9
Deteksi User Berpengaruh Berdasarkan Kombinasi Fitur Popularitas User Dan
Topik Monomorphism Pada Data Twitter untuk Promosi Produk
Satrio Hadi Wijoyo1, Chastine Fatichah2, Diana Purwitasari3 Program Studi Teknik Informatika, Fakultas Teknologi Informasi,
Institut Teknologi Sepuluh Nopember
Email: satriohawe@gmail.com1, chastine.fatichah@gmail.com2, diana.purwitasari@gmail.com3
ABSTRAK
User berpengaruh merupakan sebuah user yang biasanya populer di twitter dengan ditandai memiliki banyak follower, isi tweet atau pendapatnya sering dikutip atau diikuti oleh akun lainnya dengan ditandai tweet yang sering di retweet, dan namanya sering disebut atau
di-mention. Akan tetapi, ketertarikan tweet user berpengaruh tidak dapat dilihat hanya dari fitur
retweet dan mention saja, melainkan dapat dilihat dari fitur topik monomorphism.Berdasarkan permasalahan tersebut, suatu metode diusulkan kombinasi fitur popularitas user dan topik
monomorphism untuk mendeteksi user berpengaruh pada data twitter untuk promosi produk. Berdasarkan hasil ujicoba, nilai rata-rata akurasi algoritma fuzzy inference system dari produk Iphone sebesar 75,75%, produk Samsung sebesar 79,25%, dan produk Apple sebesar 74,5%. Hasil ini menunjukkan bahwa deteksi user berpengaruh berdasarkan kombinasi fitur popularitas user
dan topik monomorphism menghasilkan keluaran cukup baik.
Kata Kunci: Deteksi user berpengaruh, fitur popularitas user, topik monomorphism fuzzy inference system,twitter.
ABSTRACT
User influence is a user who is usually popular on twitter with marked has many followers, tweet contents or opinions often quoted or followed by other accounts with tweets that are often marked retweet, and his name is often referred to, or mention. However, interest tweet user influence can not be seen only from the feature retweet and mention only, but can be seen from the features monomorphism topic. Based on this problems, a method is proposed combination of features user popularity and monomorphism topic to detect an user influence on the data user twitter for product promotion. Based on the test results, the average value of the accuracy of the algorithm fuzzy inference system of products amounted to 75.75% Iphone, Samsung products amounted to 79.25%, and 74.5% of Apple products. These results indicate that the effect on user detection based on a combination of features user popularity and monomorphism topic produce output is quite good.
Keywords: User influence detection, feature user popularity, monomorphism topic fuzzy inference system, twitter.
1. Pendahuluan
Twitter adalah salah satu platform
yang paling populer dari media sosial lainnya sebagai sumber informasi. Twitter
merupakan sebuah microblog yang dapat menyebarkan atau membagikan informasi berupa tweet dengan sangat cepat dan berbasis real-time. Tweet adalah teks tulisan 140 karakter yang ditampilkan pada halaman profil user (pengguna) [1].
Twitter telah dimanfaatkan banyak
perusahaan melakukan promosi-promosi
produk baru mereka melalui jaringan sosial. Keberhasilan perusahaan untuk promosi produk baru agar banyak pelanggan tertarik menggunakan produk mereka, tidak serta merta hanya karena
user milik perusahaan sendiri di twitter. Melainkan adanya peran aktif user
10
sebuah user yang biasanya populer di
twitter dengan ditandai memiliki banyak
follower. Selain itu, isi tweet atau pendapatnya sering dikutip atau diikuti oleh akun lainnya dengan ditandai tweet
yang sering di retweet dan namanya sering disebut atau di-mention [3].
Banyak metode telah digunakan untuk mengetahui user berpengaruh pada data twitter. Pembentukan Graph
digunakan untuk mengetahui user
berpengaruh berdasarkan perhitungan jumlah friends, jumlah followers, jumlah
mention, jumlah retweet, dan jumlah URLs posted per user [4], [5], [6], dan [7]. Penelitian tersebut menemukan bahwa jumlah followers tidak menunjukkan pengaruh signifikan pada penyebaran tweet
dari user berpengaruh. Tetapi jumlah
retweet menunjukkan pengaruh interaksi antar user. Keempat penelitian tersebut menggunakan Graph untuk mengetahui
user berpengaruh memberikan hasil yang cukup baik, akan tetapi dalam pembentukan Graph membutuhkan node
banyak. Semakin banyak node yang dibutuhkan maka semakin memakan waktu proses yang banyak.
