SPAM FILTER MENGGUNAKAN MODEL KLASIFIKASI
MULTIVARIATE BERNOULLI DAN MULTINOMIAL NAIVE
BAYES
DENIS FADILLAH
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2014
PERNYATAAN MENGENAI SKRIPSI DAN SUMBER
INFORMASI SERTA
PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Spam Filter Menggunakan Model Klasifikasi Multivariate Bernoulli dan Multinomial Naive Bayesadalah be-nar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Desember 2014 Denis Fadillah G64124052
ABSTRAK
DENIS FADILLAH. Spam Filter Menggunakan Model Klasifikasi Multivariate Bernoulli dan Multinomial Naive Bayes. Dibawah bimbingan JULIO ADISAN-TOSO.
Pertumbuhan pengguna email memicu peningkatan spam email sehingga diperlukan teknik spam filter. Model klasifikasi Naive Bayes (NB) adalah salah satu supervised learning yang dapat digunakan untuk spam filter karena tingkat akurasi yang tinggi dan mudah diimple-mentasikan. Multivariat Bernoulli NB menggunakan atribut Boolean sedangkan Multino-mial NB menggunakan frekuensi term, adalah dua model NB yang sering digunakan untuk fungsi klasifikasi. Pemilihan fitur ciri yang baik juga berpengaruh pada peningkatan akurasi klasifikasi. Penelitian ini mencoba memodelkan spam filter menggunakan model klasifikasi Multivariat Bernoullidan Multinomial NB kemudian membandingkan akurasinya. Seleksi fitur chi-square dipilih dengan harapan dapat menghasilkan fitur ciri yang lebih baik. Model Multinomial NBtanpa seleksi fitur menghasilkan akurasi tertinggi sebesar 95.31%, sedan-gkan untuk tingkat akurasi terendah didapatkan pada model Multivariate Bernoulli tanpa seleksi fitur sebesar 89.69%. Seleksi fitur chi-square meningkatkan akurasi model Multi-variate Bernoulli sebesar 3.31%, sedangkan Multinomial NB mengalami penurunan akurasi sebesar 1.98%.
Kata kunci: multinomial, multivariat bernoulli, naive bayes, spam filter
ABSTRACT
DENIS FADILLAH. Spam Filter Using Multivariate Bernoulli Classifiers and Multinomial Naive Bayes Classifiers. Supervised by JULIO ADISANTOSO.
The growth of email users is triggers an increase in spam email, so that the required spam filters. Naive Bayes classification model (NB) is one of the supervised learning that can be used for spam filters because of high accuracy and easy to implement. Multivariate Ber-noulli NB that is using Boolean attribute while Multinomial NB is using term frequency, those are two NB models which often used for classification function. Selection of good features will also affects the improvement of classification accuracy. This research is try-ing to modelltry-ing spam filter by ustry-ing Multivariate Bernoulli and Multinomial NB classifiers then to compare both accuracy outputs. Chi-square feature selection also was chosen to hope producing a better features. Multinomial NB models without feature selection resulted in the highest accuracy of 95.31%, while the lowest accuracy rate obtained in the Multi-variate Bernoulli models without feature selection by 89.69%. Chi-square feature selection improve the accuracy of the model Multivariate Bernoulli at 3.31%, while the accuracy of Multinomial NB decreased by 1.98%.
SPAM FILTER MENGGUNAKAN MODEL KLASIFIKASI
MULTIVARIATE BERNOULLI DAN MULTINOMIAL NAIVE
BAYES
DENIS FADILLAH
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2014
Penguji:
1. Ahmad Ridha, SKom MS
Judul Skripsi : Spam Filter Menggunakan Model Klasifikasi Multivariate Bernoulli dan Multinomial Naive Bayes
Nama Mahasiswa : Denis Fadillah NIM : G64124052
Disetujui oleh
Ir. Julio Adisantoso, M.Komp Pembimbing
Diketahui oleh
Dr.Ir. Agus Buono, MSc Ketua Departemen
PRAKATA
Puji syukur penulis panjatkan kehadirat Allah SWT yang telah memberikan rah-mat dan hidayah-Nya sehingga penulis dapat menyelesaikan skripsi yang berjudul “Spam Filter Menggunakan Model Klasifikasi Multivariate Bernoulli dan Multino-mial Naive Bayes”.
Skripsi ini disusun sebagai syarat mendapat gelar Sarjan Komputer (SKomp) pada Program Sarjana Ilmu Komputer di Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertnaian Bogor (IPB).
Akhir kata, penulis mengucapkan terimakasih kepada semua pihak yang telah banyak membantu dalam menyelsaikan skripsi ini. Semoga skripsi ini dapatmemberikan kontribusi yang bermakna bagi pengembangan wawasan parapembaca, khususnya mahasiswa dan masyarakat pada umumnya.
Semoga karya ilmiah ini bermanfaat.
