7
LANDASAN TEORI
2.1. Pengertian Data, Informasi dan Knowledge
Data merupakan fakta yang dikumpulkan, disimpan, dan diproses boleh sebuah sistem informasi. Selain deskripsi dari sebuah fakta, data dapat pula merepresentasikan suatu objek sebagaimana dikemukakan oleh Wawan dan Munir (2006). Dengan demikian dapat dijelaskan kembali bahwa data merupakan suatu objek, kejadian, atau fakta yang terdokumentasikan dengan memiliki kodifikasi terstruktur untuk suatu atau beberapa entitas.
Informasi merupakan suatu hasil dari pemrosesan data menjadi sesuatu yang bermakna bagi yang menerimanya, sebagaimana dikemukakan oleh Vercellis (2009). Informasi juga merupakan data yang telah diolah dan diproses untuk menyediakan output yang berguna bagi user. Dengan demikian informasi dapat dijelaskan kembali sebagai sesuatu yang dihasilkan dari pengolahan data menjadi lebih mudah dimengerti dan bermakna yang menggambarkan suatu kejadian dan fakta yang ada.
Pengetahuan (knowledge) sebenarnya merupakan sebuah informasi juga yang merupakan hasil dari pengolahan data. Vercellis (2009) memandang bahwa suatu informasi dikatakan pengetahuan jika dapat digunakan dalam pengambilan keputusan. Dengan demikian pengetahuan dapat dijelaskan kembali sebagai kumpulan dari data dan informasi yang bertemu dengan kompetensi dan
pengalaman seseorang untuk menindaklanjuti data dan informasi yang ada sehingga dapat dikembangkan untuk pengambilan suatu keputusan. Tidak seperti informasi yang hanya bersifat memberi tahu, pengetahuan harus mampu digunakan untuk proses pengambilan keputusan.
2.2. Data Mining
2.2.1. Pengertian Data Mining
“Data mining adalah proses untuk menemukan interesting knowledge dari sejumlah besar data yang disimpan dalam database, data warehouse, atau media penyimpanan yang lainnya.” (Han, Kamber, 2001). Sedangkan menurut Wikipedia (ID), penggalian atau penambangan data (Bahasa Inggris: data mining, DM) adalah proses pencarian otomatis terhadap pola dalam data dalam jumlah besar dengan menggunakan perangkat seperti klasifikasi, penggugusan (clustering), dll. Penambangan data adalah suatu topik yang kompleks dan berpautan dengan berbagai bidang inti seperti ilmu komputer dan memberikan nilai tambah dari teknik komputasi lain seperti statistika, pengambilan informasi, pembelajaran mesin, dan pengenalan pola. Data mining diterapkan dengan paradigma untuk melihat informasi yang tersembunyi.
Sedangkan definisi data mining berdasarkan Han Jiawei dan M. Kamber adalah proses mengekstaksi pola-pola yang menarik (implisit, tidak diketahui sebelumnya, dan berpotensi untuk dapat dimanfaatkan) dari data yang berukuran besar.
Data mining muncul berdasarkan fakta bahwa pertumbuhan data yang
sangat pesat, tetapi minim pengetahuan apa yang ada di dalam data tersebut. Alasan memilih data mining dibandingan analisis data secara tradisional adalah :
• Data mining mampu menangani jumlah data kecil sampai dengan data yang berukuran sangat besar.
• Data mining mampu menangani data yang mempunyai banyak dimensi, yaitu puluhan sampai ribuan dimensi.
• Data mining mampu menangani data dengan kompleksitas yang tinggi, misalnya data stream, data spasial, teks, web, dan lain-lain.
