PENGENALAN
PEMBELAJARAN
MESIN
Tentang Catatan Ini
Saya banyak mendengar baik dari teman, junior, senior, dsb; kalimat berikut ini “kuliah mengajari teori saja, prakteknya kurang, tidak relevan dengan industri”. Menurut saya di suatu sisi itu benar; tapi di sisi lain, karena pemikiran tersebutlah kita banyak merasakan hal seperti pada meme berikut
https://s-media-cache-ak0.pinimg.com/236x/4f/54/29/4f5429df5ea6361fa8d3f08dfcdccdf9.jpg
Banyak yang buru-buru “langsung ajalah kasi tahu cara menggunakan, kan lebih practical”. Barangkali lebih asyik membaca buku yang berjudul “pembelajaran mesin menggunakan <bahasa_pemrograman>”. Saya ingin menyampaikan satu hal, apakah menurut Anda mereka yang bekerja dalam tim Google Translate, IBM Watson, Google Tensor Flow, Deep Mind (bukan promosi) adalah orang yang hanya belajar pembelajaran mesin dengan mindset “yang penting bisa memakai”?
Sepengetahuan saya, banyak PhD dalam tim inti tersebut. Jadi marilah kita mampu memahami dan juga memanfaatkan.
Lecture note/buku ini ditujukan sebagai penunjang mata kuliah machine learning/pembelajaran mesin untuk mahasiswa tingkat sarjana di Indonesia. Seperti yang kita ketahui, kebanyakan buku perkuliahan berasal dari luar negeri. Konsumsi mahasiswa adalah buku dengan bahasa asing/terjemahan. Kadang kala, mahasiswa menganggap belajar dengan bahasa asing cukup sulit. Di lain pihak, (with all my respect) buku terjemahan terkadang kurang pas karena belum tentu maksud pengarang aslinya dapat diterjemahkan 100% oleh penerjemah, ke bahasa lainnya.
Untuk itu, pada masa luang saya, saya ingin berkontribusi pada pendidikan melalui lecture note ini (catatan kuliah saya). Lecture note/buku ini adalah ringkasan kuliah di universitas-universitas saya belajar yang disesuaikan penyampaiannya untuk tingkat pendidikan sarjana. Tentunya Lecture note/buku ini memiliki banyak kekurangan. Kritik dan saran akan sangat membantu pengembangan buku ini. Lecture note/buku ini tidak dapat dijadikan sebagai acuan utama pada perkuliahan
machine learning karena hanya bersifat sebagai pengantar. Tetapi, mudah-mudahan lecture note/buku ini dapat membantu proses belajar. Anggap saja sedang baca novel.
Disarankan pembaca mengerti/sudah mengambil kuliah tentang statistika, kalkulus, aljabar linier/geometri, pengenalan kecerdasan buatan (artificial intelligence). Hati-hati membedakan vektor (bold), dan bukan. Saat membaca buku ini, disarankan membaca dari bagian pendahuluan (jangan diabaikan ya). Gaya penulisan lecture note/buku ini diusahakan santai, mudah-mudahan melibatkan
cukup kuat untuk memahami materi. Terlalu banyak penjelasan matematis juga bisa membuat pusing beberapa orang. Istilah/jargon dalam lecture note/buku ini akan menggunakan bahasa Inggris. Saya sendiri sadar tentunya catatan ini tidak sempurna, kritik dan saran akan sangat dihargai (silahkan email).
Saya mengucapkan terima kasih yang sebesar-besarnya pada Bapak/Ibu/Saudara/i, karena telah memberikan masukan/semangat untuk penulisan buku ini. Mohon maaf apabila ada penulisan gelar yang salah.
1) I Gede Mahendra Darmawiguna, S.Kom., M.Sc. (Universitas Pendidikan Ganesha)S 2) Fabiola Maria, S.T. (Institut Teknologi Bandung)
3) Chairuni Aulia Nusapati, Erick Chandra, Joshua Beezaleel Abednego (Institut Teknologi Bandung)ah
Best Regards,
Jan Wira Gotama Putra
Email: gotama(dot)w(dot)aa(at)m(dot)titech(dot)ac(dot)jp https://icemerly.wordpress.com
Notasi
Pembelajaran mesin banyak mengadopsi teori statistika, akan tetapi notasi antar buku dapat berbeda-beda. Untuk buku ini, berikut adalah beberapa catatan notasi penting.
• P(x) adalah probabilitas x; “P” kapital.
• p(x) adalah probabilitas densitas (probability density function) x. “p” tidak kapital. • Tentang x (mengacu pada dua hal diatas) adalah random variable atau sampel, harap
disesuaikan dengan konteks. Secara umum, “x” atau “X” mengacu pada random variable/variable, xn (dengan indeks tertentu) mengacu pada sampel/suatu nilai random variable/event. Hal ini berlaku kecuali diberikan catatan khusus.
Daftar Isi
Tentang Catatan Ini ... 2
Notasi ... 4
1 Statistical Learning Theory ... 6
1.1 Apa itu Pembelajaran ... 6
1.2 Intelligent Agent ... 6
1.3 Konsep Statistical Machine Learning ... 7
1.4 Supervised Learning ... 9
1.5 Unsupervised Learning ... 11
1.6 Proses Belajar (Training) ... 12
1.7 Tipe Permasalahan di Dunia (debateable) ... 12
1.8 Tips Menjadi Master ... 13
1.9 Contoh Aplikasi... 13
2 Pengetahuan Dasar ... 14
2.1 Probabilitas ... 14
2.2 Probability Density Function ... 15
2.3 Expectations dan Variance ... 16
2.4 Probabilitas Bayesian ... 17
2.5 Probabilitas Gaussian ... 17
2.6 Teori Keputusan ... 21
2.7 Teori Informasi ... 22
2.7.1 Entropy ... 23
2.7.2 Relative Entropy dan Mutual Information ... 24
2.8 Bacaan Lanjutan ... 25
3 Curve Fitting, Error Function & Gradient Descent ... 26
3.1 Curve Fitting dan Error Function ... 26
3.2 Steepest Gradient Descent ... 28
3.3 Bacaan Lanjutan ... 30
4 Artificial Neural Network ... 31
4.1 Definisi ... 31
4.2 Single Perceptron ... 31
4.3 Multilayer Perceptron & Backpropagation ... 33
4.3.1 Binary Classification ... 36
4.3.2 Multi-label Classification ... 36
4.4 Deep Neural Network... 36
4.5 Recurrent Neural Network ... 38
4.6 Tips for Neural Network ... 40
4.7 Bacaan Lanjutan ... 41
Indeks ... 42
1
Statistical Learning Theory
Bab ini adalah bab paling penting pada lecture note ini, karena memuat ide paling utama tentang
machine learning.
1.1 Apa itu Pembelajaran
Bayangkan kamu berada di suatu negara asing, kamu tidak tahu norma yang ada di negara tersebut. Apa yang kamu lakukan agar bisa menjadi orang “normal” di tempat tersebut? Tentunya kamu harus belajar! Kemudian kamu mengamati bagaimana orang bertingkah laku di negara tersebut dan perlahan-lahan mengerti norma di tempat itu. Begitulah belajar. Belajar adalah berusaha memperoleh kepandaian atau ilmu; berlatih; berubah tingkah laku atau tanggapan yang disebabkan oleh pengalaman (KBBI, 2016). Pembelajaran adalah proses, cara, perbuatan atau menjadikan orang atau makhluk hidup belajar. Akan tetapi, pada kasus ini, yang diajarkan/yang belajar bukanlah makhluk hidup, tapi mesin.
1.2 Intelligent Agent
Sebuah agen cerdas (intelligent agent) memiliki empat macam dimensi(Russel and Norvig, 1995):
1) Acting Humanly
Pada dimensi ini, kita ingin agen mampu bertingkah sebagai manusia. Misalnya adalah agen yang mampu berinteraksi seperti manusia (baca: turing test).
2) Acting Rationally
Pada dimensi ini, kita ingin agen mampu bertingkat dengan optimal. Tindakan optimal belum tentu menyerupai tindakan manusia, karena tindakan manusia belum tentu optimal. Misalnya, agen yang mampu memilih rute terpendek dari suatu kota A ke kota B untuk mengoptimalkan penggunaan sumber daya. Apabila manusia, kita bisa basa memilih rute lain yang pemandangannya lebih indah.
3) Thinking Humanly
Pada dimensi ini, kita ingin proses berpikir agen, sama dengan proses berpikir manusia (secara kognitif).
4) Thinking Rationally
Pada dimensi ini, kita ingin proses berpikir agen rasional, sederhananya sesuai dengan konsep logika matematika.
Untuk mewujudkan interaksi manusia-komputer seperti manusia-manusia, tentunya kita ingin
intelligence agent bisa mewujudkan dimensi acting humanly, dan thinking humanly. Sayangnya, manusia tidak konsisten (Gratch and Marsella, 2014). Sampai saat ini konsep kecerdasan buatan adalah untuk meniru manusia; apabila manusia tidak konsisten, kita pun tidak dapat memodelkan cara berpikir/tingkah laku manusia ke dalam bentuk deterministik. Dengan hal itu, saat ini kita hanya mampu mengoptimalkan agen yang mempunyai dimensi acting rationally, dan thinking rationally.
Perhatikan Gambar 1.1. Agen mengumpulkan informasi dari lingkungannya, kemudian memberikan respons berupa aksi. Kita ingin agen melakukan aksi yang “benar”. Tentu saja kita perlu mendefinisikan secara detil, teliti, tepat (precise), apa maksud dari “aksi yang benar”. Dengan
demikian, lebih baik apabila kita mengukur kinerja agen, menggunakan performance measure. Misalnya untuk robot pembersih rumah, performance measure-nya adalah seberapa persen debu yang bisa ia bersihkan.
Gambar 1.1. Agent vs Environment (Khodra & Lestari, 2015).
