BAB II
TINJAUAN PUSTAKA
2.1 Manggis (Garcinia Mangostana Linn)
Manggis merupakan tanaman buah berupa pohon yang berasal dari hutan tropis yang teduh di kawasan Asia Tenggara, yaitu hutan belantara Malaysia atau Indonesia. Dari Asia Tenggara, tanaman ini menyebar ke daerah Amerika Tengah dan daerah tropis lainnya seperti Srilanka, Malagasi, Karibia, Hawaii dan Australia Utara. Sentra produksi manggis di Indonesia antara lain di Jawa Barat, Jawa Tengah, Jawa Timur, Lampung, Sumatera Barat dan Nagroe Aceh Darussalam. Manggis di Indonesia disebut dengan berbagai macam nama lokal seperti manggu (Jawa Barat), Manggus (Lampung), Manggusto (Sulawesi Utara), Manggista (Sumatera Barat) (Kastaman et al. 2008).
Buah manggis berbentuk bulat, terdiri dari bagian perikarp (kulit luar) dan daging buah yang menyelimuti biji. Pada bagian pangkal buah terdapat calyx (daun buah) dan pada bagian ujung terdapat 4 – 8 tonjolan berbentuk segitiga (triangle), mencirikan jumlah daging buah. Daging buah berwarna putih susu, diameter buah berkisar antara 3,4 – 7,5 cm. Biji buah kadang-kadang tidak seluruhnya didapati pada daging buah. Daging buah ini berukuran panjang 2,5 cm dan lebar 1,6 cm, berbentuk oval. Pada buah berumur muda daging buah berasa asam, semakin matang berasa manis. Buah manggis termasuk rendah kalori, protein, lemak dan vitamin, namun jumlah seratnya termasuk cukup tinggi. Kadar gula total (sukrosa, glukosa, fruktosa) sebesar 16,42 – 16,82 % dari total karbohidrat. Selain itu, terdapat pula senyawa tanin dan resin sebesar 7 – 14 %,
polyhydroxy-xanthone, dan mangostin (Morton J 1987). Manggis bermanfaat
sebagai antioksidan dan berbagai obat, diantaranya sariawan, wasir, luka, anti peradangan dan nyeri, mencegah alzheimer dan arthritis, memperbaiki sistem pernafasan, mendukung tulang rawan dan sendi, serta menjaga pencernaan.
Manggis merupakan salah satu komoditas ekspor yang menjadi andalan Indonesia untuk meningkatkan pendapatan devisa. Berdasarkan data volume
ekspor manggis Indonesia dari tiga tahun terakhir terus mengalami peningkatan dari 6.9 ribu ton pada tahun 2002 meningkat menjadi 7.2 ribu ton pada tahun 2003. Dengan pangsa pasar utama adalah Taiwan dan Hongkong (Departemen Pertanian 2004). Volume ekspor Manggis Indonesia meningkat nyata pada dua bulan pertama tahun 2011, hampir sama dengan volume ekspor sepanjang tahun 2009.
Buah manggis merupakan buah klimakterik sehingga buah dapat matang selama masa penyimpanannya. Puncak klimakterik dicapai setelah penyimpanan 10 hari pada suhu ruang (Martin 1980). Pemanenan umumnya dilakukan setelah buah berumur 104 hari dihitung mulai bunga mekar, saat itu warna kulit buah manggis masih berwarna hijau dengan sedikit ungu muda pada permukaan kulit buahnya. Enam hari setelah dipanen warna kulit buah menjadi ungu tua (Suyanti
et al. 1999a.). Buah yang dipanen saat buah berwarna merah tua (114 hari)
menyebabkan daya simpannya lebih singkat dan tidak dapat memenuhi persyaratan mutu manggis untuk ekspor.
Perubahan warna buah dari hijau menjadi ungu hitam setelah panen yang mencerminkan perkembangan warna kematangan tahap 1 sampai tahap 6 digunakan sebagai panduan kualitas bagi petani dan konsumen. Tidak ada perbedaan yang signifikan dalam kualitas buah pada buah manggis yang dipanen pada salah satu tahap dari tahap yang ditetapkan (tahap 1-6), sehingga matang pada tahap 6 untuk masing-masing (Palapol et al. 2009). Hal ini menunjukkan bahwa pemeraman buah manggis yang dipetik pada salah satu tahap untuk kebutuhan ekspor tidak memiliki efek merugikan pada kualitas buah akhir.
Berdasarkan SPO panen manggis departemen pertanian 2004 dinyatakan bahwa panen manggis dilakukan berdasarkan penentuan umur dan visual. Manggis layak dipanen bila telah berumur 104-110 setelah bunga mekar (SBM) atau bila secara visual sudah banyak buah yang matang, hal ini hanya bisa ditentukan oleh seseorang yang telah berpengalaman. Pemanenan buah dalam satu pohon dapat dilakukan dua sampai tiga kali sesuai dengan tingkat kematangan buah.
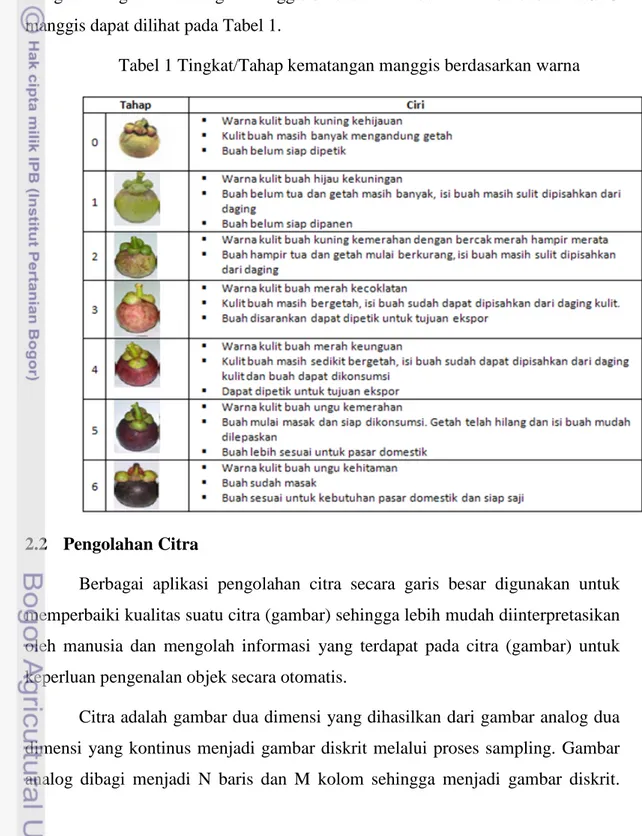
Mutu buah manggis ditentukan oleh berbagai parameter diantaranya adalah parameter tingkat ketuaan dan kematangan (indeks warna) serta ukuran (Deptan 2004). Proses grading dalam SPO komoditas manggis 2004, merupakan suatu pengelompokan buah berdasarkan kriteria/kelas dan indek kematangan manggis untuk mendapatkan ukuran, warna buah dan tingkat kematangan yang seragam. Tingkat kematangan manggis berdasarkan indek warna berdasarkan SPO manggis dapat dilihat pada Tabel 1.
