Penerapan Metode K-Means Dalam Pengolompokan Jumlah
Wisatawan Asing Di Indonesia
Surya Darma
1, Sarjon Defit
2, Dedy Hartama
1, Wendi Robiansyah
1, Fahm
Firzada
1,1,3
Universitas Putra Indonesia (YPTK) Padang
4STIKOM Tunas Bangsa Pematangsiantar
1suryadarmaatb@gmail.com,
2wendirobiansyah@gmail.com ,
3fahmi.firzada@gmail.com ,
4dedyhartama@amiktunasbangsa.co.id
,
Abstract
Sebagai negara yang sedang berkembang, Indonesia saat ini tengah aktif
mengembangkan diri dalam segala bidang. Pengembangan kegiatan di setiap
sektor tentunya membutuhkan dana yang tidak sedikit. Penelitian ini memfokuskan
bagaimana jumlah kedatangan wisatawan asing di indonesia setiap bulannya.
Kedatangan Wisatawan asing sangat berperan penting dapat peningkatan
perekonomian suatu negara, dengan banyaknya wisata asing yang berkunjung
kesuatu negara, maka negara tersebut dituntut untuk lebih meningkatkan kualitas
dari tempat-tempat wisata yang ada dinegara tersebut. Hasil penelitian ini
diperoleh bahwa bulan Juni tahun 2017-2019 merupakan bulan yang paling
banyak dikunjungin wisatawan asing di indonesia dan bulan lainnya merupakan
bulan yang rendah dikunjungi wisatawan asing di indonesia.
Keywords: Wisatawan Asing, Data Mining, Metode K-Means.
1
. Pendahuluan
Penggunaan perangkat teknologi informasi telah menjadi menjadi darah daging bagi setiap kegiatan masyarakat saat ini. Disatu sisi kebutuhan berwisata yang semakin tumbuh dan kurang diiringi dengan penyediaan informasi yang mendukung minat calon wisatawan. Wisatawan asing (foreign tourist) atau wisatawan mancanegara adalah orang asing yang melakukan perjalanan wisata, yang datang memasuki suatu negara lain yang bukan merupakan negara dimana orang tersebut tinggal. Wisatawan domestik adalah wisatawan dalam negeri yaitu seseorang warga negara pada suatu negara yang melakukan perjalanan wisata dalam batas wilayah negarannya sendiri tanpa melewati perbatasan negaranya, jadi disini tidak terdapat unsur asing baik kebangsaan maupun uang yang dibelanjakan serta dokumen perjalanan yang dimilikinya. Jumlah wisatawan yang berkunjung ke suatu daerah sangat erat kaitannya terhadap pendapatan daerah itu sendiri[1]. Sekarang ini Indonesia tengah meningkatkan jumlah kunjungan wisata. Banyak kebijakan pemerintah yang dilakukan guna menarik wisatawankhususnya wisatawan asing ke Indonesia. Salah satunya dengan membebaskan visa berkunjung. Usaha tersebut sepertinya menuai hasil, di akhir tahun 2017, dalam scope global, Indonesia telah naik peringkat menjadi nomor 42 dunia dalam kunjungan wisata terbanyak. Peringkat ini langsung diungkapkan oleh menteri Pariwisata Arief Yahya dalam sebuah kesempatan[2].
