6 BAB 2
KAJIAN PUSTAKA
2.1 Citra dan Pemrosesan Citra 2.1.1 Definisi Citra dan Citra Dijital
Citra dalam penelitian ini mengacu kepada citra dijital. Sebuah citra didefinisikan sebagai matrix berukuran N baris dan M kolom yang terdiri dari sekumpulan nilai dijital yang disebut piksel. Piksel merupakan elemen terkecil dari suatu gambar. Nilai pada matrix merepresentasikan intensitas atau tingkat kecerahan suatu piksel. Dengan kata lain, intensitas suatu warna pada citra merupakan fungsi posisi f(x,y) dari suatu citra.
Citra sebagai keluaran dari suatu sistem perekaman data dapat bersifat 1. Optik berupa foto,
2. Analog berupa sinyal video seperti gambar pada monitor televisi, 3. Digital yang dapat langsung disimpan pada suatu pita magnetik.
Berdasar gerak atau tidaknya citra, maka citra dapat dikelompokkan menjadi dua, yaitu:
1. Citra diam (still images).
Citra diam adalah citra tunggal yang tidak bergerak. Untuk selanjutnya, citra yang dimaksud dalam penelitian ini adalah citra diam.
2. Citra bergerak (moving images)
Citra bergerak adalah rangkaian citra diam yang ditampilkan secara beruntun (sekuensial) sehinggal member kesan pada mata kita sebagai gambar yang bergerak. Setiap citra dalam rangkaian itu disebut frame.
7 2.1.2 Pengolahan Citra
Pengolahan citra atau image processing merujuk kepada pengolahan citra dengan menggunakan komputer. Contoh operasi pemrosesan citra : mengubah ukuran citra, menghitung histogram dari suatu citra, mengubah tingkat kecerahan, komposisi (menggabungkan dua citra atau lebih), dll.
Operasi-operasi yang dilakukan di dalam pengolahan citra banyak ragamnya. Namun, secara umum, operasi pengolahan citra dapat diklasifikasikan dalam beberapa jenis sebagai berikut:
1. Perbaikan kualitas citra (image enhancement)
Jenis operasi ini bertujuan untuk memperbaiki kualitas citra dengan cara memanipulasi parameter-parameter citra. Dengan operasi ini, ciri-ciri khusus yang terdapat di dalam citra lebih ditonjolkan. Contoh-contoh operasi perbaikan citra:
a) perbaikan kontras gelap/terang
b) Perbaikan tepian objek (edge enhancement) c) Penajaman (sharpening)
d) Pemberian warna semu (pseudocoloring) e) Penapisan derau (noise filtering)
2. Pemugaran Citra (Image Restoration)
Operasi ini bertujuan menghilangkan/meminimumkan cacat pada citra. Tujuan pemugaran citra hampir sama dengan operasi perbaikan citra. Bedanya, pada pemugaran citra penyebab degradasi gambar diketahui. Contoh-contoh operasi pemugaran citra:
8 b) Penghilangan derau (noise) 3. Pemampatan Citra (Image Compression)
Jenis operasi ini dilakukan agar citra dapat direpresentasikan dalam bentuk yang lebih kompak sehingga memerlukan memori yang lebih sedikit. Hal penting yang harus diperhatikan dalam pemampatan adalah citra yang telah dimampatkan harus tetap mempunyai kualitas gambar yang bagus. Contoh metode pemampatan citra adalah metode JPEG.
4. Segmentasi Citra (Image Segmentation)
Jenis operasi ini bertujuan memecah suatu citra ke dalam beberapa segmen dengan kriteria tertentu. Jenis operasi ini berkaitan erat dengan pengenalan pola. 5. Analisis Citra (Image Analysis)
Jenis operasi ini bertujuan menghitung besaran kuantitatif dari suatu citra untuk menghasilkan deskripsinya. Teknik analisis citra mengekstraksi ciri-ciri tertentu dari suatu citra yang membantuk dalam proses identifikasi objek. Proses segmentasi kadangkala diperlukan untuk melokalisasi objek yang diinginkan dari sekelilingnya. Contoh – contoh operasi analisis citra adalah :
a) Pendeteksian tepi objek (edge detection) b) Ekstraksi batas (boundary)
c) Representasi daerah (region) 6. Rekonstruksi Citra (Image Reconstruction)
Jenis operasi ini bertujuan untuk membentuk ulang objek dari beberapa citra hasil proyeksi. Operasi rekonstruksi citra banyak digunakan dalam bidang medis. Misalnya beberapa foto rontgen dengan sinar X digunakan untuk membentuk ulang gambar organ tubuh.
9 2.2 Fitur dan Ekstraksi Fitur
Ketika suatu input data berukuran terlalu besar untuk diproses dan diperkirakan memiliki banyak data tetapi sedikit informasi, maka terhadap input tersebut perlu ditransformasi menjadi suatu sekumpulan fitur yang direpresentasikan dengan vektor, yang disebut fitur vektor. Proses transformasi diatas disebut ekstraksi fitur. Suatu fitur merupakan ciri yang diamati dari suatu objek dan juga merupakan suatu deskriptor numerik yang dapat menangkap karekteristik visual tertentu. Ekstraksi fitur memiliki dua tujuan, yaitu membuang aspek yang tidak relevan dari suatu objek sehingga representasi informasi hanya mengandung data yang perlu dan penting dan mentransformasi data menjadi sebuah representasi yang membawa informasi lebih eksplisit.
Fitur dapat diekstrak dari suatu citra secara keseluruhan yang mendeskripsikan karakteristik visual secara global, ataupun dari bagian tertentu suatu citra yang mendeskripsikan karakteriksik secara lokal. Secara umum, representasi suatu citra dalam fitur membutuhkan ruang penyimpanan yang jauh lebih kecil daripada menyimpan citra itu sendiri.
