106
Perancangan Data Mining
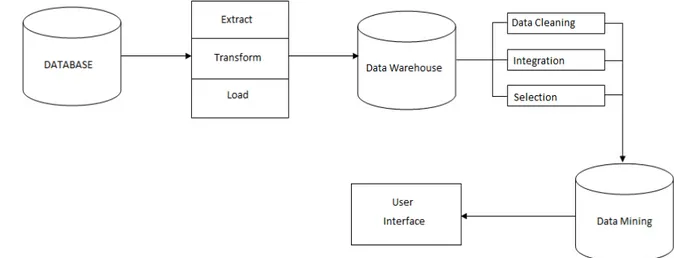
4.1 Arsitektur Perancangan Data Mining yang Diusulkan
Data layanan dan operasional yang berhubungan dengan pembuatan laporan bagi pihak eksekutif diambil dan ditampung ke dalam media penyimpanan yang besar yaitu database, sumber data yang akan digunakan dalam proses perancangan data mining diambil dari data warehouse. Hal ini disebabkan karena informasi yang tersimpan di dalam data warehouse, sehingga memberikan gambaran akhir dari proses customer service operational dan data analyst. Data yang tersimpan dalam data warehouse bersifat terpusat.
Selanjutnya data mining dibuat dari data warehouse untuk menghasilkan laporan yang sifatnya prediktif dan klasifikasi. Data warehouse dan data mining dibuat menggunakan analysis service yang disediakan oleh Micosoft SQL Server 2005.
4.2 Tahapan Dalam Proses Data Mining 4.2.1 Data Cleaning
Langkah pertama dalam metode perancangan ini adalah data cleaning. Fungsi daripada data cleaning adalah menghapus dan
mengganti data yang tidak konsisten, namun karena perusahaan telah menerapkan data warehouse, maka data yang digunakan adalah data yang ada dalam data warehouse perusahaan.
4.2.2 Data Integration
Pada tahap ini dilakukan penggabungan data. Dalam tahapan ini dibentuk skema yang berisi informasi sejumlah entity yang saling berhubungan dalam tabel dimensi yang satu dengan tabel dimensi yang lain, namun karena perusahaan telah menerapkan data warehouse maka data yang digunakan adalah data yang ada dalam data warehouse perusahaan
4.2.3 Data Selection
Pada tahap ini, dilakukan seleksi data yang ada di dalam data warehouse yang akan digunakan dalam perancangan model data mining.
Data yang diseleksi adalah data dari hasil analisis data warehouse yang sebelumnya sudah di jelaskan pada sub bab 3.4 data warehouse perusahaan. Berdasarkan kebutuhan perusahaan, data yang akan diseleksi adalah data – data yang berhubungan dengan prediksi survei dan indeks kepuasan pelanggan.
4.2.4 Data Transformation
Pada tahap ini, dipilih informasi yang ada di dalam data warehouse yang berhubungan dan akan digunakan dalam pembuatan
model data mining, yang dapat berguna bagi perusahaan dan belum diketahui perusahaan, bahwa data yang ada dalam perusahaan dapat diubah menjadi informasi yang sangat bermanfaat.
Model data mining dibuat dengan cara mempelajari data perusahaan yang sudah terintegrasi dan menemukan pola yang tersembunyi, tanpa adanya penambahan data baru ke dalam data warehouse, maka transformasi data ini dilakukan dengan cara membuat
view dari data warehouse, yang berisi data – data yang digunakan.
Berdasarkan kebutuhan perusahaan akan penilaian customer satisfaction dan proses survei, maka berikut ini adalah view – view yang dibentuk untuk memenuhi kebutuhan perusahaan :
• ViewFactKomplainPrediksiSurvey
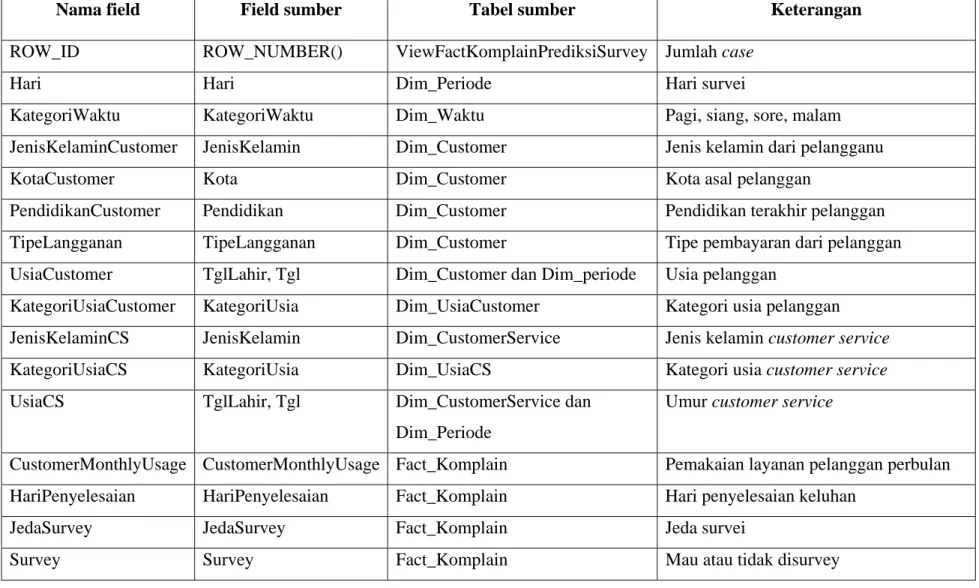
ViewFactKomplainPrediksiSurvey merupakan view yang dibuat dari tabel FactKomplain dan dimensi – dimensi yang terkait. ViewFactKomplainPrediksiSurvey dibuat untuk mendukung analisis survei pelanggan dengan karakteristik pelanggan dan agent yang berbeda – beda. Dalam ViewFactKomplainPrediksiSurvey juga terdapat analisis hari dan waktu survei yang dianjurkan, sehingga pelanggan mempunyai keinginan untuk disurvei. Berikut adalah SQL pembuatan ViewFactKomplainPrediksiSurvey :