Tabel 1 Tingkat/Tahap kematangan manggis berdasarkan warna
2.2 Pengolahan Citra
Berbagai aplikasi pengolahan citra secara garis besar digunakan untuk memperbaiki kualitas suatu citra (gambar) sehingga lebih mudah diinterpretasikan oleh manusia dan mengolah informasi yang terdapat pada citra (gambar) untuk keperluan pengenalan objek secara otomatis.
Citra adalah gambar dua dimensi yang dihasilkan dari gambar analog dua dimensi yang kontinus menjadi gambar diskrit melalui proses sampling. Gambar analog dibagi menjadi N baris dan M kolom sehingga menjadi gambar diskrit.
Persilangan antara baris dan kolom tertentu disebut dengan piksel. Contohnya adalah gambar/titik diskrit pada baris n dan kolom m disebut dengan piksel[n,m].
Suatu citra dapat didefinisikan sebagai fungsi dua dimensi f(x,y) yaitu fungsi intensitas atau tingkat keabuan dari citra pada titik tersebut. Fungsi ini berukuran M baris dan N kolom, dengan x dan y adalah koordinat spasial dalam sistem koordinat piksel, dan amplitudo f di titik koordinat (x,y). Jika nilai x, y, dan nilai amplitudo f secara keseluruhan berhingga (finite) dan bernilai diskrit maka dapat dikatakan bahwa citra tersebut adalah cira digital. Matrik citra digital direpresentasikan dalam suatu koordinat piksel, yang tidak mempunyai nilai x dan y negatif.
Citra digital dapat ditulis dalam bentuk matrik sebagai berikut :
Masing-masing elemen dalam matriks disebut dengan elemen citra atau piksel, f(x,y) merupakan intensitas citra, sedangkan x dan y
2.3 Model Warna
merupakan posisi piksel dalam citra.
Model warna RGB (Red, Green, Blue) mendefinisikan warna berdasarkan tingkat intensitas komponen warna merah, hijau dan biru atau RGB, yang disajikan dalam bentuk koordinat tiga dimensi yang disebut kubus warna, disajikan pada Gambar 1.
Jika ketiga intensitas warna tersebut bernilai 0, maka warna yang terjadi adalah hitam, sedangkan jika ketiga intensitas warna tersebut bernilai 1, maka warna yang terjadi adalah putih. Nilai RGB didapatkan dari rata-rata keseluruhan piksel. Proses konversi dari model warna RGB ke model warna lain sebelumnya dilakukan menormalisasi nilai RGB menjadi rgb dengan membaginya dengan 255. Konsep Model Warna RGB berorientasi pada hardware dan kita jumpai di peralatan seperti : monitor computer, LCD proyektor, scanner, kamera video dan kamera digital.
Model HSV (Hue, Saturation dan Value) menunjukkan ruang warna dalam bentuk tiga komponen utama, yaitu hue, saturation, dan value atau disebut juga
brightness, disajikan pada Gambar 2.
Gambar 2 Nilai hue, saturasi dan value
Hue adalah sudut dari 0 sampai 360 derajat yang menunjukkan jenis warna
(seperti merah, biru atau kuning) atau corak warna yaitu tempat warna tersebut ditemukan dalam spektrum warna (Putra, 2010). Saturation (saturasi) dari suatu warna adalah ukuran seberapa besar kemurnian dari warna tersebut, yang bernilai antara 0 sampai 1 (atau 0 sampai 100%) dan menunjukkan nilai keabu-abuan warna (Putra, 2010). Value disebut juga intensitas yaitu ukuran seberapa besar kecerahan dari suatu warna atau seberapa besar cahaya datang dari suatu warna.
Value dapat bernilai 0 sampai 100%. Nilai HSV didapatkan dengan mengkonversi
nilai rgb dengan persamaan (Putra, 2010) :
𝑉𝑉 = max(𝑟𝑟, 𝑔𝑔, 𝑏𝑏) ………. …… (1) 𝑆𝑆 = �𝑉𝑉 −0 , 𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗 𝑉𝑉 = 0min (𝑟𝑟,𝑔𝑔,𝑏𝑏)
𝑉𝑉 , 𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗 𝑉𝑉 > 0
𝐻𝐻 = �0 , 𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗 𝑆𝑆 = 060∗(𝑔𝑔−𝑏𝑏) 𝑆𝑆∗𝑉𝑉 , 𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗 𝑉𝑉 = 𝑟𝑟 ……….. (3) 𝐻𝐻 = �60 ∗ �2 + (𝑏𝑏−𝑟𝑟) 𝑆𝑆∗𝑉𝑉 � , 𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗 𝑉𝑉 = 𝑔𝑔 60 ∗ �4 +(𝑟𝑟−𝑔𝑔)𝑆𝑆∗𝑉𝑉 � , 𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗 𝑉𝑉 = 𝑏𝑏 .……….. (4) 𝐻𝐻 = 𝐻𝐻 + 360, 𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗 𝐻𝐻 < 0 ………. (5) Model warna CIE L*a*b* bekerja berdasar pada persepsi manusia atas warna, yaitu lightness A (Green-red axis) dan lightness B (Blue-yellow Axis). Model ini terdiri dari besaran Lightness/Luminance (L*), dimensi a (a*), dan dimensi b (b*), disajikan pada Gambar 3.
Gambar 3 Model warna CIELab
Nilai skala untuk Lightness/Luminance berkisar 0 sampai 100, yaitu dari warna hitam sampai warna putih (L* = 100 untuk warna putih dan L* = 0 untuk warna hitam). Dimensi a* dan b* menyimpan informasi komponen kromatik warna hijau sampai merah dan warna biru sampai kuning. Angka negatif a* mengindikasikan warna hijau dan sebaliknya a* positif mengindikasikan warna merah, sedangkan angka negatif b* mengindikasikan warna biru dan sebaliknya CIE_b* positif mengindikasikan warna kuning. Nilai L*a*b* didapatkan dengan mengkonversi nilai rgb dengan persamaan :
x ≤ 0,03928; 𝑓𝑓(𝑥𝑥) = 𝑥𝑥 12,92 ………. (6) x ≥ 0,3928; 𝑓𝑓(𝑥𝑥) = �𝑥𝑥+0,055 1,055 � 2,4 ..………. (7) Nilai x adalah nilai R'G' atau B'. Nilai f(x) menunjukkan nilai konversi sR, sG dan sB. Nilai sRGB selanjutnya dikonversi ke model warna CIE XYZ menggunakan persamaan :
�𝑋𝑋𝑌𝑌 𝑍𝑍� = � 0,4124 0,3576 0,1805 0,2126 0,7152 0,0722 0,0193 0,1192 0,9505� � 𝑠𝑠𝑠𝑠 𝑠𝑠𝑠𝑠 𝑠𝑠𝑠𝑠� .……….. (8)
Untuk menghitung nilai L*a*b* dari CIE XYZ menggunakan persamaan : 𝐿𝐿∗ = 116 ∗ 𝑓𝑓 �𝑌𝑌 𝑌𝑌𝑛𝑛� − 16 …..………. (9) 𝑗𝑗∗ = 500 ∗ �𝑓𝑓 �𝑋𝑋 𝑋𝑋𝑛𝑛� − 𝑓𝑓 � 𝑌𝑌 𝑌𝑌𝑛𝑛�� ……….…… (10) 𝑏𝑏∗ = 200 ∗ �𝑓𝑓 �𝑌𝑌 𝑌𝑌𝑛𝑛� − 𝑓𝑓 � 𝑍𝑍 𝑍𝑍𝑛𝑛�� ………...… (11) dengan f(τ) = �𝜏𝜏 1 3 𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗 𝜏𝜏 > 0,008856 7,7867 𝜏𝜏 + 11616 𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗 𝜏𝜏 ≤ 0,008856
Nilai Xn, Yn dan Zn adalah nilai XYZ dengan observer 2o dan illuminant D65 (easyrgb.com 2011).
