KLASIFIKASI DATA SPASIAL UNTUK KEMUNCULAN
HOTSPOT DI PROVINSI RIAU MENGGUNAKAN
ALGORITME ID3
VIKHY FERNANDO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2013
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Klasifikasi Data Spasial untuk Kemunculan Hotspot di Provinsi Riau Menggunakan Algoritme ID3 adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Januari 2014 Vikhy Fernando NIM G64114041
ABSTRAK
VIKHY FERNANDO. Klasifikasi Data Spasial untuk Kemunculan Hotspot di Provinsi Riau Menggunakan Algoritme ID3. Dibimbing oleh IMAS SUKAESIH SITANGGANG.
Kebakaran hutan merupakan salah satu persoalan lingkungan yang muncul hampir setiap tahun di Indonesia termasuk di Provinsi Riau, yang menyebabkan dampak negatif bagi kehidupan manusia. Data kebakaran persebaran hotspot yang berukuran besar dapat dianalisis menggunakan teknik spatial data mining, salah satunya pohon keputusan spasial. Penelitian ini bertujuan untuk mengklasifikasikan kemunculan hotspot di Provinsi Riau yang dapat digunakan untuk mendapatkan aturan-aturan klasifikasi. Dalam penelitian ini, pembentukan pohon keputusan spasial dilakukan dengan menggunakan algoritme ID3. Hasil penelitian menunjukkan bahwa akurasi tertinggi adalah 70.80%. Model klasifikasi ini terdiri dari 125 aturan klasifikasi yang dapat digunakan untuk prediksi kemunculan titik api.
Kata kunci: algoritme ID3, hotspot, klasifikasi, pohon keputusan spasial
ABSTRACT
VIKHY FERNANDO. Spatial Classification for Hotspot Occurrences in Riau Province using ID3 Algorithm. Supervised by Imas Sukaesih Sitanggang.
Forest fire is one of the environmental issues that occurs almost every year in Indonesia including in Riau Province, which causes negative impacts for human life. The large data of hotspot distribution can be analyzed using one of spatial data mining techniques, namely spatial decision tree. The purpose of this research is to classify the hotspot occurences in Riau province in order to obtain the classification rules. In this research, the spatial decision tree is developed using ID3 algorithm. The result shows that the highest accuracy is 70.80%. The classification model consists 125 classification rules that can be used to predict the hotspot occurrences.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
KLASIFIKASI DATA SPASIAL UNTUK KEMUNCULAN
HOTSPOT DI PROVINSI RIAU MENGGUNAKAN
ALGORITME ID3
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2013
Judul Skripsi : Klasifikasi Data Spasial untuk Kemunculan Hotspot di Provinsi Riau Menggunakan Algoritme ID3
Nama : Vikhy Fernando NIM : G64114041
Disetujui oleh
Dr Imas Sukaesih Sitanggang, SSi MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Juli 2013 ini ialah spatial data mining dengan judul Klasifikasi Data Spasial untuk Kemunculan Hotspot di provinsi Riau Menggunakan Algoritme ID3.
Dalam pelaksanaan penelitian tugas akhir ini, penulis ingin menyampaikan terima kasih kepada:
1 Allah Shubanallah Wa Taala yang atas izin karunia dan rahmat-Nya penulis dapat menyelesaikan tugas akhir ini.
2 Ibu Dr Imas Sukaesih Sitanggang, SSi MKom selaku dosen pembimbing atas nasihat dan bimbingannya selama proses pengerjaan tugas akhir ini. 3 Bapak Hari Agung Adrianto, SKom MSi dan Bapak Endang Purnama Giri,
SKom MKom selaku dosen penguji atas kesediaannya menjadi penguji pada ujian tugas akhir ini.
4 Ayahanda Jontrifizal, Ibunda Gusmiyetty, Kakak, Adik dan keluarga yang senantiasa memberikan doa dan dukungan.
5 Teman-teman satu bimbingan yang senantiasa saling memberikan semangat. 6 Rekan-rekan dari Departemen Ilmu Komputer IPB Alih Jenis angkatan 6
yang senantiasa memberikan semangat dan motivasi. Semoga karya ilmiah ini bermanfaat.
Bogor, Januari 2014
DAFTAR ISI
DAFTAR TABEL vi DAFTAR GAMBAR vi PENDAHULUAN 1 Latar Belakang 1 Perumusan Masalah 1 Tujuan Penelitian 1 Manfaat Penelitian 1Ruang Lingkup Penelitian 2
METODE 2
Data Penelitian dan Area Studi 2
Tahapan Penelitian 2
Praproses 2
Klasifikasi Menggunakan Algoritme ID3 4
Penggunaan Klasifikasi Data Baru 6
Lingkungan Pengembangan 6
HASIL DAN PEMBAHASAN 6
Pra Proses 6
Penentuan Data Latih dan Data Uji 11
Klasifikasi Menggunakan Algoritme ID3 11
Akurasi Model 14
Penggunaan Klasifikasi pada Data Baru 14
SIMPULAN DAN SARAN 15
Simpulan 15
Saran 15
DAFTAR PUSTAKA 16
LAMPIRAN 17
DAFTAR TABEL
1 Jarak terdekat hotspot ke pusat kota 9
2 Jarak terdekat hotspot ke sungai 10
3 Jarak terdekat hotspot ke jalan 10
4 Kategori untuk jarak terdekat ke pusat kota 10
5 Kategori untuk jarak terdekat ke sungai 10
6 Kategori untuk jarak terdekat ke jalan 11
7 Pembagian fold dan akurasi pohon keputusan 12
8 Ketepatan prediksi model klasifikasi 14
9 Contoh data baru 14
DAFTAR GAMBAR
1 Tahapan praproses 3
2 Tahapan penelitian 4
3 Hotspot di Provinsi Riau tahun 2005. 7
4 Non hotspot di Provinsi Riau tahun 2005. 7
5 Layer pusat kota di Provinsi Riau 8
6 Layer Sungai di Provinsi Riau 8
7 Layer Jalan di Provinsi Riau 8
8 Sub pohon keputusan spasial untuk jarak terdekat ke sungai dengan
PENDAHULUAN
Latar Belakang
Kebakaran hutan merupakan salah satu persoalan lingkungan yang muncul hampir setiap tahun di Indonesia termasuk di Provinsi Riau. Padahal, dampak yang ditimbulkan dari kebakaran hutan sangat merugikan. Dampak tersebut tidak hanya dialami oleh masyarakat di Provinsi Riau saja, tetapi juga oleh masyarakat di Provinsi sekitar Riau yakni, Provinsi Sumatera Barat dan Provinsi Sumatera Utara. Selain dekat dengan Provinsi lain di Indonesia, Provinsi Riau juga dekat dengan wilayah negara tetangga, yaitu Singapura dan Malaysia.
