i
MENENTUKAN BOBOT SIMILARITY DAN BETWEENNESS
SECARA DINAMIS PADA PROTOKOL ROUTING SIMBET
MENGGUNAKAN METODE ENTROPY-WEIGHT
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer Program Studi Informatika
Oleh:
Yustina Lyvia Violita 165314027
PROGRAM STUDI INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
DYNAMIC WEIGHT OF SIMILARITY AND BETWEENNESS
ON SIMBET ROUTING PROTOCOL
USING THE ENTROPY -WEIGHT METHOD
THESIS
Presented as Partial Fullment of Requirements to Obtain Sarjana Komputer Degree in Informatics Study Program
By :
Yustina Lyvia Violita 165314027
INFORMATICS STUDY PROGRAM
INFORMATICS DEPARTMENT
FACULTY OF SIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
2020
v
MOTTO
“
Do not ever give up, the beginning is always
the hardest”
viii
ABSTRAK
Jaringan sosial oportunistik merupakan jaringan komunikasi nirkabel dimana manusia berperan sebagai node yang membawa suatu alat komunikasi. Pengiriman pesan dalam jaringan oportunistik menjadi sulit karena topologi jaringan yang berubah-ubah dan pergerakan node secara bebas didalam jaringan. Protokol routing digunakan untuk menentukan jalur terbaik yang akan dilewati saat pengiriman pesan. Pada penelitian ini, protokol routing yang diuji oleh penulis yaitu protokol routing SimBet. Protokol routing SimBet menggunakan 2 komponen dasar yaitu node similarity dan betweenness centrality untuk menentukan node relay
terbaik. Kelemahan protokol SimBet yaitu pembobotan nilai alpha untuk similarity
dan beta untuk betweenness harus ditentukan terlebih dahulu. Padahal, berdasarkan penelitian yang sudah dilakukan, bobot similarity dan betweenness pada setiap pergerakan berbeda-beda. Maka dari itu, penulis menerapkan algoritma entropy-weight yang bertujuan agar setiap node secara dinamis dapat melakukan pembobotan untuk setiap pesan dalam jaringan untuk mendapatkan performa delivery yang baik. Nantinya, setiap pesan akan dihitung kedekatannya terhadap tujuan dan seberapa populer node tersebut dalam jaringan. Penulis juga membandingkan hasil protokol SimBet dengan SimBet pembobotan dinamis dan menentukan bahwa SimBet pembobotan dinamis mampu beradaptasi dengan setiap
dataset yang di uji dan menghasilkan performa deliveryprobability yang lebih baik dibanding SimBet yang sudah ditentukan bobotnya di awal simulasi.
ix
ABSTRACT
Social opportunistic networks are wireless communication networks where humans act as nodes that carry a means of communication. Messaging in opportunistic networks becomes difficult because of the changing network topology and the movement of nodes freely within the network. The routing protocol is used to determine the best path to pass when sending messages. In this study, the routing protocol tested by the author is the SimBet routing protocol. The SimBet routing protocol uses 2 basic components, namely node similarity and betweenness centrality to determine the best relay node. The weakness of the SimBet protocol is that the weighting of alpha values for similarity and beta for betweenness must be determined first. In fact, based on the research that has been done, the weight of similarity and betweenness in each movement is different. Therefore, the authors apply an entropy-weight algorithm that aims to dynamically weight each node for each message in the network to get good delivery performance. Later, each message will be calculated on its proximity to the destination and how popular the node is in the network. The author also compares the results of the SimBet protocol with dynamic weighting SimBet and determines that dynamic weighting SimBet is able to adapt to each dataset being tested and results in better delivery probability performance than SimBet which has been weighted at the beginning of the simulation.
x
KATA PENGANTAR
Puji Syukur penulis panjatkan kepada Tuhan Yang Maha Esa karena atas rahmat dan berkat-Nya penulis dapat menyelesaikan penyusunan tugas akhir dengan tepat waktu. Dalam pelaksanaan penyusunan skripsi ini mendapatkan banyak bimbingan dan bantuan dari berbagai pihak. Pada kesempatan ini penulis mengucapkan banyak terimakasih kepada pihak-pihak yang ikut membantu menyelesaikan tugas akhir ini secara langsung maupun tidak langsung. Ucapan terimakasih penulis sampaikan pada :
1. Tuhan Yesus Kristus atas berkatNya yang melimpah hingga penulis dapat menyelesaikan tugas akhir ini.
2. Kedua orang tua saya dan seluruh keluarga yang selalu mendukung saya dan menjadi motivasi saya untuk menyelesaikan tugas akhir. 3. Bapak Bambang Soelistijanto, S.T, M.Sc., Ph.D selaku dosen
pembimbing tugas akhir yang sudah memberikan banyak bimbingan dan ilmu dalam mengerjakan tugas akhir.
4. Ibu Vittalis Ayu S.T., M.Cs selaku dosen pembimbing akademik yang memberikan bimbingan selama perkuliahan.
5. Diri saya sendiri, karena sudah berjuang dan tidak mudah menyerah dalam mengerjakan tugas akhir hingga bisa terselesaikan.
6. Mas Edwin Adiadhma yang selalu mendukung, menyemangati, dan mau mendengar keluh kesah saya dalam mengerjakan tugas akhir hingga bisa terselesaikan.
7. Teman-teman seperjuangan selama kuliah yaitu Alaw, Yova, Clara, Nanang, Yoga, Tatag, dan teman-teman kelas A yang tidak bisa disebut satu persatu disini.
8. Teman-teman KusFam dan GOF yang selalu menghibur dan menyemangati saya dikala sedang menghadapi masa sulit.
9. Kakak tingkat dan adik tingkat yang sudah memberikan dukungan sehingga saya dapat termotivasi mengerjakan tugas akhir.
10. Teman-teman Jaringan Komputer 2016 yang senantiasa membantu saya dan selalu mendukung saya dalam menyelesaikan tugas akhir.
xi
11. Seluruh teman-teman Informatika 2016 Universitas Sanata Dharma.
Penulis menyadari bahwa masih ada kekurangan pada tugas akhir ini. Mengingat keterbatasan pengetahuan dan pengalaman penulis, maka penulis mengharapkan kritik dan saran atas tugas akhir ini. Penulis mengharapkan tugas akhir ini dapat bermanfaat bagi banyak pihak dan bagi para pembacanya.
