PENGUKURAN KINERJA SPAM FILTER MENGGUNAKAN
METODE NAIVE BAYES CLASSIFIER GRAHAM
WILDAN RACHMAN
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2011
PENGUKURAN KINERJA SPAM FILTER MENGGUNAKAN
METODE NAIVE BAYES CLASSIFIER GRAHAM
WILDAN RACHMAN
Skripsi
Sebagai salah satu syarat untuk memperoleh
gelar Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2011
ABSTRACT
WILDAN RACHMAN. Measuring Performance of Spam Filter using Graham‘s Naive Bayes Classifier. Supervised by JULIO ADISANTOSO.
Email spam has become a major problem for internet users and providers. After several failed attempt to filter spam based on heuristic approach such as black-listing or rule-based filtering, content-based filtering using naive Bayes classifier has become the standard for spam filtering today. However, the naive Bayes classifier exists in different forms. This research aims to compare two different forms of naive Bayes which are multinomial naive Bayes using boolean attribute and Graham version of naive Bayes which is popular among several commercial and open source spam filter applications. This research also compares performace of two different methods for data trainings which are train-everything (TEFT) and Train-on-Error (TOE). Finally, this research attempts to identify several hard-to-classify emails.
The evaluation result showed that multinomial naive Bayes had better performances compared to Graham naive Bayes. The result also showed that TEFT successfully outperforms TOE in term of accuracy.
Judul : Pengukuran Kinerja Spam Filter Menggunakan Metode Naive Bayes Classifier Graham Nama : Wildan Rachman
NIM : G64054230
Menyetujui: Pembimbing,
Ir. Julio Adisantoso, M.Kom. NIP. 19620714 198601 1 002
Mengetahui:
Ketua Departemen Ilmu Komputer,
Dr. Ir. Sri Nurdiati, M.Sc. NIP. 19601126 198601 2 001
RIWAYAT HIDUP
Penulis lahir di Bandung pada tanggal 24 Juni 1988 dari ayah Topani dan ibu Yati Rachmiati. Penulis merupakan anak pertama dari dua bersaudara.
Sewaktu SMA penulis menjuarai seleksi Tim Olimpiade Komputer Indonesia (TOKI) tingkat Kabupaten dan Provinsi dan sempat bergabung dengan TOKI sampai dengan babak 16 besar. Tahun 2005 penulis lulus dari SMA Pesantren Unggul Al-Bayan Sukabumi dan melanjutkan kuliah di Institut Pertanian Bogor melalui jalur Prestasi Internasional Nasional (PIN).
Pada tahun 2006 penulis bersama tiga rekan lainnya diutus untuk mengikuti PIMNAS XX di Bandar Lampung mewakili IPB dalam kompetisi pemrograman antar mahasiswa dan berhasil mencapai babak final. Pada tahun 2007 penulis bersama dua rekan lainnya mengikuti kompetisi pemrograman antar mahasiswa yang diadakan oleh Universitas Bina Nusantara dan berhasil mencapai babak final. Pada tahun 2008 penulis menjadi asisten dosen untuk mata kuliah Algoritma dan Pemrograman.
KATA PENGANTAR
Puji syukur Alhamdulillah penulis panjatkan ke hadirat Allah SWT atas limpahan rahmat dan karunia-Nya sehingga skripsi yang berjudul Spam Filter dengan Naive Bayes Classifier ini dapat penulis selesaikan dengan baik. Penelitian ini dilaksanakan di departemen Ilmu Komputer IPB selama periode Januari 2010 sampai dengan Desember 2010.
Selama penulis melakukan penelitian penulis menyadari bahwa banyak pihak yang ikut membantu sehingga skripsi ini dapat dirampungkan, oleh karena itu penulis ingin menyampaikan ucapan terima kasih yang sebesar-besarnya kepada:
1. Orang tua tercinta dan adik atas doa dan berbagai bantuan yang diberikan.
2. Bapak Julio Adisantoso selaku pembimbing akademis yang telah memberikan banyak bantuan serta kemudahan kepada penulis.
3. Sahabat-sahabat terbaik dari ilkomerz 43 Hendro, Ridwan, Iki, Arief B, Ardhan, Musthofa, Endy, Saul, Yuli, dan Reddy yang telah berbagi cerita suka dan duka bersama selama penulis menjadi mahasiswa.
4. Teman-teman satu bimbingan Eka, Tina, Hendrex, Ayu, Awet, Maryam, dan Ryo atas saran, masukan, dan nasihat yang diberikan kepada penulis.
5. Kawan-kawan se-Dota dan se-Tanah air Akbar, Rendy, Aan, Hizri, Doris, Eko, dan Ade F. 6. Ucapan terima kasih khusus untuk Uut yang sudah banyak membantu persiapan seminar dan
sidang penulis.
Penulis menyadari bahwa masih banyak kekurangan yang ditemukan dalam tugas akhir ini. Penulis berharap adanya saran dan kritik yang membangun dari pihak manapun yang membaca tulisan ini. Akhir kata, semoga tulisan ini dapat membawa manfaat.
Bogor, Desember 2010
iii
DAFTAR ISI
Halaman DAFTAR GAMBAR ... iv DAFTAR TABEL ... iv PENDAHULUAN ... 1 Latar Belakang ... 1 Tujuan ... 1 Ruang Lingkup ... 1 Manfaat Penelitian ... 1 TINJAUAN PUSTAKA... 2 Spam ... 2 Klasifikasi Dokumen ... 2Naive Bayes Classifier ... 2
Multinomial NB... 2
Multi-variate Bernoulli NB ... 3
Multinomial NB dengan Atribut Boolean ... 3
Spam Filtering dengan Multinomial NB ... 4
Metode NB Graham ... 5
Metode Training ... 5
METODE PENELITIAN ... 6
Pengumpulan Data ... 6
Pengujian Metode Training ... 6
Pengujian Metode Klasifikasi ... 6
Analisis Kesalahan Klasifikasi ... 7
Lingkungan Pengujian ... 7
HASIL DAN PEMBAHASAN ... 7
Pengumpulan Data ... 7
Detail Proses Pengujian... 8
Pemrosesan Dokumen ... 8
Hasil Pengujian Metode Training ... 10
Hasil Pengujian Metode Klasifikasi ... 12
KESIMPULAN DAN SARAN ... 14
Kesimpulan ... 14
Saran ... 15
iv
DAFTAR GAMBAR
Halaman
1 Hasil pengujian metode training ... 11
2 Hasil pengujian metode klasifikasi menggunakan metode training TEFT ... 12
3 Hasil pengujian metode klasifikasi menggunakan metode training TOE ... 12
DAFTAR TABEL
Halaman 1 Tabel kontingensi kelas hasil prediksi dan kelas sebenarnya ... 72 Proporsi pesan spam untuk masing-masing acakan pengujian ... 8
3 Komponen header yang disertakan dalam proses klasifikasi ... 9
4 Hasil pengujian metode training menggunakan teknik klasifikasi Graham ... 10
5 Hasil pengujian metode klasifikasi dengan metode training TEFT ... 12
1
PENDAHULUAN Latar Belakang
Pemanfaatan teknologi jaringan internet yang semakin meningkat intensitasnya dewasa ini berdampak besar pada metode pengiriman surat. Jalur fisik yang semula menjadi pilihan semakin ditinggalkan dan digantikan oleh jalur pengiriman elektronik dalam bentuk
electronic mail atau biasa disebut dengan
email.
Email sangat populer karena biaya pengiriman pesannya yang jauh lebih murah. Email juga relatif lebih praktis dibandingkan dengan surat konvensional karena tidak perlu menyiapkan perangko maupun amplop. Selain itu, email dapat mencapai objek yang dituju dalam waktu sangat cepat.
Berbagai macam keunggulan yang dimiliki oleh email ternyata banyak disalahgunakan untuk mengirimkan pesan berbau komersial secara massal. Email berisi pesan komersial ataupun pesan lain yang tidak diinginkan dan dikirimkan secara massal tersebut biasa disebut dengan spam.
Spam menimbulkan banyak masalah. Bagi pihak penerima, spam dapat menghabiskan waktu untuk menghapusnya. Bagi penyedia layanan, spam akan memakan banyak sumberdaya seperti kapasitas penyimpanan dan bandwith. Perusahaan keamanan McAfee (2008) dalam laporannya menyatakan bahwa pada tahun 2008 saja, terdapat sekitar 62 triliun spam yang dikirimkan ke seluruh dunia. Berbagai upaya telah dilakukan untuk mengatasi permasalahan spam. Pada mulanya proses penyaringan email spam dilakukan dengan pendekatan rule-based. Email akan dikategorikan sebagai spam menurut aturan-aturan tertentu seperti kemunculan kata, alamat pengirim, dan struktur header.
Pendekatan ini secara praktik kurang efektif dan memiliki tingkat false positive yang tinggi. Selain rule-based, metode
spam-filtering yang banyak digunakan di masa lalu
adalah server blacklist dan signature-based
filtering (Graham 2003).
Pendekatan berbasis content statistic (menggunakan metode naive Bayes classifier) untuk menyaring pesan spam pertama kali diteliti oleh Pantel dan Lin (1998) dan berhasil mencapai tingkat akurasi 92% dengan tingkat
false positive 1,16%. Teknik serupa juga
digunakan oleh Sahami et al. (1998) meskipun
kinerjanya tidak setinggi spam-filter yang dirancang oleh Pantel dan Lin (1998).
