SUBSAMPLE IN BIG DATA BASED SOME METHOD
(LEVERAGE, MEAN OF LOG LIKELIHOOD, BUGS OF LITTLE BOOTSTRAPS (BLB))TUGAS PENGANTAR BIG DATA
Dosen Pengampu : Dr.Danardono, MPH Vemmie Nastiti, M.Si Disusun oleh :
Danang Akbar Riyano (13/352688/PA/15690)
Farah Adibah M (14/363866/PA/15867)
Dita Dwi Aprilliani Ayu Lestari (14/364245/PA/15965)
Andi Giofanny M (14/368626/PA/16297)
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS GADJAH MADA
YOGYAKARTA
2017
BAB I
PENDAHULUAN
Pada bagian ini akan diberikan pengantar mengenai latar belakang dituliskannya paper ini. Dimulai dengan permasalahan umum dari big data dan beberapa cara untuk mengatasinya. Dalam pendahuluan ini akan dijelaskan secara umum mengenai beberapa untuk menyelesaikan kasus dalam big data.
1.1 Latar Belakang
Belakangan ini, big data menjadi isu yang hangat dalam dunia statistika. Big data mulai masuk dan dikenal di Indonesia sejak tahun 2000 seiring dengan kebutuhan manusia yang semakin banyak dan keinginan pemenuhan kebutuhannya yang semakin cepat dan serba praktis. Oleh karena itu big data merupakan sebuah tantangan baru yang harus dieksekusi sesegera mungkin dan seefisien mungkin. Semakin besar sebuah data maaka semakin besar yang harus ditangani. Big data tidak hanya mengenai suatu data yang berjumlah besar tetapi lebih pada sebuah sistem yang merupakan perpaduan dari tiga unsur utama, yaitu volume, variasi dan kecepatan. Volume menyangkut mengenai jumlah dari data yang besar, bahkan mencapai angka miliaran data. Selain itu, volume juga menunjukkan berbagai sub-sub populasi dari berbagai karakteristik yang bersatu padu dalam kapasitas yang besar. Variasi, elemen variasi dalam Data Besar menunjukkan besarnya keragaman karakteristik yang ada dari setiap kombinasi antar data dalam jumlah yang besar dalam satuan volume tertentu. Secara mendalam adanya variasi menunjukkan keanekaragaman informasi dalam suatu data sehingga semakin bervariasi artinya data tersebut semakin besar memberikan informasi dalam beragam karakteristik.
Oleh karena itu, dalam big data terdapat informasi yang memungkinkan hampir tidak terbatas jumlahnya sehingga sangat diperlukan alat yang sesuai untuk analisis yang nantinya digunakan sebagai pengambilan. Kecepatan, elemen ketiga ini sangat erat hubungannya dengan kendala waktu atas keinginan para pengguna data karena selain ada beberapa sifat data yang sangat sensitif dan strategis juga terdapat pula data yang memang perlu waktu relatif lama untuk digunakan. Kecepatan diperlukan karena menyangkut
strategi bisnis dan perdagangan sehingga menuntut agar informasi mengenai data tersebut bisa didapatkan oleh pengguna data dengan cepat untuk segera mengambil keputusan dan kebijakan bisnis dan perdagangan. Semakin besar jumlah data maka akan menghasilkan informasi yang semakin banyak, valid dan mengambarkan kenyataan. Namun, dalam kenyataannya sangat sulit untuk mengolah data dalam jumlah yang sangat besar. Selain itu juga masih terbatasnya jurnal dan alat yang dapat digunakan untuk mengolah big data.
Sejalan dengan kemajuan dan perkembangan ilmu pengetahuan dan teknologi, peranan ilmu statistika mengalami banyak perubahan ke arah yang lebih baik, khususnya metodologi penelitian, baik eksak maupun non-eksak. Keterkaitan dengan metodologi penelitian, dalam prosedur untuk sampai tahapan analisis secara umum salah satunya dapat menggunakan metode sub sampling.
