JARINGAN SARAF HIBRIDA PB-SKNC DAN APLIKASINYA PADA PENGENALAN AROMA
Benyamin Kusumoputro, Ari Saptawijaya*
ABSTRAK
JARINGAN SARAF HIBRIDA PB-SKNC DAN APLIKASINYA PADA PENGENALAN AROMA. Salah satu tujuan penelitian terhadap jaringan saraf tiruan adalah untuk meningkatkan
kemampuan pengenalan dan mempersingkat waktu pelatihan jaringan. Kedua hal ini dapat dicapai dengan mengkombinasikan dua tipe pelatihan pada jaringan saraf tiruan, yaitu pelatihan dengan pengarahan dan pelatihan tanpa pengarahan. Jaringan saraf hibrida PB-SKNC dibangun dari jaringan saraf propagasi balik yang memiliki tipe pelatihan dengan pengarahan dan jaringan saraf swa-organisasi yang memiliki tipe pelatihan tanpa pengarahan. Jaringan saraf swa-organisasi yang membangun jaringan saraf hibrida ini telah dimodifikasi dengan memperhatikan sejarah kemenangan neuron cluster dalam proses pelatihannya. Dengan menggunakan sejarah kemenangan ini, dilakukan operasi pembentukan neuron cluster yang memiliki probabilitas kemenangan tinggi dan penghapusan neuron cluster yang memiliki probabilitas kemenangan rendah. Kedua operasi ini memungkinkan seluruh neuron cluster terdistribusi menurut data masukan. Adanya distribusi seluruh neuron cluster terhadap data masukan akan mempersingkat waktu pelatihan jaringan saraf hibrida ini, sedangkan kemampuan pengenalan yang baik dicapai melalui pelatihan dengan pengarahan. Dalam aplikasinya pada pengenalan aroma, jaringan saraf hibrida PB-SKNC menunjukkan kemampuan pengenalan yang baik dan waktu pelatihan yang lebih singkat dibandingkan dengan jaringan saraf hibrida PB-Adaptif yang pernah dikembangkan sebelumnya.
ABSTRACT
PB-SKNC HYBRID NEURAL NETWORK. One of the goals in the research on artificial
neural network (ANN) is to improve the recognition ability of the network for some patterns and at the same time minimize the time needed for learning the patterns. These two goals can be achieved by combining two types of learning in artificial neural network, i.e. supervised learning and unsupervised learning. We have developed a hybrid ANN which we named PB-SKNC. This proposed network is built from back propagation neural network (PB – Propagasi Balik – in Indonesia) with its supervised learning and self-organizing neural network with its unsupervised learning. The self-organizing neural network used in this hybrid ANN has already modified by concerning cluster neuron winning history (SKNC – Sejarah Kemenangan Neuron Cluster – in Indonesia) in its learning algorithm. By concerning this winning history, creation and deletion operation of cluster neuron can be done. Cluster neuron with high winning probability is created while cluster neuron with low winning probability is deleted from the network. These two operations together will distribute all cluster neurons according to the patterns given. The distribution of all cluster neurons will improve the learning time of this hybrid ANN while good recognition ability can still be achieved through supervised learning that is also implemented in this new network. In its application on odor discrimination, PB-SKNC showed good recognition ability and shorter learning time than another hybrid ANN, i.e. PB-Adaptif that has already been built before.
*
PENDAHULUAN Latar Belakang
Secara umum terdapat dua tipe pelatihan jaringan saraf tiruan, yaitu pelatihan dengan pengarahan (supervised training) dan pelatihan tanpa pengarahan (unsupervised training). Salah satu jaringan saraf tiruan yang menggunakan algoritma pelatihan dengan pengarahan adalah jaringan saraf propagasi balik (backpropagation
neural network), sedangkan yang menggunakan algoritma pelatihan tanpa pengarahan
adalah jaringan saraf swa-organisasi (self-organizing neural network). Jaringan saraf propagasi balik memiliki kemampuan generalisasi yang baik, namun memerlukan waktu pelatihan yang lama [1]. Di lain pihak, jaringan saraf swa-organisasi memiliki kemampuan mengelompokkan data masukan dan memerlukan waktu pelatihan yang singkat [2],[3]. Dengan mengkombinasikan kedua jaringan saraf ini dapat dihasilkan suatu jaringan saraf hibrida yang memiliki kemampuan generalisasi yang baik dan waktu pelatihan yang singkat [3].
Suatu penelitian telah dilakukan untuk mengembangkan jaringan saraf hibrida dengan terlebih dahulu memodifikasi jaringan saraf swa-organisasi menggunakan mekanisme adaptif [4]. Hasil pengujian pada pengenalan aroma menunjukkan, bahwa kinerja jaringan ini lebih baik dibandingkan jaringan saraf Propagasi Balik [4]. Jaringan saraf hibrida ini (selanjutnya dapat disebut jaringan saraf hibrida
PB-Adaptif) masih memiliki kekurangan. Pada kasus distribusi data masukan sulit
dipisahkan, jaringan ini dengan mekanisme adaptifnya akan membentuk banyak neuron cluster. Walaupun demikian, beberapa neuron cluster yang dibentuk sebenarnya tidak diperlukan. Kelebihan jumlah neuron cluster ini akan mengakibatkan lamanya waktu pelatihan.
