PENGUJIAN HIPOTESIS DUA SAMPEL INDEPENDEN BERDASARKAN UJI MANN-WHITNEY DAN UJI KOLMOGOROV SMIRNOV DUA SAMPEL SERTA SIMULASINYA DENGAN PROGRAM SPSS
Bebas
111
0
0
Teks penuh
Gambar


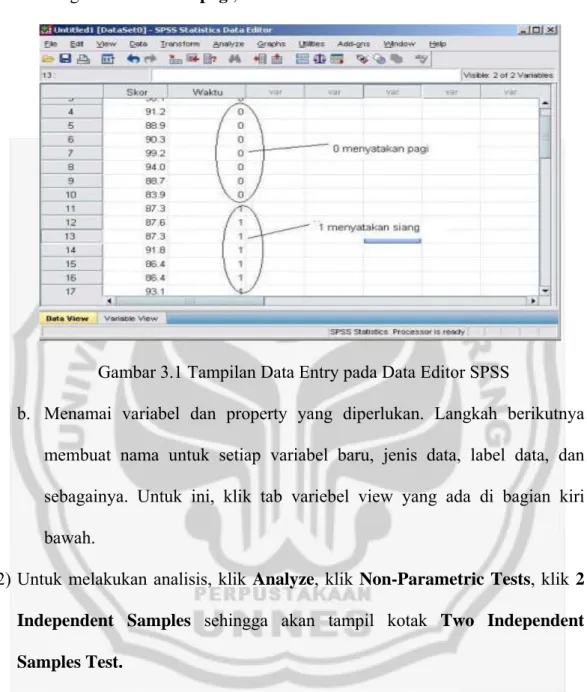
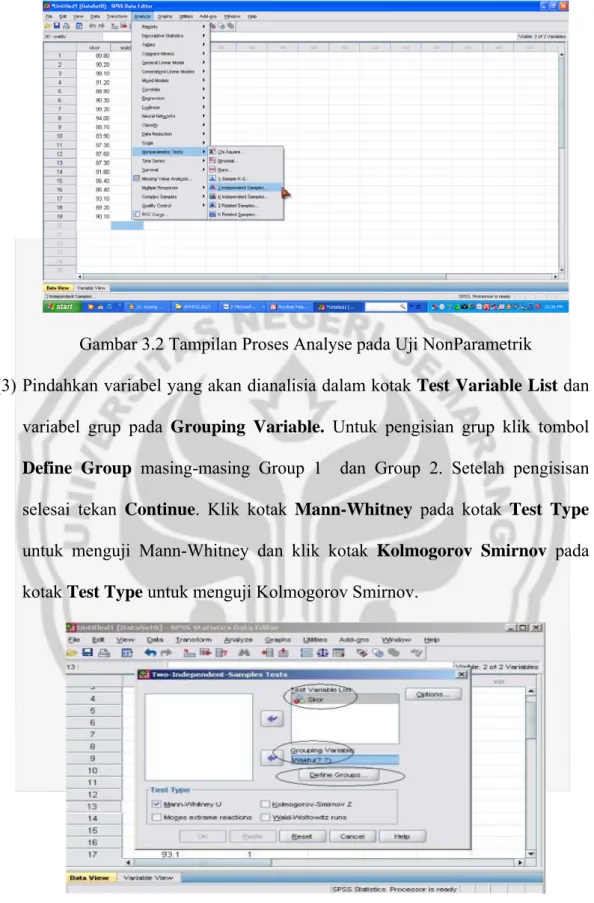
+7


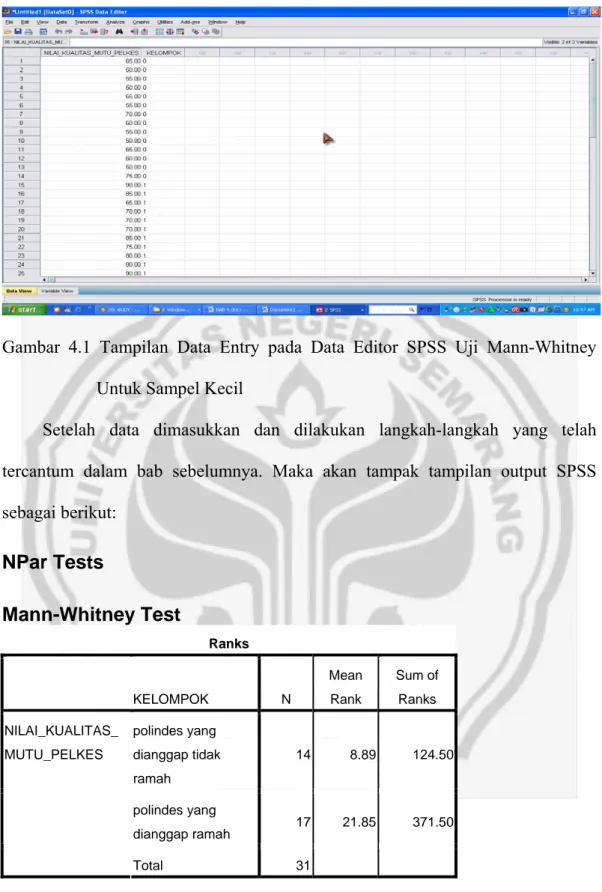
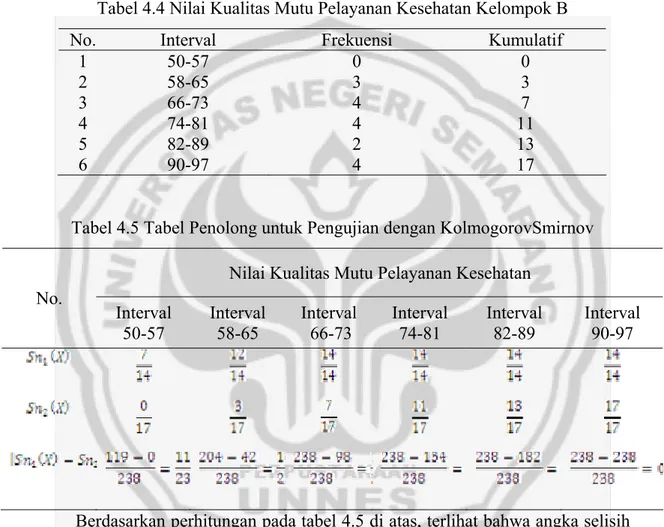

Garis besar
Dokumen terkait
