ix
5.2.1 Pencarian frequent item ... 62
5.2.2 FP-Tree ... 63
5.2.3 Conditional FP-Tree ... 68
5.2.4 Ekstraksi itemset ... 71
5.3 Implementasi Cosine Similarity ... 72
5.4 Implementasi Penentuan Rekomendasi ... 73
BAB VI HASIL DAN PEMBAHASAN ... 77
6.1 Data Pengujian ... 77
6.1.1 Dokumen pengujian ... 77
6.1.2 Data transaksi ... 77
6.1.3 Stopword ... 79
6.2 Metode Pengumpulan Data ... 79
6.3 Skenario Pengujian ... 79
6.4 Hasil Pengujian ... 79
6.4.1 Precision ... 80
6.4.2 Recall ... 84
6.4.3 F-Measure ... 87
6.4.4 Mean average precision ... 90
BAB VII KESIMPULAN DAN SARAN ... 94
7.1 Kesimpulan ... 94 7.2 Saran ... 95 DAFTAR PUSTAKA ... 96 LAMPIRAN 1 ... 101 LAMPIRAN 2 ... 106 LAMPIRAN 3 ... 117 LAMPIRAN 4 ... 126 LAMPIRAN 5 ... 130
x
DAFTAR TABEL
Tabel 2.1 Tinjauan pustaka ... 16
Tabel 3.1 Data transaksi ... 20
Tabel 3.2 Representasi keranjang ... 20
Tabel 3.3 Frequent itemset ... 20
Tabel 3.4 Daftar partikel ... 27
Tabel 3.5 Daftar kata ganti kepunyaan ... 27
Tabel 3.6 Daftar awalan pertama ... 28
Tabel 3.7 Kombinasi ilegal ... 28
Tabel 3.8 Daftar akhiran ... 29
Tabel 3.9 Daftar awalan kedua... 29
Tabel 3.10 Awalan ganda ... 29
Tabel 3.11 Pembagian kondisi hasil yang memungkinkan ... 32
Tabel 4.1 Contoh data transaksi ... 44
Tabel 4.2 Seleksi data transaksi ... 45
Tabel 4.3 Jumlah kemunculan item ... 45
Tabel 4.4 Urutan frequent item ... 47
Tabel 4.5 Data transaksi terurut dan terseleksi ... 48
Tabel 4.6 Hasil frequent itemset... 49
Tabel 4.7 Rancangan tabel administrator ... 53
Tabel 4.8 Rancangan tabek transaksi ... 53
Tabel 4.9 Rancangan tabel dokumen ... 54
Tabel 4.10 Rancangan tabel ambang batas ... 54
Tabel 4.11 Rancangan tabel stoplist... 55
Tabel 4.12 Rancangan tabel dokumen term ... 55
Tabel 5.1 Penyimpanan jumlah item pada array ... 63
Tabel 5.2 Urutan frequent itemset ... 75
Tabel 6.1 Dokumen uji ... 78
Tabel 6.2 Jumlah data transaksi masing-masing dokumen uji ... 78
xi
Tabel 6.4 Precision minimum similarity 40% dengan minimum support 20% ... 81
Tabel 6.5 Nilai precision jumlah rekomendasi maksimal ... 81
Tabel 6.6 Nilai precision jumlah rekomendasi terbatas ... 83
Tabel 6.7 Recall minimum similarity 40% dengan minimum support 20% ... 84
Tabel 6.8 Nilai recalljumlah rekomendasi maksimal...85
Tabel 6.9 Nilai recall jumlah rekomendasi terbatas ... 86
Tabel 6.10 F-measure minimum similarity 40% dengan minimum support 20% . 88 Tabel 6.11 Nilai F-measure jumlah rekomendasi maksimal ... 88
Tabel 6.12 Nilai F-measure jumlah rekomendasi terbatas ... 89
Tabel 6.13 AP ID 9 minimum similarity 40% dengan minimum support 20% ... 91
Tabel 6.14 MAP minimum similarity 40% dengan minimum support 20% ... 92
xii
DAFTAR GAMBAR
Gambar 3.1 Penentuan frequent item ... 21
Gambar 3.2 FP-Tree ... 22
Gambar 3.3 Pembentukan conditional FP-Tree item „e‟ ... 22
Gambar 3.4 Conditional FP-Tree item „e‟ ... 23
Gambar 3.5 Pembentukan conditional FP-Tree item „b e‟ ... 23
Gambar 3.6 Urutan hasil penggalian frequent itemset ... 24
Gambar 3.7 Skema Tala stemmer ... 26
Gambar 4.1 Gambaran umum hybrid recommendation system ... 35
Gambar 4.2 Arsitektur hybrid recommendation system ... 38
Gambar 4.3 Flowchart tokenisasi ... 39
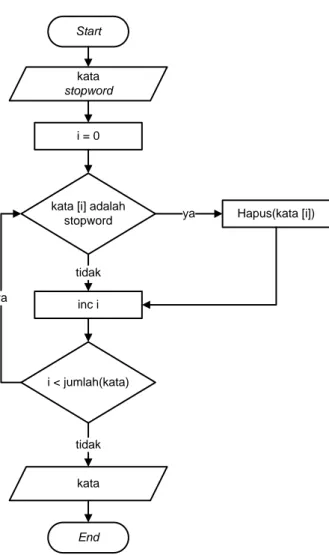
Gambar 4.4 Flowchart stopword removal ... 41
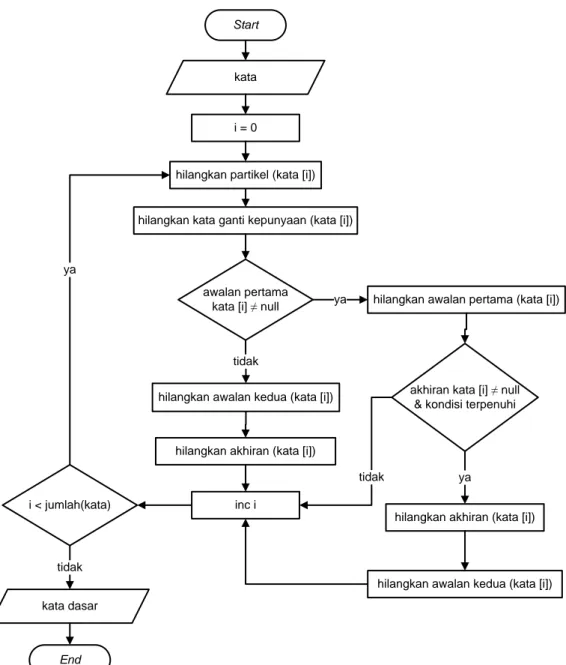
Gambar 4.5 Flowchart Tala stemmer... 42
Gambar 4.6 Flowchart pembobotan ... 43
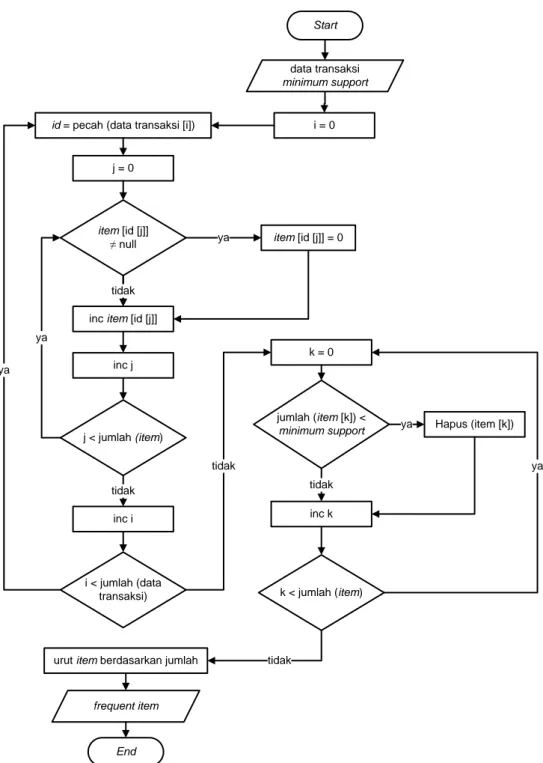
Gambar 4.7 Flowchart pencarian frequent item ... 46
Gambar 4.8 Flowchart pembentukan FP-Tree... 48
Gambar 4.9 FP-Tree dan Prefix Path ... 49
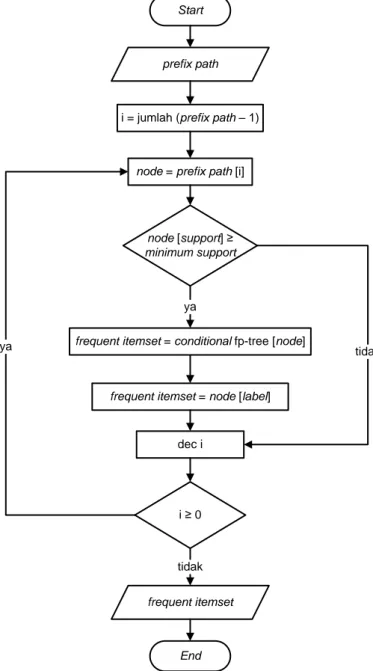
Gambar 4.10 Flowchart penggalian frequent itemset ... 50
Gambar 4.11 Flowchart cosine similarity ... 51
Gambar 4.12 Flowchart penentuan rekomendasi ... 52
Gambar 4.13 Rancangan halaman penampilan rekomendasi ... 56
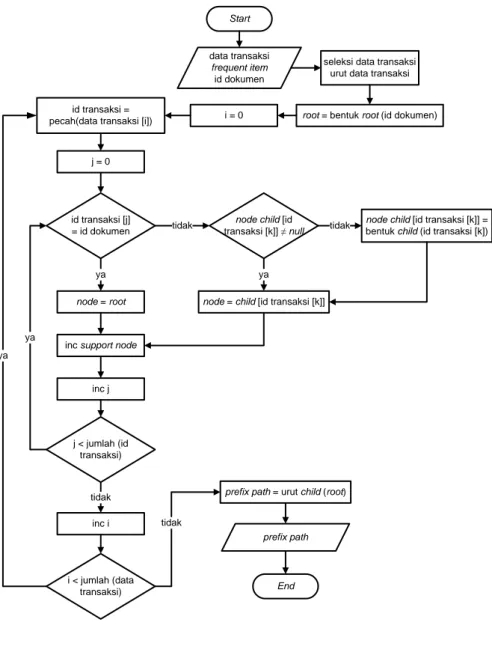
Gambar 4.14 Flowchart pembentukan data transaksi ... 57
Gambar 5.1 Potongan kode tokenisasi ... 59
Gambar 5.2 Potongan kode stopword removal ... 59
Gambar 5.3 Potongan kode stemming ... 60
Gambar 5.4 Potongan kode perhitungan term frequency ... 61
Gambar 5.5 Potongan kode frequent item search ... 62
Gambar 5.6 Pengurutan frequent item ... 63
Gambar 5.7 Potongan kode struktur data Tree... 64
xiii
Gambar 5.9 Pembentukan FP-Tree data transaksi 1, 2, 4, 5, dan 6 ... 66
Gambar 5.10 FP-Tree semua data transaksi ... 67
Gambar 5.11 Implementasi FP-Tree akhir ... 67
Gambar 5.12 Potongan kode pembentukan conditional FP-Tree ... 68
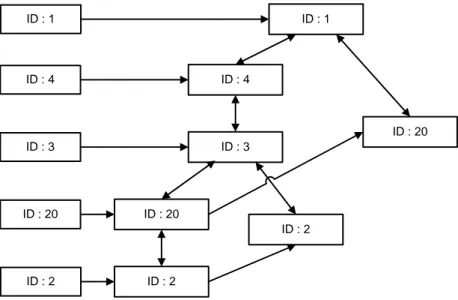
Gambar 5.13 Conditional FP-Tree untuk item id 2... 69
Gambar 5.14 Conditional FP-Tree untuk item id 20... 70
Gambar 5.15 Conditional FP-Tree untuk item id 3... 70
Gambar 5.16 Conditional FP-Tree untuk item id 4... 71
Gambar 5.17 Potongan kode ekstraksi itemset ... 71
Gambar 5.18 Urutan penggalian itemset ... 72
Gambar 5.19 Potongan kode perhitungan cosine similarity ... 73
Gambar 5.20 Potongan kode proses rekomendasi ... 74
Gambar 5.21 Antar muka halaman rekomendasi ... 76
Gambar 6.1 Grafik nilai precision jumlah rekomendasi maksimal ... 82
Gambar 6.2 Grafik nilai precision jumlah rekomendasi terbatas ... 84
Gambar 6.3 Grafik nilai recall jumlah rekomendasi maksimal ... 86
Gambar 6.4 Grafik nilai recall rekomendasi terbatas ... 87
Gambar 6.5 Grafik nilai F-measure jumlah rekomendasi maksimal ... 89
Gambar 6.6 Grafik nilai F-measure jumlah rekomendasi terbatas ... 90
xiv
INTISARI
HYBRID RECOMMENDATION SYSTEM MEMANFAATKAN PENGGALIAN FREQUENT ITEMSET DAN PERBANDINGAN
KEYWORD Oleh
Wayan Gede Suka Parwita 11/322973/PPA/03599
Recommendation system sering dibangun dengan memanfaatkan data peringkat item dan data identitas pengguna. Data peringkat item merupakan data yang langka pada sistem yang baru dibangun. Sedangkan, pemberian data identitas pada recommendation system dapat menimbulkan kekhawatiran penyalahgunaan data identitas.
Hybrid recommendation system memanfaatkan algoritma penggalian frequent itemset dan perbandingan keyword dapat memberikan daftar rekomendasi tanpa menggunakan data identitas pengguna dan data peringkat item. Penggalian frequent itemset dilakukan menggunakan algoritma FP-Growth. Sedangkan perbandingan keyword dilakukan dengan menghitung similaritas antara dokumen dengan pendekatan cosine similarity.