Graham (2002) membahas teknik
spam-filtering menggunakan metode naive Bayes classifier (NB) dengan pendekatan yang
cukup berbeda jika dibandingkan dengan metode naive Bayes classifier pada umumnya. Metode ini diklaim berhasil mencapai tingkat akurasi sebesar 99,95% dengan false positive sebesar 0,05%. Kinerja yang cukup tinggi ini membuat metode content-based filtering semakin banyak digunakan dalam aplikasi
spam-filter (Yerazunis 2004).
Penelitian ini melakukan pengujian terhadap dua model dari teknik klasifikasi NB yaitu NB multinomial dengan atribut boolean dan NB Graham. Penelitian ini juga menguji dua metode training yang digunakan pada
spam filter. Lebih lanjut, penelitian ini
membahas komponen pendukung yang digunakan dalam pembuatan spam filter seperti teknik pemrosesan email, pemilihan fitur, dan tokenisasi.
Tujuan
Tujuan dari penelitian ini adalah:
Mengimplementasikan dua model dari
naive Bayes untuk diuji kinerjanya.
Menguji dua jenis metode training. Membahas komponen pendukung yang
digunakan dalam sebuah spam filter. Menganalisis faktor-faktor yang
menyebabkan kesalahan klasifikasi.
Ruang Lingkup
Korpus yang digunakan untuk proses pengujian adalah email MIME1 dalam format
raw2 yang sudah melalui proses pembersihan
dari content-content berbahaya. Email ini disimpan dalam bentuk file teks.
Manfaat Penelitian
Manfaat dari penelitian ini adalah mengetahui model naive Bayes dan metode
training yang memiliki kinerja paling baik,
membahas komponen-komponen pendukung yang digunakan pada spam filter dan menganalisis faktor-faktor yang menyebabkan kegagalan proses klasifikasi.
1
Multipurpose Internet Mail Extension. Standar format
untuk email yang isinya tidak terbatas pada karakter 7bit saja.
2
Email yang masih memiliki komponen header dan body serta tidak mengalami praproses yang terlalu banyak.
2
TINJAUAN PUSTAKA Spam
Spam adalah pesan atau email yang ―tidak diinginkan‖ oleh penerimanya dan dikirimkan secara massal. Makna ―tidak diinginkan‖ disini memiliki arti pihak pengirim tidak mendapatkan izin untuk mengirimkan pesan tersebut dari pihak penerima. Makna ―dikirimkan secara massal‖ berarti pesan tersebut merupakan bagian dari sekumpulan pesan yang memiliki isi yang sama atau sejenis dan dikirimkan sekaligus dalam jumlah besar (Spamhaus 2004).
Selain definisi dari Spamhaus (2004) tersebut, Drucker et al. (1999) mendefinisikan spam sebagai pesan yang tidak diinginkan penerimanya tanpa menyebutkan secara spesifik apakah pesan tersebut dikirimkan secara massal atau tidak.
Untuk merujuk pesan yang tidak termasuk dalam kategori spam pada penelitian ini digunakan istilah ―ham‖.
Klasifikasi Dokumen
Klasifikasi adalah proses untuk menentukan kelas dari suatu objek. Pada klasifikasi dokumen, permasalahannya didefinisikan sebagai berikut: diberikan sebuah deskripsi 𝑑 𝜖 𝕏 dari sebuah dokumen dimana 𝕏 adalah ruang dokumen; dan sebuah himpunan tetap kelas ℂ = {c1,c2,c3,…,cj}, dengan menggunakan metode atau algoritme pembelajaran, dilakukan proses training terhadap fungsi klasifikasi 𝛾 sehingga dapat memetakan dokumen 𝕏 kepada kelas-kelas ℂ:
𝛾 ∶ 𝕏 → ℂ
kelas dapat juga disebut dengan label atau kategori dan didefinisikan sendiri secara manual. Proses pelatihan suatu fungsi klasifikasi menggunakan data latih yang sudah diberikan label secara manual seperti di atas disebut dengan supervised learning (Manning
et al. 2008).
Penelitian ini menggunakan email sebagai ruang dokumen yang nantinya diklasifikasikan ke dalam dua kelas yaitu email yang berisi spam dan email yang tidak bersalah (innocent
mail). Email yang berisi spam selanjutnya
disebut dengan ―spam‖ sementara email yang tidak bersalah selanjutnya disebut dengan ―ham‖.
Naive Bayes Classifier
Naive Bayes classifier (NB) adalah metode
klasifikasi yang mengasumsikan seluruh atribut dari contoh bersifat independen satu sama lain dalam konteks kelas (McCallum & Nigam 1998). Meskipun secara umum asumsi ini adalah asumsi yang buruk, pada praktiknya metode naive Bayes menunjukkan kinerja yang sangat baik (Rish 2001).
Bedasarkan teori Bayes, peluang dokumen 𝑑 untuk masuk ke dalam kelas 𝑐 atau 𝑃 𝑐 𝑑 adalah:
𝑃 𝑐 𝑑 = 𝑃 𝑑 𝑐 𝑃(𝑐) 𝑃(𝑑)
dengan 𝑃 𝑑 𝑐 adalah peluang kemunculan dokumen 𝑑 di kelas 𝑐, 𝑃(𝑐) adalah peluang awal suatu dokumen untuk masuk ke dalam kelas 𝑐, dan 𝑃(𝑑) adalah peluang awal kemunculan dokumen 𝑑.
Peluang awal kemunculan dokumen 𝑑 yaitu 𝑃 𝑑 sama nilainya untuk seluruh kelas 𝑐, sehingga dapat diabaikan:
𝑃 𝑐 𝑑 = 𝑃 𝑑 𝑐 𝑃(𝑐)
Menurut Manning et al. (2008) kelas yang paling sesuai bagi dokumen 𝑑 adalah kelas yang memiliki nilai 𝑃 𝑐 𝑑 paling tinggi yaitu:
max
𝑐∈ℂ 𝑃 𝑑 𝑐 𝑃(𝑐)
Nilai peluang awal 𝑃(𝑐) dapat diestimasi dengan melihat jumlah dokumen yang dimiliki oleh kelas 𝑐 relatif terhadap jumlah seluruh dokumen yang ada. Nilai peluang awal 𝑃 𝑑 𝑐 diestimasi secara berbeda untuk setiap model NB (Metsis et al. 2006).
Multinomial NB
Pada multinomial NB, dokumen direpresentasikan sebagai sekumpulan token yang terdapat pada dokumen 𝑑 yaitu 𝑡1, … , 𝑡𝑘, … , 𝑡𝑛𝑑 dimana token yang muncul
lebih dari satu kali pada dokumen yang sama ikut diperhitungkan.
Nilai dari 𝑃 𝑑 𝑐 yaitu peluang kemunculan dokumen 𝑑 pada kelas 𝑐 dapat diestimasi dengan cara:
𝑃 𝑑 𝑐 = 𝑃( 𝑡1, … , 𝑡𝑘, … , 𝑡𝑛𝑑 |𝑐)
Karena banyaknya kombinasi dari 𝑡1, … , 𝑡𝑘, … , 𝑡𝑛𝑑 yang harus diestimasi, akan
sangat sulit untuk mendapatkan nilai 𝑃 𝑑 𝑐 menggunakan model ini secara langsung.
3 Selain itu, tidak ada batasan yang jelas
mengenai panjang dari dokumen yang mungkin sehingga dapat dikatakan bahwa kombinasi dari 𝑡1, … , 𝑡𝑘, … , 𝑡𝑛𝑑 yang
mungkin berjumlah tak hingga (Manning et al. 2008). Oleh sebab itu, dibuat suatu asumsi bahwa kemunculan masing-masing token 𝑡 bersifat independen antara satu token dengan token yang lainnya. Dengan asumsi tersebut, nilai dari 𝑃 𝑑 𝑐 dapat diestimasi sebagai berikut:
𝑃 𝑑 𝑐 = 𝑃(𝑡𝑘|𝑐) 1≤𝑘 ≤𝑛𝑑
sehingga peluang suatu dokumen 𝑑 untuk masuk ke dalam kelas 𝑐 dapat diestimasi dengan cara:
𝑃 𝑐 𝑑 ∝ 𝑃 𝑐 𝑃(𝑡𝑘|𝑐) 1≤𝑘 ≤𝑛𝑑
dengan 𝑃(𝑡𝑘|𝑐) adalah peluang dari suatu
token 𝑡𝑘 muncul pada dokumen yang
diketahui memiliki kelas c; sedangkan 𝑃 𝑐 adalah peluang awal dari suatu dokumen untuk masuk ke dalam kelas c.
Nilai dari 𝑃 𝑐 dapat diestimasi dengan melihat frekuensi kemunculan dokumen pada kelas 𝑐 relatif terhadap jumlah seluruh dokumen yaitu:
𝑃 𝑐 = 𝑁𝑐 𝑁
dengan 𝑁𝑐 adalah jumlah dokumen yang
terdapat di kelas 𝑐 dan 𝑁 adalah jumlah seluruh dokumen yang ada.
