BAB 2
LANDASAN TEORI
Pada bab ini akan diuraikan beberapa hal penting berkenaan dengan dasar perancangan sistem rekomendasi film Indonesia menggunakan algoritma Apriori. Semua dasar teori tentang sistem rekomendasi beserta algoritma yang digunakan dikutip dari buku, jurnal, laporan dan Internet.
2.1 Sistem Rekomendasi
Sistem rekomendasi merupakan sistem yang bertujuan memperkirakan informasi yang menarik bagi penggunanya dan juga membantu calon konsumen dalam memutuskan barang apa saja yang akan dibelinya. (Adi, 2010). Dalam sistem rekomendasi diperlukan adanya preferensi atau profil pengguna dalam menentukan pilihan dari sekian banyak item yang ada sesuai dengan kebutuhan pengguna. Profil pengguna umumnya didasarkan menarik tidaknya suatu informasi yang dilihat oleh user (Tsalaatsa, et al, 2013). Sistem rekomendasi akan menawarkan kemungkinan dari penyaringan informasi personal sehingga hanya informasi yang sesuai dengan kebutuhan dan preferensi pengguna yang akan ditampilkan di sistem dengan menggunakan sebuah teknik atau model rekomendasi (Sebastia, et al, 2009).
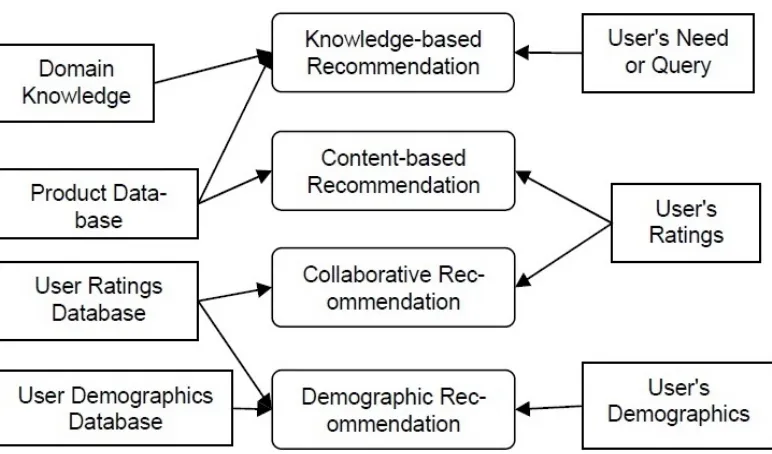
1. Content-Based : bekerja dengan cara mencari item lain yang mirip dengan item yang disukai oleh user berdasarkan informasi content atau tekstual dari setiap item (Mobasher, et al, 2000)
2. Collaborative Filtering : metode yang digunakan untuk memprediksi kegunaan item berdasarkan penilaian pengguna sebelumnya (Adomavicious, et al, 2005) 3. Knowledge-Based : merekomendasikan berdasarkan pengetahuan tentang
bagaimana item tertentu dapat memenuhi kebutuhan pengguna.
4. Hybrid Based : kombinasi dari beberapa metode yang ada dalam pengembangan sistem rekomendasi.
Gambar 2.1 Diagram teknik rekomendasi dan sumber pengetahuannya menurut Burke, Robin (2007)
2.2 Data Mining
Secara sederhana, data mining merupakan ekstrasi informasi atau pola yang penting atau menarik dari data yang ada di database yang besar (Sucahyo, 2003). Prosesnya memungkinkan pengguna untuk menganalisis data dari dimensi
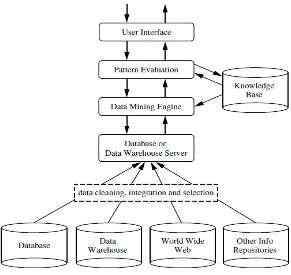
Gambar 2.2 merupakan komponen utama dalam data mining menurut Han & Kamber (2001) :
Gambar 2.2 Arsitektur Data Mining
1. Database, data warehouse, internet dan repositori informasi lainnya : merupakan kumpulan data, ataupun jenis informasi lainnya. Pemilahan data atau integrasi data dilakukan untuk pengolahan data.
