SEJARAH PEMINATAN.docx](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)