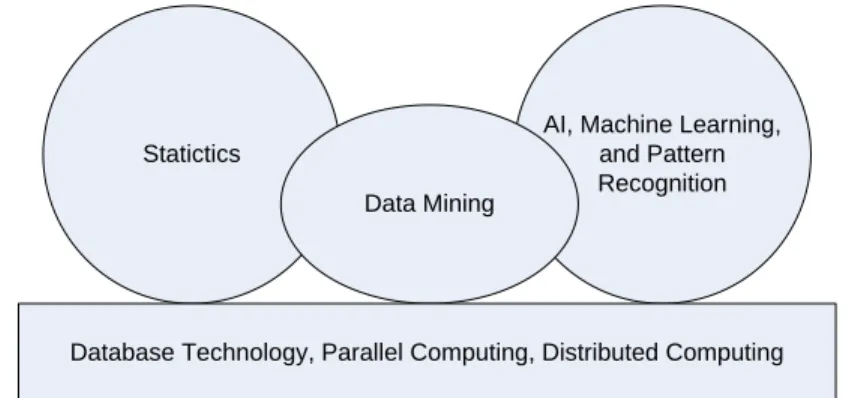
Statictics
AI, Machine Learning, and Pattern Recognition Data Mining
Database Technology, Parallel Computing, Distributed Computing
Gambar 2.1. Data mining sebagai pertemuan dari beberapa prinsip.
Dengan menggunakan data mining, para pelaku bisnis dapat memanfaatkan data yang ada untuk memecahkan masalah bisnis mereka yang umumnya dihadapi adalah :
- Bagaimana menyajikan advertensi kepada target yang tepat sasara - Menyajikan halaman web yang khusus setiap pelanggam
- Menampilkan informasi produk lain yang biasa dibeli bersamaan dengan produk tertentu.
- Mengklasifikasi artikel-artikel secara otomatis
- Mengelompokkan pengunjung web yang memiliki kesamaan karateristik tertentu
- Mengestimasi data yang hilang
- Memprediksi kelakuan di masa yang akan datang
Secara sederhana, data mining adalah ekstraksi informasi atau pola yang penting atau menarik dari data yang ada di database yang besar. Data mining merupakan proses dari Knowledge Discovery in Databases (KDD).
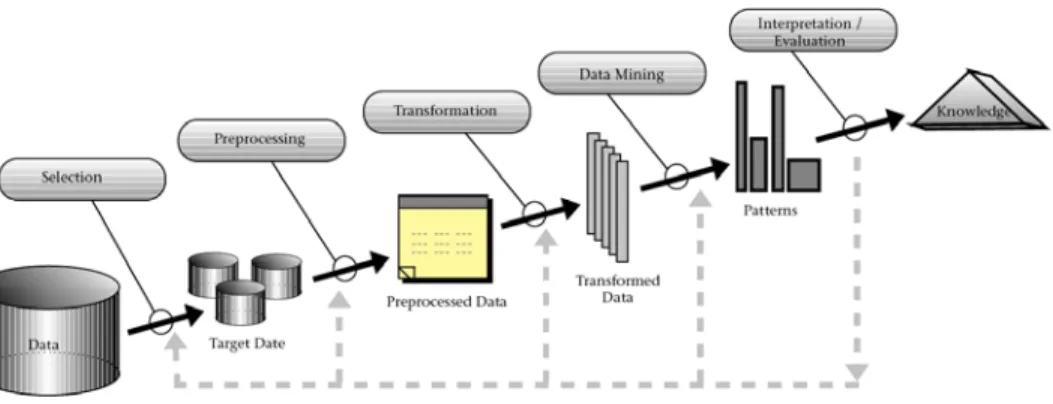
2.2.2. Knowledge Discovery in Databases (KDD)
Data mining digambarkan sebagai suatu proses untuk menemukan
pengetahuan yang menarik, seperti pola, asosiasi, aturan, perubahan, keganjilan dan struktur penting dari sejumlah besar data yang disimpan pada bank data dan tempat penyimpanan informasi lainnya.