Makalah ini menawarkan alternatif lain dari jaringan saraf hibrida ini dengan mengkombinasikan jaringan saraf Propagasi Balik dan jaringan saraf swa-organisasi berbasiskan Sejarah Kemenangan Neuron Cluster (selanjutnya dapat disebut jaringan
saraf hibrida PB-SKNC). Di samping sebagai alternatif lain, jaringan ini juga
diharapkan dapat memperbaiki jaringan saraf hibrida yang telah dikembangkan sebelumnya.
Tujuan
Penelitian yang dilakukan bertujuan untuk mengembangkan suatu jaringan saraf hibrida baru yang mengkombinasikan jaringan saraf propagasi balik dan jaringan saraf swa-organisasi berbasiskan sejarah kemenangan neuron cluster sebagai alternatif jaringan saraf tiruan yang telah ada. Arsitektur dan kinerja jaringan baru diamati
dengan membandingkannya dengan jaringan saraf hibrida PB-Adaptif pada aplikasi pengenalan aroma dengan atau tanpa penambahan noise.
Ruang Lingkup
Pengujian kinerja jaringan saraf hibrida PB-SKNC pada penelitian ini dilakukan pada aplikasi pengenalan aroma dari suatu sistem penciuman elektronik [5]. Penelitian dibatasi hanya pada bagian jaringan saraf tiruan, sedangkan bagian-bagian lain dari sistem penciuman elektronik seperti prapemrosesan aroma tidak dibahas dalam makalah ini.
LANDASAN TEORI
Jaringan Saraf Propagasi Balik
Jaringan saraf propagasi balik terdiri dari beberapa lapisan, yaitu lapis masukan, satu atau lebih lapis tersembunyi, dan lapis keluaran. Setiap lapisan terhubung penuh (fully connected) dengan lapisan berikutnya [1].
Pelatihan atau pembelajaran pada jaringan saraf propagasi balik merupakan pelatihan dengan pengarahan. Setiap data masukan yang disebut juga vektor
pelatihan memiliki pasangan vektor target yang akan mengarahkan proses pelatihan
jaringan. Pelatihan pada jaringan saraf propagasi balik terdiri dari tiga tahapan, yaitu
tahapan maju, tahapan propagasi balik kesalahan, dan tahapan perbaikan bobot.
Jaringan Saraf Swa-Organisasi
Jaringan saraf swa-organisasi hanya terdiri dari lapis masukan dan lapis keluaran. Jaringan ini tidak memiliki lapis tersembunyi. Seperti pada jaringan saraf propagasi balik, setiap neuron pada lapisan yang satu terhubung dengan setiap neuron pada lapisan berikutnya (fully connected).
Pelatihan atau pembelajaran pada jaringan saraf swa-organisasi merupakan pelatihan tanpa pengarahan. Dalam proses pelatihannya hanya diperlukan vektor pelatihan, sedangkan vektor target tidak diperlukan. Dengan vektor-vektor pelatihan ini, jaringan mencoba menemukan pola atau keteraturan dari data masukan [1],[2].
Pelatihan pada jaringan ini menggunakan skema kompetisi (competitive
learning). Setiap neuron cluster berkompetisi dan pada akhir kompetisi hanya satu
dilatihkan (winner-take-all). Neuron cluster yang aktif ini menjadi pemenang dari kompetisi tersebut.
Pelatihan jaringan dilakukan dengan mengarahkan vektor bobot neuron pemenang mendekati vektor pelatihan yang sedang dilatihkan, hingga pada akhir proses pelatihan vektor bobot suatu neuron cluster dapat menjadi pewakil bagi data masukan yang terkelompok dalam neuron cluster tersebut.
METODOLOGI
Jaringan Saraf Swa-organisasi Berbasiskan Sejarah Kemenangan Neuron Cluster
Jaringan saraf swa-organisasi berbasiskan sejarah kemenangan neuron cluster (SKNC) merupakan salah satu modul dari jaringan saraf hibrida PB-SKNC. Jaringan saraf ini merupakan modifikasi dari jaringan saraf swa-organisasi standar yang telah dijelaskan sebelumnya. Modifikasi dilakukan pada bagian algoritma pelatihan sedangkan arsitektur jaringan tidak mengalami perubahan. Modifikasi ini dilatarbelakangi oleh permasalahan yang muncul pada algoritma pelatihan jaringan saraf swa-organisasi yang menggunakan skema kompetisi.
Dalam skema kompetisi standar, neuron cluster dengan vektor bobot paling dekat dengan vektor pelatihan dipilih sebagai pemenang kompetisi dan proses belajar dilakukan dengan memperbaiki vektor bobot neuron pemenang tersebut. Di lain pihak, neuron-neuron dengan vektor bobot yang jauh dari vektor-vektor pelatihan tidak akan pernah menjadi pemenang. Akibatnya neuron-neuron tersebut tidak akan pernah belajar. Dengan demikian, skema kompetisi standar pada umumnya tidak menghasilkan himpunan vektor bobot yang optimal. Himpunan vektor bobot yang optimal akan dicapai apabila setiap neuron cluster memiliki kesempatan yang sama untuk memenangkan kompetisi [6].