Penulis,
Yustina Lyvia Violita
xii
DAFTAR ISI
HALAMAN PERSETUJUAN ...iii
HALAMAN PENGESAHAN ... iv
MOTTO ... v
PERNYATAAN LEMBAR KEASLIAN KARYA ... vi
LEMBAR PERSETUJUAN PUBLIKASI KARYA ILMIAH ... vii
ABSTRAK ... viii
ABSTRACT ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR GAMBAR ... xiv
DAFTAR RUMUS ... xv
DAFTAR TABEL ... xvi
BAB I PENDAHULUAN ... 1 1.1 Latar Belakang ... 1 1.2 Rumusan Masalah ... 2 1.3 Tujuan Penelitian ... 3 1.4 Manfaat Penelitian ... 3 1.5 Batasan Masalah ... 3 1.6 Metodologi Penelitian ... 3 1.7. Sistematika Penulisan ... 4
BAB II LANDASAN TEORI ... 6
2.1 Mobile Ad-Hoc Network (MANET) ... 6
2.2. Jaringan Oportunistik ... 6
2.2.1 Jaringan Sosial Oportunistik ... 6
2.3. Protokol RoutingSimBet ... 7
2.3.1Betweenness Centrality ... 7
2.3.2Node similarity ... 8
2.3.3 Penghitungan Nilai Utilitas SimBet ... 10
2.4 Metode Entropy-Weight ... 11
xiii
2.6 Simulator ONE ... 16
BAB III PERANCANGAN SKENARIO SIMULASI ... 17
3.1. Data ... 17
3.3. Alat Penelitian ... 19
3.4. Desain Tahap Pengujian ... 19
BAB IV PENGUJIAN DAN ANALISIS ... 22
4.1 Haggle 4 – Cambridge Imotes ... 22
4.2 Sassy ... 25
4.3 Reality Mining ... 28
BAB V KESIMPULAN DAN SARAN ... 32
5.1 Kesimpulan ... 32
5.2 Saran ... 32
DAFTAR PUSTAKA ... 33
xiv
DAFTAR GAMBAR
Gambar 2. 5. 1 Ilustrasi pertemuan node A dan node B ... 13
Gambar 4. 1. 1 Grafik delivery probability dataset Haggle 4...22
Gambar 4. 1. 2 Grafik overhead ratio dataset Haggle 4 ... 23
Gambar 4. 1. 3 Grafik Latency Average dataset Haggle 4 ... 24
Gambar 4. 1. 4 Grafik Hop Count Average dataset Haggle 4 ... 24
Gambar 4. 2. 1 Grafik delivery probability dataset Sassy...25
Gambar 4. 2. 2 Grafik overhead ratio dataset Sassy ... 26
Gambar 4. 2. 3 Grafik latency average dataset Sassy ... 27
Gambar 4. 2. 4 Grafik hop count average dataset Sassy ... 27
Gambar 4. 3. 1 Grafik delivery probability dataset Reality MIT...28
Gambar 4. 3. 2 Grafik overhead ratio dataset Reality MIT... 29
Gambar 4. 3. 3 Grafik latency average dataset Reality MIT ... 30
xv
DAFTAR RUMUS
Rumus 2. 3. 1 Matrix adjacency ... 8
Rumus 2. 3. 2 Egocentric betweenness centrality... 8
Rumus 2. 3. 3 Node Similarity ... 9
Rumus 2. 3. 4 Perhitungan SimUtil ... 10
Rumus 2. 3. 5 Perhitungan BetUtil ... 10
Rumus 2. 3. 6 Perhitungan SimBetUtil ... 11
Rumus 2. 4. 1Normalisasi matrik...11
Rumus 2. 4. 2 Perhitungan Entropy ... 11
Rumus 2. 4. 3 Perhitungan nilai K ... 11
Rumus 2. 4. 4 Perhitungan Entropy-Weight ... 12
Rumus 3. 2. 1 Delivery Probability...18
Rumus 3. 2. 2 Latency Average ... 18
xvi
DAFTAR TABEL
Tabel 2. 5. 1 Tabel Similarity dan Betweenness dari node A ... 13
Tabel 2. 5. 2 Tabel Hasil Normalisasi Matrix ... 13
Tabel 2. 5. 3 Tabel Perkalian LN Similarity dan Betweenness dari suatu node ... 14
Tabel 2. 5. 4 Tabel Hasil Perhitungan Entropy ... 15
Tabel 2. 5. 5 Tabel Hasil Perhitungan Similarity dan Betweenness ... 15
1
BAB I
PENDAHULUAN
1.1 Latar BelakangMobile Ad-hoc Network (MANET)[1] yaitu jaringan wireless yang dinamis dan tidak membutuhkan infrastruktur jaringan. Setiap node pada MANET dapat berfungsi sebagai pengirim pesan, relay, dan juga sebagai penerima pesan. Sifat node pada MANET yaitu dapat bergerak setiap saat dan topologinya yang sering berubah-ubah sehingga dapat putus sewaktu waktu ini menciptakan adanya Delay Tolerant Networks (DTN) atau
Opportunistic Network (OppNet). Keunggulan dari OppNet adalah mampu menoleransi adanya delay dan bisa melakukan pencarian jalur komunikasi dari node source ke node destination tanpa adanya topologi yang terbentuk. Tantangan yang ada pada OppNet adalah bagaimana cara menentukan node terbaik untuk meneruskan suatu pesan. Beberapa protokol routing
digunakan dengan memanfaatkan relasi sosial antar node untuk membantu memutuskan kepada node manakah sebuah pesan akan diteruskan. Protokol-protokol tersebut disebut dengan social-aware routing protocols. Pada algoritma social-aware routing protocols ada 2 properti sosial yaitu
social closeness (tie strength) atau yang biasa disebut dengan similarity
yaitu node relay dipilih dengan cara menghitung nilai kedekatan/tingkat keterhubungan antara node yang ditemui dengan node destination. Ketika node yang ditemui oleh node pembawa pesan memiliki tingkat keterhubungan yang lebih tinggi ke node destination, pesan akan diteruskan ke node tersebut dan social rank (global popularity) atau yang biasa disebut
betweenness yaitu menentukan node relay dengan cara menghitung nilai kepopularitasan antara node yang ditemui dengan dirinya sendiri dan node yang lebih popular akan menjadi node relay. Dari berbagai routing social-aware yang ada, peneliti tertarik untuk melakukan penelitian untuk protokol
2
Protokol routing ini menggunakan node similarity dan menggunakan betweenness centrality Pada dasarnya, pembobotan terhadap nilai similarity dan betweenness centrality pada protokol ini diberi nilai yang sama untuk setiap pengiriman pesan. Pembobotan ini berpengaruh pada performa SimBet. Pembobotan yang optimal tergantung pada kecenderungan pergerakan node suatu jaringan yang bersangkutan. Karakteristik pada setiap pergerakan juga berbeda-beda. Jika nilai kedekatan/tingkat keterhubungan antara node yang ditemui dengan node
destination lebih tinggi maka pergerakan tersebut cenderung berkelompok. Jika nilai kepopularitasan antara node yang ditemui dengan dirinya sendiri lebih tinggi maka pergerakan tersebut cenderung tidak berkelompok. Maka dari itu, dibutuhkan algoritma agar pembobotan terhadap kedua matriks
SimBet untuk setiap pengiriman pesan bisa dilakukan secara dinamis oleh tiap-tiap node. Pada penelitian ini, penulis akan melakukan pengukuran seberapa efektif performa SimBet jika pembobotan dilakukan secara dinamis menggunakan metode entropy weight[2]. Entropy weight
digunakan untuk pembobotan atau penentuan tingkat kepentingan kriteria. Karena pada jaringan sosial oportunistik tidak terbentuk sebuah topologi, perhitungan betweenness centrality akan menggunakan konsep ego network.
1.2Rumusan Masalah
Berdasarkan latar belakang yang telah dipaparkan, rumusan masalah yang didapat adalah seberapa efektif performa protokol routing SimBet
dengan pembobotan nilai Betweenness Centrality dan Similarity secara dinamis menggunakan metode entropy-weight pada jaringan sosial oportunistik.
3 1.3Tujuan Penelitian
Tujuan dari tugas akhir ini adalah mengetahui seberapa efektif kinerja protokol routing SimBet ketika pembobotan nilai Similarity dan
Betweenness Centrality dilakukan secara dinamis menggunakan metode
entropy-weight.
1.4Manfaat Penelitian
Hasil dari penelitian ini diharapkan dapat digunakan sebagai bahan pertimbangan dalam menentukan protokol routing yang akan digunakan dalam komunikasi pada jaringan sosial oportunistik.
1.5Batasan Masalah
Batasan masalah dalam penelitian ini adalah :
a. Protokol routing yang diuji adalah protokol routing SimBet pada jaringan sosial oportunistik
b. Menggunakan metode perhitungan entropy-weight.
c. Metrik unjuk kerja yang digunakan yaitu delivery probability, overhead ratio, latency average, hop count average
1.6Metodologi Penelitian
Metodologi Penelitian yang digunakan : 1. Studi Pustaka
Mempelajari teori-teori yang berkaitan dengan protokol routing SimBet,
betweenness centrality, node similarity, danmetode entropy-weight.
2. Pengumpulan Bahan Penelitian
Data yang akan digunakan untuk melakukan penelitian sudah tersedia di Internet pada alamat http://www.shigs.co.uk/index.php?page=traces.
4 3. Pembuatan Alat Uji
Perancangan sistem dilakukan mulai dari mengidentifikasi apa yang dilakukan oleh protokol sehingga dapat menghasilkan data hasil simulasi yang dapat dianalisis.