Deteksi atau identifikasi user
berpengaruh tidak selalu menggunakan pembentukan Graph hubungan antar user.
Pada penelitian [3] menggunakan fitur popularitas user seperti fitur jumlah
follower, jumlah retweet, dan jumlah
mention. Hasil penelitian menunjukkan jika jumlah follower dari user tinggi maka menunjukkan user tersebut hanya popular di twitter. Sedangkan jika jumlah retweet
dan jumlah mention yang tinggi maka menunjukkan bahwa tweet dari user
menarik dan user tersebut memiliki pengaruh. Untuk mengetahui ketertarikan
tweet user berpengaruh terhadap suatu topik tidak dapat dilihat hanya dari fitur
retweet dan mention. Akan tetapi, tweet
user dapat diketahui dengan melihat
kesamaan (similarity) tweet user tersebut pada topik-topik tertentu.
Ketertarikan seorang individu atau
user terhadap suatu opini atau pendapat pada satu topik disebut monomorphism. Sedangkan polymorphism adalah ketertarikan seorang individu terhadap pendapat pada topik yang bervariasi [8]. Pada penelitian [9] menggunakan fitur
monomorphism vs. polymorphism, high
latency vs. Low latency, dan information inventor vs. information spreader untuk melakukan prediksi user berpengaruh di
twitter dari segi penyebaran informasi secara dinamik. Cosine similarity
digunakan untuk menghitung kesamaan antara dua topik sebagai topik similarity
dari tweet user.
Berdasarkan permasalahan tersebut, suatu metode diusulkan untuk mendeteksi user berpengaruh berdasarkan kombinasi fitur popularitas user dan topik
monomorphism pada data twitter untuk promosi produk. Selain itu, pada penelitian ini akan melakukan leveling atau tingkatan dari user berpengaruh menggunakan fuzzy
untuk mengetahui seberapakah user
tersebut berpengaruh di twitter. Dengan adanya usulan tersebut diharapkan pemilik produk atau perusahaan dapat mengetahui
user berpengaruh yang sedang popular di
twitter.
2. Deteksi User Berpengaruh pada Twitter Twitter adalah sebuah situs web yang dimiliki dan dioperasikan oleh Twitter Inc., yang menawarkan jaringan sosial berupa mikroblog sehingga memungkinkan penggunanya untuk mengirim dan membaca pesan yang disebut kicauan (tweets). Tweets adalah teks tulisan hingga 140 karakter yang ditampilkan pada halaman profil pengguna (User). Pengguna dapat melihat tweets
pengguna lain yang dikenal dengan sebutan pengikut (followers). Tweet yang menyebut nama user dan menunjukkan kemampuan user yang terlibat dengan user
lain dalam percakapan disebut mention.
11 kemampuan user yang menghasilkan
konten dengan nilai bersamaan [1].
User berpengaruh (influencer) bisa siapa saja, bukan hanya artis ataupun selebritis dunia hiburan seperti televisi dan perfileman tetapi juga pada bidang-bidang lain seperti politik, budaya, ekonomi, olahraga, dan sebagainya. Para selebriti tersebut, kemudian menggunakan twitter
sebagai media mereka menyampaikan informasi kepada para penggemarnya. Banyak user yang berperan untuk menjadikan dirinya sebagai selebriti di
twitter. Berbagai jenis profesi bisa dianggap sebagai selebriti seperti user
berpengaruh. Peran selebriti untuk mendorong banyaknya promosi produk serta kampanye periklanan di twitter. Sehingga dibutuhkan deteksi user
berpengaruhpada twitter.
User berpengaruh merupakan sebuah user yang biasanya populer di
twitter dengan ditandai memiliki banyak
follower. Selain itu, isi tweet atau pendapatnya sering dikutip atau diikuti oleh akun lainnya dengan ditandai tweet
yang sering di retweet dan namanya sering disebut atau di-mention [3]. User
berpengaruh ini akan menyebarkan informasi di twitter dan nantinya diharapkan akan menyebar dan diperbincangkan banyak followers.
3. Monomorphism dan Polymorphism
Pengertian monomorphism adalah kecenderungan atau ketertarikan bagi seseorang individu terhadap opini atau pendapat untuk hanya satu topik atau tunggal topik. Sedangkan polymorphism
adalah kecenderungan atau ketertarikan suatu individu terhadap opini untuk berbagai topik atau bervariasi topik [8]. Dalam media sosial, pengguna dengan
monomorphism tinggi biasanya selalu
fokus pada satu topik yang tetap, sedangkan pengguna polymorphism tinggi akan melakukan posting berbagai topik dari waktu ke waktu. Mengetahui hal ini, pengguna media sosial bisa mendapatkan
keuntungan aplikasi dengan tujuan yang berbeda. Misal, user berpengaruh
monomorphism tinggi harus peringkatnya lebih tinggi dari user berpengaruh
polymorphism dalam aplikasi
rekomendasi. Namun, user berpengaruh
polymorphism tinggi akan lebih diinginkan untuk pengguna bertujuan untuk mengumpulkan informasi umum [9].