Dalam melakukan penelitian dalam pengelompokan jumlah wisman di indonesia tahun 2017-2019, penulis menggunakan metode K-Means Clustering untuk melihat junlah wisatawan tertinggi dan terendah di indonesia berdasarkan bulan. Data yang digunakan diperoleh dari Badan Pusat Statistik Indonesia melalui Website yang bersumber dari https://www.bps.go.id. Dalam mengelompokkan jumlah
sebelumnya yaitu pada studi kasus : K-Means Untuk Menentukan Calon Penerima Beasiswa Bidik Misi Di Polbeng dengan kesimpulan algoritma K-Means mampu mengelompokan calon penerima beasiswa bidik misi ke dalam 4 cluster, yang mana cluster 0 berarti memberikan rekomendasi dengan pertimbangan, cluster 1 memberikan rekomendasi sangat layak, cluster 2 memberikan rekomendasi layak dan cluster 3 memberikan rekomendasi kurang layak. Dari hasil pengujian dihasilan sebanyak 17 orang direkomendasi dengan pertimbangan, 24 orang direkomendasikan sangat layak, 32 orang direkomendasikan layak dan 56 orang direkomendasikan kurang layak. Dan penelitian sebelumnya yaitu pada studi kasus : Persepsi Wisatawan Asing Terhadap Wisata Indonesia dengan kesimpulan persepsi wisatawan asing terhadap wisata di Indonesia masih tertuju pada Bali sebagai arus utama wisata di Indonesia, Dari hasil penelitian
ditemukan bahwa ketertarikan wisatawan
asing ke Indonesia dikelompokan menjadi 3, yakni wisata alam (layaknya pantai dan gunung), wisata budaya (tradisi, ritual dan sebagainya), dan wisata spiritual/keagamaan dan kebangsaan atau keberagaman, Indonesia dipersepsikan sebagai mempunyai wisata alam yang indah, masyarakat yang ramah dan biaya hidup yang murah. Dengan diterapkannya metode K-Means, penelitian ini diharapkan dapat memberikan hasil yang dapat membantu pemerintah dalam dalam meningkatkan jumlah wisman di indonesia berdasarkan bulan Penelitian ini juga diharapkan dapat membantu peneliti selanjutnya terkait penggunaan metode K-Means.
2. Metodologi Penelitian
Penelitian ini menggunakan data tahun 2017-2019 yang bersumber dari https://www.bps.go.id. Proses pengelompokan menggunakan metode datamining dengan metode K-Means. Pada proses metode K-Means akan digunakan 2 cluster yaitu tinggi(C1) dan rendah(C2). Berikut adalah beberapa penjelasan dari metode K-Means.
2.1. Data Mining
Data Mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data mining adalah proses yang menggunakan teknik statistic, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar[3]. Pemilihan tugas Data Mining merupakan pemilihan goal dari proses KDD misalnya karakterisasi, klasifikasi, regresi, clustering, asosiasi, dan lain-lain. Pemilihan tugas Data Mining merupakan pemilihan goal dari proses KDD misalnya karakterisasi, klasifikasi, regresi, clustering, asosiasi,dan lain-lain. Pemilihan teknik, metode ataualgoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan[4].
2.2. Metode K-Means
“Metode K-Means adalah metode yang termasuk dalam algoritma clustering berbasis jarak yang membagi data ke dalam sejumlah cluster dan algoritma ini hanya bekerja pada atribut numeric[5]. K-Means adalah suatu metode penganalisaan data atau metode Data Mining yang melakukan proses pemodelan tanpa supervisi (unsupervised) dan merupakan salah satu metode yang melakukan pengelompokan data dengan sistem partisi [6].
Berikut adalah Alur penyelesaian dari metode K-Means::
1. Tentukan berapa jumlah cluster yang ingin ditetapkan pusat cluster k.
2. Menggunakan jarak euclidean dan kemudian menghitung setiap data ke pusat cluster.
3. Kategorikan data ke dalam cluster dengan jarak yang terpendek dengan menggunakan persamaan
∑ √∑
(2)00
4. Menghitung pusat cluster dengan menggunakan persamaan
∑
(3)
Dengan : xij € Kluster ke – k p = banyak member cluster ke - k
Silahkan ulangi langkah dua sampai empat sehingga sudah tidak ada lagi data yang berpindah ke cluster yang lain.