4. Pengujian
Dalam tahap ini akan dibuat implementasi dari protokol routing yang akan digunakan dalam penelitian dan akan dilakukan pengujian untuk mengetahui performa protokol routing SimBet.
5. Analisis Hasil Pengujian
Dalam tahap ini data yang telah dikumpulkan akan diproses menggunakan simulator dan diamati untuk dianalisis berdasarkan parameter unjuk kerja yang sudah ditentukan.
1.7. Sistematika Penulisan
Berikut ini merupakan sistematika penulisan yang terbagi kedalam bab : BAB I : PENDAHULUAN
Bab ini berisi penjelasan tentang latar belakang masalah, rumusan masalah, tujuan penelitian, manfaat penelitian, batasan masalah, metodologi penelitian dan sistematika penulisan.
BAB II : LANDASAN TEORI
Bab ini berisi tentang dasar teori yang digunakan sebagai dasar dalam melakukan penelitian tugas akhir.
BAB III : PERANCANGAN SKENARIO SIMULASI
Bab ini berisi tentang rancangan simulasi yang akan digunakan dalam penelitian.
BAB IV : PENGUJIAN DAN ANALISIS
Bab ini berisi tentang tahap pengujian, yaitu simulasi, dan analisis hasil data simulasi.
5 BAB V : KESIMPULAN DAN SARAN
Bab ini berisi tentang kesimpulan hasil penelitian dan saran dari penulis untuk penelitian selanjutnya.
6
BAB II
LANDASAN TEORI
2.1 Mobile Ad-Hoc Network (MANET)
Mobile Ad-Hoc Network adalah jaringan wireless yang dinamis dan tidak membutuhkan infrastruktur jaringan. Setiap node dapat dengan bebas bergerak. Syarat utama pada MANET yaitu tersedianya jalur komunikasi dari node source ke node destination. Saat melakukan komunikasi, kedua buah node harus saling mengenali node yang akan diajak berkomunikasi dengan syarat node yang akan diajak berkomunikasi berada pada satu radio range dengan node pengirim. Namun, karena node dapat bergerak dengan bebas maka ketersediaan jalur dari source ke
destination sangat sulit, oleh karena itu, sering terjadi kegagalan pengiriman pesan karena topologi yang selalu berubah dalam waktu yang tidak menentu.
2.2. Jaringan Oportunistik
Jaringan Oportunistik atau Opportunistic Network (OppNet) merupakan bentuk khusus dari MANET. Pada jaringan ini tidak selalu tersedia jalur dari source
ke destination karena topologi jaringan yang berubah-ubah sehingga menjadikan routing dalam jaringan ini menjadi sulit dan mempunyai delay yang tinggi pada tiap pengiriman pesan, Jaringan Oportunistik memiliki system store-carry-forward
yaitu ketika dua buah node terdeteksi dalam satu radio-range, kemudian akan saling mengirim pesan yang dibawa masing-masing node. Setelah menerima pesan, node akan menyimpannya didalam buffer sampai ia menemuinode relay yang lebih baik atau menemukan node destination.
2.2.1 Jaringan Sosial Oportunistik
Jaringan Sosial Oportunistik[3] yaitu jaringan oportunistik dimana manusia ikut mengambil peran untuk membawa alat komunikasi yang kelakuannya dideskripsikan dalam bentuk sosial. Alat komunikasi tersebut ikut berpindah seiring dengan perpindahan manusia. Pola pergerakan
7
manusia dapat dibagi menjadi 2 properti sosial, yaitu properti social rank (global popularity) yaitu tidak membentuk kelompok-kelompok dan properti social closeness (tie strength) yaitu membentuk kelompok-kelompok tertentu selama proses kegiatannya. Dapat disimpulkan bahwa pergerakan manusia ternyata tidak random dan bisa dipelajari.
2.3. Protokol Routing SimBet
Algoritma routing SimBet merepresentasikan komunikasi antara node A dan node B. Protokol routing SimBet memiliki dua komponen dasar yaitu node similarity dan betweenness centrality.
2.3.1 Betweenness Centrality
Betweenness Centrality merupakan perhitungan untuk mengetahui seberapa penting sebuah node dalam menjadi penghubung komunikasi antar node. Semakin tinggi nilai
betweenness centrality maka node dianggap semakin populer dan mampu memfasilitasi interaksi antar node-node yang terhubung dengan node tersebut, dengan kata lain node tersebut dapat dititipi pesan. Di jaringan sosial oportunistik, tidak ada topologi jaringan yang terbentuk sehingga sangat tidak dimungkinkan untuk mengumpulkan informasi dari seluruh jaringan. Oleh karena itu, pada penelitian ini akan digunakan konsep “ego network”[4] yang hanya terdiri dari satu node (ego node) beserta node-node yang terhubung dengan ego node dan link antar node yang terbentuk. Penggunaan ego network dapat mengurangi banyaknya informasi yang harus dikumpulkan karena strukturnya yang sederhana dan terbatas. Secara matematis, node-node yang sudah ditemui ego node dapat direpresentasikan dalam bentuk matriks adjacency. Matriks yang terbentuk adalah matriks simetris yang akan memiliki orde n x n, n merupakan jumlah node yang sudah ditemui oleh ego node.
8
Rumus 2. 3. 1 Matrix adjacency
A = matriks adjacency dari sebuah ego node A
𝐸𝐵𝐶(𝐴) = ∑ 1 𝐴2⌈1 − 𝐴⌉
𝑖,𝑗
Rumus 2. 3. 2 Egocentric betweenness centrality
EBC(A) = nilai egocentric betweenness centralitysebuah ego node A
A² = kuadrat dari matriks adjacency A
Karena matrik yang terbentuk adalah matrik simetris, hanya nilai di atas diagonal dan tidak bernilai 0 yang perlu diperhatikan. Ketiga ego node bertemu dengan node baru yang belum termasuk dalam daftar node-node yang ditemuinya, ego node akan melakukan pembaharuan daftar node dan orde matriks adjacency. Pada ego network, node yang diperhitungkan adalah node yang ditemui ego node secara langsung maka hanya daftar node milik contact node
(node yang ditemui ego node) yang sama-sama ditemui oleh ego node dan contact node saja yang dimasukkan ke dalam matriks
adjacency. [5] 2.3.2 Node similarity
Node similarity yaitu semakin banyak kesamaan himpunan node tetangga yang sama antara node x dan y maka semakin tinggi probabilitas kedua buah node untuk bertemu. Jaringan sosial dapat menunjukkan adanya derajat transitivity yang sangat tinggi.
Transitivity yaitu relasi antara 3 node dimana jika ada hubungan antara node 1 dengan node 2, dan node 2 dengan node 3, maka secara
Jika node i dan node j pernah bertemu sebaliknya
9
tidak langsung node 1 dan node 3 juga berhubungan. Semakin tinggi nilai transitivity antara node 1 dan node 3 maka probabilitas untuk bertemu akan semakin meningkat. Dalam sebuah jaringan, semakin banyak teman yang sama yang dimiliki oleh dua buah node yang tidak saling terhubung, maka akan semakin tinggi probabilitas kedua node ini saling terhubung. Probabilitas dari penghitungan di bawah dapat menggambarkan adanya ‘node similarity’ dari node x dan
node y pada sebuah topologi jaringan. Semakin banyak kesamaan himpunan node tetangga yang sama antara node x dan node y maka semakin tinggi probabilitas kedua buah node untuk saling bertemu. Dengan kata lain, semakin banyak tetangga yang sama antara node x dan node y maka akan semakin similar.
