I - 92 SENTRA
Jl.Raya Tlogomas No. 246 Malang, Kampus 3 Gedung Kuliah Bersama 3 Telp. 0341-464318, E-mail: [email protected], [email protected]
Abstrak
Pengelompokkan citra berdasarkan kategori yang sesuai sangat dibutuhkan dalam basis data citra. Beberapa bidang ilmu yang membutuhkan basis data antara lain temu kembali citra, pengenalan objek pada citra, image annotation, dan relavance feedback. Oleh karena itu penelitian ini dikembangkan tentang klasifikasi citra menggunakan multi texton histogram dan probabilistic neural network. Berdasarkan hasil uji coba, akurasi untuk data Batik mencapai nilai 92% dan data Brodatz mencapai 98%. Multi Texton Histogram dan Probabilistic Neural Network mampu mengklasifikasi citra Brodatz dan Batik dengan efektif.
Kata kunci: Klasifikasi, Texton, Probabilistic Neural Network.
Pendahuluan
Beberapa penelitian sebelumnya telah diusulkan pada topik pengenalan pola dan klasifikasi citra. Cheong dan Loke telah meneliti tentang klasifikasi citra tekstur kain songket. Pada penelitian yang diusulkan, enam multispectral co-occurrence matrix untuk mengekstraksi fitur warna. Kemudian Tchebichef orthogonal polynomial digunakan untuk mendapatkan koefisien momen sebagai metode ekstraksi fitur berdasarkan co-occurrence. Metode tersebut memberikan hasil positif untuk membedakan warna tekstur pada kain songket [1]. Melanjutkan penelitian sebelumnya Cheong dan Loke melakukan reduksi fitur menggunakan Principal Component Analysis (PCA). Pada penelitiannya berhasil mereduksi jumlah fitur turun hingga 2%. Hasil penelitian mereka menunjukkan bahwa pengurangan fitur sebesar 2% mampu mengurangi komputasi dengan jumlah fitur yang lebih sedikit namun tetap dapat mempertahankan akurasi klasifikasi [2].
Nurhaida et al [3] telah mengusulkan metode ekstraksi fitur untuk mengenali tekstur citra batik. Dalam penelitiannya mereka membandingan metode untuk klasifikasi citra. Metode yang dibandingkan adalah Gray Level Co-occurrence Matrices (GLCM), Canny Edge Detection, dan Gabor filters. Dari beberapa metode tersebut dinyatakan bahwa GLCM memiliki fitur yang baik untuk klasifikasi tekstur pada citra kain batik.
Pada umumnya klasifikasi citra dibangun menggunakan fitur warna, tekstur dan bentuk baik secara terpisah maupun dengan kombinasi. Fitur warna merupakan fitur yang paling dominan dan paling mudah dalam membedakan citra. J. Huang telah mengusulkan tentang pengindekan citra menggunakan tabel tiga dimensi berdasarkan warna dan jarak antar pixel. Tabel tersebut menggambarkan hubungan spasial pada perubahan warna citra. Tujuan pengindekan warna adalah sistem dapat membedakan sebuah citra dengan citra yang ada pada basis data [4]. Penelitian tentang tekstur juga telah banyak usulkan, baik dalam bidang pengenalan pola pengelompokan, klasifikasi maupun pendeteksian objek. Julesz, dalam penelitiannya melakukan analisa tentang interaksi texton untuk melakukan diskriminasi tekstur. Sebuah texton dapat terdiri dari beberapa pixel. Hasil penelitiannya mengungkapkan bahwa texton hanya dengan menggunakan metode statistik sederhana mampu memberikan persepsi visual secara signifikan untuk membedakan tekstur [5,6,7,8,9]. Penelitian tentang tekstur juga telah dikerjakan oleh Haralick menggunakan Gray Co-Occurrence matrix (GLCM). GLCM menggunakan metode statistik orde satu dan dua untuk menghasilkan 14 fitur. Diantaranya mean, variance, correlation, energy, homogeneity dan sebagainya [10].
SENTRA I - 93 Histogram dengan pengklasifikasi Probabilistic Neural Network (PNN). PNN dipilih sebagai pengklasifikasi karena merupakan pengembangan dari Neural Network yang memiliki kompleksitas komputasi yang tinggi. Sementara PNN memiliki kompleksitas komputasi yang relatif rendah dibandingkan dengan Neural Network [11].
Dataset yang digunakan pada penelitian ini adalah Brodatz color dataset dengan jumlah sebanyak 950 citra dan data Batik yang berjumlah 300 citra, yang terdiri dari 50 kelas dan setiap kelas terdapat 6 citra. Brodatz dataset terdiri dari 50 kelas. Masing-masing kelas berjumlah 19 citra.