CREATE VIEW ViewFactKomplainPrediksiSurvey AS
SELECT
ROW_ID=ROW_NUMBER() OVER(ORDER BY f.Periode_Key), p.Hari, w.KategoriWaktu, JenisKelaminCustomer=c.JenisKelamin, KotaCustomer=c.Kota, PendidikanCustomer=c.Pendidikan, c.TipeLangganan, UsiaCustomer=DATEDIFF(YEAR, c.TglLahir, p.Tgl), KategoriUsiaCustomer=uc.KategoriUsia, JenisKelaminCS=cs.JenisKelamin, KategoriUsiaCS=ucs.KategoriUsia, UsiaCS=DATEDIFF(YEAR, cs.TglLahir, p.Tgl), f.CustomerMonthlyUsage, f.HariPenyelesaian, f.JedaSurvey, s.Survey FROM Fact_Komplain f
INNER JOIN Dim_Periode p ON f.Periode_Key=p.Periode_Key INNER JOIN Dim_Waktu w ON f.Waktu_Key=w.Waktu_Key
INNER JOIN Dim_ProfilCustomer cp ON f.ProfilCustomer_Key=cp.ProfilCustomer_Key
INNER JOIN Dim_UsiaCustomer uc ON f.UsiaCustomer_Key=uc.UsiaCustomer_Key
INNER JOIN Dim_LamaBerlangganan l ON f.LamaBerlangganan_Key=l.LamaBerlangganan_Key
INNER JOIN Dim_CustomerService cs ON f.CustomerService_Key=cs.CustomerService_Key
INNER JOIN Dim_UsiaCS ucs ON f.UsiaCS_Key=ucs.UsiaCS_Key
INNER JOIN Dim_MasaKerja m ON f.MasaKerja_Key=m.MasaKerja_Key
INNER JOIN Dim_TipeKomplain t ON f.TipeKomplain_Key=t.TipeKomplain_Key
INNER JOIN Dim_WaktuPenyelesaian wp ON f.WaktuPenyelesaian_Key=wp.WaktuPenyelesaian_Key
INNER JOIN Dim_Survey s ON f.Survey_Key=s.Survey_Key
Tabel 4.1 Struktur Tabel View ViewFactKomplainPrediksiSurvey
Nama field Field sumber Tabel sumber Keterangan
ROW_ID ROW_NUMBER() ViewFactKomplainPrediksiSurvey Jumlah case
Hari Hari Dim_Periode Hari survei
KategoriWaktu KategoriWaktu Dim_Waktu Pagi, siang, sore, malam JenisKelaminCustomer JenisKelamin Dim_Customer Jenis kelamin dari pelangganu
KotaCustomer Kota Dim_Customer Kota asal pelanggan
PendidikanCustomer Pendidikan Dim_Customer Pendidikan terakhir pelanggan
TipeLangganan TipeLangganan Dim_Customer Tipe pembayaran dari pelanggan UsiaCustomer TglLahir, Tgl Dim_Customer dan Dim_periode Usia pelanggan
KategoriUsiaCustomer KategoriUsia Dim_UsiaCustomer Kategori usia pelanggan JenisKelaminCS JenisKelamin Dim_CustomerService Jenis kelamin customer service KategoriUsiaCS KategoriUsia Dim_UsiaCS Kategori usia customer service UsiaCS TglLahir, Tgl Dim_CustomerService dan
Dim_Periode
Umur customer service
CustomerMonthlyUsage CustomerMonthlyUsage Fact_Komplain Pemakaian layanan pelanggan perbulan HariPenyelesaian HariPenyelesaian Fact_Komplain Hari penyelesaian keluhan
JedaSurvey JedaSurvey Fact_Komplain Jeda survei
• ViewFactSurveyIndeksKepuasan
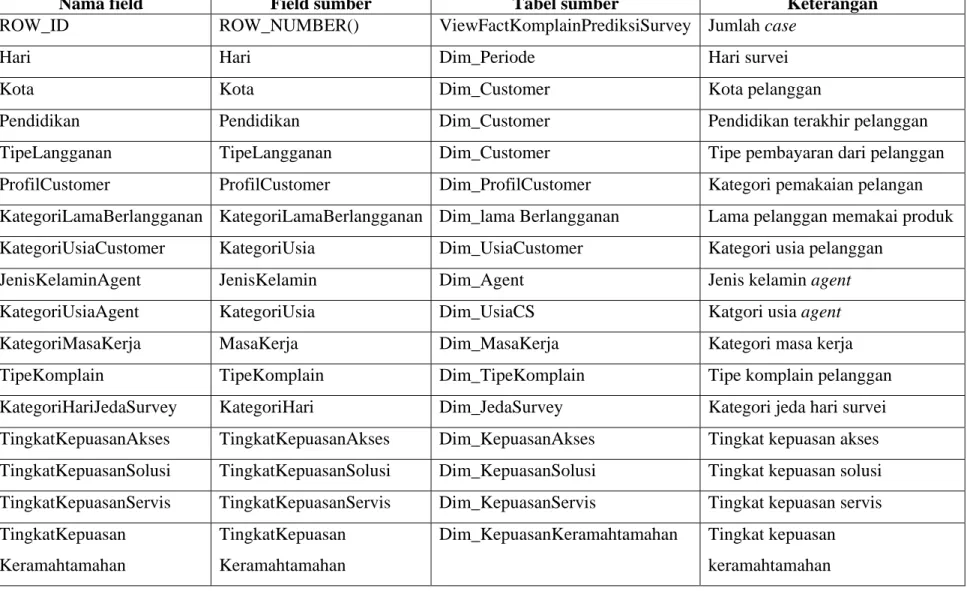
ViewFactSurveyIndeksKepuasan merupakan view yang dibuat dari FactSurvey dan dimensi – dimensi yang terkait. ViewFactSurveyIndeksKepuasan dibuat untuk mengukur tingkat kepuasan pelanggan akan layanan yang diberikan perusahaan pada pelanggan. ViewFactSurveyIndeksKepuasan terdiri dari kepuasan akses, solusi, servis, dan keramahtamahan. Berikut adalah SQL pembuatan ViewFactKomplainPrediksiSurvey :
CREATE VIEW ViewFactSurveyIndeksKepuasan AS
SELECT
ROW_ID=ROW_NUMBER() OVER (ORDER BY f.Periode_Key), p.Hari,