Subsampling adalah sebuah metode statistika unuk mengukur dan mengontrol
non-sampling error dan mengestimasi standard errors. Metode ini menjadi sebuah alat mengambil kesimpulan dari berbagai kondisi populasi. Metode ini mulai berkembang sejak berkembangnya metode bootstraping yang mampu mengestimasi dan membangun
sampling distribution menggunakan nilai dari subsample-nya. Terkait dalam upaya mendapatkan sampel, dalam perkembangannya para ahli statistika telah mengembangkan berbagai bentuk formula mengenai seberapa besar jumlah sampel yang relevan untuk digunakan sebagai pondasi bahan baku analisis data. Relasinya dengan Big Data, dengan volumenya yang banyak dengan variasi yang besar serta adanya kendala waku dalam aspek kecepatan dalam penyajian hasil kepada konsumen data, menjadikan metode sub sampling bisa digunakan sebagai salah satu alternatif dalam mengolah big data. Dalam tugas ini akan dibahas beberapa metode dalam subsampling seperti Bootstrap, Laveraging, dan Mean Log-Likelihood.
1. Leveraging
Dalam metode laveraging sebuah sampel diambil dari proporsi tertentu sebuah data dengan bobot tertentu dari data keseluruhan, kemudian dilakukan perhitungan
jumlah sampel keseluruhan. Inti dari metode laveraging adalah proses pembobotan, distribusi marginal dari setiap sampel. Salah satu analisis statistik yang lazim digunakan dalam menentukan nilai suatu sampel adalah regresi linier. Dalam tugas ini akan dibahas proses laveraging untuk model regresi dalam melakukan analisis big data.
Dimulai dengan membahas model linier dan estimasi parameternya. Ordinary Lest Square (OLS) merupakan salah satu metode yang sering digunakan dalam membuat suatu model linier. Diberikan model regresi linier gaussian
𝑦 = 𝑋𝛽0+ 𝜀
dimana y adalah vektor varibel respon berukuran n x 1, X merupakan matrix variabel prediktor berukuran n x p, 𝛽0adalah vektor keofisien berukuran p x 1, dan noise vector
𝜀~𝑁(0, 𝜎2𝐼). Dengan kondisi keofisien 𝛽0 diestimasi dengan maximum likelihood
estimation dan diperoleh
𝛽̂𝑜𝑙𝑠 = 𝑎𝑟𝑔𝑚𝑖𝑛𝛽‖𝑦 − 𝑋𝛽‖2 = (𝑋𝑇𝑋)−1𝑋𝑇𝑦
dalam kasus ini vektor respon didapatkan 𝑦̂ = 𝐻𝑦, dimana 𝐻 = (𝑋𝑇𝑋)−1𝑋𝑇. Diagonal elemen ke-𝑖𝑡ℎ dari H dituliskan ℎ
𝑖𝑖 = 𝑥𝑖𝑇(𝑋𝑇𝑋)−1𝑥𝑖, dimana 𝑥𝑖𝑇 adalah baris ke-𝑖𝑡ℎdari
X, adalah statistical laverage dari 𝑖𝑡ℎatau disebut sampel. Sejak H dapat dituliskan seperti
𝐻 = 𝑈𝑈𝑇 dimana U adalah setiap basis ortogonal untuk ruang kolom dari X , leverage dari observasi 𝑖𝑡ℎ dituliskan
ℎ𝑖𝑖 = ∑ 𝑈𝑖𝑗2 𝑝
𝑗=1
= ‖𝑢𝑖‖2
dimana 𝑢𝑖𝑇adalah baris ke-𝑖𝑡ℎdari U. Untuk estimasi 𝛽, nilai kesalahan estimator 𝛽̂
diukur dengan Mean Ssquared Error didefinisikan
𝑀𝑆𝐸(𝛽̂) =1 𝑛𝐸 [(𝑋𝛽0− 𝑋𝛽̂) 𝑇 (𝑋𝛽0 − 𝑋𝛽̂)] =1 𝑛𝑇𝑟(𝑉𝑎𝑟[𝑋𝛽̂]) + 1 𝑛(𝐸[𝑋𝛽̂] − 𝑋𝛽0) 𝑇 (𝐸[𝑋𝛽̂] − 𝑋𝛽0)
=1 𝑛𝑇𝑟(𝑉𝑎𝑟[𝑋𝛽̂]) + 1 𝑛(𝑏𝑖𝑎𝑠[𝑋𝛽̂]) 𝑇 (𝑏𝑖𝑎𝑠[𝑋𝛽̂])
dimana 𝛽0 adalah nilai sebenarnya dari 𝛽. MSE dapat digunakan sebagai pembanding dengan estimator subsampling lain.