𝑃(𝑥, 𝑦) = |𝑁(𝑥) ∩ 𝑁(𝑦)|
Rumus 2. 3. 3 Node Similarity
P(x,y) = probabilitas node x dan node y yang terhubung N(x) = himpunan node yang terhubung dengan x
N(y) = himpunan node yang terhubung dengan y
Perhitungan nilai node similarity juga menggunakan matriks pertemuan yang sudah dibuat pada saat akan menghitung nilai
betweenness centrality. Cara menghitung nilai node similarity untuk node-node yang sudah ditemui secara langsung oleh ego node dengan menguadratkan matriks adjacency yang telat dibuat. Tetapi, untuk menghitung nilai node similarity terhadap node-node yang tidak ditemui secara langsung yaitu dengan membentuk matriks n x m, dimana n merupakan jumlah node yang telah ditemui ego node secara langsung dan m adalah jumlah node yang tidak ditemuinya secara langsung namun dapat dijangkau melalui node yang telah
10
ditemui oleh ego node. Setelah matriks node yang tidak ditemui secara langsung terbuat, perhitungan node similarity dilakukan dengan mencari irisan dari kedua buah matriks, ada berapa node yang sama-sama memiliki nilai 1 pada matriks.
2.3.3 Penghitungan Nilai Utilitas SimBet
Utilitas SimBet menggunakan dua matriks penghitungan yaitu node similarity dan betweenness centrality. Node yang terpilih sebagai node relay adalah node yang memiliki nilai utilitas tertinggi dalam menyampaikan pesan ke node destination. Nilai utilitas SimBet didapatkan dari penghitungan nilai utilitas node similarity dan utilitas betweenness dari ego node (n) untuk mengirim pesan ke node destination (d) dibandingkan dengan node relay (m).
𝑆𝑖𝑚𝑈𝑡𝑖𝑙𝑛(𝑑) =
𝑆𝑖𝑚𝑛(𝑑) 𝑆𝑖𝑚𝑛(𝑑) + 𝑆𝑖𝑚𝑚(𝑑)
Rumus 2. 3. 4 Perhitungan SimUtil
𝑆𝑖𝑚𝑈𝑡𝑖𝑙𝑛(𝑑) = nilai utilitas node similarity node n terhadap node d
𝑆𝑖𝑚𝑛(𝑑) = nilai node similarity node n terhadap node d
𝑆𝑖𝑚𝑚(𝑑) = nilai node similarity node m terhadap node d
𝐵𝑒𝑡𝑈𝑡𝑖𝑙𝑛 =
𝐵𝑒𝑡𝑛 𝐵𝑒𝑡𝑛+ 𝐵𝑒𝑡𝑚
Rumus 2. 3. 5 Perhitungan BetUtil
𝐵𝑒𝑡𝑈𝑡𝑖𝑙𝑛 = nilai utilitas betweenness node n
𝐵𝑒𝑡𝑈𝑡𝑖𝑙𝑛 = nilai utilitas betweenness node n
𝐵𝑒𝑡𝑚 = nilai betweenness node m
Nilai utilitas SimBet node n ke node d dapat diukur dengan mengombinasikan nilai utilitas node similarity dan utilitas betweenness
yang telah diukur sebelumnya.
11
𝑆𝑖𝑚𝐵𝑒𝑡𝑈𝑡𝑖𝑙𝑛(𝑑) = 𝛼𝑆𝑖𝑚𝑈𝑡𝑖𝑙𝑛(𝑑) + 𝛽𝐵𝑒𝑡𝑈𝑡𝑖𝑙𝑛
Rumus 2. 3. 6 Perhitungan SimBetUtil
𝑆𝑖𝑚𝐵𝑒𝑡𝑈𝑡𝑖𝑙𝑛(𝑑) = nilai utilitas SimBet dari node n ke node d
α = bobot nilai alpha β = bobot nilai beta
Nilai α dan β jika dijumlah harus bernilai 1.
Nilai α dan β adalah nilai yang dapat berubah-ubah dan berfungsi untuk menentukan nilai utilitas mana yang lebih dominan untuk digunakan untuk meneruskan pesan ke destination.
2.4 Metode Entropy-Weight
Metode pembobotan menggunakan entropy digunakan untuk menghitung bobot suatu kriteria. Pada awalnya entropy lebih dikenal didalam ilmu termodinamika. Tetapi dalam perkembangannya, metode ini dapat pula digunakan dalam ilmu yang lainnya, salah satunya adalah dalam metode mengambil keputusan atau membobot suatu nilai tertentu. Untuk dapat menghitung nilai entropy, kita harus melakukan normalisasi matriknya terlebih dahulu.
𝑓
𝑖𝑗= 𝑋𝑖𝑗 ∑ 𝑋𝑖𝑗
𝑚 𝑖=1
Rumus 2. 4. 1 Normalisasi matrik
𝑋𝑖𝑗 = data matrik dari i sampai j
∑𝑚𝑖=1𝑋𝑖𝑗 = jumlah data matrik
𝐻𝑖 = −𝑘 ∑ 𝑓𝑖𝑗ln𝑓𝑖𝑗 , 𝑖 = 1,2, … , 𝑚 𝑛
𝑗=1
Rumus 2. 4. 2 Perhitungan Entropy
K = 1 ln (𝑛)
12
𝐻𝑖 = nilai entropy yang akan dihitung n = jumlah data yang dihitung
𝑓𝑖𝑗 = data matriks perhitungan
m = indikator data
Setelah menghitung nilai entropy, selanjutnya, hitung nilai bobot entropy. Untuk membobot suatu nilai tertentu dengan menggunakan rumus entropy, maka bisa didefinisikan dengan rumus
𝑤𝑖 =
1 − 𝐻𝑖 𝑚 − ∑𝑚𝑖=1𝐻𝑖
Rumus 2. 4. 4 Perhitungan Entropy-Weight
𝑊𝑖 = bobot entropy yang akan dihitung
𝐻𝑖 = nilai entropy yang sudah dihitung sebelumnya m = jumlah indikator data
Jika nilai entropy nya semakin tinggi maka bobotnya akan semakin rendah, karena nilai entropy berbanding terbalik dengan bobotnya.