Metode Penelitian
Ide yang melatar belakangi MTH adalah teori texton yang diusulkan oleh Julesz. MTH menggunakan empat jenis texton untuk mendeteksi struktur mikro dari citra. Gambar 1 menunjukkan empat jenis texton MTH. Pendekatan yang dilakukan tanpa melibatkan proses segmentasi dan training data. MTH mengekstraksi fitur citra memanfaatkan histogram warna pada ruang warna RGB dan mendeteksi orientasi tepi citra menggunakan operator sobel. Tahapan yang dilakukan MTH dijelaskan menjadi beberapa bagian. Pertama, melakukan deteksi orientasi tepi citra menggunakan operator Sobel. Hasil dari pendeteksian orientasi tepi kemudian dikuantisasi menjadi 18 bin.
MTH menggunakan 1-180 derajat dalam merepresentasikan orientasi tepi, sehingga jika dikuantisasi menjadi 18 bin dengan orientasi 180 derajat maka nilai kuantisasi memiliki kelipatan 10. Kedua MTH melakukan kuantisasi citra pada ruang warna RGB. Nilai kuantisasi yang diterapkan pada masing-masing komponen RGB adalah R=4 bit G=4 bit dan B=4 bit. Tahap ketiga adalah proses deteksi texton pada hasil kuantisasi orientasi tepi dan warna menggunakan empat texton yang berbeda. Proses pendeteksian dilakukan dari arah kiri ke kanan dan dari atas ke bawah, dengan langkah dua piksel setiap pergeserannya. Hasil dari deteksi texton berupa histogram warna dan histogram orientasi tepi.
Tahapan ke empat adalah menggabungkan histogram warna dengan histogram orientasi tepi. Karena kuantisasi warna menggunakan 4x4x4 pada masing-masing komponen RGB maka jumlah fitur yang dihasilkan sebanyak 64 fitur. Sedangkan histogram orientasi tepi menggunakan kuantisasi sebanyak 18. Jadi total fitur yang terdapat pada histogram MTH adalah 64+18=82 fitur.
1. Probabilistic Neural Network
Probabilistic Neural Network (PNN) dipilih karena alasan kecepatan dan akurasinya dalam mengenali pola dan klasifikasi. PNN merupakan pengembangan dari metode Neural Network yang berbasis pada Bayes Parzen Classification, dimana metode ini menawarkan solusi dalam masalah klasifikasi. Input layer terdiri dari beberapa node yang merupakan vektor. Vektor tersebut merupakan ciri dari citra masukkan. Pattern layer terdiri dari penjumlahan neuron sebanyak jumlah total dari data latih. Pada pattern layer fitur masukkan dihitung menggunakan fungsi gausian dengan probability density function (PDF) berbasis Parzen window. Summation layer merupakan lapisan yang menghitung jumlah kemungkinan terbesar dari pattern layer. Terakhir adalah decission layer dimana pada layer ini citra yang memiliki fitur yang paling mirip dengan target akan diputuskan masuk kedalam kelas tersebut.
2. Ekstraksi Fitur dan Klasifikasi
2.1 Ekstraksi Fitur Orientasi Tepi
Tahapan pertama adalah melakukan ekstraksi fitur orientasi tepi. Tahapan ini menggunakan operator Sobel untuk mendeteksi fitur tepi. Operator Sobel menghasilkan vektor dan magnitude yang kemudian dikuantisasi menjadi 18 bin. Pemilihan jumlah bin didasari dari penelitian sebelumnya oleh [5,7,8,9,10]. Hasil akhir dari tahapan ini menghasilkan 18 fitur orientasi tepi.
2.2 Ekstraksi Fitur Warna
I - 94 SENTRA 2.3 Deteksi Texton
Tahapan berikutnya setelah kuantisasi warna dan deteksi orientasi tepi adalah melakukan deteksi texton pada hasil kuantisasi warna dan hasil kuantisasi orientasi tepi. Texton yang digunakan MTH seperti pada Gambar 1, dimana T1, T2, T3 dan T4 merupakan jenis Texton. Proses ekstraksi fitur pada MTH menggunakan 4 jenis Texton yang dikonvolusikan pada hasil kuantisasi warna dan hasil kuantisasi deteksi orientasi tepi dari arah kiri menuju ke kanan dan dari atas menuju ke bawah dengan langkah 2 piksel per deteksi. Dimensi grid yang digunakan adalah 2 x 2 pixel yang ditandai dengan V1, V2 V3 dan V4. Jika terdapat dua piksel yang sama berada pada daerah yang ditandai maka
grid akan dihitung sebagai Texton. Perhitungan jumlah hasil deteksi Texton berdasarkan nilai kuantisasi. Misalkan, pada saat pendeteksian Texton menggunakan T1 terdapat 2 piksel yang sama pada nilai kuantisasi 10 maka, nilai kuantisasi 10 nilainya ditambah 1. Nilai hasil deteksi texton akan disimpan sebagai histogram yang akan menjadi fitur Texton. Ilustrasi deteksi Texton pada Gambar 2.