Nilai 𝑃 𝑡 𝑐 untuk masing-masing token didapatkan dari proses training. Lebih sepesifik lagi, nilai 𝑃 𝑡 𝑐 diestimasi dengan melihat frekuensi token 𝑡 yang muncul pada kelas c relatif terhadap jumlah kemunculan seluruh token yang ada di kelas c yaitu:
𝑃 𝑡𝑘 𝑐 =
𝑇𝑐𝑡
𝑇𝑐𝑡 ′ 𝑡′𝜖𝑣
dengan 𝑇𝑐𝑡 adalah jumlah kemunculan token 𝑡
dalam dokumen training yang berada di kelas
c termasuk di dalamnya kemunculan token
yang berjumlah lebih dari satu kali; dan 𝑇𝑐𝑡 ′
𝑡′𝜖𝑣 adalah jumlah seluruh token yang
terdapat pada seluruh dokumen di kelas c termasuk untuk token-token yang muncul berulang kali pada dokumen yang sama.
Permasalahan akan terjadi saat ditemukan token yang hanya muncul pada salah satu kelas saja atau tidak muncul di kelas manapun
pada proses training. Nilai 𝑃(𝑡𝑘|𝑐) yang
dihasilkan akan sama dengan nol sehingga mengacaukan perhitungan 𝑃 𝑑 𝑐 . Untuk mengatasi permasalahan tersebut, digunakan
laplace smoothing yaitu menambahkan jumlah
kemunculan setiap token sebanyak satu sehingga perhitungan nilai dari 𝑃 𝑡𝑘 𝑐
menjadi: 𝑃 𝑡𝑘 𝑐 = 𝑇𝑐𝑡+ 1 (𝑇𝑐 𝑡′ + 1) 𝑡′𝜖𝑣 𝑃 𝑡𝑘 𝑐 = 𝑇𝑐𝑡+ 1 𝑇𝑐𝑡 ′ 𝑡′𝜖𝑣 + 𝐵′
dengan 𝐵′ adalah jumlah seluruh vocabulary
(kata unik) yang terdapat dalam data training. Multi-variate Bernoulli NB
Berbeda dengan multinomial NB,
multi-variate Bernoulli NB hanya mencatat indikator kemunculan suatu token tanpa menghitung term frequency-nya. Perbedaan lain yang cukup menonjol adalah multi-variate Bernoulli NB ikut memperhitungkan token-token yang tidak muncul dalam dokumen pada proses klasifikasinya.
Perbedaan ini terjadi karena perbedaan dalam cara menduga 𝑃 𝑡𝑘 𝑐 . Multi-variate
Bernoulli NB menduga 𝑃 𝑡𝑘 𝑐 sebagai fraksi
dari dokumen pada kelas 𝑐 yang mengandung token 𝑡 sementara multinomial NB menduga 𝑃 𝑡𝑘 𝑐 sebagai fraksi dari token pada
dokumen di kelas 𝑐 yang mengandung token 𝑡 (Manning et al. 2008).
Multinomial NB dengan Atribut Boolean
Multinomial NB dengan atribut boolean hampir sama dengan multinomial NB yang menggunakan atribut term frequency (tf) termasuk dalam proses pendugaan nilai 𝑃 𝑡 𝑐 . Perbedaannya terletak pada atribut yang digunakan yaitu atribut boolean. Pada atribut boolean, token yang muncul berulang kali tetap dianggap sebagai satu kemunculan untuk setiap dokumennya.
Schneider (2004) dalam penelitiannya menyatakan bahwa term frequency bukanlah faktor yang menjadi penyebab multinomial NB memiliki kinerja yang lebih baik dibandingkan dengan multi-variate Bernoulli NB. Perbedaan kinerja antar dua metode tersebut lebih disebabkan oleh bagaimana kedua metode tersebut memperlakukan bukti yang tidak ada (negative evidence) yaitu token yang tidak muncul pada pesan. Pada metode
4
multi-variate Bernoulli, hasil dari klasifikasi
lebih banyak dipengaruhi oleh kata-kata yang tidak ada di dalam pesan.
Schneider (2004) menunjukkan bahwa multinomial NB akan memiliki kinerja yang lebih baik jika atribut term frequency digantikan dengan atribut boolean.
Penggunaan atribut term frequency menyebabkan pengaruh negative evidence menjadi lebih besar dibandingkan dengan penggunan atribut boolean. Karena kemunculan setiap term akan dibandingkan dengan jumlah kemunculan dari seluruh kata yang terdapat pada kelas tersebut, penggunaan atribut term frequency menyebabkan nilai peluang untuk setiap term akan semakin kecil. Dengan menggunakan atribut boolean, efek dari negative evidence dapat dikurangi karena kemunculan setiap kata hanya dicatat satu kali saja pada setiap dokumennya.
Spam Filtering dengan Multinomial NB
Spam Filtering adalah proses menyaring
email menjadi dua buah kategori yaitu spam dan ham. Meskipun aksi pengiriman pesan dalam jumlah massal merupakan salah satu ciri utama yang menyebabkan pesan tersebut dikatakan sebagai spam, dapat dilihat bahwa kandungan bahasa yang digunakan oleh pesan spam memiliki tema tersendiri dan jarang ditemukan pada pesan biasa (ham). Dengan karakteristik seperti ini, teknik klasifikasi teks dapat diterapkan untuk permasalahan spam
filtering (Androutsopoulos et al. 2000).
Jika dimisalkan 𝑆 sebagai kelas dari email 𝐸 yang termasuk ke dalam kategori spam, maka dengan teori Bayes, peluang email 𝐸 adalah spam 𝑆 yaitu 𝑃 𝑆 𝐸 dapat diestimasikan sebagai berikut:
𝑃 𝑆 𝐸 =𝑃 𝐸 𝑆 𝑃(𝑆) 𝑃(𝐸)
dengan 𝑃 𝐸 𝑆 adalah peluang kemunculan email 𝐸 pada kelas spam, 𝑃 𝑆 adalah peluang awal suatu email masuk ke dalam kelas spam dan 𝑃(𝐸) adalah peluang kemunculan email 𝐸.
Dengan cara yang sama, peluang email 𝐸 masuk ke dalam kelas ham 𝐻 dapat diestimasikan dengan cara:
𝑃 𝐻 𝐸 =𝑃 𝐸 𝐻 𝑃(𝐻) 𝑃(𝐸)
Pada metode multinomial NB, nilai dari 𝑃 𝐸 𝑆 dapat diestimasikan sebagai berikut:
𝑃 𝐸 𝑆 = 𝑃 𝑤1, … , 𝑤𝑛|𝑆
Karena antara satu token dengan token yang lainnya diasumsikan independen, maka nilai 𝑃 𝑤1, … , 𝑤𝑛|𝑆 dapat dihitung dengan cara:
= 𝑃 𝑤𝑖|𝑆 𝑛
𝑖=1
Lalu dengan cara yang sama, untuk 𝑃 𝐸 𝐻 : 𝑃 𝐸 𝐻 = 𝑃 𝑤1, … , 𝑤𝑛|𝐻
= 𝑃 𝑤𝑖|𝐻 𝑛
𝑖=1
Sementara itu, dengan merujuk kembali pada teori NB multinomial, nilai dari 𝑃 𝑤𝑖|𝑆 dapat
dihitung dengan cara: 𝑃(𝑤𝑖|𝑆) =
𝑇𝑠𝑤 + 1
𝑇𝑠𝑤′
𝑤′𝜖𝑣 + 𝐵′
dengan 𝑇𝑠𝑤 adalah jumlah kemunculan
token 𝑤 pada email dengan kelas 𝑆, B‘ adalah jumlah vocabulary yang terdapat dalam data
training, sementara 𝑤′𝜖𝑣𝑇𝑠𝑤′ adalah jumlah kemunculan seluruh token pada kelas S (Sun 2009).
Karena NB yang digunakan adalah NB multinomial dengan atribut boolean, seluruh kemunculan token dihitung satu untuk setiap dokumennya meskipun token tersebut muncul berulang kali.
Selanjutnya kelas dari email 𝐸 dapat ditentukan dengan membandingkan antara 𝑃 𝑆 𝐸 dengan 𝑃 𝐻 𝐸 : 𝑃 𝑆 𝐸 𝑃 𝐻 𝐸 = 𝑃 𝐸 𝑆 𝑃(𝑆) 𝑃 𝐸 𝐻 𝑃(𝐻) 𝑃 𝑆 𝐸 𝑃 𝐻 𝐸 = 𝑃 𝑤𝑖|𝑆 𝑛 𝑖=1 𝑃(𝑆) 𝑃 𝑤𝑖|𝐻 𝑛 𝑖=1 𝑃(𝐻) 𝑃 𝑆 𝐸 𝑃 𝐻 𝐸 = 𝑃(𝑆) 𝑃(𝐻) 𝑃 𝑤𝑖|𝑆 𝑃 𝑤𝑖|𝐻 n i
Karena pada proses perhitungannya nilai-nilai di atas bisa sangat kecil dan menghasilkan kesalahan presisi (Manning et al. 2008), kedua sisi dihitung hasil log-nya sehingga menjadi:
log𝑃 𝑆 𝐸 𝑃 𝐻 𝐸 = log 𝑃(𝑆) 𝑃(𝐻) 𝑃 𝑤𝑖|𝑆 𝑃 𝑤𝑖|𝐻 n i log𝑃 𝑆 𝐸 𝑃 𝐻 𝐸 = log 𝑃 𝑆 𝑃(𝐻)+ log 𝑃 𝑤𝑖|𝑆 𝑃 𝑤𝑖|𝐻 𝑛 𝑖
5 Jika persamaan di atas menghasilkan nilai
lebih besar daripada nol, nilai dari 𝑃 𝑆 𝐸 lebih besar daripada 𝑃 𝐻 𝐸 sehingga email 𝐸 masuk ke dalam kategori spam. Sebaliknya, jika nilainya lebih kecil daripada nol, email 𝐸 masuk ke dalam kategori ham.