2. Server database : server database bertanggung jawab dalam pengambilan data yang relevan dengan permintaan pengguna.
3. Knowledge base : digunakan untuk memandu dan mengevaluasi ketertarikan dari pola yang dihasilkan. Pengetahuan tersebut dapat mencakup konsep hirarki yang digunakan untuk mengatur atribut atau nilai atribut ke dalam berbagai tingkat abstraksi.
5. Modul evaluasi pola : komponen ini biasanya menggunakan ukuran “ketertarikan” dan interaksinya dengan modul data mining untuk memfokuskan pencarian ke pola yang menarik.
6. Antar Muka (User Interface) : modul ini memungkinkan pengguna untuk berinteraksi dengan sistem data mining.
Secara umum, data mining melibatkan enam kelas tugas (Fayyad, et al. 1996), yaitu:
1. Anomaly Detection : identifikasi data yang tidak biasa dari kumpulan data, yang mungkin menarik atau data yang rusak yang membutuhkan investigasi lebih lanjut.
2. Association Rule Learning : mencari hubungan antara variabel data.
3. Clustering : menemukan kelompok – kelompok dan struktur dalam data tanpa menggunakan struktur yang dikenal dalam data.
4. Classification : generalisasi struktur yang dikenal untuk diterapkan ke data baru. Sebagai contoh, program e-mail mungkin akan mencoba untuk mengklasifikasikan e-mail sebagai “sah” atau sebagai “spam”.
5. Regression : mencoba untuk menemukan sebuah fungsi yang memodelkan data dengan kesalahan yang minim.
6. Summarization : memberikan representasi yang lebih padat dari kumpulan data, termasuk visualisasi dan pembuatan laporan.
Sebagian besar teknik yang dipakai dalam sistem rekomendasi merupakan penerapan dari teknik yang dikenal dalam proses data mining. Dalam sistem rekomendasi, data mining digunakan untuk mendeskripsikan kumpulan teknik analisis untuk menyimpulkan aturan rekomendasi atau membangun model rekomendasi dari kumpulan data yang besar, dan sistem rekomendasi yang menggabungkan teknik tersebut akan menghasilkan rekomendasi berdasarkan pengetahuan yang dipelajari dari tindakan dan atribut pengguna (Schafer, 2009), maka dari itu data mining sering juga disebut knowledge discovery in database (KDD) dimana keluaran dari data mining bisa dipakai untuk memperbaiki pengambilan keputusan di masa depan (Rochmah, 2010).
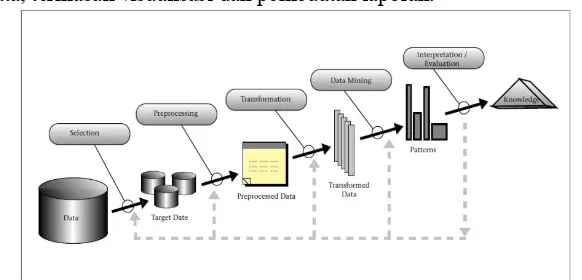
Proses data mining biasanya terdiri dari tiga langkah yang dilakukan secara berurutan (Pyle, D, 1999), yaitu : data preprocessing, analisis data, dan hasil interpretasi, seperti gambar dibawah berikut :
Dari Gambar 2.4, maka analisis dalam data mining terdiri dari dua fungsi (Santosa, 2007), yaitu :
1. Fungsi prediksi : memprediksi nilai atribut tertentu berdasarkan nilai atribut yang lain dimana atribut yang diprediksi itu dikenal sebagai variabel yang tergantung pada variabel lain
2. Fungsi deskripsi : memperoleh pola dari kecenderungan korelasi, cluster dan anomali data yang menyimpulkan hubungan dalam data.
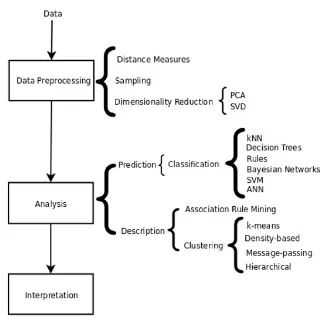
Beberapa teknik ataupun algoritma dalam data mining yang dapat digunakan adalah teknik Clustering, Classification, Association Rule dan sebagainya.