Data persebaran hotspot yang berukuran besar dapat dianalisis menggunakan teknik spatial data mining. Salah satu teknik dalam spatial data mining adalah spatial decision tree. Hasil dari spatial decision tree akan membangun sebuah decision tree dari data spasial yang dapat digunakan untuk membentuk aturan-aturan klasifikasi. Klasifikasi spasial bertujuan memberikan sebuah label atau menentukan kelas dari sebuah objek berdasarkan nilai atribut yang ada dalam spasial dataset dengan memperhatikan objek tetangganya.
Penelitian ini menggunakan data hotspot di wilayah Indonesia yang bersumber dari Direktorat Pengendalian Kebakaran Hutan (DPKH) Departemen Kehutanan Republik Indonesia. Penelitian ini mengklasifikasikan data spasial persebaran hotspot di wilayah Riau pada tahun 2005 menggunakan algoritme ID3.
Perumusan Masalah
Rumusan permasalahan pada penelitian ini adalah bagaimana membuat model klasifikasi untuk data kebakaran hutan di wilayah Provinsi Riau pada tahun 2005.
Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1 Membuat model klasifikasi untuk data kebakaran hutan di wilayah Provinsi Riau pada tahun 2005.
2 Evaluasi model klasifikasi untuk prediksi kemunculan titik api.
Manfaat Penelitian
Penelitian ini diharapkan dapat membentuk model klasifikasi dari persebaran hotspot di Provinsi Riau pada tahun 2005 dan dapat memprediksi kemunculan titik api di wilayah baru sehingga dapat mengantisipasi kebakaran hutan di wilayah tersebut.
2
Ruang Lingkup Penelitian
Ruang lingkup pada penelitian ini adalah:
1 Penelitian difokuskan pada pembentukan model klasifikasi menggunakan algoritme ID3 pada data persebaran hotspot di wilayah Provinsi Riau pada tahun 2005.
2 Data spasial yang digunakan adalah data sebaran hotspot tahun 2005, non hotspot, sungai, jalan dan pusat kota di wilayah Riau.
METODE
Data Penelitian dan Area Studi
Luas wilayah Provinsi Riau adalah 107932.71 km2 yang membentang dari lereng Bukit Barisan hingga Selat Malaka, hal ini membuat Provinsi Riau berada pada jalur yang sangat strategis karena terletak pada jalur perdagangan Regional dan Internasional di kawasan ASEAN. Provinsi Riau memiliki luas daratan 89150.15 km2 dan luas lautan 18782.56 km2, di daratan terdapat 15 (lima belas) sungai di antaranya ada 4 (empat) sungai dapat digunakan sebagai prasarana perhubungan (Pemerintah Provinsi Riau 2013).
Data spasial yang digunakan adalah data sebaran hotspot tahun 2005 yang berjumlah 7169 titik hotspot, 7200 titik non hotspot, 457 segmen aliran sungai, 37656 segmen jalan dan 6 titik pusat kota di wilayah Riau.
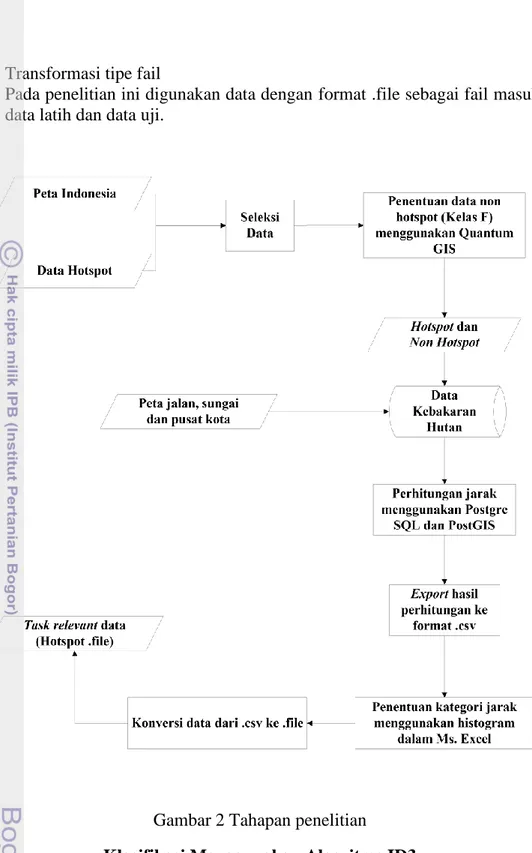
Tahapan Penelitian
Penelitian ini akan dilakukan dalam beberapa tahap. Tahapan dari metode penelitian ini dapat dilihat pada Gambar 1.