Cosine similarity adalah salah satu metode untuk mengukur kemiripan teks dengan menggunakan nilai cosinus sudut antara dua vektor. Konsepnya adalah jika terdapat dua vektor dokumen 𝐷𝑗 dan 𝐷𝑘 maka nilai cosinus antara dua pasangan teks tersebut dapat dihitung dengan menggunakan persamaan (1).
𝑐𝑜𝑠𝑠𝑖𝑚(𝐷⃗⃗⃗ , 𝐷𝑗 ⃗⃗⃗⃗ ) =𝑘 ∑ 𝑤𝑗ℎ 𝑚
ℎ=1 × 𝑤𝑘ℎ
√∑ (𝑤𝑚𝑗=1 𝑗ℎ)2 × √∑ (𝑤𝑚𝑗=1 𝑘ℎ)2 (1)
dimana 𝐷𝑗 dan 𝐷𝑘 adalah tweet yang dilakukan user, 𝑤𝑗ℎ adalah bobot dari term ke-h pada 𝐷𝑗, 𝑤𝑘ℎ adalah bobot dari
tweet term ke-h pada 𝐷𝑘, dan h adalah indek dari term yang didapatkan.
4. Metodologi Penelitian 4.1. Metode yang Diusulkan
Pada bagian ini akan dibahas tentang deteksi user berpengaruh berdasarkan kombinasi fitur popularitas
user dan topik monomorphism pada data
twitter untuk promosi produk. Desain sistem dalam penelitian ini terdiri atas tiga bagian utama yaitu: praproses (preprocessing), ekstraksi fitur popularitas
12
Gambar 1. Diagram Metode Penelitian
4.1.1. Data Uji Coba
Tahap berikutnya adalah pengumpulan data yang digunakan dalam penelitian ini adalah data tweet atau dokumen tweet dengan memanfaatkan
Search API yang disediakan oleh twitter.
Sebuah aplikasi dibangun untuk mengambil data tweet tersebut dari twitter
dengan menggunakan search API dengan dibatasi wilayah geografis indonesia untuk mendapatkan data bahasa Indonesia. Dengan menggunakan search API ini, diharapkan mendapatkan berbagai informasi yang dibutuhkan. Data tweet
hanya dibatasi topik-topik produk dari
brand antara lain : Apple, Iphone, dan Samsung. Data tweet dikumpulkan atau dikoleksi selama 2 bulan dengan rentang dari tanggal 17 Maret 2015 sampai 16 Juni 2015.
Gambar 2. menunjukkan contoh
tweet sebuah produk dari brand. Pada suatu tweet tersebut dapat informasi jumlah retweet secara langsung. Contohnya pada tweet yang dilakukan user
dari kompas TV, dapat diperoleh jumlah
retweet sebanyak 7. Berarti tweet tersebut sudah di retweet oleh 7 orang. Pada penelitian ini, jumlah retweet dan jumlah
mention diperoleh dari informasi teks
tweet.
Gambar 2. Contoh Tweet Yang Sebuah Produk
4.1.2. Tahap Praproses Data
Setelah diperoleh dataset yang dibutuhkan untuk penelitian ini. Kemudian dilakukan tahap praproses data untuk menyiapkan data tweet agar siap diproses pada tahap selanjutnya. Tahap praproses dalam penelitian ini terdiri tiga bagian yaitu : pembersihan kata (cleaning term), pemenggalan kata (tokening term), penghapusan stopword (stopword removal), dan perhitungan bobot tf_idf.
Term Frequency Inverse Document
Frequency (tf_idf) adalah konsep
pembobotan term pada sebuah dokumen. Metode ini melakukan perbandingan antara frekuensi kemunculan term j pada kalimat i (𝑡𝑓𝑖𝑗) dengan frekuensi kalimat yang mengandung term j (𝑑𝑓𝑗). Bobot
tf_idf dari term j dapat dihitung dengan menggunakan persamaan (2), dimana 𝑡𝑓𝑖𝑗 adalah frekuensi kata term ke-i pada dokumen ke-j. Konsep tersebut memberikan pengukuran terhadap pentingnya kata term ke-i pada dokumen tersebut. Sedangkan 𝑖𝑑𝑓𝑖 ditentukan melalui persamaan (3), dimana N adalah jumlah dokumen, 𝑑𝑓𝑖 adalah jumlah dari dokumen yang mengandung kata term
ke-i.