Performance measure, secara matematis didefinisikan sebagai utility function, yaitu fungsi apa yang ingin dimaksimalkan oleh agen tersebut. Setiap tindakan yang dilakukan agen yang rasional, harus memaksimalkan performance measure atau utility function
1.3 Konsep Statistical Machine Learning
Pada masa sekarang ini data bertebaran sangat banyak dimana-mana. Pemrosesan data secara manual tentu adalah hal yang kurang bijaksana. Beberapa pemrosesan yang dilakukan, misal kategorisasi (kategorisasi teks berita), peringkasan dokumen, ekstraksi informasi (mencari 5W+1H pada teks berita), rekomendasi produk berdasarkan catatan transaksi, dll (Khodra & Lestari, 2015). Tujuan
machine learning minimal ada dua yaitu: memprediksi masa depan (unobserved); dan/atau memperoleh ilmu pengetahuan (knowledge discovery/discovering unknown structure). Untuk mencapai tujuan tersebut, kita menggunakan data (sampel), kemudian membuat model untuk menggeneralisasi “aturan” atau “pola” data, sehingga kita dapat menggunakannya untuk mendapatkan informasi/membuat keputusan (Bishop, 2006; Watanabe, 2016). Disebut statistical
karena basis pembelajarannya memanfaatkan data, juga menggunakan banyak teori statistik untuk melakukan inferensi (misal memprediksi unobservedevent). Jadi, statistical machine learning adalah cara untuk memprediksi masa depan dan/atau menyimpulkan/mendapatkan pengetahuan dari data secara rasional dan non-paranormal. Hal ini sesuai dengan konsep intelligent agent, yaitu bertingkah berdasarkan lingkungan. Dalam hal ini, lingkungannya adalah data.
Perhatikan Gambar 1.2 (permasalahan yang disederhanakan). Misalkan kamu diundang ke suatu pesta. Pada pesta tersebut ada 3 jenis kue yang disajikan. Kamu ingin mengetahui berapa rasio kue yang disajikan dibandingkan masing-masing jenisnya (seluruh populasi). Tapi kamu terlalu malas untuk menghitung semua kue yang ada. Karena itu, kamu mengambil beberapa sampel. Dari sampel tersebut, kamu mendapati bahwa ada 4 buah kue segi empat, 3 buah kue hati, dan 2 buah kue segitiga. Lalu
kamu menyimpulkan (model) bahwa perbandingan kuenya adalah 4:3:2 (segiempat:hati:segitiga). Perbandingan tersebut hampir menyerupai kenyataan seluruh kue yaitu 4:2,67:2. Tentu saja kondisi ini terlalu ideal.
Perhatikan Gambar 1.3, temanmu Ari datang juga ke pesta yang sama dan ingin melakukan hal yang sama (rasio kue). Kemudian ia mengambil beberapa sampel kue. Dari sampel tersebut ia mendapati bahwa ada 3 buah segiempat, 3 buah hati, dan 3 buah segitiga, sehingga perbandingannya adalah 3:3:3. Tentunya hal ini sangat melenceng dari populasi.
Dari kedua contoh tersebut, kita menyimpulkan, menginferensi (infer) atau mengeneralisasi sampel. Kesimpulan yang kita buat berdasarkan sampel tersebut, kita anggap merefleksikan populasi, kemudian kita menganggap populasi memiliki aturan/pola seperti kesimpulan yang telah kita ciptakan (Caffo, 2015). Baik pada statistika maupun statistical machine learning, pemilihan sampel (selanjutnya disebut training data) adalah hal yang sangat penting. Apabila training data tidak mampu melambangkan populasi, maka model yang dihasilkan pembelajaran (training) tidak bagus. Untuk itu, biasanya terdapat juga test data sebagai penyeimbang. Mesin dilatih menggunakan training data, kemudian diuji dengan test data. Seiring dengan membaca buku ini, konsep training data dan
test data akan menjadi lebih jelas.
Gambar 1.2. Ilustrasi Makanan Pesta 1.
Gambar 1.3. Ilustrasi Makanan Pesta 2.
Seperti halnya contoh sederhana ini, persoalan machine learning sesungguhnya menyerupai persoalan
statistical inference (Caffo, 2015). Kita berusaha mencari tahu populasi dengan cara menyelidiki
features (sifat-sifat) yang dimiliki oleh sampel. Kemudian, menginferensi unobserved data
1.4 Supervised Learning
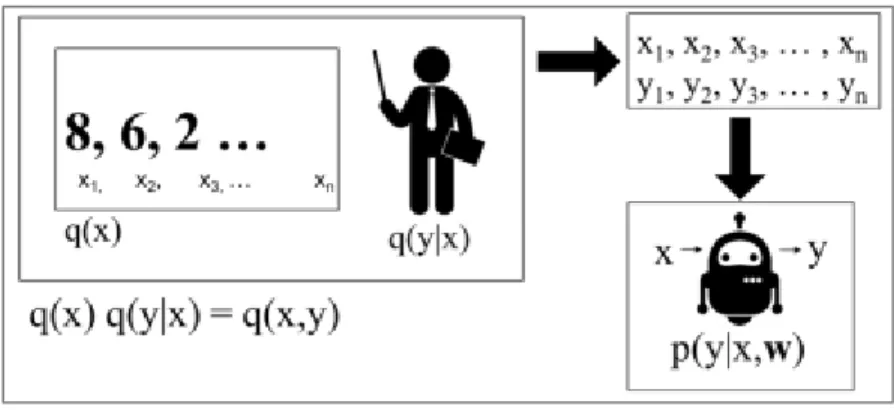
Jika diterjemahkan secara literal, supervised learning adalah pembalajaran terarah. Artinya, pada pembelajaran ini, ada guru yang mengajar, dan ada siswa yang diajar. Kita disini berperan sebagai guru, kemudian mesin berperan sebagai siswa. Perhatikan Gambar 1.4 sebagai ilustrasi! Pada Gambar 1.4 seorang guru menuliskan angka di papan “8, 6, 2” sebagai contoh untuk siswanya, kemudian gurunya memberikan cara membaca yang benar untuk masing-masing angka. Contoh angka melambangkan input, kemudian cara membaca melambangkan desired output. Pasangan input-desired output ini disebut sebagai training data (untuk kasus supervised learning). Perhatikan Gambar 1.5 dan Gambar 1.6! Kita akan masuk ke ilustrasi yang lebih matematis.
Gambar 1.4. Supervised Learning.
Gambar 1.6. Supervised Learning - Math Explained 2.
Perhatikan Gambar 1.5 dan Gambar 1.6. x adalah event, untuk event tertentu dapat dinotasikan sebagai {x1, x2, x3, ... , xn}. Seorang guru sudah mempunyai jawaban yang benar untuk masing-masing contoh dengan suatu fungsi distribusi probabilitas kondisional (conditional probability density function) q(y|x) baca: functionq for y given x. Hasilyang benar/diharapkan untuk suatu event. Siswanya (mesin) mempelajari tiap pasang pasangan input-desired output (training data) dengan suatu fungsi
conditional probability density function p(y|x,w), dimana y adalah target (output), x adalah input dan vector w adalah learning parameter. Proses belajar ini, yaitu mengoptimalkan w disebut sebagai
training.
Gambar 1.7. Supevised Learning Framework.
Perhatikan kembali Gambar 1.5 dan Gambar 1.6! Secara formal (supervised learning), information source dan guru direpresentasikan dengan q(x) dan q(y|x), kemudian learning machine p(y|x,w) dengan parameter vector w. Himpunan training data terdiri atas {(xi,yi); i=1,2,3,…,n} yang secara
independently subject to q(x)q(y|x). n disebut sebagai banyaknya training data (ruang sampel). Sebuah learning machine mengoptimasi parameter w sehingga p(y|x,w) dapat mengaproksimasi (approximates) q(y|x).
Perhatikan Gambar 1.7! q(x)q(y|x) = q(x,y) memiliki panah ke training data dan test data, artinya model hasil training sangat bergantung pada data dan guru. Model yang dihasilkan training (hasil pembelajaran – kemampuan siswa) untuk data yang sama bisa berbeda untuk guru yang berbeda.
𝑝(𝑦|𝑥, 𝒘)
Selain supervised learning, masih ada metode pembelajaran lainnya yaitu unsupervised learning, semi-supervised learning, dan reinforcement learning. Tetapi lecture note/buku ini berfokus pada pembahasan supervised learning dan unsupervised learning.
Tujuan supervised learning, secara umum untuk melakukan klasifikasi (classification). Misalkan mengklasifikasikan teks berita menjadi salah satu kategori {olah raga, politik, nasional, regional, hiburan, teknologi}. Apabila hanya ada dua kategori, disebut binary classification. Sedangkan bila terdapat lebih dari dua kategori, disebut multi-label classification. Ada tipe klasifikasi lain, tetapi
lecture note ini hanya akan membahas dua kategori tersebut.
1.5 Unsupervised Learning
Jika pada supevised learning ada guru yang mengajar, maka pada unsupevised learning tidak ada guru yang mengajar. Contoh permasalahan unsupervised learning adalah clustering. Misalnya kamu membuka sebuah toko serba ada, agar pelanggan mudah belanja, kamu mengelompokkan barang-barang, tetapi definisi “kelompoknya” belum ada. Yang kamu lakukan adalah membuat kelompok-kelompok berdasarkan karakteristik barang-barang.
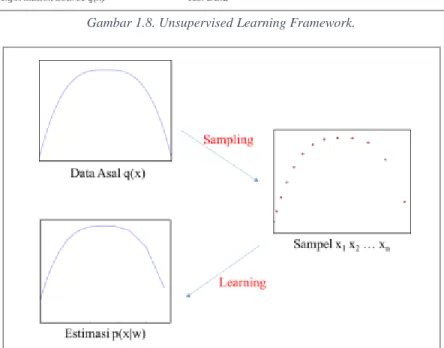
Gambar 1.8. Unsupervised Learning Framework.
Perhatikan Gambar 1.8 dan Gambar 1.9! Berbeda dengan supervised learning yang memiliki desired output, pada unsupervised learning tidak ada desired output (jelas, tidak ada gurunya). Populasi mempunyai distribusi q(x), kita ingin mengestimasi q(x) tersebut dengan mengambil beberapa sampel, lalu melakukan learning. Learning dilakukan dengan menggunakan p(x|w) yang mengoptimasi parameter w. Perbedaan antara estimasi dan fungsi asli disebut sebagai loss.
𝑝(𝑥|𝒘)
Persamaan 1.2. Learning Machine - Unsupervised Learning (Watanabe, 2016).