Secara umum, proses KDD terdiri dari langkah-langkah (Han, Kamber, 2001), yaitu :
1. Pemilihan data (data selection), pemilihan data relevan yang didapat dari database.
2. Pembersihan data (data cleaning), proses menghilangkan noise dan data yang tidak konsisten atau data tidak relevan.
3. Melakukan integrasi data (data integration), penggabungan data dari berbagai database ke dalam satu database baru.
4. Transformasi data (data transformation), data diubah ke dalam format yang sesuai untuk diproses dalam data mining.
5. Data mining, suatu proses dimana metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data.
6. Evaluasi pola (pattern recognation), untuk mengidentifikasi pola-pola menarik untuk dipresentasikan ke dalam knowledge based.
7. Representasi pengetahuan (knowledge presentation), visualisasi dan penyajian pengetahuan mengenai teknik yang digunakan untuk memperoleh pengetahuan yang diperoleh oleh user.
Gambar 2.2. Proses pada Knowledge Discovery in Databases
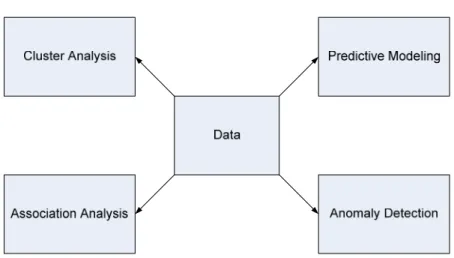
2.2.3. Teknik-Teknik Data Mining
Teknik pada data mining pada umumnya dibagi menjadi dua buah kategori yaitu :
Obyektif dari ketegori ini adalah untuk memprediksi nilai dari atribut tertentu berdasarkan nilai dari atribut yang lainnya. Atribut yang akan diprediksi umumnya dikenal sebagai target atau dependent variable, dan atribut yang digunakan untuk membuat prediksi disebut juga dengan
explanatory atau independent variable.
2. Deskriptif
Obyektif dari kategori ini adalah untuk mengenali pola (korelasi, trend,
cluster, trajector, dan anomali) yang merupakan summary dari
relasi-relasi di dalam data.
Gambar 2.3. Empat metode utama pada data mining.
2.2.3.1. Predictive Modeling
Metode ini digunakan untuk membangun sebuah model untuk variabel tujuan sebagai fungsi pada variable yang bersifat menjelaskan. Terdapat dua buah
model pada metode ini, yaitu klasifikasi yang digunakan untuk variabel tujuan yang diskrit, dan regresi yang digunakan untuk variabel tujuan yang kontinu.
Contohnya, memprediksikan apakah seorang pengguna web akan melakukan pembelian pada toko buku online termasuk dalam metode klasifikasi karena variable tujuannya adalah nilai biner. Sedangkan hal lainnya adalah memprediksikan nilai saham di masa akan datang merupakan metode regresi karena harga saham merupakan atribut nilai kontinu.
Hasil yang ingin dicapai pada metode ini adalah untuk mempelajari sebuah model yang akan meminimalkan kesalahan atau error diantara prediksi dan nilai yang sesungguhnya pada suatu variabel tujuan. Model prediksi dapat juga digunakan untuk mengidentifikasi pelanggan yang akan merespon sebuah promosi, memprediksikan gangguan pada ekosistem bumi, atau menentukan apakah seorang pasien mempunyai penyakit tertentu berdasarkan hasil dari pemeriksaan medis.
2.2.3.2. Cluster Analysis
Analisis cluster bertujuan untuk menemukan grup pada observasi yang
hubungannya berdekatan, sehingga observasi yang terkandung pada cluster yang sama adalah lebih mirip atau mendekati dibandingan pada observasi pada cluster lainnya.
Metode ini sudah digunakan untuk set grup pada pelanggan yang berhubungan, menemukan area-area di laut yang mempunyai dampak pada cuaca bumi.
Gambar 2.5. Beberapa contoh clustering.