𝑡𝑓_𝑖𝑑𝑓𝑖𝑗 = 𝑡𝑓𝑖𝑗× 𝑖𝑑𝑓𝑖 (2)
13 4.1.3. Ekstraksi Fitur Popularitas User
Perhitungan retweet pada penelitian ini diperoleh dari teks atau isi tweet. Tweet user yang diposting ulang dengan adanya tanda atau simbol tambahan seperti RT, retweeting, retweet, dan lainnya, serta simbol @nama_user [3]. Bobot retweet
adalah menghitung jumlah retweet dari
tweet user berpengaruh yang terdapat pada
twitter. Perhitungan bobot retweet dari
tweet user mengikuti persamaan (4) seperti berikut.
𝑤1(𝑢𝑠𝑒𝑟𝑖) =max (𝑟𝑒𝑡𝑤𝑒𝑒𝑡(𝑢𝑠𝑒𝑟∑ 𝑟𝑒𝑡𝑤𝑒𝑒𝑡(𝑢𝑠𝑒𝑟𝑖)
𝑝)) (4)
dimana 𝑤1(𝑢𝑠𝑒𝑟𝑖) merupakan bobot
retweet dari user ke-i, ∑ 𝑟𝑒𝑡𝑤𝑒𝑒𝑡(𝑢𝑠𝑒𝑟𝑖) merupakan jumlah retweet dari user ke-i,
dan max (𝑟𝑒𝑡𝑤𝑒𝑒𝑡(𝑢𝑠𝑒𝑟𝑝)) merupakan nilai maksimal dari jumlah retweet dari sebuah koleksi retweet user, dan p
merupakan jumlah user.
Bobot mention adalah menghitung jumlah mention dari user yang terdapat pada tweet. Nama user yang disebut dalam
tweet user lain dengan adanya tanda atau simbol tambahan seperti @ serta nama dari
user tersebut. Perhitungan bobot mention
mengikuti persamaan (5) seperti berikut.
𝑤2(𝑢𝑠𝑒𝑟𝑖) =max (𝑚𝑒𝑛𝑡𝑖𝑜𝑛(𝑢𝑠𝑒𝑟∑ 𝑚𝑒𝑛𝑡𝑖𝑜𝑛(𝑢𝑠𝑒𝑟𝑖)
𝑝)) (5)
dimana 𝑤2(𝑢𝑠𝑒𝑟𝑖) merupakan bobot
mention dari user ke-i, ∑ 𝑚𝑒𝑛𝑡𝑖𝑜𝑛(𝑢𝑠𝑒𝑟𝑖) merupakan jumlah mention nama dari user
ke-i, dan max (𝑚𝑒𝑛𝑡𝑖𝑜𝑛(𝑢𝑠𝑒𝑟𝑝)) merupakan nilai maksimal dari jumlah
mention dari koleksi 𝑚𝑒𝑛𝑡𝑖𝑜𝑛user.
4.1.4. Ekstraksi Fitur Topik Monomorphism
Pada penelitian ini untuk mengetahui user berpengaruh yang termasuk topik monomorphism atau
polymorphism dalam melakukan tweet
dihitung dengan cara lain, tidak dihitung menggunakan cosine similarity. Akan tetapi, dengan cara menghitung bobot kemunculan user dalam klaster topik
tweet. Adapun proses ekstraksi fitur topik
monomorphism terdapat 2 tahapan, yaitu :
tahap klasterisasi tweet dan perhitungan bobot kemunculan user dalam klaster.
Pada tahap klasterisasi ini digunakan untuk mengkelompokkan atau membagi koleksi tweet ke dalam sejumlah
cluster. Algoritma klasterisasi yang digunakan dalam penelitian ini adalah algoritma klasterisasi hierarkikal
agglomerative. Setelah itu, dilakukan perhitungan bobot kemuculan user ini mengadopsi dari konsep perhitungan bobot
tf_idf dengan merubah nama variabel agar tidak sama dengan variabel sebelumnya. Sehingga pembobotan kemunculan user
dalam klaster disebut User Frequency Inverse Cluster Frequency (uf_icf). Metode ini melakukan perbandingan antar frekuensi kemunculan user i pada cluster j
(𝑢𝑓𝑖𝑗) dengan frekuensi cluster yang mengandung user i (𝑐𝑓𝑖). Bobot uf_icf dari
user i dapat dihitung dengan menggunakan persamaan (6).