2.5Penentuan Nilai α
Penentuan nilai α dihitung menggunakan matriks penghitungan yaitu
similaritynoderelay(m) terhadap destinasi (d) seperti pada rumus rumus 2.3.4 dan
betweenness centrality node relay terhadap ego node(n) seperti yang sudah dijabarkan dalam dan rumus 2.3.5
Contoh :
Node A bertemu node B. Node A membawa 7 pesan dan node B membawa 6 pesan. A B A1 A2 A3 A4 A5 A6 A7 dfs AA6 A7 A8 A9 A2 A1 A8 A4
13
Gambar 2. 5. 1 Ilustrasi pertemuan node A dan node B yang mempunyai destinasi pesan
Node A mempunyai 7 tujuan pesan dalam jaringan sebagai berikut :
Tabel 2. 5. 1 Tabel Similarity dan Betweenness dari node A
Node : A
Tujuan Pesan Similarity node
relay (node B) terhadap tujuan
Betweenness node
relay (node B) terhadap ego node
(node A) A1 5.0 0.600407 A2 5.0 0.600407 A3 9.0 0.600407 A4 10.0 0.600407 A5 8.0 0.600407 A6 6.0 0.600407 A7 6.0 0.600407
Maka nilai α dapat dihitung menggunakan metode entropy-weight seperti berikut :
1. Node A akan membuat normalisasi matrix dengan rumus 2.4.1
Tabel 2. 5. 2 Tabel Hasil Normalisasi Matrix
Destinasi Pesan Normalisasi matrix Similarity node
Normalisasi Matrix Betweenness node
14 Node : A
relay (node B) terhadap dest
relay (node B) terhadap ego node (node A) A1 8.0 / 39 0.4178 / 2.9246 A2 7.0 / 39 0.4178 / 2.9246 A3 4.0 / 39 0.4178 / 2.9246 A4 6.0 / 39 0.4178 / 2.9246 A5 2.0 / 39 0.4178 / 2.9246 A6 6.0 / 39 0.4178 / 2.9246 A7 6.0 / 39 0.4178 / 2.9246 ∑ 𝑋𝑖𝑗 𝑚 𝑖=1 39 2.9246
2. Hitung entropy nya menggunakan rumus 2.4.2 dan nilai K dihitung menggunakan rumus 2.4.3
K = 0.513898342 dimana n merupakan jumlah banyaknya data (destinasi pesan)
Tabel 2. 5. 3 Tabel Perkalian LN Similarity dan Betweenness dari suatu node
Destinasi Pesan
Perkalian LN Similarity node relay (node B) terhadap dest
Perkalian LN
Betweenness node relay (node B) terhadap ego node (node A)
15 Node : A A1 0.205128205* LN (0.205128205) 0.142857 * LN (0.142857) A2 0.179487179 * LN (0.179487179) 0.142857 * LN (0.142857) A3 0.102564103 * LN (0.102564103) 0.142857 * LN (0.142857) A4 0.153846154 * LN (0.153846154) 0.142857 * LN (0.142857) A5 0.051282051 * LN (0.051282051) 0.142857 * LN (0.142857) A6 0.153846154 * LN (0.153846154) 0.142857 * LN (0.142857) A7 0.153846154 * LN (0.153846154) 0.142857 * LN (0.142857)
Tabel 2. 5. 4 Tabel Hasil Perhitungan Entropy
Node : A
Destinasi Pesan
Hasil Perkalian LN Similarity node relay (node B) terhadap dest
Hasil Perkalian LN
Betweenness node relay (node B) terhadap ego node (node A) A1 -0.324947714 -0.277987164 A2 -0.308296423 -0.277987164 A3 -0.233565875 -0.277987164 A4 -0.287969566 -0.277987164 A5 -0.152328947 -0.277987164 A6 -0.287969566 -0.277987164 A7 -0.287969566 -0.277987164 ∑ 𝑓𝑖𝑗 𝑚 𝑖=1 ln𝑓𝑖𝑗 -1.88305 -1.945910149
Setelah nilai K dan jumlah dari hasil perkalian LN sudah didapatkan, maka kita bisa menghitung nilai H atau nilai entropynya
𝐻𝑆𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦 = −0.513898342 x -1.88305 = 0.967695
𝐻𝑏𝑒𝑡𝑤𝑒𝑒𝑛𝑛𝑒𝑠𝑠 = −0.513898342 x -1.945910149 =1
∑𝐻 = 0.967695 + 1 = 1.967695
3. Hitung bobot entropy (entropy weight) nya dengan rumus 2.4.4 :
Tabel 2. 5. 5 Tabel Hasil Perhitungan Similarity dan Betweenness
Hasil Perhitungan
16
1 0
Maka didapatkan bobot nilai α = 1 dan β = 0
2.6 Simulator ONE
The ONE[6] adalah simulator untuk menjalankan routing pada Jaringan Oportunistik (OppNet) . Fungsi dari simulator ONE yaitu bisa melakukan simulasi pergerakan node menggunakan model pergerakan yang berbeda-beda dan juga bisa melakukan simulasi routing pengiriman pesan antar node dengan berbagai algoritma routing yang ada pada OppNet serta bisa menampilkan visualisasi pergerakan dan persebaran pesan secara real time pada tampilan grafis yang disediakan.
17
BAB III
PERANCANGAN SKENARIO SIMULASI
3.1. DataData yang digunakan adalah Human contact datasets.Datasets yang akan digunakan adalah Haggle 4 – Camimote, Sassy dan Reality Mining oleh MIT. Data ini merupakan himpunan waktu pertemuan antar node menggunakan perangkat bergerak nirkabel pada percobaan penambangan data dalam kehidupan nyata. Waktu pertemuan dua buah node dapat didefinisikan secara sederhana yaitu ketika sebuah node menyadari adanya kehadiran node lain dalam satu radio range.
Parameter tetap yang digunakan pada peneltian ini dan digunakan pada beberapa skenario yang berbeda adalah sebagai berikut
Tabel 3. 1. 1 Tabel parameter simulasi
Parameter Haggle 4
CAMIMOTE
SASSY Reality MIT
Scenario Time (second) 987529 6413284 8490908
Buffer Size (MB) 20 M 20 20
TTL (minute) 30240 30240 20160
Msg. Interval (second) 580, 620 580, 620 580, 620
Msg Size (kB) 10 10 10
3.2. Matriks Unjuk Kerja Jaringan
Dalam penelitian ini, ada 4 matrik unjuk kerja yang akan digunakan yaitu
delivery probability, overhead ratio, latency average, hop count average. Metrik unjuk kerja jaringan digunakan untuk mengetahui performa dari sebuah protokol
18 a. Delivery Probability
Delivery Probability berguna untuk mengetahui probabilitas pesan yang berhasil dikirimkan ke tujuan (node destination). Semakin tinggi nilai delivery probability yang dihasilkan maka unjuk kerja protokol routing dapat dikatakan baik.
𝐷𝑒𝑙𝑖𝑣𝑒𝑟𝑦 𝑃𝑟𝑜𝑏𝑎𝑏𝑖𝑙𝑖𝑡𝑦 = 𝑇𝑜𝑡𝑎𝑙 𝐷𝑒𝑙𝑖𝑣𝑒𝑟𝑒𝑑 𝑀𝑒𝑠𝑠𝑎𝑔𝑒 𝑇𝑜𝑡𝑎𝑙 𝐺𝑒𝑛𝑒𝑟𝑎𝑡𝑒𝑑 𝑀𝑒𝑠𝑠𝑎𝑔𝑒
Rumus 3. 2. 1 Delivery Probability
b. Latency Average
Latency Average berguna untuk mengetahui jumlah rata-rata waktu yang dibutuhkan sebuah pesan untuk mencapai node destination sejak pesan dibuat. Semakin tinggi nilai latency average yang dihasilkan maka unjuk kerja protokol
routing dapat dikatakan buruk.
𝐿𝑎𝑡𝑒𝑛𝑐𝑦 𝑎𝑣𝑒𝑟𝑎𝑔𝑒 =𝑠𝑢𝑚 𝑜𝑓 𝑙𝑎𝑡𝑒𝑛𝑐𝑦 𝑜𝑓 𝑑𝑒𝑙𝑖𝑣𝑒𝑟𝑒𝑑 𝑚𝑒𝑠𝑠𝑎𝑔𝑒𝑠 𝑡𝑜𝑡𝑎𝑙 𝑔𝑒𝑛𝑒𝑟𝑎𝑡𝑒𝑑 𝑛𝑒𝑤 𝑚𝑒𝑠𝑠𝑎𝑔𝑒
Rumus 3. 2. 2 Latency Average
c. Hop Count Average
Hop Count berguna untuk mengetahui jumlah rerata hop yang dilalui oleh sebuah pesan untuk mencapai node destination. Semakin tinggi nilai rerata hop count yang dihasilkan, maka unjuk kerja protokol routing dapat dikatakan buruk. d. Overhead Ratio
Overhead ratio berguna untuk mengetahui perbandingan antara total copy
pesan dalam jaringan dengan jumlah pesan yang sampai ke node destination. Semakin tinggi nilai overhead ratio yang dihasilkan, maka unjuk kerja protokol
19
Overhead ratio = number of relayed messages − number of delivered messages number of delivered messages
Rumus 3. 2. 3 Overhead Ratio
3.3. Alat Penelitian a. Hardware
Sistem Operasi : Windows 10 Pro 64-bit (10.0, Build 18363) Pabrikan sistem : Micro-Star International Co., Ltd.
Prosesor : Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz (12 CPUs),~3.2 GHz
Memori : 8192MB RAM
b. Software Simulator ONE
3.4. Desain Tahap Pengujian 1. Studi Pustaka
Studi pustaka dilakukan dengan membaca jurnal yang berkaitan dengan protokol routing simulator ONE, SimBet, centrality, betweenness centrality, node similarity, metode entropy weight.
2. Pengumpulan Bahan Penelitian
Data human contact datasets sudah tersedia online di Internet http://www.shigs.co.uk/index.php?page=traces. Peneliti hanya perlu mengunduh data pada link yang tersedia.