Bogor, Desember 2014
DAFTAR ISI
Halaman DAFTAR TABEL iv DAFTAR GAMBAR iv PENDAHULUAN 1 Latar Belakang . . . 1 Perumusan Masalah . . . 1 Tujuan Penelitian . . . 2 Manfaat Penelitian . . . 2Ruang Lingkup Penelitian . . . 2
METODE 2 Pengumpulan Dokumen Email . . . 2
Ekstraksi Dokumen Email . . . 3
Praproses . . . 3
Fungsi Klasifikasi . . . 6
Evaluasi . . . 7
Lingkungan Pengembangan . . . 8
HASIL DAN PEMBAHASAN 8 Pengumpulan Dokumen Email . . . 8
Ekstraksi Dokumen Email . . . 9
Praproses . . . 10
Fungsi Klasifikasi Naive Bayes . . . 10
Evaluasi . . . 11
SIMPULAN DAN SARAN 14 Simpulan . . . 14
Saran . . . 14
DAFTAR PUSTAKA 14 LAMPIRAN 16 1. Confussion Matrix untuk setiap pengujian model klasifikasi . . . 16
2. Algoritme ukuran kesamaan antar dokumen . . . 17
DAFTAR TABEL
1 Struktur dokumen email . . . 4
2 Tabel kontingensi . . . 5
3 Nilai Kritis χ2 . . . 5
4 Confussion Matrix kelas prediksi dan aktual . . . 7
5 Jumlah token yang dihasilkan . . . 10
6 Lima term hasil pendugaan pada Multivariate Bernoulli . . . 11
7 Lima term hasil pendugaan pada Multinomial NB . . . 11
DAFTAR GAMBAR
1 Diagram Alir Penelitian . . . 32 Komposisi jumlah token hasil tahap seleksi fitur . . . 10
3 Tingkat akurasi setiap model klasifikasi . . . 12
4 Pengaruh seleksi fitur terhadap model klasifikasi . . . 13
1
PENDAHULUAN
Latar Belakang
Surat elektronik atau email adalah sarana mengirim surat melalui jaringan in-ternet. Berbeda dengan surat konvensional, email tidak memerlukan perangko atau amplop untuk mengirim pesan sehingga mudah dan murah. Selain itu email dapat dikirim ke banyak orang dalam satu waktu dengan waktu yang cepat.
Pertumbuhan pengguna email yang semakin pesat memicu peningkatan spam email. Spam email adalah email yang tidak diinginkan oleh penerimanya dan dikir-imkan secara massal. Spam biasanya dikirim oleh suatu perusahaan sebagai me-dia promosi suatu produk. Tahun 2008 diperkirakan terdapat 62 triliun spam yang dikirim di seluruh dunia (McAfee 2008). Banyaknya spam tersebut mengakibatkan kerugian seperti memakan banyak sumber daya dan memerlukan waktu untuk meng-hapusnya.
Menyaring spam secara manual sulit dilakukan untuk ukuran dokumen email yang sangat besar. Oleh karena itu diperlukan suatu metode yang dapat mengk-lasifikasikan spam dan bukan spam (ham) secara otomatis. Model klasifikasi Naive Bayes (NB) adalah salah satu metode supervised learning yang banyak digunakan untuk klasifikasi secara otomatis. NB dapat digunakan untuk berbagai permasa-lahan klasifikasi dengan error rate sebesar 20% (Manning et al. 2009).
Metode NB terbagi menjadi dua model yaitu Multivariate Bernoulli NB dan Multinomial NB (Manning et al. 2009). Penelitian Rahman (2013) memband-ingkan model Multinomial NB (atribut Boolean) dengan model Graham menggu-nakan metode training Train-Everything (TEFT) dan Training On Error (TOE). Metode TEFT melatih data email ketika ada data email baru, sedangkan metode TOE melatih data email ketika ada kesalahan klasifikasi. Dari penelitian tersebut model Multinomial NB untuk spam filter menghasilkan nilai recall yang tinggi yaitu di atas 96% untuk setiap percobaan.
Schneider (2003) membandingkan kinerja dua model NB dan menyimpulkan model Multinomial NB dapat mencapai akurasi yang lebih tinggi dibandingkan de-ngan model Multivariat Bernoulli NB dede-ngan menggunakan seleksi fitur Mutual Information(MI). Schneider (2003) juga berasumsi bahwa peningkatan fungsi se-leksi fitur dapat menghasilkan tingkat akurasi yang lebih baik. Salah satu metode seleksi fitur yang populer adalah chi-square (Manning et al. 2009). Oleh karena itu, perlu dilakukan penelitian membandingkan Multivariate Bernoulli NB dan Multi-nomial NB untuk spam filter pada dokumen email menggunakan seleksi fitur chi-square. Seleksi fitur chi-square diharapkan dapat menghasilkan tingkat akurasi yang lebih baik.
Perumusan Masalah
2
1. Bagaimana memodelkan klasifikasi Multivariate Bernoulli NB dan Multino-mial NB untuk spam filter?
2. Seberapa besar tingkat akurasi spam filter dengan menggunakan seleksi fitur chi-square?
3. Bagaimana perbandingan hasil klasifikasi Multivariate Bernoulli NB dan Multi-nomial NB untuk spam filter menggunakan seleksi fitur chi-square?
Tujuan Penelitian
Tujuan dari penelitian ini adalah membuat model klasifikasi Multivariate Berno-ulli NB dan Multinomial NB untuk spam filter dengan menggunakan seleksi fitur chi-square kemudian membandingkan akurasi antara dua model tersebut.
Manfaat Penelitian
Penelitian ini diharapkan dapat menghasilkan model klasifikasi untuk spam fil-ter menggunakan model klasifikasi NB dan seleksi fitur chi-square dengan tingkat akurasi yang tinggi.