2.3 Basis Data Multimedia
Kemajuan dalam komputer modern dan telekomunikasi mengakibatkan banyaknya data multimedia dalam berbagai bidang seperti kedokteran, pendidikan, hiburan, dll. Hal ini mirip dengan peningkatan data alfanumerik pada awal era komputerisasi, yang menyebabkan kepada pengembangan sistem manajemen basis data (DBMS / Database Manajemen Systems). Sistem manajemen basis data tradisional didesain untuk mengorganisasi data alfanumerik ke dalam kumpulan data yang saling berhubungan, sehingga informasi dapat diretriv dan disimpan dengan cara yang baik sekali dan efisien.
10
Tetapi teknologi ini tidak sesuai untuk manajemen informasi multimedia. Perbedaan format dan tipe data, ukuran objek yang besar, dan kesulitan untuk mengekstrak arti semantik secara otomatis merupakan hal yang baru bagi teknik manajemen basis data tradisional. Untuk dapat menggunakan informasi multimedia yang luas ini dengan efektif, metode yang efisien untuk penyimpanan, penjelajahan, pengindeksan dan retrival harus dikembangkan. Tipe data multimedia yang berbeda mungkin membutuhkan metodologi pengindeksan dan retrival yang spesifik.
Kemajuan dalam bidang komputer, komunikasi, dan teknologi penyimpanan, disertai juga dengan munculnya penggunaan multimedia skala besar, telah membuat desain dan pengembangan sistem informasi multimedia sebagai salah satu yang paling menantang dan penting dalam arah riset dan pengembangan dalam ilmu komputer. Hasil dari pembangunan infrastruktur multimedia itu akan memungkinkan banyak aplikasi bernilai milyaran dolar untuk diimplementasikan. Contohnya adalah sistem informasi medis, penjualan elektronik, perpustakaan digital (seperi penyimpanan data multimedia untuk pelatihan, pendidikan, penyiaran, dan hiburan), basis data dengan tujuan khusus (seperti basis data wajah atau sidikjari untuk keamanan), dan sistem informasi geografi yang menyimpan citra satelit, peta, dan lain sebagainya.
Sebuah komponen penting dari infrastuktur multimedia adalah sistem manajemen basis data. Sistem seperti ini mendukung mekanisme untuk mengekstrak dan merepresentasikan konten dari objek multimedia, menyediakan penyimpanan konten yang efisien dalam basis data, mendukung kueri berbasis konten terhadap objek multimedia, dan menyediakan integrasi tanpa hambatan antara multimedia objek dengan informasi tradisional yang telah tersimpan dalam basis data yang ada. Sebuah sistem
11
basis data multimedia terdiri dari beberapa komponen, yang menyediakan fungsionalitas sebagai berikut:
Representasi objek multimedia (Multimedia Object Representation) Teknik atau model untuk untuk merepresentasikan struktur dan konten dari objek multimedia dengan ringkas di dalam basis data.
Ekstraksi konten (Content Extraction)
Mekanisme untuk secara otomatis atau semiotomasi mengekstrak fitur yang berarti yang dapat menangkap konten dari multimedia objek dan dapat diindeks untuk mendukung proses retrival.
Retrival informasi multimedia (Multimedia Information Retrieval) Teknik untuk mencocokan dan meretriv objek multimedia berdasarkan kemiripan dari representasinya.
Manajemen Basis Data Multimedia (Multimedia Database Management)
Perluasan dari teknologi manajemen data untuk pengindeksan dan pemrosesan kueri agar secara efektif mendukung retrival berbasis konten yang efisien dalam manajemen basis data.
2.4 Retrival Berbasis Konten (Content Based Retrieval)
Citra memiliki informasi yang tidak terstruktur yang membuat proses pencarian menjadi sangat sulit dilakukan. Sebuah kueri yang umum dilakukan dalam basis data finansial akan meminta menampilkan semua cek yang ditulis dari suatu rekening tertentu dan pada rentang waktu tertentu. Sebuah kueri yang umum pada basis data dari citra adalah meminta semua citra yang di dalamnya terdapat mobil berwarna merah. Kueri
12
pertama yaitu pencarian dari basis data finansial merupakan hal yang mudah karena semua transaksi pada rekord basis data mengandung semua informasi yang dibutuhkan (tanggal, tipe, nomor rekening, jumlah, dll) dan sistem manajemen basis data dibuat untuk mengeksekusinya dengan efisien. Kueri kedua yang berupa pencarian citra merupakan suatu hal yang sangat sulit, kecuali semua citra dalam basis data telah diberi kata kunci.
Informasi tidak terstruktur yang terkandung dari suatu citra sulit untuk ditangkap secara otomatis. Teknik yang mencari cara untuk mengindeks informasi visual tidak terstruktur ini disebut retrival berbasis konten.
2.5 RCBK (Retrival Citra Berbasis Konten) / CBIR (Content Based Image Retrieval) RCBK adalah suatu sistem yang bertujuan untuk mencari citra tertentu di dalam basis data citra yang mirip dengan kueri (query) citra. Sistem ini merupakan solusi dari permasalahan pencarian citra di dalam database yang besar. Istilah ini diduga di perkenalkan oleh T.Kato pada tahun 1992 untuk mendeskripsikan percobaan dalam retrival citra secara otomatis dari basis data berdasarkan warna dan bentuk (diunduh dari http://en.wikipedia.org/wiki/Content-based_image_retrieval).
Terdapat dua pendekatan dalam retrival citra. Pertama adalah pendekatan dengan atribut teks, yaitu menggunakan representasi sekumpulan atribut yang diekstrak secara manual, dimana pencarian didasarkan pada atribut ini. Pendekatan ini memiliki keunggulan yaitu dapat menangkap abstraksi citra tingkat tinggi. Pendekatan kedua adalah dengan menggunakan ekstraksi fitur secara otomatis, pendekatan ini dilakukan untuk mengatasi keterbatasan pendekatan dengan atribut teks dimana ekstraksi harus dilakukan secara manual.