Permasalahan ini dicoba diatasi dengan menerapkan mekanisme adaptif pada skema kompetisi dalam pelatihan jaringan saraf swa-organisasi. Dengan mekanisme ini, pada akhir proses pelatihan diperoleh distribusi neuron cluster menurut data masukan [7]. Hal ini berarti setiap neuron cluster memiliki kesempatan yang sama untuk memenangkan kompetisi. Namun di lain pihak, pada kasus distribusi data masukan sulit dipisahkan, mekanisme ini membentuk banyak neuron cluster, walaupun sebenarnya beberapa dari neuron cluster tersebut telah mencerminkan distribusi dari neuron cluster terhadap data masukan.
Jaringan saraf swa-organisasi berbasiskan SKNC mampu memperbaiki kelemahan skema kompetisi standar sekaligus menjadi alternatif bagi mekanisme adaptif. Dalam proses pelatihan jaringan ini, sejarah kemenangan neuron cluster
disimpan dalam suatu tabel sejarah pemenang. Detail algoritma pelatihan jaringan ini adalah sebagai berikut :
Langkah 0. Inisialisasi informasi bagi setiap neuron cluster (bobot, dll.).
Langkah 1. Selama kondisi henti tidak terpenuhi, lakukan Langkah 2 –10
Langkah 2. Untuk setiap vektor pelatihan, lakukan Langkah 3 – 9
Langkah 3. Hitung nilai similaritas setiap neuron cluster terhadap vektor pelatihan
dengan menggunakan jarak Mahalanobis.
Langkah 4. Tentukan neuron cluster pemenang.
Langkah 5. Perbarui tabel sejarah pemenang.
Langkah 6. Hitung probabilitas kemenangan setiap neuron cluster
Langkah 7. Tentukan apakah operasi pembentukan dan penghapusan neuron cluster
akan dilakukan atau tidak. Jika operasi ini dilakukan, lakukan langkah 8. Jika tidak, lakukan langkah 9.
Langkah 8. Bentuk satu neuron cluster baru sebagai duplikat neuron pemenang dan
buang neuron cluster terlemah dari jaringan.
Langkah 9. Lakukan perbaikan informasi (bobot, dll.) untuk neuron pemenang.
Langkah 10. Uji kondisi henti.
Neuron cluster pemenang ditentukan dengan menggunakan nilai similaritas. Nilai similaritas suatu neuron cluster merupakan ukuran kemiripan antara suatu vektor pelatihan dan vektor bobot neuron cluster tersebut. Nilai similaritas suatu neuron
cluster dihitung dengan terlebih dahulu menghitung jarak antara vektor bobot neuron cluster tersebut dengan vektor pelatihan menggunakan jarak Mahalanobis. Jarak ini
digunakan karena mampu merepresentasikan distribusi data masukan yang lebih kompleks dibandingkan jarak Euclidean [7]. Untuk menghitung jarak Mahalanobis, setiap neuron cluster j menyimpan informasi jumlah total anggota (tj), vektor bobot
(w.j), matriks variansi kesalahan (Vj).
Bila n menyatakan dimensi dari setiap vektor pelatihan, maka vektor pelatihan ke-k dapat direpresentasikan sebagai berikut (T menyatakan transpose suatu matriks) :
y(k) = [y1(k), y2(k),…, yn(k)] T
(1) Matriks variansi kesalahan memiliki bentuk sebagai berikut :
Vj = diag [σ 2 1j, σ 2 2j,…, σ 2 nj] (2)
Inisialisasi informasi pada setiap neuron cluster j adalah sebagai berikut [3]:
§ tj = 1. (3)
§ w.j diinisialisasi dengan bilangan acak antara –0,5 hingga 0,5.
§ elemen σ2ij pada Vj :
σ2
Nilai similaritas (dj) dan jarak Mahalanobis (Dj) dihitung sebagai berikut : dj = exp
−
2n
D
j (5) Dj = α. ej T . Vj -1 . ej (6) ej = y – w.j (7)Pada persamaan (6) di atas, α merupakan faktor penyearah (0 < α ≤ 1) dan Vj -1
merupakan invers dari matriks Vj seperti yang tertulis pada persamaan (2).
Neuron cluster pemenang kemudian disimpan dalam tabel sejarah pemenang yang memiliki ukuran tertentu. Penambahan entri neuron pemenang ke dalam tabel sejarah pemenang mengikuti aturan FIFO (First In First Out), artinya jika tabel telah penuh maka entri yang paling lama berada dalam tabel akan dihapus sebelum dilakukan penambahan neuron pemenang baru ke dalam tabel. Probabilitas kemenangan setiap neuron cluster j (pj) dihitung dengan persamaan berikut :
pj = all j
E
E
(8)Ej pada persamaan (8) merepresentasikan jumlah entri neuron cluster j dalam tabel
sejarah pemenang, sedangkan Eall merupakan jumlah total entri dalam tabel.