2.3 Aturan Asosiasi (Association Rule Mining)
Aturan asosiasi adalah teknik untuk menemukan aturan asosiatif antara suatu kombinasi atribut, mencari dan menemukan hubungan antar item yang ada dalam kumpulan data dan bertujuan untuk menemukan informasi item-item yang saling berhubungan dalam bentuk sebuah aturan, maka dari itu, aturan asosiasi termasuk dalam metode analisis market basket (Rochmah, 2010). Aturan asosiasi dapat digunakan untuk menemukan “hubungan atau sebab akibat” (Kusumo, et al. 2003). Aturan asosiasi ataupun korelasi item-ke-item merupakan salah satu metode yang paling terkenal dalam sistem rekomendasi (Sarwar, et al. 2001). Aturan asosiasi telah digunakan dalam berbagai bidang seperti jaringan telekomunikasi, market, manajemen resiko, dan sebagainya.
Market Basket Analysis adalah Analisis terhadap kebiasaan membeli customer dengan mencari asosiasi dan korelasi antara item-item berbeda yang diletakkan customer dalam keranjang belanjaannya (Rochmah, 2010). Association rule memiliki bentuk LHSRHS dengan interpretasi bahwa jika setiap item dalam LHS (Left Hand Side) dibeli, maka item dalam RHS (Right Hand Side) juga dibeli (Kusumo, et al. 2003).
1. Nilai pendukung (Support) yaitu ukuran yang menunjukkan seberapa besar tingkat dominasi suatu item dari keseluruhan transaksi yang ada dimana ukuran ini menentukan apakah item tersebut layak untuk dicari nilai kepastiannya.
2. Nilai Kepastian (Confidence) yaitu ukuran yang menunjukkan hubungan antar item secara kondisional
Kedua ukuran itulah nantinya yang berfungsi untuk menentukan interesting association rules, untuk dibandingkan dengan batasan yang ditentukan oleh pengguna yang mana batasan tersebut umumnya terdiri dari min_support dan min_confidence (Aritonang, 2012).
Dalam pencarian aturan asosiasi, diperlukan suatu variabel ukuran yang dapat ditentukan oleh pengguna, untuk mengatur batasan sejauh mana dan sebanyak apa hasil output yang diinginkan oleh pengguna (Rochmah, 2010). Dalam asosiasi terdapat istilah antecedent dan consequent, antecedent untuk mewakili bagian “jika” dan consequent untuk mewakili bagian “maka”. Dimana antecedent dan consequent adalah sekelompok item yang tidak punya hubungan secara bersama (Santoso, 2007).
2.4 Algoritma Apriori
Terdapat dua proses utama pada algoritma apriori (Han & Kamber 2006), yaitu : 1. Penggabungan (Join)
Setiap item dikombinasikan dengan item yang lainnya sampai tidak terbentuk kombinasi lagi
2. Pemangkasan (Prune)
Hasil kombinasi item akan dipangkas dengan menggunakan minimum support yang telah ditentukan pengguna.
Algoritma apriori bertujuan untuk menemukan frequent itemsets pada kumpulan data. Analisis apriori merupakan suatu proses untuk menemukan semua aturan apriori yang memenuhi syarat minimum untuk nilai pendukung (Support) dan nilai kepastian (Confidence), (Syaifullah, 2010). Nilai pendukung dari sebuah item bisa didapatkan dengan rumus :
Support (A) = ( ) 100%
Dimana : JT = Jumlah transaksi yang terdapat A T = Total Transaksi
Sedangkan nilai pendukung dari 2 buah item bisa didapatkan dengan rumus :
Support (A, B) = ( → ) ( → ) 100%
Dimana : JT (A→B) = Jumlah transaksi yang terdapat A dan B
Untuk mendapatkan nilai kepastian bisa didapatkan dengan rumus :
Confidence (A, B) = ( → ) ( → ) 100%
Frequent itemset merupakan iterasi pada data. Pada iterasi ke-k ditemukan semua himpunan item-item yang mempunyai k item yang disebut k-itemset. Setiap iterasi terdiri dari dua tahap. Pertama, adalah tahap pembangkitan kandidat (candidate generation) dimana himpunan semua frequent (k – 1) -itemset Fk-1 yang ditemukan pada pass ke-(k – 1) digunakan untuk membangkitkan kandidat itemset Ck. Prosedur pembangkitan kandidat menjamin bahwa Ck adalah superset dari himpunan semua frequent k-itemset. Kemudian data di-scan dalam tahap Penghitungan Support (Support Counting). Pada akhir pass Ck diperiksa untuk menentukan kandidat mana yang sering muncul, menghasilkan Fk. Penghitungan support berakhir ketika Fk atau Ck+1 kosong. Untuk membangkitkan rule akan dibangkitkan lebih dahulu candidate rule. Candidate rule berisi semua kemungkinan rule yang memiliki support > minimum support karena input candidate rule adalah frequent-itemset. Kemudian candidate rule akan join dengan tabel F untuk menemukan support antecedent. Confidence rule dihitung dengan cara membandingkan support rule dengan support antecedent rule. Hanya rule yang mempunyai confidence > minimum confidence yang disimpan dalam tabel rule (tabel R), (Kusumo, et al. 2003).