CIELuv (L*u*v*) merupakan model warna yang sebanding dengan persepsi mata manusia yang didefinisikan dengan menggambarkan 3 koordinat geometrik L*, u* dan v*, disajikan pada Gambar 4.
Gambar 4 Model warna CIELuv
CIE_ L* merupakan lightness atau kecerahan warna. CIE_u* merupakan kuat warna pada sumbu merah – hijau. CIE_v* merupakan kuat warna pada sumbu kuning – biru. Konversi dari sistem X, Y, Z ke sistem L*u*v* menggunakan persamaan (Lu G & Phillips J, 1998) :
L∗ = 116 �𝑌𝑌
𝑌𝑌0� 13 − 16 untuk
𝑌𝑌
𝐿𝐿∗ = 903,3 �𝑌𝑌 𝑦𝑦0� untuk 𝑌𝑌 𝑌𝑌0 ≤ 0,008856 ... (13) u* = 13L* (u' – u'0) ... (14) v* = 13L* (v' – v'0) ... (15) dengan : u′ = 4𝑋𝑋 (𝑋𝑋+15𝑌𝑌+3𝑍𝑍)= 4𝑥𝑥 −2𝑥𝑥+12𝑦𝑦+3 ... (16) v′ = 9𝑌𝑌 (𝑋𝑋+15𝑌𝑌+3𝑍𝑍)= 9𝑦𝑦 −2𝑥𝑥+12𝑦𝑦+3 ... (17) 𝑢𝑢0′ = 𝑥𝑥0+15𝑦𝑦4𝑥𝑥00+3𝑧𝑧0 ... (18) 𝑣𝑣0′ =𝑥𝑥0+15𝑦𝑦9𝑦𝑦00+3𝑧𝑧0 ... (19) Dimana x0, y0 dan z0 adalah x, y dan z dengan observer 2o dan illuminant D65 (easyrgb.com 2011).
2.4 Analisis Tekstur
Salah satu cara untuk mengenali suatu citra adalah dengan membedakan tekstur yang merupakan komponen dasar pembentuk citra dan dapat dimanfaatkan sebagai dasar klasifikasi citra. Tekstur citra dapat dibedakan berdasar kerapatan, keseragaman, keteraturan, kekasaran dan lain-lain. Untuk mengetahui pola suatu citra digital berdasarkan ciri yang diperoleh secara matematis digunakan analisis tekstur. Ciri atau karakteristik suatu tekstur diperoleh melalui proses ekstraksi ciri. Salah satu metode untuk mendapatkan ciri atau karakteristik suatu tekstur adalah metode co-occurrence.
Secara umum tekstur mengacu pada repetisi elemen-elemen tekstur dasar yang disebut elemen tekstur. Elemen tekstur terdiri dari beberapa piksel dengan aturan posisi bersifat periodik, kuasiperiodik atau acak. Dua syarat terbentuknya tekstur (Ahmad 2005) adalah : (1) adanya pola-pola primitif yang terdiri dari satu atau lebih piksel. Bentuk-bentuk pola primitif ini dapat berupa titik, garis lurus, garis lengkung, luasan dan lain-lain yang merupakan elemen dasar dari suatu bentuk. (2) pola-pola primitif tadi muncul berulang-ulang dengan interval jarak dan arah tertentu sehingga dapat dipresiksi atau ditemukan karakteristik pengulangannya.
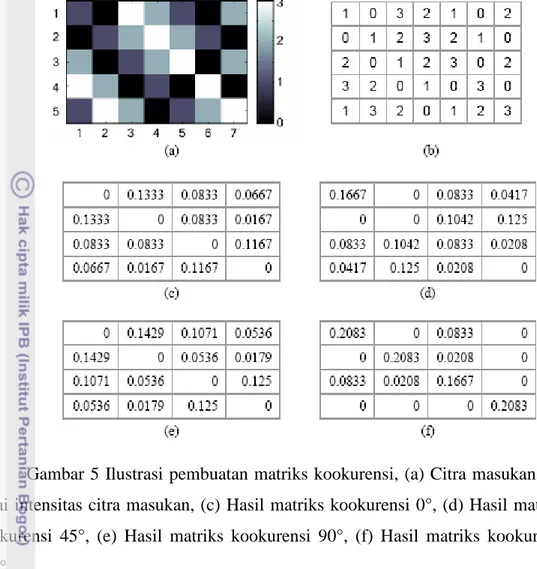
Metode co-occurrence bekerja dengan membentuk sebuah matriks kookurensi dari data citra dan menentukan ciri sebagai fungsi dari matriks tersebut. Matriks kookurensi dibentuk dari suatu citra greyscale dengan melihat pada piksel-piksel yang berpasangan yang memiliki intensitas tertentu. Penggunaan metode ini berdasar pada hipotesis bahwa dalam suatu tekstur akan terjadi perulangan pola-pola primitif. Misalkan d didefinisikan sebagai jarak antara dua posisi piksel (x1, y1) dan (x2, y2), dan θ didefinisikan sebagai sudut diantara keduanya, maka matriks kookurensi didefinisikan sebagai matriks yang menyatakan distribusi spasial antara dua piksel yang bertetangga yang memiliki intensitas i dan j, yang memiliki jarak d dan sudut θ diantara keduanya. Orientasi dibentuk dalam empat arah sudut dengan interval sudut 45°, yaitu 0°, 45°, 90°, dan 135°. Sedangkan jarak antar piksel biasanya ditetapkan sebesar 1 piksel. Matriks kookurensi dinyatakan sebagai Pdθ(i,j).
Matriks kookurensi didapatkan melalui tiga tahap, yaitu : (1) mengubah citra RGB menjadi citra grayscale, (2) menghitung kookurensi matrik dalam 4 arah, masing-masing 0o, 45o, 90o dan 135o, (3) menentukan nilai untuk setiap ciri tekstur dengan merata-rata nilai dari keempat arah sudut tersebut. Langkah untuk membuat matriks kookurensi simetris ternormalisasi yaitu : (1) membuat area kerja matriks, (2) menentukan hubungan spasial antara piksel referensi dengan piksel tetangga, berapa nilai sudut θ dan jarak d, (3) menghitung jumlah kookurensi dan mengisikannya pada area kerja, (4) menjumlahkan matriks kookurensi dengan transposenya untuk menjadikannya simetris, dan (5) normalisasi matriks untuk mengubahna ke bentuk probabilitas. Pembuatan matriks kookurensi ditunjukkan oleh Gambar 5.