𝑢𝑓_𝑖𝑐𝑓𝑖𝑗 = 𝑢𝑓𝑖𝑗 × 𝑖𝑐𝑓𝑖 (6)
dimana 𝑢𝑓𝑖𝑗 adalah frekuensi user ke-i
pada cluster ke-j. Sedangkan 𝑖𝑐𝑓𝑖 ditentukan melalui persamaan (7) berikut ini.
𝑖𝑐𝑓𝑖 = log (𝑐𝑓𝑁𝑖) (7)
dimana 𝑐𝑓𝑖 adalah jumlah dari cluster yang mengandung user ke-i dan N adalah jumlah cluster. Hasil dari perhitungan bobot kemunculan user berupa koleksi
user (𝑢𝑗) dan frekuensinya (𝑓𝑖𝑗), dimana 𝑝 merupakan total jumlah user sebuah
cluster.
Setelah didapatkan bobot uf_icf
masing-masing user dalam klaster. Kemudian dilakukan perhitungan bobot topik monomorphism dari user.
Perhitungan bobot topik monomorphism
adalah menghitung jumlah bobot uf – icf
dari user yang terdapat pada cluster. Perhitungan bobot topik monomorphism
mengikuti persamaan (8) seperti berikut.
𝑤3(𝑢𝑠𝑒𝑟𝑖) =max (𝑢𝑓_𝑖𝑐𝑓(𝑢𝑠𝑒𝑟∑ 𝑢𝑓 _𝑖𝑐𝑓(𝑢𝑠𝑒𝑟𝑗)
14
user tersebut termasuk topik
monomorphism.
4.1.5. Implentasi Fuzzy Inference System
untuk Deteksi User Berpengaruh
FIS (Fuzzy Inference System) untuk deteksi user berpengaruh mempunyai 3 variabel input dan 1 variabel output. Variabel input terdiri atas rasio retweet,
rasio mention, dan monomorphism. Sedang untuk variabel keputusan atau user
berpengaruh didapatkan dari perbandingan nilai variabel rasio retweet, rasio mention,
dan nilai monomorphism.
Fungsi derajat keanggotaan linear turun digunakan untuk merepresentasikan himpunan fuzzy rendah dan fungsi derajat keanggotaan linear naik untuk himpunan
fuzzy tinggi. Fungsi derajat keanggotaan segitiga digunakan untuk merepresentasikan himpunan fuzzy normal. Untuk fungsi keanggotaan rasio retweet
memiliki label L (rendah), M (sedang), dan H (tinggi). Nilai fungsi keanggotaan dari rasio retweet mengikuti persamaan (9).
𝜇𝑅𝑡𝐿(𝑤1) = {
Nilai fungsi keanggotaan dari rasio
mention mengikutin persamaan (10).
𝜇𝑀𝑒𝐿(𝑤2) = {
Nilai fungsi keanggotaan dari bobot
monomorphism mengikuti persamaan (11).
𝜇𝑀𝑒𝐿(𝑤3) = { keanggotaan dari output mengikuti persamaan (12)
Pembentukan Aturan Fuzzy, dari tiga variabel input dan sebuah variabel output, dengan melakukan analisa data terhadap batas tiap – tiap himpunan fuzzy pada tiap-tiap variabelnya maka terdapat 22 aturan
fuzzy yang akan dipkai dalam sistem ini, dengan susunan aturan IF Retweet AND Mention AND Monomomorphism THAN User Berpengaruh, contoh hasil aturan
15 Tabel 1. Contoh Aturan Fuzzy
Id Rule
Variabel Input User
Berpengaruh
Retweet Mention Mono
R1 Rendah Rendah Rendah Rendah R2 Rendah Rendah Sedang Rendah R3 Rendah Rendah Tinggi Rendah R4 Rendah Sedang Rendah Rendah R5 Rendah Sedang Sedang Sedang R6 Rendah Sedang Tinggi Rendah R7 Rendah Tinggi Rendah Tinggi R8 Rendah Tinggi Sedang Rendah R9 Rendah Tinggi Tinggi Rendah R10 Sedang Rendah Rendah Rendah R11 Sedang Rendah Sedang Rendah R12 Sedang Rendah Tinggi Rendah R13 Sedang Sedang Rendah Sedang R14 Sedang Sedang Sedang Rendah R15 Sedang Sedang Tinggi Tinggi R16 Sedang Tinggi Rendah Tinggi R17 Tinggi Rendah Rendah Rendah R18 Tinggi Rendah Sedang Sedang R19 Tinggi Rendah Tinggi Sedang R20 Tinggi Sedang Rendah Sedang R21 Tinggi Sedang Sedang Tinggi R22 Tinggi Tinggi Rendah Tinggi
Setelah didapatkan aturan inferensi untuk mendapatkan suatu himpunan fuzzy
digunakan sebagai input dari proses
defuzzifikasi. Hasil dari defuzzifikasi ini merupakan output dari sistem kendali logika fuzzy. Metode defuzzifikasi yang digunakan adalah metode centroid atau
center of area seperti pada persamaan (13).