2.5 PHP (Hypertext Prepocessor)
PHP adalah singkatan dari Hypertext Preprocessor yaitu bahasa pemrograman web server-side yang bersifat open source atau gratis. PHP merupakan script yang menyatu dengan HTML dan berada pada server (server side HTML embedded scripting). PHP adalah script yang digunakan untuk membuat halaman web dinamis, dimana halaman yang akan ditampilkan dibuat saat halaman itu diminta oleh client. Mekanisme ini menyebabkan informasi yang diterima client selalu terbaru atau up to date (Lubis, et al. 2011). Semua script PHP di eksekusi pada server dimana script tersebut dijalankan. Contoh terkenal dari aplikas PHP adalah phpBB dan MediaWiki. PHP dapat juga dilihat sebagai pilihan lain dari ASP.NET/C#/VB.NET Microsoft, ColdFusion Macromedia, JSPJava Sun Microsystems, dan CGI/Perl.
Server
Request Response
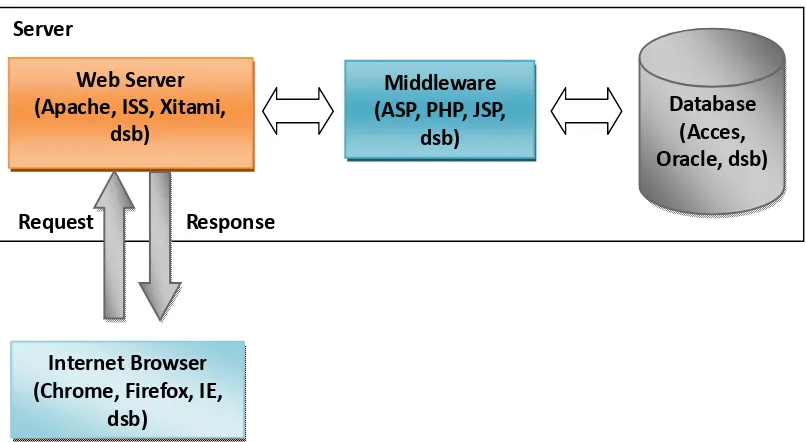
yang diminta didapatkan oleh web server, isinya segera dikirimkan ke mesin PHP untuk diproses dan memberikan hasilnya ke web server dan menyampaikannya ke klien. PHP bertugas sebagai interpreter (Lubis, et al. 2011).
Gambar 2.5 Arsitektur aplikasi web yang melibatkan Middleware
Kelebihan PHP :
Membuat web menjadi dinamis.
Program atau aplikasi dapat dijalankan disemua sistem operasi.
Dapat berjalan dalam web server di sistem operasi yang berbeda.
Dapat berjalan di sistem operasi yang berbeda.
Dapat didapatkan secara gratis
PHP yang dikembangkan dengan bahasa C dapat kita kembangkan sendiri
Tidak melakukan kompilasi dalam penggunaannya
Mendukung banyak paket database baik komersial maupun nonkomersial
Mudah dipakai karena terdapat banyak referensi
Kekurangan PHP :
Permasalahan sering terjadi pada register_global
Tidak mengenal package
Script dapat dibaca semua orang jika tidak di encoding dulu
Kelemahan dalam keamanan.
Dalam PHP, variabel selalu diisi dengan nilai. Dengan kata lain, ketika anda mengisikan sebuah ekspresi pada suatu variabel, semua nilai ekspresi asal akan disalin ke dalam variabel tujuan. Ini berarti setelah mengisikan nilai suatu variabel ke variabel yang lain, jika kita mengubah nilai salah satu variabel tidak akan mempengaruhi variabel yang lain.