c.Kota, c.Pendidikan, c.TipeLangganan, cp.ProfilCustomer, l.KategoriLamaBerlangganan, KategoriUsiaCustomer=uc.KategoriUsia, JenisKelaminAgent=a.JenisKelamin, KategoriUsiaAgent=ucs.KategoriUsia, m.KategoriMasaKerja, t.TipeKomplain, KategoriHariJedaSurvey=j.KategoriHari, TingkatKepuasanAkses='Kepuasan Akses='+ka.TingkatKepuasanAkses, TingkatKepuasanSolusi='Kepuasan Solusi='+ks.TingkatKepuasanSolusi,
TingkatKepuasanServis='Kepuasan Servis='+kse.TingkatKepuasanServis, TingkatKepuasanKeramahtamahan='Kepuasan
Keramahtamahan='+kk.TingkatKepuasanKeramahtamahan
FROM Fact_Survey f
INNER JOIN Dim_Periode p ON f.Periode_Key=p.Periode_Key INNER JOIN Dim_Waktu w ON f.Waktu_Key=w.Waktu_Key
INNER JOIN Dim_Customer c ON f.Customer_Key=c.Customer_Key INNER JOIN Dim_ProfilCustomer cp ON
f.ProfilCustomer_Key=cp.ProfilCustomer_Key INNER JOIN Dim_UsiaCustomer uc ON f.UsiaCustomer_Key=uc.UsiaCustomer_Key INNER JOIN Dim_LamaBerlangganan l ON
f.LamaBerlangganan_Key=l.LamaBerlangganan_Key INNER JOIN Dim_Agent a ON f.Agent_Key=a.Agent_Key
INNER JOIN Dim_UsiaCS ucs ON f.UsiaAgent_Key=ucs.UsiaCS_Key INNER JOIN Dim_MasaKerja m ON f.MasaKerja_Key=m.MasaKerja_Key INNER JOIN Dim_TipeKomplain t ON
f.TipeKomplain_Key=t.TipeKomplain_Key
INNER JOIN Dim_JedaSurvey j ON f.JedaSurvey_Key=j.JedaSurvey_Key INNER JOIN Dim_KepuasanAkses ka ON
f.KepuasanAkses_Key=ka.KepuasanAkses_Key INNER JOIN Dim_KepuasanSolusi ks ON f.KepuasanSolusi_Key=ks.KepuasanSolusi_Key
INNER JOIN Dim_KepuasanServis kse ON f.KepuasanServis_Key=kse.KepuasanServis_Key INNER JOIN Dim_KepuasanKeramahtamahan kk ON
f.KepuasanKeramahtamahan_Key=kk.KepuasanKeramahtamahan_Key
Tabel 4.2 Struktur Tabel View ViewFactSurveyIndeksKepuasan
Nama field Field sumber Tabel sumber Keterangan
ROW_ID ROW_NUMBER() ViewFactKomplainPrediksiSurvey Jumlah case
Hari Hari Dim_Periode Hari survei
Kota Kota Dim_Customer Kota pelanggan
Pendidikan Pendidikan Dim_Customer Pendidikan terakhir pelanggan
TipeLangganan TipeLangganan Dim_Customer Tipe pembayaran dari pelanggan
ProfilCustomer ProfilCustomer Dim_ProfilCustomer Kategori pemakaian pelangan KategoriLamaBerlangganan KategoriLamaBerlangganan Dim_lama Berlangganan Lama pelanggan memakai produk KategoriUsiaCustomer KategoriUsia Dim_UsiaCustomer Kategori usia pelanggan
JenisKelaminAgent JenisKelamin Dim_Agent Jenis kelamin agent
KategoriUsiaAgent KategoriUsia Dim_UsiaCS Katgori usia agent
KategoriMasaKerja MasaKerja Dim_MasaKerja Kategori masa kerja
TipeKomplain TipeKomplain Dim_TipeKomplain Tipe komplain pelanggan
KategoriHariJedaSurvey KategoriHari Dim_JedaSurvey Kategori jeda hari survei TingkatKepuasanAkses TingkatKepuasanAkses Dim_KepuasanAkses Tingkat kepuasan akses TingkatKepuasanSolusi TingkatKepuasanSolusi Dim_KepuasanSolusi Tingkat kepuasan solusi TingkatKepuasanServis TingkatKepuasanServis Dim_KepuasanServis Tingkat kepuasan servis TingkatKepuasan
Keramahtamahan
TingkatKepuasan Keramahtamahan
Dim_KepuasanKeramahtamahan Tingkat kepuasan keramahtamahan
4.2.5 Model Data Mining
Pada tahapan ini, dijelaskan mengenai proses pembuatan model data mining, yang terdiri dari teknik – teknik data mining. Langkah
pertama yang harus dilakukan untuk membuat model data mining, jalankan SQL Server Business Intelligence Development Studio 2008 untuk merancang model yang akan dibuat. Perancangan model ini, dapat dilakukan dengan memilih Analysis Services Project pada menu File.