Setelah memperoleh matriks kookurensi tersebut, dapat dihitung ciri yang merepresentasikan citra yang diamati. Berbagai jenis ciri tekstural dapat diekstraksi dari matriks kookurensi. Komponen yang digunakan dalam pengukuran tekstur adalah energi, kontras, homogenitas dan entropi (Haralic et
Gambar 5 Ilustrasi pembuatan matriks kookurensi, (a) Citra masukan, (b) Nilai intensitas citra masukan, (c) Hasil matriks kookurensi 0°, (d) Hasil matriks kookurensi 45°, (e) Hasil matriks kookurensi 90°, (f) Hasil matriks kookurensi 135°.
Fitur energy berfungsi untuk mengukur konsentrasi pasangan grey level pada matrik co-occurance. Nilai energi didapatkan dengan memangkatkan setiap elemen dalam grey level co-occurance matrix (GLCM), kemudian dijumlahkan. Fitur kontras digunakan untuk mengukur perbedaan lokal dalam citra atau mengukur variasi derajat keabuan suatu daerah citra atau menyatakan sebaran terang (lightness) dan gelap (darkness) dalam sebuah citra. Fitur homogenitas berfungsi untuk mengukur kehomogenan variasi grey level (perbedaan lokal) dalam sebuah citra. Fitur entropi digunakan untuk mengukur keteracakan dari distribusi perbedaan lokal dari sebuah citra (Mathwork 2011).
Komponen pengukuran tekstur yang meliputi energi, kontras, homogenitas dan entropy dapat diambil menggunakan persamaan :
𝐸𝐸𝑛𝑛𝐸𝐸𝑟𝑟𝑔𝑔𝑗𝑗 = ∑ ∑𝑛𝑛 𝑝𝑝2 𝑗𝑗=1 𝑚𝑚 𝑗𝑗=1 (𝑗𝑗, 𝑗𝑗) ... (20) 𝐾𝐾𝐾𝐾𝑛𝑛𝐾𝐾𝑟𝑟𝑗𝑗𝑠𝑠 = ∑ ∑ (𝑗𝑗 − 𝑗𝑗)𝑛𝑛 2 𝑗𝑗=1 𝑚𝑚 𝑗𝑗=1 𝑝𝑝(𝑗𝑗, 𝑗𝑗) ... (21) 𝐻𝐻𝐾𝐾𝑚𝑚𝐾𝐾𝑔𝑔𝐸𝐸𝑛𝑛𝑗𝑗𝐾𝐾𝑗𝑗𝑠𝑠 = ∑ ∑𝑛𝑛 1+|𝑗𝑗−𝑗𝑗|𝑝𝑝(𝑗𝑗,𝑗𝑗) 𝑗𝑗=1 𝑚𝑚 𝑗𝑗=1 ... (22) 𝐸𝐸𝑛𝑛𝐾𝐾𝑟𝑟𝐾𝐾𝑝𝑝𝑗𝑗 = − ∑ ∑𝑛𝑛 𝑝𝑝(𝑗𝑗, 𝑗𝑗) log 𝑝𝑝(𝑗𝑗, 𝑗𝑗) 𝑗𝑗=1 𝑚𝑚 𝑗𝑗=1 ... (23) Dengan i dan j adalah intensitas dari resolusi 2 piksel yang berdekatan. Sedangkan P(i, j) adalah frekuensi relatif matrik dari resolusi 2 piksel yang berdekatan.
2.5 Transformasi Data
Sebelum menggunakan data dengan metode atau teknik tertentu perlu dilakukan praproses terhadap data dengan maksud agar data dapat dikenali dengan lebih baik. Salah satu praproses yang sering dipakai adalah transformasi data. Transformasi data dilakukan untuk mengubah data ke dalam rentang nilai tertentu. Rentang nilai ditentukan berdasarkan kasus dan keperluan terntentu. Sebagai misal penggunaan fungsi aktivasi sigmoid pada jaringan FNN. Untuk keperluan tersebut maka data mesti ditransformasi sehingga semua data memiliki range yang sama dengan range keluaran fungsi aktivasi sigmoid yang dipakai, yaitu [0, 1]. Data dapat ditransformasi ke interval [0,1]. Namun akan lebih baik jika ditransformasikan ke interval yang lebih kecil, misal pada interval [0.1 0.9]. Hal ini mengingat bahwa fungsi sigmoid merupakan fungsi asimtotik yang nilainya tidak pernah mencapai nilai 0 maupun 1.
Berikut adalah transformasi linier yang dipakai untuk mentrasformasikan data ke interval [0.1 0.9] jika a adalah data minimum dan b adalah data maksimum.
𝑥𝑥′ =0.8(𝑥𝑥−𝑗𝑗)
𝑏𝑏−𝑗𝑗 + 0.1 ... (24)
2.6 Koefisien Determinasi
Koefisien determinasi pada regresi linier sering diartikan sebagai seberapa besar kemampuan semua variabel bebas dalam menjelaskan varians dari variabel
terikatnya. Secara sederhana koefisien determinasi dihitung dengan mengkuadratkan Koefisien Korelasi (R). Sebagai contoh, jika nilai R adalah sebesar 0,80 maka koefisien determinasi (R Square) adalah sebesar 0,80 x 0,80 = 0,64. Berarti kemampuan variabel bebas dalam menjelaskan varians dari variabel terikatnya adalah sebesar 64,0%. Berarti terdapat 36% (100%-64%) varians variabel terikat yang dijelaskan oleh faktor lain. Berdasarkan interpretasi tersebut, maka tampak bahwa nilai R Square adalah antara 0 sampai dengan 1.
Berikut adalah penetapan dan interpretasi koefisien korelasi dan koefisien determinasi pada regresi linier sederhana.
𝑟𝑟 =
𝑛𝑛 ∑𝑛𝑛𝑗𝑗=1𝑥𝑥𝑗𝑗𝑦𝑦𝑗𝑗−�∑𝑛𝑛𝑗𝑗=1𝑥𝑥𝑗𝑗��∑𝑛𝑛𝑗𝑗=1𝑦𝑦𝑗𝑗���𝑛𝑛 ∑𝑛𝑛𝑗𝑗=1𝑥𝑥12−�∑𝑛𝑛𝑗𝑗=1𝑥𝑥𝑗𝑗�2��𝑛𝑛 ∑𝑛𝑛𝑗𝑗=1𝑦𝑦12−�∑𝑛𝑛𝑗𝑗=1𝑦𝑦𝑗𝑗�2�
𝑠𝑠 = 𝑟𝑟2 ... (25) Berikut adalah koefisien determinasi untuk regresi linier berganda.
𝑠𝑠
𝑦𝑦.122= 1 −
(𝑛𝑛−1)𝑠𝑠𝐽𝐽𝐾𝐾𝑠𝑠𝑦𝑦2 ... (26)
Dimana JKG adalah jumlah kuadrat galat sedangkan sy2 adalah jumlah kuadrat y dengan definisi sebagai berikut :
𝑠𝑠
𝑦𝑦2=
𝑛𝑛 ∑ 𝑦𝑦 2−(∑ 𝑦𝑦)2 𝑛𝑛(𝑛𝑛−1)𝐽𝐽𝐾𝐾𝑠𝑠 = ∑ 𝑦𝑦2− 𝑗𝑗 ∑ 𝑦𝑦 − 𝑏𝑏 1∑ 𝑥𝑥1𝑦𝑦 − 𝑏𝑏2∑ 𝑥𝑥2𝑦𝑦 2.7 Klasifikasi
Klasifikasi adalah tugas pembelajaran sebuah fungsi target f yang memetakan setiap himpunan atribut x ke salah satu label kelas y yang telah didefinisikan sebelumnya. Data input yang digunakan untuk klasifikasi adalah koleksi dari record. Setiap record dikenal sebagai instance atau contoh, yang ditentukan oleh sebuah tuple (x,y) dimana x adalah himpunan atribut yang disebut atribut predictor dan y adalah suatu atribut tertentu yang dinyatakan sebagai label kelas atau target.