Keputusan untuk melakukan operasi pembentukan dan penghapusan neuron
cluster didasarkan atas probabilitas kemenangan dari setiap neuron cluster. Kedua
operasi ini dipandang sebagai suatu operasi atomik. Artinya, setiap pembentukan satu neuron cluster baru akan diikuti pula dengan penghapusan satu neuron cluster yang lain. Dengan demikian, jumlah neuron cluster akan selalu tetap. Keputusan ini ditentukan oleh terpenuhinya kondisi berikut [6]:
(pr≥
m
Cr
) ∨ ((ps≤m
De
) ∧ (pr = max (pj))) (9)Nilai pr pada kondisi di atas menunjukkan probabilitas kemenangan neuron pemenang
r, sedangkan ps menunjukkan probabilitas kemenangan neuron terlemah s. Neuron
terlemah adalah neuron dengan nilai probabilitas kemenangan terkecil. Notasi pj
menunjukkan probabilitas kemenangan sembarang neuron j dan notasi m menunjukkan jumlah neuron cluster. Pada kondisi (9) di atas terdapat dua nilai ambang, yaitu Cr dan De. Nilai ambang Cr merupakan nilai ambang untuk operasi pembentukan sebuah neuron cluster baru bagi neuron pemenang yang memiliki
probabilitas kemenangan tinggi, sedangkan De merupakan nilai ambang untuk operasi penghapusan neuron yang memiliki probabilitas kemenangan sangat rendah.
Jika kondisi di atas terpenuhi, maka operasi pembentukan dan penghapusan neuron cluster akan dilakukan. Operasi pembentukan neuron cluster dilakukan dengan membentuk satu neuron cluster baru r' yang merupakan duplikat dari neuron pemenang r. Sebagai konsekuensinya, neuron r' memiliki vektor bobot dan variansi kesalahan yang sama dengan neuron r :
w.r' = w.r (10)
σ2
ir ' = σ
2
ir , untuk semua i (11)
Untuk jumlah total anggota, neuron r dan neuron r' membagi dua jumlah total anggota yang semula dimiliki oleh neuron pemenang r :
t r =
2
(semula)
t
r ; t r ' =
2
(semula)
t
r (12)Untuk persamaan (12) perlu ditambahkan kondisi berikut :
jika (t r ' = 0) maka (t r ' = 1) (13)
Kondisi (13) diperlukan untuk menjamin agar nilai minimal jumlah total anggota suatu neuron cluster sama dengan nilai inisialisasinya seperti yang ditunjukkan pada persamaan (3).
Neuron baru r' dan neuron pemenang r juga membagi dua probabilitas kemenangan neuron r semula :
pr = all r all
E
2
(semula)
p
E
⋅
; pr ' = all r allE
2
(semula)
p
E
⋅
(14)Selanjutnya, entri neuron pemenang r yang ada pada tabel sejarah pemenang disubstitusi secara bergantian dengan neuron r dan neuron baru r'. Hal ini dapat dipandang sebagai konsekuensi pembagian probabilitas kemenangan antara neuron r dan neuron r' di atas.
Operasi penghapusan neuron cluster dilakukan dengan membuang neuron
cluster terlemah s dari jaringan dan menghapus setiap kemunculan entri neuron s pada
Langkah terakhir dari proses pelatihan jaringan ini adalah melakukan perbaikan nilai bobot, variansi kesalahan, dan jumlah total anggota, khusus bagi neuron pemenang r. Hal ini berlaku, baik operasi pembentukan neuron baru dilakukan ataupun tidak dilakukan. Perbaikan ketiga nilai informasi neuron pemenang ini dilakukan sebagai berikut :
wir (baru) = Γ0 . wir (lama) + Γ1 . yi , untuk semua i (15)
Γ0 =
(baru)
t
(lama)
t
r r dan Γ1 =(baru)
t
1
r (16) tr (baru) = λ . tr (lama) + 1 (17) σ2 ir (baru) = Γ0 . σ 2 ir + 0 1Ã
Ã
. (yi – wir (baru)) 2 (18) Notasi λ pada persamaan (17) merupakan forgetting factor (0 < λ < 1).Jaringan Saraf Hibrida PB-SKKNC
Jaringan saraf hibrida PB-SKNC merupakan kombinasi dari jaringan saraf swa-organisasi berbasiskan sejarah kemenangan neuron cluster (SKNC) yang memiliki tipe pelatihan tanpa pengarahan dan jaringan saraf propagasi balik yang memiliki tipe pelatihan dengan pengarahan. Arsitektur jaringan ini memiliki kemiripan dengan arsitektur jaringan saraf propagasi balik. Perbedaannya terletak pada lapis tersembunyi. Lapis tersembunyi pada jaringan saraf hibrida ini merupakan lapis keluaran dari jaringan saraf swa-organisasi berbasiskan SKNC. Gambar 1 menunjukkan arsitektur jaringan saraf hibrida PB-SKNC.