Metode NB Graham
Graham (2002) menggunakan pendekatan yang berbeda dalam mengimplementasikan
naive Bayes. Jika pada metode yang telah
dibahas sebelumnya digunakan estimasi nilai 𝑃 𝑤𝑖|𝑆 untuk mendapatkan peluang suatu
email masuk ke dalam kategori spam, metode NB Graham menggunakan 𝑃 𝑆|𝑤𝑖 yang
diestimasikan sebagai peluang suatu pesan untuk masuk dalam kategori spam jika diketahui pesan tersebut mengandung token 𝑤𝑖 yaitu: 𝑃 𝑆𝑝𝑎𝑚|𝑤𝑖 = 𝑓𝑖𝑠 𝑛𝑠 𝑓𝑖𝑠 𝑛𝑠 + 𝑓𝑖 𝑛
dimana 𝑓𝑖𝑠 dan 𝑓𝑖 berturut-turut adalah
jumlah pesan pada kelas spam dan ham yang mengandung token i, sementara 𝑛𝑠 dan 𝑛
berturut-turut adalah jumlah pesan yang tedapat pada kelas spam dan ham. Semakin sering suatu token muncul di kelas spam, nilai peluangnya akan semakin mendekati satu. (Crossan 2009).
Graham (2002) menemukan bahwa dengan mengalikan jumlah kemunculan token-token yang ada pada ham dengan faktor dua, jumlah dari false positive dapat dikurangi. Jika suatu token hanya muncul pada kelas spam saja, token tersebut akan langsung diberikan nilai peluang 0,99 sementara jika token hanya muncul di kelas ham saja, token tersebut akan diberikan nilai peluang 0,01. Untuk token yang belum pernah muncul sebelumnya atau memiliki jumlah kemunculan lebih kecil dari lima, diberikan peluang netral 0,4. Nilai 0,4 dipilih untuk lebih mengurangi lagi tingkat
false positive.
Untuk menghitung peluang suatu email masuk ke dalam kelas spam, metode NB Graham hanya menggunakan lima belas token yang paling signifikan saja. Seberapa signifikan suatu token dalam menentukan hasil klasifikasi ditentukan dengan melihat selisih nilai 𝑃 𝑆|𝑤𝑖 token tersebut dengan
nilai peluang netral 0,5.
Selanjutnya, lima belas token yang paling signifikan tersebut digunakan untuk
menghitung peluang suatu email masuk ke dalam kelas spam dengan persamaan:
𝑃 𝑆|𝑤1, … , 𝑤𝑔 = 𝑃(𝑆|𝑤𝑖) 15 𝑖=1 𝑃(𝐶′|𝑤 𝑖) 15 𝑖=1 𝐶′𝜖 𝑆,𝐻
dengan S merupakan event saat email masuk ke dalam kelas spam. Pesan akan dikategorikan sebagai spam jika persamaan di atas bernilai lebih besar dari 0,9.
Metode Training
Sebelum dapat melakukan proses klasifikasi, spam filter perlu ditunjukkan contoh-contoh email dari masing-masing kelas. Proses ini disebut dengan training (Zdziarski 2005).
Pada penelitian ini, terdapat dua macam metode training yang diujikan yaitu Train
Everything (TEFT) dan Train-On-Error
(TOE).
1. Train-Everything (TEFT)
Pada metode TEFT seluruh email yang masuk akan di-training tanpa memperhatikan kebenaran hasil klasifikasinya.
Kelebihan dari metode ini adalah dataset milik spam filter akan terus menyesuaikan nilainya sesuai dengan email yang diterimanya. Sebagai contoh, jika pengguna berlangganan mailing-list tertentu, filter akan segera mengenali token-token di dalamnya sebagai bagian dari kelas ham.
Kekurangan dari metode ini adalah filter akan menjadi sangat rentan terhadap komposisi email pengguna. Sebagai contoh, jika pengguna terlalu banyak menerima email spam, metode training ini akan mengenali terlalu banyak token sebagai token spam karena kurangnya data ham. Hal ini dapat mengganggu proses klasifikasi ham yang masuk.
2. Training On Error (TOE)
Pada metode TOE, email hanya akan dimasukkan ke dalam proses training jika terjadi kesalahan klasifikasi. Kelebihan metode TOE adalah proses training hanya dilakukan seperlunya sehingga menghemat
resource seperti proses disk-writing yang
lambat. Metode TOE juga menyimpan lebih sedikit token sehingga dapat menghemat
space.
Kelebihan metode training ini ternyata juga menjadi kelemahannya. TOE hanya akan melakukan proses training jika menemukan
6 kesalahan dalam proses klasifikasi. Hal ini
menyebabkan TOE cenderung lambat dalam mengenali token-token baru saat terjadi perubahan kebiasaan penerimaan email pengguna.
3. Metode Training Lainnya
Selain TOE dan TEFT, masih ada dua metode training lagi yang dapat digunakan dalam sistem spam filter. Metode tersebut adalah Training Until Mature (TUM) dan
Training Until No Error (TUNE).
Pada metode TUM, proses training untuk token tertentu tidak akan diteruskan lagi saat
filter sudah merasa ―cukup mengenal‖ token
tertentu. TUM hanya akan melakukan proses
training saat menemukan kesalahan.
Pada metode TUNE, proses training dilakukan beberapa kali dalam bentuk
training-loop sampai tidak ditemukan error
atau akurasi tidak dapat ditingkatkan lagi. Yerazunis (2004) menemukan bahwa metode
training TUNE hanya sedikit lebih baik
dibandingkan dengan TOE meskipun proses
training yang dilakukan oleh TUNE jauh lebih
lama.
METODE PENELITIAN
Penelitian ini terdiri atas empat tahap yaitu pengumpulan data, pengujian metode training, pengujian metode klasifikasi dan analisis kesalahan klasifikasi.
Untuk metode training, terdapat dua macam metode yang diuji yaitu TEFT (Training Everything) dan TOE (Training On
Error). Masing-masing metode training
diduga memiliki kinerja yang berbeda sehingga dilakukan pengujian untuk menentukan metode training mana yang memiliki kinerja yang lebih baik.
Selanjutnya dilakukan pengujian terhadap dua model NB yaitu Bayes Multinomial dengan atribut boolean dan Metode Bayes Graham. Analisis juga dilakukan terhadap faktor-faktor yang menyebabkan terjadinya kesalahan klasifikasi.
Bahasa pemrograman yang digunakan adalah PHP meskipun penggunaan bahasa pemrograman lain seperti C diduga bisa meningkatkan performance sistem secara signifikan.
Pengumpulan Data
Tahap penelitian yang pertama adalah tahap pengumpulan data. Data yang digunakan sebagai data uji adalah korpus email dalam format aslinya yaitu email yang masih memiliki bagian header dan body. Data ini berisi campuran pesan yang sudah diberi dua macal label yaitu ‗ham‘ dan ‗spam‘ sesuai dengan kelasnya. Proses pemberian kelas tersebut dilakukan secara manual.
Pengujian Metode Training
Terdapat dua jenis metode training yang diuji dalam penelitian ini yaitu metode
Training Everything (TEFT) dan metode Training on Error (TOE). Pengujian dilakukan dengan cara mengukur akurasi kedua metode tersebut saat dipasangkan dengan metode Graham.
Pengujian Metode Klasifikasi
Pada penelitian ini, NB multinomial yang diujikan adalah NB multinomial yang menggunakan atribut boolean sehingga istilah NB multinomial selanjutnya akan merujuk pada NB multinomial yang menggunakan atribut boolean.
Untuk membandingkan kinerja dari versi-versi NB yang diujikan, digunakan metode pengujian yang sama dengan metode evaluasi pada penelitian Yerazunis (2004) yaitu: 1. Disediakan data uji berupa korpus email
yang sudah diklasifikasikan ke dalam dua kelas yaitu ‗ham‘ dan ‗spam‘. Setiap email diberikan label sesuai dengan kelasnya. Data yang sudah diberi label tersebut kemudian digabungkan.
2. Data uji kemudian diacak sebanyak sepuluh kali. Setiap acakan dicatat urutan pembacaannya sehingga seluruh metode yang diuji dievaluasi menggunakan acakan dan urutan pembacaan data yang sama. 3. Untuk setiap acakan, diambil sebanyak N
data yang nantinya digunakan sebagai data
testing akhir.
4. Proses pengujian dilakukan sebanyak jumlah acakan yaitu sepuluh kali pengujian.
5. Langkah-langkah di atas menghasilkan data awal hasil pengujian berupa jumlah kesalahan klasifikasi dari 10 kali N data
testing.