Ruang Lingkup Penelitian
Ruang lingkup pada penelitian ini antara lain:
1. Korpus yang digunakan adalah dokumen email berbahasa Inggris dengan standar MIME dalam format raw.
2. Korpus email terbagi ke dalam dua kelas yaitu kelas spam dan ham. 3. Praproses tidak melewati langkah stemming
METODE
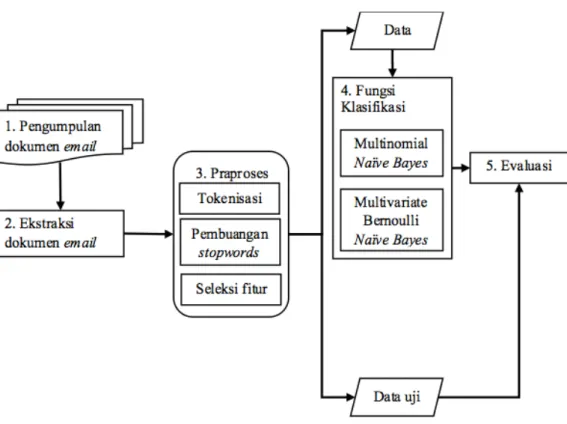
Tahapan penelitian terdiri atas lima tahap, yaitu: pengumpulan data email, ek-straksi dokumen email, praproses, membuat fungsi klasifikasi, dan evaluasi hasil. Gambar 1 menunjukkan diagram alir penelitian yang dilakukan.
Pengumpulan Dokumen Email
Tahapan penelitian yang pertama adalah pengumpulan dokumen email. Doku-men email yang terkumpul digunakan sebagai korpus. Korpus yang digunakan pada
3
Gambar 1 Diagram Alir Penelitian
penelitian ini adalah public email copus yang disediakan oleh Spamassasin1dengan kode prefix “20030228”. Korpus email dibagi menjadi dua kelas yaitu kelas spam dan kelas ham. Korpus tersebut akan digunakan sebagai data latih dan data uji pada tahap selanjutnya.
Ekstraksi Dokumen Email
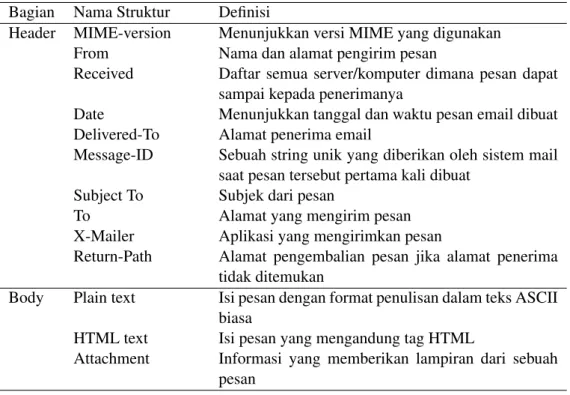
Dokumen email yang terdapat dalam korpus masih dengan format standar email yang terdiri dari header dan body. Oleh karena itu, struktur email tersebut harus dipecah sesuai dengan bagian-bagiannya. Ekstraksi dokumen email dilakukan un-tuk mendapatkan bagian email yang akan dimasukkan dalam proses tokenisasi. Tabel 1 menampilkan struktur yang terdapat dalam dokumen email. Bagian header yang digunakan untuk proses tokensisasi adalah subject, sedangkan pada bagian body adalah plain text dan HTML text.
Praproses
Dokumen email yang telah diekstraksi kemudian ditokenisasi. Tokenisasi ada-lah memotong dokumen teks menjadi potongan-potongan kecil yang disebut token
4
Tabel 1 Struktur dokumen email
Bagian Nama Struktur Definisi
Header MIME-version Menunjukkan versi MIME yang digunakan From Nama dan alamat pengirim pesan
Received Daftar semua server/komputer dimana pesan dapat sampai kepada penerimanya
Date Menunjukkan tanggal dan waktu pesan email dibuat Delivered-To Alamat penerima email
Message-ID Sebuah string unik yang diberikan oleh sistem mail saat pesan tersebut pertama kali dibuat
Subject To Subjek dari pesan
To Alamat yang mengirim pesan
X-Mailer Aplikasi yang mengirimkan pesan
Return-Path Alamat pengembalian pesan jika alamat penerima tidak ditemukan
Body Plain text Isi pesan dengan format penulisan dalam teks ASCII biasa
HTML text Isi pesan yang mengandung tag HTML
Attachment Informasi yang memberikan lampiran dari sebuah pesan
dan membuang karakter-karakter tertentu seperti tanda baca (Manning et al. 2009). Whitespace (spasi, tab, newline) digunakan sebagai pemisah antar kata yang akan dipotong. Selain itu token yang dihasilkan biasanya diubah ke dalam bentuk lower-case. Proses tokensisasi dilakukan sebagai berikut:
• Tanda baca diganti menjadi spasi sehingga tanda baca tersebut dianggap se-bagai pemisah token. Tanda baca yang digunakan yaitu ´ - ) ( \ / = . , : ; ! ?.
• Teks dipotong menjadi token-token. Karakter numerik dibuang sehingga to-ken hanya terdiri dari karakter huruf (string).
• Token dengan panjang kurang dari 3 karakter dibuang. • Semua token diubah ke dalam bentuk lowercase.
Token yang termasuk ke dalam stopword2 akan dibuang. Stopword adalah kata yang sangat umum dan sering muncul seperti kata sambung (Manning et al. 2009). Stopword tidak menambah informasi untuk fungsi klasifikasi dan untuk mengurangi beban komputasi.