Pendekatan umum yang digunakan dalam klasifikasi adalah adanya
training set yang berisi record berlabel kelas, digunakan untuk membangun
model klasifikasi. Selanjutnya model klasifikasi diaplikasikan ke test set yang berisi record tanpa label kelas. Hal ini merupakan proses pengenalan kembali suatu objek berdasarkan pola yang telah dikenal (Duda, Hart & Stork 1997). Teknik klasifikasi yang digunakan dalam penelitian ini adalah klasifikasi fuzzy menggunakan neural network yang dikenal dengan fuzzy neural network.
2.8 Neural Network (NN)
Neural Network (NN) atau Jaringan syaraf tiruan (JST) adalah sistem
komputasi dimana arsitektur dan operasi diilhami dari pengetahuan tentang sel syaraf biologi di dalam otak (Fausett 1994). NN didasari oleh kemampuan otak manusia dalam mengorganisasikan sel-sel penyusunnya yang disebut neuron, sehingga mampu melaksanakan tugas-tugas tertentu khususnya pengenalan pola dengan efektifitas yang tinggi. Pengetahuan diperoleh jaringan melalui proses belajar dan kekuatan hubungan antar sel syaraf (neuron) yang dikenal sebagai bobot-bobot sinaptik digunakan untuk menyimpan pengetahuan (Haykin & Simon, 1994). Model syaraf ditunjukkan dengan kemampuannya dalam emulasi, analisis, prediksi dan asosiasi.
NN adalah pemrosesan informasi yang mempunyai karakteristik kinerja tertentu seperti jaringan neural biologis, yang berdasarkan pada asumsi (Siang 2009) : (1) pemrosesan informasi terjadi pada banyak elemen sederhana yang disebut neuron, (2) sinyal diberikan antara neuron lewat jalinan koneksi, (3) setiap jalinan koneksi mempunyai bobot yang mengalikan sinyal yang ditransmisikan, (4) setiap neuron menerapkan fungsi aktivasi (yang biasannya non linier) terhadap jumlah sinyal masukan terbobot untuk menentukan sinyal keluarannya.
NN dicirikan oleh (Fauset 1994) : (1) pola hubungan antara
neuron-neuron-nya, yang disebut arsitektur, (2) metode penentuan bobot (weight) pada
hubungan, yang disebut pelatihan (training), pembelajaran (learning) atau algoritma (3) fungsi aktivasinya.
Struktur jaringan neural terdiri atas sejumlah besar komponen yang disebut neuron. Setiap neuron terhubung dengan neuron lainnya dengan jalinan
koneksi yang berkaitan dengan bobot. Bobot mewakili informasi yang diterima jaringan dan dijadikan sebagian nilai untuk menyelesaikan masalah. Gambar 6 memperlihatkan model tiruan sebuah neuron.
Gambar 6 Model Neuron (Hermawan, 2006).
Sebuah neuron menerima sejumlah n masukan, yaitu 𝑥𝑥1, 𝑥𝑥2, … , 𝑥𝑥𝑛𝑛. Setiap masukan dimodifikasi oleh bobot sinapsis 𝑤𝑤1, 𝑤𝑤2, … , 𝑤𝑤𝑛𝑛 sehingga masukan ke dalam neuron adalah 𝑥𝑥𝑗𝑗 = 𝑥𝑥𝑗𝑗𝑤𝑤𝑗𝑗, dimana 𝑗𝑗 = 1,2, … , 𝑛𝑛. Kemudian neuron akan menghitung hasil penjumlahan seluruh masukan, dan fungsi aktivasi akan menentukan keluaran neuron :
𝑛𝑛𝐸𝐸𝐾𝐾 = 𝑥𝑥1𝑤𝑤1+ 𝑥𝑥2𝑤𝑤2+ ⋯ + 𝑥𝑥𝑛𝑛𝑤𝑤𝑛𝑛 atau 𝑛𝑛𝐸𝐸𝐾𝐾 = ∑𝑛𝑛𝑗𝑗=1𝑥𝑥𝑗𝑗𝑤𝑤𝑗𝑗 ... (27) Dengan mengasumsikan suatu black box yang tidak tahu isinya, neural
network akan menemukan pola hubungan antara input dan output melalui fasa training. Neural network masuk dalam kategori supervised learning. Dalam
kategori ini suatu network dilatih untuk menemukan parameter model yaitu w dan b yang terbaik.
Hal yang perlu dipertimbangkan dalam mendesain suatu neural network adalah tipe jaringan, jumlah layer, banyaknya simpul/node di tiap layer, fungsi transfer atau activation function dalam setiap layer dan jumlah epoch/iterasi yang digunakan untuk training (Santosa 2007).
2.8.1 Arsitektur Backpropagation
Backpropagation adalah salah satu tipe neural network yang paling
populer dan sering digunakan. Jaringan neuron yang sering digunakan dalam NN untuk pengenalan pola adalah jaringan lapis tunggal (single layer network) dan jaringan lapis banyak (multi layer network). Perbedaan kedua arsitektur ini adalah adanya lapisan tersembunyi. Pada jaringan lapis tunggal tidak ada lapisan
tersembunyi, sedangkan pada jaringan lapis banyak memiliki minimal satu lapisan tersembunyi (Kusumadewi, 2003).
Lapisan-lapisan penyusun neural network terdiri dari lapisan input (input
layer), lapisan tersembunyi (hidden layer) dan lapisan output (output layer).
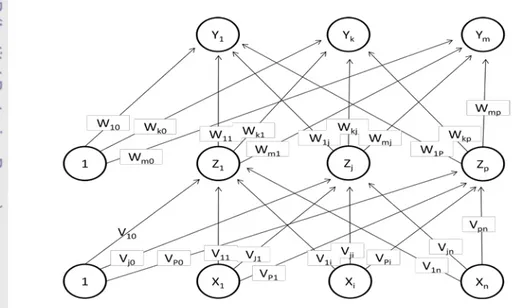
Gambar 7 menunjukkan arsitektur backpropagation dengan n buah masukan (dengan sebuah bias), sebuah layar tersembunyi yang terdiri dari p unit (dengan sebuah bias) serta m unit keluaran. Vji merupakan bobot garis dari unit masukan xi ke unit layar tersembunyi zj (vjo merupakan bobot garis yang menghubungkan bias di unit masukan ke layar tersembunyi zj). wkj merupakan bobot dari layar tersembunyi zj ke unit keluaran yk (wk0 merupakan bobot dari bias di layar tersembunyi ke unit keluaran zk).
Gambar 7 Arsitektur backpropagation (Siang, 2009).