13
Penggunaan retrival citra berbasis teks dimulai pada akhir 1970-an. Pada masa itu citra diberi kata kunci dan disimpan dalam basis data tradisional. Dua masalah muncul yang membuat pemberian kata kunci secara manual menjadi tidak efektif ketika jumlah citra dalam basis data menjadi sangat besar. Pertama adalah masalah penggunaan tenaga kerja yang besar untuk melakukan pemberian kata kunci pada citra. Masalah kedua yang lebih penting adalah kesulitan menangkap persepsi dari citra hanya dengan sedikit kata kunci, hal ini merupakan kesulitan yang dikarenakan subyektifitas persepsi manusia.
Pada awal 1990-an,dikarenakan munculnya kumpulan citra dalam skala besar, RCBK diusulkan sebagai sebuah cara untuk mengatasi kesulitan kesulitan pada retrival citra berbasis teks. Dalam RCBK, citra secara otomatis diindeks melalui konten visual melalui fitur yang diekstrak, fitur yang digunakan misalnya warna, tekstur, atau bentuk.
Beberapa piranti lunak dibuat untuk mencoba menghasilkan RCBK yang efisien, misalnya QBIC (IBM), Pichunter (NEC Research Institute), VisualSEEK (Columbia University Centre for Telecommunication Research), Photobook (MIT’s Vision and Modeling Group), Chabot, Excalibur, dll. Dari piranti-piranti tersebut RCBK dengan pendekatan ekstraksi fitur otomatis semakin berkembang, studi tentang berbagai fitur dari suatu citra dipelajari lebih lanjut. Perkembangan dalam studi ini didefinisikan dalam 3 tingkatan:
1. Level 1 merupakan level primitif dimana fitur level rendah seperti warna, bentuk dan tekstur digunakan. Beberapa piranti lunak RCBK otomatis dibuat dengan menggunakan pendekatan level 1, seperti QBIC, Excalibur, dan Virage. Namun penggunaanya hanya pada area tertentu. Belum ada suatu teknik universal dalam level ini yang telah dikembangkan. Teknik
14
retrival otomatis yang dikembangkan, masih jauh dari sempurna. Level ini masih membutuhkan untuk dikembangkan lebih lanjut agar dapat digunakan secara universal.
2. Level 2 menghasilkan semantik atau arti dari suatu citra pada basis data. Salah satu hasil terbaik adalah dilakukan oleh Forsyth yang berhasil mengidentifikasi keberadaan manusia dalam suatu citra. Teknik ini diaplikasikan untuk objek lain, misalnya kuda dan pohon.
3. Level 3 berusaha melakukan retrival dengan atribut abstrak dari suatu citra. Untuk melakukan interpretasi dan analisa suatu citra secara efisien membutuhkan penalaran yang rumit. Contoh atribut abstrak dari suatu citra adalah perasaan senang, dimana akan sangat sulit bagi komputer untuk menginterpretasikan citra yang memiliki ekspresi senang.
Banyak penelitian terkait RCBK telah dilakukan, namun belum ditemukan sebuah model yang secara universal diterima. Penelitian dikonsentrasikan pada fitur level rendah seperti warna, tekstur dan bentuk. Tetapi untuk menemukan semantik dari suatu citra masih merupakan suatu hal yang sulit. Usaha dilakukan untuk menghubungkan fitur level rendah dengan semantik dari suatu citra, namun hal ini terbukti merupakan suatu hal yang sulit, dikarenakan suatu alasan sederhana, yaitu terdapat perbedaan yang sangat besar antara persepsi manusia dan persepsi komputer.
Tantangan terbesar dalam mendesain sebuah RCBK adalah bagaimana mengurangi perbedaan semantik antara apa yang diharapkan pengguna dengan yang dapat dilakukan oleh sistem. Terdapat beberapa definisi dari perbedaan semantik ini, yaitu
15
1. Perbedaan semantik mengacu kepada perbedaan antara semantik dan fitur level rendah.
2. Perbedaan semantik didefinisikan sebagai informasi yang hilang dari suatu citra, ketika suatu citra direpresentasikan sebagai fitur vektor.
3. Perbedaan semantik merupakan ketidakcocokan antara permintaan dari pengguna dan hasil yang diberikan oleh RCBK.
Perbedaan semantik adalah permasalahan menantang yang masih terbuka yang berusaha untuk dicari solusinya oleh banyak peneliti. Ada kebutuhan untuk mempelajari perbedaan semantik secara teliti untuk mengembangkan sebuah sistem RCBK yang efektif.
Fitur yang digunakan dalam RCBK dapat dikategorikan menjadi dua, yaitu fitur umum dan khusus. Fitur umum biasanya meliputi warna, tekstur dan bentuk dan fitur yang khusus digunakan pada area aplikasi yang khusus, misalnya pengenalan wajah atau sidik jari
2.5.1 Pemanfaatan RCBK
Beberapa aplikasi yang dapat mengimplementasikan sistem ini adalah:
Menyimpan dan mencari Koleksi Lukisan
Album Foto
Katalog Produk
Basis data Medis (X-ray, CT scan, MRI scan)
16 2.5.2 Tahap-tahap dalam RCBK
Kebanyakan sistem retrival (retrieval) citra, terdiri dari pendekatan dua tahap, yaitu :
1. Pengindeksan (indexing)
Untuk setiap citra dalam basis data, dilakukan pengekstrakkan fitur. Setiap citra direpresentasikan oleh vektor berdimensi n yang disebut fitur vektor (feature vector). Selanjutnya setiap fitur vektor disimpan ke dalam basis data fitur.
2. Pencarian (searching)
Untuk setiap kueri citra yang diberikan, dilakukan pengekstrakan ciri dan direpresentasikan dalam fitur vektor, selanjutnya fitur vektor dari kueri akan dibandingkan ke dalam basis data fitur untuk mencari citra atau sekumpulan citra yang paling mirip dengan kueri citra. Selanjutnya, citra – citra yang paling mirip tersebut ditampilkan kepada pengguna.