𝑧∗= ∫ 𝜇𝑐(𝑧)𝑧𝑑𝑧
∫ 𝜇𝑐(𝑧)𝑑𝑧 (13)
4.2. Pengujian
4.2.1. Pengujian Kualitas Clustering
Pada penelitian ini yang akan digunakan untuk uji akurasi adalah
internal evaluation, secara khusus dengan menggunakan metode evaluasi Silhouette
Coefficient [11] (Rousseeuw, 1987).
Silhouette coefficient akan mengukur
kualitas cluster yang dihasilkan sekaligus mengindikasikan derajat kepemilikan setiap objek atau data yang berada di dalam cluster. Nilai shilhoutte dari sebuah objek berada pada rentang antara -1
sampai dengan 1. Semakin dekat nilai
silhouette objek ke 1, maka semakin tinggi derajat kepemilikan objek di dalam cluster.
Dimana objek direpresentasikan dengan
tweet. Adapun perhitungan nilai silhoutte
(𝑠(𝑖)) untuk tiap tweet menggunakan persamaan (14) dan (15).
𝑏(𝑖) = max𝐶𝑗≠𝑈{𝑑(𝑖, 𝐶𝑗)} (14) 𝑠(𝑖) =max{𝑎(𝑖),𝑏(𝑖)}𝑏(𝑖)−𝑎(𝑖) (15) dimana 𝑎(𝑖) adalah jarak kedekatan tweet
ke-i terhadap seluruh tweets yang ada di
cluster internal, yaitu cluster tempat tweet
ke-i berada. Sedangkan 𝑏(𝑖) adalah jarak kedekatan antara tweet ke-i terhadap seluruh cluster eksternal, yaitu seluruh
cluster selain cluster internal.
Nilai silhouette akan mengindikasikan derajat kepemilikian tiap objek berdasarkan 3 kriteria yaitu negatif, nol, dan positif. Nilai (𝑠(𝑖)) dengan kriteria negatif overlapping tinggi yang menunjukkan bahwa tweet ke-i tidak berada dalam cluster U. Nilai (𝑠(𝑖)) dengan kriteria nol menunjukkan bahwa
tweet ke-i adalah irisan dari cluster U dan
V. Sedangkan nilai (𝑠(𝑖)) dengan kriteria positif menunjukkan bahwa objek tepat berada pada cluster U.
Setelah didapatkan nilai (𝑠(𝑖)) untuk tiap tweet pada tiap cluster langkah selanjutnya adalah rata-rata nilai (𝑠(𝑖)) untuk tiap cluster atau yang lebih dikenal dengan Average Silhouette Width (ASW). Nilai ASW ini mampu mengindikasikan kualitas clustering. Berdasarkan range nilai ASW yang dihasilkan dibedakan menjadi 4 kriteria (Rousseeuw, 1987), yaitu : sangat baik (dengan range
0,71≤ASW≤1), sudah baik
(0,51≤ASW<0,71), cukup baik
(0,26≤ASW<0,51), dan kurang baik
(ASW<0,26).
4.2.2. Pengujian Pengukuran Kinerja Klasifikasi
16
klasifikasi semuat set data dengan benar, tetapi tidak dapat dimungkiri bahwa kinerja suatu sistem tidak bisa 100% benar. sehingga sistem klasfikasi juga harus diukur kinerjanya. Umumnya, pengukuran kinerja klasifikasi dilakukan dengan matriks konfusi (confusion matrix). Matrik konfusi merupakan tabel pencatat hasil kerja klasifikasi. Kita dapat mengetahui jumlah data dari masing-masing kelas yang diprediksi secara benar dan data yang diklasifikasikan secara salah. Kuantitas matriks konfusi dapat di ringkas manjadi dua nilai, yaitu akurasi dan laju eror. Untuk menghitung akurasi digunakan persamaan (16).