2.6 SQL
SQL adalah kepanjangan dari Structured Query Language, yang merupakan bahasa pemrograman untuk menyimpan, memanipulasi dan mendapatkan data yang tersimpan dari basis data relasional (database). SQL adalah bahasa standar untuk sistem basis data relasional (Lubis, et al. 2011). Sistem basis data yang umumnya dipakai seperti MySQL, MS Access, Oracle, SQL Server, dan sebagainya. Dan biasanya sistem basis data tersebut menggunakan SQL versi yang tersendiri seperti MS SQL Server menggunakan T-SQL, Oracle menggunakan PL/SQL, MS Access menggunakan Jet SQL.
SQL memungkinkan seorang programmer atau administrator database untuk melakukan :
Modifikasi struktur database
Mengubah pengaturan sistem keamanan
Melakukan proses kueri (query) untuk mencari informasi dalam database
Memperbaharui data yang ada dalam database
Numerik = INTEGER, SMALLINT, BIGINT, NUMERIC (w,d), DECIMAL(w,d), FLOAT, REAL, DOUBLE PRECISION
Karakter = CHARACTER(L), VARCHAR(L)
Biner = BIT(L), BIT VARYING (L), BLOB
Temporal = DATE, TIME, TIMESTAMP Contoh query dalam SQL (Halvorsen, 2014) :
Insert into STUDENT (Name, Number, SchoolId)
Values (‘John Smith’, ‘100005’, l)
Select SchoolId, Name from SCHOOL
Select * from SCHOOL where SchoolId > 100
Update STUDENT set Name=’John Wayne’ where
StudentId=2
Delete from STUDENT where SchoolId=3
Dalam penggunaannya SQL dikategorikan menjadi tiga sub perintah, yaitu :
1. DDL (Data Definition Language) : digunakan untuk membangun kerangka database
2. DML (Data Manipulation Language) : digunakan untuk memanipulasi data dalam database yang telah terbuat
3. DCL (Data Control Language) : digunakan untuk menghapus data dari tabel.
2.7 Unified Modelling Language (UML)
(Hayati, 2011). Notasi UML merupakan sekumpulan bentuk khusus untuk menggambarkan berbagai diagram piranti lunak dimana setiap bentuk memiliki makna tertentu, dan sintaks UML mendefinisikan bagaimana bentuk-bentuk tersebut dapat dikombinasikan (Dharwiyanti, S & Wahono, R.S, 2003).
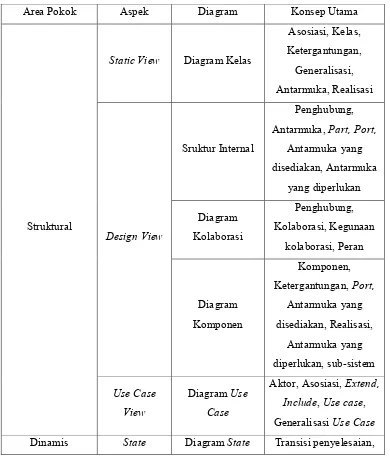
Berikut adalah tabel 2.1 yang merupakan pandangan atau aspek UML dan pembagiannya sesuai dengan konsep utama yang relevan menurut Rumbaugh, et al (2005).
Tabel 2.1 Pandangan/Aspek UML
Area Pokok Aspek Diagram Konsep Utama
Struktural
Static View Diagram Kelas
Machine
Diagram Package Impor, Model, Paket
Diagram Package
Pembatas, Profil, Stereotipe, Tagged
Value
Ada beberapa model yang sering digunakan dalam pengembangan sistem perangkat lunak berbasis objek, yaitu :
2.7.1 Diagram Use Case
1. Aktor
Aktor adalah sesuatu atau seseorang yang berinteraski dengan sistem. Aktor merepresentasikan peran bukan individu dari sistem tersebut. Nama yang dipilih untuk aktor harus menyatakan peran dari aktor tersebut.
Gambar 2.6 Aktor
2. Use Case
Sebuah use case adalah cara penggunaan sistem yang spesifik oleh aktor. Use case menggambarkan suatu fungsi yang tampak.