2.8.2 Fungsi Aktivasi
Fungsi aktivasi merupakan keadaan internal suatu neuron yang digunakan pada perhitungan input yang diterima neuron, setelah itu diteruskan ke neuron berikutnya. Dengan fungsi aktivasi ini neuron dapat mengambil keputusan dari pengolahan bobot-bobot yang ada dan menentukan kuat lemahnya sinyal yang dikeluarkan oleh suatu neuron. Dalam backpropagation fungsi aktivasi yang dipakai harus memenuhi beberapa syarat, yaitu kontinyu, terdiferensial dengan mudah dan merupakan fungsi yang tidak turun.
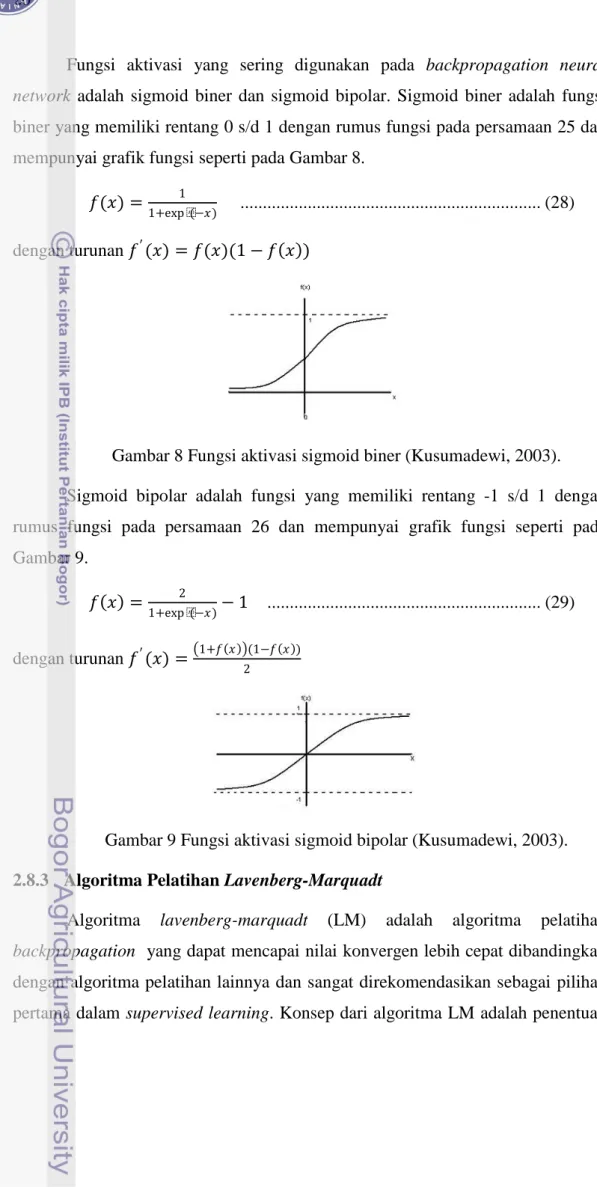
Fungsi aktivasi yang sering digunakan pada backpropagation neural
network adalah sigmoid biner dan sigmoid bipolar. Sigmoid biner adalah fungsi
biner yang memiliki rentang 0 s/d 1 dengan rumus fungsi pada persamaan 25 dan mempunyai grafik fungsi seperti pada Gambar 8.
𝑓𝑓(𝑥𝑥) =1+exp (−𝑥𝑥)1 ... (28) dengan turunan 𝑓𝑓′(𝑥𝑥) = 𝑓𝑓(𝑥𝑥)(1 − 𝑓𝑓(𝑥𝑥))
Gambar 8 Fungsi aktivasi sigmoid biner (Kusumadewi, 2003). Sigmoid bipolar adalah fungsi yang memiliki rentang -1 s/d 1 dengan rumus fungsi pada persamaan 26 dan mempunyai grafik fungsi seperti pada Gambar 9.
𝑓𝑓(𝑥𝑥) =1+exp (−𝑥𝑥)2 − 1 ... (29)
dengan turunan 𝑓𝑓′(𝑥𝑥) =�1+𝑓𝑓(𝑥𝑥)�(1−𝑓𝑓(𝑥𝑥)) 2
Gambar 9 Fungsi aktivasi sigmoid bipolar (Kusumadewi, 2003).
2.8.3 Algoritma Pelatihan Lavenberg-Marquadt
Algoritma lavenberg-marquadt (LM) adalah algoritma pelatihan
backpropagation yang dapat mencapai nilai konvergen lebih cepat dibandingkan
dengan algoritma pelatihan lainnya dan sangat direkomendasikan sebagai pilihan pertama dalam supervised learning. Konsep dari algoritma LM adalah penentuan
matriks hessian untuk mencari bobot-bobot dan bias koneksi (Budi & Sumiyati 2007).
Matriks hessian adalah matriks yang setiap elemennya terbentuk dari turunan kedua dari fungsi kinerja terhadap setiap komponen bobot dan bias. Untuk memudahkan komputasi, matriks hessian diubah dengan pendekatan iteratif pada setiap epoch selama algoritma berjalan. Proses pengubahannya dilakukan menggunakan fungsi gradien. Berikut adalah estimasi matriks hessian jika fungsi kinerja yang digunakan berbentuk jumlah kuadrat error (SSE).
𝐻𝐻 = 𝐽𝐽𝑇𝑇𝐽𝐽 + 𝜂𝜂𝜂𝜂 ... (30) Dimana η merupakan parameter marquadt, I merupakan matriks identitas dan J adalah matriks jacobian yang terdiri dari turunan pertama error jaringan terhadap masing-masing komponen bobot bias.
Nilai parameter marquadt (η) dapat berubah pada setiap epoch. Jika setelah berjalan satu epoch nilai fungsi error menjadi lebih kecil, nilai η akan dibagi oleh faktor τ. Bobot dan bias baru yang diperoleh akan dipertahankan dan pelatihan dapat dilanjutkan ke epoch berikutnya. Sebaliknya jika setelah berjalan satu epoch nilai fungsi error menjadi lebih besar maka nilai η akan dikalikan faktor τ. Nilai perubahan bobot dan bias dihitung kembali sehingga menghasilkan nilai yang baru.
2.8.4 Proses Pembelajaran Backpropagation
Proses pembelajaran merupakan proses perubahan bobot-bobot yang ada pada jaringan dengan tujuan untuk meminimalkan mean square error (mse) atau toleransi galat antara keluaran yang dihasilkan dengan keluaran yang diinginkan (target). Perubahan ini dapat berkurang atau bertambah sesuai dengan informasi yang diberikan oleh neuron yang bersangkutan. Perubahan ini akan berhenti jika bobot-bobot pada jaringan sudah cukup seimbang. Kondisi ini mengindikasikan bahwa setiap input telah berhubungan dengan output yang diharapkan.
Pembelajaran terawasi (supervised learning) merupakan metode yang hanya berlaku jika output yang diharapkan sudah diketahui, sehingga dalam proses pembelajaran, setiap input akan memiliki target output yang harus dicapai.