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 𝐽𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎 𝑦𝑎𝑛𝑔 𝑑𝑖𝑝𝑟𝑒𝑑𝑖𝑘𝑠𝑖 𝑠𝑒𝑐𝑎𝑟𝑎 𝑏𝑒𝑛𝑎𝑟𝐽𝑢𝑚𝑙𝑎ℎ 𝑝𝑟𝑒𝑑𝑖𝑘𝑠𝑖 𝑦𝑎𝑛𝑔 𝑑𝑖𝑙𝑎𝑘𝑢𝑘𝑎𝑛 (16)
5. Hasil dan Pembahasan
Pada bab ini dijelaskan mengenai skenario pengujian beserta hasil pengujian yang dilakukan dan analisis hasil uji yang diperoleh. Pengujian dilakukan untuk mengetahui kualitas clustering dari algoritma hirarkikal agglomerative dan nilai akurasi dari algoritma fuzzy inference
system. Pengujian dilakukan dengan
membandingkan nilai betweenness centrality dari hasil software nodexl. Data uji coba yang digunakan pada penelitian ini data twiiter selama 25 hari sebanyak 285.883 tweet dan total user sebanyak 183.564 user.
Pada uji coba 1 menggunakan dataset produk brand samsung, iphone, dan
apple dengan jumlah masing-masing tweet
sebesar 500 tweets dan 600 tweets dari data untuk setiap produk brand. Pemberian beberapa variasi jumlah centroid (k) terhadap clustering untuk mendapatkan satu hasil clustering yang terbaik untuk proses selanjutnya. Ujicoba nilai k dimulai dari k=3 sampai k=10. Selanjutnya hasil
clustering untuk setiap nilai k akan dihitung validasinya menggunakan metode
Silhouette pada persamaan (14) dan (15).
Tabel 2. Nilai k untuk 500 Data Data
Tweet Tiap Produk Jumlah
k
AWS (500 Data) Iphone Samsung Apple 3 0.8365 0.7864 0.7456 4 0.7709 0.8538 0.8263 5 0.8169 0.8804 0.6842 6 0.6726 0.8108 0.5506 7 0.5996 0.7555 0.7404 8 0.6764 0.7484 0.6572 9 0.5951 0.6179 0.6959 10 0.5103 0.6308 0.7231
Tabel 2. menunjukkan nilai k
optimal untuk 500 dataset dan 600 dataset dari ketiga produk. Pada sampel 500 dataset yang digunakan ketiga produk menghasilkan kualitas clustering dengan
kriteria “sangat bagus”. Nilai ASW
terbesar ada pada produk Samsung sebesar 0,8804 dengan nilai k optimal adalah 5. Sedangkan untuk produk Iphone dan Apple masing-masing menghasilkan kualitas clustering dengan nilai ASW sebesar 0.8365 di k optimal adalah 3 dan nilai ASW sebesar 0.8263 di k optimal adalah 4. Nilai ASW terkecil ada pada topik produk Iphone sebesar 0.5103 dan nilai k optimal adalah 10.
Tabel 3. Nilai k untuk 600 Data Data
Tweet Tiap Produk Jumlah
k
AWS (600 Data) Iphone Samsung Apple 3 0,7773 0,7656 0,7841 4 0,8253 0,8083 0,8292 5 0,8611 0,8598 0,7463 6 0,8599 0,6880 0,7774 7 0,8232 0,6463 0,6613 8 0,7314 0,5913 0,5713 9 0,5909 0,5692 0,5009 10 0,5736 0,5038 0,5148
17 terbesar ada pada produk Iphone sebesar
0,8611 dengan nilai k optimal adalah 5. Sedangkan untuk produk Samsung dan Apple masing-masing menghasilkan kualitas clustering dengan nilai ASW sebesar 0,8598 di k optimal adalah 5 dan nilai ASW sebesar 0,8292 di k optimal adalah 4. Nilai ASW terkecil ada pada topik produk Apple sebesar 0,5009 dan nilai k optimal adalah 9.
Hasil dan analisa tentang kualitas
clustering yang telah dijelaskan dengan menggunakan metode evaluasi silhouette
dapat disimpulkan bahwa nilai ASW untuk ketiga topik produk dengan bervariasi jumlah dataset pada range 0.71≤ASW≤1 yang berarti bahwa kualitas clustering yang dihasilkan “sangat baik”.