Setelah terbentuk Analysis Services Project, lanjutkan dengan membuat Data Source, fungsi Data Source adalah sebagai sumber data yang akan digunakan untuk melakukan analisis tren pada model data mining. Langkah pertama yang harus dilakukan untuk membuat Data
Source adalah klik kanan pada Data Source kemudian pilih New Data
Source. Selanjutnya klik Next pada window Data Source Wizard,
kemudian pilih “Create a data source based on an existing or new connection” dilanjutkan dengan memilih server dan jenis autentikasinya,
setelah itu pilih database yang mau dimasukan, setelah selesai klik Test Connection untuk mengetahui apakah koneksi ke server berhasil. Bila
berhasil, tekan OK, kemudian klik Finish.
Apabila Data Source sudah terbentuk, kemudian dilanjutkan dengan membuat Data Source View, fungsi dari Data Source View adalah menampilkan relation dari data – data yang terdapat pada Data Source. Langkah pertama yang harus dilakukan pada saat membuat Data Source View adalah klik kanan pada Data Source View kemudian akan muncul
kemudian pilih view yang akan menjadi sumber data dari model data mining yang akan dibuat. Klik nama view yang dibuat, kemudian klik “>”
atau “>>” untuk menambah view ke daftar objek yang akan digunakan sebagai sumber data model. Kemudian, klik Next dan beri nama Data Source View yang dibuat. Terakhir, klik Finish.
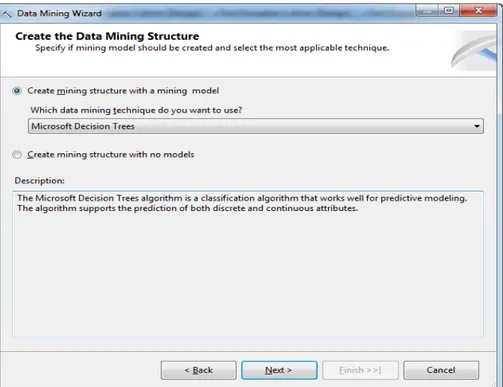
Setelah itu, rancangan model data mining dapat dibuat. Langkah pertama yang harus dilakukan adalah klik kanan Mining Structure dan pilih New Mining Structure. Kemudian, akan muncul window Data Mining Wizard. Klik Next kemudian pilih “From existing relational
database or data warehouse” dan klik Next. Kemudian, pilih algoritma
yang akan digunakan dalam membuat model data mining, selanjutnya klik Next. Berikut ini adalah tampilan untuk memilih algoritma yang akan dipakai dalam membuat proses model data mining :
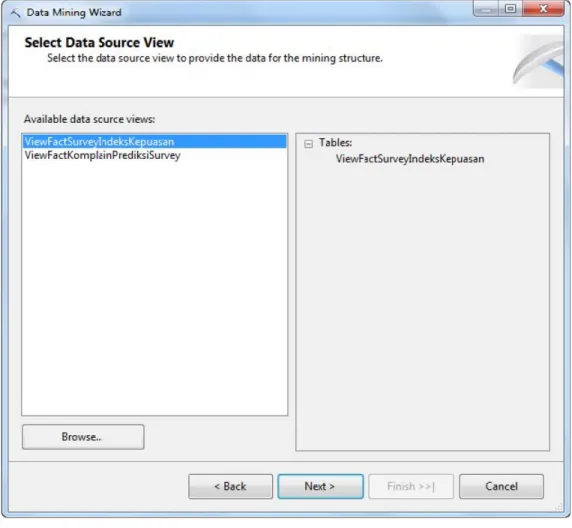
Selanjutnya , pilih Data Source View yang akan digunakan sebagai sumber data dari model data mining yang akan dibuat dan klik Next.
Gambar 4.3 Window Memilih Data Source View
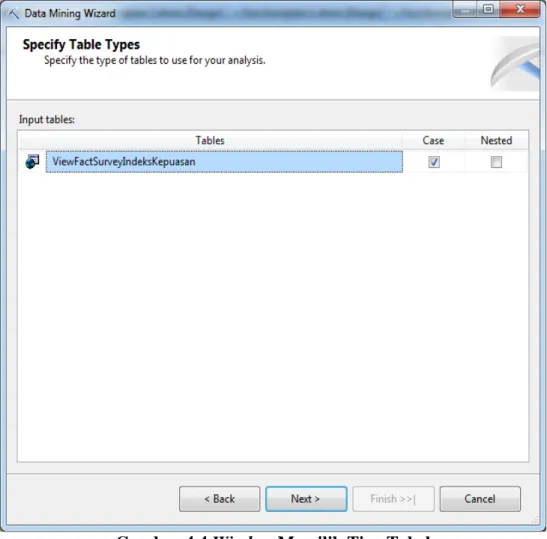
Selanjutnya, pilih tabel input yang terdiri dari : case tabel, nested table, atau case table dan nested table. Hal ini tergantung dari algoritma
Gambar 4.4 Window Memilih Tipe Tabel
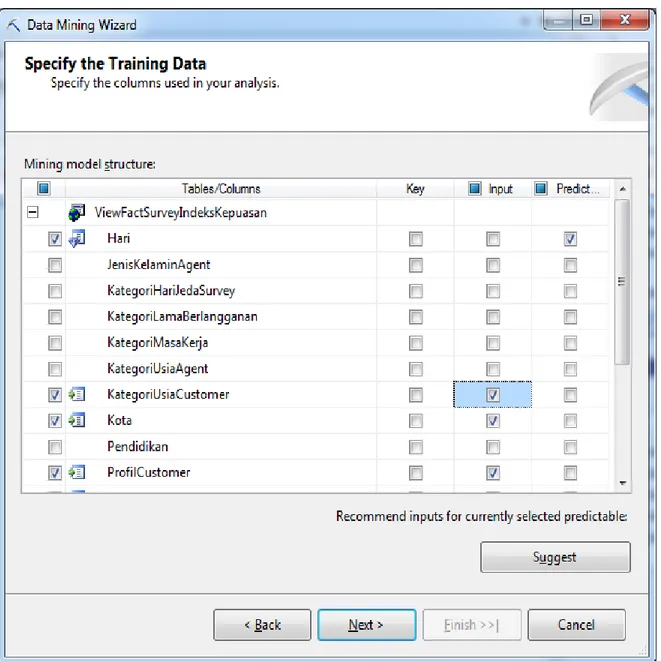
Langkah selanjutnya adalah menentukan atribut dari tabel yang digunakan sebagai atribut input, atribut yang diprediksi, atau atribut key. Mengenai berapa banyak atribut yang dapat digunakan sebagai atribut input, atribut yang diprediksi, atau atribut key, tergantung dari algoritma
yang digunakan. Misalnya, algoritma Time Series membutuhkan dua buah key, satu sebagai key time, dan satunya lagi sebagai key biasa. Sedangkan, algoritma Clustering tidak memiliki atribut yang diprediksi. Terdapat button Suggest pada saat memilih key, input, dan predict,
Suggest berfungsi untuk membantu menentukan atribut mana yang akan
dijadikan atribut input.