Data awal hasil pengujian diolah lagi untuk mendapatkan tingkat akurasi hasil prediksi berupa jumlah true positive, true
7
negative, false positive, dan false negative
seperti yang dapat dilihat pada Tabel 1. Tabel 1 Tabel kontingensi kelas hasil
prediksi dan kelas sebenarnya
Kelas Prediksi Spam Ham Kelas Sebenarnya Spam TP FN Ham FP TN
Hasil positive merujuk pada email yang diprediksikan masuk ke dalam kategori spam dan hasil negative merujuk pada email yang diprediksikan masuk ke dalam kategori ham oleh spam filter. Keterangan selengkapnya adalah sebagai berikut:
True Positive (TP), yaitu email dari kelas spam yang benar diklasifikasikan sebagai spam.
True Negative (TN), yaitu email dari kelas ham yang benar diklasifikasikan sebagai ham.
False Positive (FP), yaitu email dari kelas ham yang salah diklasifikasikan sebagai spam.
False Negatif (FN), yaitu email dari kelas spam yang salah diklasifikasikan sebagai ham.
Selanjutnya, kinerja masing-masing metode dievaluasi dengan melihat nilai dari
spam recall dan ham recall-nya. Spam recall
adalah proporsi dari pesan spam yang berhasil diblok oleh filter, sedangkan ham recall menunjukkan proporsi dari pesan ham yang dilewatkan oleh filter (Metsis et al. 2006).
Nilai dari Spam Recall dihitung dengan membandingkan jumlah email spam yang benar diklasifikasikan sebagai spam (true
positive) dengan jumlah seluruh email spam
yang tedapat pada data uji yaitu: 𝑆𝑝𝑎𝑚 𝑅𝑒𝑐𝑎𝑙𝑙 = 𝑇𝑃
𝑇𝑃 + 𝐹𝑁
dengan cara yang sama, nilai dari ham recall dapat dihitung dengan cara:
𝐻𝑎𝑚 𝑅𝑒𝑐𝑎𝑙𝑙 = 𝑇𝑁 𝑇𝑁 + 𝐹𝑃
Analisis Kesalahan Klasifikasi
Setelah pengujian untuk metode training dan metode klasifikasi selesai dilakukan, penelitian selanjutnya berfokus pada analisis
kesalahan klasifikasi. Pesan-pesan yang gagal diklasifikasikan ke dalam kelas yang benar diteliti lebih lanjut untuk dicari penyebab kegagalan klasifikasinya.
Lingkungan Pengujian
Perangkat lunak yang digunakan dalam pengujian sebagai berikut:
Sistem Operasi Windows 7.
Bahasa pemrograman PHP versi 5.2.9. EzMailParser dari EzComponent sebagai
library yang digunakan untuk membaca
struktur email.
Web Server Apache 2.2.11
Sementara itu, perangkat keras yang digunakan untuk pengujian adalah:
Prosesor intel core i5 M450 pada kecepatan 2.4Ghz.
Memory DDR3 sebesar 2GB.
Untuk mempercepat proses pengujian, data hasil training disimpan langsung dalam memori. Data hasil pengujian di-serialize lalu disimpan ke dalam file teks untuk digunakan dalam tahap analisis kesalahan klasifikasi.
HASIL DAN PEMBAHASAN Pengumpulan Data
Korpus yang digunakan pada penelitian ini adalah public email corpus yang disediakan oleh Spamassasin dengan kode prefix ―20030228‖ 3
. Korpus ini terdiri atas 6.047 pesan email yang sudah diklasifikasikan sebelumnya secara manual dengan komposisi: 3.900 easy-ham, yaitu pesan ham yang dapat dibedakan dengan mudah dari pesan spam karena tidak banyak mengandung ciri-ciri yang dimiliki oleh pesan spam. 250 hard-ham, yaitu pesan bertipe ham
namun mengandung cukup banyak feature yang biasa terdapat pada pesan spam sehingga agak sulit diklasifikasikan. 1.897 spam, yaitu pesan yang masuk
dalam kategori spam.
Pesan yang memiliki label easy-ham dan
hard-ham tidak dibedakan secara khusus dan
digabungkan ke dalam satu kategori yaitu ―ham‖. Dengan demikian, data yang
3
Korpus email dari Spamassasin dapat diunduh di alamat http://www.spamassassin.org/publiccorpus/.
8 digunakan untuk penelitian mengandung spam
sebanyak 31%.
Detail Proses Pengujian
Pengujian kinerja metode klasifikasi dilakukan dengan metode training TEFT dan TOE sementara proses pengujian metode
training dilakukan dengan menggunakan
metode Graham. Langkah pengujian yang dilakukan adalah sebagai berikut:
Data uji yang digunakan berjumlah 6.047 email dengan proporsi spam sebesar 31%. Data uji ini diacak sebanyak sepuluh kali
lalu dicatat ukuran pembacaannya.
Pengukuran kinerja dilakukan dengan melihat akurasi pada saat pemrosesan 750 data terakhir.
Karena pengujian dilakukan sebanyak sepuluh kali pengulangan, data awal jumlah kesalahan klasifikasi yang ditampilkan adalah jumlah kesalahan per 7.500 kali uji.
Perbandingan jumlah spam dan ham untuk data testing pada masing-masing acakan dapat dilihat pada Tabel 2.
Tabel 2 Proporsi pesan spam untuk masing-masing acakan pengujian
Acakan Ke Jumlah Ham Jumlah Spam Persen Spam 1 529 221 29,46 2 512 238 31,73 3 514 236 31,46 4 528 222 29,60 5 518 232 30,93 6 484 266 35,46 7 518 232 30,93 8 508 242 32,26 9 529 221 29,46 10 511 239 31,86 Jumlah 5.151 2.349 31,32 Pemrosesan Dokumen
Untuk fase training dan fase testing, setiap email diproses dengan teknik yang sama. Pemrosesan yang dilakukan terdiri atas empat tahap yaitu dekomposisi struktur email, pemilihan atribut, penyeragaman sistem karakter, dan tokenisasi.
1. Dekomposisi Struktur Email
Tahap pemrosesan dokumen yang pertama adalah dekomposisi struktur email. Email yang hendak diproses dipecah menjadi bagian-bagian yang lebih kecil. Tahapan ini diperlukan karena masing-masing komponen akan diolah secara berbeda pada saat dilakukan proses tokenisasi.
Secara garis besar, tahapan dekomposisi yang dilakukan sebagai berikut:
Email dipecah ke dalam dua bagian utama yaitu header dan body.
Komponen header dipecah lagi menjadi komponen-komponen yang lebih kecil sesuai dengan informasi yang dikandungnya.
Untuk komponen body, pesan yang terdiri atas beberapa part akan digabungkan menjadi satu. Jika pada email terdapat
attachment, hanya informasi nama file dan
jenisnya yang disertakan.
Berdasarkan hasil pengamatan saat dilakukan proses tahap pertama ini, terlihat bahwa email dari kelas spam terkadang memiliki infomasi header yang salah ataupun rusak. Sebagai contoh, pada beberapa email, informasi waktu pengiriman email ditulis dengan format di luar standar atau waktu yang dipastikan salah, contoh tahun 2020.
Saat ini belum dapat disimpulkan apakah kesalahan penulisan header tersebut merupakan suatu kesengajaan atau bukan. Bagaimanapun, kesalahan seperti ini sangat jarang ditemukan pada email ham.
Untuk bagian body, mayoritas email dari kelas ham hanya menggunakan satu part saja. Lain halnya dengan email dari kelas spam dimana email dengan body multipart bukanlah hal yang jarang ditemui.
2. Pemilihan Atribut
Setelah email dipecah menjadi komponen-komponen yang lebih kecil, tahapan selanjutnya adalah pemilihan komponen yang akan disertakan ke dalam proses klasifikasi. Tahapan ini berlaku terutama untuk bagian
header dari email.
Tidak semua komponen dari header email dimasukkan ke dalam klasifikasi. Hal ini dilakukan karena terdapat beberapa informasi pada header yang telah mengalami kerusakan
9 ataupun telah diubah sebelumnya oleh pihak
Spamassasin4 sebagai penyedia data. Selain itu, terdapat komponen header yang hanya muncul di sebagian kecil dokumen saja. Komponen-komponen tersebut adalah informasi tambahan yang biasanya disertakan oleh email client atau Mail Transfer Agent yang dilalui oleh email sebelum sampai ke tujuan.
Untuk bagian body, email-email yang dipecah ke dalam beberapa part akan digabungkan menjadi satu. Seluruh metadata yang terkandung dalam setiap part ikut disertakan pada proses klasifikasi. Metadata tersebut berguna untuk menglasifikasikan email yang hanya berisi attachment saja atau email yang terdiri atas beberapa part.
Komponen header yang disertakan dalam proses klasifikasi serta informasi yang terkandung di dalamnya dapat dilihat pada Tabel 3.
Tabel 3 Komponen header yang disertakan dalam proses klasifikasi
Nama Keterangan
subject Subjek dari pesan.
sender Nama dan alamat pengirim pesan.
return-path Alamat pengembalian pesan jika terjadi
bouncing5.
x-mailer Aplikasi yang digunakan oleh pengguna untuk mengirimkan pesan.
reply-to Alamat yang digunakan untuk membalas pesan.
content- transfer-encoding
Metode content transfer
encoding yang digunakan
jika ada. 3. Penyeragaman Sistem Karakter
Tahapan pemrosesan selanjutnya adalah penyeragaman sistem karakter yaitu encoding dan character set yang digunakan. Email pada data uji memiliki sistem encoding dan
character set yang berbeda-beda. Perbedaan
tersebut terutama terlihat pada bagian subject, nama pengirim, dan isi utamanya. Hal tersebut
4
Perubahan ini dilakukan terutama pada alamat email penerima dan jalur server yang dilalui oleh email. 5
Kondisi dimana alamat penerima tidak ditemukan.
disebabkan oleh perbedaan sistem yang digunakan oleh pengirim. Penggunaan sistem
encoding khusus kadang dilakukan dengan
sengaja oleh pengirim spam dengan tujuan mempersulit pemrosesan email oleh spam
filter.