1.6 Proses Belajar (Training)
Seperti yang sudah dijelaskan pada sub bab sebelumnya, pada supervised maupun unsupervised learning, kita ingin mengestimasi sesuatu dengan teknik machine learning. Kinerja learning machine
berubah-ubah sesuai dengan parameter w (parameter belajar). Kinerja learning machine diukur oleh fungsi tujuan (utility function), yaitu mengoptimalkan nilai fungsi tertentu; misalnya meminimalkan nilai error, atau meminimalkan loss (dijelaskan kemudian). Secara intuitif, learning machine sama seperti manusia belajar. Kita awalnya membuat banyak kesalahan, tetapi kita mengetahui/diberi tahu mana yang benar. Untuk itu kita menyesuaikan diri secara perlahan agar menjadi benar (iteratif). Inilah yang juga dilakukan learning machine, yaitu mengubah-ubah parameter w untuk mengoptimalkan suatu fungsi tujuan.
Secara bahasa lebih matematis, kami beri contoh supervised learning. Kita mempunyai distribusi data asli q(y|x). Dari distribusi tersebut, kita diberikan beberapa sampel pasangan input-output z1,z2,z3,...zn; z={x,y}. Kita membuat learning machine p(y|x,w). Awalnya kita disodorkan x1, sehingga learning
machine mengestimasi fungsi asli dengan mengoptimalkan parameter w sesuai dengan data yang ada. Seiring berjalannya waktu, kita diberikan data observasi lainnya, sehingga learning machine semakin menyesuaikan dirinya terhadap observasi yang ada. Semakin lama, kita jadi makin percaya bahwa
learning machine semakin optimal (mampu memprediksi fungsi aslinya).
1.7 Tipe Permasalahan di Dunia (debateable)
Ada dua tipe permasalahan, yaitu klasifikasi dan konstruksi. Permasalahan klasifikasi adalah mengkategorikan sesuatu sesuai kelompok yang telah ditentukan sebelumnya. Contohnya klasifikasi buku di perpustakaan. Perpustakaan sudah menentukan kelompok-kelompok buku, misalnya teknik, sains, dan seni. Saat ada buku baru, perpustakaan nantinya menaruh buku pada tempat dengan kelompok bersesuaian. Contoh lainnya adalah klasifikasi makhluk hidup berdasarkan kingdom.
Jenis permasalahan kedua adalah konstruksi. Permasalahan konstruksi misalnya kita memiliki banyak buku di rumah, agar bukunya rapi kita ingin mengelompokkan buku-buku tersebut sesuai dengan kecocokan satu sama lain (clustering). Contoh lainnya adalah bagaimana cara menyusun kelompok/susunan/struktur kingdom makhkluk hidup (ontologi). Menurut pendapat saya, regresi dapat dikategorikan sebagai permasalahan konstruksi, karena harus membangun (menebak) suatu fungsi yang mampu memprediksi output.
1.8 Tips Menjadi Master
Jujur, saya sendiri belum master pada bidang ini, tetapi berdasarkan pengalaman pribadi (dan membaca), dan beberapa rekan; ada beberapa materi wajib yang harus dipahami untuk mengerti bidang machine learning. Sederhananya, kamu harus menguasai banyak teori matematika & probabilitas agar dapat mengerti machine learning sampai tulang dan jeroannya. Saya tidak menyebutkan bahwa mengerti machile learning secara intuitif (atau belajar dengan pendekatan deskriptif) itu buruk, tetapi untuk mengerti sampai dalam memang perlu mengerti matematikanya (menurut pengalaman saya). Disarankan untuk belajar materi berikut:
1) Matematika Diskrit & Teori Bilangan
2) Aljabar Linier & Geometri (vektor, matriks, skalar, decomposition, transformasi, tensor) 3) Calculus (diferensial & integral)
4) Optimasi (Lagrange Multiplier, Convex, Gradient Descent, Integer Linear Problem, dsb) 5) Probabilitas & Statistika (Probabilitas, Probability Densities, Hypothesis Testing, Inter-rater
agreement, Bayesian, Statistical Mechanics)
1.9 Contoh Aplikasi
Sebenarnya, aplikasi pemanfaatan machine learning sudah terasa dalam kehidupan sehari-hari. Contoh mudahnya adalah produk-produk Google, misalnya google translate (machine translation, handwritten recognition, speech recognition). Berikut adalah beberapa artikel berita menarik:
1) https://techcrunch.com/2016/03/15/google-ai-beats-go-world-champion-again-to-complete-historic-4-1-series-victory/
2) http://www-formal.stanford.edu/jmc/whatisai/node3.html 3) https://www.google.com/selfdrivingcar/
2
Pengetahuan Dasar
Mungkin saat pertama kali membaca bab ini, Anda merasa bab ini tidak masuk akal/kurang dibutuhkan. Seiring membaca buku ini, mungkin bab ini akan sering dikunjungi kembali. Bab ini hanyalah pengantar saja, tentunya untuk mengerti probabilitas, sebaiknya Anda mengambil kuliah khusus tentang materi itu. Karena Anda diharapkan sudah memiliki “cukup latar pengetahuan”, bab ini sebenarnya hanyalah sekilas pengingat. Sebenarnya kami agak ragu mau meletakkan bab ini sebagai bab 1 atau bab 2, tapi yasudahlah dibuat jadi bab 2 saja agar bab 1 tidak membosankan. Kami akan banyak memakai contoh-contoh dari buku Bishop (2006) untuk bab ini.
2.1 Probabilitas
Kita tahu bahwa banyak hal yang tidak pasti (uncertain), sebetulnya pada machine learning, kita juga berurusan dengan ketidakpastian (uncertainty). Dengan hal itu, machine learning memiliki kaitan yang sangat erat dengan statistika. Probabilitas menyediakan framework untuk kuantifikasi dan manipulasi ketidakpastian (Bishop, 2006). Mari kita lihat contoh sederhana, terdapat dua buah kotak berwarna merah dan berwarna biru. Pada kotak merah terdapat 3 apel dan 1 jeruk. Pada kotak biru, terdapat 2 apel dan 4 jeruk. Bila kita ingin mengambil buah dari salah satu kotak tersebut, dalam hal ini, kotak adalah random variable. Random variableb (melambangkan kotak) dapat bernilai merah, atau biru. Begitu pula dengan buah, dilambangkan dengan variabel f, dapat bernilai apel atau jeruk.
Saat kita mengambil buah dari kotak biru, peluang untuk memilih apel bernilai 2/6, sedangkan peluang untuk memilih jeruk bernilai 4/6; kita tulis probabilitas ini sebagai 𝑃(𝑓 = 𝑎𝑝𝑒𝑙) = 2/6; dan
𝑃(𝑓 = 𝑗𝑒𝑟𝑢𝑘) = 4/6. Nilai suatu probabilitas haruslah berada diantara [0,1]. Artinya, jika kita mengambil buah dari kotak biru, lebih banyak kejadian saat kita mendapat jeruk.
Lalu sekarang ada pertanyaan baru; pada suatu percobaan, berapakah probabilitas mengambil sebuah apel dari kotak biru, atau sebuah jeruk dari kotak merah. Hal ini dituliskan sebagai 𝑃((𝑏 = 𝑏𝑖𝑟𝑢, 𝑓 = 𝑎𝑝𝑒𝑙) 𝑎𝑡𝑎𝑢 (𝑏 = 𝑚𝑒𝑟𝑎ℎ, 𝑓 = 𝑗𝑒𝑟𝑢𝑘)). Nilai probabilitas tersebut dapat dihitung dengan
𝑃((𝑏 = 𝑏𝑖𝑟𝑢, 𝑓 = 𝑎𝑝𝑒𝑙) 𝑎𝑡𝑎𝑢 (𝑏 = 𝑚𝑒𝑟𝑎ℎ, 𝑓 = 𝑗𝑒𝑟𝑢𝑘)) = 𝑃(𝑏 = 𝑏𝑖𝑟𝑢, 𝑓 = 𝑎𝑝𝑒𝑙) + 𝑃(𝑏 = 𝑚𝑒𝑟𝑎ℎ, 𝑓 = 𝑗𝑒𝑟𝑢𝑘)
𝑃(𝑏 = 𝑏𝑖𝑟𝑢, 𝑓 = 𝑎𝑝𝑒𝑙)disebut joint probability, yaitu probabilitas untuk dua variabel.
𝑃(𝑏 = 𝑏𝑖𝑟𝑢, 𝑓 = 𝑎𝑝𝑒𝑙1) + 𝑃(𝑏 = 𝑚𝑒𝑟𝑎ℎ, 𝑓 = 𝑗𝑒𝑟𝑢𝑘) ini disebut sebagai sum rule (aturan tambah).
Misalkan terdapat percobaan lain, kali ini kamu mengambil 1 buah. Kamu ingin mengetahui berapakah probabilitas untuk mengambil buah apel kotak mana saja. Hal ini dihitung dengan
𝑃(𝑓 = 𝑎𝑝𝑒𝑙) = ∑ 𝑃(𝑓 = 𝑎𝑝𝑒𝑙, 𝑏 = 𝑏𝑘) 𝐾
𝑘=1
Kadang kala sum rule disebut marginal probability, karena hasilnya didapat dengan menjumlahkan probabilitas seluruh kemungkinan nilai pada variable tertentu, dengan mengontrol variable lainnya.
Kemudian, kamu ingin melakukan percobaan lain. Kali ini kamu mengambil 2 buah sekaligus dari kedua kotak. Kamu ingin mengetahui berapakah probabilitas mengambil buah apel yang berasal dari kotak biru; dan buah jeruk yang berasal dari kotak merah. Hal ini dihitung dengan
𝑃((𝑏 = 𝑏𝑖𝑟𝑢, 𝑓 = 𝑎𝑝𝑒𝑙), (𝑏 = 𝑚𝑒𝑟𝑎ℎ, 𝑓 = 𝑗𝑒𝑟𝑢𝑘)) = 𝑃(𝑏 = 𝑏𝑖𝑟𝑢, 𝑓 = 𝑎𝑝𝑒𝑙) ∗ 𝑃(𝑏 = 𝑚𝑒𝑟𝑎ℎ, 𝑓 = 𝑗𝑒𝑟𝑢𝑘)
Aturan ini disebut production rule (aturan kali). Perhatikan kembali 𝑃((𝑏 = 𝑏𝑖𝑟𝑢, 𝑓 = 𝑎𝑝𝑒𝑙), (𝑏 = 𝑚𝑒𝑟𝑎ℎ, 𝑓 = 𝑗𝑒𝑟𝑢𝑘)) adalah bentuk joint probability. Kita dapat tulis kembali sebagai 𝑃(𝑋, 𝑌), apabila X dan Y independent maka 𝑃(𝑋, 𝑌) = 𝑃(𝑋) ∗ 𝑃(𝑌). Dalam kasus ini, kita kejadiannya adalah saling lepas, artinya mengambil bola dari kotak biru, pada saat yang bersamaan tidak akan mempengaruhi hasil pengambilan kotak merah. Sebaliknya, apabila X tidak saling lepas Y, maka keduanya disebut dependent. Artinya X dan Y saling mempengaruhi.