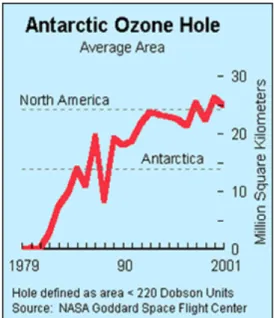
2.2.3.3. Anomaly Detection
Deteksi anomali adalah sebuah metode untuk mengidentifikasi observasi karakteristik apa saja yang secara signifikan berbeda dengan data-data lainnya. Observasi-observasi ini disebut juga dengan anomalis atau outliners. Tujuan dari metode ini adalah untuk menemukan anomalis sesungguhnya dan menghindari kesalahan melabelkan obyek biasa sebagai anomalis. Dengan kata lain, sebuah
detektor anomalis yang baik tentu saja harus memiliki tingkat deteksi yang tinggi dan tingkat kesalahan yang rendah.
Contoh dari deteksi anomali ini adalah pendeteksian penipuan kartu kredit, gangguan jaringan komputer, pola penyakit yang tidak biasa, dan gangguan ekosistem.
Gambar 2.6. Deteksi Anomali pada Lubang Ozon
2.2.3.4. Association Rule
Aturan asosiasi atau seringkali disebut juga dengan association analysis digunakan untuk menemukan pola yang mendeskripsikan kekuatan ciri-ciri asosiasi di dalam data. Association rule merupakan salah satu metode yang umum digunakan untuk mencari hubungan antar item. Sebagai contohnya, dari suatu himpunan data transaksi, seseorang mungkin menemukan suatu hubungan seperti berikut, yaitu ketika seorang pelanggan membeli laptop, ia biasanya juga membeli mouse dalam satu transaksi yang sama atau ketika seorang pelanggan membeli
sikat gigi, dalam transaksi yang sama ia juga membeli odol. Dengan demikian proses untuk menemukan hubungan antar item ini mungkin memerlukan pembacaan data transaksi secara berulang-ulang dalam jumlah data transaksi yang besar untuk menemukan polapola hubungan yang berbeda-beda, maka waktu dan biaya komputasi tentunya juga akan sangat besar, sehingga untuk menemukan hubungan tersebut diperlukan suatu algoritma yang efisien.
Gambar 2.7. Association Analysis pada Transaksi di Supermarket
Dalam menentukan suatu association rule, terdapat ukuran yang
menyatakan bahwa suatu informasi atau knowledge dianggap menarik (interestingness measure). Ukuran ini didapatkan dari hasil pengolahan data dengan perhitungan tertentu. Untuk mengukur interestingness measure, dapat digunakan variabel berikut ini :
1. Support
Suatu ukuran yang menunjukkan berapa besar tingkat dominasi suatu item atau itemset dari keseluruhan transaksi. Ukuran ini menentukan apakah suatu item atau itemset layak dicari confidence-nya (misalnya, dari keseluruhan transaksi yang ada, seberapa besar tingkat dominasi yang menunjukkan bahwa item A dibeli bersamaan dengan item B.
2. Confidence
Suatu ukuran yang menunjukkan hubungan antar dua item secara
conditional (misalnya seberapa sering item B dibeli jika pelanggan
membeli item A).
Ada beberapa simbol yang akan membantu untuk menerapkan association
rule, yaitu:
• Association rule: implikasi yang dimisalkan dengan bentuk X -> Y, dimana X dan Y saling disjoin (X ځ Y)
• Support count(σ(X)): jumlah transaksi yang memuat itemset tertentu • Support (s(X->Y)): tingkat intensitas kemunculan gabungan rule(X U Y)
pada association rule pada seluruh data set
• Confidence(c(X->Y)): tingkat intensitas kemunculan item Y pada transaksi yang memuat X
Rumus support dan confidence :
2.2.4. Market Basket Analysis
Market basket analysis adalah suatu metodologi untuk melakukan analisis
berbeda, yang diletakan konsumen dalam shopping basket yang dibeli pada suatu transaksi tertentu. Tujuan dari market basket adalah untuk mengetahui produk-produk mana yang mungkin akan dibeli secara bersamaan. Analisis data transaksi dapat menghasilkan pola pembelian produk yang sering terjadi. Informasi ini dapat digunakan bagi para penjual dalam mengembangkan strategi dan pengambilan keputusan dengan melihat beberapa item mana saja yang sering dibeli secara bersamaan oleh konsumen, misalnya dalam pengaturan peletakan produk di toko, produk yang sering dibeli bersamaan diletakkan secara berdekatan. Teknik ini telah digunakan oleh banyak toko grosir maupun retail (Olson, Yong, 2006).