Seleksi fitur merupakan suatu proses memilih subset dari setiap kata unik yang ada di dalam himpunan dokumen latih yang akan digunakan sebagai fitur di dalam klasifikasi dokumen. Subset kata unik yang terpilih disebut dengan penciri. Se-leksi fitur memiliki dua tujuan, yaitu mengurangi jumlah kata yang digunakan dan meningkatkan akurasi hasil klasifikasi (Manning et al. 2009).
5
Pada penelitian ini, pemilihan fitur dilakukan dengan metode chi-square. Chi-square digunakan untuk menguji independensi antara dua kejadian yaitu kejadian kemunculan kata unik dan kejadian kemunculan kelas (Manning et al. 2009). Nilai chi-square kata t pada kelas c dihitung menggunakan persamaan:
χ2(t, c) =
∑
et∈{0,1}∑
ec∈{0,1} [N(etec) − E(etec)]2 E(etec) (1)dengan N adalah frekuensi yang diamati dan E adalah frekuensi yang diharapkan. Pada persamaan (1), et bernilai 1 jika dokumen mengandung kata t dan et bernilai
0 jika dokumen tidak mengandung kata t, sedangkan ec bernilai 1 jika dokumen
terdapat dalam kelas c dan ecbernilai 0 jika dokumen tidak terdapat dalam kelas c.
Tabel 2 Tabel kontingensi
Kata Kelas c ¬c
t A B
¬t C D
Penghitungan nilai chi-square pada setiap kata t yang muncul pada setiap ke-las c dapat dibantu dengan menggunakan tabel kontingensi (Tabel 2). Nilai yang terdapat pada Tabel 2 merupakan nilai frekuensi obsevasi dari suatu kata terhadap kelas yaitu A merupakan banyaknya dokumen pada kelas c yang memuat kata t, B merupakan banyaknya dokumen yang bukan kelas c namun memuat kata t, C meru-pakan banyaknya dokumen yang ada di kelas c namun tidak memiliki kata t, serta Dmerupakan banyaknya dokumen yang bukan kelas c dan tidak memuat kata t.
Berdasarkan Tabel 2, perhitungan chi-square pada (1) dapat disederhanakan men-jadi:
χ2(t, c) = N(AD − BC)
2
(A +C)(A + B)(B + D)(C + D)
dengan t merupakan kata yang diujikan terhadap suatu kelas c dan N merupakan jumlah dokumen latih.
Tabel 3 Nilai Kritis χ2
Taraf Nyata (α) Nilai Kritis
0.050 3.841
0.025 5.024
0.010 6.635
0.005 7.879
Pengambilan keputusan dilakukan berdasarkan nilai χ2dari masing-masing kata. Kata yang memiliki nilai χ2 lebih besar dari nilai kritis pada taraf nyata α adalah kata yang akan dipilih sebagai penciri dokumen. Kata yang dipilih sebagai penciri
6
merupakan kata yang memiliki pengaruh terhadap kelas c. Nilai kritis χ2 untuk taraf nyata α (Walpole 1968) ditunjukkan pada Tabel 3.
Penelitian ini menggunakan satu taraf nyata α dengan nilai 0.01 yang diartikan bahwa kriteria kata yang dipilih sebagai penciri dokumen adalah kata yang memi-liki nilai χ2 lebih besar dari 6.635. Hasil seleksi fitur ini akan digunakan sebagai vocabulary untuk proses klasifikasi.
Fungsi Klasifikasi
Ada dua cara mengelompokkan dokumen ke dalam kategori tertentu, yaitu man-ual dan otomatis. Cara pertama yaitu secara manman-ual yang dilakukan oleh para pakar/ahli. Akan tetapi cara manual sulit dilakukan untuk dokumen dengan skala besar. Cara kedua adalah klasifikasi dokumen secara otomatis menggunakan fungsi klasifikasi yang dapat memetakan dokumen ke dalam kategori tertentu, γ : X 7→ C, dengan X adalah kumpulan dokumen dan C adalah himpunan kelas atau kategori.
Manning et al. (2009) membagi fungsi klasifikasi menjadi dua metode, yaitu metode berbasis vektor dan peluang. Pada fungsi klasifikasi berbasis vektor, setiap dokumen direpresentasikan sebagai vektor yang diberi label sesuai dengan kelasnya. Beberapa metode yang sering digunakan untuk klasifikasi berbasis vektor adalah kNN dan Rocchio classification.
Metode kedua adalah berbasis peluang dimana penentuan label kelas akan diten-tukan dari nilai peluang dokumen terhadap kelas. Metode berbasis peluang yang sering digunakan adalah NB classifier. NB classifier terbagi menjadi dua model, yaitu Multivariate Bernoulli dan Multinomial NB.