(a) (b) (c) (d) (e)
Gambar 2. Ilustrasi Perbandingan deteksi Texton MTH (a) citra asli; (b) deteksi 4 texton; (c) jenis texton; (d) hasil deteksi 4 texton;
2.4 Klasifikasi PNN
Klasifikasi PNN menggunakan 950 citra yang dibagi menjadi 900 untuk data latih dan 50 untuk data uji. Pemilihan metode klasifikasi menggunakan PNN dikarenakan PNN memiliki kecepatan dalam melakukan operasi dan meiliki akurasi yang baik dibandingkan dengan Neural Network. PNN merupakan kombinasi dari Neural Network dan PDF. Metode ini memiliki kecepatan karena proses aktivasi dilakukan berdasarkan probabilitas. Probability Density Function dihitung menggunakan Persamaan 1 dan Persamaan 2. diklasifikasikan kedalam kelas k. Perhitungan terakhir adalah menghitung probabilitas maksimum yang ada pada layer output dari PNN dengan Persamaan 3.
SENTRA I - 95
3. Evaluasi Performa
Tolak ukur dari keberhasilan ekstraksi fitur dan klasifikasi menggunakan akurasi yang dihitung menggunakan Persamaan 4.
Akurasi = M / N (4)
Dimana N adalah jumlah data uji yang diklasifikasikan dengan benar, sedangkan N adalah jumlah keseluruhan data uji.
Hasil Penelitian dan Pembahasan
Untuk mengetahui performa dari metode ekstraksi fitur menggunakan Multi Texton Histogram dan klasifikasi Probabilistic Neural Network dilakukan percobaan menggunakan dataset Brodatz dan Batik. Jumlah keseluruhan data Brodatz adalah 950 citra. Terdiri dari 50 kelas, masing-masing kelas terdapat 19 citra. Data latih dipilih sebanyak 900 data dan sisanya 50 citra untuk data uji. Sedangkan dataset batik dipilih 4 citra sebagai data latih dan 2 citra sebagai data uji.
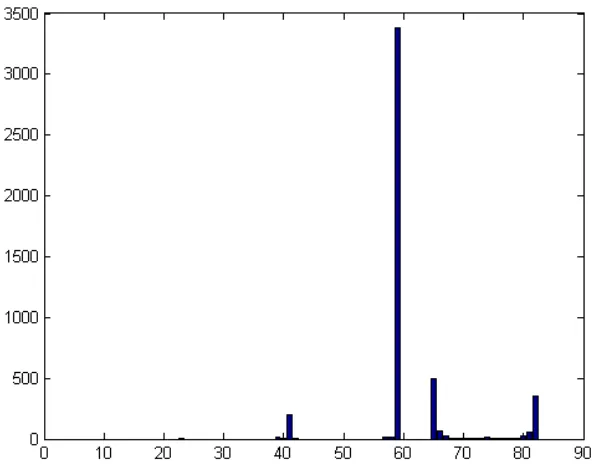
Fitur yang menjadi masukan di PNN adalah fitur hasil deteksi texton pada kuantisasi warna dan hasil deteksi texton pada kuantisasi orientasi tepi. Jumlah fitur hasil dari deteksi texton warna adalah 64 fitur sedangkan hasil deteksi texton dari orientasi tepi adalah 18 fitur. Fitur pada MTH direpresentasikan dalam bentuk histogram. Contoh hasil deteksi orientasi tepi menggunakan sobel dapat diamati pada Gambar 3. Sedangkan histogram hasil deteksi texton kuantisasi dan warna terdapat pada Gambar 6. Pada Gambar 3 (a) merupakan citra Brodatz dan Gambar 3 (b) merupakan hasil deteksi tepi menggunakan operator Sobel. Histogram MTH merepresentasikan jumlah co-occurrence piksel yang berhasil di deteksi menggunakan 4 jenis texton yang ada pada MTH. Nilai pada sumbu Y merupakan banyaknya co-occurrence yang terdapat pada nilai piksel ke i, dimana i adalah jumlah fitur atau nilai pada hasil kuantisasi. Hasil deteksi texton memiliki ketergantungan yang kuat terhadap nilai kuantisasi, pemilihan nilai kuantisasi pada penelitian ini didasarkan pada penelitian sebelumnya yang menggunakan 64 bin untuk warna dan 18 bin untuk orientasi tepi.