Praproses
Data spasial diolah menggunakan perangkat lunak Quantum GIS 1.8.0 Lisboa untuk mendapatkan data hotspot, non hotspot, pusat kota, sungai dan jalan di Provinsi Riau pada tahun 2005. Selanjutnya, data tersebut di-import ke basis data menggunakan PosgreSQL 9.1 yang didalamnya telah terintegrasi dengan PostGIS 2.0. Kemudian dilakukan kueri pada data yang diperlukan hingga didapatkan data yang dibutuhkan untuk diklasifikasikan. Agar kueri sesuai dengan kode yang telah dibuat di perangkat lunak Python, maka digunakan Microsoft Excel 2010 sebagai perangkat lunak pembantu. Berikut alur dari praproses yang dapat dilihat pada Gambar 2.
3
Gambar 1 Tahapan praproses
Beberapa tahapan yang dilakukan pada tahap praproses adalah: 1 Seleksi data
Pada proses ini dilakukan pemilihan data hotspot dan data non hotspot yang terjadi di Provinsi Riau pada tahun 2005. Selanjutnya, data tersebut juga akan dipilih menjadi data pusat kota, sungai dan jalan di Provinsi Riau. 2 Pemberian label kelas
Pemberian label kelas ini digunakan untuk mendapatkan hasil data. Label T digunakan pada data hotspot dan label F digunakan pada data non hotspot. 3 Perhitungan jarak
Pada tahap ini dilakukan perhitungan jarak terdekat dari kelas T dan kelas F ke pusat kota, kelas T dan kelas F ke sungai dan kelas T dan kelas F ke jalan di Provinsi Riau.
4 Transformasi jarak terdekat dari hotspot
Pada tahap ini dilakukan transformasi hasil data menjadi kategorik agar lebih memudahkan untuk diproses bahasa perograman Python.
4
5 Transformasi tipe fail
Pada penelitian ini digunakan data dengan format .file sebagai fail masukan data latih dan data uji.
Gambar 2 Tahapan penelitian
Klasifikasi Menggunakan Algoritme ID3
Pada tahap ini dibangun model klasifikasi untuk membentuk pohon keputusan spasial. Kemudian dilakukan perhitungan akurasi dari pohon keputusan spasial yang terbentuk. Pembentukan pohon keputusan spasial ini menggunakan algoritme ID3. Contoh algoritme pohon keputusan adalah algoritme ID3 atau Iterative Dischotomister 3. Algoritme ini menggunakan konsep entropi informasi. Secara umum algoritme ID3 (Han dan Kamber 2006) adalah sebagai berikut:
5 Algoritme ID3 (Han dan Kamber 2006)
Input : Data latih, data uji Output : Decision tree Metode :
a Buat node N;
b Jika semua sampel memiliki kelas yang sama yaitu C, maka jadikan node N sebagai leaf node dan beri label C;
c Jika daftar atribut kosong, maka jadikan node N sebagai leaf node dengan label = nilai kelas yang terbanyak pada sampel;
d Pemilihan atribut uji dengan nilai information gain yang terbesar; e Beri label node N dengan atribut uji;
f Untuk setiap nilai ai dalam atribut uji yang diketahui, g Tambahkan cabang di bawah node N untuk atribut uji = ai; h Tentukan si sebagai subset dari sampel dimana atribut uji = ai; i Jika sampel si kosong,
j Tambahkan leaf node dengan label = nilai kelas yang terbanyak pada sampel;
k Selainnya, tambah cabang baru di bawah cabang yang sekarang dengan memanggil fungsi ID3 (si daftar atribut-atribut uji);
Pohon Keputusan Spasial
Proses pembentukan pohon keputusan spasial dari data sebaran hotspot di Provinsi Riau menggunakan tabel gabungan yang terdiri dari beberapa hubungan spasial yang terbentuk dari kelas targetnya.
Perhitungan Akurasi
Pada tahap ini menghitung akurasi dari model klasifikasi yang diperoleh dari proses klasifikasi. Akurasi menunjukkan tingkat kebenaran pengklasifikasian data terhadap kelas yang sebenarnya. Semakin rendah nilai akurasi maka semakin tinggi kesalahan klasifikasi pada data baru. Tingkat akurasi yang baik adalah tingkat akurasi yang mendekati 100%. Dalam penelitian, metode yang digunakan dalam proses perhitungan akurasi ini adalah metode fold cross validation. K-fold cross validation (Stone 1974 diacu dalam Fu 1994) adalah sebuah metode yang membagi himpunan contoh secara acak menjadi k himpunan bagian (subset). Pada metode ini dilakukan pengulangan sebanyak k kali untuk data pelatihan dan pengujian. Pada setiap pengulangan, satu subset digunakan untuk pengujian sedangkan subset sisanya digunakan untuk pelatihan.
Akurasi diperoleh berdasarkan data pengujian terhadap model klasifikasi. Untuk menghitung akurasi digunakan rumus sebagai berikut:
∑ ∑
6
Penggunaan Klasifikasi Data Baru
Model klasifikasi yang terbentuk akan digunakan untuk menentukan kelas dari data baru yang belum diketahui label kelasnya. Label kelas didapatkan dengan menelusuri model pohon keputusan yang terbentuk atau aturan yang telah diturunkan dari model pohon yang dihasilkan pada data latih.