Multivariate Bernoulli menyatakan bahwa dokumen diwakili oleh atribut biner yang menunjukkan ada dan tidak ada term dalam dokumen. Frekuensi kemunculan term dalam dokumen tidak ikut diperhitungkan. Ketika menghitung peluang dari sebuah dokumen, semua nilai atribut dikalikan termasuk kemungkinan ada dan tidak ada term dalam dokumen. Pada model ini, dokumen akan direpresentasikan ke dalam angka biner 1 jika terdapat dalam dokumen atau 0 jika tidak terdapat dalam dokumen:
d=< e1, . . . , ei, . . . eM>, ei∈ {0, 1}
Peluang dokumen d dalam kelas c dihitung menggunakan cara:
P(c|d) ∝ ˆP(c)
∏
ti∈V
ˆ
P(Ui= ei|c) (2)
dengan ˆP(Ui= ei|c) adalah rasio dokumen dari kelas c yang mengandung term Ui,
ˆ
P(c) adalah peluang dokumen pada kelas c. Pendugaan ˆP(c) dan ˆP(ei|c) dihitung
dengan cara: ˆ P(c) = Nc N , ˆP(ei|c) = Tct ∑t∈VTct
dengan Tct adalah banyaknya dokumen yang mengandung term t dalam dokumen
7
Laplace smoothing atau Add-One Smoothing sehingga pendugaan ˆP(ei|c) menjadi:
ˆ
P(ei|c) = Tct+ 1 ∑t∈VTct+ b
(3)
dengan b adalah banyaknya kelas atau kategori (Manning et al. 2009).
Dalam Multinomial NB, dokumen diwakili oleh serangkaian kemunculan term dari dokumen, yaitu:
d=< t1, . . . ,tk, . . .tnd >,tk∈ V
Dalam model ini jumlah kemunculan dari setiap term dalam dokumen akan diper-hitungkan. Peluang dokumen d dalam kelas c dihitung menggunakan persamaan:
P(c|d) ∝ ˆP(c)
∏
1≤k≤nd
ˆ
P(X = tk|c) (4)
dengan ˆP(X = tk|c) adalah rasio term dalam kelas c yang mengandung term t, ˆ
P(c) adalah peluang dokumen pada kelas c. Pendugaan ˆP(X = tk|c) menggunakan
Laplace smoothing yang dihitung dengan cara:
ˆ
P(tk|c) = Tct+ 1 ∑t∈VTct+ b0
(5)
sedangkan b0adalah banyaknya term dalam vocabulary.
Evaluasi
Langkah terakhir adalah melakukan pengujian dan evaluasi terhadap model klasi-fikasi yang telah dibuat. Pengujian dilakukan terhadap data uji yang telah ditentukan sebelumnya. Confussion Matrix (Tabel 4) digunakan untuk membantu perhitungan evaluasi dengan TP adalah banyaknya dokumen yang kelas aktualnya adalah kelas Spam dengan kelas prediksinya kelas Spam, FN adalah banyaknya dokumen yang kelas aktualnya adalah kelas Spam dengan kelas prediksinya kelas Ham, FP ada-lah banyaknya dokumen yang ada kelas aktualnya adaada-lah kelas Ham dengan kelas prediksinya kelas Spam serta TN adalah banyaknya dokumen yang ada kelas aktu-alnya adalah kelas Ham dengan kelas prediksinya kelas Ham.
Tabel 4 Confussion Matrix kelas prediksi dan aktual
Kelas Aktual Kelas Prediksi Spam Ham
Spam TP FP
Ham FN TN
Evaluasi penelitian ini menggunakan perhitungan akurasi dengan formula:
Akurasi= T P+ T N T P+ FN + FP + T N
8
Untuk mengetahui akurasi setiap kelas digunakan perhitungan akurasi ham dan akurasi spam dengan formula:
Akurasi Ham= |Hk|
|H|, Akurasi Sam = |Sk|
|S|
dengan |Hk| adalah banyaknya dokumen ham yang benar diklasifikasikan, |H| ada-lah total dokumen ham, |Sk| adalah banyaknya dokumen spam yang benar
diklasi-fikasikan, dan |S| adalah total dokumen spam.
Masing-masing model NB akan dihitung nilai akurasinya kemudian dibandingkan sehingga diketahui model mana yang paling baik untuk spam filter. Perbandingan model klasifikasi sebelum menggunakan seleksi fitur dan setelah menggunakan se-leksi fitur dihitung untuk mengetaui pengaruh sese-leksi fitur terhadap model klasi-fikasi.
Lingkungan Pengembangan
Spesifikasi perangkat keras dan perangkat lunak yang digunakan untuk peneli-tian ini adalah sebagai berikut:
1. Perangkat keras berupa komputer personal dengan spesifikasi sebagai berikut: • Processor Intel Dual Core
• RAM 3GB
• Monitor LCD 14.0” HD • Harddisk 250 GB HDD 2. Perangkat lunak:
• Sistem Operasi Windows 7 • Bahasa pemrograman PHP • XAMPP v3.2.1
• Notepad++ digunakan sebagai editor kode program
HASIL DAN PEMBAHASAN
Pengumpulan Dokumen Email
Korpus yang digunakan pada penelitian ini adalah public email corpus yang dise-diakan oleh Spamassasin dengan kode prefix “20030228”. Korpus ini terdiri atas 6.047 pesan email yang sudah diklasifikasikan sebelumnya dengan komposisi:
9
• 3900 easy-ham, yaitu pesan ham yang dapat dibedakan dengan mudah dari pesan spam karena tidak banyak mengandung ciri-ciri yang dimiliki oleh pe-san spam.
• 250 hard-ham, yaitu pesan bertipe ham namun mengandung cukup banyak feature yang biasa terdapat pada pesan spam sehingga agak sulit diklasi-fikasikan.
• 1897 spam, yaitu pesan yang masuk dalam kategori spam.