Secara garis besar, terdapat dua jenis
encoding yang digunakan oleh email:
Encoding dan Character Set yang digunakan untuk penulisan karakter-karakter pada email seperti UTF-8 dan latin1.
Content-Transfer-Encoding yaitu sistem
encoding yang digunakan khusus untuk
mengirimkan data binary dalam format 7bit ASCII text.
Untuk menghindari kesalahan pembacaan terutama saat proses tokenisasi, dilakukan penyeragaman sistem encoding dan
character-set yang digunakan menjadi UTF-8.
Jika email menggunakan
content-transfer-encoding tertentu seperti Base64 content-transfer-encoding
atau Quote-printable, isinya akan dikonversi terlebih dahulu menjadi data aslinya. Jika data aslinya ternyata berbentuk file binary, isi dari
file yang dihasilkan tidak disertakan, namun
informasi jenis file yang dikandung (jika ada) akan ikut disertakan ke dalam klasifikasi.
Dari hasil pengamatan, dapat disimpulkan bahwa penggunaan encoding dapat menjadi penciri yang baik dalam membedakan email dari kelas ham dengan email dari kelas spam. Email-email yang tidak bersalah atau email ham cenderung menggunakan sistem karakter
encoding yang seragam atau sejenis seperti
latin1 dan ISO-8859-1 untuk orang yang mayoritas emailnya berbahasa Inggris atau bahasa lain yang menggunakan karakter latin.
Sementara itu di kelas spam, sistem
encoding yang digunakan cenderung lebih
bervariasi tergantung dari asal pengirimnya. Seringkali email dari kelas spam mencantumkan informasi encoding yang salah atau tidak standar. Sebagai contoh, sistem
encoding ks_c_5601-19876 hanya ditemukan pada email spam.
Selain sistem encoding untuk karakter, penggunaan content-transfer-encoding juga dapat membantu proses pengenalan email spam. Dari hasil pengamatan pada data, hanya email-email dari kelas spam yang menggunakan content-transfer-encoding
6
Encoding ini banyak ditemukan pada email spam
yang menggunakan karakter Korea. Encoding yang benar untuk karakter korea adalah EU-KR.
10 khusus seperti Base64 maupun
Quote-printable. Pada beberapa kasus, email yang
menggunakan content-transfer-encoding
Base64 tidak dapat dikonversikan isinya karena terdapat kerusakan atau miss pada rangkaian karakter hasil encoding-nya. Pada kasus tersebut, proses pengklasifikasian hanya dapat mengandalkan informasi yang terdapat pada header email dan metadata yang disertakan.
4. Tokenisasi
Tahapan terakhir dari pemrosesan email adalah tokenisasi. Tokenisasi adalah proses memotong teks menjadi bagian-bagian yang disebut dengan token. Selain pemotongan, tokenisasi juga mungkin diikuti dengan proses pembuangan karakter-karakter tertentu (Manning et al. 2008).
Proses tokenisasi dilakukan sebagai berikut:
Teks dipotong menjadi token-token. Karakter yang dianggap sebagai karakter pemisah token didefinisikan dengan ekspresi regular berikut:
/[\s.;,\"':?{}\[\]()%=<>+\/*&@_-]+/
Token yang hanya terdiri atas karakter numerik saja tidak ikut disertakan.
Besar kecilnya karakter dari token (case) dipertahankan. Tidak dilakukan penyeragaman.
Karakter khusus yang menempel pada token dan tidak termasuk ke dalam karakter pemisah token juga dipertahankan.
Karakter ‗~‘, ‗|‘ dan ‗!‘ yang menempel di awal token dibuang.
Karakter ‗#‘ dan ‗$‘ yang menempel di akhir token dibuang.
Jika email yang sedang dibaca mengandung tag HTML, seluruh tag yang ditemukan akan ikut diproses termasuk
attribute yang terdapat di dalamnya. Tag
komentar HTML tidak akan diproses sama sekali dan dibuang terlebih dahulu sebelum keseluruhan proses tokenisasi dimulai.
Khusus untuk URL (Uniform Resources
Locator), proses tokenisasi dilakukan sebelum
proses tokenisasi pada body atau komponen
header email dilakukan. Keberadaan URL
pada masing-masing komponen email akan diperiksa terlebih dahulu. Jika ternyata ada, URL akan diekstrak dari teks dan ditokenisasi seperti aturan di atas. Perbedaannya,
token-token yang dihasilkan akan diberi prefix ‗URL*‘ untuk menandai bahwa token tersebut berasal dari suatu URL dan tidak bercampur dengan token-token biasa. Proses ini disebut dengan proses optimasi URL dan diduga dapat meningkatkan kinerja dari spam filter
(Graham 2002).
Untuk komponen header, token-token yang dihasilkan akan diberi prefix khusus (seperti halnya pada URL) untuk membedakannya dengan token biasa yang terdapat pada body. Sebagai contoh, jika suatu email memiliki subject ―Hello There‖, maka token-token yang terdapat pada subjek tersebut akan ditokenisasi menjadi ―SUBJECT*Hello‖ dan ―SUBJECT*There‖.
Berdasarkan hasil pengamatan mayoritas email yang mengandung tag HTML adalah email spam. Kode-kode warna seperti #FF0000 hanya ditemukan pada email spam. Begitu pula dengan alamat URL, hampir seluruh pesan spam yang ada pada data uji mencantumkan informasi URL untuk dikunjungi oleh penerima.
Hasil Pengujian Metode Training
1. Tingkat Akurasi
Pengujian metode training dilakukan dengan cara memasangkan kedua metode tersebut pada spam filter yang menggunakan metode klasifikasi NB Graham.
Pada metode TEFT, seluruh email yang dibaca akan di-training ke dalam kelas yang benar setelah hasil dari klasifikasi diperoleh. Proses training ini dilakukan tanpa mempedulikan apakah hasil klasifikasinya benar atau salah. Pada metode TOE, proses
training hanya akan dilakukan jika terjadi
kesalahan klasifikasi.
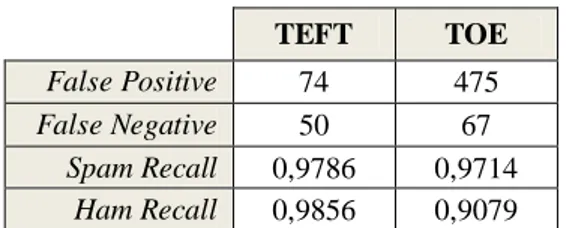
Jumlah False Positive dan False Negative per 7.500 kali pengujian beserta Ham Recall dan Spam Recall dapat dilihat pada Tabel 4. Tabel 4 Hasil pengujian metode training
menggunakan teknik klasifikasi Graham TEFT TOE False Positive 74 475 False Negative 50 67 Spam Recall 0,9786 0,9714 Ham Recall 0,9856 0,9079
11 Grafik perbandingan nilai spam recall dan
ham recall dari kedua metode training dapat
dilihat pada Gambar 1.
Gambar 1 Hasil pengujian metode training. Hasil pengujian menggunakan metode NB Graham menunjukkan metode training TEFT memiliki tingkat akurasi yang lebih tinggi dibandingkan dengan metode training TOE. Perbedaan akurasi tersebut disebabkan oleh lebih banyaknya proses training yang dilakukan oleh metode TEFT dibandingkan dengan metode TOE.
Proses training yang lebih banyak membuat metode TEFT menyimpan informasi yang lebih akurat mengenai karakteristik token-token dari kelas spam maupun ham dalam data hasil training-nya. Untuk spam
recall, perbedaan nilainya hanya sebesar
0,0072, namun untuk ham recall perbedaan nilai antara kedua metode training tersebut cukup tinggi yaitu 0,0777.
Nilai ham recall berhubungan dengan tingkat false positive. Pada spam filter, cost dari false positive lebih tinggi dibandingkan dengan cost dari false negative. Berdasarkan petimbangan tersebut perbedaan tingkat akurasi ini cukup signifikan untuk dipertimbangkan.
Perlu diperhatikan bahwa pada sistem yang sebenarnya koreksi hasil klasifikasi tidak dilakukan seketika seperti pada pengujian ini. Kelas yang benar dari setiap email tidak akan diketahui oleh sistem kecuali pengguna melakukan koreksi. Untuk itu baik TEFT maupun TOE akan mengasumsikan bahwa hasil klasifikasi dari sistem merupakan hasil yang benar. Hal ini akan berpengaruh terhadap proses klasifikasi terutama pada TEFT.