Hybrid recommendation system memanfaatkan kombinasi penggalian frequent itemset dan perbandingan keyword dapat menghasilkan rekomendasi tanpa menggunakan identitas pengguna dan data peringkat dengan penggunaan ambang batas berupa minimum similarity, minimum support, dan jumlah rekomendasi. Dengan data uji yang digunakan, nilai pengujian yaitu precision, recall, F-measure, dan MAP dipengaruhi oleh besarnya nilai ambang batas yang ditetapkan. Selain itu, kasus biasa pada kondisi terbaik dapat mencapai nilai yang lebih tinggi dibandingkan dengan kasus coldstart baik untuk jumlah rekomendasi terbatas maupun rekomendasi maksimal.
Kata kunci : Hybrid recommendation system, frequent itemset, cosine similarity.
xv
ABSTRACT
HYBRID RECOMMENDATION SYSTEM USING FREQUENT ITEMSET MINING AND KEYWORD COMPARISON
By
Wayan Gede Suka Parwita 11/322973/PPA/03599
Recommendation system was commonly built by manipulating item ranking data and user identity data. Item ranking data was a rare data on newly constructed system. Whereas, giving identity data to the recommendation system can cause concern about identity data misuse.
Hybrid recommendation system used frequent itemset mining algorithm and keyword comparison, it can provide recommendations without identity data and item ranking data. Frequent itemset mining was done using FP-Gwowth algorithm and keyword comparison with calculating document similarity value using cosine similarity approach.
Hybrid recommendation system with a combination of frequent itemset mining and keywords comparison can give recommendations without using user identity and rating data. Hybrid recommendation system used 3 thresholds ie minimum similarity, minimum support, and number of recommendations. With the testing data used, precision, recall, F-measure, and MAP testing value are influenced by the threshold value. In addition, the usual problem in the best threshold can achieve a higher testing value than the coldstart problem both for the limited number of recommendations and the maximum recommendations.
Keyword : Hybrid recommendation system, frequent itemset, cosine similarity.
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Peningkatan jumlah dokumen ilmiah yang ada menimbulkan kebutuhan akan suatu sistem yang dapat memberikan rekomendasi dokumen ilmiah yang baik. Recommendation system merupakan model aplikasi yang dibangun dari hasil pengamatan terhadap keadaan dan keinginan pengguna. Sistem ini memanfaatkan opini pengguna terhadap suatu item dalam domain atau kategori tertentu. Karena itu sistem ini memerlukan model rekomendasi yang tepat agar apa yang direkomendasikan sesuai dengan keinginan pengguna, serta mempermudah pengguna mengambil keputusan yang tepat (McGinty dan Smyth, 2006).
Recommendation system atau disebut pula recommender system mulai diperhatikan sejak kemunculan penelitian tentang collaborative filtering pada pertengahan 90‟an (Goldberg, dkk., 1992), (Resnick, dkk., 1994). Selama dekade terakhir ini, recommendation system telah banyak diterapkan dengan berbagai pendekatan baru, baik oleh dunia industri maupun akademis. Pada dunia industri, recommendation system sangat diperlukan terutama pada e-commerce web sites. Ini ditunjukkan dengan penggunaan recommendation system pada sebagian besar e-commerce web sites yang dimiliki oleh industri. Selain membantu pengguna dalam mencari item yang diinginkan, recommendation system juga dapat meningkatkan penjualan, ketertarikan maupun loyalitas pengguna terhadap suatu item dan juga perusahaan (Godfrey, 2007). Amazone.com merupakan contoh industri yang menerapkan sistem rekomendasi dalam e-commerce web sites mereka (Linden, dkk., 2003). Penerapan recommendation system berbasis collaborative filtering juga diterapkan pada jejaring sosial seperti Facebook, MySpace, dan LinkedIn (Ricci, dkk., 2011)
Berbagai metode pendekatan telah diterapkan dan dikembangkan dalam implementasi recommendation system. Berdasarkan object filtering, metode tersebut dapat dikelompokkan ke dalam 3 jenis umum, yaitu metode collaborative
2
filtering, content-based filtering, dan hybrid filtering (Hsieh, dkk., 2004). Metode yang banyak digunakan adalah collaborative filtering dan content-based filtering. Masing-masing metode tersebut memiliki sejumlah kelebihan. Umpan balik yang digunakan pada metode collaborative filtering mengakibatkan sistem dapat memprediksi keinginan pengguna. Sedangkan metode content-based filtering menggunakan konten dari item sehingga dapat memberikan rekomendasi tanpa adanya umpan balik dari pengguna.
Di samping memiliki kelebihan, kedua metode tersebut juga memiliki sejumlah kelemahan. Metode collaborative filtering baik user-based maupun item-based sangat tergantung dengan umpan balik yang diberikan oleh pengguna. Umpan balik berupa peringkat, data transaksi, maupun data identitas yang diberikan oleh pengguna. Tanpa umpan balik, metode collaborative filtering tidak dapat melakukan rekomendasi. Penggunaan data identitas pada metode user-based collaborative filtering juga mengakibatkan pengguna harus terdaftar pada sistem untuk membedakan klasifikasi data yang dikumpulkan dari pengguna. Akan tetapi, pengguna terkadang enggan untuk mendaftar pada sistem karena kekhawatiran terhadap penyalahgunaan data identitas. Di sisi lain, metode content-based memiliki ketergantungan terhadap perbandingan konten maupun atribut antara item.
Recommendation system berbasis data mining dapat dikategorikan menjadi collaborative filtering maupun content-based filtering. Namun recommendation system yang memanfaatkan data mining berbasis data transaksi dapat dikategorikan ke dalam item-based collaborative filtering. Item-based collaborative filtering menggunakan kedekatan item untuk menentukan rekomendasi. Kedekatan dapat dicari dengan melihat data transaksi yang melibatkan item tersebut. Metode pada data mining dapat dimanfaatkan dalam pencarian rekomendasi karena data mining juga memiliki fungsi untuk mencari kedekatan atara item. Dalam penerapan item-based ini dapat digunakan berbagai metode dalam data mining diantaranya klasifikasi, asosiasi, dan klaterisasi.