Apabila suatu variabel (X) dikondisikan (conditioned) oleh variabel lain (misal Y). Maka probabilitas X adalah conditional probability function, ditulis 𝑃(𝑋|𝑌). Artinya probabilitas x yang dikondisikan oleh Y. Apabila X ternyata tidak dikondisikan oleh variabel Y, maka P(X|Y) = P(X). Contoh kasus ini adalah gempa bumi, tidak dikondisikan oleh kegiatan menabung.
2.2 Probability Density Function
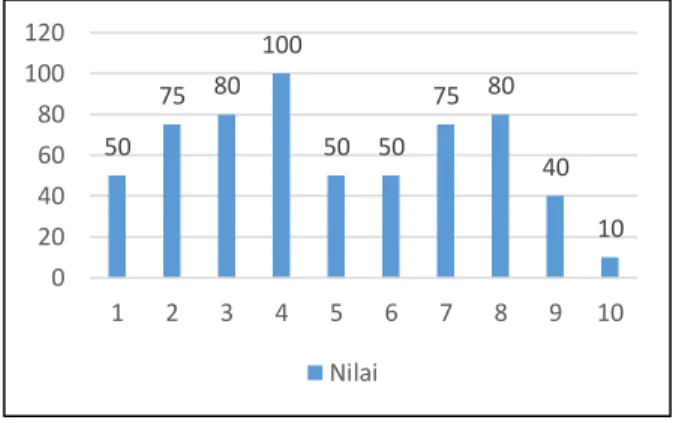
Kali ini tentang pelajaran di sekolah. Terdapat ujian mata pelajaran di kelas yang beranggotakan N siswa. Guru ingin mengetahui persebaran (distribusi/distribution) nilai ujian untuk menentukan batas kelas nilai (misal nilai “A” adalah >=85), jadi ia membuat grafik nilai ujian untuk tiap-tiap siswa. Sebut saja variabel nilai siswa adalah X. Sumbu horizontal menandakan nomor urut siswa.
Grafik 2.1. Nilai Siswa.
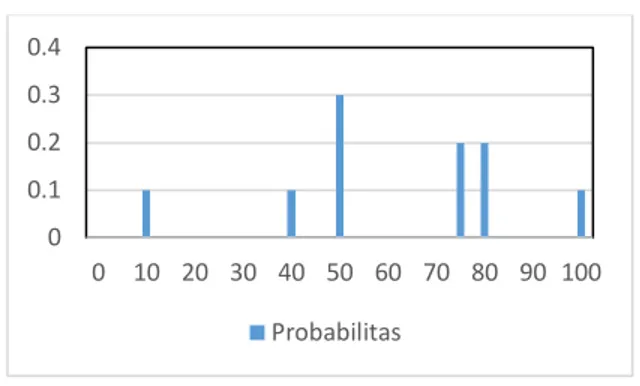
Perhatikan Grafik 2.1. Terdapat 3 orang anak mendapatkan nilai 50, 2 orang anak mendapat nilai 75 dan 80, 1 orang anak mendapat nilai 100, 1 orang anak mendapat nilai 40, serta 1 orang anak mendapat nilai 10. Grafik probabilitas nilai dapat dilihat pada Grafik 2.2.
50 75 80 100 50 50 75 80 40 10 0 20 40 60 80 100 120 1 2 3 4 5 6 7 8 9 10 Nilai
Grafik 2.2. Grafik Probabilitas Nilai Ujian.
Ini adalah contoh untuk data diskrit, tetapi sering kali kita berurusan dengan data kontinu. Untuk mengetahui nilai probabilitas dari himpunan event/kejadian, kita dapat mengintegralkan kurva distribusi kejadian pada interval tertentu. Nilai dibawah kurva pada interval −∞ sampai ∞ adalah 1. 2.3 Expectations dan Variance
Salah satu operasi paling penting dalam probabilitas adalah menemukan nilai rata-rata terbobot (weighted average) sebuah fungsi (Bishop, 2006). Hal ini disebut menghitung ekspektasi (expectation). Untuk sebuah fungsi f(x) berdasar distribusi probabilitas p(x), nilai expectation adalah
𝐸(𝑓) {
∑ 𝑝(𝑥)𝑓(𝑥); 𝑑𝑖𝑠𝑘𝑟𝑖𝑡
𝑥
∫ 𝑝(𝑥)𝑓(𝑥)𝑑𝑥; 𝑘𝑜𝑛𝑡𝑖𝑛𝑢
Dalam kasus nyata, misalkan diberikan N buah sampel x dan f(x), dimana sampel tersebut diambil dengan distribusi tertentu, maka fungsi untuk menghitung nilai expectation menjadi
𝐸(𝑓) ≅1
𝑁 ∑ 𝑓(𝑥𝑖)
𝑁
𝑖=1
Persamaan 2.2. Expectation.
Perhatikan, persamaan tersebut sama dengan persamaan untuk menghitung rata-rata(𝑚𝑒𝑎𝑛 / 𝜇)
seperti yang sudah Anda pelajari di SMA. Untuk mengetahui seberapa variabilitas (perbeda-bedaan nilai) pada f(x) di sekitar nilai rata-ratanya, kita menghitungnya mengunakan variance, disimbolkan dengan var[f] atau 𝜎2
.
𝑣𝑎𝑟[𝑓] = 𝐸(𝑓(𝑥) − 𝐸[𝑓(𝑥)]2)
Ekspresi tersebut juga dapat ditulis sebagai
𝑣𝑎𝑟[𝑓] = 𝐸[𝑓(𝑥)]2− 𝐸(𝑓(𝑥)2
Bila nilai variance tinggi, secara umum banyak variabel yang nilainya jauh dari nilai rata-rata. Interpretasi geometrisnya dari sisi distribusi, kurnya semakin “lebar”. Untuk fungsi dengan parameter
0 0.1 0.2 0.3 0.4 0 10 20 30 40 50 60 70 80 90 100 Probabilitas
lebih dari satu variabel, misal f(x,y) kita menghitung covariance (untuk lebih dari satu variabel).
Covariance adalah variance untuk random variable berdimensi lebih dari satu. Covariance adalah cara untuk menghitung tingkat korelasi (Wolfram, 2016)
2.4 Probabilitas Bayesian
Dalam sub bab sebelumnya, kita menghitung probabilitas dengan frekuensi kejadian yang dapat diulang. Pada pandangan Bayesian, kita ingin menguantifikasi ketidakpastian. Misalkan kita ingin tahu, seberapa peluang Mars dapat dihuni. Ini adalah sesuatu yang tidak dapat dihitung dengan frekuensi, maupun sebuah kejadian yang dapat diulangi (pergi ke mars, lihat berapa orang yang hidup). Akan tetapi, tentunya kita memiliki sebuah asumsi awal (prior). Dengan sebuah alat canggih yang baru, kita dapat mengumpulkan data baru tentang Mars. Dengan data tersebut, kita mengoreksi pendapat kita tentang Mars (posterior). Hal ini menyebabkan perubahan dalam pengambilan keputusan.
Pada keadaan ini, kita ingin mampu menguantifikasi ekspresi ketidakpastian; dan membuat revisi tentang ketidakpastian menggunakan bukti baru (Bishop, 2006). Dalam Bayesian, nilai numerik digunakan untuk merepresentasikan derajat kepercayaan/ketidakpastian.
𝑃(𝐴|𝐵) = 𝑃(𝐵|𝐴)𝑃(𝐴) 𝑃(𝐵)
Persamaan 2.3. Probabilitas Bayesian.
𝑃(𝐴) disebut prior, yaitu pengetahuan/asumsi awal kita. Setelah kita mengobservasi data B, kita mengubah asumsi kita. 𝑃(𝐵|𝐴) disebut likelihood function. Likelihood function mendeskripsikan peluang data, untuk asumsi/pengetahuan tentang A yang berubah-ubah (A sebagai parameter yang dapat diatur). Dengan likelihood function tersebut, kita mengoreksi pendapat akhir kita yang nantinya digunakan untuk mengambil keputusan (posterior).
𝑝𝑜𝑠𝑡𝑒𝑟𝑖𝑜𝑟 ∝ 𝑙𝑖𝑘𝑒𝑙𝑖ℎ𝑜𝑜𝑑 ∗ 𝑝𝑟𝑖𝑜𝑟
Pada umumnya, untuk mengestimasi likelihood, digunakan maximum likelihood estimator; yang berarti mengatur nilai A untuk memaksimalkan nilai 𝑃(𝐵|𝐴). Dalam literatur machine elearning, banyak menggunakan negative log of likelihood function (Bishop, 2006); karena nilai logaritma negatif, secara monotonik menurun, maka memaksimalkan nilai likelihood ekuivalen dengan meminimalkan negatifnya (contoh nyata akan diberikan pada sub bab berikutnya).
Perhatikan kembali Persamaan 2.3, secara intuitif, posterior dipengaruhi prior, artinya bergantung pada sampel yang kita punya. Hal ini berlaku pada machine learning, kualitas model yang dihasilkan bergantung pada kualitas training data.