Dari masing-masing kategori, secara acak diambil sebanyak 70% sebagai data latih dan sisanya digunakan data uji. Pesan yang memiliki label easy-ham dan hard-ham digabungkan ke dalam satu kategori yaitu hard-ham. Dengan demikian, dokumen email tersebut diklasifikasikan ke dalam dua kategori yaitu spam dan ham dengan komposisi:
• Total dokumen ham 4150, sebanyak 2905 dokumen digunakan sebagai data latih dan 1245 dokumen digunakan sebagai data uji.
• Total dokumen spam 1897, sebanyak 1328 dokumen digunakan sebagai data latih dan 569 dokumen digunakan sebagai data uji.
Hasil pengamatan menunjukkan dokumen spam rata-rata mempunyai ukuran data yang lebih besar dibandingkan dengan dokumen ham. Ukuran terbesar dari dokumen ham adalah 301 KB, sedangkan untuk dokumen spam adalah 232 KB. Besar ukuran dokumen email tergatung dari isi yang terdapat di dalam dokumen. Dokumen email dengan content-type multipart biasanya menghasilkan ukuran data yang lebih besar dibandingkan dengan singlepart.
Ekstraksi Dokumen Email
Langkah ekstraksi dokumen dilakukan untuk memecah dokumen email menjadi bagian-bagian yang lebih kecil. Langkah ini diperlukan karena tidak semua bagian email digunakan untuk tahapan selanjutnya. Struktur header seperti sender, return path, dan X-mailer hanya muncul pada beberapa dokumen email sehingga tidak bagus digunakan sebagai penciri. Subject email merupakan salah satu bagian email yang baik digunakan sebagai penciri (Sahami et al. 1998). Bagian struktur email yang digunakan untuk langkah selanjutnya adalah subject dan body (plain text dan HTML text).
Ekstraksi dokumen menggunakan library mailparse3 yang telah tersedia untuk bahasa pemrograman php. Hasil pengamatan menunjukkan content plain text pal-ing banyak ditemukan pada dokumen easy-ham, sedangkan HTML text banyak dite-mukan pada dokumen hard-ham dan spam.
10
Praproses
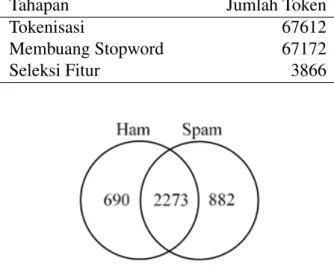
Tahap tokenisasi dilakukan pada bagian email yang digunakan. Dalam tahap to-kenisasi data latih diperoleh 67612 token. Seluruh token tersebut disaring dengan membuang kata-kata yang terdapat dalam daftar stopword sehingga diperoleh token sebanyak 67172. Dapat disimpulkan bahwa hanya sebanyak 0.7% dari seluruh to-ken data latih merupakan stopword. Dengan menggunakan seleksi fitur chi-square dan taraf α = 0.01, token akhir yang dijadikan sebagai vocabulary adalah 3866 to-ken atau 5.8% dari total toto-ken setelah pembuangan stopword. Tabel 5 menunjukkan jumlah token yang dihasilkan pada setiap langkah praproses. Sebanyak 2273 to-ken terdapat pada kelas ham dan spam seperti kata “absolutely”, “account” dan “address” termasuk tag-tag HTML. Sedangkan sebanyak 690 token hanya terdapat pada kelas ham dan 882 token hanya terdapat pada kelas spam. Gambar 2 menun-jukkan komposisi jumlah token terhadap kelas dari hasil seleksi fitur.
Tabel 5 Jumlah token yang dihasilkan
Tahapan Jumlah Token
Tokenisasi 67612
Membuang Stopword 67172 Seleksi Fitur 3866
Gambar 2 Komposisi jumlah token hasil tahap seleksi fitur
Fungsi Klasifikasi Naive Bayes
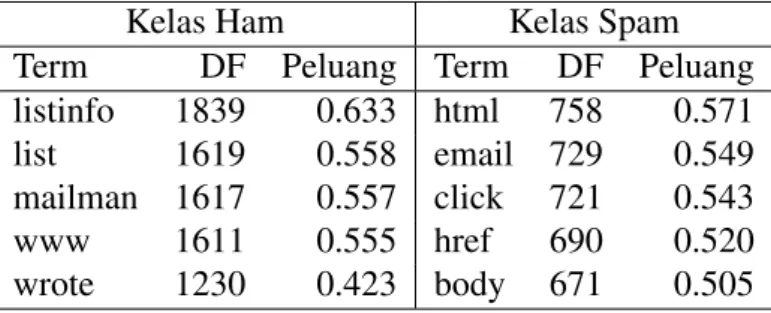
Setelah melewati langkah praproses, langkah selanjutnya adalah membuat fungsi klasifikasi yang dapat memetakan dokumen ke dalam kategori tertentu. Pada model Multivariate Bernoulli, pendugaan parameter setiap term dihitung menggunakan persamaan (2). Peluang dari pendugaan parameter Multivariate Bernoulli bergan-tung pada nilai document frequency (DF). Semakin besar nilai DF maka semakin besar pula peluangnya. Tabel 6 menunjukkan lima term urutan tertinggi hasil pen-dugaan parameter Multivariate Bernoulli berdasar pada nilai DF dan peluangnya. Tabel 6 menunjukkan pada kelas ham, jika dibandingkan term ‘listinfo’ yang berni-lai DF 1839 menghasilkan peluang sebesar 0.633, sedangkan untuk term ‘wrote’ dengan nilai DF 1230 menghasilkan peluang yang lebih kecil yaitu sebesar 0.423.