Kaidah asosiasi digunakan untuk mencari hubungan asosiatif antara kombinasi item. Asosiasi telah sukses diterapkan dalam masalah market basket. Pada pencarian kaidah asosiasi terdapat 2 tahap yang dilalui. Salah satu tahap yang dilakukan untuk pencarian kaidah asosiasi adalah penggalian frequent itemset dengan memanfaatkan minimum support. Tahap ini merupakan tahap yang menggunakan sumber daya yang paling besar. Semakin besar data transaksi yang digunakan maka semakin besar sumber daya yang digunakan. Data transaksi menyimpan informasi penting yang dihasilkan selama interaksi manusia dan komputer yang berguna untuk algoritma pembentukan rekomendasi. Data transaksi juga mencakup umpan balik eksplisit pengguna (Ricci, dkk., 2011). Untuk menghasilkan frequent itemset yang baik, maka minimum support pada tahap ini harus disesuaikan dengan data transaksi yang dimiliki. Recommendation system untuk dokumen ilmiah dapat memanfaatkan fungsi dari penggalian frequent itemset ini. Hanya saja, hubungan antara item belum dapat dipastikan secara jelas walaupun fungsi dari penggalian itu sendiri merupakan pencarian hubungan antara item. Ini disebabkan karena tahap penggalian frequent itemset tidak dilanjutkan dengan perhitungan confident antara item/itemset. Untuk mendapatkan kepastian hubungan antar item dalam itemset, dapat digunakan perbandingan keyword yang diekstraksi dari masing-masing dokumen ilmiah.
Ekstraksi keyword yang dilakukan secara manual membutuhkan waktu yang tidak sedikit. Untuk itu, ekstraksi keyword pada dokumen ilmiah dapat menggunakan keyword extraction system. Dalam penerapannya, umumnya sistem ini digunakan untuk identifikasi topik dokumen. Pembandingan keyword dokumen termasuk content-based recommendation system karena menggunakan isi dari dokumen untuk membentuk rekomendasi. Keyword extraction system merupakan sistem yang dapat menemukan keyword dari dokumen secara otomatis. Metode cosine similarity merupakan salah satu metode untuk menghitung similaritas dokumen. Kelebihan utama dari metode cosine similarity adalah tidak terpengaruh pada panjang pendeknya suatu dokumen (Rozas dan
4
Sarno, 2011). Dengan melakukan perbandingan keyword yang dihasilkan, maka kedekatan antara item-pun dapat dipastikan.
Penentuan rekomendasi tanpa penggunaan data peringkat dan data identitas pengguna dapat dilakukan dengan menggunakan kombinasi metode penggalian frequent itemset dan perbandingan keyword yang menjadi kontribusi penelitian ini. Penggunaan penggalian frequent itemset yang dikombinasikan dengan perbandingan keyword akan menghasilkan hybrid recommendation system. Penggalian frequent itemset akan memperkecil jumlah pembandingan keyword yang dilakukan sehingga jumlah perbandingan keyword dapat dikurangi. Sedangkan perbandingan keyword akan memastikan item yang dihasilkan algoritma penggalian frequent itemset saling terkait.
Berdasarkan latar belakang tersebut, maka pada penelitian ini akan dilakukan kombinasi dari algorima penggalian frequent itemset dan perbandingan hasil keyword extraction system untuk penentuan rekomendasi. Kombinasi ini akan menghasilkan hybrid recommendation system untuk penentuan rekomendasi dokumen ilmiah.
1.2 Rumusan Masalah
Berdasarkan latar belakang yang telah dipaparkan dapat dirumuskan masalah yang akan dikaji dalam penelitian ini yaitu bagaimana menghasilkan recommendation system untuk merekomendasikan dokumen ilmiah tanpa menggunakan data identitas pengguna dan data peringkat yang diberikan oleh pengguna dengan memanfaatkan kombinasi 2 metode. Metode pertama melakukan penggalian frequent itemset pada data transaksi pemilihan dokumen ilmiah. Kemudian metode kedua melakukan perbandingan antar item yang masuk pada itemset dengan membandingkan keyword yang dihasilkan secara otomatis.
1.3 Batasan Masalah
Berikut merupakan batasan masalah yang digunakan agar penelitian ini tetap mengacu pada topik penelitian:
a. Keyword extraction system akan didasarkan pada dokumen ilmiah berbahasa Indonesia.
b. Keyword extraction system melakukan ekstraksi terhadap teks bukan gambar ataupun bentuk lain selain teks.
c. Recommendation system yang dibangun tidak menekankan pada proses seleksi dokumen saat pencarian dokumen.
d. Jumlah rekomendasi yang dihasilkan oleh sistem akan ditentukan secara manual oleh administrator sistem.
e. Dokumen ilmiah yang digunakan untuk pengujian merupakan 100 dokumen ilmiah yang berupa jurnal bahasa Indonesia yang diambil secara acak.
1.4 Tujuan Penelitian
Tujuan penelitian yaitu menghasilkan recommendation system dokumen ilmiah bahasa Indonesia yang berfokus pada pemanfaatan algoritma penggalian frequent itemset dan perbandingan keyword dengan memanfaatkan data transaksi dan isi dari dokumen.
1.5 Manfaat Penelitian
Penelitian ini diharapkan menjadi referensi tentang pengembangan hybrid recommendation system untuk dokumen berbahasa Indonesia tanpa memperhitungkan peringkat yang diberikan pengguna dan juga dapat mengatasi kelemahan dari item-based collaborative filtering dan content-based filtering yang berdiri sendiri. Selain itu, penelitian ini juga diharapkan menjadi referensi dalam pemanfaatan algoritma pada data mining dan text mining untuk pengembangan recommendation system.
6
1.6 Metodologi Penelitian
Penelitian ini dilakukan dengan mengikuti langkah-langkah sebagai berikut:
1. Mempelajari pustaka dan literatur acuan: tahap ini dilakukan dengan membaca serta memahami buku teks, jurnal, dan karya ilmiah lainnya yang terkait dengan penelitian.
2. Analisis: kegiatan analisa meliputi analisa metode, alternatif algoritma yang diterapkan, sepesifikasi perangkat lunak, dan analisa fungsionalitas.
3. Perancangan: tahap ini meliputi perancangan algoritma dan pemodelan arsitektur untuk metode keyword extraction system, penggalian frequent itemset, dan perbandingan keyword yang diterapkan untuk penentuan rekomendasi dokumen.
4. Implementasi: tahap implementasi merupakan pembangunan sistem perangkat lunak berdasarkan perancangan yang telah dilakukan sebelumnya. 5. Evaluasi dan perbaikan: pada tahap ini dilakukan evaluasi dari sistem serta
memperbaikinya jika terdapat kesalahan yang terjadi.
6. Pengujian dan analisa akhir: tahap ini meliputi pengujian kualitas dan kinerja dari recommendation system yang dibangun.
7. Penulisan laporan: pada tahap ini dilakukan penulisan laporan dari hasil penelitian yang telah dilakukan.
1.7 Sistematika Penulisan
Penulisan tesis ini terdiri dari 7 bab, adapun sistematika dari tesis ini adalah:
BAB I PENDAHULUAN
Pada bab ini diuraikan secara singkat mengenai latar belakang masalah, perumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metodologi penlitian, dan sistematika penulisan.
BAB II TINJAUAN PUSTAKA
Pada bab ini dibahas penelitian-penelitian yang sudah dilakukan sebagai perbandingan dan acuan untuk penelitian ini.
BAB III LANDASAN TEORI
Pada bab ini diuraikan teori-teori dasar berkaitan dengan penelitian yang dilakukan sebagai dasar dalam pemecahan masalah. Teori tersebut meliputi recommendation system, keyword extraction system, penggalian frequent itemset serta cosine similarity.
BAB IV ANALISIS DAN PERANCANGAN
Pada bab ini diuraikan perancangan metode-metode yang digunakan pada penelitian.
BAB V IMPLEMENTASI
Pada bab ini dibahas tentang implementasi rancangan algoritma dan antarmuka yang digunakan pada sistem meliputi potongan program serta implementasi rancangan antarmuka sistem.
BAB VI HASIL DAN PEMBAHASAN
Pada bab ini dilakukan pengujian terhadap recommendation system yang dibangun serta pembahasan hasil pengujian. Pengujian meliputi
8
perhitungan nilai precision, recall, F-measure, mean average precision dari sistem yang dibangun.
BAB VII KESIMPULAN DAN SARAN
Pada bab ini berisi kesimpulan dari hasil penelitian serta saran-saran untuk penelitian lebih lanjut.
9
BAB II
TINJAUAN PUSTAKA
Recommendation system pertama kali muncul pada tahun 1997 (Resnick dan Varian, 1997). Beberapa penelitian yang telah dilakukan sebelumnya berkaitan dengan document recommendation system dan hybrid recommendation system.
2.1 Document Recommendation System
Hsieh dkk. (2004) mengajukan recommendation system yang dapat melakukan penyaringan berita online secara efektif pada world wide web. Recommendation system ini menggunakan pendekatan content-based dan collaborative filtering yang dimodifikasi. Untuk meminimalisasi waktu komputasi, pendekatan ini mengatur minimum support dan confident untuk pencarian hunbungan asosiatif antar item. Klasterisasi akan diterapkan dalam pencarian kedekatan berita dengan berbasis isi dari berita. Setiap pengguna sistem harus memasukkan peringkat untuk setiap berita yang dibaca, sehingga pengguna harus terdaftar sebelumnya. Jika pengguna membaca berita dan merasa tertarik pada isi berita, maka berita tersebut akan direkomendasikan ke tetangga terdekat. Dimana kedekatan ini dihitung dengan algoritma lintasan terpendek. Dengan penggunaan pendekatan yang diusulkan Hsieh dkk. (2004), sistem dapat mengatasi kelemahan cluster-based recommnedation system yaitu dapat memberikan rekomendasi kepada pengguna walaupun pengguna tidak masuk ke dalam salah satu kelas.