2.5.2.1 Pengindeksan
Dalam melakukan pengindeksan terhadap basis data fitur dari citra, terdapat dua macam pendekatan yang dapat dilakukan
1. Pengindeksan berdasarkan deskripsi teks (kata kunci, judul citra, dll)
Setiap citra diindeks berdasarkan kata kunci yang dapat berupa deskripsi ataupun metadata.
2. Pengindeksan berdasarkan konten dari citra (warna, tekstur, bentuk, dll) Setiap citra diindeks berdasar deksripsi numerik berupa fitur vektor yang diturunkan dari data visual.
17
Dalam implementasinya, deskripsi dari teks dapat direpresentasikan dengan tipe data string akan tetapi tidak ada tipe data yang dapat menyimpan konten dari suatu citra, oleh karena itu harus dilakukan pendekatan lain untuk merepresentasikan konten-konten tersebut. Ada 3 konten primitif yang biasa digunakan dalam melakukan pengindeksan yaitu warna, tekstur dan bentuk.
2.5.2.1.1 Warna
Warna dari sebuah citra menyampaikan banyak informasi. Pada retrival citra berbasis konten warna direpresentasikan dalam bentuk histogram warna.
2.5.2.1.2 Tekstur
Tekstur merupakan salah satu fitur citra yang penting, akan tetapi sulit untuk dideskripsikan dan persepsi tentang tekstur subjektif dalam tingkat tertentu. (Lu, p155). Tekstur memiliki kemampuan untuk membedakan antara daerah citra dengan warna yang mirip seperti langit dengan laut atau daun dengan rumput. (Dunckley, p363)
Ada 6 fitur yang dapat digunakan untuk mendeskripsikan tekstur (Lu, p155) yaitu:
- Kekasaran / coarseness: Kekasaran merupakan fitur tekstur yang paling fundamental dan bagi beberapa orang tekstur berarti kekasaran. Semakin besar jarak dari elemen sebuah citra maka citra tersebut semakin kasar.
- Kontras / contrast: Kontras diukur menggunakan 4 parameter: jarak dinamis tingkat keabuan citra, polarisasi distribusi hitam dan putih pada histogram tingkat keabuan / grey level histogram, ketajaman tepi, dan periode pola terulang.
- Directionality: directionality Merupakan property global terhadap daerah yang diberikan. Directionality mengukur bentuk elemen dan penempatannya.
18
- Kemiripan garis / line likeness: Parameter ini bersangkutan dengan bentuk dari elemen tekstur. 2 bentuk umum dari tekstur adalah bentuk garis atau bentuk gumpalan.
- Keteraturan / regularity: Fitur ini mengukur variasi dari aturan penempatan elemen. Hal ini bersangkutan dengan apakah tekstur tersebut teratur atau tidak teratur. Perbedaan bentuk elemen mengurangi keteraturan. Tekstur yang baik cenderung teratur.
- Kekesatan / roughness: Kekesatan mengukur apakah tekstur kesat atau halus. Kekesatan berhubungan dengan kekasaran dan kontras.
Representasi tektur lain yang biasa digunakan adalah:
- Dimensi fraktal / fractal dimension: Dimensi fraktal mencirikan kompleksitas geometri dari himpunan. Sebuah citra dapat dilihat sebagai himpunan 3 dimensi: 2 dimensi pertama adalah posisi piksel dan dimensi ketiga merupakan intensitas piksel. Semakin kesat / rough sebuah citra maka dimensi fraktalnya semakin besar.
- Koefisien fourier / fourier coefficients: Koefisien fourier pada sebuah citra mendeskripsikan seberapa cepat perubahan dari intensitas piksel. Koefisien tersebut kemudian digunakan untuk menunjukkan kekesatan sebuah citra. - Statistik distribusi warna / color distribution statistics: Statistik distribusi
warna seperti momen pertama, kedua dan ketiga dari distribusi warna dapat menunjukkan tekstur sebuah citra.
Metode alternatif lain dalam merepresentasikan tekstur adalah menggunakan filter gabor dan fraktal. Filter gabor merupakan salah satu dari teknik yang powerful dalam analisa citra. (Dunckley, p364).
19 2.5.2.1.3 Bentuk
Kemampuan untuk meretriv berdasarkan bentuk melibatkan memberikan bentuk dari benda deskripsi kuantitatif yang dapat digunakan untuk mencocokkan citra lain. Bentuk dari citra terdefinisikan dengan baik dan ada banyak bukti bahwa di dalam otak, objek alami pada dasarnya dikenali dengan bentuknya. Proses ini melibatkan perhitungan dari jumlah karakteristik fitur dari bentuk objek yang independen terhadap ukuran atau orientasi. Fitur ini kemudian dihitung untuk setiap objek yang teridentifikasi didalam setiap citra yang di simpan. Kemudian hasil dari kueri diperoleh dengan menghitung kumpulan fitur yang sama untuk citra kueri, kemudian meretriv citra yang disimpan tersebut yang fiturnya paling mirip dengan citra kueri.
Dua jenis fitur bentuk yang biasa digunakan adalah:
1. Fitur global / global features seperti aspek rasio, circularity dan moments invariants
2. Fitur local / local features seperti himpunan segmen batas berurutan / consecutive boundary segments.
Batas 2 dimensi dari objek 3 dimensi memungkinkan pengenalan objek. Representasi dari bentuk sangatlah sulit. Bentuk didefinisikan dengan koordinat x dan y dari titik batasnya. Transformasi kemiripan dapat mencangkup translasi, pembesaran seragam / uniform scaling dan perubahan orientasi. Jika sudut pandang kamera berubah dengan tetap fokus ke objek, bentuk dari objek akan berubah, sebagai contoh sebuah lingkaran akan berubah menjadi elips.