Ketika ukuran sampel n sangat besar estimator OLS dapat menyebabkan bias dalam melakukan estimasi. Misalnya, jika 𝑝 = √𝑛, perhitungan estimator OLS adalah
𝑂(𝑛2) untuk n yang sangat besar mungkin tidak layak digunakan. Untuk
mengoptimalisasikannya dapat digunakan metode laveraging. Seperti yang telah dijelaskan sebelumnya, salah satu hal terpenting dalam metode ini adalah proses pembobotannya. Langkah pembobotan metode laveraging adalah sebagai berikut: - Mengambil randomsubsample dengan besar r dari data yang probablitas samplingny
telah ditentukan 𝜋 = {𝜋1, 𝜋2, … , 𝜋𝑛}. Membuat random subsample dari r<<n, tuliskan sebagai (𝑋∗, 𝑦∗)dari sampel keseluruhan dengan probabilitas 𝜋. Lalu simpan matrix sampling probabilitas 𝜗 = 𝑑𝑖𝑎𝑔{𝜋𝑘∗} yang saling berkorespondensi
- Berikutnya dilakutan pembobotan least square menggunakan subsample yang telah dihasilkan. Lalu akan diperoleh estimator OLS menggunakan subsample. Estimasi dari β yang diperoleh dari subsample pembobotan least square, sehingga diperoleh
𝛽̂𝑤𝑙𝑠 = 𝑎𝑟𝑔𝑚𝑖𝑛𝛽‖𝜗−1 2⁄ 𝑦 − 𝜗−1 2⁄ 𝑋𝛽‖2
2. Mean Log-likelihood
Metode ini menggunakan rata-rata Monte Carlo yang dihitung dari sub-sampel untuk memperkirakan ukuran yang dibutuhkan untuk data penuh. Misalkan dimiliki n sampel 𝑋1, 𝑋2, … , 𝑋𝑛, selanjutnya dari setiap sampel dilakukan perhatingan subsample
yang dinotasikan dengan 𝑥1, 𝑥2, … , 𝑥𝑛. Untuk setiap 𝑥𝑖, 𝑖 = 1,2, … , 𝑛 merupakan rata-rata
Monte Carlo berikutnya dilambangkan 𝜇𝑖. Selanjutnya dengan mengambil
Ω adalah ruang parameter yang menunjukan himpunan seluruh nilai 𝜃 yang mungkin maka fungsi likelihood dari 𝜃 adalah sebagai berikut
𝐿(𝜃) = 𝑓(𝜇1; 𝜃)𝑓(𝜇2; 𝜃) … 𝑓(𝜇𝑛; 𝜃)
𝐿(𝜃) merupakan fungsi peluang bersama dari variabel random 𝑋1, 𝑋2, … , 𝑋𝑛 yang bersifat
i.i.d (identically independent distributed).
Prinsip maximum likelihood dalam mengestimasi 𝜃 adalah memilih estimator 𝜃̂
yang memaksimumkan nilai likelihood-nya (Bain dan Engelhard, 1991). Nilai suatu 𝜃̂
dalam Ω yang memaksimumkan 𝐿(𝜃) disebut sebagai Maksimum Likelihood Estimator
(MLE). Nilai 𝜃̂ merupakan suatu nilai dari 𝜃 yang memenuhi
𝑓(𝜇1; 𝜃)𝑓(𝜇2; 𝜃) … 𝑓(𝜇𝑛; 𝜃̂) = max 𝜃 ∈ Ω𝑓(𝜇1; 𝜃)𝑓(𝜇2; 𝜃) … 𝑓(𝜇𝑛; 𝜃)
𝐿(𝜃) maksimum jika turunan pertamanya sama dengan nol dan turunan keduanya bernilai negatif, maka nilai MLE dapat diperoleh dengan menyelesaikan persamaan
𝜕𝐿(𝜃) 𝜕𝜃 = 0 𝜕2𝐿(𝜃)
𝜕𝜃2 < 0
Diferensiasi yang dilakukan pada fungsi likelihood umumnya lebih mudah dilakukan pada nilai logaritmanya yaitu 𝑙𝑜𝑔𝐿(𝜃), fungsi tersebut dikenal dengan log likelihood. Fungsi log likelihood yang naik tegas dalam interval (0, ∞) menyebabkannya akan memliki nilai ekstrem yang sama sehingga dapat merepresentasikan fungsi
likelihood. Karena setiap nilai 𝜃 yang memaksimalkan 𝐿(𝜃) juga akan memaksimalkan
𝑙𝑜𝑔𝐿(𝜃) maka fungsi log likelihood dapat digunakan sebgai berikut.