Penelitian Hsieh dkk. (2004) memiliki perbedaan dengan penelian ini pada penggunaan data input untuk menentukan rekomendasi. Penelitian ini hanya melibatkan data transaksi pemilihan dokumen dan konten dokumen untuk menentukan rekomendasi. Penelitian dkk. (2004) menggunakan kaidah asosiasi sebagai algoritma untuk mencari hubungan asosiatif antara berita, sedangkan penelitian ini hanya menggunakan penggalian itemset untuk pencarian hubungan asosiatif antara dokumen.
10
Market-based collaborative information-filtering (MarCol) dibangun untuk untuk pencarian dokumen yang relevan untuk pengguna. MarCol diusulkan oleh Melamed dkk. (2007) dengan memanfaatkan pendekatan collaborative filtering. Pencarian dokumen yang relevan dicari menggunakan kemiripan antara query yang dimasukkan pengguna serta kemiripan antara pengguna. Dengan kata lain, dokumen yang direkomendasikan dihasilkan dari pencocokan keyword yang dimasukkan oleh pengguna yang dikombinasikan dengan data transaksi dan data profil penggguna. Selain itu, recommendation system diaplikasikan dengan penerapan biaya rekomendasi. Dalam penelitian Melamed dkk. (2007) terdapat 2 biaya yang diuji yaitu gratis dan berbayar. Berdasarkan hasil penelitian, penerapan model MarCol menunjukkan adanya peningkatan umpan balik dan kualitas rekomendasi. MarCol merupakan penelitian yang berfokus pada perbedaan anatara sistem gratis dan berbayar. Selain dalam penggunaan algoritma, penelitian ini berbeda dengan MarCol pada bagian penggunaan data identitas pengguna dalam penentuan rekomendasi dokumen.
Penelitian recommendation system untuk dokumen juga dilakukan oleh Popa dkk. (2008). Hanya saja, penelitian Popa dkk. (2008) difokuskan untuk dokumen ilmiah dan menerapkan sistem yang terdistribusi. Sistem yang dibangun akan menghasilkan 2 rekomendasi yaitu “pengguna yang mirip” dan “dokumen yang mungkin disukai”. Untuk rekomendasi “pengguna yang mirip”, sistem akan menghitung kemiripan menggunakan pendekatan klasifikasi dengan berbasis pada identitas pengguna. Daftar rekomendasi pengguna tersebut akan digunakan untuk membentuk identitas pengguna yang baru terdaftar. Sedangkan untuk “dokumen yang mungkin disukai”, sistem akan melakukan klaterisasi terhadap dokumen. Sebelum melakukan klasterisasi, sistem akan mencari dokumen yang sesuai dengan pengguna berdasarkan data transaksi pengguna lain yang memiliki karakteristik sama. Dalam implementasinya, pendekatan Popa dkk. (2008) berhasil melakukan rekomendasi dokumen ilmiah berbasis sudut pandang pengguna. Penelitian Popa dkk. (2008) juga memanfaatkan content-based filtering dengan isi dokumen sebagai data untuk melakukan penyaringan dokumen
rekomendasi. Penelitian Popa dkk. (2008) dan penelitian ini memiliki perbedaan pada bagian penggunaan data identitas untuk menghitung kemiripan antara pengguna. Penelitian ini tidak memperhatikan latar belakang dari pengguna sistem dalam penentuan dokumen terkait.
Pham dan Trach (2011) mengungkapkan bahwa menemukan dan merekomendasikan dokumen yang relevan bagi pengguna yang membutuhkan bukanlah tugas yang mudah. Mereka lalu mengusulkan pendekatan recommendation system dengan memanfaatkan kemiripan dokumen. Pendekatan Pham dan Trach (2011) menggunakan konten dari dokumen digabungkan dengan social tags dan data pengguna yang terkait. Ketiga faktor tersebut lalu disebut sebagai 3 dimensi dokumen. Dilihat dari faktor yang digunakan, pendekatan yang diusulkan merupakan gabungan antara user-based, item-based collaborative filtering, dan content-based filtering. Dengan demikian, pendekatan sistem yang diusulkan merupakan sistem hybrid. Penelitian Pham dan Trach (2011) mendapati hasil bahwa ketiga dimensi tersebut memiliki kontribusi penting dalam perhitungan kemiripan dokumen. Akan tetapi, penggunaan tag yang diberikan oleh komunitas dan profil pengguna untuk menghitung kemiripan mengakibatkan pengguna harus terdaftar terlebih dahulu di dalam sistem.
Suzuki dkk. (2011) mengusulkan metode recommendation system baru untuk dokumen dengan pendekatan content-based menggunakan kompresi data. Berbeda dengan penelitian recommendation system dokumen sebelumnya yang hanya menggunakan sejumlah kata pada dokumen untuk mencari kedekatan profil pengguna serta dokumen, pendekatan Suzuki dkk. (2011) menggunakan kombinasi kompresi data, kedekatan profil pengguna, dan dokumen berdasarkan kata yang ada pada dokumen. Hasil eksperimen menggunakan surat kabar Jepang menunjukkan bahwa metode kompresi data lebih baik daripada metode yang hanya mengandalkan sejumlah kata pada dokumen, terutama ketika topik pada surat kabar berjumlah besar. Selain itu metode kombinasi Suzuki dkk. (2011) mengungguli metode kompresi data sebelumnya dan kombinasi kompresi data serta pemanfaatan kata pada dokumen juga dapat meningkatkan kinerja. Maka
12
dari itu dapat disimpulkan bahwa metode Suzuki dkk. (2011) lebih baik dalam menangkap profil pengguna dan dengan demikian memberikan kontribusi untuk membuat recommendation system untuk dokumen yang lebih baik.
Perbedaan penelitian ini dengan penelitian Suzuki dkk. (2011) terletak pada penggunaan algoritma dan data acuan untuk menentukan rekomendasi. Penelitian ini menggunakan keyword sebagai penentu rekomendasi. Penentuan keyword ini tidak menggunakan tahap kompresi data. Penelitian ini juga mengabaikan data identitas pengguna dalam penentuan rekomendasi.
2.2 Hybrid Recommendation System
Item-based Clustering Hybrid Method (ICHM) diusulkan oleh Li dan Kim (2003). Metode ini dirancang untuk mengatasi kasus cold-start yang terdapat pada metode collaborative filtering. Bebeda dengan penelitian ini, ICHM memanfaatkan atribut dari item dalam penemtuaan rekomendasi saat kasus coldstart. Metode ini memanfaatkan klasterisasi untuk pengelompokan item dengan memanfaatkan kemiripian setiap item yang dicari berdasarkan atribut dari item tersebut. Lalu dengan collaborative filtering, data peringkat yang diberikan pengguna akan digunakan untuk menentukan kemiripan selera pengguna satu dengan pengguna lain terhadap item tertentu. Sistem ICHM diaplikasikan untuk rekomendasi data film yang diambil dari MovieLens.org. Sistem ICHM diuji dengan menggunakan perhitungan mean absolute error (MAE). Setelah diuji, sistem ICHM dikatakan dapat mengatasi cold-start problem dengan memanfaatkan teknik klasterisasi tersebut. Selain itu, sistem ICHM juga dapat meningkatkan kualitas prediksi yang dihasilkan.
Liangxing dan Aihua (2010) mengusulkan sebuah hybrid recommendation system yang berbasis content-base filtering dan collaborative filtering yang dapat memberikan rekomendasi pembelian bagi pelanggan VIP dari toko pakaian ritel. Sebelum menghasilkan rekomendasi akhir, sistem yang diusulkan Liangxing dan Aihua (2010) membentuk daftar rekomendasi awal dengan menggunakan gabungan hasil dari 2 proses collaborative filtering. Proses pertama adalah
pengolahan data transaksi pembelian menggunakan metode item-based collaborative filtering. Proses kedua adalah pengolahan data pengguna menggunakan metode user-based collaborative filtering. Daftar rekomendasi awal tersebut diproses dengan content-based filtering yang berupa pengklasifikasian produk untuk menghasilkan rekomendasi akhir. Penggunaan metode user-based collaborative filtering mebuat penelitian Liangxing dan Aihua (2010) berbeda dengan penelitian ini. Hasil pengujian menunjukkan bahwa hybrid recommendation system dapat melaksanakan analisis selera pelanggan dan rekomendasi produk di toko pakaian ritel.
Penelitian tentang Item-based Clustering Hybrid Method (ICHM) kembali dilakukan oleh Djamal dkk. (2010). ICHM merupakan salah satu cara untuk menggabungkan metode yang digunakan dalam pembangunan recommendation system. Pembahasan pada penelitian difokuskan pada implementasi ICHM dalam recommendation system untuk film dengan dataset yang bersumber dari movielens.org. Pada sistem yang dibangun, content-based filtering dimanfaatkan pada klasterisasi pada konten setiap item. Sedangkan item-based collaborative filtering dimanfaatkan dalam perhitungan kedekatan antara item dengan menggunakan peringkat yang telah diberikan oleh pengguna. Untuk perhitungan prediksi yang dihasilkan, sistem ICHM menggunakan 2 pendekatan yang berbeda. Yang pertama untuk masalah start dan yang kedua untuk masalah non cold-start. Walaupun dapat memberikan rekomendasi tanpa data peringkat, penggunaan data peringkat sebagai salah satu penentu rekomendasi pada penelitian Djamal dkk. (2010) berbeda dengan penelitian ini yang sama sekali tidak memperhitungkan data peringkat item sebagai penentu rekomendasi. Hasil implementasi menunjukkan bahwa recommender system dengan metode ICHM dapat memprediksi item baru yang belum memiliki peringkat sama sekali dengan cara memperhitungkan kedekatan berdasarkan genre item. Selain itu setelah dihitung berdasarkan mean absolute error (MAE) penambahan jumlah cluster hingga 70 buah cenderung meningkatkan akurasi prediksi baik untuk kasus cold-start dan kasus non cold-cold-start, namun akurasi turun pada jumlah cluster sebanyak
14
60 buah karena terdapat nilai membership yang saling bertolak belakang untuk beberapa item di beberapa cluster.