Lingkungan Pengembangan
Pembentukan pohon keputusan spasial ini dibangun dengan menggunakan perangkat keras dan perangkat lunak sebagai berikut:
1 Perangkat keras berupa komputer personal dengan spesifikasi sebagai berikut:
Processor Intel® Core™ I3 CPU Memori 2048MB RAM
Mouse Keyboard 2 Perangkat lunak
Sistem Operasi Windows 8
Quantum GIS (1.8.0) untuk analisis dan visualisasi data spasial Sistem Manajemen Basis Data PostgreSQL
PostGIS 2.0 sebagai ekstensi PostgreSQL untuk analisis data spasial Bahasa Pemrograman Python 2.7.5
HASIL DAN PEMBAHASAN
Pra Proses Seleksi Data
Data yang digunakan dalam penelitian ini merupakan data persebaran hotspot pada tahun 2005, data non hotspot, data pusat kota, data sungai dan data jalan untuk Provinsi Riau. Secara terperinci dapat dilihat sebagai berikut
a. Data persebaran Hotspot
Data persebaran hotspot yang digunakan adalah data hotspot tahun 2005. Data ini memiliki atribut wkt_geom, longitude, latitude, bulan, minggu dan tanggal. Pada awalnya, data persebaran hotspot Indonesia berbetuk shapefile. Data tersebut di-clip menjadi daerah Provinsi Riau saja menggunakan perangkat lunak Quantum GIS. Pada wilayah Provinsi Riau terdapat 7169 titik hotspot. Gambar 3 menunjukkan persebaran hotspot di provinsi Riau pada tahun 2005.
7
Gambar 3 Hotspot di Provinsi Riau tahun 2005. b. Data Persebaran Non Hotspot
Data persebaran non hotspot diperoleh dari titik-titik di luar hotspot. Data ini didapat dengan cara membangkitkan titik acak di sekitar hotspot. Titik non hotspot tersebut dibangkitkan di luar buffer dengan radius 1 km dari sebuah hotspot. Buffer dibuat menggunakan operasi Geo processing Tools pada Quantum GIS. Data non hotspot yang dibangkitkan sebanyak 7200 titik. Gambar 4 menunjukkan persebaran non hotspot di Provinsi Riau pada tahun 2005.
Gambar 4 Non hotspot di Provinsi Riau tahun 2005. c. Data Pusat kota Riau
Data pusat kota Riau merupakan data yang berisi mengenai ibu kota tiap kota/kabupaten wilayah Riau. Data ini berbentuk shapefile yang diolah menggunakan Quantum GIS. Data pusat kota Riau ini memiliki 6 pusat kota yaitu Tembilahan, Selatpanjang, Balai pungut, Duri, Bengkalis dan Dumai. Gambar 5 menunjukkan titik pusat kota di Provinsi Riau pada tahun 2005.
8
Gambar 5 Layer pusat kota di Provinsi Riau d. Data Sungai Riau
Data sungai Riau merupakan data yang berisi mengenai wilayah Riau yang dilalui oleh aliran sungai. Data ini berbentuk shapefile yang diolah menggunakan Quantum GIS. Terdapat 457 segmen aliran sungai di data sungai Riau. Gambar 6 menunjukkan aliran sungai di Provinsi Riau pada tahun 2005.
Gambar 6 Layer Sungai di Provinsi Riau e. Data Jalan Riau
Data jalan Riau merupakan data yang berisi seluruh jalan di wilayah Riau. Data ini berbentuk shapefile yang diolah menggunakan Quantum GIS. Data jalan Riau memiliki sebanyak 37657 segmen jalan. Gambar 7 menunjukkan segmen jalan di Provinsi Riau pada tahun 2005.
9
Pemberian label kelas
Pemberian label kelas ini digunakan untuk mendapatkan hasil data. Setelah semua shape di-import ke Sistem Manajemen Basis Data postgreSQL menjadi beberapa tabel dilakukan pemberian label kelas dengan kueri. Label T (True) digunakan pada data hotspot yang berjumlah 7169 titik hotspot dan label F (False) digunakan pada data non hotspot yang berjumlah 7200 titik non hotspot. Tabel tersebut diberi nama tabel hotspot.
Perhitungan Jarak
Pada tahap ini dilakukan perhitungan jarak dari kelas T dan kelas F ke pusat kota, kelas T dan kelas F ke sungai serta kelas T dan kelas F ke jalan di Provinsi Riau. Setelah setiap tabel diberikan label kelas True (T) dan False (F) dilakukan perhitungan jarak menggunakan kueri di PostgreSQL. Data sebaran hotspot, non hotspot, pusat kota, sungai dan jalan awalnya diolah di Quantum GIS berbentuk shapefile. Agar PostgreSQL dapat membaca shapefile yang berbentuk data spasial harus menggunakan PostGIS yang terintegrasi dengan PostgreSQL. Data tersebut di import dari Quantum GIS untuk menjadi tabel-tabel di PostgreSQL.
Perhitungan jarak hotspot dan non hotspot ke pusat kota terdekat, ke jalan terdekat dan ke sungai terdekat dilakukan dengan mengeksekusi pernyataan kueri spasial dalam PostgreeSQL. Berikut kueri untuk menghitung jarak hotspot dan non hotspot ke pusat kota (maincities) terdekat.
SELECT [h.gid as ID_hotspot],[h.geom as geom], min(ST_Distance (h.geom, m.geom))
FROM [riau_maincities AS m], [hotspot AS h] GROUP BY [h.gid];
Dataset jarak harus dikonversi dari decimal degree menjadi km untuk menyiapkan dataset akhir (1 degree = 111319.5 m = 111.3195 km). Jarak terdekat beberapa hotspot ke pusat kota, ke sungai dan ke jalan diberikan berturut-turut dalam Tabel 1, 2 dan 3.