3. Pembuatan Alat Uji a Analisis Kebutuhan
Analisis kebutuhan pada alat uji yang digunakan sudah ditulis dalam landasan teori Simulator ONE, BAB II.
b. Desain Alat Uji
Alat uji yang digunakan merupakan implementasi protokol SimBet
20 i. Perhitungan nilai α
Algoritma perhitungan nilai α
1: Ambil destinasi pesan dari buffer
2: Bangun matriks dengan 2 data yaitu data Similarity peer terhadap destinasi pesan dan data Betweenness peer 3: Nilai α dihitung dengan rumus entropy weight
ii. Pseudo-code routing SimBet
Pseudo-code routing SimBet dengan nilai α dinamis while 𝑁𝐴 is in contact with 𝑁𝐵do
//exchange neighbours list
send list of neighbours of Node 𝑁𝐴
receive list of neighboursNode of Node 𝑁𝐵
//update
update betweenness_centrality node 𝑁𝐴
update node_similarity node 𝑁𝐴
for all message in buffer node 𝑁𝐴 do
//count similarity and betweenness
count Similarity(𝑁𝐵, 𝑑𝑒𝑠𝑡)
count Betweenness(𝑁𝐵, 𝑁𝐴)
//count α value using entropy-weight method
α = entropyWeight(𝑁𝐴) //count simbetUtil 𝑁𝐴and 𝑁𝐵
my_SimBetUtil = count SimBet_Util(𝑁𝐴)
21 //forwarding decision if (peer_SimBetUtil > my_SimBetUtil OR (𝑁𝐵) = destination) then forward(m, 𝑁𝐵) end if end while 4. Pengujian a. Skenario Pengujian
1. Menjalankan simulasi dengan bobot α statis yang bervasiasi mulai dari 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.
2. Menjalankan simulasi dengan bobot α dinamis menggunakan metode entropy-weight
Kemudian membandingkan hasil dari pengujian 1 dan 2. b. Desain Cara Melakukan Pengujian dengan Alat Uji
Pengujian dilakukan dengan cara menjalankan simulasi sebanyak 1 kali untuk setiap skenario yang diuji pada setiap dataset yang digunakan.
5. Analisis Hasil Pengujian
Menentukan nilai metrik unjuk kerja yang dibutuhkan untuk menganalisis unjuk kerja SimBet, yaitu delivery probability, overhead ratio, latency average, dan hop count average.
22
BAB IV
PENGUJIAN DAN ANALISIS
Untuk mengevaluasi unjuk kerja protocol routing SimBet, dilakukan simulasi dengan skenario yang telah dirancang pada Bab III, pada dataset Haggle 3 – Infocom 5, Haggle 4 – Cambridge Imotes, Sassy, dan Reality Mining oleh MIT. Data hasil simulasi diperoleh dari report yang dibangkitkan ketika simulasi berjalan.
4.1Haggle 4 – Cambridge Imotes
Dataset ini berisi data pertemuan antar pelajar di Universitas Cambridge. Jumlah partisipan yang digunakan dalam simulasi ini sebanyak 36 orang. Lokasi pengambilan data berada di Kota Cambridge, Inggris. Selain dibawa 36 orang mahasiswa Cambridge, iMotes juga diletakkan di beberapa tempat yang sering dikunjungi partisipan, yaitu laboratorium komputer Universitas Cambridge, took penjual bahan makanan, pub, supermarket, pusat perbelanjaan di Kota Cambridge. Durasi simulasi pada dataset ini adalah 987529 detik atau sekitar 11,43 hari.
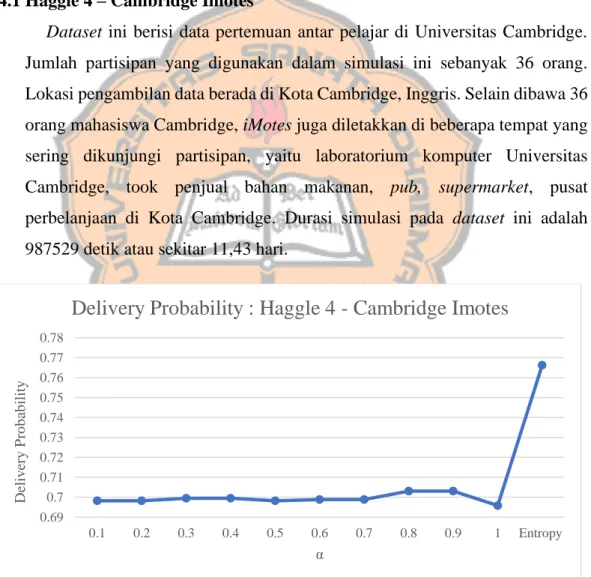
Gambar 4. 1. 1 Grafik delivery probability dataset Haggle 4 – Cambridge Imotes
Berdasarkan hasil simulasi, dapat dilihat pada gambar 4.1.1 bahwa semakin tinggi nilai α, maka nilai delivery probability yang dihasilkan cenderung
0.69 0.7 0.71 0.72 0.73 0.74 0.75 0.76 0.77 0.78 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Entropy Deliv er y P ro b ab ilit y α
23
meningkat. Nilai delivery probability tertinggi pada dataset ini adalah saat α=0.8 dan α=0.9 yang artinya property sosial pada dataset ini cenderung mengarah pada social closeness atau cenderung menggunakan nilai similarity
dan pergerakan node dalam dataset ini cenderung mengelompok. Namun pada saat α dinamis, delivery probability nya bernilai lebih tinggi dari pada saat nilai α yang di set terlebih dahulu. Hal ini membuktikan bahwa algoritma pembobotan ini mampu beradaptasi dalam menentukan nilai α yang baik untuk tiap pesan dlaam dataset yang cenderung mengalami pengelompokan ini.
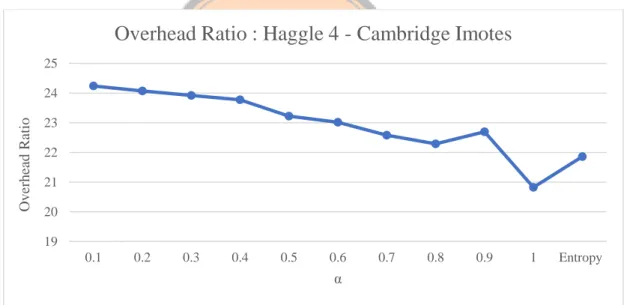
Gambar 4. 1. 2 Grafik overhead ratio dataset Haggle 4 – Cambridge Imotes
Pada gambar 4.1.2 , dapat dilihat bahwa overhead akan semakin berkurang saat nilai α atau penggunaan metrik node similarity semakin besar atau semakin kuat. Untuk nilai α dinamis, nilai overhead ratio yang dihasilkan rendah mendekati layaknya Ketika pembobotan α = 0,8. Hal ini dikarenakan nilai α yang berbeda untuk tiap pesan dari hasil perhitungan pada saat pertemuan antar node
19 20 21 22 23 24 25 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Entropy Ov er h ea d R atio α
24
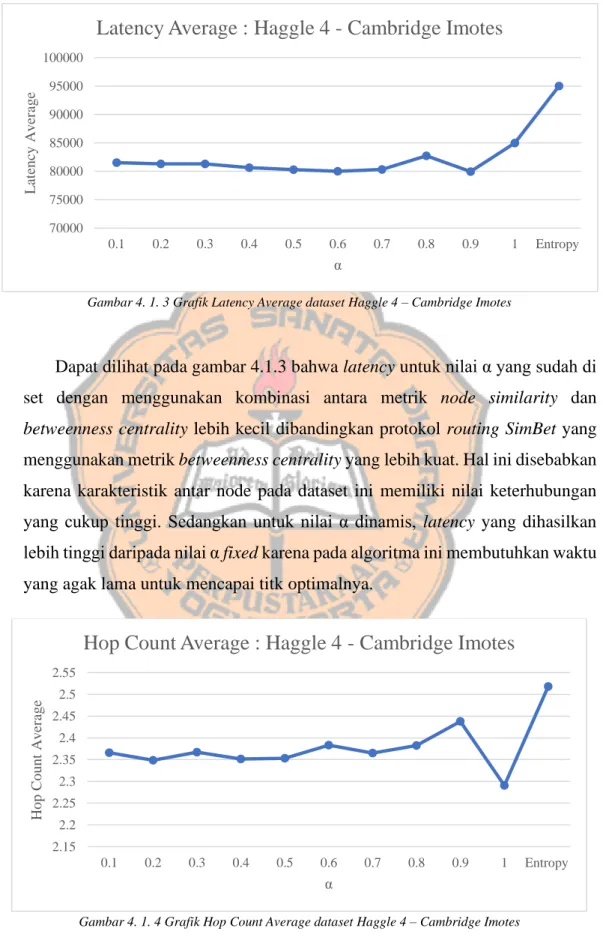
Gambar 4. 1. 3 Grafik Latency Average dataset Haggle 4 – Cambridge Imotes
Dapat dilihat pada gambar 4.1.3 bahwa latency untuk nilai α yang sudah di set dengan menggunakan kombinasi antara metrik node similarity dan
betweenness centrality lebih kecil dibandingkan protokol routing SimBet yang menggunakan metrik betweenness centrality yang lebih kuat. Hal ini disebabkan karena karakteristik antar node pada dataset ini memiliki nilai keterhubungan yang cukup tinggi. Sedangkan untuk nilai α dinamis, latency yang dihasilkan lebih tinggi daripada nilai α fixed karena pada algoritma ini membutuhkan waktu yang agak lama untuk mencapai titk optimalnya.