2.3 RapidMiner
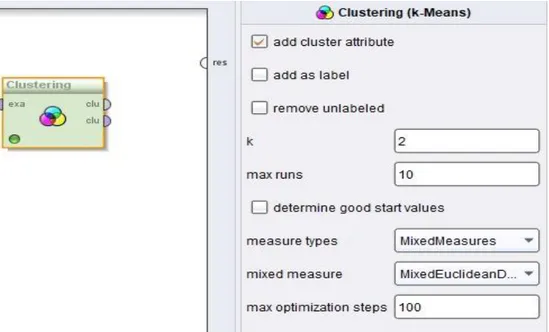
Menurut [7] RapidMiner merupakan perangkat lunak yang bersifat terbuka (Open Source), sebuah salah satu solusi untuk melakukan analisis terhadap Data Mining. RapidMiner aplikasi yang berdiri sendiri untuk analisis data dan sebagai mesin Data Mining untuk integrasi kepada penelian atau suatu produk. Hal ini digunakan untuk bisnis dan komersial, juga untuk penelitian, pendidikan, pelatihan, rapid prototyping, dan pengembangan aplikasi serta mendukung semua langkah dalam proses pembelajran mesin termasuk persiapan data, hasil visualisasi, validasi model dan optimasi. Berikut Gambar 1 menjelaskan bentuk Operator K-Means pada RapidMiner dan fungsinya :
Gambar 1. Tampilan Operator K-Means pada RapidMiner
Berikut penjelasan parameter dari fungsi K-Means pada RapidMiner :
1) Add Cluster Atribute yaitu jika diaktifkan atribute baru dengan peran cluster dihasilkan secara langsung dari operator K-Means, Jika tidak operator ini tidak menambahkan atribute cluster
2) K yaitu menentukan junlah klaster yang akan dibentuk. Penelitian ini menggunakan 2 cluster yaitu tinggi dan rendah
3) Max Runs yaitu menentukan jumlah maksimum berjalan K–Means dengan inisialisasi acak yang dilakukan
4) Measure Types yaitu untuk memilih jenis ukuran yang akan digunakan. Penelitian ini menggunakan Measure Types mix yaitu ukuran yang dilakukan dengan tindakan campuran.
3. Hasil dan Pembahasan
Penelitian ini menggunakan satu data yaitu data Wisman di indonesia tahun 2017-2019. Berikut adalah data penelitian yang digunakan.
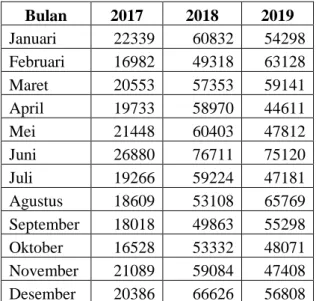
Tabel 1. Data Wisman Di Indonesia
Bulan 2017 2018 2019 Januari 22339 60832 54298 Februari 16982 49318 63128 Maret 20553 57353 59141 April 19733 58970 44611 Mei 21448 60403 47812 Juni 26880 76711 75120 Juli 19266 59224 47181 Agustus 18609 53108 65769 September 18018 49863 55298 Oktober 16528 53332 48071 November 21089 59084 47408 Desember 20386 66626 56808
Selanjutnya masuk dalam tahap perhitungan menggunakan metode K-Means: 1. Penetuan Pusat Cluster Awal
Penentuan titik cluster ini dilakukan dengan mengambil nilai terbesar (maksimum) untuk (C1), nilai terkecil untuk (C2) sebagai berikut:
Tabel 2. Cluster Awal Data Pengangguran
Cluster 2017 2018 2019 Tinggi 26880 76711 75120 Rendah 16528 53332 48071 2. Perhitungan Jarak Cluster
Untuk menghitung jarak antara data dengan pusat cluster menggunakan persamaan (1)(2) berikut adalah proses menghitung jarak antara data dengan pusat cluster: Iterasi 1: D(1)=√ = 26577 D(2)=√ = 11349
Dan seterusnya. Perhitungan dilakukan hingga bulan terakhir baik untuk cluster tinggi maupun rendah. Berikut adalah hasil dari perhitungan jarak cluster untuk iterasi 1.