Tabel 1 merupakan hasil dari klasisikasi menggunakan MTH dan PNN. Dari hasil percobaan Tabel 1 menunjukkan bahwa metode ekstraksi fitur MTH dan pengklasifikasi PNN mampu mengklasifikasikan citra dengan baik. Hal ini terbukti dengan nilai akurasi yang diperoleh dari uji coba kedua dataset. Pada data Batik nilai akurasi mencapai nilai 92% menggunakan 250 data latih dan 50 data uji. Sedangkan pada dataset Brodatz nilai akurasi mencapai 98% menggunakan 900 data latih dan 50 data uji. Pemilihan data Brodatz dan Batik karena memiliki fitur yang beragam sehingga sangat tepat untuk menguji kehandalan MTH. Berdasarkan Tabel 1 dapat diamati bahwa penggunaan data latih yang banyak ataupun sedikit pada data Brodatz dan Batik tidak memberikan pengaruh yang signifikan. MTH dan PNN masih mampu memberikan performa yang baik.
a b
I - 96 SENTRA
Gambar 6. Contoh representasi histogram MTH citra Gambar 3.1(a)
Tabel 1. Hasil Klasifikasi PNN
Skema Pengujian Dataset Akurasi
Batik 250 data latih, 50 data uji Batik 92.00
Brodatz 900 data latih 50 data uji Brodatz 98.00
Kesimpulan
Penelitian ini telah memaparkan tentang metode ekstraksi fitur menggunakan Multi Texton Histogram dan Probabilistic Neural Netwrok untuk melakukan klasifikasi citra Brodatz dan citra Batik. Hasil pengujian menunjukkan nilai akurasi yang tinggi mencapai 92% untuk citra Batik dan 98% untuk citra Brodatz. Berdasarkan hasil uji coba yang telah dilakukan oleh penulis, Multi Texton Histogram dan Probabilistic Neural Netwrok handal dalam melakukan klasifikasi citra terutama citra berwarna yang memiliki karakteristik tekstur. Penelitian selanjutnya dapat dikembangkan untuk meningkatkan pendeteksian co-occurrence piksel pada hasil kuantisasi warna dan orientasi tepi.
Referensi
[1] M. Cheong and K. S. Loke, “An approach to texture-based image recognition by deconstructing
multispectral co-occurrence matrices using tchebichef orthogonal polynomials,” in Pattern Recognition, 2008. ICPR 2008. 19th International Conference on. IEEE. 2008; pp. 1–4.
[2] K. S. Loke and M. Cheong, “Efficient textile recognition via decomposition of co-occurrence
matrices.” in 2009 IEEE International Conference on signal and Image Processing
Applications. 2009; pp.257-261.
[3] I. Nurhaida, R. Manurung, and A. M. Arymurthy, “Performance comparison analysis features
extraction methods for batik recognition,” in Advanced Computer Science and Information Systems (ICACSIS), 2012 International Conference on. IEEE, 2012; pp. 207–212.
[3] C. W. D. de Almeida, R.M. C. R. de Souza, A. L. B. Candeias, “Texture classification based on
co-occurrence matrix and self-organizing map”, IEEE International conference on Systems Man& Cybernetics, University of pernambuco, Recife. 2010; pp. 2487 - 2491.
SENTRA I - 97 [5] Guang-Hai Liu, Lei Zhang, Ying-Kun Hou, Zuo Yong Li, Jing Yu Yang. 2010. Image Retrieval
based on multi-texton histogram. Journal of Pattern Recognition 43 (2010). 2380-2389. Science Direct.
[6] Haralick, Robert M. "Statistical and structural approaches to texture." Proceedings of the IEEE 67, no. 5 (1979): 786-804.
[7] Agus Eko Minarno, Yuda Munarko, Fitri Bimantoro, Arie Kurniawardhani, Nanik Suciati,
“Batik Image Retrieval Based on Enhanced Micro-Structure Descriptor”, 2nd Asia Pacific
Conference on Computer Aided System Engineering (APCASE) 2014, Bali, 10 – 12 February
2014
[8] Agus Eko Minarno, Yuda Munarko, Fitri Bimantoro, Arie Kurniawardhani, Nanik Suciati,
“Texture Feature Extraction using Co-Occurence Matrix of Sub-Band Image for Batik Image
Classification”, ICoICT 2014, Bandung, 28 – 29 May 2014
[9] Agus Eko Minarno, Nanik Suciati, “Batik Image Retrieval Based on Color Difference
Histogram and Gray Level Co-Occurence Matrix”, TELKOMNIKA Journal, September 2014,
Vol. 12, No. 3, ISSN: 1693-6930. pp.125-132.
[10] Agus Eko Minarno, Nanik Suciati, “Image Retrieval using Multi Texton Co-Occurence
Descriptor”, Journal of Theoretical and Applied Information Technology”, 2014, Vol 67 No 3,
E-ISSN 1817-3195 / ISSN 1992-8645,p103-110.