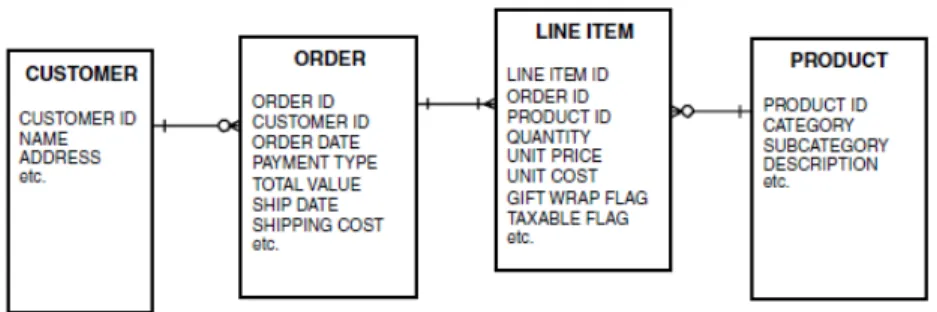
Market basket data adalah data transaksi yang mendeskripsikan tiga
fundamental dari entitas yang berbeda, yaitu: 1. Pelanggan
2. Pembelian 3. Item
Pada sebuah database relasional, struktur data untuk market basket data seringkali terlihat seperti gambar di bawah ini. Struktur data ini mengandung empat entitas yang penting.
2.2.4.1. Algoritma Apriori
Association rule mining terdiri dari dua sub persoalan yaitu menemukan
semua kombinasi dari item, disebut dengan frequent itemset yang memiliki
support lebih besar daripada mininum support, dan menggunakan frequent itemset
untuk menjalankan aturan yang ditetapkan.
Algoritma apriori bertujuan untuk menemukan frequent itemsets yang dijalankan pada sekumpulan data. Pada iterasi ke-k, akan ditemukan semua
itemset yang memiliki k item, disebut dengan k-itemset. Tiap iterasi terdiri dari
dua tahap, yaitu :
‐ Gunakan frequent (k – 1)-itemset untuk membangun kandidat frequent
k-itemset.
‐ Gunakan scan database dan pencocokan pola untuk mengumpulkan hitungan untuk kandidat itemset.
Faktor-faktor yang dapat mengakibatkan kompleksitas pada algoritma apriori adalah sebagai berikut :
1. Pemilihan minimum support
‐ Dengan menurunkan batas minimum support dapat menyebabkan semakin banyaknya frequent itemset yang didapatkan.
‐ Hal ini juga menyebabkan peningkatan jumlah dari kandidat dan panjang maksimum dari frequent itemset
2. Dimensi atau jumlah item pada data set
‐ Lebih banyak ruang yang dibutuhkan untuk menyimpan hitungan
‐ Jika jumlah pada frequent item juga meningkat, baik komputasi dan I/O Cost mungkin juga akan meningkat.
3. Besarnya ukuran database
‐ Karena apriori membuat multiple pass, run time dari algoritma juga akan meningkat dengan jumlah dari transaksi.
4. Rata-rata panjang transaksi
‐ Lebar transaksi akan meningkatkan kepadatan data set.
‐ Hal ini akan meningkatkan panjang maksimum dari frequent itemset dan garis lintang pada hash tree (jumlah dari subset di dalam sebuah transaksi meningkatkan lebarnya).