Gambar 4.5 Window Spesifikasi Data Training
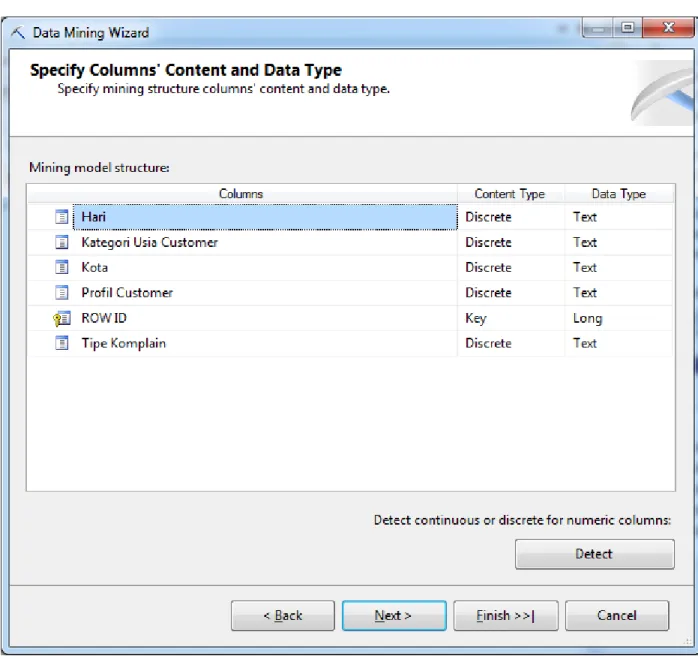
Setelah klik Next, selanjutnya memilih tipe data dari atribut yang sudah di input. Secara otomatis, tipe data yang ditampilkan adalah tipe data atribut yang ada dalam database. Tipe data ini perlu diubah sesuai dengan algoritma yang digunakan karena ada beberapa algoritma data
mining yang tidak mendukung semua tipe data yang ada. Misalnya,
algoritma Naïve Bayes tidak mendukung tipe data yang bersifat continuous seperti Long atau Double sehingga perlu mengubah tipe data
bersifat continuous tadi ke tipe data yang bersifat discrete.
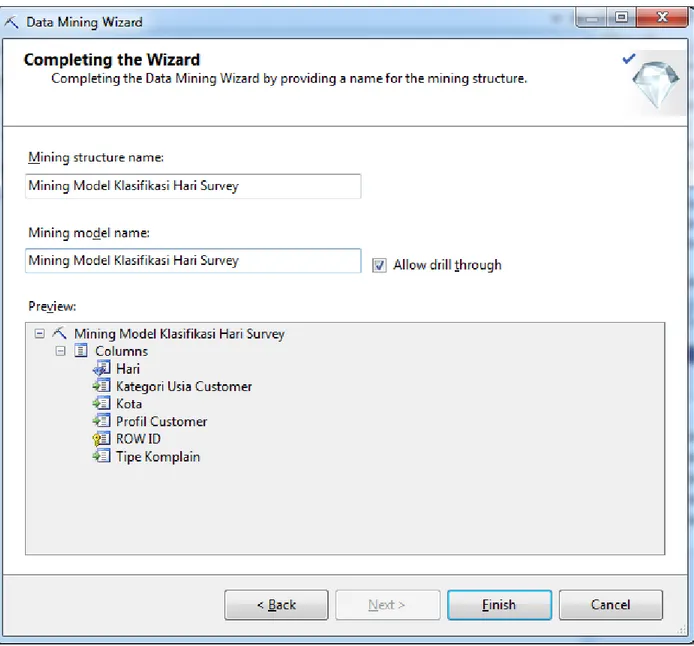
Setelah tipe data sesuai dengan algoritma yang digunakan, klik Next. Selanjutnya beri nama mining structure yang baru dibuat dan nama
model data mining yang baru dibuat. Kemudian, klik Finish dan model data mining telah selesai dibuat.
Gambar 4.7 Window Penamaan Mining Structure dan Mining Model
Agar model data mining tersebut dapat digunakan, model tersebut harus di-deploy ke dalam database Analysis Service yang terletak di
server. Langkah yang harus dilakukan adalah klik menu Build kemudian
pilih Deploy Model
Gambar 4.8 Window Mining Structure Design
4.2.6 Pattern Evaluation
Setelah perancangan data mining struktur maka tahapan selanjutnya adalah mengidentifikasi pola – pola yang terdapat dalam struktur data mining yang telah dibuat beserta algoritma yang sudah di hubungkan dengan struktur yang sudah terbentuk. Data mining dapat menemukan bermacam - macam pola yang terdapat dalam berbagai tipe data. Tahapan ini akan merepresentasikan pola – pola yang dapat dihasilkan oleh data mining yang telah terbentuk.