𝑙𝑜𝑔𝜕𝐿(𝜃) 𝜕𝜃 = 0 𝑙𝑜𝑔𝜕2𝐿(𝜃)
BAB II
Bags of Little Bootstraping
Pada bab ini akan dibahas mengenai metode bootstraping, dan metode bags of little bootstraping sebagai metode pengembangannya. Pembahasan dimulai dengan pengenalan metode bootstrap secara umum dan dilanjutkan dengan bags of little bootstrap. Berikutnya dilanjutkan dengan algoritma dari metode bags of little bootstrap.
2.1 Metode Bootstrap
Bootstrap adalah suatu metode yang dapat bekerja tanpa membutuhkan asumsi distribusi karena sampel asli digunakan sebagai populasi. Bootstrap adalah teknik resampling nonparametrik yang bertujuan untuk menentukan estimasi standar eror dan interval konfidensi dari parameter populasi seperti mean, rasio, median, proporsi, koefisien korelasi atau koefisien regresi tanpamenggunakan asumsi distribusi. Bootstrap
diperkenalkan pertama kali oleh Efron pada tahun 1979. Metode bootstrap dilakukan dengan mengambil sampel darisampel asli dengan ukuran sama dengan ukuran sampel asli dan dilakukan dengan pengembalian. Kedudukan sampel asli dalam metode
bootstrap dipandang sebagai populasi. Metode peyampelan ini biasa disebut dengan resampling bootstrap.
Misalkan 𝑥𝑛 = (𝑋1, 𝑋2, … , 𝑋𝑛) merupakan sampel berukuran n dari variabel
random i.i.d yang nilainya terdapat diruang sample S dan memiliki distribusi probabilitas yang belum diketahui P, dimana P diasumsikan mengikuti distribusi tertentu dari 𝚸. Kumpulan dari 𝚸 mungkin besifat parametric, semiparametric, atau nonparametric. Tentu keluarga distribusi dari 𝚸 diparameterisasi dari koleksi probabilitas P didalam 𝚸, dengan tidak perlu memberi batasan terhadap 𝚸. Hal yang menarik dalam membangun interval konfidensi untuk beberapa parameter 𝜃(𝑃), didalam range {𝜃(𝑃): 𝑃 ∈ 𝚸} dapat dinotasikan Θ. Θ merupakan sebuah subset dari garis bilangan real, namun Θ dapat
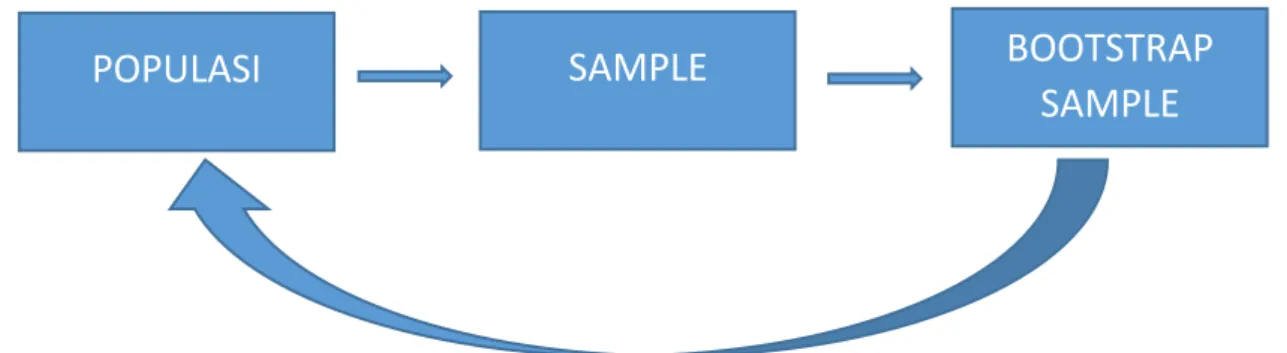
disesuaikan dengan parameter lain yang lebih umum. Secara deskriptif fungsi dari metode bootstrap dapat dilihat melalu gamabr dibawah:
Gambar 3.1 Deskripsi Penggunaan Bootstrap
Sebagai contoh akan dibahas proses pengestimasian parameter model regresi. Metode bootstrap yang diberikan pada regresi ini adalah resampling residual.Misalkan dimiliki sampel berpasangan antara variabel dependen dan independen yang dituliskan dalam bentuk matrik Y dan X dengan ukuran sampel n. Selanjutnya sampel ini disebut sampel asli. Prosedur bootstrap resampling residual untuk estimasi parameter regresi dapat dituliskan sebagai berikut :