Gambar 1. Arsitektur jaringan saraf hibrida PB-SKNC.
Modul Swa-Organisasi Modul Propagasi Balik
Proses pelatihan pada jaringan ini terdiri dari dua tahap. Tahap pertama merupakan pelatihan tanpa pengarahan, yaitu pelatihan yang dilakukan oleh jaringan saraf swa-organisasi berbasiskan SKNC, sedangkan tahap kedua merupakan pelatihan dengan pengarahan yang dilakukan oleh modul propagasi balik. Pelatihan tahap pertama bertujuan untuk membentuk vektor bobot inisial bagi neuron-neuron lapis tersembunyi yang representatif terhadap karakteristik data masukan untuk digunakan selanjutnya pada pelatihan tahap kedua. Dengan demikian, bobot neuron lapis tersembunyi tidak lagi bernilai acak pada tahap inisialisasinya sehingga pelatihan tahap kedua dapat dilakukan dengan lebih cepat. Pelatihan tahap kedua bertujuan untuk mengenali data masukan sesuai dengan target yang diberikan.
Pelatihan tahap kedua secara umum menggunakan mekanisme pelatihan jaringan saraf propagasi balik standar dengan beberapa modifikasi untuk menyesuaikan keberadaan modul propagasi balik sebagai bagian dari jaringan saraf hibrida PB-SKNC secara keseluruhan. Pada tahap inisialisasi, bobot neuron lapis tersembunyi tidak perlu diinisialisasi kembali dengan bilangan acak, karena bobot pada lapisan ini telah didapat langsung dari hasil pelatihan tahap pertama.
Dalam perhitungan nilai aktivasi, fungsi yang digunakan untuk menghitung nilai aktivasi neuron pada lapis tersembunyi berbeda dengan fungsi aktivasi yang digunakan neuron pada lapis keluaran. Pada lapis tersembunyi, nilai similaritas setiap neuron cluster terhadap data masukan yang sedang dilatihkan menjadi nilai aktivasi bagi neuron tersebut [3]. Dengan demikian, untuk menghitung nilai aktivasi ini digunakan persamaan-persamaan yang telah dibahas sebelumnya, yaitu persamaan (2), (5), (6), dan (7). Pada lapis keluaran, nilai aktivasi bagi setiap neuron dihitung dengan menggunakan fungsi sigmoid biner. Misalkan jaringan ini memiliki n neuron masukan, p neuron tersembunyi, dan m neuron keluaran, maka nilai aktivasi untuk setiap neuron keluaran (
y
k) dihitung sebagai berikut :k k) y_ink
∑
=⋅
+
p 1 j j jk kw
d
è
(20) sigmoid (x) = −xk
t
, maka informasi kesalahan untuk neuron keluaran k (ξk) tersebut dihitung sebagai berikut :ξk =
2
⋅
(t
k−
y
k)
⋅
y
k⋅
(1
−
y
k)
(22)Nilai informasi kesalahan ini (ξk) digunakan untuk menghitung koreksi bobot pada
lapis keluaran (∆wjk). Koreksi bobot tersebut dihitung sebagai berikut :
∆wjk (baru) = η.ξk.dj + ε.∆wjk (lama) (23)
Dengan menggunakan informasi kesalahan yang sama (ξk), koreksi bobot pada lapis
tersembunyi (∆vij) dapat dihitung sebagai berikut :
∆vij (baru) =
å'
Äv
(lama)
ó
x
v
á
d
w
î
n
ç'
ij m 1 k 2ij i ij j jk k
+
−
∑
= (24)Notasi η dan ε masing-masing menunjukkan learning rate dan momentum untuk koreksi bobot pada lapis keluaran, sedangkan notasi
η
'
danε
'
masing-masing menunjukkan learning rate dan momentum untuk koreksi bobot pada lapis tersembunyi. Faktor α merupakan faktor penyearah yang digunakan pada pelatihan tahap pertama jaringan saraf hibrida ini. Di samping untuk menghitung koreksi bobot, informasi kesalahan (ξk) juga digunakan untuk memperbaiki nilai bias pada setiapneuron keluaran k (θk) :
θk (baru) = θk (lama) + η.ξk (25)
Perbaikan bobot-bobot pada lapis keluaran dan bobot-bobot pada lapis tersembunyi dilakukan secara simultan setelah koreksi bobot pada kedua lapisan dihitung. Perbaikan bobot pada lapis keluaran dapat dihitung sebagai berikut :
jk
w
(baru) =w
jk (lama) + ∆w
jk (26)Analog dengan perbaikan bobot pada lapis keluaran, bobot pada lapis tersembunyi diperbaiki dengan persamaan berikut :
ij
UJI COBA DAN HASIL Lingkungan dan Data Uji Coba
Uji coba dilakukan pada komputer dengan prosesor Pentium 166 Mhz dan
memory 32 MB. Untuk data uji coba digunakan data aroma produk Martha Tilaar dan
data sintetik yang berfungsi sebagai noise bagi data aroma tersebut. Data aroma produk Martha Tilaar yang digunakan terdiri dari tiga jenis aroma, yaitu aroma mawar, kenanga, dan jeruk sedangkan untuk data sintetik terdiri dari dua kelas. Dari dua kelas data sintetik ini, salah satu kelas tidak diikutkan dalam proses pelatihan dan hanya digunakan untuk keperluan pengujian.