Hybrid recommendation system yang menerapkan pendekatan berbeda diajukan oleh Chikhaoui dkk. (2011) dengan melakukan penelitian tentang recommendation system yang menggunakan 3 pendekatan, yaitu collaborative filtering, content-based, dan demographic filtering untuk rekomendasi film. Pada collaborative filtering digunakan pendekatan dengan menggunakan neigborhood-based terhadap data peringkat. Dalam pendekatan neigborhood-neigborhood-based, kesukaan dari pengguna u terhadap item i akan dihitung berdasarkan kesukaan pengguna lain yang memiliki karakteristik mirip dengan pengguna u terhadap item i. Dengan algoritma KNN, data karakteristik film seperti genre, negara pembuat, dan tanggal perilisan digunakan sebagai pembanding untuk menentukan kemiripan suatu item terhadap item i. Pengolahan data karakteristik film tersebut merupakan content-based filtering. Pada sisi demographic filtering dicari pengguna yang memiliki kesukaan yang mirip atau selera yang sama. Demographic filtering ini digunakan untuk mengatasi kelemahan dari collaborative filtering dan juga content-based filtering pada saat terjadinya kasus coldstart. Selain algoritma yang digunakan, penggunaan data identitas pengguna dan penggunaan atribut item merupakan perbedaan utama antara penelitian ini dan penelitian Chikhaoui dkk. (2011). Dengan melalui eksperimen, hasil penelitian Chikhaoui dkk. (2011) menunjukkan bahwa pendekatan tersebut mencapai akurasi yang baik dengan cakupan tinggi melebihi algoritma penyaringan konvensional serta metode hybrid biasa. Selain itu, hasil eksperimen menunjukkan bagaimana pendekatan Chikhaoui dkk. (2011) berhasil mengatasi kasus cold-start dengan memasukkan karakteristik demografis pengguna.
Di tahun yang sama, Hayati (2011) membangun hybrid recommendation system untuk penentuan daerah wisata. Dalam penentuan rekomendasi, sistem yang dibangun menggunakan peringkat daerah wisata dan profil pengguna sebagai acuan. Sistem tersebut juga memiliki keunggulan dengan tidak diperlukannya data masukan dan peringkat awal untuk mendapatkan rekomendasi karena penggunaan
algoritma klasifikasi terhadap data daerah wisata dan profil pengguna. Pengklasifikasian dilakukan dengan menggunakan algoritma nearest neighbor untuk mencari kedekatan antara daerah wisata dan juga pengguna, sehingga hybrid recommendation system yang dibangun berhasil mengatasi masalah cold-start.
Penentuan rekomendasi dokumen dilakukan dengan memperhatikan data peringkat dan data identitas pengguna. Pendekatan tersebut memiliki kelemahan pada kasus coldstart yaitu saat sistem tidak memiliki data umpan balik dari pengguna. Selain itu, penelitian sebelumnya tidak memperhatikan data transaksi yang didapat dari pemilihan dokumen. Secara umum, terdapat beberapa perbedaan antara penelitian ini dengan penelitian-penelitian sebelumnya. Selain pada algoritma penentuan rekomendasi, penelitian ini tidak memanfaatkan data identitas pengguna dan data peringkat sebagai data acuan untuk penentuan rekomendasi. Hal ini dapat mengurangi kekhawatiran penyalahgunaan data identitas pengguna. Selain itu, untuk pengguna baru maupun saat sistem baru dibangun tidak akan terkendala dengan kebutuhan data umpan balik dari pengguna untuk penentuan rekomendasi dokumen. Hal ini dimungkinkan karena penggunaan konten dokumen sebagai data penentuan rekomendasi.
Pada Tabel 2.1 akan ditunjukkan perbandingan dan ringkasan dari beberapa penelitian yang telah disebutkan diatas.
16 Tabel 2.1 Tinjauan pustaka
No. Peneliti Domain Metode Hasil
1. Li dan Kim (2003) Film Collaborative filtering pada pemeringkatan item
dan klasifikasi terhadap atribut item
Mengatasi masalah cold-start pada
collaborative filtering
2. Hsieh, Huang, Hsu dan Chang (2004)
Berita Collaborative fitering pada pemeringkatan item
dan content-based filtering pada konten beserta data transaksi item
Mengatasi kelemahan cluster-based
recommnedation system yaitu dapat
memberikan rekomendasi kepada pengguna walaupun pengguna tidak masuk ke dalam salah satu kelas
3. Melamed, Shapira dan Elovici (2007)
Dokumen Collaborative filtering pada umpan balik
pengguna dan pencarian dengan memperhatikan
query yang dimasukkan pengguna
Menunjukkan adanya peningkatan umpan balik dan kualitas rekomendasi
4. Popa, Negru, Pop dan Muscalagiu (2008)
Dokumen ilmiah
Pendekatan klasifikasi dengan berbasis pada profil pengguna dan klasterisasi pada data dokumen
Menghasilkan recommendation system terdistribusi berbasis sudut pandang pengguna 5. Liangxing dan Aihua
(2010)
Pakaian Item-based collaborative filtering pada data
transaksi pembelian, user-based collaborative
filtering pada data pengguna, content-base filtering untuk pengklasifikasian produk
Dapat melaksanakan analisis selera pelanggan dan rekomendasi produk di toko pakaian ritel
6. Djamal, Maharani dan Kurniati (2010)
Film Content-base filtering pada klasterisasi pada
konten setiap item. Item-based collaborative
filtering dalam perhitungan peringkat
Dapat memprediksi item baru yang belum memiliki peringkat sama sekali
7. Pham dan Thach (2011)
Dokumen User-based collaborative filtering terhadap data
pengguna, item-based collaborative filtering terhadap social tag, dan content-based
filteringterhadap isi dokumen
Ketiga dimensi dokumen Memiliki kontribusi penting dalam perhitungan kemiripan dokumen
8. Chikhaoui, Chiazzaro dan Wang (2011)
Film collaborative filtering pada data peringkat item, content-based pada data karakteristik film, dan demographic filtering pada data pengguna
Mengatasi kasus cold-start dengan memasukkan karakteristik demografis pengguna
9. Hayati (2011) Daerah wisata
Collaborative filtering pada peringkat daerah
wisata dan profil pengguna. Jika tidak
Mengatasi masalah cold-start dengan penerapan klasifikasi
Hamamoto dan Aizawa (2011)
data yang menggunakan “kantong kata”
11. Parwita (2014) Dokumen Ilmiah
Item-based collaborative filtering pada penggalian frequent itemset dengan memanfaatkan data
transaksi dan content-based filtering pada perbandingan keyword dokumen dengan perhitungan cosine similarity.
Menghasilkan rekomendasi tanpa menggunakan data identitas pengguna dan data peringkat. Serta mengatasi kelemahan dan
menggabungkan keunggulan penggunaan metode collaborative filtering atau
18
BAB III
LANDASAN TEORI
3.1 Recommendation System
Recommendation system merupakan teknik dan software untuk menghasilkan usulan item yang akan dimanfaatkan oleh pengguna. “Item” merupakan istilah yang digunakan untuk menyatakan apa yang direkomendasikan oleh sistem kepada pengguna. Usulan tersebut dihasilkan berdasarkan berbagai proses pengambilan keputusan seperti barang apa yang akan dibeli, lagu apa yang ingin didengarkan dan berita apa yang akan dibaca. Dalam bentuknya, recommendation system akan memberikan semacam daftar item. Item tersebut dapat berupa produk maupun jasa. Dalam pembuatan daftar item tersebut, recommendation system mencoba untuk menemukan produk atau jasa yang paling sesuai berdasarkan kebutuhan dan keinginan pengguna. Untuk menemukannya, recommendation system menggunakan data ketertarikan pengguna yang dinyatakan secara eksplisit dalam data peringkat item atau disimpulkan dengan menebak tindakan pengguna (Ricci, dkk., 2011).
Pembangunan recommendation system dimulai dari keinginan untuk meniru kebiasaan sederhana yaitu pengguna sering mengandalkan rekomendasi yang diberikan oleh pengguna lain dalam membuat rutinitas maupun keputusan. Contohnya adalah saat penonton ingin menyaksikan sebuah film. Untuk memutuskan apakah layak atau tidak menyaksikan film tersebut, maka penonton akan menilai dari review maupun pendapat dari penonton yang telah menyaksikan film tersebut. Dalam pembangunan recommendation system, dilakukan penerapan algoritma dengan memanfaatkan rekomendasi yang dihasilkan oleh komunitas pengguna untuk memberikan rekomendasi kepada pengguna lain. Item yang direkomendasikan merupakan item yang disukai oleh pengguna-pengguna dengan selera serupa. Pendekatan ini disebut collaborative filtering dengan dasar pemikirannya adalah jika pengguna setuju dengan pendapat beberapa pengguna lain terhadap suatu item, maka rekomendasi yang dihasilkan dari pengguna lain dengan selera sama akan relevan dan menarik bagi pengguna tersebut. Pendapat
pengguna dapat berupa peringkat yang diberikan maupun pilihan yang dilakukan oleh pengguna.
Collaborative filtering merupakan implementasi paling sederhana dan merupakan versi awal dari pendekatan recommendation system. Kemiripan selera dari dua pengguna dihitung berdasarkan kesamaan dalam pendapat pengguna terhadap item. Dengan kata lain, collaborative filtering adalah proses penyaringan atau evaluasi item menggunakan pendapat dari orang lain (Schafer, dkk., 2007).
Content-based filtering dan collaborative filtering telah lama dipandang saling melengkapi. Content-based filtering dapat memprediksi relevansi untuk item tanpa peringkat (misalnya, item baru, artikel berita, halaman website). Content-based filtering memerlukan konten untuk melakukan analisis. Pada beberapa hal, konten merupakan sesuatu yang langka (misalnya, rekomendasi untuk restoran dan buku teks yang tersedia tanpa ulasan) atau sulit untuk mendapatkan dan mewakili konten itu (misalnya, film dan musik). Di sisi lain, collaborative filtering membutuhkan peringkat item untuk melakukan prediksi tanpa memerlukan konten.