Gambar 2.7 Use Case
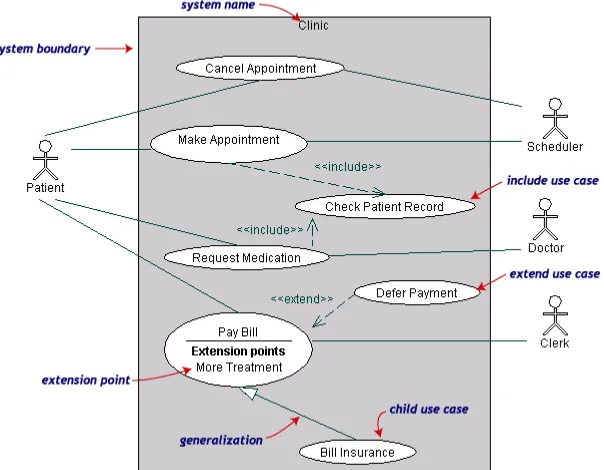
3. Keterhubungan
Keterhubungan antara use case dengan use case lain berupa generalisasi antara use case tersebut, yaitu :
Gambar 2.8 Contoh diagram use case
2.7.2 Diagram Sequence
Sequence diagram menggambarkan interaksi antar objek di dalam dan di sekitar sistem. Sequence diagram terdiri atar dimensi vertikal (waktu) dan dimensi horizontal (objek-objek yang terkait). Diawali dari apa yang men-trigger aktivitas tersebut, proses dan perubahan apa saja yang terjadi secara internal dan output apa yang dihasilkan (Dharwiyanti, S & Wahono, R.S, 2003).
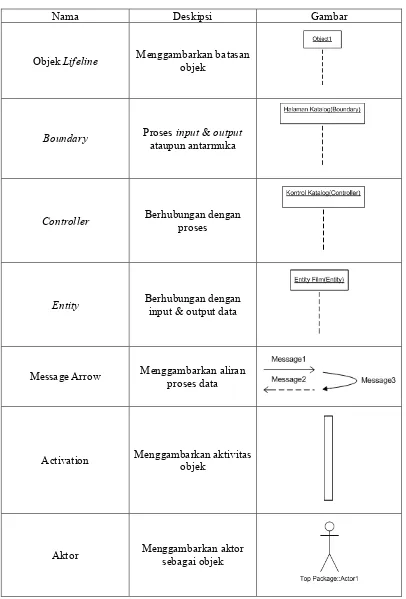
Tabel 2.2 Elemen Diagram Sequence
Nama Deskipsi Gambar
Objek Lifeline Menggambarkan batasan objek
Boundary Proses input & output ataupun antarmuka
Controller Berhubungan dengan proses
Entity Berhubungan dengan input & output data
Message Arrow Menggambarkan aliran proses data
Activation Menggambarkan aktivitas objek
Aktor Menggambarkan aktor
2.7.3 Diagram Kelas
Kelas (Class) menggambarkan keadaan (atribut/properti) suatu sistem, sekaligus menawarkan layanan untuk memanipulasi keadaan tersebut (metoda/fungsi) (Dharwiyanti, S & Wahono, R.S, 2003). Kelas memiliki tiga area pokok, yaitu :
1. Nama 2. Atribut 3. Metoda
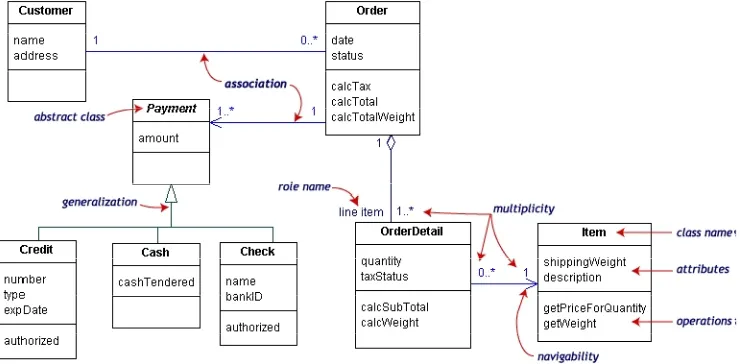
Class dapat merupakan implementasi dari sebuah interface, yaitu class abstrak yang hanya memiliki metoda. Gambar 2.9 adalah contoh dari diagram kelas :
Gambar 2.9 Contoh diagram kelas
2.7.4 Diagram Aktivitas