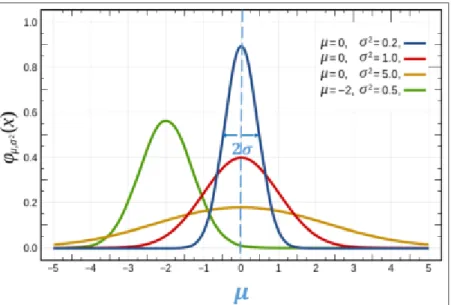
2.5 Probabilitas Gaussian
Anda harusnya sudah mengetahui distribusi ini. Ini adalah distribusi yang sangat terkenal yaitu bell curve/distribusi normal. Distribusi normal adalah bentuk khusus dari Gaussian distribution. Ada beberapa macam distribusi yang akan dibahas pada bab ini, yaitu: univariate Gaussian, multivariate
Gaussian, dan Gaussian mixture model. Pertama kita bahas univariate Gaussian terlebih dahulu. Disebut univariate karena distribusinya bergantung pada satuvariable skalar. Dalam hal ini adalah x. Distribusi sebenarnya adalah fenomena random atau deskripsi matematis suatu random variable. Berikut adalah formula distribusi univariateGaussian dikarakteristikkan oleh mean (𝜇)dan variance
(𝜎2
)
𝑁(𝑥|𝜇, 𝜎2) = 1
√2𝜋𝜎2exp (−
(𝑥 − 𝜇)2
2𝜎2 )
Persamaan 2.4. Univariate Gaussian (Bishop, 2006)
Gambar 2.1. Distribusi Univariate Gaussian
(https://upload.wikimedia.org/wikipedia/commons/thumb/7/74/Normal_Distribution_PDF.svg/720px-Normal_Distribution_PDF.svg.png)
Perhatikan Gambar 2.1, nilai N (Persamaan 2.4) adalah ordinat pada kurva ini. Bentuk distribusi berubah-ubah sesuai dengan nilai rata-rata (mean), serta variance. Semakin besar variance-nya, maka kurva distribusi semakin lebar (seperti yang dijelaskan pada sub bab sebelumnya). Untuk menggeser-geser kurva ke kiri maupun ke kanan, dapat dilakukan dengan mengmenggeser-geser nilai mean. Untuk mencari nilai pada suatu interval tertentu, cukup mengintegralkan fungsi pada interval tersebut. Nilai integral fungsi dari minus tak hingga, hingga tak hingga adalah satu.
∫
𝑁(
𝑥|
𝜇, 𝜎2)
𝑑𝑥∞
−∞
= 1
Sekarang bayangkan kita diberikan N buah data hasil observasi. Diasumsikan observasi dihasilkan oleh distribusi univariate Gaussian dengan rata-rata 𝜇 dan variance𝜎2.
Setiap data diambil secara independen dari distribusi yang sama, disebut independent and identically
distributed. Kita tahu bahwa data yang idependen, apabila dihitung probabilitasnya maka tersusun
atas probabilitas masing-masing data. Artinya,
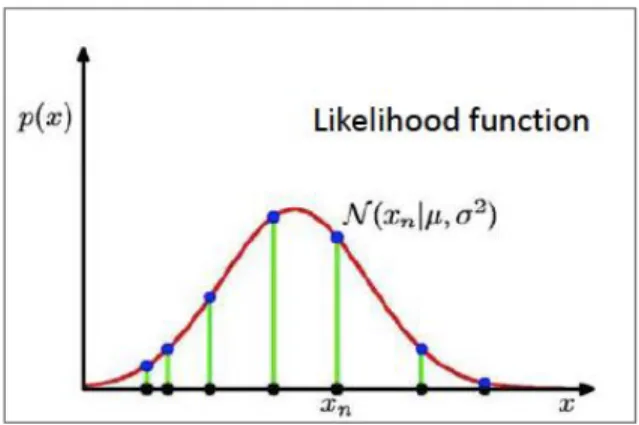
𝑝(𝒙|𝜇, 𝜎2) = ∏ 𝑁(𝑥|𝜇, 𝜎2) 𝑁
𝑖=1
x (bold) adalah himpunan data (observasi). Apabila dipandang dari sisi mean dan variance, p sebenarnya adalah fungsi likelihood (likelihood function) (Bishop, 2006).
Gambar 2.2. Ilustrasi likelihood function (Bishop, 2006)
Kita ingin mencari tahu bagaimana distribusi Gaussian yang sebenarnya. Untuk itu, kita ingin memaksimalkan fungsi likelihood; agar prior berubah menjadi posterior (fungsi Gaussian yang sebenarnya). Ini disebut maximum likelihood estimation Ingat kembali sub bab sebelumnya (Bayesian)! Sayangnya hal ini agak sulit dilakukan, malah sebaliknya, kita memaksimalkan log likelihood function berdasarkan data yang kita miliki. Logaritma secara monotonik akan bertambah nilainya, dan memaksimalkan fungsi logaritma sebanding dengan meminimalkan error, bentuknya seperti pada persamaan matematis berikut (dipakai logiritma bilangan natural)
ln 𝑝(𝒙|𝜇, 𝜎2) = − 1 2𝜎2∑(𝑥𝑖− 𝜇) 2 𝑁 𝑖=1 −𝑁 2ln 𝜎 2−𝑁 2ln 2𝜋
Solusi persamaan tersebut adalah
𝜇 = 1 𝑁∑ 𝑥𝑖 𝑁 𝑖=1 ; 𝜎2= 1 𝑁∑(𝑥𝑖− 𝜇) 2 𝑁 𝑖=1
Perhatikan baik baik interpretasi berikut! Artinya kita dapat mengestimasi distribusi asli menggunakan sampel data yang kita miliki. Mean distribusi asli diestimasi dengan mean sampel.
Variance distribusi asli diestimasi dengan variance sampel. Inilah jantung machine learning! Masih ingat materi bab 1? Pada machine learning, kita mengestimasi sesuatu yang kita tidak ketahui, dengan sampel data yang kita miliki. Proses estimasi akan dibahas lebih lanjut pada bab 3.
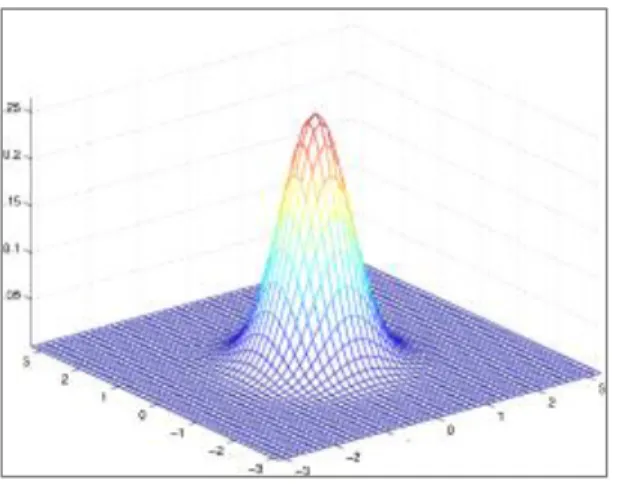
Lanjut ke topik berikutnya. Multivariate Gaussian adalah distribusi Gaussian untuk suatu random variable non-skalar (vektor/mempunyai dimensi). Berikut adalah fungsinya
𝑁(𝒙|𝝁, Σ) = 1 2𝜋𝐷2Σ12
exp (−1 2(𝑥 − 𝜇)
𝑇Σ−1(𝑥 − 𝜇))
Persamaan 2.5. Multivariate Gaussian (Jurafsky & Martin, 2009).
Perhatikan! x dan 𝝁(di-bold) adalah vektor. Σ adalah covariance (matriks). Untuk multivariate Gaussian, silahkan kamu membaca lebih lanjut sendiri. Untuk vektor berdimensi 2, multivariate Gaussian diilustrasikan pada Gambar 2.3.
Gambar 2.3. Multivariate Gaussian
(http://archive.cnx.org/resources/4e9f9a101e73795705f86b26f6f9bfefc9e67e10/gaussian_0.6_0_0.6.png)
Sedangkan Gaussian Mixture Model (GMM) adalah gabungan dari satu atau lebih distribusi Gaussian
(bisa univariate maupun multivariate). Secara umum, bentuknya sebagai pada persamaan berikut
𝑁(𝑥|𝜇, Σ) = ∑ 𝑐𝑖 1 √2𝜋|Σ|exp [(𝑥 − 𝜇𝑖) 𝑇Σ−1(𝑥 − 𝜇 𝑖)] 𝑀 𝑖=1
ci adalah konstanta, artinya setiap distribusi Gaussian diberikan bobot. Konon katanya, GMM dapat memodelkan fungsi apapun (Jurafsky & Martin, 2009). Ilustrasinya seperti pada Gambar 2.4. Pada gambar tersebut, fungsi asli berwarna merah, fungsi tersebut diestimasi menggunakan mixture dari 3 buah univariate Gaussian (biru).
Gambar 2.4. Gaussian Mixture Model
(http://dirichletprocess.weebly.com/uploads/1/9/8/4/19847957/3346416.png?1367446693)
2.6 Teori Keputusan
Diberikan himpunan pasangan data input-output {(xi,yi)}; x=input, y=output/target; walaupun tidak pasti, kita ingin mengestimasi hubungan antara input dan output. Untuk itu kita melakukan estimasi p(x|y,w). Pada bab pertama, kamu telah mempelajari bahwa kita mampu melakukan hal ini dengan teknik machine learning. Selangkah lebih jauh, kita juga harus mampu untuk membuat keputusan berbasiskan perkiraan nilai y, aspek ini adalah decision theory (Bishop, 2006).
Dalam machine learning kita dapat membangun model untuk dua tujuan: meminimalkan error, atau meminimalkan loss; konsep meminimalkan error dijelaskan pada bab curve fitting. Ibratnya untuk sebuah robot, kita ingin robot tersebut tidak melakukan tindakan yang salah. Tetapi, kadang kala meminimalkan error belum tentu membuat model menjadi “bagus”. Kami ilustrasikan menggunakan
contoh dari Bishop (2006).
Misalkan kita diminta untuk membuat model klasifikasi kanker. Kita dapat mengklasifikasikan pasien menjadi dua kelas C = {C1,C2}. C1 = kanker, C2 = normal.
Apabila kita ingin meminimalkan error, maka kita ingin mengklasifikasikan secara tepat orang yang kanker dianggap memiliki kanker, dan yang tidak dianggap sebagai tidak. Akan tetapi, terdapat
tradeoff yang berbeda saat salah klasifikasi. Apabila kita mengklasifikasikan orang yang normal sebagai kanker, konseuensi yang mungkin adalah membuat pasien menjadi stres, atau perlu melakukan pemeriksaan ulang. Tetapi bayangkan, apabila kita mengklasifikasikan orang kanker sebagai normal, konsekuensinya adalah penanganan medis yang salah. Tentunya kedua kasus ini memiliki beban yang berbeda. Secara formal, kasus ini disebut loss. Fungsi tujuan pembelajaran (secara umum untuk merepresentasikan error atau loss) disebut utility function. Sekali lagi kami tekankan, tujuan machine learning adalah memaksimalkan performance. Performance diukur berdasarkan utility function (Bishop, 2006; Russel and Norvig, 1995).