2.5.2.2 Pencarian
Dalam melakukan pencarian, untuk database citra dalam jumlah yang kecil dapat dilakukan pencarian linier, yaitu kueri dicocokkan dengan semua citra dalam basis data
20
satu per satu. Jumlah data yang besar akan mengakibatkan proses pencocokkan yang lambat, maka dari itu dibutuhkan metode lain untuk mempercepat proses retrival. Terdapat beberapa metode yang dapat digunakan untuk mempercepat proses retrival, seperti:
1. Reduksi dimensi dengan menggunakan Principal Components Analysis / PCA, Latent Semantic Indexing
2. Pengindeksan, antara lain dengan hashing, R-tree, dan Kd-tree. 3. Clustering
2.6 Model Warna (Color Models)
Model warna merupakan sebuah model untuk merepresentasikan nilai dari warna. Ada dua buah ruang warna yang biasanya digunakan, yaitu:
1. Model Warna RGB (Red Green Blue)
Model warna ini terdiri dari 3 komponen yang di simpan, yaitu nilai merah (red), hijau (green) dan biru (blue). Model warna ini biasa di gunakan di dalam monitor CRT, scanner, kamera digital dan kamera video.
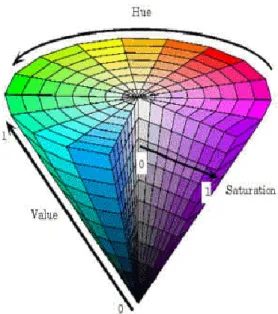
Model RGB menggunakan sistem koordinat kartesian seperti terlihat pada citra (2.1). sebuah diagonal dari (0,0,0) hitam hingga (1,1,1) putih merupakan nilai kehitaman (grayscale).
21 Konversi RGB ke HSV 𝐻 = cos−1 1 2 𝑅 − 𝐺 + 𝑅 − 𝐵 𝑅 − 𝐺 2+ 𝑅 − 𝐵 𝐺 − 𝐵 𝑆 = 1 − 3 𝑅 + 𝐺 + 𝐵 min(R, G, B) 𝑉 = 1 3 𝑅 + 𝐺 + 𝐵
R,G,B adalah koordinat nilai merah, hijau dan biru pada koordinat RGB yang nilainya bernilai dari 0 sampai 1.
2. Model Warna HSV (Hue Saturation Value)
Model warna ini terdiri dari 3 komponen yang di simpan, yaitu warna (hue), saturasi (saturation) dan kecerahan (value).
22
Nilai dari warna berkisar antara 0 sampai 360 merepresentasikan warna yang dibentangkan dari merah, kuning, hijau, biru, lalu kembali lagi ke merah, warna pada 0 dan 360 sama-sama merupakan warna merah. Nilai saturasi merupakan nilai keabuan dari sebuah warna berkisar antara 0 sampai 1, dan kecerahan merupakan tingkat terang atau gelapnya sebuah warna yang berkisar dari 0 sampai 1. Konversi HSV ke RGB
23
r, g, b merupakan koordinat pada model warna RGB yang nilainya berkisar 0 sampai 1. Max adalah nilai maksimum dari r,g, dan b, dan min adalah nilai minimum.
2.7 Histogram Warna (Color Histogram)
Histogram warna merupakan suatu representasi dari distribusi warna suatu citra. Histogram warna didapat dengan menghitung jumlah piksel untuk setiap warna. Histogram warna dapat dikuantitasi untuk mengurangi jumlah bin agar menghemat memori dan mempercepat proses retrival. Kuantitasi dalam pengolahan citra (image processing) adalah suatu teknik mengkompres / menggabungkan data dalam suatu rentang tertentu menjadi satu data baru.
Histogram warna dari suatu citra I dinyatakan dengan vektor berdimensi N, H(I) = [H(I,j) , j = 1, 2, …, N] dimana N adalah banyaknya bin dan H(I,j) adalah banyaknya piksel dengan nilai warna j. Histogram warna dapat dihitung dengan cara sebagai berikut Algoritma Pembentukan Histogram Warna
For i = 1 to imageHeight
For j = 1 to imageWidth
ColorHistogram[image(I,j).color]++
2.8 Jarak Kemiripan (similarity distance)
Kemiripan dua buah citra dapat dihitung dengan jarak. Semakin mirip dua buah citra, maka jaraknya akan semakin kecil. Begitu juga sebaliknya, semakin berbeda dua buah citra maka jaraknya akan semakin besar.
Fungsi kemiripan merupakan pemetaan dari dua buah fitur vektor menjadi nilai riil positif, yang dipilih untuk merepresentasikan kemiripan visual antara dua buah citra.
24
Untuk menghitung jarak antara dua fitur vektor yang digunakan dalam RCBK, dapat digunakan berbagai macam fungsi jarak, antara lain:
1. Jarak Euclidean histogram (Histogram euclidean distance)
Misalkan h dan g adalah 2 buah histogram warna. Jarak Euclidean antara histogram h dan g adalah:
𝑑(ℎ, 𝑔)2 = (ℎ 𝑖 − 𝑔 𝑖 )2 𝑁
𝑖=1
Jarak Euclidean disebut juga L2 distance.
2. Jarak Interseksi Histogram (Histogram intersection distance) Jarak interseksi histogram h dan g adalah:
𝑑 ℎ, 𝑔 = min(h i , g i ) 𝑁
𝑖=1
min( ℎ , 𝑔 )
|h| adalah jumlah dari seluruh bin histogram h dan |g| adalah jumlah dari seluruh bin pada histogram h.
3. Jarak Kuadratik Histogram (Histogram quadratic (cross) distance) Jarak kuadratik histogram h dan g adalah:
𝑑 ℎ, 𝑔 = (ℎ − 𝑔)𝑡𝐴 ℎ − 𝑔
Dimana A merupakan matrik kemiripan (similarity matrix). Nilai ai,j untuk model warna RGB adalah
𝑎𝑖𝑗 = 1 − 𝑑𝑖𝑗 max 𝑑𝑖𝑗
Dimana dij adalah jarak Manhattan antara warna i dan j dalam model warna RGB.