Untuk kasus sederhana hanya digunakan data aroma produk Martha Tilaar tanpa melibatkan data sintetik yang berfungsi sebagai noise. Untuk kasus yang lebih kompleks digunakan keseluruhan kelas data (data aroma dan data sintetik) dengan tujuan untuk mengamati kemampuan jaringan dalam mengklasifikasikan aroma sesuai dengan kelasnya masing-masing dan sekaligus memisahkan noise dari ketiga kelas aroma tersebut. Baik pada kasus sederhana maupun kasus kompleks, lapis masukan jaringan saraf hibrida PB-SKNC terdiri dari 4 neuron.
Hasil Uji Coba dan Pembahasan
Jaringan yang digunakan untuk kasus sederhana terdiri dari 4 neuron tersembunyi dan 3 neuron keluaran sehingga memiliki konfigurasi lapis masukan, lapis tersembunyi, dan lapis keluaran 4-4-3. Kondisi uji coba yang digunakan adalah sebagai berikut : ukuran tabel sejarah pemenang = 10, batas epoch pelatihan tahap pertama = 1, α = 0.8, λ = 0.9999, Cr = 2, De = 0.02, batas toleransi kesalahan pelatihan tahap kedua = 0.004, η = 0.8, ε = 0.8, η’= ε’= 0.
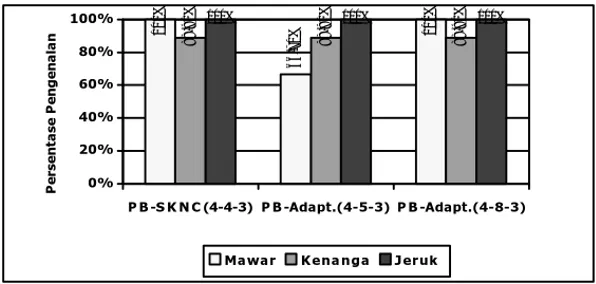
Untuk keperluan perbandingan, dilakukan pula uji coba pada jaringan saraf hibrida PB-Adaptif dengan kondisi uji coba sama seperti di atas, kecuali tanpa faktor Cr dan De. Nilai ambang pembentukan neuron cluster (merupakan neuron pada lapis tersembunyi) yang digunakan adalah 0.99 (diperoleh konfigurasi 4-8-3) dan 0.97 (diperoleh konfigurasi 4-5-3). Gambar 2 menunjukkan perbandingan waktu pelatihan jaringan saraf hibrida PB-SKNC dengan kondisi di atas dan kedua konfigurasi jaringan saraf hibrida Adaptif. Kedua jaringan saraf hibrida (SKNC dan PB-Adaptif) mampu mengenal seluruh data yang telah dilatih (100%), sedangkan perbandingan persentase pengenalan data yang belum dilatih oleh kedua jaringan ditunjukkan oleh gambar 3.
Gambar 2. Perbandingan waktu pelatihan untuk kasus sederhana.
Gambar 3. Perbandingan persentase pengenalan data yang belum dilatih untuk kasus sederhana.
Dari gambar 2 dan gambar 3 terlihat, bahwa jaringan saraf hibrida PB-SKNC dengan waktu pelatihan yang jauh lebih singkat memiliki kemampuan pengenalan data yang belum dilatih lebih baik dibandingkan jaringan saraf hibrida PB-Adaptif 4-5-3 untuk aroma mawar.
Jaringan yang digunakan untuk kasus kompleks terdiri dari 6 neuron tersembunyi dan 4 neuron keluaran sehingga memiliki konfigurasi lapis masukan, lapis tersembunyi, dan lapis keluaran 4-6-4. Kondisi uji coba yang digunakan adalah sebagai berikut : ukuran tabel sejarah pemenang = 10, batas epoch pelatihan tahap pertama = 1, α = 0.8, λ = 0.9999, Cr = 2, De = 0.02, batas toleransi kesalahan pelatihan tahap kedua = 0.0027, η = 0.8, ε = 0.9, η’= ε’= 0.