Tabel 1 Jarak terdekat hotspot ke pusat kota
Id_Hotspot Jarakterdekat_Pusatkota (km) Kelas
1 39.0253843 T 2 39.58416374 T 3 10.50838916 T . . . . . . 9999 77.74134721 F 10000 107.922778 F
10
Tabel 2 Jarak terdekat hotspot ke sungai
Id_Hotspot Jarakterdekat_Sungai (km) Kelas
1 15.00513534 T 2 18.50195349 T 3 25.17563015 T . . . . . . 9999 5.021882999 F 10000 8.049548723 F
Tabel 3 Jarak terdekat hotspot ke jalan
Id_Hotspot Jarakterdekat_Jalan (km) Kelas
1 1.260659936 T 2 1.308696992 T 3 0.019610453 T . . . . . . 9999 0.681320262 F 10000 8.614583682 F
Transformasi Jarak Terdekat dari Hotspot
Pada tahap ini dilakukan transformasi hasil data menjadi kategorik agar lebih dimudahkan. Tahapan transformasi ini menggunakan perangkat lunak Microsoft Excel 2010 dengan menggunakan tools data analyst histogram. Kategori untuk jarak terdekat ke pusat kota, ke sungai dan ke jalan diberikan berturut-turut dalam Tabel 4, 5 dan 6.
Tabel 4 Kategori untuk jarak terdekat ke pusat kota
Tabel 5 Kategori untuk jarak terdekat ke sungai Pusat Kota
Bin Frequency Kategori Range (km)
31 2868 M1 (0, 31] 48 2832 M2 (31 , 48] 74 2947 M3 (48 , 74] 105 2868 M4 (74, 105] More 2854 M5 > 105 Sungai
Bin Frequency Kategori Range (km)
2 2913 RI1 (0 , 2]
4.5 2823 RI2 (2 , 4.5]
8.5 2939 RI3 (4.5 , 8.5]
16 2873 RI4 (8.5 , 16]
11 Tabel 6 Kategori untuk jarak terdekat ke jalan
Transformasi Tipe fail
Dalam tahap ini dilakukan perubahan format data latih dan data uji dari format CSV menjadi format .file sehingga dapat diolah ke dalam perangkat lunak Python 2.7.5.
Penentuan Data Latih dan Data Uji
Pemisahan data ke dalam data latih dan data uji untuk membentuk pohon keputusan spasial ini menggunakan 10-folds cross validation. Data akan dibagi ke dalam 10 bagian (folds). Setiap bagian akan digunakan sebagai data uji, 9 bagian (folds) akan dijadikan sebagai data latih, dan 1 bagian (fold) lainnya akan dijadikan sebagai data uji. Data latih akan digunakan untuk membentuk model klasifikasi. Sedangkan, data uji akan digunakan untuk menghitung akurasi yang diperoleh dari model klasifikasi.
Setelah tahap transformasi tipe fail dilakukan, tahap selanjutnya adalah membagi data menjadi 10 fold. Fold inilah yang akan digunakan pada tahap klasifikasi sebagai data latih dan data uji. Subset yang terbentuk memiliki jumlah instance sebanyak 1000 per fold dengan mengabaikan proporsi perbandingan antarkelas.
Klasifikasi Menggunakan Algoritme ID3
Proses klasifikasi dilakuan dua tahap, yaitu pembentukan pohon keputusan spasial dan perhitungan akurasi dari pohon keputusan spasial yang terbentuk.
Pohon Keputusan Spasial
Pembentukan pohon keputusan spasial dilakukan dengan menggunakan algoritme ID3 yang telah diimplementasikan dalam bahasa pemrograman Python 2.7.5. Modul ID3 dalam Python diperoleh dari Onlamp (2013). Dalam pembuatan pohon keputusan spasial di pemrograman Python ini terdapat 3 modul penting antara lain decision tree, ID3 dan modul test. Pada modul decision tree adalah proses untuk mendapatkan atribut terbaik dari himpunan atribut yang ada dengan menggunakan fungsi fitness yaitu information gain sebagai parameter. Dataset yang telah terbentuk diolah dan menghasilkan sebuah pohon keputusan. Atribut yang dipilih sebagai atribut uji adalah atribut yang memiliki information gain tertinggi sesuai dengan algoritme ID3.