Tabel 2.1. Penalti Klasifikasi Kanker (Bishop, 2006) Kanker Normal
Kanker 0 1000
Tujuan machine learning, selain meminimalkan error, dapat juga untuk meminimalkan loss. Misalkan kita berikan penalti untuk kasus diatas seperti pada Tabel 2.1. Apabila kita mengklasifikasikan orang kanker sebagai orang kanker, maka tidak ada penalti. Apabila kita mengklasifikasikan orang normal sebagai kanker maka diberikan penalti sebesar 1. Apabila kita mengklasifikasikan orang kanker sebagai normal, maka penaltinya 1000.
Untuk mengukur nilai loss; dapat diekspresikan dengan loss function. Secara umum, ada dua macam
loss, yaitu: generalization loss/error, dan training loss/error. Generalization loss/error adalah ukuran sebagaimana algoritma mampu memprediksi unobserved data dengan tepat, karena kita hanya membangun model dengan data yang terbatas, tentunya bisa saja terdapat ketidakcocokan dengan data yang asli. Sedangkan training loss/error seperti namanya, ukuran loss saat training. Misalkan q(x) adalah distribusi data asli. Menggunakan sampel data dengan distribusi p(x). Maka
generalization loss dan trainingloss seperti yang didefinisikan pada Persamaan 2.6 dan Persamaan 2.7.
𝐺 = ∫ 𝑞(𝑥) log 𝑝(𝑥)𝑑𝑥
Persamaan 2.6. Generalization Loss.
𝑇 = 1
𝑁∑ log 𝑝(𝑥)
𝑁
𝑖=1
Persamaan 2.7. Training Loss.
Tentunya sekarang kamu bertanya-tanya. Kita tidak mengetahui bagaimana q(x) aslinya, bagaimana cara menghitung generalization loss? Nah, untuk itulah ada teknik-teknik aproksimasi distribusi asli q(x), misalnya maximimum likelihood method, maximum posterior method, Bayesian method
(silahkan dieksplorasi).
Secara lebih filosofis, berkaitan dengan meminimalkan loss; tugas machine learning adalah untuk menemukan struktur tersembunyi (discover hidden structure). Hal ini sangat erat kaitannya dengan
knowledge discovery, dan data mining. Bila Anda membuka forum di internet, kebanyakan akan membahas perihal learning machine yang memaksimalkan akurasi (meminimalkan error).
2.7 Teori Informasi
Kami tidak akan membahas bagian ini terlalu detil, jika kamu membaca buku, topik ini sendiri bisa mencapai satu buku (baca Cover & Thomas, 1991). Mudah-mudahan bab ini dapat memberikan gambaran (serius, ini sekedar gambaran!). Information Theory menjawab dua pertanyaan fundamental, pertama: bagaimana cara kompresi data terbaik (jawab: entropy); kedua: apakah cara transimisi komunikasi terbaik (jawab: channel capacity) (Cover & Thomas, 1991). Dalam statistical learning theory, fokus utama adalah menjawab pertanyaan pertama, yaitu bagaimana melakukan kompresi. Contoh aplikasi entropy adalah decision tree learning.
Pada machine learning, kita ingin features pembelajaran yang digunakan mampu melambangkan
information source properties. Artinya, kita ingin memilih features yang memuat informasi terbanyak (relatif terhadap information source). Karena hal tersebut, mengerti entropy menjadi penting. Ada
bentuk training data dengan semua kemungkinan features, kemudian mengambil beberapa features
yang dekat dengan root. Hal tersebut dimaksudkan untuk mencari features yang memuat banyak informasi. Kemudian, features tersebut dapat dicoba pada algorithma learning lainnya.
2.7.1 Entropy
Diberikan sebuah random variable x, kita ingin mengetahui seberapa banyak informasi yang kita dapatkan ketika kita mengobservasi sebuah nilai spesifik x. Kuantitas informasi yang kita dapatkan bisa dipandang sebagai “degree of surprise” (Bishop, 2006). Misalkan kita mengetahu seorang teman
A sering makan es krim. Suatu ketika kita diberitahu bahwa dia sedang makan es krim, tentu kita tidak heran lagi karena hal tersebut sudah lumrah. Tetapi, apabila kita diberitahu bahwa teman A tidak memakan es krim yang diberikan teman B (padahal kita tahu dia suka), maka akan ada efek “kaget”. Kasus kedua memuat lebih banyak informasi karena suatu kejadian yang seharusnya tidak mungkin, terjadi. Persamaan 2.8 adalah rumus entropy oleh Shannon untuk data diskrit, sedangkan Persamaan 2.9 untuk data kontinu. Rumus ini banyak digunakan pada information processing)
𝑆(𝑥) ≅ − ∑ 𝑝(𝑥𝑖) log 𝑝(𝑥𝑖); 𝑁 = 𝑛𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑡𝑟𝑎𝑖𝑛𝑖𝑛𝑔 𝑑𝑎𝑡𝑎 𝑁
𝑖=1
Persamaan 2.8. Entropy – Shannon Entropy (Cover & Thomas, 1991).
𝑆(𝑥) = − ∫ 𝑝(𝑥) log 𝑝(𝑥)𝑑𝑥
Persamaan 2.9. Entropy - Data Kontinu (Bishop, 2006).
Mari kita ambil contoh dari Bishop (2006). Misalkan sebuah random variable x memiliki 8 kemungkinan event yang kemungkinannya sama (yaitu 1/8). Entropy untuk kasus ini adalah (log dalam basis 2)
𝑆 = −8 × 1 8log (
1 8) = 3
Sekarang kita ambil contoh dari Cover dan Thomas (1991). Misalkan sebuah random variable x memiliki 8 kemungkinan event {a,b,c,d,...,h} dengan peluang {12,1
4, 1 8, 1 16, 1 64, 1 64, 1 64, 1 64} . Entropy-nya
adalah (log dalam basis 2)
𝑆 = −1 2log ( 1 2) − 1 4log ( 1 4) − 1 8log ( 1 8) − 1 16log ( 1 16) − 4 64log ( 1 64) = 2
Dari contoh ini, kita tahu bahwa distribusi yang tidak uniform, memiliki entropy yang lebih besar dibanding distribusi yang uniform. Dari sisi information transmission, dapat diinterpretasikan kita dapat mengirimkan data sebuah distribusi dengan jumlah bit lebih sedikit. Distribusi yang memberikan nilai entropy maksimal adalah distribusi Gaussian (Bishop, 2006). Nilai entropy bertambah seiring variance distribusi bertambah. Dari sisi fisika, Anda dapat mempelajari entropy pada statistical mechanics (microstate, macrostate).
2.7.2 Relative Entropy dan Mutual Information
Gambar 2.5. Information Source vs Learning Machine.
Perhatikan Gambar 2.5! Kami harap Anda masih ingat materi bab 1, karena materi bagian ini juga menyinggung kembali materi bab 1. Misalkan kita mempunyai data dengan probability density function q(x). Sebuah learning machinemengaproksimasi data tersebut dengan probability density function p(x). Ingat! Learning machine adalah aproksimasi. Ketika kita melakukan aproksimasi, seringkali aproksimasi yang dilakukan tidaklah tepat. Tentunya kita ingin tahu seberapa bagus aproksimasi kita, untuk mengukurnya terdapat sebuah perhitungan yang bernama Kullback-Leibler Divergence (KL-divergence). Secara konseptual, dirumuskan sebagai Persamaan 2.10. Dari sisi
information processing, KL-divergence dapat diinterpretasikan sebagai berapa informasi tambahan rata-rata untuk mengirimkan data distribusi dengan menggunakan fungsi aproksimasi, dibanding menggunakan distribusi sebenarnya.
𝐾𝐿(𝑞||𝑝) = − ∫ 𝑞(𝑥) log𝑞(𝑥) 𝑝(𝑥) 𝑑(𝑥)
Persamaan 2.10. Kullback-Leibler Divergence (Bishop, 2006).
KL-divergence disebut juga sebagai relative entropy. Tentunya, persamaan tersebut dapat diminimalkan jika dan hanya jika q(x) = p(x). Kita dapat menganggap KL-divergence sebagai ukuran seberapa jauh aproksimasi terhadap distribusi asli. Akan tetapi, kita tidak mengetahui q(x). Karena itu, kita dapat mengaproksimasi KL-Divergence. Misalkan kita diberikan training data x1,x2,...xn yang kita asumsikan diambil dari q(x). Lalu kita membuat learning machine p(x|w). Ekspektasi terhadap q(x) dapat diaproksimasi dengan menggunakan data sampel ini, sehingga menjadi persamaan berikut (Bishop, 2006) 𝐾𝐿(𝑞||𝑝) ≅ 1 𝑁∑{− log 𝑝(𝑥𝑛|𝒘) 𝑁 𝑛=1 + log 𝑞(𝑥𝑛)}
Ingat kembali p(x|w) adalah bentuk likelihood. Kita dapat interpretasikan hasil ini; meminimalkan
KL-divergence sama dengan memaksimalkan nilai likelihood.
Misalkan terdapat joint probability distribution p(x,y). Apabila x dan y independen, maka p(x,y) = p(x)p(y). Kita dapat mencari tahu apakah mereka cukup “dependent” dengan menggunakan KL-divergence
𝐼[𝑥, 𝑦] ≡ 𝐾𝐿(𝑝(𝑥, 𝑦)||𝑝(𝑥)𝑝(𝑦)) = − ∫ ∫ 𝑝(𝑥, 𝑦) ln (𝑝(𝑥)𝑝(𝑦) 𝑝(𝑥, 𝑦) ) 𝑑𝑥𝑑𝑦
I[x,y] disebut mutual information. I[x,y] = S[x] – S[x|y] = S[y] – S[y|x]; S adalah entropy. Mutual information dapat dipandang sebagai pengurangan ketidakyakinan terhadap posterior, seiring diberikannya data observasi yang baru. Seiring diberikannya ada observasi yang baru, kita semakin yakin terhadap posterior.
2.8 Bacaan Lanjutan
1) Caffo, Brian. 2015. Statistical Inference for Data Science. Learn Publishing.
2) Freedman, David, Pisani, Robert & Purves, Roger. 2007. Statistics Fourth Edition. New York: W.W. Norton & Company, Inc.