Content based filtering dan collaborative filtering dapat dikombinasikan secara manual oleh pengguna untuk menentukan fitur tertentu. Dalam implementasinya kedua metode tersebut dapat digabungkan secara otomatis yang disebut dengan pendekatan hybrid. Ada banyak cara dalam menggabungkan metode tersebut dan tidak ada kesepakatan di antara peneliti untuk cara menggabungannya.
3.2 Penggalian Frequent Itemset
Kaidah asosiasi adalah teknik data mining untuk menemukan aturan asosiatif antara suatu kombinasi item. Fungsi kaidah asosiasi seringkali disebut dengan “market basket analysis”. Penting tidaknya suatu aturan asosiatif dapat diketahui dengan menggunakan dua parameter, support yaitu persentase kombinasi item tersebut dalam basis data dan confidence yaitu kuatnya hubungan antar item dalam aturan asosiatif. Salah satu tahap dalam kaidah asosiasi adalah
20
menemukan semua kombinasi dari item, disebut dengan itemset, yang jumlah kemunculannya lebih besar daripada minimum support (Rajaraman dan Ullman, 2010). Misalkan, ada sekumpulan data transaksi pembelian perangkat komputer seperti yang ditunjukkan pada Tabel 3.1.
Tabel 3.1 Data transaksi
Transaction ID (TID) Item
1 processor, motherboard, memory 2 processor, motherboard, memory
3 processor 4 processor, motherboard 5 motherboard 6 processor, motherboard 7 processor, memory 8 motherboard, memory 9 motherboard 10 memory
Setiap data transaksi sering disebut dengan keranjang (basket). Setelah disusun, setiap keranjang tersebut dapat direpresentasikan dengan Tabel 3.2.
Tabel 3.2 Representasi keranjang
Produk TID Jumlah
processor 1, 2, 3, 4, 6, 7 6 motherboard 1, 2, 4, 6, 8, 9 6 memory 1, 2, 7, 8, 10 5 processor, motherboard 1, 2, 4, 6 4 processor, memory 1, 2, 7 3 motherboard, memory 1, 2, 8 3
processor, motherboard, memory 1, 2 2
Tabel 3.3 Frequent itemset Produk
processor motherboard memory
Data transaksi tersebut akan dikenakan minimum support sebesar 40% dari jumlah data transaksi sehingga didapatkan beberapa itemset melebihi minimum support disebut dengan frequent itemset yang ditunjukkan oleh Tabel 3.3.
3.2.1 FP-Growth
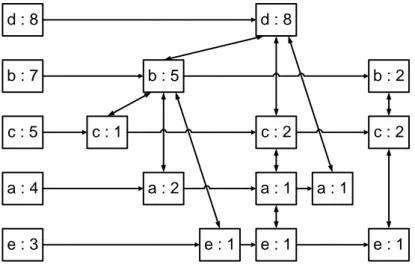
Salah satu algoritma penggalian frequent itemset yang cepat dan juga populer adalah algoritma FP-Growth. FP-Growth berbasis pada tree disebut dengan FP (Frequent Pattern)-Tree (Zaki dan Meira, 2014). FP-Tree dapat menghemat penggunaan memori untuk penyimpanan data transaksi. Ide dasar dari FP-Growth dapat digambarkan sebagai skema eliminasi secara rekursif. Dalam langkah preprocessing, dilakukan penghapusan semua item yang kemunculannya kurang dari minimum support yang diberikan. Kemudian dipilih semua transaksi yang mengandung frequent item lalu dibentuk FP-Tree berdasarkan data transaksi tersebut. Dalam penggalian frequent itemset, dibentuk conditional FP-Tree yang berakhir pada salah satu frequent item. Pembentukan ini dilakukan secara rekursif dengan mengeliminasi satu persatu frequent item akhir yang terdapat pada tree tersebut. Penentuan frequent itemset dilakukan bersamaan saat pengeliminasian dengan melihat support dari frequent item tersebut (Han, dkk., 2011).
a d f d a a c d e d 8 d c a e b d b 7 d b b c d c 5 d b c b c a 4 b c a b d e 3 d b a b d e f 2 d b e b c e g g 1 b c e c d f d c a b d d b a
Gambar 3.1 Penentuan frequent item
Sebelum membentuk FP-Tree, semua item tunggal yang memenuhi minimum support (frequent item) diidentifikasi dan diurutkan berdasarkan banyaknya jumlah kemunculan (Han, dkk., 2011). Kemudian untuk item yang tidak memenuhi minimum support akan diabaikan dari data transaksi, karena item tersebut sudah pasti bukan bagian dari frequent itemset. Pengurutan item
22
dilakukan dari yang paling sering muncul ke yang paling jarang. Hal ini untuk meningkatkan kinerja dari algoritma (Borgelt, 2005). Gambar 3.1 merupakan contoh penentuan frequent item untuk minimum support 3 dan pengurutan itemset berdasarkan jumlah kemunculan.
d : 8 b : 7 a : 4 e : 3 c : 5 d : 8 b : 5 b : 2 c : 1 c : 2 c : 2 a : 2 a : 1 a : 1 e : 1 e : 1 e : 1 Gambar 3.2 FP-Tree
FP-Tree mengandung data label, jumlah kemunculan, alamat parent, child, dan prefix path (Han, dkk., 2011). Contoh FP-Tree ditunjukkan oleh Gambar 3.2. Untuk kepentingan pembentukan prefix path, maka child sebuah node diurutkan berdasarkan jumlah kemunculan keseluruhan.
d : 8 b : 7 a : 4 e : 3 c : 5 d : 8 b : 5 b : 2 c : 1 c : 2 c : 2 a : 2 a : 1 a : 1 e : 1 e : 1 e : 1
Conditional FP-Tree merupakan bagian FP-Tree yang berakhir pada node tertentu. Conditional FP-Tree digunakan untuk penggalian frequent itemset (Han, dkk., 2011). Misalnya, untuk penentuan item „e‟ akan diambil semua path node yang berakhir di „e‟. Lalu, node „e‟ di masing path akan dihapus. Gambar 3.3 dan Gambar 3.4 merupakan contoh pembentukan conditional FP-Tree yang berakhir pada node „e‟.
d : 2 b : 1 c : 1 c : 1 a : 1 b : 1 d : 2 b : 2 a : 1 c : 2
Gambar 3.4 Conditional FP-Tree item „e‟
Untuk penentuan itemset lain yang mengandung „e‟, maka conditional FP-Tree item tersebut akan dibentuk dari conditional FP-FP-Tree „e‟. Gambar 3.5 merupakan contoh pembentukan conditional FP-Tree untuk itemset „b e‟. Penggalian frequent itemset dilakukan secara rekursif. Jika node memenuhi minimum support maka node tersebut merupakan frequent itemset. Gambar 3.6 merupakan urutan itemset hasil penggalian frequent itemset dalam FP-Growth.
d : 2 b : 1 c : 1 c : 1 a : 1 b : 1 d : 2 b : 2 a : 1 c : 2
24 e a e c e b e d e c a e b a e d a e b c a e d c a e d b c a e d b a e b c e d c e ……... ……... ……... ……... a ……... ….
Gambar 3.6 Urutan hasil penggalian frequent itemset
3.3 Keyword Extraction System
Dalam dokumen ilmiah, keyword adalah kata pokok yang merepresentasikan masalah yang diteliti atau istilah-istilah yang merupakan dasar pemikiran dan dapat berupa kata tunggal atau gabungan kata. Similaritas keyword dokumen dapat digunakan untuk menentukan relevansi dokumen terhadap dokumen lain (Weiss, dkk., 2005). Automatic keyword extraction system memiliki tugas untuk mengidentifikasi kumpulan kata, frase kunci, keyword, atau segmen kunci dari sebuah dokumen yang dapat menggambarkan arti dari dokumen (Hulth, 2003). Tujuan dari ekstraksi otomatis adalah menekan kelemahan pada ekstraksi manual yang dilakukan manusia yaitu pada kecepatan, ketahanan, cakupan, dan juga biaya yang dikeluarkan.
Salah satu pendekatan yang dapat digunakan dalam automatic keyword extraction yaitu pendekatan tata bahasa. Pendekatan ini menggunakan fitur tata bahasa dari kata-kata, kalimat, dan dokumen. Metode ini memperhatikan fitur tata bahasa seperti bagian kalimat, struktur sintaksis, dan makna yang dapat menambah bobot. Fitur tata bahasa tersebut dapat digunakan sebagai penyaring untuk keyword yang buruk. Dalam ekstraksi keyword dengan pendekatan tata bahasa berbasis struktur sintaksis, ada beberapa tahap yang dilakukan yaitu tokenisasi, stopword removal, stemming, dan pembobotan kata (Oelze, 2009).
3.3.1 Tokenisasi
Teks elektronik adalah urutan linear simbol (karakter, kata-kata atau frase). Sebelum dilakukan pengolahan, teks perlu disegmentasi ke dalam unit-unit linguistik seperti kata-kata, tanda baca, angka, alpha-numeric, dan lain-lain Proses ini disebut tokenisasi. Tokenisasi sederhana (white space tokenization) merupakan tokenisasi yang memisahkan kata berdasarkan karakter spasi, tab, dan baris baru (Weiss, dkk., 2005). Namun, tidak setiap bahasa melakukan hal ini (misalnya bahasa Cina, Jepang, Thailand). Dalam bahasa Indonesia, selain tokenisasi sederhana diperlukan juga tokenisasi yang memisahkan kata-kata berdasarkan karakter lain seperti “/” dan “-“.
3.3.2 Stopword removal
Stopword removal adalah pendekatan mendasar dalam preprocessing yang menghilangkan kata-kata yang sering muncul (stopword). Fungsi utamanya adalah untuk mencegah hasil proses selanjutnya terpengaruh oleh stopword tersebut. Banyak diantara stopword tersebut tidak berguna dalam Information Retrival (IR) dan text mining karena kata-kata tersebut tidak membawa informasi (seperti ke, dari, dan, atau). Cara biasa untuk menentukan apa yang dianggap sebagai stopword adalah menggunakan stoplist. Stoplist merupakan kumpulan kata atau kamus yang berisi daftar stopword. Langkah penghilangan stopword ini adalah langkah yang sangat penting dan berguna (Srividhya dan Anitha, 2010).