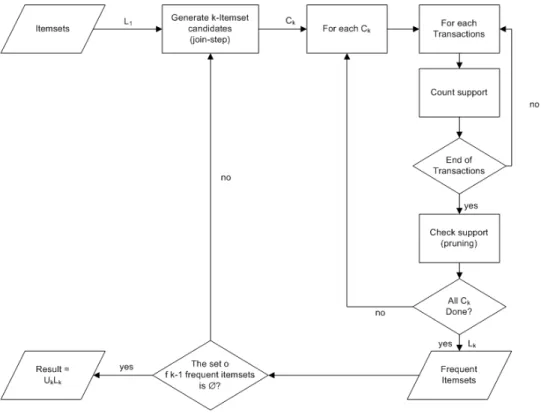
Berikut di bawah ini adalah pseudocode yang digunakan oleh algoritma apriori :
L1 = {large 1-itemset};
For ( k=2; Lk-1 = 0; k++) do begin
Ck = apriori-gen(Lk-1); // New candidates Forall transactions t ∈ D do begin
Ct = subset(Ck,t); // Candidates contained in t Forall candidates c ∈ Ct do c.count++; end Lk = {c ∈ Ck | c.count >= minsup } End Answer = Uk Lk;
Gambar 2.9. Flowchart Algoritma Apriori
Contoh cara kerja dari algoritma apriori dapat diilustrasikan pada tabel dibawah ini, dengan menggunakan minimum support sebesar 50% dan minimum
confidence sebesar 70%. Tid Itemsets 1 A B C D E 2 A B C 3 C D E F 4 A B E
Tabel 2.1 Database Transaksi
Implementasi prosesnya adalah dengan mencari frequent itemset terlebih dahulu dengan hasil sebagai berikut ini :
1. Frequent 1 – itemsets {{A}, {B}, {C}, {D}, {E}}
2. Frequent 2 – itemsets {{AB}, {AC}, {AE}, {BC}, {BD}, {CD}, {CE}} 3. Frequent 3 – itemsets {ABC}
4. Hasilnya L = L1 ∪ L2 ∪ L3 = {{A}, {B}, {C}, {D}, {E}, {AB}, {AC}, {AE}, {BC}, {BD}, {CD}, {CE}, {ABC}}
5. Menentukan asosiasi dari {ABC}, hanya {AC} → {B}, {BC} → A, {A} → B, {B} → {A} yang memenuhi persyaratan dimana level confidencenya adalah 100%.
Kelemahan daripaada algoritma apriori dapat menciptakan banyak item kandidat di dalam proses kalkulasi. Ketika jumlah dari frequent 1-itemsets sangat besar atau pola frequent menjadi sangat panjang, maka jumlah kandidat yang digenerate menjadi meningkat. Sehingga efisiensi dari algoritma ini akan menurun sangat tajam.
Contohnya apabila jumlah dari frequent 1-itemset adalah 104, maka jumlah kandidat pada 2-itemset yang akan kita generate akan menjadi 107. Jika panjang dari frequent mode adalah 100, maka kita perlu mengenerate 2100 set kandidat. Jika kita mencari terlalu banyak set kandidat, maka efisiensi dari algoritma tersebut akan menjadi terlalu rendah.
Algoritma apriori juga memerlukan scanning database berulang-ulang dan mencari itemset kandidat dengan pola mencocokan. Jika database terlalu besar dan pola yang perlu dicocokan terlalu panjang, maka efisiensi dari algoritma ini akan sangat berkurang.
2.2.4.2. FP Growth Algorithm
Dengan menggunakan algoritma fp growth, dapat dilakukan pencarian frequent itemset tanpa harus melalui candidate generation. Fp growth menggunakan struktur data fp tree, sehingga cara kerja dari algoritma ini adalah melalui scan database yang dilakukan hanya dua kali saja. Data kemudian ditampilkan dalam bentuk fp tree, dan setelah fp tree terbentuk, digunakan pendekatan devide dan conquer untuk mendapatkan frequent itemset.