Pada uji coba 2 menggunakan dataset produk brand samsung, iphone, dan
apple dengan jumlah masing-masing tweet
sebesar dengan jumlah data tweet dari total 5 hari pertama (dari hari ke-1 sampai hari ke-5),5 hari kedua (dari hari ke-6 sampai hari ke-10), 5 hari ketiga (dari hari ke-11 sampai hari ke-15), dan 5 hari keempat (dari hari ke-16 sampai hari ke-20) untuk setiap produk brand. Data tweet dari 5 hari pertama sebagai data training digunakan untuk mendapatkan fungsi membership
dan aturan inference dari fuzzy inference
system. Sedangkan data testing
menggunakan data tweet dari hari kedua, 5 hari ketiga, dan 5 hari keempat.
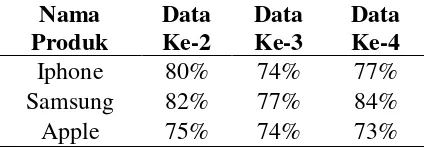
Tabel 4. Hasil Akurasi Fuzzy Inference akurasi fuzzy inference system dari produk Samsung tertinggi daripada produk Iphone dan Samsung sebesar 82% pada dataset hari ke-6 sampai hari ke-10. Sedangkan untuk nilai akurasi terendah adalah produk
Apple dengan nilai akurasi sebesar 73% pada hari ke-16 sampai hari ke-20. Hasil dan analisa tentang kualitas klasifikasi yang telah dijelaskan dengan menggunakan metode evaluasi nilai akurasidapat disimpulkan bahwa performa dari algoritma fuzzy inference system
dihasilkan “cukup baik”. Nilai rata-rata
akurasi dari produk Iphone sebesar 77%, produk Samsung sebesar 81%, dan produk Apple sebesar 74%.
6. Kesimpulan
Berdasarkan ujicoba dan analisa hasil, maka dapat ditarik kesimpulan. Hasil ujicoba pengelompokkan tweets dari ketiga produk dengan menggunakan algoritma
Agglomerative hierarchical clustering
telah memberikan kualitas clustering masuk kriteria “sangat baik” pada range
0.71≤ASW≤1. Nilai ASW 0.8804 untuk
500 Dataset pada produk Samsung dan 0,8611 untuk 600 dataset pada produk Iphone.
Hasil ujicoba klasifikasi user
berpengaruhmenggunakan algoritma fuzzy inference system dihasilkan “cukup baik”.
Nilai rata-rata akurasi dari produk Iphone sebesar 77%, produk Samsung sebesar 781, dan produk Apple sebesar 74%.
7. Saran
Pengembangan selanjutnya dari metode deteksi user berpengaruh untuk promosi produk adalah mencari atau memilih fitur yang lain yang digunakan sebagai fitur tambahan, selain fitur popularitas user dan fitur topik
monomorphism. Sehingga memungkinkan
dapat mendeteksi user berpengaruh lebih baik. Penambahan metode deteksi tweet
yang tidak sesuai dengan kata kunci yang digunakan.
Daftar Pustaka
[1] Twitter.(2015). https://support.twitter. com/. Diakses tanggal 10 Maret 2015. [2] Zhu, T., Bai, W., Bin, W., & Chuanxi,
18
influence rangking in social networks.
Information Sciences, 535-544.
[3] Cha, M., H. Haddadi, F. Benevenuto, & K. P. Gummadi. (2010). Measuring user influence in twitter: the million follower fallacy. In Proceedings of 4th international AAAI conference on weblogs and social media (ICWSM
‘10), 10-17.
[4] Weng, J., E. P. Lim, J. Jiang, & Q. He. (2010). TwitterRank: Finding topic-sensitive influential twitterers. In
Proceedings of the 3rd ACM
international conference on web
search and data mining (WSDM ‘10),
261-270.
[5] Romero, D. M., W. Galuba, S. Asur, & B. A. Huberman. (2011). Influence and passivity in social media. In
Proceedings of the 20th international conference companion on world wide
web (WWW ‘11), 113-114.
[6] Bakshy, E., J. M. Hofman, W. A. Mason, & D. J. Watts. (2011).
Everyone’s an influencer: Quantifying
influence on twitter. In Proceedings of the 4th ACM international conference on web search and data mining
(WSDM ‘11). 65-74.
[7] Luiten, M., W. A. Kosters, & F. W. Takes. (2012). Topical influence on twitter: a feature construction approach.
[8] Rogers, E. M. (2013). Diffusion of innovations. Vol. 27. Free press. [9] Jingxuan, L., W. Peng, T. Li, T. Sun,