3.3.3 Stemming
Algoritma stemming adalah proses yang melakukan pemetaan varian morfologi yang berbeda dari kata-kata ke dalam kata dasar/kata umum (stem). Stemming berguna pada banyak bidang komputasi linguistik dan information retrieval (Lovins, 1968).
Dalam kasus bahasa Indonesia, sejauh ini hanya ada dua algoritma untuk melakukan proses stemming yaitu algoritma yang dikembangkan oleh Nazief dan Adriani serta algoritma yang dikembangkan oleh Tala. Algoritma Nazief dan Adriani dikembangkan dengan menggunakan pendekatan confix stripping dengan
26
disertai pemindaian pada kamus. Sedangkan stemming yang dikembangkan Tala menggunakan pendekatan yang berbasis aturan (rule-based).
Pengembangan Algoritma Tala didasarkan pada kenyataan bahwa sumber daya seperti kamus besar digital untuk bahasa mahal karena kurangnya penelitian komputasi di bidang linguistik. Maka, ada kebutuhan untuk algoritma stemming tanpa keterlibatan kamus. Algoritma Tala sendiri dikembangkan dari algoritma Porter stemmer yang dimodifikasi untuk bahasa Indonesia. Algoritma Tala menghasilkan banyak kata yang tidak dipahami. Ini disebabkan oleh ambiguitas dalam aturan morfologi Bahasa Indonesia. Dalam beberapa kasus kesalahan tidak mempegaruhi kinerja, tetapi dalam kasus lain menurunkan kinerja (Tala, 2003).
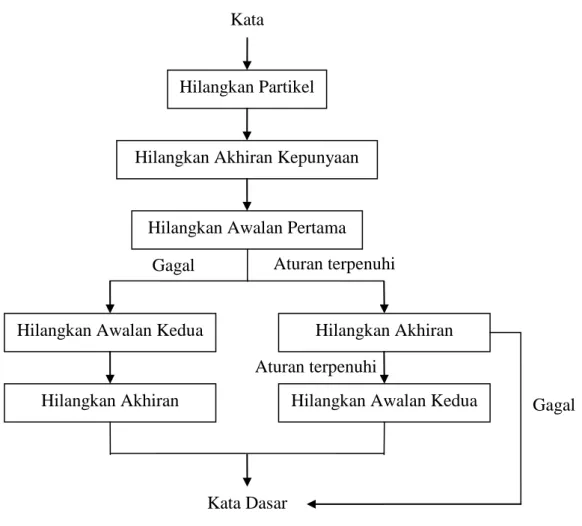
3.3.4 Tala stemmer
Gambar 3.7 Skema Tala stemmer Kata
Hilangkan Partikel
Hilangkan Akhiran Kepunyaan
Hilangkan Awalan Pertama
Hilangkan Awalan Kedua Hilangkan Akhiran
Hilangkan Awalan Kedua Hilangkan Akhiran
Kata Dasar
Gagal Gagal Aturan terpenuhi
Algoritma Tala memproses awalan, akhiran, dan kombinasi keduanya dalam kata turunan. Walaupun dalam bahasa Indonesia terdapat sisipan, jumlah kata yang diturunkan menggunakan sisipan sangat sedikit. Karena hal tersebut dan juga demi penyederhanaan, sisipan akan diabaikan.
Algoritma Porter stemmer dibangun berdasarkan ide tentang akhiran pada bahasa Inggris yaitu kebanyakan merupakan kombinasi dari akhiran yang lebih sederhana dan lebih kecil. Beberapa perubahan dilakukan pada algoritma Porter stemmer agar sesuai dengan Bahasa Indonesia. Perubahan dilakukan pada bagian kumpulan aturan dan penilaian kondisi. Karena algoritma Porter stemmer hanya dapat menangani akhiran, maka perlu penambahan agar dapat menangani awalan, akhiran, dan juga penyesuaian penulisan dalam kasus dimana terjadi perubahan karakter pertama kata dasar. Gambar 3.7 menunjukkan langkah-langkah proses pada algoritma Tala.
Tabel 3.4 Daftar partikel
Akhiran Pengganti
kah NULL
lah NULL
pun NULL
Penurunan kata dasar diawali dengan penghilangan imbuhan yang melekat pada kata. Imbuhan ini dapat berupa awalan, akhiran maupun kombinasi keduanya. Akhiran yang berupa partikel dan akhiran ganti kepunyaan akan dihapus lebih dulu dibandingkan awalan. Daftar partikel ditunjukkan pada Tabel 3.4 dan daftar akhiran ganti kepunyaan pada Tabel 3.5.
Tabel 3.5 Daftar kata ganti kepunyaan
Akhiran Pengganti
ku NULL
mu NULL
28
Setelah itu, proses akan dilanjutkan dengan penghilangan awalan pertama yang ditunjukkan pada Tabel 3.6. Langkah selanjutnya dilakukan dengan memperhatikan kombinasi awalan dan akhiran yang ilegal. Daftar kombinasi ini dapat dilihat pada Tabel 3.7.
Tabel 3.6 Daftar awalan pertama
Awalan Pengganti meng NULL meny s men NULL mem p mem NULL me NULL peng NULL peny s pen NULL pem p di NULL ter NULL ke NULL
Tabel 3.7 Kombinasi ilegal
Awalan Akhiran ber i di an ke i|kan meng an peng i|kan ter an
Jika kombinasi awalan dan akhiran merupakan kombinasi ilegal, maka hanya awalan yang dihilangkan sedangkan akhiran tidak dihilangkan. Daftar akhiran dapat dilihat pada Tabel 3.8 dan awalan kedua pada Tabel 3.9. Pada penghapusan awalan juga diperhatikan karakter ganti yang disebabkan oleh penggunaan awalan. Awalan juga dapat terdiri dari dua awalan (awalan ganda). Daftar kombinasi awalan ganda dapat dilihat pada Tabel 3.10.
Tabel 3.8 Daftar akhiran
Akhiran Pengganti Kondisi
kan NULL awalan ∉ {ke, peng}
an NULL awalan ∉ {di, meng, ter} i NULL V|K…c1c1, c1 ≠ s, c2 ≠ I, dan awalan
∉ {ber, ke, peng}
Tabel 3.9 Daftar awalan kedua
Awalan Pengganti ber NULL bel NULL be NULL per NULL pel NULL pe NULL
Tabel 3.10 Awalan ganda
Awalan 1 Awalan 2
meng per
di ber
ter ke
Dalam Bahasa Indonesia, unit terkecil dari suatu kata adalah suku kata. Suku kata paling sedikit terdiri dari satu huruf vokal. Desain implementasi algoritma Tala belum dapat mengenali seluruh suku kata. Ini disebabkan karena adanya dua huruf vokal yang dianggap satu suku kata yaitu ai, au, dan oi. Kombinasi dua huruf vokal (terutama ai, oi) tersebut dapat menjadi masalah, apalagi jika berada pada akhir sebuah kata. Ini disebabkan oleh sulitnya membedakannya dengan kata yang mengandung akhiran –i. Hal ini menyebabkan kombinasi huruf vokal ai/oi akan diperlakukan seperti kata turunan. Huruf terakhir (-i) akan dihapus pada hasil proses stemming. Kebanyakan kata dasar terdiri dari minimal dua suku kata. Inilah alasan kenapa kata yang akan diproses memiliki minimal dua suku kata.
30
3.3.5 Pembobotan
Tahapan ini dilakukan dengan tujuan untuk memberikan suatu bobot pada term yang terdapat pada suatu dokumen. Term adalah satu kata atau lebih yang dipilih langsung dari corpus dokumen asli dengan menggunakan metode term-extraction. Fitur tingkat term, hanya terdiri dari kata-kata tertentu dan ekspresi yang ditemukan dalam dokumen asli (Feldman dan Sanger, 2007). Misalnya, jika dokumen berisi kalimat:
“Presiden Indonesia mengalami perjalanan karir yang membawa beliau dari rumah sederhana hingga Istana Merdeka”
Daftar term untuk mewakili dokumen dapat mencakup bentuk kata tunggal seperti “Indonesia”, “perjalanan”, “karir”, dan “rumah” lalu untuk yang lebih dari satu kata seperti “Presiden Indonesia”, “rumah sederhana”, and “Istana Merdeka”.
Dalam pengkategorian teks dan aplikasi lain di information retrieval maupun machine learning, pembobotan term biasanya ditangani melalui metode yang diambil dari metode pencarian teks, yaitu yang tidak melibatkan tahap belajar (Debole dan Sebastiani, 2003). Ada tiga asumsi monoton yang muncul di hampir semua metode pembobotan dapat dalam satu atau bentuk lain yaitu (Zobel dan Moffat, 1998):
a. Term yang langka tidak kalah penting daripada term yang sering muncul (asumsi IDF).
b. Kemunculan berkali-kali dari term pada dokumen tidak kalah penting daripada kemunculan tunggal (asumsi TF).
c. Untuk pencocokan term dengan jumlah pencocokan yang sama, dokumen panjang tidak lebih penting daripada dokumen pendek (asumsi normalisasi).
Bobot diperlukan untuk menentukan apakah term tersebut penting atau tidak. Bobot yang diberikan terhadap sebuah term bergantung kepada metode yang digunakan untuk membobotinya.