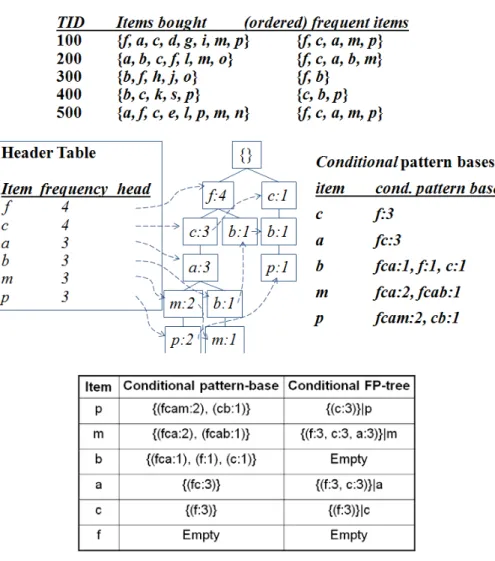
Berikut ini adalah contoh dari penggunakan algoritma fp growth pada data penjualan :
Berikut di bawah ini adalah pseudocode yang digunakan oleh algoritma FP Growth :
Procedure: FPGrowth(DB, e) Define and clear F-List : F[]; Foreach Transaction Ti in DB do Foreach Item aj in Ti do F[a]++; End End Sort F[]
Define and clear the root of FP-tree : r; Foreach Transaction Ti in DB do
Make Ti ordered according to F; Call ConstructTree(ti,r); End
Foreach item ai in I do
Call Growth(r,ai,e); End
2.2.4.2.1. Performa FP Growth Algorithm
Berikut ini adalah grafik hasil pengujian dengan menggunakan database yang terdiri dari 491403 transaksi dan 100 barang.
2.2.4.3. Vertical Format Algorithm
Dari penjelasan di atas, dapat dilihat bahwa terdapat beberapa kekurangan pada algoritma tradisional tersebut. Algoritma apriori adalah algoritma dengan format horizontal yang digunakan untuk mencari frequent itemset. Algoritma ini secara berulang men-scan database untuk mendapatkan tingkat support pada set kandidat. Beberapa algoritma apriori yang sudah diimproved menawarkan pengurangan waktu perbandingan antara set kandidat dan record transaksi. Tetapi apabila proses perbandingan tersebut dapat dihilangkan, maka akan membuat performa menjadi meningkat drastis.
Vertical Format Algorithm adalah sebuah algoritma baru yang diciptakan
oleh Yi-ming Gou dan Zhi-jun Wan dari Universitas Teknik Liaoning, Huludao, China dengan mencari frequent itemset dengan format vertikal. Algoritma ini melakukan scanning database hanya satu kali untuk mendapatkan frequent
1-itemset dan untuk langkah selanjutnya tidak perlu dilakukan scan terhadap
database lagi.
Keuntungan dari algoritma ini adalah dapat menentukan itemset
non-frequent sebelum generate itemset kandidat sehingga dapat menghemat waktu.
Setiap id transaksi pada k-itemset membawa informasi yang lengkap yang dapat mengkalkulasi tingkat support, sehingga tidak perlu lagi melakukan scan
database untuk mencari tingkat support dari (k+1) itemsets.
2.2.4.3.1. Cara Kerja Vertical Format Algorithm
Pada awalnya dilakukan scanning database untuk mendapatkan frequent 1-itemset. Kemudian merubah format horizontal menjadi format vertikal pada
frequent 1-itemset tersebut. Langkah selanjutnya adalah dengan melakukan “operasi AND” untuk setiap elemen dari frequent itemset tersebut dan simpan hasilnya. Jika hasilnya melebihi minimal support, maka kita mendapatkan kandidat set untuk Ck+1, dan dilakukan “operasi AND” berikutnya dan dilakukan secara berulang-ulang sampai mendapatkan situasi seperti berikut ini:
‐ Hanya tersisa satu frequent itemset dan tidak mungkin dapat digunakan “operasi AND” lagi.
‐ Seluruh hasil dari “operasi AND” kurang dari minimum support.