11
Tabel 6 Lima term hasil pendugaan pada Multivariate Bernoulli
Kelas Ham Kelas Spam Term DF Peluang Term DF Peluang listinfo 1839 0.633 html 758 0.571 list 1619 0.558 email 729 0.549 mailman 1617 0.557 click 721 0.543 www 1611 0.555 href 690 0.520 wrote 1230 0.423 body 671 0.505
Pada model Multinomial NB, pendugaan parameter dihitung menggunakan per-samaan (4). Berbeda dengan model Multivariate Bernoulli, nilai peluang model Multinomial NB dipengaruhi oleh nilai TF (term frequency). Semakin tinggi nilai TF maka semakin besar pula peluangnya. Tabel 7 menunjukkan lima term urutan tertinggi hasil pendugaan parameter Multinomial NB berdasar pada nilai TF dan peluangnya. Tabel 7 menunjukkan pada kelas ham, jika dibandingkan term ‘width yang bernilai TF 16815 menghasilkan peluang sebesar 0.038, sedangkan untuk term ‘src’ dengan nilai TF 9340 menghasilkan peluang yang lebih kecil yaitu sebe-sar 0.021. Pendugaan ˆP(c) untuk setiap model bernilai sama yaitu ˆP(ham)=0.686 sedangkan ˆP(spam)=0.314.
Tabel 7 Lima term hasil pendugaan pada Multinomial NB
Kelas Ham Kelas Spam Term TF Peluang Term TF Peluang width 16815 0.038 font 27602 0.090 www 12055 0.027 size 10335 0.033 font 11042 0.025 width 7855 0.025 height 9598 0.022 color 7892 0.025 src 9340 0.021 face 7594 0.024
Evaluasi
Proses pengujian model klasifikasi dilakukan menggunakan yang terdiri dari 1245 dokumen ham dan 569 dokumen spam. Pengujian menggunakan pendugaan parameter yang telah dibuat pada tahap fungsi klasifikasi. Persamaan (2) digunakan pada pengujian model Multivariate Bernoulli sedangkan (4) digunakan untuk men-guji model Multinomial NB. Perhitungan (2) dan (4) menghasilkan nilai 0 karena nilai peluang yang dihasilkan sangat kecil. Oleh karena itu, untuk mengatasi hal tersebut semua nilai pendugaan parameter dijadikan log sehingga persamaan (2) menjadi:
log(P(c|d)) ∝ log( ˆP(c)) +
∑
ti∈V
12
sedangkan persamaan (4) menjadi:
log(P(c|d)) ∝ log( ˆP(c)) +
∑
1≤k≤nd
log( ˆP(X = tk|c))
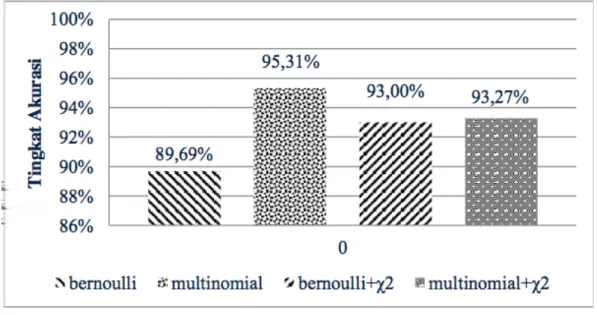
Pada semua dokumen uji dilakukan pengujian terhadap setiap model klasifikasi baik sebelum dan sesudah menggunakan seleksi fitur chi-square. Hasil pengujian dalam bentuk confussion matrix terdapat pada lampiran 1. Akurasi tertinggi dicapai model Multinomial NB tanpa seleksi fitur chi-square dengan tingkat akurasi sebe-sar 95.31%. Model Multivariate Bernoulli tanpa seleksi fitur chi-square memiliki tingkat akurasi terendah yaitu sebesar 89.69%. Secara keseluruhan, model Multino-mial NB menunjukkan tingkat akurasi yang lebih tinggi, baik menggunakan seleksi fitur atau tidak. Gambar 3 menunjukkan tingkat akurasi dari model klasifikasi yang telah dibuat.
Gambar 3 Tingkat akurasi setiap model klasifikasi
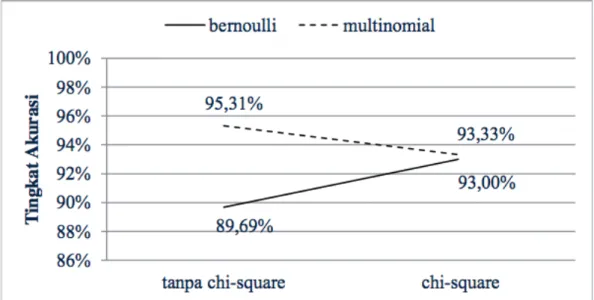
Gambar 4 menunjukkan pengaruh dari seleksi fitur terhadap model klasifikasi. Dengan menggunakan seleksi fitur chi-square, terjadi penuruan akurasi sebesar 1.98% pada model Multinomial NB. Hal ini berbanding terbalik pada model Multivariate Bernoulli yang mengalami peningkatan akurasi sebesar 3.31%. Banyaknya vocabu-lary yang digunakan mempengaruhi turun-naiknya akurasi model klasifikasi. Mul-tivariate Bernoulli lebih baik jika vocabulary yang digunakan berjumlah sedikit, sedangkan untuk vocabulary dalam jumlah banyak, Multinomial NB menghasilkan tingkat akurasi yang lebih baik.