4.2.6.1 Mining Model Prediksi Keinginan untuk Disurvei
Mining model ini menggunakan teknik neural network. Mining
model prediksi keinginan untuk disurvei mengambil data dari tabel ViewFactKomplainPrediksiSurvei dengan atribut sebagai berikut :
Gambar 4.9 Atribut Prediksi Keinginan untuk Disurvei
Hari, jeda survei, jenis kelamin cs, jenis kelamin customer, kategori usia customer, kategori waktu dan kota customer digunakan sebagai input untuk memprediksi keinginan untuk disurvei. Dari mining model prediksi keinginan untuk disurvei para manajer dapat memperkirakan keinginan pelanggan untuk disurvei dari berbagai atribut di atas. Berikut ini contoh mining yang dapat dihasilkan dari mining model prediksi keinginan untuk disurvei :
Gambar 4.10 Hasil Mining Model Prediksi Keinginan untuk Disurvei
Dari hasil yang didapat di atas dapat disimpulkan bahwa waktu yang paling baik untuk melakukan survei di Jakarta Barat pada hari Senin adalah pada malam hari, disusul dengan siang hari. Sedangkan waktu yang paling buruk adalah pada pagi hari. Jeda survei yang paling disukai adalah lima sampai tujuh hari setelah komplain yang dilayangkan. Usia pelanggan yang paling mudah untuk disurvei rata-rata diatas 40 tahun atau kurang dari 25 tahun. Sedangkan untuk jenis kelamin customer service tidak terlalu berpengaruh terhadap minat pelanggan untuk
disurvei. Dengan analisis data mining tersebut para agent maupun manajer dapat memfokuskan target surveinya ke pelanggan yang
memang memiliki kecenderungan untuk disurvei sehingga membuat proses survei jadi lebih mudah.
4.2.6.2 Mining Model Korelasi Profil Customer Terhadap Minat Disurvei
Mining model korelasi profil customer terhadap minat disurvei
menggunakan teknik association rules. Mining model ini memprediksi hubungan antara profil pelanggan terhadap minat mereka untuk disurvei. Dalam mining model ini kami hasilkan dari tabel ViewFactKomplainPrediksiSurvey dengan atribut sebagai berikut :
Gambar 4.11 Atribut Korelasi Profil Customer Terhadap Minat Disurvei
Kami menggunakan customer monthly usage, hari, jenis kelamin CS, jenis kelamin customer, kategori usia CS, dan kategori usia customer
sebagai input untuk memprediksi survei minat pelanggan. Berikut hasil dari mining model korelasi profil customer terhadap minat disurvei :
Gambar 4.12 Hasil Korelasi Terkuat
Dari hasil mining model korelasi profil customer terhadap minat disurvei dapat disimpulkan bahwa kebanyakan pelanggan dengan profil apapun kemungkinan akan menolak untuk disurvei pada hari senin dan hari sabtu. Lalu pelanggan yang berminat untuk disurvei umumnya memiliku usia 25-30 tahun dan hari yang paling baik untuk diadakan survei adalah hari minggu. Dengan hasil diatas para agent dapat menyusun rencana survei maupun mengambil data pelanggan yang memiliki kecenderungan untuk menerima survei sehingga dapat membantu dalam proses survei.
4.2.6.3Mining Model Segmentasi Pelanggan
Mining model segmentasi pelanggan ini menggunakan teknik
clustering. Pada mining model segmentasi pelanggan, para agent dapat
melihat pembagian profil pelanggan. mining model segmentasi pelanggan ini mengambil data dari tabel ViewFactSurveyIndeksKepuasan dengan atributnya sebagai berikut :
Gambar 4.14 Atribut Segmentasi Pelanggan
Jenis kelamin customer, kategori lama berlangganan, usia customer, kota, dan pendidikan di input untuk menghasilkan segmentasi
pelanggan. pada mining model ini dapat dihasilkan informasi sebagai berikut :
Gambar 4.15 Hasil Cluster Diagram
Gambar 4.16 Hasil Cluster Profile
Gambar 4.17 Hasil Cluster Characteristic
Berdasarkan data yang kami gunakan, kebanyakan pelanggan PT. XL Axiata Tbk., umumnya berjenis kelamin laki-laki dengan lama berlangganan tidak lebih dari tiga bulan. Pelanggan PT. XL Axiata Tbk., umumnya memiliki jenjang pendidikan D3-S1 dan berumur kurang dari dua puluh lima tahun. Lalu umumnya pelanggan PT. XL Axiata Tbk., sudah puas dengan solusi dan keramah-tamahan customer service, akses
layanan dan servis yang diberikan oleh PT. XL Axiata Tbk. Dengan tersedianya informasi tersebut diharapkan dapat mempermudah pihak manajemen PT. XL Axiata Tbk., untuk mengukur tingkat kepuasan dan juga segmentasi pelanggannya. Salah satu hasil mining model ini yang dapat digunakan oleh pihak manajemen adalah hasil perhitungan umur pelanggan. Dengan mengetahui bahwa kebanyakan pelanggannya memiliki usia antara 25-40 tahun maka dapat disimpulkan bahwa kebanyakan pelanggannya adalah kalangan pekerja yang banyak menggunakan akses telepon maupun akses internet. Dengan tersedianya informasi tersebut sekiranya pihak manajer dapat menyusun layanan yang lebih cocok digunakan untuk kalangan tersebut.
4.2.6.4 Mining Model Kepuasan Solusi
Mining model kepuasan solusi dihasilkan dari hasil survei ke
pelanggan oleh para agent. Tugas mining model ini adalah mengukur kepuasan atas solusi yang diberikan oleh customer service terhadap keluhan yang dilayangkan oleh pelanggan. Mining model kepuasan solusi kami hasilkan dari ViewFactIndeksKepuasan dengan teknik neural network. Kepuasan solusi akan diukur dari beberapa atribut seperti
pemakaian pelanggan perbulan, jeda survei,atau tipe komplain yang dilayangkan.