3) Nishimori, Hidetoshi. 2001. Statistical Physics of Spin Glasses and Information Processing: An Introduction. Oxford: Clarendon Press.
4) Walpole, Ronald E., Myers, Raymond H., Myres, Sharon L, and Ya, Keying. 2012. Probability & Statistics for Engineers & Scientists. New Jersey: Prentice Hall.
3
Curve Fitting, Error Function & Gradient Descent
Bab ini akan membahas tentang curve fitting problem (regresi), sebagai contoh pembelajaran yang sederhana karena cukup mudah dipahami idenya. Bab ini juga membahas error function yang merupakan salah satu utility function dalam machine learning. Gradient Descent dapat diterapkan pada proses pembelajaran untuk mencapai konfigurasi model yang optimal.3.1 Curve Fitting dan Error Function
Masih ingat contoh bab sebelumnya tentang estimasi distribusi univariate Gaussian? Ingat kembali konsep tersebut untuk mengerti bab ini. Diberikan (x,y) sebagai random variable berdimensi RM dan RN (keduanya adalah Euclidiean Space), which is subject to a simultaneous probability density
function q(x,y). Terdapat sebuah fungsi f(x) ⟶ y, yang memetakan x ke y. Approksimasi f(x), sebut saja sebagai g(x) adalah fungsi hasil regresi. Fungsi regresi g: RM⟶ RN didefinisikan secara konseptual sebagai Persamaan 3.1.
𝑔(𝑥) = ∫ 𝑦 𝑞(𝑦|𝑥)𝑑𝑦
Persamaan 3.1. Bentuk Konseptual Regresi (Watanabe, 2016).
Persamaan 3.1 dibaca sebagai expectation of y, with the distribution of q. Secara statistik, regresi dapat disebut sebagai expectation untuk y berdasarkan/dengan input x. Regresi adalah approksimasi, dan approksimasi belum tentu 100% tepat sasaran. (Ingat kembali bab sebelumnya!)
Sebagai ilustrasi curve fitting problem, kamu diberikan fungsi f(a) seperti pada gambar 3.1. sekarang fungsi f(a) tersebut disembunyikan (tidak diketahui), diberikan contoh-contoh pasangan (ai,bi); i=1,2,…,6 adalah titik pada dua dimensi (titik sampel), seperti tanda bulat warna biru. Tugasmu adalah untuk menentukan f(a)!
Gambar 3.2 Fungsi Approksimasi.
Anggap metode regresi, kamu berhasil melakukan approksimasi dan menghasilkan fungsi seperti gambar 3.2 (garis berwarna hijau). Akan tetapi, fungsi approksimasi ini tidak 100% tepat sesuai dengan fungsi aslinya (ini perlu sangat ditekankan). Jarak antara titik biru terhadap garis hijau disebut error.
Salah satu cara menghitung error fungsi g(x) menggunakan square error function dengan bentuk konseptual pada Persamaan 3.2. Estimasi terhadap persamaan tersebut disajikan dalam bentuk diskrit pada persamaan 3.3. {(xi, yi); i=1,2,3,…,n} adalah himpunan training data. Nilai square error menjadi tolak ukur untuk membandingkan kinerja suatu learning machine. Secara umum, bila nilainya tinggi, maka kinerja relatif dianggap buruk; sebaliknya bila rendah, kinerja relatif dianggap baik. Hal ini sesuai dengan konsep intelligent agent (Russel and Norvig, 1995).
𝐸(𝑔) = ∫ ∫‖𝑦 − 𝑔(𝑥)‖2 𝑞(𝑥, 𝑦)𝑑𝑥𝑑𝑦
Persamaan 3.2. Square Error Function (Watanabe, 2016).
𝐸(𝒘) = ∑‖𝑦𝑖− 𝑔(𝑥𝑖, 𝒘)‖2 𝑛
𝑖=1
; 𝒘 = 𝑙𝑒𝑎𝑟𝑛𝑖𝑛𝑔 𝑝𝑎𝑟𝑎𝑚𝑒𝑡𝑒𝑟𝑠
Persamaan 3.3. Square Error Function Estimator (Watanabe , 2016).
Perhatikan baik-baik Persamaan 3.3, secara filosofis ia sama dengan Persamaan 3.2. Ingat bab 1, tentunya learning machine yang direpresentasikan dengan fungsi g bisa diatur kinerjanya dengan parameter trainingw. Square error untuk learning machine dengan parameter trainingw diberikan oleh Persamaan 3.3. (xi,yi) adalah pasangan input-desired output. Selain untuk menghitung square
error pada training data, Persamaan 3.3 juga dapat digunakan untuk menghitung square error pada
testing data. Tujuan dari regresi/machine learning in general adalah meminimalkan nilai error function. Akan tetapi, fenomena overfitting dapat terjadi apabila nilai error function saat training
kecil, tetapi besar saat testing. Learning machine terlalu menyesuaikan diri terhadap tarining data.
Ingat kembali, fungsi pembelajaran ditulis sebagai p(y|x,w), yaitu mengaproksimasi fungsi target, dengan parameter w. Untuk menghindari overfitting, kadang ditambahkan fungsi noise/bias (selanjutnya disebut noise/bias saja). Fungsi belajar dapat ditulis kembali sebagai p(y|x,w,s), dimana s adalah noise/bias. Seiring membaca lecture note ini, Anda akan lebih mengerti tentang noise/bias
yang langsung diaplikasikan pada algoritma machine learning (untuk sekarang harap bersabar).
𝑝(𝑦|𝑥, 𝒘, 𝑠)
3.2 Steepest Gradient Descent
Pada bab ini tujuan dari pembelajaran adalah untuk meminimalkan error, sehingga kinerja learning machine diukur oleh square error. Dengan kata lain, utility function adalah meminimalkan square error. Secara matematis, yang kita lakukan adalah mengestimasi minimum square error, dengan mencari nilai w yang meminimalkan nilai error, E(w) = E(w1, w2, w3, … wn). Terdapat beberapa cara untuk memimalkan square error (steepestgradient descent, stochastic gradient descent, dsb), tetapi pada lecture note ini, hanya akan dibahas steepest gradient descent.
Bayangkan kamu sedang berada di puncak pegunungan, kamu ingin mencari titik terendah pegunungan tersebut. Kamu tidak dapat melihat keseluruhan pegunungan, jadi yang kamu lakukan adalah mencari titik terendah sejauh mata memandang, kemudian menuju titik tersebut dan menganggapnya sebagai titik terendah. Layaknya asumsi sebelumnya, kamu juga turun menuju titik terendah dengan cara melalui jalanan dengan kemiringan paling tajam, dengan anggapan bisa lebih cepat menuju ke titik terendah (Watanabe, 2016). Sebagai ilustrasi, perhatikan gambar 3.3!
Gambar 3.3. Ilustrasi Steepest Gradient Descent
Jalanan dengan kemiringan paling tajam adalah –grad E(w). Dengan definisi grad E(w) diberikan pada Persamaan 3.5. 𝑔𝑟𝑎𝑑 𝐸(𝒘) = (𝜕𝐸 𝜕𝑤1, 𝜕𝐸 𝜕𝑤2, 𝜕𝐸 𝜕𝑤3, … , 𝜕𝐸 𝜕𝑤𝑛)
Persamaan 3.5. Gradient Square Error.
𝑑𝒘
𝑑𝑡 = −𝑔𝑟𝑎𝑑 𝐸(𝒘)
Persamaan 3.6. Steepest Gradient Descent.
Ingat kembali materi diferensial. Gradient adalah turunan (diferensial) fungsi. Apabila suatu fungsi turun (ke bawah secara interpretasi mata), maka nilai turunannya (diferensial) memiliki tanda minus. Untuk mencari turunan tertajam, sama halnya mencari nilai –gradient terbesar. Dengan demikian, menghitung –grad E(w) terbesar sama dengan jalanan turun paling terjal.
Tentunya seiring berjalannya waktu, kita mengubah-ubah parameter w agar kinerja model optimal. Nilai optimal diberikan oleh turunan w terhadap waktu, yang bernilai sama dengan –grad E(w).
𝒘(𝑡 + 1) − 𝒘(𝑡) = −𝜂 𝑔𝑟𝑎𝑑 𝐸(𝒘(𝑡)); 𝑡 = 0,1,2,3, …
Persamaan 3.7. Bentuk Diskrit Steepest Gradient Descent.
Eta (𝜂) disebut learning rate. Learningrate digunakan untuk mengatur seberapa pengaruh keterjalan terhadap pembelajaran. Silahkan mencari sumber tambahan lagi agar dapat mengerti learning rate
secara lebih dalam.
Walaupun kamu berharap bisa menuju titik terendah dengan menelusuri jalan terdekat dengan kemiringan paling tajam, tapi kenyataanya hal tersebut bisa jadi bukanlah jalan tercepat, seperti yang diilustrasikan pada Gambar 3.4.
Gambar 3.4. Ilustrasi Geometris Steepest Gradient Descent (Watabane, 2016).
Pandangan kita yang terbatas layaknya kita tidak bisa melihat keseluruhan pengunungan secara keseluruhan, kita juga tidak bisa melihat keseluruhan nilai error untuk semua parameter w pada ruang yang tidak terbatas. Secara filosifis, hal tersebut juga berlaku saat membaca buku, oleh karena itu sebaiknya membaca beberapa buku saat belajar.
Dalam local point of view, steepest gradient descent adalah cara tercepat menuju titik terendah, tetapi tidak dalam global point of view. Apabila nilai learning rate (𝜂) pada Persamaan 3.7 relatif kecil, maka dinamika perubahan parameter w juga kecil, tetapi bila nilainya besar, maka jalanan menuju
local minima (titik terendah dalam local point of view) akan bergoyang-goyang (swing), seperti pada Gambar 3.5.
Untuk kontrol tambahan proses mengestimasi w sehingga memberikan nilai E(w) terendah, persamaan steepest gradient descent dapat ditambahkan dengan momentum (alfa pada Persamaan 3.8). Alfa sangat jelas merupakan momentum, karena dikalikan dengan hasil descent pada tahap sebelumnya. Alfa adalah parameter kontrol tambahan untuk mengandalikan swing yang sudah dibahas sebelumnya.
Gambar 3.5. Ilustrasi Nilai Learning Rate Besar Pada Steepest Gradient Descent.