Jalan
Bin Frequency Kategori Range(km)
0.22 2910 RO1 (0 , 0.22]
0.68 2872 RO2 (0.22 , 0.68] 1.5 2877 RO3 (0.68 , 1.5]
3.5 2898 RO4 (1.5 , 3.5]
12
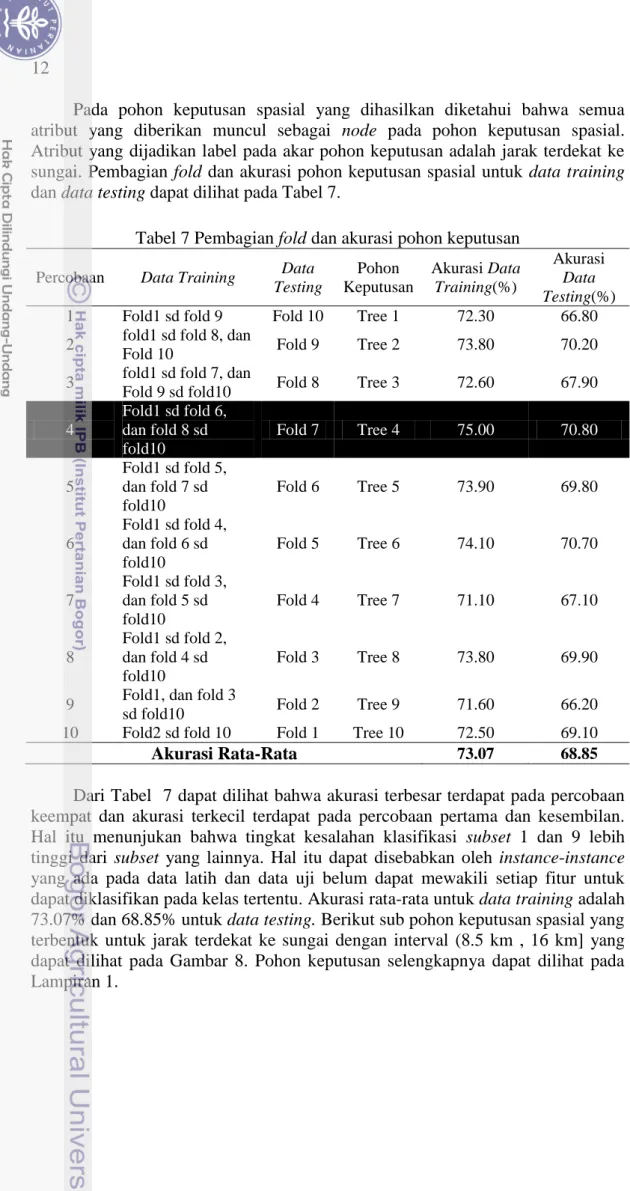
Pada pohon keputusan spasial yang dihasilkan diketahui bahwa semua atribut yang diberikan muncul sebagai node pada pohon keputusan spasial. Atribut yang dijadikan label pada akar pohon keputusan adalah jarak terdekat ke sungai. Pembagian fold dan akurasi pohon keputusan spasial untuk data training dan data testing dapat dilihat pada Tabel 7.
Tabel 7 Pembagian fold dan akurasi pohon keputusan Percobaan Data Training Data
Testing Pohon Keputusan Akurasi Data Training(%) Akurasi Data Testing(%)
1 Fold1 sd fold 9 Fold 10 Tree 1 72.30 66.80
2 fold1 sd fold 8, dan
Fold 10 Fold 9 Tree 2 73.80 70.20
3 fold1 sd fold 7, dan
Fold 9 sd fold10 Fold 8 Tree 3 72.60 67.90
4 Fold1 sd fold 6, dan fold 8 sd fold10 Fold 7 Tree 4 75.00 70.80 5 Fold1 sd fold 5, dan fold 7 sd fold10 Fold 6 Tree 5 73.90 69.80 6 Fold1 sd fold 4, dan fold 6 sd fold10 Fold 5 Tree 6 74.10 70.70 7 Fold1 sd fold 3, dan fold 5 sd fold10 Fold 4 Tree 7 71.10 67.10 8 Fold1 sd fold 2, dan fold 4 sd fold10 Fold 3 Tree 8 73.80 69.90
9 Fold1, dan fold 3
sd fold10 Fold 2 Tree 9 71.60 66.20
10 Fold2 sd fold 10 Fold 1 Tree 10 72.50 69.10
Akurasi Rata-Rata 73.07 68.85 Dari Tabel 7 dapat dilihat bahwa akurasi terbesar terdapat pada percobaan keempat dan akurasi terkecil terdapat pada percobaan pertama dan kesembilan. Hal itu menunjukan bahwa tingkat kesalahan klasifikasi subset 1 dan 9 lebih tinggi dari subset yang lainnya. Hal itu dapat disebabkan oleh instance-instance yang ada pada data latih dan data uji belum dapat mewakili setiap fitur untuk dapat diklasifikan pada kelas tertentu. Akurasi rata-rata untuk data training adalah 73.07% dan 68.85% untuk data testing. Berikut sub pohon keputusan spasial yang terbentuk untuk jarak terdekat ke sungai dengan interval (8.5 km , 16 km] yang dapat dilihat pada Gambar 8. Pohon keputusan selengkapnya dapat dilihat pada Lampiran 1.
13
Gambar 8 Sub pohon keputusan spasial untuk jarak terdekat ke sungai dengan interval (8.5 km , 16 km]
Berdasarkan pohon keputusan spasial yang terbentuk dapat dibuat 125 aturan klasifikasi. Sebagai contoh, aturan yang terbentuk dari pohon keputusan spasial pada Gambar 8 adalah sebagai berikut:
Aturan 1:
JIKA jarak lokasi ke sungai terdekat pada interval (2 km, 4.5 km] DAN jarak lokasi ke pusat kota terdekat pada interval (48 km, 74 km] DAN jarak lokasi ke jalan terdekat pada interval (0.22 km, 0.68 km] MAKA kemunculan titik api adalah T (True).
Aturan 2:
JIKA jarak lokasi ke sungai terdekat pada interval (0 km, 2 km] DAN jarak lokasi ke jalan terdekat pada interval (0.22 km, 0.68 km] DAN jarak lokasi ke pusat kota terdekat pada interval (48 km, 74 km] MAKA kemunculan titik api adalah F (False).
Aturan 3:
JIKA jarak lokasi ke sungai terdekat pada interval (8.5 km, 16 km] DAN jarak lokasi ke pusat kota terdekat pada interval (0 km, 31 km] DAN jarak lokasi ke jalan terdekat pada interval (1.5 km, 3.5 km] MAKA kemunculan titik api adalah T (True).
Aturan 4:
JIKA jarak lokasi ke sungai terdekat pada interval (2 km, 4.5 km] DAN jarak lokasi ke pusat kota terdekat pada interval (74 km, 105 km] DAN jarak lokasi ke jalan terdekat pada interval (0 km, 0.22 km] MAKA kemunculan titik api adalah F (False).