25 𝑎𝑖𝑗 = 1 − 1 5 𝑣𝑖− 𝑣𝑗 2 + 2 𝑠𝑖cos ℎ𝑖 − 𝑠𝑗cos ℎ𝑗 2 1 2
h,s dan v adalah nilai warna pada model warna HSV. 4. Jarak Manhattan (Manhattan Distance)
Jarak manhattan antara 2 histogram adalah
𝑑 ℎ, 𝑔 = ℎ 𝑖 − 𝑔 𝑖 𝑁
𝑖=1
Jarak manhattan disebut juga L1 distance atau city block distance. 5. Jarak Minkowski (Minkowski Distance)
Jarak minkowski merupakan generalisasi dari jarak manhattan dan juga jarak Euclidean. Jarak minkowski orde p antara 2 histogram adalah
𝑑(ℎ, 𝑔)𝑝 = |ℎ 𝑖 − 𝑔 𝑖 |𝑝 𝑁
𝑖=1
Jarak minkowski dengan p = 1 merupakan jarak manhattan, dan jarak minkowski dengan p = 2 merupakan jarak Euclidean.
2.9 Pohon Berdimensi K (Kd Tree)
RCBK sangat tergantung kepada pencarian dalam ruang berdimensi tinggi. Secara lebih spesifik, fitur dari suatu citra seperti warna, tekstur ataupun bentuk dideskripsikan direpresentasikan dalam fitur vektor yang dapat dianggap sebagai titik pada ruang multidimensi.
Proses pencarian dapat dilakukan dengan jauh lebih efisien dengan menggunakan pengindeksan multidimensi. Terdapat banyak metode pengindeksan multidimensi, yang berbeda pada jenis kueri yang dapat dilakukan dan juga banyaknya dimensi dimana suatu metode memiliki keunggulan.
26
Kebanyakan sistem manajemen basis data sekarang tidak mendukung pengindeksan multidimensi dan sistem manajemen basis data yang mendukung memberikan sedikit sekali pilihan untuk metode pengindeksan multidimensi. Penelitian aktif dilakukan pada bagaimana menyediakan mekanisme pada sistem manajemen basis data yang memungkinkan pengguna untuk menyertakan pengindeksan multidimensi yang dipilih ke dalam mesin pencari.
Salah satu metode pengindesan multidimensi yang mudah diimplementasikan dan berguna untuk berbagai macam masalah pencarian adalah pohon berdimensi k.
2.9.1 Definisi dan Konstruksi
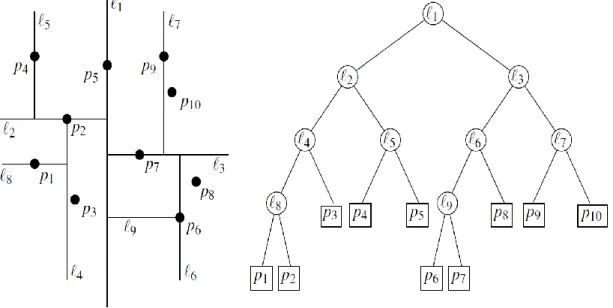
Pohon berdimensi k merupakan sebuah struktur data berbentuk pohon biner (binary tree) dimana setiap daun (leaf) menyimpan satu titik berdimensi d. Dalam dua dimensi, setiap titik mempunyai koordinat x dan y, dengam demikian untuk membentuk pohon berdimensi 2, pertama-tama titik dibagi menurut koordinat x, lalu koordinat y, dan kembali ke koordinat x, dan seterusnya. Misalkan terdapat himpunan titik dalam dua dimensi yaitu P, maka pada akar (root) dari pohon berdimensi k, himpunan P dibagi oleh garis vertikal menjadi 2 subhimpunan yang berukuran hampir sama, garis pembagi ini disimpan pada akar. Pleft adalah himpunan titik di sebelah kiri atau pada garis pembagi, Pleft disimpan pada subpohon kiri dan Pright adalah himpunan garis di sebelah kanan titik pembagi, Pright disimpan pada subtree kanan. Pada anak kiri dari akar yaitu u, himpunan Pleft dibagi menurut garis horizontal, titik yang berada di bawah atau pada garis tersebut disimpan dalam subpohon kiri dari u sedangkan yang berada di atas, disimpan pada subpohon kanan dari u. Garis pembagi horizontal ini disimpan pada anak kiri dari akar. Pada anak kanan dari root yaitu v, juga dilakukan hal yang sama, dibagi menurut garis horizontal dan titik yang berada di bawah atau pada garis pembagi, disimpan pada
27
subtree kiri dari v, dan titik yang berada di atasnya disimpan pada subtree kanan dari v. Pada anak dari u dan v, titik dibagi lagi menurut garis vertikal. Secara umum, pembagian dilakukan menurut garis vertikal pada simpul (node) dengan kedalaman (depth) genap dan garis horizontal pada simpul dengan kedalaman ganjil. Kedalaman dimulai dari 0. Pembagian berhenti ketika tersisa satu titik. Awalnya, nama pohon berdimensi k berarti pohon k-dimensi, pohon seperti di atas yaitu pada 2 dimensi disebut 2d tree, sekarang nama tersebut artinya berubah, dari yang seharusnya pohon berdimensi 2, sekarang disebut 2-dimensional kd tree. Untuk generalisasi pada d dimensi, pembagian dimulai dari dimensi pertama, kedua, dan seterusnya sampai kedalaman d-1, pada kedalaman d, pembagian dimulai kembali dari dimensi pertama.
Pembentukan Pohon Berdimensi K Algorithm BUILDKDTREE(P,depth)
28
Input. Himpunan titik P dan kedalaman sekarang depth Output. Akar dari pohon berdimensi k yang menyimpan P. 1. if P contains only one point
2. then return a leaf storing this point 3. else if depth is even
4. then Split P into two subsets with a vertical line l through the median x-coordinate of
the points in P. Let P1 be the set of points to the left of l or on l, and let P2 be the set
of points to the right of l.