Model Multinomial NB tanpa seleksi fitur chi-square sangat baik dalam men-genali dokumen ham dengan tingkat akurasi 98.39%. Sedangkan dalam menmen-genali dokumen spam, model Multinomial NB dengan seleksi fitur chi-square dan tanpa seleksi fitur sama-sama menghasilkan akurasi yang terbaik yaitu sebesar 88.58%. Gambar 5 menunjukkan tingkat akurasi ham dan spam setiap model klasifikasi.
Se-13
Gambar 4 Pengaruh seleksi fitur terhadap model klasifikasi
Gambar 5 Tingkat akurasi ham dan spam setiap model klasifikasi
tiap model klasifikasi menunjukkan tingkat akurasi ham selalu lebih baik diband-ingkan dengan akurasi spam.
SIMPULAN DAN SARAN
Simpulan
Berdasarkan penelitian yang telah dilakukan, dapat disimpulkan beberapa hal sebagai berikut:
1. Model Multinomial NB tanpa seleksi fitur chi-square menghasilkan akurasi tertinggi sebesar 95.31%, sedangkan untuk tingkat akurasi terendah didap-atkan pada model Multivariate Bernoulli tanpa seleksi fitur chi-square dengan akurasi sebesar 89.69%.
2. Seleksi fitur chi-square mempengaruhi tingkat akurasi model klasifikasi. Se-leksi fitur chi-square meningkatkan akurasi model Multivariate Bernoulli sebe-sar 3.31%, sedangkan Multinomial NB mengalami penurunan akurasi sebesebe-sar 1.98%.
3. Dari semua pengujian, pengenalan dokumen ham selalu lebih baik diband-ingkan dengan pengenalan dokumen spam.
4. Secara keseluruhan model Multinomial NB menghasilkan akurasi yang lebih baik dibandingkan dengan model Multivariate Bernoulli.
Saran
Pada penelitian ini, pengenalan dokumen ham menghasilkan akurasi yang tinggi, tetapi pengenalan spam menghasilkan akurasi yang rendah. Dengan menggunakan model klasifikasi berbasis aturan, dokumen spam sulit diklasifikasikan karena pen-ciri antara dokumen ham dan spam banyak mempunyai kemiripan. Spam email mempunyai beberapa penciri yang unik dan dapat mudah diklasifikasikan tanpa per-hitungan peluang. Penggabungan model klasifikasi Naive Bayes dan model klasi-fikasi berbasis aturan (hand-crafted rules) diharapkan dapat meningkatkan akurasi pada pengenalan dokumen spam sehingga pada penelitian selanjutnya kinerja spam filter dapat lebih baik.
DAFTAR PUSTAKA
Manning, CD, P Raghavan, dan H Schutze. 2009. Introduction to Information Re-trieval. Cambridge (GB): Cambridge University Press. [Internet]. [Diunduh tang-gal 20/01/2015 ]. Dapat diunduh dari: http://julio.staff.ipb.ac.id. McAfee. 2008. The Carbon Footprint of Email Spam Report. Santa Clara: McAfee,
Inc.
Pantel, P dan D Lin. 1998. “SpamCop: A Spam Classification and Organization Program” dalam: AAAI Technical Report WS-98-05.
Rahman, W. 2013. “Pengukuran Kinerja Spam Filter Menggunakan Metode Naive Bayes Classifier Graham”. Skripsi. Bogor (ID): Institut Pertanian Bogor.
15
Sahami, M, S Dumais, D Heckerman, dan E Horvitz. 1998. “A Bayes Approach to Filtering Junk E-Mail” dalam: AAAI Technical Report WS-98-05.
Saputra. 2012. “Klasifikasi dokumen Bahasa Indonesia menggunakan semantic smoothing dengan ekstraksi ciri chi-square”. Skripsi. Bogor (ID): Institut Per-tanian Bogor.
Schneider, KM. 2003. Comparison of Event Models for Naive Bayes Anti-Spam EMail Filtering. Department of General Linguistics University of Passau.
Walpole, ER. 1968. Introduction to Statistics. Macmillan: University of Wisconsin - Madison.
16
Lampiran 1. Confussion Matrix untuk setiap pengujian model
klasifikasi
Model Kelas Aktual Kelas Prediksi Spam ¬Spam Multivariate Bernoulli tanpa χ2 Spam 406 163
¬Spam 24 1221
Multivariate NB tanpa χ2 Spam 504 65
¬Spam 20 1225
Multivariate Bernoulli dengan χ2 Spam 480 89
¬Spam 38 1207
Multivariate NB dengan χ2 Spam 504 65
17
18
RIWAYAT HIDUP
Penulis dilahirkan di Sumedang pada tanggal 8 Juni 1990 dari ayah Dedi Kusnadi dan ibu Ai Sumartini. Penulis adalah putra kedua dari tiga bersaudara. Tahun 2008 penulis lulus SMA Negeri 1 Sumedang dan pada tahun yang sama penulis lulus seleksi masuk Institut Pertanian Bogor Program Diploma, Program Keahlian Man-ajemen Informatika. Setelah menempuh pendidikan pada program Diploma penulis melanjutkan pendidikan tingkat sarjana pada program Ekstensi Ilmu Komputer IPB angkatan ke-7.