Gambar 4.18 Atribut Mining Model Kepuasan Solusi
Customer monthly usage, jeda survey, kategori lama
berlangganan, dan tipe komplain adalah input yang kami gunakan untuk memprediksi tingkat kepuasan solusi ke pelanggan. Hasil yang kami dapatkan dari mining model tingkat kepuasan solusi antara lain sebagai berikut :
Gambar 4.19 Hasil Mining Model Kepuasan Solusi
Dari mining model diatas dapat disimpulkan bahwa kebanyakan pelanggan PT. XL Axiata Tbk., sangat puas dengan solusi yang diberikan customer service tentang komplain yang berkaitan tentang content,
internet, dan activation. Sedangkan untuk solusi yang berkaitan dengan
Blackberry dan network masih banyak pelanggan yang merasa belum
puas. Lalu untuk pemakaian perbulan, umumnya pelanggan yang jumlah pemakaiannya antara Rp.139.000-Rp.200.000 merasa sangat puas dengan solusi yang diberikan oleh customer service. Dengan informasi diatas para manajer dapat mengambil kesimpulan bahwa masih banyak customer service yang belum menguasai solusi yang berkaitan dengan
Blackberry dan network sehingga pada pelatihan untuk customer service,
4.2.6.5 Mining Model Kepuasan Akses
Untuk mining model kepuasan akses, sama dengan model kepuasan sebelumnya kami menggunakan metode Neural network dan dihasilkan dari ViewFactIndeksKepuasan. Pada mining model kepuasan akses kami menekankan pada tingkat kepuasan pelanggan mengenai koneksi ke layanan 817 atau customer service PT. XL Axiata Tbk.
Gambar 4.20 Atribut Mining Model Kepuasan Akses
Pada mining model kepuasan akses kami menggunakan hari, kategori lama berlangganan, kategori waktu, kota, tipe layanan dan tipe komplain. Dengan mining model kepuasan akses ini kami dapat memprediksi kapan waktu yang paling padat dilihat dari tingkat kepuasan akses ataupun informasi lain yang berhubungan. Berikut ini hasil dari mining model kepuasan akses :
Gamber 4.21 Hasil Mining Model Kepuasan Akses
Gambar 4.21 menunjukkan hasil mining model kepuasan akses dengan case : kota Jakarta Pusat, hari Sabtu, kategori waktu : sore hari, tipe langganan pascabayar dan lama berlangganan 6-12 bulan. Dari hasil mining model diatas dapat dilihat untuk pelanggan dengan tipe komplain
network problem, activation, dan content tingkat kepuasannya sangat
puas. Dari contoh hasil mining model kepuasan akses diatas manajer dapat mengalokasikan lebih banyak customer service untuk menangani komplain mengenai blackberry dan internet untuk meningkatkan kepuasan akses pelanggan ke layanan customer service 817.
4.2.6.6 Mining Model Kepuasan Keramahtamahan
Mining model kepuasan keramahtamahan dihasilkan dari
ViewFactIndeksKepuasan dengan menggunakan teknik neural network. Mining model kepuasan keramahtamahan bertujuan untuk mengukur
tingkat keramah-tamahan customer service. Mining model kepuasan keramahtamahan ini memiliki beberapa atribut yang dapat dilihat dibawah ini:
Gambar 4.22 Atribut Mining Model Kepuasan Keramahtamahan
Kami menggunakan customer monthly usage, jeda survey, kategori lama berlangganan, dan tipe komplain untuk memprediksi tingkat kepuasan keramahtamahan. Pada mining model ini kami mendapatkan hasil sebagai berikut :
Gambar 4.23 Hasil Mining Model Kepuasan Keramahtamahan
Dari hasil diatas dapat disimpulkan bahwa berdasarkan data yang kami gunakan, dari hasil survei yang dilakukan oleh para agent, banyak pelanggan PT. XL Axiata Tbk., mengeluhkan tentang tingkat keramahan dari customer service yang menangani keluhan tentang blackberry dan network. Sedangkan untuk masalah internet, activation, dan content
tingkat keramahannya sudah cukup baik. Dan untuk pelanggan yang sudah berlangganan lebih dari 24 bulan, mereka juga merasa tingkat keramah-tamahan dari customer service itu kurang. Hal ini harus diperhatikan oleh pihak manajer untuk mencegah hilangnya pelanggan-pelanggan setia yang telah lama menggunakan jasa PT. XL Axiata Tbk. Salah satu tindakan yang dapat diambil oleh manajer contohnya, mengirimkan sms selamat ulang tahun dari sms centre kepada pelanggan setia yang sedang kebetulan merayakan ulang tahunnya atau memberikan
bonus-bonus yang diperuntukkan khusus untuk pelanggan yang telah lama menggunakan layanan XL.
4.2.6.7 Mining Model Kepuasan Servis
Mining model ini dihasilkan dengan teknik neural network dari
data yang berasal dari ViewFactKomplainPrediksiSurvey. Tugas mining model ini adalah mengukur kepuasan servis XL kepada pelanggan dari
beberapa kategori seperti pemakaian pelanggan perbulan, jeda survei,atau tipe komplain yang dilayangkan.
Gambar 4.24 Atribut Mining Model Kepuasan Servis
Customer monthly usage, jeda survey, kategori lama
berlangganan, dan tipe komplain adalah input yang kami gunakan untuk memprediksi tingkat kepuasan servis ke pelanggan. Hasil yang kami dapatkan dari mining model tingkat kepuasan servis antara lain sebagai berikut :
Gambar 4.25 Hasil Mining Model Kepuasan Servis
Dari mining model diatas dapat kami simpulkan bahwa kebanyakan pelanggan PT. XL Axiata Tbk tidak puas terhadap servis activation dan content. Namun para pengguna Blackberry dan pelanggan
lain sangat puas dengan servis yang dimiliki oleh PT. XL Axiata Tbk. Lalu jeda survei yang paling disukai oleh pelanggan adalah 6-8 hari atau 1-2 hari setelah komplain dilayangkan. Dari hasil mining model diatas sekiranya pihak manajer dapat melihat sektor yang kurang memuaskan bagi pelanggan dan dapat melakukan evaluasi mengenai servis yang ada di PT. XL Axiata.