Jika terjadi perbedaan pola output hasil pembelajaran dengan pola target, maka akan muncul galat. Jika nilai galat ini masih cukup besar, maka perlu iterasi pembelajaran yang berikutnya (Kusumadewi, 2003). Ilustrasi supervised learning dapat dilihat pada Gambar 10.
Gambar 10 Supervised Learning (Rios).
Backpropagation adalah salah satu algoritma yang menggunakan metode supervised learning. Pelatihan backpropagation meliputi 3 fase. Fase pertama
adalah fase maju atau propagasi maju. Pola masukan dihitung maju mulai dari layar masukan hingga layar keluaran menggunakan fungsi aktivasi yang ditentukan. Fase kedua adalah fase mundur atau propagasi mundur. Selisih antara keluaran jaringan dengan target yang diinginkan merupakan kesalahan yang terjadi. Kesalahan tersebut dipropagasikan mundur, mulai garis yang berhubungan langsung dengan unit-unit di layar keluaran. Fase ketiga adalah modifikasi bobot untuk menurunkan kesalahan yang terjadi. Ketiga fase tersebut diulang-ulang terus hingga kondisi penghentian dipenuhi. Umumnya kondisi penghentian yang dipakai adalah jumlah iterasi atau kesalahan. Berikut proses selengkapnya yang terjadi pada setiap fase (Siang 2009).
Fase I : Propagasi maju
Selama propagasi maju, sinyal masukan (xi) dipropagasikan ke lapisan tersembunyi menggunakan fungsi aktivasi yang ditentukan. Keluaran setiap unit lapisan tersembunyi (zj) tersebut selanjutnya dipropagasikan maju ke layar tersembunyi di atasnya menggunakan fungsi aktivasi yang ditentukan. Demikian seterusnya hingga menghasilkan keluaran jaringan (yk). Berikutnya keluaran
jaringan (yk) dibandingkan dengan target yang harus dicapai (tk). Selisih dari tk terhadap yk yaitu tk-yk adalah kesalahan yang terjadi. Jika kesalahan ini lebih kecil dari batas toleransi yang ditentukan, maka iterasi dihentikan. Tetapi apabila kesalahan masih lebih besar dari batas toleransinya, maka bobot setiap garis dalam jaringan dimodifikasi untuk mengurangi kesalahan yang terjadi.
Fase II : Propagasi Mundur
Berdasarkan kesalahan tk-yk, dihitung faktor δk (k = 1, 2, …, m) yang dipakai untuk mendistribusikan kesalahan di unit yk ke semua unit tersembunyi yang terhubung langsung dengan yk. Faktor δk juga dipakai untuk mengubah bobot garis yang berhubungan langsung dengan unit keluaran. Dengan cara yang sama, dihitung faktor δj (j = 1, 2, …, m) di setiap unit di lapisan tersembunyi di layar bawahnya. Demikian seterusnya hingga semua faktor δ di unit tersembunyi yang berhubungan langsung dengan unit masukan dihitung.
Fase III : Perubahan Bobot
Setelah semua faktor δ dihitung, bobot semua garis dimodifikasi bersamaan. Perubahan bobot satu garis didasarkan atas faktor δ neuron di lapisan atasnya. Sebagai contoh, perubahan bobot garis yang menuju lapisan keluaran didasarkan atas δk yang ada di unit keluaran.
Ketiga fase tersebut diulang-ulang terus hingga kondisi penghentian dipenuhi. Umumnya kondisi penghentian yang sering dipakai adalah jumlah iterasi atau kesalahan. Iterasi dihentikan jika jumlah iterasi yang dilakukan sudah melebihi jumlah maksimum iterasi yang ditetapkan atau jika kesalahan yang terjadi sudah lebih kecil dari batas toleransi yang diijinkan. Setelah pelatihan selesai dilakukan, jaringan dapat dipakai untuk pengenalan pola. Dalam hal ini hanya propagasi maju saja yang digunakan untuk menentukan keluaran jaringan. Algoritma selengkapnya disajikan pada Lampiran 1.
Berikut fungsi kinerja yang digunakan oleh backpropagation, yaitu Mean
Square Error (MSE) yang didapatkan dari nilai rata-rata kuadrat error yang
terjadi antara output jaringan (yk) dan target (tk).
2.9 Logika Fuzzy
Teori himpunan fuzzy merupakan perluasan dari himpunan klasik (crisp). Pada teori himpunan crisp keberadaan suatu elemen pada suatu himpunan A hanya akan mempunyai dua kemungkinan nilai keanggotaan atau derajat keanggotaan, yaitu menjadi anggota A (𝜇𝜇𝐴𝐴(𝑥𝑥) = 1) atau tidak menjadi anggota A (𝜇𝜇𝐴𝐴(𝑥𝑥) = 0) (Chak et al. 1998), Sehingga akan mengakibatkan perbedaan kategori yang cukup bermakna dengan himpunan klasik. Himpunan crisp diilustrasikan menggunakan Gambar 11. Pada teori himpunan fuzzy yang diperkenalkan oleh Lotfi A. Zadeh keberadaan suatu elemen pada suatu himpunan A akan mempunyai derajat keanggotaan antara 0 dan 1. Hal ini banyak digunakan untuk membuat suatu klasifikasi sebagai solusi terhadap suatu pola yang berada diantara dua kelas yang tidak dapat diselesaikan oleh klasifikasi klasik.
Gambar 11 Himpunan klasik.
Pada himpunan fuzzy seseorang akan dapat masuk dalam 2 himpunan yang berbeda. Seseorang dengan umur 40 tahun masuk dalam himpunan usia muda dengan derajat keanggotaan 0.25 dan sekaligus masuk dalam himpunan usia parobaya dengan derajat keanggotaan 0.5, hal ini diilustrasikan pada Gambar 12.
Beberapa hal yang berhubungan dengan sistem fuzzy adalah variabel fuzzy, himpunan fuzzy, semesta pembicaraan dan domain. Variabel fuzzy merupakan variabel yang akan dibahas di dalam fuzzy, misalnya umur, permintaan, temperatur dan sebagainya. Himpunan fuzzy merupakan suatu grup yang mewakili kondisi tertentu dalam variabel fuzzy, misalnya variabel umur dibagi menjadi muda, parobaya dan tua. Semesta pembicaraan adalah seluruh nilai yang diperbolehkan untuk dioperasikan dalam suatu variabel fuzzy, misalnya semesta pembicaraan variabel umur adalah 0 sampai 100. Domain adalah keseluruhan nilai yang diijinkan dalam semesta pembicaraan dan boleh dioperasikan dalam himpunan fuzzy, misalnya domain umur muda 20-45, domain umur parobaya 25-65 dan domain umur tua 45-70.
2.9.1 Fungsi Keanggotaan (membership function)
Fungsi keanggotaan (membership function) adalah suatu kurva yang menunjukkan pemetaan titik-titik input data ke dalam nilai keanggotaan yang memiliki interval antara 0 - 1. Ada beberapa fungsi keanggotaan yang digunakan untuk mendapatkan fungsi keanggotaan antara lain representasi kurva sigmoid,
triangular dan trapezoid.
Metode popular untuk menentukan fuzzy set adalah menggunakan fungsi keanggotaan bell (lonceng), karena kehalusan dan keringkasannya (mathwork 2011).