1. Menentukan fit model berdasarkan sampel asli dengan menggunakanmetode kuadrat terkecil, diperoleh 𝑌̂ = 𝑋𝛽̂
2. Menghitung nilai residual 𝑒 = 𝑌 − 𝑌̂, diperoleh 𝑒 = (𝑒1, 𝑒2, … , 𝑒𝑛)
3. Mengambil sampel bootstrap berukuran n dari 𝑒1, 𝑒2, … , 𝑒𝑛secara random dengan pengembalian, diperoleh sampel bootstrap pertama sebagaiberikut
𝑒1 = (𝑒
11, 𝑒21, … , 𝑒𝑛1)
4. Menghitung nilai bootstrap untuk 𝑌 dengan menambahkan 𝑒1 pada fit model,
sehingga diperoleh 𝑌1 = 𝑋𝛽̂ + 𝑒1
5. Menghitung koefisien regresi untuk sampel bootstrap yang pertama dengan 𝑌1
dengan 𝑋, diperoleh 𝛽̂1 = (𝑋𝑇𝑋)−1𝑋𝑇𝑌1
6. Mengulangi proses diatas sebanyak B kali, diperoleh 𝛽̂1, 𝛽̂2, … , 𝛽̂𝐵
POPULASI
SAMPLE
BOOTSTRAP
7. Pendekatan estimasi bootstrap untuk parameter regresi adalah mean dari distribusi
𝛽̂1, 𝛽̂2, … , 𝛽̂𝐵
Estimasi interval konfidensi bootstrap untuk parameter regresi diberikan dalam interval pendekatan normal dan interval persentil. Interval konfidensi bootstrap dengan pendekatan normal sebenarnya analog dengan interval konfidensi standar. Pemanfaatan metode bootstrap dalam mengkonstruksi interval ini adalah untuk menentukan standar eror dari estimator. Berdasarkan sampel bootstrap dengan replikasi B kali diperoleh
𝛽̂1, 𝛽̂2, … , 𝛽̂𝐵. Variansi estimator bootstrap 𝛽̂𝑘 diberikan oleh
𝑉(𝛽̂𝑘) = ∑(𝛽̂𝑘
𝑏− 𝛽̂𝑘)2
(𝐵 − 1)
𝐵
𝑏=1
2.2 Metode Bags of Little Bootstrap
Bags of Little Bootstrap (BLB) merupakan pengembangan dari metode bootstrap yang telah dikenalkan sebelemunya. Fungsi BLB berasal dari rata-rata hasil dari proses
bootstraping. Misalkan sample dari BLB dengan subset s berukuran b yang diambil dari sampel berukuran n. Besarnya b dapat ditentukan dengan 𝑏 = 𝑛𝛾, dimana 𝛾 𝜖 [0.5,1]. Dalam jurnalnya “A Scalable Bootstrap for Massive Data” Kleiner menuliskan hasil
penelitiannya dimana dari 1 Terra Byte (TB) data populasi, ketika menggunakan metode bootstrap standar dibutuhkan sampel sebesar 632 Giga Byte (GB) untuk merepresentasikan atau mendekati sifat-sifat yang dimiliki populasi. Ketika menggunakan metode BLB hanya diperlukan sampel sebesar 4GB untuk untuk dapat merepresentasikan populasi yang ada.