14
Aturan 5:
JIKA jarak lokasi ke sungai terdekat pada interval > 16 km DAN jarak lokasi kepusat kota terdekat pada interval (31 km, 48 km] DAN jarak lokasi ke jalan terdekat pada interval > 3.5 km MAKA kemunculan titik api adalah T (True).
Akurasi Model
Pada penelitian ini didapat akurasi model yang dapat dilihat pada Tabel 8. Tabel 8 Akurasi Model
Kelas Hasil Aktual
Kelas Hasil Prediksi
Total
T F
T 324 126 450
F 166 384 550
Total 490 510 1000
Dari Tabel 8 diketahui dari 450 data di kelas hasil aktual T, sebanyak 324 atau 72% data diprediksi secara benar sebagai label kelas T (True Positif) dan 126 data diprediksi salah sebagai label kelas F (False Negative). Dari 550 data di kelas hasil aktual F, sebanyak 384 data diprediksi benar sebagai label kelas F (True Negative) atau 66.12% dan 166 data diprediksi salah sebagai label kelas F (False Negative). Akurasi rata-ratanya sebesar 70.91%.
Penggunaan Klasifikasi pada Data Baru
Pada tahap ini, terdapat beberapa record data contoh untuk menunjukkan bagaimana penggunaan klasifikasi pada data baru yang belum memiliki label kelas. Pada data contoh terdapat 5 record yang atribut kelasnya belum terisi. Untuk pengisian masing-masing record dilakukan dengan cara menelusuri model pohon yang didapat dengan melihat dari aturan pohonnya. Ilustrasi data contoh dapat dilihat pada Tabel 9.
Tabel 9 Contoh data baru
Record_ID JARAKTERDEKAT PUSAT KOTA (km) JARAKTERDEKAT SUNGAI (km) JARAKTERDEKAT JALAN (km) Kelas 1 M2 (31 , 48] RI5> 16 RO5> 3.5 ? 2 M4 (74, 105] RI2 (2 , 4.5] RO1 (0 , 0.22] ? 3 M3 (48 , 74] RI2 (2 , 4.5] RO2 (0.22 , 0.68] ? 4 M3 (48 , 74] RI1 (0 , 2] RO4 (1.5 , 3.5] ? 5 M1 (0, 31] RI4 (8.5 , 16] RO4 (1.5 , 3.5] ?
Pengisian label kelas pada record 1 dilakukan dengan mencari aturan yang sesuai pada himpunan aturan. Aturan yang sesuai adalah Rules 5 dengan nilai tes atribut jarak dengan pusat kota terdekat pada interval (31 km, 48 km], jarak
15 dengan sungai interval > 16 km dan jarak dengan jalannya sejauh > 3.5 km maka kemunculan titik api adalah kelasnya T (True).
Pengisian label kelas pada record 2 dilakukan dengan mencari aturan yang sesuai pada himpunan aturan. Aturan yang sesuai adalah Rules 4 dengan nilai tes atribut jarak dengan pusat kota terdekat pada interval (74 km, 105 km], jarak dengan sungai interval (2 km, 4.5 km] dan jarak dengan jalannya sejauh interval (0 km, 0.22 km] maka kemunculan titik api adalah kelasnya F (False).
Pengisian label kelas pada record 3 dilakukan dengan mencari aturan yang sesuai pada himpunan aturan. Aturan yang sesuai adalah Rules 1 dengan nilai tes atribut jarak dengan pusat kota terdekat pada interval (48 km, 74 km], jarak dengan sungai interval (2 km, 4.5 km] dan jarak dengan jalannya sejauh interval (0.22 km, 0.68 km] maka kemunculan titik api adalah kelasnya T (True).
Pengisian label kelas pada record 4 dilakukan dengan mencari aturan yang sesuai pada himpunan aturan. Aturan yang sesuai adalah Rules 2 dengan nilai tes atribut jarak dengan pusat kota terdekat pada interval (48 km, 74 km], jarak dengan sungai interval (0 km, 2 km] dan jarak dengan jalannya sejauh interval (1.5 km, 3.5 km] maka kemunculan titik api adalah kelasnya F (False).
Pengisian label kelas pada record 5 dilakukan dengan mencari aturan yang sesuai pada himpunan aturan. Aturan yang sesuai adalah Rules3 dengan nilai test atribut jarak dengan pusat kota terdekat pada interval (0 km, 31 km], jarak dengan sungai interval (8.5 km , 16 km] dan jarak dengan jalannya sejauh interval (1.5 km, 3.5 km] maka kemunculan titik api adalah kelasnya T (True).
SIMPULAN DAN SARAN
Simpulan
Berdasarkan penelitian yang dilakukan dalam membentuk model klasifikasi hotspot di wilayah Riau pada tahun 2005, dapat diambil kesimpulan sebagai berikut:
1 Pohon keputusan spasial yang telah dibentuk memiliki label akar yaitu jarak terdekat sungai. Pohon keputusan spasial ini terdiri dari 31 node.
2 Dari pohon keputusan spasial yang dihasilkan dapat diturunkan 125 aturan klasifikasi untuk menentukan kemunculan hotspot.
3 Pohon keputusan spasial telah diuji pada data training dan data testing dengan menggunakan metode 10-fold cross validation. Akurasi terbesar pohon keputusan spasial pada data training adalah 75% , sedangkan pada data testing adalah 70.80%.
4 Akurasi rata-rata pada data training adalah 73.07% dan pada data testing adalah 68.85%.
Saran
Saran-saran yang dapat diberikan untuk pengembangan lebih lanjut adalah penambahan data spasial lainnya terkait kebakaran hutan yang menentukan kemunculan titik api, sehingga pohon keputusan yang dihasilkan lebih akurat.