Seperti halnya pada kasus sederhana, dilakukan pula uji coba pada jaringan saraf hibrida PB-Adaptif dengan kondisi uji coba sama seperti di atas (tanpa faktor Cr dan De). Nilai ambang pembentukan neuron cluster (merupakan neuron pada lapis
0 5.26 5.45 1.05 18.39 32.49 1.05 23.65 37.94 0 10 20 30 40 PB-SKNC(4-4-3) PB-Adapt.(4-5-3) PB-Adapt.(4-8-3)
Waktu Pelatihan (detik)
Pelatihan Tahap 1 Pelatihan Tahap 2 Total Waktu
100% 66.70% 100% 88.90% 88.90% 88.90% 100% 100% 100% 0% 20% 40% 60% 80% 100% P B -S K N C (4-4-3) P B -Adapt.(4-5-3) P B -Adapt.(4-8-3) Persentase Pengenalan
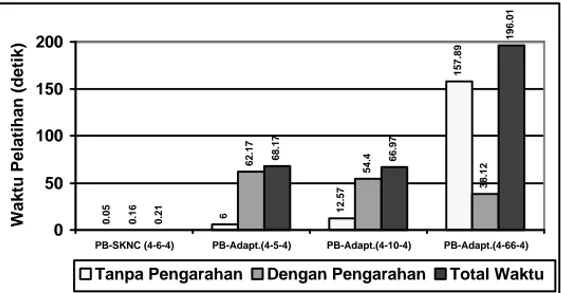
tersembunyi) yang digunakan adalah 0.97 (diperoleh konfigurasi 4-66-4), 0.94 (diperoleh konfigurasi 4-10-4), dan 0.93 (diperoleh konfigurasi 4-5-4). Gambar 4 menunjukkan perbandingan waktu pelatihan jaringan saraf hibrida PB-SKNC dengan kondisi di atas dan ketiga konfigurasi jaringan saraf hibrida PB-Adaptif.
Gambar 4. Perbandingan waktu pelatihan untuk kasus kompleks.
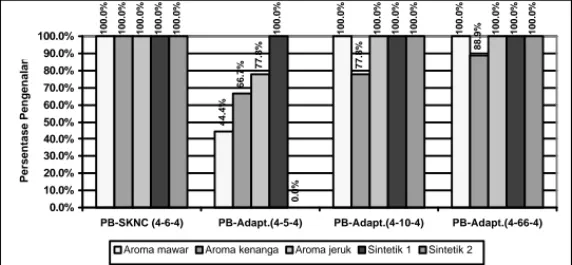
Pada kasus kompleks, baik jaringan saraf hibrida PB-SKNC maupun jaringan saraf hibrida PB-Adaptif mampu mengenal seluruh aroma yang telah dilatih (100%), kecuali untuk jaringan saraf hibrida PB-Adaptif dengan konfigurasi 4-5-4 yang mengenal data aroma mawar hanya sebesar 95.2%. Perbandingan persentase pengenalan data yang belum dilatih untuk kedua jaringan saraf hibrida ditunjukkan oleh gambar 5. Dari gambar 4 dan gambar 5 terlihat, bahwa jaringan saraf hibrida PB-SKNC dengan waktu pelatihan yang jauh lebih singkat memiliki kemampuan pengenalan data yang belum dilatih lebih baik dibandingkan jaringan saraf hibrida PB-Adaptif 4-5-4 (untuk aroma mawar, jeruk, kenanga, dan sintetik 2) dan aroma kenanga untuk PB-Adaptif konfigurasi 4-10-4 dan 4-66-4. Uji coba ini juga menunjukkan, bahwa jaringan saraf hibrida PB-SKNC memiliki kemampuan untuk memisahkan noise dari ketiga aroma yang ada dengan baik, bahkan untuk noise yang belum pernah dilatih sama sekali.
0.05 6 12.57 157.89 0.16 62.17 54.4 38.12 0.21 68.17 66.97 196.01 0 50 100 150 200
PB-SKNC (4-6-4) PB-Adapt.(4-5-4) PB-Adapt.(4-10-4) PB-Adapt.(4-66-4)
Waktu Pelatihan (detik)
Gambar 5. Perbandingan persentase pengenalan data yang belum dilatih untuk kasus kompleks.
KESIMPULAN DAN SARAN
Dari uji coba yang telah dilakukan dapat disimpulkan, bahwa jaringan saraf swa-organisasi sebagai salah satu modul dari jaringan saraf hibrida dapat dimodifikasi dengan memperhatikan sejarah kemenangan neuron cluster. Modifikasi ini mampu memperbaiki jaringan saraf swa-organisasi standar dalam hal pembentukan distribusi neuron cluster terhadap data masukan. Hal ini sangat berguna dalam membentuk representasi internal yang baik dari karakteristik data masukan bagi jaringan saraf hibrida PB-SKNC sehingga waktu pelatihan jaringan juga menjadi lebih singkat.
Jaringan saraf hibrida PB-SKNC dibangun dengan mengkombinasikan jaringan saraf swa-organisasi yang berbasiskan sejarah kemenangan neuron cluster dan jaringan saraf propagasi balik. Dalam aplikasinya pada pengenalan aroma, jaringan saraf hibrida PB-SKNC menunjukkan kemampuan pengenalan yang baik. Dalam beberapa uji coba yang telah dilakukan, jaringan ini bahkan menunjukkan kemampuan pengenalan yang lebih baik dibandingkan dengan jaringan saraf hibrida PB-Adaptif. Dengan ukuran jaringan yang relatif lebih kecil dibandingkan dengan jaringan saraf hibrida PB-Adaptif (dengan mengurangi jumlah neuron cluster sebagai neuron pada lapis tersembunyi), jaringan saraf hibrida PB-SKNC membutuhkan waktu pelatihan lebih singkat dibandingkan dengan jaringan saraf hibrida PB-Adaptif. Sebagai saran bagi penelitian mendatang, jaringan dapat diaplikasikan lebih lanjut pada permasalahan lainnya. Dengan demikian, kemampuan jaringan ini akan lebih teruji.