3.4 Cosine Similarity
Pendekatan cosine similarity sering digunakan untuk mengetahui kedekatan antara dokumen teks. Perhitungan cosine similarity dimulai dengan menghitung dot product. Dot product merupakan perhitungan sederhana untuk setiap komponen dari kedua vektor. Vektor merupakan representasi dari masing-masing dokumen dengan jumlah term pada masing-masing-masing-masing dokumen sebagai dimensi dari vektor (Manning, dkk., 2009). Vektor ditunjukkan oleh notasi (3.1) dan (3.2). Hasil dot product bukan berupa vektor tetapi berupa skalar. Persamaan (3.3) merupakan perhitungan dot product dimana n merupakan dimensi dari vector (Axler, 1997). 𝑎 = 𝑎1, 𝑎2, 𝑎3, … , 𝑎𝑛 (3.1) 𝑏 = 𝑏1, 𝑏2, 𝑏3, … , 𝑏𝑛 (3.2) 𝑎 ∙ 𝑏 = 𝑎𝑖𝑏𝑖 = 𝑎1𝑏1+ 𝑎2𝑏2+ ⋯ + 𝑎𝑛𝑏𝑛 𝑛 𝑖=1 (3.3) 𝑎𝑛 dan 𝑏𝑛 merupakan komponen dari vektor (bobot term masing-masing
dokumen) dan n merupakan dimensi dari vektor. Cosine similarity merupakan perhitungan yang mengukur nilai cosine dari sudut antara dua vektor (atau dua dokumen dalam vector space). Cosine similarity dapat dilihat sebagai perbandingan antara dokumen karena tidak hanya mempertimbangkan besarnya masing-masing jumlah kata (bobot) dari setiap dokumen, tetapi sudut antara dokumen. Persamaan (3.4) dan (3.5) adalah notasi dari metode cosine similarity dimana a merupakan Euclidean norm dari vektor a dan b merupakan Euclidean norm vektor b (Han, dkk., 2011).
a ∙ 𝑏 = a b cos θ (3.4)
32
Dari notasi (3.5) dapat dibentuk persamaan matematika yang ditunjukkan oleh persamaan (3.6) (Lops, dkk., 2011).
𝑆𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦 𝑥, 𝑦 = 𝑎𝑖𝑏𝑖 𝑛 𝑖=1 𝑛𝑖=1𝑎𝑖2∙ 𝑛𝑖=1𝑏𝑖2 (3.6) Dimana:
ai : term ke-i yang terdapat pada dokumen a.
bi : term ke-i yang terdapat pada dokumen b. 3.5 Evaluasi Recommendation System
3.5.1 Precision
Precision bersama recall merupakan salah satu pengujian dasar dan paling sering digunakan dalam penentuan efektifitas information retrival system maupun recommendation system. True positive (tp) pada information retrival merupakan item relevan yang dihasilkan oleh sistem. Sedangkan false positive (fp) merupakan semua item yang dihasilkan oleh sistem. Sehingga dalam information retrival, precision dihitung dengan persamaan (3.7) (Manning, dkk., 2009).
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑡𝑝 𝑡𝑝 + 𝑓𝑝=
𝑟𝑒𝑙𝑒𝑣𝑎𝑛𝑡 𝑖𝑡𝑒𝑚 𝑟𝑒𝑡𝑟𝑖𝑒𝑣𝑒𝑑 𝑟𝑒𝑡𝑟𝑖𝑒𝑣𝑒𝑑 𝑖𝑡𝑒𝑚
(3.7) Istilah positive dan negative mengacu pada prediksi yang dilakukan oleh sistem. Sedangkan istilah true dan false mengacu pada prediksi yang dilakukan oleh pihak luar atau pihak yang melakukan observasi. Pembagian kondisi tersebut dapat dilihat pada Tabel 3.11 (Manning, dkk., 2009).
Tabel 3.11 Pembagian kondisi hasil yang memungkinkan
Relevant Nonrelevant
Retrieved True positive (tp) False positive (fp) Not retrieved False negative (fn) True negative (tn)
3.5.2 Recall
Recall digunakan sebagai ukuran dokumen yang relevan yang dihasilkan oleh sistem. False negative (fn) merupakan semua item relevan yang tidak dihasilkan oleh sistem. Dalam evaluasi information retrival system, recall dihitung dengan persamaan (3.8) (Manning, dkk., 2009).
𝑅𝑒𝑐𝑎𝑙𝑙 = 𝑡𝑝 𝑡𝑝 + 𝑓𝑛 = 𝑟𝑒𝑙𝑒𝑣𝑎𝑛𝑡 𝑖𝑡𝑒𝑚 𝑟𝑒𝑡𝑟𝑖𝑒𝑣𝑒𝑑 𝑟𝑒𝑙𝑒𝑣𝑎𝑛𝑡 𝑖𝑡𝑒𝑚 (3.8) 3.5.3 F-Measure
F-measure merupakan nilai tunggal hasil kombinasi antara nilai precision dan nilai recall. F-measure dapat digunakan untuk mengukur kinerja dari recommendation system ataupun information retrival system. Karena merupakan rata-rata harmonis dari precision dan recall, F-measure dapat memberikan penilaian kinerja yang lebih seimbang. Persamaan (3.9) merupakan persamaan untuk menghitung F-measure (Jannach, dkk., 2010).
𝐹𝑚𝑒𝑎𝑠𝑢𝑟𝑒 = 2 ∙
𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 ∙ 𝑟𝑒𝑐𝑎𝑙𝑙 𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 + 𝑟𝑒𝑐𝑎𝑙𝑙
(3.9)
3.5.4 Mean average precision
Nilai mean average precision (MAP) merupakan nilai rata-rata dari average precision. Average precision merupakan nilai yang didapatkan dari setiap nilai precision item relevan yang dihasilkan dan menggunakan nilai 0 untuk item relevan yang tidak dihasilkan oleh sistem. Nilai precision untuk average precision dihitung dengan memperhatikan urutan item yang diberikan oleh sistem, sehingga nilai precision diberikan untuk setiap item yang dihasilkan oleh sistem. Persamaan (3.10) merupakan persamaan untuk menghitung nilai mean average precision dalam information retrival (Manning, dkk., 2009).
34 𝑀𝐴𝑃 𝑄 = 1 𝑄 1 𝑚𝑗 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 𝑅𝑗𝑘 𝑚𝑗 𝑘=1 𝑄 𝑗 =1 (3.10) Dimana:
Q : jumlah query uji
R : item relevan yang dihasilkan oleh sistem m : jumlah item relevan yang dihasilkan dari query
Dalam penelitian ini, query (Q) merupakan item uji yang digunakan dalam pengujian.
35
BAB IV
ANALISIS DAN RANCANGAN SISTEM
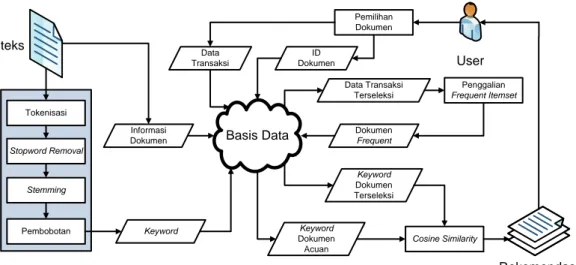
4.1 Gambaran Umum Sistem
Hybrid recommendation system yang dibangun menghasilkan rekomendasi dokumen. Rekomendasi dokumen merupakan dokumen-dokumen yang saling terkait atau terasosiasi dengan dokumen yang dibutuhkan oleh pengguna. Untuk mencari dokumen terasosiasi dapat digunakan penggalian frequent itemset. Keterkaitan dokumen dapat dicari dengan perhitungan kedekatan dokumen. Perhitungan kedekatan dokumen dapat memanfaatkan perhitungan cosine similarity. Proses yang digunakan pada keyword extraction system dan perbandingan keyword menggunakan penndekatan berbasis aturan. Gambaran umum proses pada hybrid recommendation system dideskripsikan pada Gambar 4.1. Basis Data Tokenisasi Stopword Removal Stemming Pembobotan teks Keyword Data Transaksi Terseleksi Keyword Dokumen Terseleksi Penggalian Frequent Itemset Dokumen Frequent Cosine Similarity Rekomendasi User Pemilihan Dokumen Data Transaksi Keyword Dokumen Acuan ID Dokumen Informasi Dokumen
Gambar 4.1 Gambaran umum hybrid recommendation system
Dengan penggunaan algoritma frequent itemset dan perhitungan cosine similarity pada perbandingan keyword, sistem rekomendasi dibentuk dalam beberapa proses. Proses pemilihan dokumen digunakan sebagai proses untuk pengambilan data transaksi. Proses pemilihan dokumen adalah saat pengguna melakukan pemilihan dokumen yang disajikan oleh sistem. Dokumen yang
36
disajikan oleh sistem dapat berupa dokumen hasil pencarian dan dokumen rekomendasi. Dokumen teks diproses pada keyword extraction system untuk memperoleh keyword dokumen. Dokumen pilihan pengguna digunakan sebagai dokumen acuan dalam penggalian frequent itemset maupun perbandingan keyword. Penggalian frequent itemset dilakukan untuk mendapatkan frequent document. Keyword extraction system melakukan ekstraksi keyword untuk dokumen yang dimasukkan pada sistem sehingga setiap dokumen akan memiliki daftar keyword hasil ekstraksi.
Data transaksi dibentuk saat proses pemilihan dokumen yang dilakukan oleh pengguna. Proses pemilihan adalah saat pengguna melakukan pemilihan dokumen yang ada pada daftar dokumen hasil pencarian atau hasil rekomendasi. Setiap sesi merupakan satu data transaksi. Dalam satu data transasi, terdapat deret item yang merupakan id dari dokumen. Deret item ini merupakan dokumen-dokumen yang dipilih pada sesi penggunaan sistem. Sesi yang digunakan merupakan sesi default pada browser. Dengan demikian, walaupun pengguna sama tetapi penggunaan sistem dilakukan pada sesi yang berbeda, maka data pemilihan dokumen tersebut akan dipisahkan. Hal ini dilakukan untuk mengantisipasi proses pemilihan dokumen dengan konten yang berbeda walaupun penggunanya sama. Penggunaan asumsi tersebut mengakibatkan data identitas pengguna dapat diabaikan. Selain menjadi data transaksi, dokumen pilihan pengguna juga menjadi dokumen acuan untuk menentukan daftar data transaksi terseleksi yang digunakan pada proses penggalian frequent itemset.
Keyword dokumen frequent lalu dibandingkan dengan keyword dokumen acuan menggunakan metode cosine similarity. Nilai cosine similarity digunakan untuk penentuan rekomendasi dokumen. Dokumen pembanding akan direkomendasikan kepada pengguna apabila nilai similaritas memenuhi ambang batas. Hasil rekomendasi berupa daftar dokumen yang memenuhi ambang batas yang ditentukan oleh pengguna.