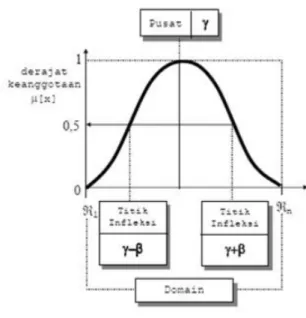
Fungsi keanggotaan : 𝑠𝑠(𝑥𝑥; 𝛾𝛾, 𝛽𝛽) = 1
1+�𝑥𝑥−𝛾𝛾𝛽𝛽 �2 ... (32) Terdapat tiga kurva berbentuk bell (lonceng) yaitu PI, beta dan Gauss, dengan perbedaan terletak pada gradien-nya. Kurva beta sama halnya dengan PI hanya saja kurva beta lebih rapat. Kurva beta didefinisikan dengan dua parameter, yaitu nilai pada domain yang menunjukkan pusat kurva (γ) dan setengah lebar kurva (β), seperti terlihat pada Gambar 13.
Gambar 13 Karakteristik fungsional kurva beta (Cox, 1994).
2.10 Fuzzy Neural Network (FNN)
Fuzzy neural network (FNN) merupakan suatu model yang dilatih
menggunakan jaringan syaraf, namun struktur jaringannya diinterpretasikan dengan sekelompok aturan fuzzy (Kasabow 2002). Pada FNN parameter-parameter yang dimiliki oleh neuron dan bobot-bobot penghubung yang biasanya disajikan secara numeris, dapat diganti menggunakan parameter fuzzy. Adakalanya input dan bobot bernilai crisp, sedangkan output-nya bernilai fuzzy. Terdapat tujuh tipe FNN dengan variasi jenis nilai bobot, input dan output-nya (Mashinchi & Shamsuddin, 2009), seperti dalam Tabel 2.
Tabel 2 Tipe-tipe Fuzzy Neural Network (FNN)
Type weights inputs outputs
Case 0 of ANNs : crisp value crisp value crisp value Case 1 of FNNs : crisp value fuzzy crisp value Case 2 of FNNs : crisp value fuzzy fuzzy Case 3 of FNNs : fuzzy crisp value fuzzy
Case 4 of FNNs : fuzzy fuzzy fuzzy
Case 5 of FNNs : crisp value crisp value fuzzy Case 6 of FNNs : fuzzy crisp value crisp value
Case 7 of FNNs : fuzzy fuzzy crisp value
Pada klasifikasi klasik menggunakan jaringan backpropagation, jumlah
neuron pada lapisan output sama dengan jumlah kelas. Output neuron akan
konsep winner take all. Namun adakalanya, suatu pola berada pada batas kelas yang tumpang tindih, sehingga berada diantara 2 kelas. Apabila hal ini terjadi, maka tidak akan bisa diselesaikan menggunakan klasifikasi klasik (Pal & Mitra, 1992).
Pal dan Mitra (1992) memperkenalkan klasifikasi pola secara fuzzy menggunakan algoritma pembelajaran backpropagation. Konsep data dari model ini adalah menggunakan derajat keanggotaan pada neuron output sebagai target pembelajaran. Penghitungan derajat keanggotaan diawali dengan penghitungan jarak terbobot pola terhadap target output. Berdasar jarak terbobot tersebut selanjutnya dihitung derajat keanggotaan.
Penghitungan jarak terbobot terhadap sekelompok pola xk = {x1, x2, …, xn} yang terdiri dari p kelas akan menghasilkan sejumlah p neuron pada lapisan
output. Jarak terbobot dengan nilai terkecil pada tiap pola menunjukkan kelas
target. Jarak terbobot pola pelatihan ke-k dari xk terhadap kelas target ke-k, dihitung sebagai berikut (Sarkar et al. 1998) :
𝑧𝑧
𝑗𝑗𝑗𝑗= �∑
�
𝑥𝑥𝑗𝑗𝑗𝑗𝑣𝑣−𝑚𝑚𝑗𝑗𝑗𝑗 𝑗𝑗𝑗𝑗�
2 𝑛𝑛𝑗𝑗=1
; 𝑗𝑗 = 1, … , 𝑝𝑝
... ... (33)Dengan mk dan vk adalah mean dan deviasi standar dari kelas ke-k, xij adalah nilai komponen ke-j dari pola ke-i.
Derajat keanggotaan pola ke-i pada kelas ck dapat dihitung sebagai (Sarkar, 1998) :
𝜇𝜇
𝑗𝑗(𝑥𝑥
𝑗𝑗) =
1 1+�𝑧𝑧𝑗𝑗𝑗𝑗𝑓𝑓𝑑𝑑�
𝑓𝑓𝐸𝐸
; 𝑗𝑗 = 1, … , 𝑝𝑝
... (34)Dengan fd dan fe adalah konstanta yang akan mengendalikan tingkat kekaburan pada himpunan keanggotaan kelas tersebut. Dari sini didapatkan p vector derajat keanggotaan �𝜇𝜇1(𝑥𝑥1), 𝜇𝜇2(𝑥𝑥2), … , 𝜇𝜇𝑝𝑝�𝑥𝑥𝑝𝑝��. Pada kasus paling fuzzy, akan digunakan operator INT (intensified) (Sarkar et al. 1998) :
𝜇𝜇𝜂𝜂𝐼𝐼𝑇𝑇𝑥𝑥𝑗𝑗 = �2[𝜇𝜇𝑗𝑗𝑥𝑥𝑗𝑗]
2; 0 ≤ 𝜇𝜇
𝑙𝑙(𝑥𝑥𝑗𝑗) ≤ 0,5 1 − 2[1 − 𝜇𝜇𝑗𝑗(𝑥𝑥𝑗𝑗)]2; 0,5 ≤ 𝜇𝜇𝑗𝑗(𝑥𝑥𝑗𝑗) ≤ 1
sehingga pola input ke-i, xi akan memiliki target output ke-k (Sarkar et al. 1998) : 𝑑𝑑𝑗𝑗 = �𝜇𝜇𝜇𝜇𝜂𝜂𝐼𝐼𝑇𝑇(𝑗𝑗)(𝑥𝑥𝑗𝑗); 𝑢𝑢𝑛𝑛𝐾𝐾𝑢𝑢𝑗𝑗 𝑗𝑗𝑗𝑗𝑠𝑠𝑢𝑢𝑠𝑠 𝑝𝑝𝑗𝑗𝑙𝑙𝑗𝑗𝑛𝑛𝑔𝑔 𝑓𝑓𝑢𝑢𝑧𝑧𝑧𝑧𝑦𝑦
𝑗𝑗𝑥𝑥𝑗𝑗 ; 𝑦𝑦𝑗𝑗𝑛𝑛𝑔𝑔 𝑙𝑙𝑗𝑗𝑗𝑗𝑛𝑛𝑛𝑛𝑦𝑦𝑗𝑗
dengan 0 ≤ 𝑑𝑑𝑗𝑗 ≤ 1 untuk setiap k. Dalam tahap ini dihasilkan derajat keanggotaan dari tiap pola yang ada terhadap kelas target, dimana nilai yang paling tinggi di setiap pola menunjukkan kelas target. Selanjutnya pola input dan
output yang terbentuk akan digunakan sebagai data training menggunakan