Gambar 4. 1. 4 Grafik Hop Count Average dataset Haggle 4 – Cambridge Imotes
70000 75000 80000 85000 90000 95000 100000 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Entropy L aten cy A v er ag e α
Latency Average : Haggle 4 - Cambridge Imotes
2.15 2.2 2.25 2.3 2.35 2.4 2.45 2.5 2.55 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Entropy Ho p C o u n t A v er ag e α
25
Dapat dilihat pada gambar 4.1.4, karena pergerakan yang cenderung berkelompok ini, nilai hop count mengalami peningkatan seiring dengan semakin menguatnya metrik node similarity untuk pemilihan node relay. Peningkatan hop count ini bertujuan untuk menghindari penggunaan hub node (node yang popular) secara berlebih yang dampaknya yaitu pesan akan melalu lebih banyak hop untuk mencapai node destination.
4.2Sassy
Dataset ini berisi data pertemuan antar pelajar undergraduate, pelajar
postgraduate, dan staff di Universitas St. Andrew. Jumlah partisipan yang digunakan dalam simulasi ini sebanyak 22 pelajar undergraduate, 3 pelajar
postgraduate, dan 2 orang staff. Lokasi penelitian berada di dalam dan di luar Kota St. Andre. Dari 27 partisipan, hanya 25 device yang datanya valid dan bisa digunakan untuk melakukan penelitian. Durasi simulasi pada dataset ini adalah sekitar 79 hari.
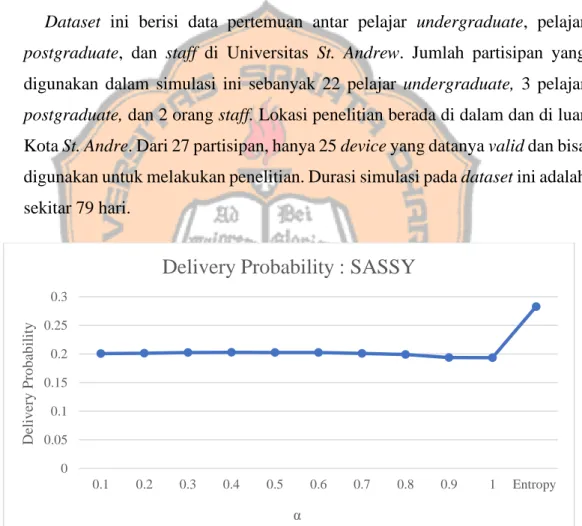
Gambar 4. 2. 1 Grafik delivery probability dataset Sassy
Berdasarkan hasil simulasi, dapat dilihat pada gambar 4.2.1 nilai delivery probability tertinggi pada pembobotan fixed dihasilkan pada saat nilai α = 0,4. Pada saat 0,3≤α≤0,6 delivery probability yang dihasilkan memiliki nilai yang konstan yang artinya pergerakan pada dataset ini seimbang dalam penggunaan matrik node similarity dan betweenness centrality. Namun, pada saat nilai α dinamis, delivery
0 0.05 0.1 0.15 0.2 0.25 0.3 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Entropy Deliv er y P ro b ab ilit y α
26
probability yang dihasilkan lebih tinggi dari pada nilai α dengan pembobotan fixed. Hal ini membuktikan bahwa algoritma ini dapat beradaptasi ketika diterapkan pada
dataset yang memiliki keseimbangan dalam penggunaan metrik node similarity dan
betweenness centrality.
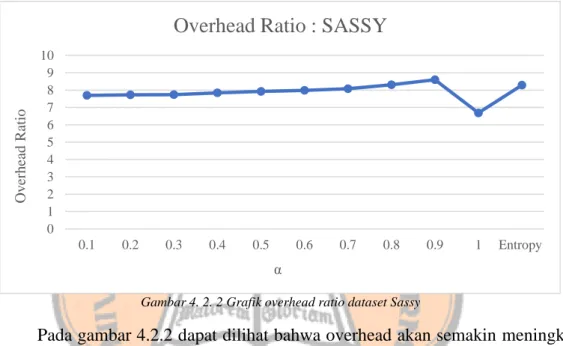
Gambar 4. 2. 2 Grafik overhead ratio dataset Sassy
Pada gambar 4.2.2 dapat dilihat bahwa overhead akan semakin meningkat saat nilai α atau penggunaan metrik node similarity semakin besar atau semakin kuat. Hal ini dikarenakan karakteristik node pada dataset ini hanya memiliki tingkat keterhubungan yang rendah. Namun, pada saat hanya pengaruh nilai similarity yang digunakan dalam pemilihan node relay, nilai overhead mengalami penurunan. Untuk nilai α dinamis, overhead ratio yang dihasilkan menunjukan perbedaan yang tidak begitu signifikan dengan nilai α fixed.
0 1 2 3 4 5 6 7 8 9 10 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Entropy Ov er h ead R atio α
27
Gambar 4. 2. 3 Grafik latency average dataset Sassy
Dapat dilihat pada gambar 4.2.3 bahwa pada pembobotan fixed, peningkatan nilai latency yang teratur terjadi pada saat 0,2≤α≤0,6 sedangkan yang lain cenderung acak dan tidak menunjukan suatu pola tertentu. Pada saat nilai α dinamis menunjukan nilai latency terendah yang artinya algoritma ini bagus untuk diterapkan pada dataset ini karena menghasilkan delivery probability yang tinggi dan latency yang paling rendah. Penggunaan metrik similarity dan betweenness centrality yang seimbang pada dataset ini mengakibatkan nilai latency nya berkurang sehingga pesan dapat lebih cepat sampai ke node tujuan.
Gambar 4. 2. 4 Grafik hop count average dataset Sassy
575000 580000 585000 590000 595000 600000 605000 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Entropy L aten cy A v er ag e α
Latency Average : SASSY
1.8 1.85 1.9 1.95 2 2.05 2.1 2.15 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Entropy Ho p C o u n t A v er ag e α
28
Pada gambar 4.2.4 dapat dilihat bahwa hop count average akan semakin meningkat saat nilai α atau penggunaan metrik node similarity semakin kuat. Namun, pada saat hanya pengaruh nilai similarity yang digunakan, terjadi penurunan nilai hop nya. Hal ini disebabkan karena node-node yang dititipi pesan hanya sedikit, namun node-node tersebut memiliki rantai pertemanan yang pendek dengan node destinasi. Pergerakan pada dataset ini membentuk kelompok-kelompok namun tidak tetap sehingga tingkat keterhubungan antar node menjadi rendah. Pada saat nilai α dinamis, rantai pertemanan sangat tinggi karena kecenderungan menggunakan metrik similarity namun dengan tetap menggunakan pengaruh metrik betweenness.