Tabel 3. Hasil Iterasi 1 Data Wisman
Bulan 2017 2018 2019 C1 C2 Jarak Terpendek C1 C2
Januari 22339 60832 54298 26577 11349 11349 1 Februari 16982 49318 63128 31498 15589 15589 1 Maret 20553 57353 59141 25886 12446 12446 1 April 19733 58970 44611 36009 7351 7351 1 Mei 21448 60403 47812 32267 8618 8618 1
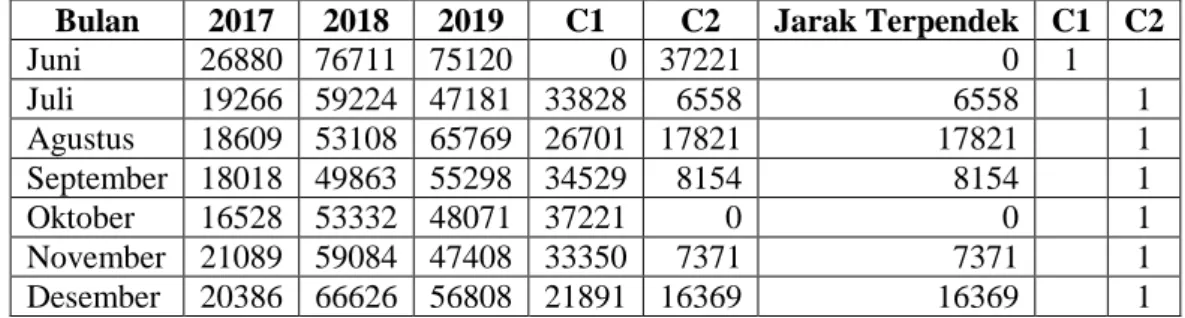
Bulan 2017 2018 2019 C1 C2 Jarak Terpendek C1 C2 Juni 26880 76711 75120 0 37221 0 1 Juli 19266 59224 47181 33828 6558 6558 1 Agustus 18609 53108 65769 26701 17821 17821 1 September 18018 49863 55298 34529 8154 8154 1 Oktober 16528 53332 48071 37221 0 0 1 November 21089 59084 47408 33350 7371 7371 1 Desember 20386 66626 56808 21891 16369 16369 1
Berdasarkan hasil pada tabel di atas maka didapatkan pengelompokkan sebagai berikut :
C1 = Bulan Juni
C2 = Bulan Januari, Februari, Maret, April, Mei, Juli, Agustus, September, Oktober, November, Desember.
3. Penetuan pusat cluster baru
Setelah didapatkan hasil dari setiap cluster kemudian pusat cluster baru dihitung berdasarkan data member tiap – tiap cluster yang sudah didapatkan menggunakan persamaan (2) yang sesuai dengan pusat member cluster sebagai berikut :
Tabel 4. Pusat Cluster Iterasi 2
Cluster 2017 2018 9 Tinggi 26880 76711 75120 Rendah 19541 57101 53593
Dan seterusnya. Perhitungan dilakukan hingga bulan terakhir baik untuk cluster tinggi maupun rendah. Berikut adalah hasil dari perhitungan jarak cluster untuk iterasi 2
Tabel 5. Hasil Iterasi 1 Data Wisman
Bulan 2017 2018 2019 C1 C2 Jarak Terpendek C1 C2
Januari 22339 60832 54298 26577 4716 4716 1 Februari 16982 49318 63128 31498 12571 12571 1 Maret 20553 57353 59141 25886 5645 5645 1 April 19733 58970 44611 36009 9177 9177 1 Mei 21448 60403 47812 32267 6925 6925 1 Juni 26880 76711 75120 0 30030 0 1 Juli 19266 59224 47181 33828 6760 6760 1 Agustus 18609 53108 65769 26701 12848 12848 1 September 18018 49863 55298 34529 7591 7591 1 Oktober 16528 53332 48071 37221 7333 7333 1 November 21089 59084 47408 33350 6677 6677 1 Desember 20386 66626 56808 21891 10088 10088 1
Iterasi selanjutnya dilakukan dengan cara yang sama dengan iterasi 1 dan begitu juga untuk pengelompokan data wisman. Dari proses pengelompokan data wisman dengan ke-2, diperoleh hasil pengelompokan sebagai berikut.