5. else Split P into two subsets with a horizontal line l through the median y-coordinate of
the points in P. Let P1 be the set of points below l or on l, and let P2 be the set of
points above l.
6. νleft ← BUILDKDTREE(P1,depth+1) 7. νright ← BUILDKDTREE(P2,depth+1)
8. Create a node ν storing l, make νleft the left child of ν, and make νright the right child of ν.
9. return ν
2.9.2 Algoritma Kueri
Diberikan sebuah rentang (range) dalam d dimensional, algoritma kueri pada pohon berdimensi k akan melaporkan titik mana saja yang berada dalam rentang. Suatu
29
simpul dalam pohon berdimensi k menyatakan suatu daerah berbentuk bidang (dalam 2 dimensi) atau hyperplane dalam d dimensi. Untuk sebuah simpul v, daerah yang direpresentasikan oleh v dinyatakan oleh region(v).
Region yang dinyatakan oleh simpul dalam pohon berdimensi k dapat memiliki batas (bounded) maupun tidak (unbounded). Sebuah titik berada dalam subtree dengan root u, jika dan hanya jika titik tersebut berada dalam region(u). Dalam algoritma kueri, dilakukan dengan menelusuri pohon dengan dfs (depth first search), suatu simpul dikunjungi hanya jika region dari simpul tersebut berpotongan dengan rentang kueri, R. Kueri Pohon berdimensi k
Procedure name SEARCHKDTREE(v,R)
Input: Akar dari ( subpohon ) pohon berdimensi k, dan sebuah rentang R. Output: Semua titik pada daun di bawah v yang berada dalam rentang R
Gambar 2.6 Contoh Region Pohon berdimensi k
30 1: if v is a leaf
2: then Report the stored at v if it lies in R 3: else if region(lv(c)) is fully contained in R 4: then REPORTSUBTREE(lc(v)) 5: else if region(lc(v)) intersects R 6: then SEARCHKDTREE(lc(v),R) 7: if region(rv(c)) is fully contained in R 8: then REPORTSUBTREE(rc(v)) 9: else if region(lc(v)) intersects R 10: then SEARCHKDTREE(lc(v),R)
2.10 Transformasi Kueri dan Rekord ke dalam Permasalahan Geometri
Kueri sebuah data dari basis data dapat di interpretasikan sebagai masalah geometri dengan mentransformasi rekord di dalam basis data menjadi titik dalam ruang multidimensi (Berg et all, p95).
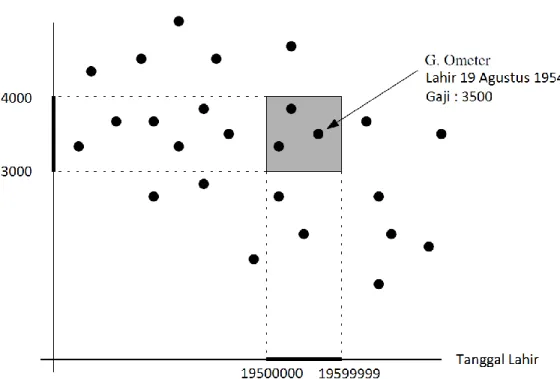
Misalnya dari sebuah basis data administrasi karyawan dimana nama, gaji, tanggal lahir alamat, dll dari sebuah karyawan disimpan, terdapat kueri dimana mencari semua karyawan dengan gaji per bulan 3000 – 4000 dan dilahirkan pada tahun 1950 – 1955. Koordinat pertama (sumbu horizontal) dari sebuah titik merupakan tanggal lahir, yang direpresentasikan dengan bilangan bulat 10000 x tahun + 100 x bulan + tanggal, dan koordinat kedua (sumbu vertikal) adalah gaji karyawan per bulan. Kueri tersebut direpresentasikan dalam masalah geometri menjadi mencari semua titik yang terdapat dalam suatu persegi panjang.
31
Secara umum, jika ingin menjawab kueri dari database dimana suatu rekord mengandung d-field, maka suatu rekord di dalam database ditransformasi menjadi titik dalam d-dimensi. Dengan demikian, sebuah kueri yang meminta untuk melaporkan semua titik dimana nilai field – fieldnya berada dalam suatu nilai yang telah ditentukan, ditransformasi menjadi kueri yang meminta melaporkan semua titik yang berada dalam dalam sebuah kotak d-dimensi yang sisinya sejajar sumbu utama. Kueri semacam ini disebut rectangular range query atau orthogonal range query (Bentley, p96).
2.11 Evaluasi Kualitas Retrival
Suatu metode retrival dikatakan memiliki kualitas baik jika mengandung error sesedikit mungkin. Dua jenis error yang terdapat dalam sistem retrival :
1. False Positive (FP)
Ter-retriev, tetapi bukan dokumen yang relevan dengan kueri. Gambar 2.8 Contoh transformasi kueri ke dalam geometri
32 2. False Negative (FN)
Dokumen yang relevan, namun tidak ter-retrieve.
Metode retrieval yang baik akan meminimalkan kedua error di atas. Untuk melakukan evaluasi terhadap suatu metode retrival, dilakukan dengan menghitung nilai recall dan precision.
𝑟𝑒𝑐𝑎𝑙𝑙 =𝑎 𝑏
𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑎 𝑐 Dimana :
a = banyaknya dokumen yang ter-retriv dan relevan.
b = banyaknya dokumen yang relevan terhadap kueri dalam basis data.
c = banyaknya dokumen yang ter-retriv.
Nilai precision yang tinggi berarti sedikit terjadi false positive dan nilai recall yang tinggi berarti sedikit terjadi false negative.
Harmonic Mean / F-measure / F-score / F1-Score adalah suatu pengukuran yang menggabungkan nilai precision dan recall.