4.2.7 Knowledge Presentation
Visualisasi dan teknik representasi pengetahuan digunakan untuk menyajikan pengetahuan yang telah diolah untuk pengguna.
4.2.7.1 Rancangan Layar
Gambar 4.26 Rancangan Layar Login
Pada saat aplikasi dijalankan, terlebih dahulu user akan diminta untuk login. Pada layar login user harus memasukan username dan password yang telah dibuat sebelumnya. Password encryption pada layar
login berupa *. Setelah memasukkan username dan password user harus
mengklik tombol login untuk masuk dalam program. Tombol database config berfungsi untuk menampilkan database yang akan dipakai sebagai
sumber data yang akan digunakan. Tombol exit digunakan untuk membatalkan login dan keluar dari program.
Gambar 4.27 Rancangan Layar User List
Rancangan layar user list berfungsi untuk menampilkan user yang sudah terdaftar pada aplikasi data mining XL centre. Terdapat tombol edit pada layar ini, fungsi daripada tombol edit tersebut untuk mengubah user yang sudah terdaftar dalam user list. Tombol delete berfungsi untuk menghapus data user yang sudah tersimpan pada user list. Tombol new berfungsi untuk menambah user baru.
Gambar 4.28 Rancangan Layar Input User
Rancangan layar input user berfungsi untuk input user baru yang akan menggunakan aplikasi data mining XL centre. Setelah memasukan user ID baru dan password, data akan tersimpan di dalam user list.
Gambar 4.29 Rancangan Layar Connect Database
Layar connect database berfungsi untuk menghubungkan database yang akan digunakan pada analisis data mining. Tombol test berfungsi untuk menguji apakah database sudah terhubung atau belum.
Gambar 4.30 Rancangan Layar Utama
Tampilan layar ini berfungsi untuk menampilkan system, transaction, masterfiles, reports, dan help. Tampilan layar ini, adalah
tampilan layar utama pada aplikasi data mining XL centre.
Mining Model Viewer Mining Model Viewer
Connect Model
Gambar 4.31 Rancangan Layar Mining Model Viewer
Tampilan layar ini berfungsi untuk menampilkan mining model yang ingin dilihat oleh user. Pada tampilan ini terdapat combo box berisi mining model yang bersangkutan untuk dianalisis. Sedangkan, tombol
connect berfungsi untuk menghubungkan database dengan mining model
yang sudah dipilih.
Gambar 4.32 Rancangan Layar Mining Model Rules
Tampilan layar mining model rules berfungsi untuk menampilkan mining model rules. Pada layar ini, terdapat probabilitas yang dapat
diinput oleh user untuk mengetahui prediksi yang ingin ditampilkan.
Gambar 4.33 Rancangan Layar Mining Model Itemset
Tampilan layar mining model itemset menampilkan mining model itemset yang terdiri dari barisan data, dan menampilkan prediksi yang
berupa penjelasan singkat.
Gambar 4.34 Rancangan Layar Mining Model Dependency Network
Tampilan layar ini, menampilkan mining model dependency network. Layar ini menampilkan hubungan atau keterkaitan antara data
yang satu dengan data yang lain. Terdapat scroll di sebelah kiri layar, yang berfungsi untuk mengukur tingkat keterkaitan yang paling kuat dan paling lemah.
Gambar 4.35 Rancangan Layar Mining Model Neural Network
Tampilan layar mining model neural network, menggambarkan prediksi yang berupa chart. Terdapat output attribute berupa combo box yang berfungsi untuk memasukan atribut – atribut yang ingin diprediksi
Gambar 4.36 Rancangan Layar Mining Model Cluster Diagram
Tampilan layar mining model cluster diagram, menggambarkan akan keterkaitan atribut yang saling berhubungan. Tampilan clustering dalam layar ini dapat dilihat dalam empat tampilan berbeda, yaitu cluster diagram, cluster profile, cluster characteristic, dan cluster discrimination
Terdapat scroll di sebelah kiri layar, yang berfungsi untuk mengukur tingkat keterkaitan antara cluster yang satu dengan yang lain. Semakin tinggi tingkat keterkaitannya, maka hubungan cluster tersebut semakin kuat dan jelas.
Gambar 4.37 Rancangan Layar Mining Model Clustering Profile
Tampilan layar mining model clustering profile, menggambarkan tingkat atribut dengan diagram batang. Tampilan clustering dalam layar ini dapat dilihat dalam empat tampilan berbeda, yaitu cluster diagram, cluster profile, cluster characteristic, dan cluster discrimination.
Gambar 4.38 Rancangan Layar Mining Model Cluster Characteristic
Tampilan layar mining model cluster characteristic,
menggambarkan atribut yang terkait berupa chart yang terdapat prediksi – prediksi di dalamnya. Tampilan clustering dalam layar ini dapat dilihat
dalam empat tampilan berbeda, yaitu cluster diagram, cluster profile, cluster characteristic, dan cluster discrimination.
Gambar 4.39 Rancangan Layar Mining Model Cluster Discrimination
Tampilan layar mining model cluster discrimination
menggambarkan atribut dalam bentuk chart, namun terdapat dua hasil output yang berbeda. Tampilan clustering dalam layar ini dapat dilihat
dalam empat tampilan berbeda, yaitu cluster diagram, cluster profile, cluster characteristic, dan cluster discrimination.
4.2.7.2 Navigation Diagram
Berikut ini adalah navigation diagram yang menggambarkan struktur alur aplikasi
4.3 Implementation Plan
Tabel 4.3 Implementation Plan
Kegiatan
Bulan
No 1 2
1 2 3 1 2 3 4
1. Pengadaan hardware, jaringan, dan
software