16
DAFTAR PUSTAKA
Fu L. 1994. Neural Network in Computers Intelligence. Singapura: McGraw-Hill. Han J, Kamber M. 2006. Data Mining : Concepts and Techniques. San Francisco :
Morgan Kaufman Publisher.
Onlamp. 2013. Onlamp [Internet]. [diunduh 2013 Dec 1].Tersedia pada http://www.onlamp.com/pub/a/python/2006/02/09/ai_decision_trees.html?page =2
Pemerintah Provinsi Riau. 2013. Pemerintah Provinsi Riau [Internet]. [diunduh 2013 Dec 1].Tersedia pada: http://www.riau.go.id/index.php?/detail/61).
17
LAMPIRAN
Lampiran 1 Pohon Keputusan Spasial.
JARAKTERDEKAT_RIVER RI4 JARAKTERDEKAT_ROAD RO1 JARAKTERDEKAT_MAINCITIES M5 -> T M4 -> F M1 -> T M3 -> T M2 -> F RO2 JARAKTERDEKAT_MAINCITIES M5 -> T M4 -> F M1 -> T M3 -> T M2 -> T RO3 JARAKTERDEKAT_MAINCITIES M5 -> T M4 -> T M1 -> T M3 -> T M2 -> T RO4 JARAKTERDEKAT_MAINCITIES M5 -> F M4 -> T M1 -> T M3 -> T M2 -> T R05
18 JARAKTERDEKAT_MAINCITIES M5 -> F M4 -> F M1 -> F M3 -> T M2 -> F RI5 JARAKTERDEKAT_MAINCITIES M5 JARAKTERDEKAT_ROAD RO1 -> T RO2 -> T RO3 -> T R05 -> F RO4 -> T M4 JARAKTERDEKAT_ROAD RO1 -> T RO2 -> T RO3 -> T RO4 -> T R05 -> T M1 JARAKTERDEKAT_ROAD RO1 -> T RO2 -> T RO3 -> T RO4 -> T R05 -> T M3 JARAKTERDEKAT_ROAD RO1 -> F RO2 -> F RO3 -> F R05
19 -> T RO4 -> F M2 JARAKTERDEKAT_ROAD RO1 -> T RO2 -> T RO3 -> T RO4 -> T R05 -> T RI2 JARAKTERDEKAT_MAINCITIES M5 JARAKTERDEKAT_ROAD RO4 -> F RO2 -> F RO3 -> F R05 -> F RO1 -> F M4 JARAKTERDEKAT_ROAD R05 -> F RO2 -> F RO3 -> F RO4 -> F RO1 -> F M1 JARAKTERDEKAT_ROAD RO4 -> F RO2 -> F RO3 -> F R05 -> F RO1 -> F M3 JARAKTERDEKAT_ROAD RO1 -> T RO4
20 -> F RO3 -> T R05 -> F RO2 -> T M2 JARAKTERDEKAT_ROAD RO1 -> T RO2 -> T RO3 -> F RO4 -> F R05 -> F RI3 JARAKTERDEKAT_MAINCITIES M5 JARAKTERDEKAT_ROAD RO1 -> T RO2 -> T RO3 -> F RO4 -> T R05 -> F M4 JARAKTERDEKAT_ROAD RO1 -> F RO2 -> F RO3 -> F RO4 -> F R05 -> F M1 JARAKTERDEKAT_ROAD RO1 -> T RO2 -> T RO3 -> T R05 -> T RO4 -> F M3
21 JARAKTERDEKAT_ROAD RO1 -> F RO2 -> F RO3 -> F RO4 -> F R05 -> F M2 JARAKTERDEKAT_ROAD RO1 -> F RO2 -> T RO3 -> T R05 -> F RO4 -> F RI1 JARAKTERDEKAT_ROAD R05 JARAKTERDEKAT_MAINCITIES M5 -> F M4 -> F M1 -> F M3 -> F M2 -> F RO2 JARAKTERDEKAT_MAINCITIES M5 -> F M4 -> F M1 -> F M3 -> F M2 -> F RO3 JARAKTERDEKAT_MAINCITIES M5 -> F M4 -> F M1 -> F M3
22 -> F M2 -> F RO4 JARAKTERDEKAT_MAINCITIES M5 -> F M4 -> F M1 -> F M3 -> F M2 -> F RO1 JARAKTERDEKAT_MAINCITIES M5 -> F M4 -> F M1 -> F M3 -> F M2 -> F
23
RIWAYAT HIDUP
Penulis dilahirkan di Padang Panjang, Sumatera Barat pada tanggal 10 Desember 1989. Penulis merupakan anak kedua dari tiga bersaudara dari pasangan Bapak Jontrifizal SSos dan Ibu Gusmiyetty Spd.
Penulis menempuh pendidikan formal di SMA N 1 Payakumbuh, Sumatera Barat dan diselesaikan pada tahun 2008. Selanjutnya pada tahun yang sama, penulis diterima sebagai mahasiswa Program Diploma Institut Pertanian Bogor, Program Keahlian Teknik Komputer melalui jalur Undangan Seleksi Masuk Institut Pertanian Bogor (USMI). Penulis kemudian melanjutkan pendidikan S1 Alih Jenis pada Program Studi Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor pada tahun 2011.





![Gambar 8 Sub pohon keputusan spasial untuk jarak terdekat ke sungai dengan interval (8.5 km , 16 km]](https://thumb-ap.123doks.com/thumbv2/123dok/4613564.3369533/23.892.143.744.140.1191/gambar-pohon-keputusan-spasial-untuk-terdekat-sungai-interval.webp)