Berikut di bawah ini adalah pseudocode yang digunakan oleh algoritma Vertical Fomat :
Output : Lk
L1 = find frequent 1-itemsets (D); For(k=2; | Lk | > 1; k++) Lk = P(Lk-1, minsup)
RETURN UkLk
Procedure P(D, min_sup) { Lk = null;
For(i=0; i<Lk-1.count; i++)
For(j=i+1; j<Lk-1.count; j++) {
If(Lk-1[i].strung(k-2)=Lk-1[j].string(k-2)) Then item.Tid=Lk-1[i].Tid ∩ Lk-1[j].Tid If(item.Tid.length>=min_sup)
Then Lk.add(item) }
Gambar 2.12. Flowchart Algoritma Vertical Format
Sebagai contoh, digunakan tabel transaksi dibawah ini dengan menentukan
minimum support yang digunakan adalah 2.
Item set TID set I1 1,4,5,7,8,9 (b1) I2 1,2,3,4,6,8,9 (b2) I3 3,5,6,7,8,9 (b3) I4 2,4 (b4) I5 1,8 (b5)
Hasilnya adalah : b1∩ b2 = {1, 4, 8, 9} Jumlah=4; b1∩ b3 = {5, 7, 8, 9} Jumlah=4; b1∩ b4 = {4} Jumlah=1 < 2 (hapus); b1∩ b5 = {1, 8} Jumlah=2; b2∩ b3 = {3, 6, 8, 9} Jumlah=4; b2∩ b4 = {2, 4} Jumlah=2; b2∩ b5 = {1, 8} Jumlah=2; b2∩ b3 = φ (hapus); b2∩ b4 = {8} Jumlah=1 < 2 (hapus); b2∩ b5 = φ (hapus);
Atur data di atas untuk mendapatkan frequent 2-itemset seperti terlihat pada tabel di bawah ini dan jika item pertama pada itemsetnya sama, hubungkan dan lakukan operasinya : Item set TID set I1I2 1,4,8,9 (b1) I1I3 5,7,8,9 (b2) I1I5 1,8 (b3) I2I3 3,6,8,9 (b4) I2I4 2,4 (b5) I2I5 1,8 (b6)
Tabel 2.3. Tabel II Database Transaksi
Hasilnya adalah :
b1∩ b3 = {1, 8} Jumlah=2;
b2∩ b3 = {8} Jumlah=1 < 2 (hapus); b4∩ b5 = φ (hapus);
b4∩ b6 = {8} Jumlah=1 < 2 (hapus); b5∩ b6 = φ (hapus);
Langkah selajuntnya adalah sama dengan langkah sebelumnya, atur kembali data di atas untuk mendapatkan frequent 3-itemset seperti pada tabel di bawah ini :
Item set TID set I1I2I3 8,9 (b1) I1I2I5 1,8 (b2)
Tabel 2.4. Tabel III Database Transaksi
Hasilnya adalah :
b1∩ b2 = {8} Jumlah=1 < 2 (hapus);
Sehingga maksimal frequent itemsetnya adalah {I1, I2, I3} dan {I1, I2, I5}.
2.2.4.3.2. Performa Vertical Format Algorithm
Pada saat menggunakan data set klasik yaitu tabel jamur (Mushroom
Database) sebagai test data, yang berisikan 8124 instance, 23 atribut dan 127
macam nilai. Ketika tingkat support tinggi, algoritma apriori membutuhkan waktu yang singkat untuk berjalan. Akan tetapi algoritma vertical format memakan waktu lebih sedikit dibandingkan algoritma apriori. Sehingga dengan pengurangan tingkat support maka performa algoritma ini akan menjadi lebih baik.
Dengan menggunakan tingkat support sebesar 25% dan data set yang
terdiri dari 8124 instance maka didapatkan hasil simulasi penelitian seperti pada gambar dibawah ini :
Gambar 2.13 Hasil Perbandingan dengan menggunakan tingkat support berbeda
Dengan adanya hasil eksperimen tersebut, dapat menunjukkan bahwa algoritma dengan menggunakan vertical format hasilnya lebih baik daripada dengan menggunakan algoritma apriori.