100.0% 44.4% 100.0% 100.0% 66.7% 77.8% 88.9% 100.0% 77.8% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 0.0% 100.0% 100.0% 100.0% 0.0% 10.0% 20.0% 30.0% 40.0% 50.0% 60.0% 70.0% 80.0% 90.0% 100.0%
PB-SKNC (4-6-4) PB-Adapt.(4-5-4) PB-Adapt.(4-10-4) PB-Adapt.(4-66-4)
Persentase Pengenalan
DAFTAR PUSTAKA
1. RICH, E. and KEVIN KNIGHT., Artificial Intelligence, Singapore : McGraw-Hill, Inc. (1991)
2. FAUSETT, L., Fundamentals of Neural Networks : Architectures, Algorithms,
and Applications, New Jersey : Prentice-Hall, Inc. (1994)
3. YOSHIKAZU MIYANAGA, HONG LAN JIN, RAFIQUL ISLAM and KOJI
TOCHINAI. "A Self-organized Network with a Supervised Training", IEEE
ISCAS, May (1995) 482-485
4. ROSTIVIANI, L., Modifikasi Jaringan Propagasi Balik Menggunakan Modul
Swa-Organisasi Adaptif : Karakteristik dan Implementasi, Depok : Fakultas Ilmu
Komputer Universitas Indonesia (1998)
5. RIVAI, M., Model Hidung Elektronik : Sistem dan Aplikasi untuk Pengenalan
Aroma, Depok : Fakultas Ilmu Komputer Universitas Indonesia. (1997)
6. TAIRA NAKAJIMA, HIROYUKI TAKIZAWA, HIROAKI KOBAYASHI and
TADAO NAKAMURA, "Kohonen Learning with a Mechanism, the Law of the Jungle, Capable of Dealing with Nonstationary Probability Distribution Functions", IEICE Trans. Inf. & Syst., E81-D(6), June (1998) 584-591
7. YOSHIKAZU MIYANAGA and KOJI TOCHINAI, “An Adaptive Recognition using Self-Organized Network,” IEEE International Symposium on Circuits and
DISKUSI
MIKE SUSMIKANTI
Dalam penelitian ini alasan atau dasar apa dilakukannya analisa pembobotan? Mohon dijelaskan istilah bobot disini!
BENJAMIN KUSUMOPUTRO
Dalam Jaringan Neural Buatan pada tahap pembelajaran kita selalu menganalisa dan memperbaharui pembobotan. Sehingga terjadi kesalahan yang konvergen. Setelah bobot tersebut ideal (mencapai kesalahan yang konvergen) nilai masing-masing bobot itulah yang dipakai dalam tahap pengenalan.
ARKO
1. Type sensor aroma apa yang Anda gunakan dan apa karakteristik sensor tersebut? 2. Bagaimana bila ada 2 aroma atau lebih tinggi yang diuji? Apakah sistem Anda
telah mampu mengenali aroma-aroma tersebut sekaligus?
BENJAMIN KUSUMOPUTRO
1. Multi sensor yang masing-masing sensor dilapisi dengan membran sensitif yang karakterisrtiknya berbeda dengan tujuan setiap sensor akan membentuk suatu pola karakteristik tertentu untuk setiap gas aroma yang berbeda. Ada 4 membran (sensor) yang digunakan, yaitu: phosphaticid, acid lethicin, cholesterol dan phospatidyl ethanolamine.
2. Selama ini pengujian terhadap 2 aroma atau lebih belum kami lakukan. Hal tersebut akan kami lakukan dengan memperbanyak jumlah sensor dan sensitivitas sensor tersebut.
AS NATIO LASMAN
2. Bagaimana tingkat kemurnian aroma dapat dibedakan? BENJAMIN KUSUMOPUTRO
1. Sama dengan pertanyaan Bapak Arko
2. Dalam penelitian ini zat aroma yang diukur ditempatkan pada suatu tabung yang dapat menjaga kemurnian suatu zat (sesuai dengan keinginan kita)
DAFTAR RIWAYAT HIDUP
1. Nama : BENYAMIN KUSUMOPUTRO
2. Tempat/Tanggal Lahir : 17 November 1957
3. Instansi : Fasilkom UI
4. Pekerjaan / Jabatan : Dosen
5. Riwayat Pendidikan : (setelah SMA sampai sekarang)
• ITB, Jurusan Fisika, (1976-1981)
(S1)
• UI, Jurusan Opto Elektro (1981-1984)
(S2)
• Inst. Tek. Tokyo, Jurusan Electronics & Electrical
Engin. (1990-1993) (S3)
6. Pengalaman Kerja :
• 1984 - 1986 : PT Philips, Div. Corp System Engineer • 1986 - 1995 : Fakultas Pasca Sarjana - UI
• 1995 - Sekarang : Fakultas Ilmu Komputer UI 7. Organisasi Professional : IASTED - CANADA