𝐹 = 12 𝑟+ 1 𝑝
= 𝑟+ 𝑝2𝑟𝑝 r : nilai recall ; p : nilai precision
Nilai F berada dalam rentang [0,1], nilai F semakin tinggi jika nilai precision dan recall tinggi. Semakin tinggi nilai F dari suatu metode retrival, berarti semakin baik pula performa suatu RCBK.
33
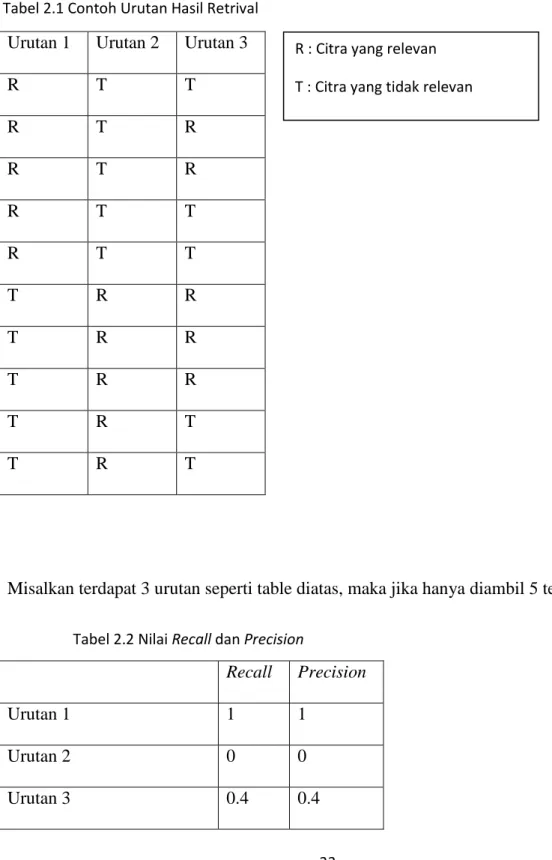
Nilai recall dan precision akan divisualisasikan dalam bentuk grafik. Untuk itu, dari semua citra dalam basis data yang terurut menaik berdasarkan jarak, dihitung nilai recall dan precision untuk setiap kemunculan citra yang relevan dengan kueri.
Urutan 1 Urutan 2 Urutan 3
R T T R T R R T R R T T R T T T R R T R R T R R T R T T R T
Misalkan terdapat 3 urutan seperti table diatas, maka jika hanya diambil 5 teratas
Recall Precision
Urutan 1 1 1
Urutan 2 0 0
Urutan 3 0.4 0.4
R : Citra yang relevan T : Citra yang tidak relevan Tabel 2.1 Contoh Urutan Hasil Retrival
34
Jika diambil 10 teratas maka ketiga urutan diatas akan menghasilkan nilai recall dan precision yang sama, yaitu recall 1 dan precision 0.5. Untuk mendapatkan grafik visual, dilakukan pengukuran nilai precision pada nilai recall yang sama, untuk setiap kueri. Umumnya nilai precision dihitung pada nilai recall yang standar yaitu 11 titik, 100%, 90%,80%, … , 0%.
Selanjutnya dari titik – titik yang didapat, dilakukan interpolasi untuk membuat kurva precision dan recall. Precision interpolasi pada suatu titik recall r didefinisikan sebagai nilai precision terbesar pada semua titik recall r’ ≥ r. Selanjutnya dari nilai precision interpolasi, digambar kurva recall dan precision.
𝑃𝑖𝑛𝑡𝑒𝑟𝑝𝑜𝑙𝑎𝑠𝑖 𝑟 = max 𝑃 𝑟′ 𝑢𝑛𝑡𝑢𝑘 𝑠𝑒𝑚𝑢𝑎 𝑟′ ≥ 𝑟
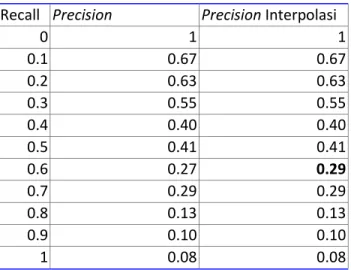
Recall Precision Precision Interpolasi
0 1 1 0.1 0.67 0.67 0.2 0.63 0.63 0.3 0.55 0.55 0.4 0.40 0.40 0.5 0.41 0.41 0.6 0.27 0.29 0.7 0.29 0.29 0.8 0.13 0.13 0.9 0.10 0.10 1 0.08 0.08
35
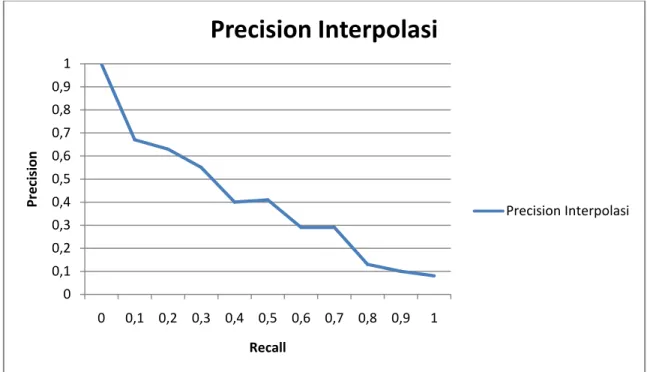
Data interpolasi pada tabel 2.4 akan menghasilkan kurva pada gambar 2.8. Untuk nilai precision pada nilai recall 0%, didefinisikan bahwa nilainya adalah 1.
Untuk menghitung nilai rata – rata precision terhadap semua kueri, maka dihitung rata – rata precision untuk tiap tingkatan recall untuk semua kueri.
𝑃 𝑟 = 𝑃𝑖 𝑟 𝑁
𝑖=1 𝑁
P(r) = rata – rata precision untuk nilai recall r
Pi(r) = rata – rata precision untuk nilai recall r pada kueri ke – i
N = banyaknya kueri 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 Pr e ci si o n Recall