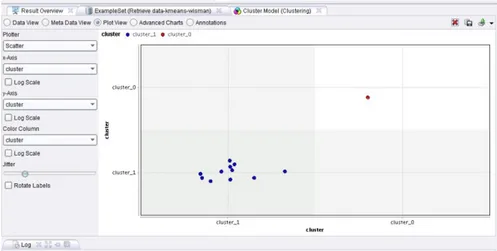
1. Hasil Pengelompokan data wisman perbulan pada tahun2017-2019, terdapat 1 bulan cluster tertinggi dan terpadat 11 bulan cluster terendah
Gambar 2. Hasil Cluster Menggunakan RapidMiner Data Wisman
Cluster tinggi : Bulan Juni.
Cluster rendah : Bulan Januari, Februari, Maret, April, Mei, Juli, Agustus, September, Oktober, November, Desember.
2. Hasil Nilai centroid akhir dari RapidMiner sebagai berikut:
Gambar 3. Hasil Centroid Akhir
Berdasarkan hasil diatas, dapat dilihat bahwa bulan tertinggi adalah bulan Juni dengan nilai centroid 26880 untuk tahun 2017, 276711 untuk tahun 2018, 75120 untuk tahun 20179.
4. Kesimpulan
Berdasarkan penjelasan diatas, dapat disimpulkan bahwa metode datamining dengan metode K-Means dapat diterapkan dalam pengelompokan jumlah wisatawan asing di indonesia dengan hasil bulan Juni tahun 2017-2019 merupakan bulan yang paling banyak dikunjungin wisatawan asing di indonesia dan bulan lainnya merupakan bulan yang rendah dikunjungi wisatawan asing di indonesia. Dari hasil yang diperoleh khususnya Dinas Pariwisata Asing di Indonesia dapat meningkatkan kualitas tempat wisata yang ada di Indonesia terutama pada bulan libur internasional yaitu pada bulan januari dan desember.
Daftar Pustaka
[1] I. G. N. O. Amerta and I. G. S. Budhiasa, “PENGARUH KUNJUNGAN WISATAWAN MANCANEGARA, WISATAWAN DOMESTIK, JUMLAH HOTEL DAN AKOMODASI LAINNYA TERHADAP PENDAPATAN ASLI DAERAH (PAD) DI KABUPATEN BADUNG TAHUN 2001 – 2012,” pp. 56–69, 2014.
[2] O. : Zein, M. Muktaf, and E. R. Zulfiana, “Persepsi Wisatawan Asing Terhadap Wisata Indonesia,” J. Cakrawala ISSN, vol. 1693, p. 6248.
[3] L. Maulida, “Penerapan Datamining Dalam Mengelompokkan Kunjungan Wisatawan Ke Objek Wisata Unggulan Di Prov. Dki Jakarta Dengan K-Means,” JISKA (Jurnal Inform. Sunan Kalijaga), vol. 2, no. 3, p. 167, 2018, doi: 10.14421/jiska.2018.23-06.
[4] B. M. Metisen and H. L. Sari, “Analisis clustering menggunakan metode K-Means dalam pengelompokkan penjualan produk pada Swalayan Fadhila,” J. Media Infotama, vol. 11, no. 2, pp. 110–118, 2015.
[5] W. Dhuhita, “Clustering Menggunakan Metode K-Mean Untuk Menentukan Status Gizi Balita,” J. Inform. Darmajaya, vol. 15, no. 2, pp. 160–174, 2015, doi: 10.30873/ji.v15i2.598.
[6] Iskandar, P. Tarigan, and saidi ramadan Siregar, “Penerapan Data Mining Dalam Surat Jalan Transportasi Mobil Angkutan Menggunakan Metode Cluestering,” J. Pelita Inform., vol. 17, pp. 460–464, 2018.
[7] P. P. P. A. N. . F. I. R. . Zer, D. Hartama, and S. R. Andani, “Analisa Faktor Dominan Mahasiswa Kesulitan Memahami Bahasa Pemrograman Menggunakan Metode C4.5,” Pros. Semin. Nas. Ris. Inf. Sci., vol. 1, no. September, p. 492, 2019, doi: 10.30645/senaris.v1i0.55.