Pada metode TEFT, setiap email yang masuk akan di-training sebagai data untuk kelas yang dianggap benar oleh sistem
tersebut. Jika ternyata terjadi kesalahan pada hasil klasifikasi sistem, proses penilaian pesan selanjutnya akan ikut dipengaruhi oleh data
training yang sudah terlanjur dimasukkan ke
dalam kelas yang salah tersebut. 2. Waktu Pelatihan
Karena proses training dilakukan untuk seluruh email yang masuk, TEFT membutuhkan waktu pengujian lebih lama dibandingkan dengan TOE. Hasil pengujian menunjukkan TEFT menghabiskan waktu sekitar 18% lebih lama dibandingkan dengan TOE. Dengan demikian, meskipun TOE memiliki tingkat akurasi yang lebih rendah dibandingkan dengan TEFT, waktu pemrosesan yang dilakukan oleh TOE lebih sebentar.
Perbedaan waktu antara kedua metode
training ini dapat dibandingkan dengan
perbedaan spam recall dan ham recall-nya untuk mengetahui seberapa besar peningkatan kinerja yang didapat untuk setiap tambahan waktu proses. Untuk spam recall, peningkatan kinerja per satuan waktu 𝐺𝑆 dapat dihitung dengan cara:
𝐺𝑆 = 𝑆𝑅𝑇𝑂𝐸− 𝑆𝑅𝑇𝐸𝐹𝑇
𝐷𝑊
dengan 𝑆𝑅 adalah nilai spam recall dan 𝐷𝑊 adalah persentase perbedaan waktu yang dihabiskan oleh kedua metode training. Dengan cara yang sama, peningkatan ham
recall 𝐺𝐻 untuk masing-masing metode
training dapat dihitung dengan cara:
𝐺𝐻 = 𝐻𝑅𝑇𝑂𝐸− 𝐻𝑅𝑇𝐸𝐹𝑇
𝐷𝑊
dengan 𝐻𝑅 adalah nilai ham recall untuk masing-masing metode training.
Mengganti metode training TOE menjadi TEFT sama halnya dengan menggunakan metode training yang lebih lambat untuk mendapatkan peningkatan akurasi. Dengan perhitungan di atas, didapat bahwa penggunaan metode TEFT dibandingkan dengan TOE akan meningkatkan spam recall (𝐺𝑆) sebesar 0,0004 atau 0,04% untuk setiap 1% penambahan waktunya. Sementara untuk
ham recall, peningkatan akurasi yang didapatkan adalah sebesar 0,0043 atau 0,43% untuk setiap 1% penambahan waktunya.
Perlu diperhatikan bahwa pada sistem yang sebenarnya data hasil training disimpan dalam
file atau database dan email yang harus
12 karena itu, baik perbedaan waktu maupun
perbedaan akurasi antara TOE dan TEFT bisa menjadi sangat signifikan. Metode training mana yang lebih baik harus disesuaikan dengan lingkungan implementasinya. Jika waktu dan resource yang dibutuhkan untuk proses training termasuk dalam faktor yang cukup dipertimbangkan, TOE yang hanya melakukan proses training seperlunya memiliki keunggulan tersendiri dibandingkan dengan TEFT dalam hal penggunaan
resources.
Hasil Pengujian Metode Klasifikasi
Proses pengujian metode klasifikasi dilakukan dengan menggunakan mode
training TEFT. Jumlah false positive dan false negative per 7.500 kali pengujian beserta nilai ham recall dan spam recall dapat dilihat pada
Tabel 5.
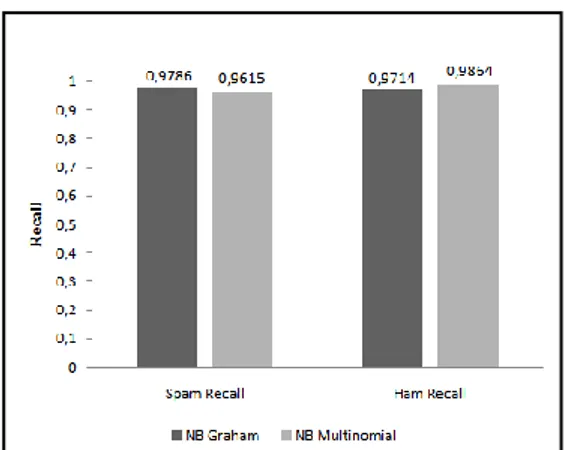
Tabel 5 Hasil pengujian metode klasifikasi dengan metode training TEFT
NB Graham NB Multinomial False Positive 74 70 False Negative 50 67 Spam Recall 0,9786 0,9615 Ham Recall 0,9714 0,9864 Grafik perbandingan nilai spam recall dan
ham recall dari pengujian kedua metode
klasifikasi menggunakan metode training TEFT dapat dilihat pada Gambar 2.
Hasil pengujian menggunakan mode
training TEFT menunjukkan bahwa metode
NB Graham memiliki spam recall lebih tinggi daripada metode NB Multinomial dengan perbedaan nilai sebesar 0,0171. Hasil sebaliknya terlihat pada ham recall dimana metode NB Multinomial memiliki nilai yang lebih tinggi dengan perbedaan nilai sebesar 0,0150.
Pada pengujian selanjutnya dengan menggunakan metode training TOE, hasil yang diperoleh ternyata sedikit berbeda seperti yang dapat dilihat pada Tabel 6.
Gambar 2 Hasil pengujian metode klasifikasi menggunakan metode
training TEFT.
Tabel 6 Hasil pengujian metode klasifikasi dengan mode training TOE
NB Graham NB Multinomial False Positive 475 117 False Negative 67 55 Spam Recall 0,9714 0,9765 Ham Recall 0,9079 0,9773 Grafik perbandingan nilai spam recall dan
ham recall dari pengujian kedua metode
klasifikasi menggunakan metode training TOE dapat dilihat pada Gambar 3.
Gambar 3 Hasil pengujian metode klasifikasi menggunakan metode
training TOE.
Pengujian dengan metode training TOE menunjukkan bahwa metode klasifikasi NB Multinomial memiliki spam recall dan ham
13
recall yang lebih tinggi dibandingkan dengan
metode NB Graham dengan perbedaan masing-masing sebesar 0,0051 dan 0,0694.
Sementara nilai hasil pengujian yang lain menurun pada saat digunakan metode TOE, hasil yang berbeda terlihat pada tingkat spam
recall. NB Multinomial yang dipasangkan
dengan metode training TOE ternyata menghasilkan nilai spam recall yang lebih baik dibandingkan dengan saat dipasangkan pada metode training TEFT.
1. Analisis Kesalahan Pengenalan Ham (False Positive)
Meskipun dalam proses klasifikasinya metode NB Graham mengalikan jumlah kemunculan token pada kelas ham dengan faktor dua, ternyata tingkat ham recall-nya masih lebih rendah dibandingkan dengan ham
recall dari metode NB Multinomial. Pada saat
pengujian dengan metode training TOE, jumlah false postive yang dihasilkan metode Graham bahkan mencapai empat kali lipat dari jumlah false positive NB Multinomial.
Lebih rendahnya ham recall dari metode NB Graham disebabkan oleh pemberian nilai 0,99 untuk token yang hanya pernah muncul di kelas spam. Dalam menentukan hasil klasifikasi, metode NB Graham hanya menggunakan lima belas token yang paling signifikan saja. Seberapa signifikan suatu token dilihat dengan melihat selisih nilai peluang token tersebut dengan nilai peluang netral 0,5. Jika email dari kelas ham mengandung token-token yang hanya muncul di kelas spam saja, proses klasifikasi akan didominasi oleh token-token spam karena token dengan peluang 0,99 memiliki selisih yang tinggi dari peluang netral 0,5.
Walaupun demikian, false positive juga cukup banyak terjadi pada metode NB multinomial. Selanjutnya akan dibahas karakteristik-karakteristik email yang menyebabkan false positive.
a. Email ham yang mengandung tag HTML Jenis pertama email ham yang salah diklasifikasikan adalah email yang mengandung token-token berpeluang spam tinggi seperti tag HTML beserta atributnya.
Karakteristik seperti ini banyak ditemukan pada email yang berjenis newsletter. Karena data uji yang digunakan tidak memiliki email
newsletter dalam jumlah yang cukup,
token-token ham pada email tersebut tidak memiliki nilai 𝑃 𝑎𝑚|𝑤 yang signifikan untuk
mengimbangi token-token spam yang ada. Akibatnya, terjadi false positive dalam proses
filtering yang dilakukan.
Walaupun hal ini juga akan menjadi masalah bagi NB multinomial, metode Graham akan terkena dampak yang cenderung lebih besar. Hal ini disebabkan oleh cara kerja metode Graham yang hanya memilih 15 token paling signifikan (paling jauh nilai dari peluang netral 0,5). Meski token spam yang ditemukan hanya berjumlah beberapa buah, nilai 𝑃 𝑠𝑝𝑎𝑚|𝑤 yang tinggi akan mengakibatkan peringkat token tersebut merangkak naik sampai menembus peringkat 15 besar. Jika kondisi ini tidak diikuti dengan keberadaan token-token dengan nilai 𝑃 𝑎𝑚|𝑤 yang juga tinggi, proses klasifikasi akan didominasi oleh token-token spam tersebut.
Solusi yang dapat digunakan untuk mengatasi persoalan ini adalah pemilihan tag HTML yang dicatat pada saat training. Menurut Zdziarski (2005), tag HTML yang terlalu umum seperti table, tr, td, div,dan p tidak perlu ikut dicatat kemunculannya. Dengan demikian, email ham yang kebetulan memang menggunakan tag HTML tidak akan langsung dianggap sebagai spam.
b. Newsletter resmi yang memiliki isi bertema promosi.