Diberikan 𝑥𝑛 = (𝑋1, 𝑋2, … , 𝑋𝑛) merupakan sampel berukuran n dari variabel random i.i.d yang nilainya terdapat diruang sample S dan memiliki distribusi probabilitas yang belum diketahui P. Berikutnya untuk setiap 𝑋𝑖, 𝑖 = 1,2, … , 𝑛 dilakukan proses
resampling dengan mengambil 𝑚𝑟 = (𝑀1, 𝑀2, … , 𝑀𝑟) sebesar b. Paramater-parameter dari populasi dapat diestimasi dangan merata-rata parameter yang dihasil dari setiap
sebesar N, karena besarnya ukuran N maka dilakukan pengambilan sampel sebesar n. Dari sampel sebesar n diambil subsampel sebanyak s dan sebesar b. Menggunakan setiap subsampel diambil sampel bootstrap sebanyak r dengan ukuran n, selanjuntnya kita dapat mengestimasi batas atas dan bawah interval konvidensi dari setiap subsampel. Dan rata-rata batas atas dan rata-rata-rata-rata batas bawah sampel bootstrap dapat mengestimasi interval konvidensi populasi keseluruhan. Dalam penelitiannya Kleiner juga menyimpulkan beberapa hasil penelitiannya mengenai kelebihan metode bags of little bootstrap selain yang telah disebutkan sebelumnya adalah:
- Sederhana dalam proses komputasinya
- Memiliki fleksibelitas seperti metode bootstrap pada umumnya - Memiliki sifat robustness dibanding metode sebelumnya - Mempertahankan sifat statistik dari metode bootstrap
BAB III
ILUSTRASI
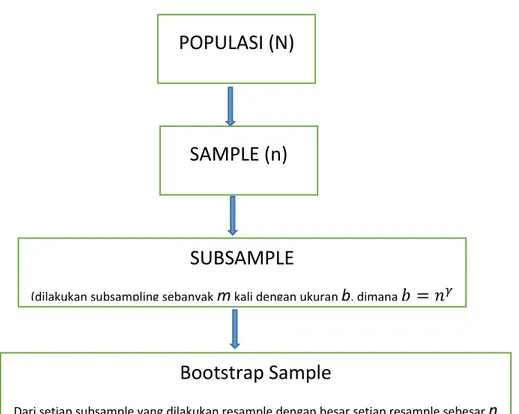
Pada bab ini akan diberikan ilustrasi penggunaan metode bags of bootstrap untuk mengestimasi nilai median dan interval konvidensi. Data yang digunakan dalam ilustrasi adalah data dari sektor penerbangan dengan sampel sebesar 5268 data dan terdapat beberapa variabel antara lain, tanggal penerbangan, lokasi, operator, aboard, fatalities,
dan ground. Deskriptif algoritma pada metode BLB bekerja sebagai berikut:
Gambar 3.1 Deskripsi Prosess Bags of Little Bootstrap
Dengan menggunakan langkah diatas kita dapat memperoleh estimasi nilai-nilai standar error dan interval konfidensi dari parameter populasi seperti mean, rasio, median, proporsi, tanpaharus mengetahui distribusi data penerbangan yang sebenarnya.
POPULASI (N)
SAMPLE (n)
Bootstrap Sample
Dari setiap subsample yang dilakukan resample dengan besar setiap resample sebesar n
SUBSAMPLE
BAB IV
KESIMPULAN
Setelah dilakukan diskusi dalam pembuatan makalah ini diperoleh beberapa kesimpulan mengenai beberapa metode subsample yang dapat diaplikasikan dalam big data yaitu antara lain
1. Sebuah data dikatakan sebuah big data ketika suatu data memliki volume,
velocity, dan variance dengan nilai yang besar.
2. Dalam metode laveraging proses pembobotan setiap subsample merupakan hal terpenting.
3. Metode mean log-likelihood dapat mengestimasi parameter populasi dengan mencari rata-rata subsample menggunakan metode Monte Carlo.
4. Bootstrap merupakan metode sampling yang sangat sederhana dalam mencari tahu kondisi parameter populasi
5. Bags of little bootstrap memiliki banyak keunggulan dibanding metode bootstrap
sederhana. Menurut Kleiner dalam analisis big data, BLB membutuhkan jumlah sampel dengan ukuran lebih kecil dibanding bootstrap biasa.
Lampiran
cs=read.delim("clipboard") #Membuat Data Frame
head(cs)
length(cs$Aboard)
clean=na.omit(cs) #Melakukan cleaning data
head(clean)
BLB = function(x,nss,r1,g1){ #Fungsi BLB
jj = r1*nss #Menentukan ukuran matriks
med = matrix(0, nrow = r1, ncol = nss) #Membuat matriks untuk nilai median
IC = matrix(0, nrow = r1*nss, ncol = 2) #Membuat matriks untuk nilai intervalkonvidensi
m=length(x)^g1 #Menentukan besar subsampel
for(i in 1:nss){ #Menentukan replikasi subsampel
for(j in 1:r1) { #Menentukan replikasi sampling bootstrap
ss = sample(length(x),m,T) datass = as.numeric(x[ss])
med[j,i] = median(datass) #Mencari rata-rata nilai median
}} for(j in 1:jj) {
ss = sample(m,length(x),T) datass = as.numeric(x[ss])
error = (qnorm(0.95,mean = mean(datass),sd = sd(datass))*sd(datass)) / (length(datass)^0.5)
IC[j,1] = mean(datass) - error #Mencari batas bawah interval konvide
IC[j,2] = mean(datass) + error #Mencari batas atas interval konvidensi
}
print(med) print(colMeans(med))print(mean(colMeans(med))) print(IC)print(colMeans(IC)) }BLB(x=clean$Aboard, nss=10, r1=5, g1=0.8)