4.3Reality Mining
Dataset ini berisi data pertemuan antar pelajar dari 2 fakultas di Universitas MIT. Jumlah partisipan yang digunakan dalam simulasi ini sebanyak 75 pelajar Fakultas Media Laboratory dan 25 pelajar dari Fakultas Business. Durasi simulasi pada dataset ini adalah 1 tahun akademik. Dari 100 partisipan yang dipilih, device yang menghasilkan data yang valid dan dapat digunakan untuk melakukan penelitian sebanyak 97.
Gambar 4. 3. 1 Grafik delivery probability dataset Reality MIT
Berdasarkan hasil simulasi, dapat dilihat pada gambar 4.3.1 bahwa semakin tinggi nilai α, maka nilai delivery probability yang dihasilkan cenderung meningkat. Nilai delivery probability tertinggi pada dataset ini adalah pada saat α=0.9 yang
0.51 0.52 0.53 0.54 0.55 0.56 0.57 0.58 0.59 0.6 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Entropy Deliv er y P ro b ab ilit y α
29
artinya property sosial pada dataset ini cenderung mengarah pada social closeness atau cenderung menggunakan nilai similarity dan pergerakan node dalam dataset
ini cenderung mengelompok. Namun pada saat α dinamis, delivery probability nya bernilai lebih tinggi dari pada saat nilai α yang di set terlebih dahulu. Hal ini membuktikan bahwa algoritma pembobotan ini mampu beradaptasi dalam menentukan nilai α yang baik untuk tiap pesan dlaam dataset yang cenderung
mengalami pengelompokan ini.
Gambar 4. 3. 2 Grafik overhead ratio dataset Reality MIT
Pada gambar 4.3.2, dapat dilihat bahwa overhead akan semakin menurun jika penggunaan metrik node similarity semakin kuat. Hal ini terjadi karena pesan hanya dititipkan ke node yang memiliki tingkat keterhubungan yang lebih tinggi dengan node destinasi untuk setiap pesan, hal ini juga akan mengurangi jumlah pesan yang digandakan. Untuk nilai α dinamis, nilai overhead ratio yang dihasilkan rendah mendekati layaknya Ketika pembobotan sepenuhnya hanya menggunakan node similarity. 0 20 40 60 80 100 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Entropy Ov er h ea d R atio α
30
Gambar 4. 3. 3 Grafik latency average dataset Reality MIT
Dapat dilihat pada gambar 4.3.3 bahwa latency akan semakin berkurang saat nilai α atau penggunaan metrik node similarity semakin besar atau semakin kuat. Pemilihan node relay yang menggunakan metrik betweenness centrality
menghasilkan nilai yang lebih tinggi dibanding pemilihan node relay yang menggunakan metrik node similarity. Hal ini disebabkan karena karakteristik antar node pada dataset ini memiliki nilai keterhubungan yang cukup tinggi. Pada saat nilai α dinamis menunjukan nilai latency terendah yang artinya algoritma ini bagus untuk diterapkan pada dataset ini karena menghasilkan delivery probability yang tinggi dan latency yang paling rendah.
Gambar 4. 3. 4 Grafik hop count average dataset Reality MIT
410000 440000 470000 500000 530000 560000 590000 620000 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Entropy L aten cy A v er ag e α
Latency Average : Reality MIT
3 3.05 3.1 3.15 3.2 3.25 3.3 3.35 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Entropy d Ho p C o u n t A v er ag e α
31
Pada gambar 4.3.4, dapat dilihat bahwa hop count average akan semakin meningkat saat nilai α atau penggunaan metrik node similarity semakin kuat. Peningkatan hop count ini bertujuan untuk menghindari pengiriman pesan ke hub node. Pada saat α dinamis, hop count nya lebih tinggi dari α = 1. Hal ini karena beberapa pesan tetap menggunakan penggunaan betweenness yang lebih kuat dari node similarity.
32
BAB V
KESIMPULAN DAN SARAN
5.1 KesimpulanBerdasarkan hasil pengujian dengan simulasi beserta analisis hasil simulasi maka dapat disimpulkan bahwa algoritma entropy weight untuk menentukan bobot α secara dinamis mampu beradaptasi dengan dataset yang memiliki pergerakan cenderung berkelompok maupun tidak berkelompok dengan kelebihan dan kekurangannya masing-masing pada protokol routing SimBet. Dengan membobot nilai α secara dinamis juga maka node bisa mencari sendiri nilai optimalnya. Algoritma ini juga dapat menghasilkan nilai delivery probability yang tinggi untuk dataset yang memiliki pergerakan cenderung berkelompok maupun tidak berkelompok. Untuk overhead, nilainya lebih rendah dari 0<α<1 yang juga cenderung menyamai saat nilai α = 1. Nilai latency yang dihasilkan juga lebih rendah dibanding dengan 0<α<1 tetapi, untuk dataset
Haggle 4 lebih tinggi karena membutuhkan waktu yang lebih lama untuk mencari nilai optimalnya pada dataset tersebut.
5.2 Saran
Pada penelitian selanjutnya dapat diteliti metode perhitungan lain untuk membobot nilai α secara dinamis pada protokol routing SimBet dengan tidak hanya melihat delivery probability yang baik, tetapi juga latency yang kecil.
33
DAFTAR PUSTAKA
[1] Z. Zhang, “Routing in Intermittenly Connected Mobile Ad Hoc Networks and Delay Tolerant Networks : Overview and Challenges,” vol. 8, no. 1, pp.24 – 37, 2006
[2] P. Principles, “Notice of Retraction Study of Entropy Weight Theory in EPC Owner Risk Decision.”
[3] E. Daly and M. Haahr, “Social Network Analysis for Routing in Disconnected Delay-Tolerant MANETs,” pp. 32–40, 2007.
[4] Everett, Martin dan Stephen P.Borgatti. 2005. Ego Network Betweenness. Social Networks 27 (2005) 31-38
[5] E. K. A. Permatasari, "Analisis Unjuk Kerja Protokol Routing Simbet pada Jaringan Sosial Oportunistik," Yogyakarta, 2017
[6] Ari Kerӓnen, Jӧrg Ott and Teemu Kӓrkkӓinen. The One Simulator for DTN Protocol Evaluation. SIMUTools'09: 2nd International Conference on Simulation Tools and Techniques. Rome, March 2009.
URL:https://www.netlab.tkk.fi/tutkimus/dtn/theone/pub/the_one_simulatoo ls.pdf. Diakses: 25 Maret 2020.
[7] B. Y. S. Sudjono, "Pembobotan Nilai Alpha Dinamis Pada Protokol Routing Simbet", Yogyakarta, 2019
[8] Greg Bigwood, Tristan Henderson, Devan Rehunathan, Martin Bateman, Saleem Bhatti, CRAWDAD dataset st_andrews/sassy (v.2011-06-03), diunduh dari http://crawdad.org/st_andrews/sassy/20110603, https://doi.org/10.15783/C7S59X, Jun 2011
[9] James Scott, Richard Gass, Jon Crowcroft, Pan Hui, Christope Diot, Agustin Chaintreau, CRAWDAD dataset cambridge/haggle (v. 2009-05-29), diunduh dari http://crawdad.org/cambridge/haggle/20090529, https://doi.org/10.15783/C70011, May 2009
[10] Nathan Eagle, Alex (Sandy) Pentland, CRAWDAD dataset mit/reality (v. 2005-07-01), diunduh dari http://crawdad.org/mit/reality/20050701, https://doi.org/10.15783/C71S31, Jul 2005.