Bila swing yang disebabkan pada Persamaan 3.7 relatif kecil, maka alfa akan membuatnya semakin kecil. Sebaliknya bila besar maka alfa akan membuatnya semakin besar.
𝒘(𝑡 + 1) − 𝒘(𝑡) = −𝜂 𝑔𝑟𝑎𝑑 𝐸(𝒘(𝑡)) + 𝛼(𝒘(𝑡) − 𝒘(𝑡 − 1)); 𝑡 = 0,1,2,3, …
Persamaan 3.8. Bentuk Diskrit Steepest Gradient Descent Dengan Momentum. 3.3 Bacaan Lanjutan
Karena penggunaan learning rate dan momentum paling kentara di Neural Network, silahkan baca artikel menarik berikut untuk tamabahan lanjutan.
1) Lecture Note in Neural Network
http://users.ics.aalto.fi/jhollmen/dippa/node22.html
2) Lecture Note in Neural Network
4
Artificial Neural Network
Bab ini membahas salah satu algorithma machine learning yang sedang popular belakangan ini, yaitu
artificial neural network. Pembahasan akan dimulai dari hal-hal sederhana sampai yang lebih kompleks. Bab ini juga mencakup variasi neural network seperti deep learning dan recurrent neural network.
4.1 Definisi
Masih ingatkah Anda materi pada bab-bab sebelumnya? Machine learning sebenarnya ingin meniru bagaimana proses manusia belajar. Pada bagian ini, peneliti ingin meniru proses belajar tersebut dengan mensimulasikan jaringan saraf biologis (artificialneural network) (Mikolov, 2012; Cripps, 1996; Atiya, 1991; Cowan, 1989). Kami yakin banyak yang sudah tidak asing dengan istilah ini, berhubung deep learning sedang populer dan banyak yang membicarakannya (dan digunakan sebagai trik pemasaran). Silahkan belajar biologi untuk lebih mengerti tentang saraf manusia. Artificial neural network adalah salah satu algoritma supervised learning yang populer, dan bisa juga digunakan untuk
unsupervised learning (Mikolov et al., 2013; Yu, 2013; Mikolov, 2012; Atiya, 1991). Pada lecture note ini, kami hanya membahas neural network untuk supervised learning. Objektif pembelajaran adalah memilimalkan error.
ArtificialNeural Network (selanjutnya disingkat ANN), menghasilkan model yang sulit dibaca dan dimengerti oleh manusia. ANN menggunakan relatif banyak parameter, kita tidak tahu apa saja yang terjadi saat proses pembelajaran. Pada bidang riset ini, ANN disebut agnostik (kita percaya, tetapi sulit membuktikan kenapa bisa benar). Secara matematis, ANN ibarat sebuah graf. ANN memiliki
neuron/node (vertex), dan sinapsis (edge). Topologi ANN akan dibahas lebih detil upabab berikutnya. Sebagai gambaran, ANN berbentuk seperti Gambar 4.1 (multilayer perceptron).
Gambar 4.1. Ilustrasi ANN (Khodra & Lestari, 2015)
4.2 Single Perceptron
Bentuk terkecil (minimal) sebuah ANN adalah single perceptron yang hanya terdiri dari sebuah
yang menjadi input bagi neuron tersebut. Neuron akan memproses inputx melalui perhitungan jumlah perkalian antara nilai input dan synapse weight. Pada training, yang dioptimasi adalah synapse weight
ini (learning parameter). Selain itu, terdapat juga bias𝜽 sebagai kontrol tambahan (ingat materi
steepest gradient descent). Output dari neuron adalah hasil fungsi aktivasi dari “perhitungan jumlah perkalian antara nilai input dan synapse weight”. Ada beberapa macam fungsi aktivasi, misal step function, sign function, dan sigmoid function. Untuk selanjutnya, pada lecture note ini, fungsi aktivasi berarti yang dimaksud adalah sigmoid function. Silahkan eksplorasi sendiri untuk fungsi aktivasi lainnya.
Gambar 4.2. Single Perceptron.
Sigmoid function diberikan oleh Persamaan 4.1, dengan u merupakan bilangan real. Secara geometris,
sigmoid function diilustrasikan pada Gambar 4.3.
𝜎(𝑢) = 1 (1 + 𝑒−𝑢)
Persamaan 4.1. Sigmoid Function.
Untuk melakukan pembelajaran single perceptron, training dilakukan berdasarkan perceptron training rule. Prosesnya adalah tahapan-tahapan berikut (Mitchel, 1997):
1. Lewatkan input pada perceptron, kemudian kita akan mendapatkan nilai output. 2. Nilai output tersebut dibandingkan dengan desired output.
3. Apabila nilai output sesuai dengan desired output, tidak perlu mengubah apa-apa.
4. Apabila nilai output tidak sesuai dengan desired output, maka lakukan perubahan terhadap
learning parameter (synapse weight).
Secara matematis, hal tersebut dirumuskan pada Persamaan 4.2. y melambangkan desired output, o
melambangkan output. 𝜂 disebut sebagai learning rate.
∆𝑤𝑖= 𝜂(𝑦 − 𝑜)𝑥𝑖
Persamaan 4.2. Perceptron Training Rule (Mitchel, 1997)
Berikut adalah pseudo-code untuk perceptron training rule (Mitchel, 1997) – naskah asli. Given K training pairs (xi,yi) arranged in the training set, i=1,2,3,...,K. K is an finite number. Step1 : choose𝜂 > 0
Step 2 : all weights w are initialized at small random values, the running error E(w) is set to 0 at first.
Step 3 : compute the actual output.
Step 4 : weights are updated. 𝑤𝑖(𝑡 + 1) = 𝑤𝑖(𝑡) + 𝜂(𝑦 − 𝑜)𝑥𝑖; 𝑖 = 1,2, … 𝑛; 𝑡 = 𝑡𝑖𝑚𝑒
Step 5 : cumulative cycle error is computed by 𝐸(𝒘) =1
2 ∑ (𝑦𝑑− 𝑜𝑑) 2 𝐾
𝑑=1 ; 𝑦𝑑=desired output for
training data-d; od= output for training data-d. *) ½ just to make math easier.
Step 6 : The training cycle is completed. For E = 0 terminate the training session. If E > 0, repeat new training cycle by going to step 3.
Hasil akhir pembelajaran adalah konfigurasi synapse weight. Saat melakukan klasifikasi, kita melewatkan input baru pada jaringan yang telah dibangun, kemudian tinggal mengambil hasilnya. Pada contoh kali ini, seolah-olah single perceptron hanya dapat digunakan untuk melakukan binary classification (hanya ada dua kelas, disimbolkan 0 dan 1). Untuk multi-label classification, kita dapat menerapkan strategi. Salah satu strategi sederhana adalah membagi-bagi kelas menjadi range nilai. Seumpama kita mempunyai lima kelas. Kelas pertama direpresentasikan dengan nilai output 0.0-0.2, kelas kedua 0.2-0.4, dst.
4.3 Multilayer Perceptron & Backpropagation
Anda sudah belajar training bagi single perceptron. Selanjutnya kita akan mempelajari multilayer perceptron (MLP). Seperti ilustrasi pada Gambar 4.1, multilayer perceptron secara literal memiliki beberapa layers. Pada lecture note ini, kita batasi permasalahan menjadi 3 layers saja: input, hidden,
dan output. Perhatikan Gambar 4.4! Input layer menerima input, kemudian nilai input (tanpa dilewati ke fungsi aktivasi) diberikan ke hidden units. Pada hidden units, input diproses dan dilakukan perhitungan hasil fungsi aktivasi untuk tiap-tiap neuron, lalu hasilnya diberikan ke layer berikutnya. Hasil dari input layer akan diterima sebagai input bagi hidden layer. Begitupula seterusnya hidden layer akan mengirimkan hasilnya untuk output layer. Kegiatan dinamakan feed forward (Mitchel, 1997; Atiya, 1991). Hal serupa berlaku untuk artificial neural network dengan lebih dari 3 layers.
Gambar 4.4. Struktur Matematis MLP.
Output of hidden unit 𝑜𝑗= 𝜎(∑𝑀𝑘=1𝑤𝑗𝑘𝑥𝑘+ 𝜃𝑗)
Output of output unit 𝑓𝑗= 𝜎(∑𝐻𝑗=1𝑢𝑖𝑗𝑜𝑗+ 𝛾𝑖) = 𝜎(∑𝐻𝑗=1𝑢𝑖𝑗 𝜎(∑𝑘=1𝑀 𝑤𝑗𝑘𝑥𝑘+ 𝜃𝑗) + 𝛾𝑖)
u, w, , adalah learning parameter. , melambangkan noise/bias. M adalah banyaknya hidden units, H adalah banyaknya output units.
Untuk melatih multilayer perceptron, algoritma yang umumnya digunakan adalah backpropagation. Arti kata backpropagation sulit untuk diterjemahkan ke dalam bahasa Indonesia. Idenya adalah, dari
output layer tentu bisa ada error dibandingkan desired output; dari error tersebut, kita perbaharui parameter (utamanya synapse weights). Intinya adalah mengkoreksi synapse weight dari output layer
ke hidden layer, kemudian error tersebut dipropagasi ke layer berikut-berikutnya. Artinya, perubahan synapse weight pada suatu layer dipengaruhi oleh perubahan synapse weight pada layer sebelumnya.
Ingat kembali materi pada bab gradient descent. Untuk meminimalkan error, kita menggunakan prinsip gradient descent. Kita akan memperlajari bagaimana cara menurunkan backpropagation
menggunakan gradient descent yaitu menghitung – 𝑔𝑟𝑎𝑑{(𝑦𝑖− 𝑓𝑖(𝒙, 𝒘)2}; untuk semua output neurons.
Ingat kembali chain rule in derivative (diferensial)? Perhatikan contoh berikut,
𝑓(𝑔(𝑥))′= 𝑓′(𝑔(𝑥))𝑔′(𝑥)
𝑓(𝑔(ℎ(𝑥)))′= 𝑓′(𝑔(ℎ(𝑥)))𝑔′(ℎ(𝑥))ℎ′(𝑥))
Ingat kembali pseudo-code perceptron training rule pada sub bab sebelumnya. Error pada suatu
output diberikan oleh persamaan
𝐸(𝒘) =1
2 ∑ (𝑦𝑖− 𝑓𝑖) 2 𝑁