Selain pengaruh tag HTML, false positive juga banyak dipengaruhi oleh isi dari emailnya itu sendiri. Meskipun newsletter dikirimkan dengan seizin penerimanya, isi dari newsletter tersebut seringkali berbau promosi dan menggunakan kata-kata yang digunakan pada email spam. Pada kasus seperti ini, baik metode Graham maupun metode NB multinomial sama-sama mengalami kesulitan dalam menentukan kelas yang benar.
c. Email ham yang memiliki beberapa format
alternative.
Jenis email ham selanjutnya yang seringkali salah diklasifikasi adalah email yang menggunakan format multipart-alternative. Format ini memungkinkan email
dikirimkan dalam beberapa versi sekaligus. Sebagai contoh, jika aplikasi client memiliki kapabilitas untuk membaca dokumen HTML, maka akan ditampilkan versi email yang menggunakan tag HTML. Namun jika tidak, akan ditampilkan versi yang hanya menggunakan teks biasa.
14 Karena cara kerja library pembaca email
yang menggabungkan email multipart menjadi satu, versi alternative yang biasanya banyak mengandung tag HTML ikut terbawa. Pada akhirnya, timbul masalah yang sama dengan email-email bertipe newsletter.
d. Kesalahan Lain
Selain beberapa poin yang sudah disebutkan di atas, terdapat beberapa faktor lain yang menyebabkan false positive
meskipun tidak dalam jumlah banyak. Email yang menggunakan token berhuruf kapital dalam jumlah banyak, seperti email berisi peringatan cuaca buruk, kadang salah diklasifikasikan sebagai spam karena kata-kata dalam huruf kapital banyak ditemukan pada email spam. Email yang dikirimkan oleh aplikasi auto-responder beberapa kali salah diklasifikasikan sebagai spam karena isinya yang pendek dan mengandung kata-kata yang umum ditemukan pada email spam seperti ‗call‘, ‗contact‘, dan ‗respond‘. Selain itu, email pendek yang hanya berisikan URL juga kadang salah diklasifikasikan sebagai spam karena URL lebih banyak ditemukan pada email spam.
2. Analisis Kesalahan Pengenalan Spam (False Negative)
Hasil pengujian terhadap kedua metode klasifikasi tidak membuahkan kesimpulan mengenai metode mana yang memiliki tingkat
false negative lebih tinggi. Selanjutnya
dibahas karakteristik pesan spam yang berhasil lolos dari proses filtering.
a. Email spam yang kebetulan memiliki isi seperti ham
Tipe email spam pertama yang berhasil lolos dari spam filter adalah email spam yang secara kebetulan memiliki karakteristik yang mirip dengan mayoritas email ham yang diterima oleh pengguna.
Pesan-pesan ham pada data uji didominasi oleh pesan dari mailing list bertemakan teknologi informasi. Pesan-pesan spam yang memiliki tema sangat berbeda seperti obat ataupun judi akan mudah dikenali oleh spam
filter, namun jika spam yang dikirim ternyata
bertemakan teknologi informasi, kata-kata yang terkandung di dalamnya akan memiliki karakteristik yang mirip dengan mayoritas email ham. Akibatnya, filter akan salah mengira email spam tersebut sebagai ham.
b. Email yang menggunakan huruf non-latin7 Pemrosesan email berkarakter latin dan berkarakter non-latin memiliki sedikit perbedaan. Proses yang paling harus diperhatikan adalah tokenisasi. Pada pesan berhuruf latin, dengan satu karakter pemisah token saja yaitu spasi, email sudah dapat dipecahkan menjadi token-token dengan cukup baik. Pada tulisan dimana karakternya tidak menggunakan spasi sebagai pemisah token, proses tokenisasi biasa tidak akan menghasilkan token-token yang sesuai.
Selain permasalahan pada tokenisasi, email dengan huruf non-latin pada data pengujian jumlahnya sangat sedikit. Kurangnya data
training untuk token-token yang ada menyebabkan token tersebut memiliki nilai peluang yang cenderung netral. Khusus pada metode Graham, batas nilai peluang suatu email untuk masuk ke dalam kelas spam adalah 0,9, akibatnya, email-email yang dipenuhi dengan token netral akan masuk ke dalam kelas ham.
c. Email yang isinya gagal di-decode. Beberapa email yang menggunakan
character-encoding maupun content-transfer-encoding khusus gagal di-decode. Hal tersebut
disebabkan oleh kekurangan dari library pembaca email yang digunakan atau kesalahan format pada emailnya sendiri.
Kegagalan proses decode menyebabkan isi dari email hanya muncul sebagian atau tidak muncul sama sekali, akibatnya, proses klasifikasi didominasi oleh token-token dari
header. Karena keterbatasan dari token yang
terdapat pada header, proses klasifikasi kadang mengalami kesalahan.
KESIMPULAN DAN SARAN Kesimpulan
Berdasarkan penelitian yang telah dilakukan, dapat disimpulkan beberapa hal sebagai berikut:
1. Pengujian menggunakan metode klasifikasi Graham menunjukkan metode
training TEFT memiliki akurasi yang lebih
tinggi dibandingkan dengan metode TOE terutama pada ham recall dimana perbedaan nilai mencapai 0,0777.
7
Contoh email seperti ini adalah email berbahasa Jepang, Arab dan Cina.
15 2. Pengujian menggunakan kedua metode
training menunjukkan metode NB multinomial memiliki akurasi yang lebih tinggi dibandingkan dengan metode NB Graham kecuali untuk spam recall pada pengujian dengan metode training TEFT dimana metode NB Graham memiliki nilai
spam recall yang lebih tinggi.
3. Kegagalan pengenalan ham (false positive) disebabkan oleh penggunaan token-token yang umum pada email spam di kelas ham seperti email dengan tag HTML.
4. Kegagalan pengenalan spam (false
negative) disebabkan oleh isi dari email
spam yang dikirim kebetulan sama dengan tema dari email pengguna.
Saran
Pengujian ini belum dapat menunjukkan kinerja dari spam filter yang sesungguhnya saat diterapkan dalam kasus di dunia nyata sehingga diperlukan metode pengujian lain untuk keperluan tersebut. Faktor-faktor yang perlu dipertimbangkan adalah:
1. Simulasi jeda waktu sebelum koreksi terhadap kesalahan klasifikasi dilakukan. 2. Urutan kedatangan pesan harus tetap
dipertahankan.
3. Proses pengujian beberapa kali dengan proporsi spam dan ham yang bervariasi. Dengan metode pengujian yang lebih realistik, diharapkan data hasil pengujian dapat lebih akurat.
Email yang menggunakan karakter non-latin perlu ditangani dengan benar terutama pada proses tokenisasi.
DAFTAR PUSTAKA
Androutsopoulos et al. 2000. An Evaluation of
Naive Bayesian Anti-Spam Filtering. Di
dalam: Proceedings of the workshop on
Machine Learning in the New Information Age. Spain, pp. 9-17, 2000.
Crossa, J. 2009. Naive Bayes Classification in Spam Filtering. -
Drucker et al. 1999. Support Vector Machine
for Spam Categorization. IEEE Transactions on Neural Networks, Vol. 10, No. 5.
Graham, P. 2002. A Plan for Spam. http://paulgraham.com/spam.html
[Diakses Pada: 14 Des 2009]
Graham, P. 2003. Stopping Spam.
http://paulgraham.com/stopspam.html. [Diakses Pada: 14 Des 2009]
Manning C D, Raghavan P, Schütze H. 2008.
Introduction to Information Retrieval.
Cambridge: Cambridge University Press. McAfee. 2008. The Carbon Footprint of
Email Spam Report. Santa Clara: McAfee,
Inc.
McCallum, A. & Nigam, K. 1998. A
Comparison of Event Models for Naive Bayes Text Classication. –
Metsis et al. 2006. Spam Filtering with Naive
Bayes – Which Naive Bayes?. Di dalam:
CEAS 2006 - Third Conference on Email
and AntiSpam.
Pantel P, Lin D.1998. SpamCop: A Spam
Classification & Organization Program.
Di dalam: AAAI Technical Report WS-98-05.
Rish et al. 2001. An analysis of data
characteristics that affect naive Bayes performance. –.
Sahami et al. 1998. A Bayes Approach to
Filtering Junk E-Mail. Di dalam: AAAI
Technical Report WS-98-05.
Schneider, K M. 2004. On Word Frequency
Information and Negative Evidence in Naive Bayes Text Classification.
Department of General Linguistics University of Passau.
Song Y, Kolz A, Gilees CL. 2009. Better
Naive Bayes classification for high-precision spam detection. Di dalam:
SOFTWARE—PRACTICE AND
EXPERIENCE, 2009; 39:1003–1024. Spamhaus. The Definition of Spam.
http://www.spamhaus.org/definition.html. [Diakses Pada: 29 Des 2009]
Sun, T. 2009. Spam Filtering based on Naive
Bayes Classication. –.
Yerazunis, W.S. 2004. The Spam-Filtering
Accuracy Plateau at 99.9 percent Accuracy and How to Get Past It. Di
dalam: MIT Spam Conference 2004. Zdziarski, J A. 2005. Ending Spam: Bayesian
Content Filtering and the Art of Statistical Language Classification. San Francisco: