3. METODE PENELITIAN
3.1 Jenis Penelitian
Jenis penelitian menggambarkan rencana yang akan dilaksanakan dalam penelitan ini dengan mengacu pada masalah yang telah terlebih dulu ditetapkan.
Penelitian konklusif merupakan sebuah penelititan yang mempunyai tujuan untuk menguji atau membuktikan sesuatu untuk membantu peneliti dalam memilih tindakan khusus pada tahap selanjutnya (Kuncoro, 2009: 89-90).
Sehingga, jenis penelitian yang digunakan dalam penelitian ini adalah penelitian kausal, menurut Istijanto (2008: 31-33) jenis penelitian kausal adalah sebuah penelitian yang bertujuan utama membuktikan hubungan sebab akibat atau hubungan mempengaruhi dan dipengaruhi dari variabel-variabel yang diteliti.
Penelitian ini menggunakan pendekatan kausal yaitu meliputi variabel-variabel Kualitas Produk, Kepuasan Pelanggan, Loyalitas Pelanggan.
3.2 Populasi, Sampel dan Teknik Penarikan Sampel 3.2.1 Populasi
Populasi adalah wilayah generalisasi yang terdiri atas obyek atau subyek yang mempunvai kualitas dan karakteristik tertentu yang ditetapkan oleh peneliti untuk dipelajari dan kemudian ditarik kesimpulan (Sugiyono, 2007: 72). Populasi dalam penelitian ini adalah pelanggan restoran Por Kee di Surabaya.
3.2.2 Sampel
Menurut Sugiyono (2007: 73) sampel adalah bagian dari jumlah dan karakteristik yang dimiliki oleh populasi tersebut. Bila populasi besar dan peneliti tidak mungkin mempelajari semua yang ada pada populasi, maka peneliti dapat menggunakan sampel yang di ambil dari populasi. Apa yang dipelajari dari sampel itu, kesimpulannya akan diberlakukan untuk populasi. Untuk itu sampel yang diambil dari populasi harus betul-betul representatif (mewakili).
3.2.3 Teknik Penarikan Sampel
Sampel ditentukan oleh peneliti berdasarkan pertimbangan masalah, tujuan, hipotesis, metode, dan instrumen penelitian, di samping pertimbangan waktu tenaga dan pembiayaan. Berdasarkan pertimbangan di atas, metode yang digunakan adalah Purposive Sampling karena peluang dari anggota populasi yang dipilih sebagai sample didasarkan pada pertimbangan dan keputusan peneliti.
Metode ini merupakan bagian dari metode Non-Probability Sampling, dimana sampel yang diambil berdasarkan kriteria – kriteria yang telah ditentukan oleh peneliti, yaitu siapa saja yang secara kebetulan bertemu dengan peneliti dan memenuhi kriteria – kriteria dapat digunakan sebagai sampel (Malhotra, 2007).
Karakteristik dari sampel penelitian ini adalah Konsumen restoran Por Kee di Surabaya. Sampel pada penelitian ini harus memenuhi kriteria-kriteria di bawah ini :
a. Menjadi konsumen restoran Por Kee 2 bulan terakhir b. Melakukan pembelian minimal 2 kali
c. Usia > 17 tahun.
3.2.4 Ukuran sampling
Dalam SEM (Structural Equation Modeling), ukuran sampel mempunyai peranan yang penting dalam estimasi dan interprestasi hasil-hasil perhitungan SEM. SEM tidak menggunakan skor data individual yang dikumpulkan, SEM hanya menggunakan matriks kovarians data sampel sebagai input untuk menghasilkan sebuah estimated population covariance matrix. Pedoman pengukuran sampel menurut Hair dalam Ferdinand (2002:51), dapat ditentukan sebagai berikut:
1. Ukuran sampel dapat disekitar 100 – 200 sampel pada penelitian 2. Penelitian ini menyebarkan 200 responden
3. Kembali = 198 Kuesioner, tidak lengkap=14, Lengkap =184 ,terdapat 184 responden yang lengkap jawaban kuesioner.
3.3 Definisi Operasional Variabel Variabel dalam penelitian ini adalah:
1. Kualitas Produk
Kualitas Produk adalah sekumpulan ciri-ciri karakteristik dari barang dan jasa yang mempunyai kemampuan untuk memenuhi kebutuhan yang merupakan suatu pengertian dari gabungan daya tahan, keandalan, ketepatan, kemudahan pemeliharaan serta atribut-atribut lainnya dari suatu produk.
Indikator kualitas produk yang digunakan dalam penelitian ini mengacu pada teori Gaspersz (2008:119), yang terdiri dari:
1. Menu makanan yang dijual Restoran Por Kee bervariasi
2. Restoran Por Kee menawarkan porsi yang lebih banyak dari restoran babi lainnya
3. Makanan yang disajikan Restoran Por Kee tidak mudah basi saat dibawa pulang
4. Makanan Restoran Por Kee disajikan dengan cepat
5. Jika menu yang tidak sesuai dengan harapan pelanggan, karyawan mau menggantinya
6. Restoran Por Kee memiliki tatanan sajian yang menarik 7. Aroma dari iga babi bakar Restoran Por Kee sangat enak 8. Restoran Por Kee memiliki kualitas rasa yang enak 2. Kepuasan pelanggan
Kepuasan pelanggan diartikan sebagai evaluasi oleh konsumen terhadap sebuah produk atau pelayanan dengan anggapan bahwa apa yang diterimanya sesuai dengan apa yang dibutuhkan dan diharapkannya.
Indikator kepuasan pelanggan yang digunakan dalam penelitian ini mengacu pada penelitian Deng, Lu, Wei, and Zhang (2010) yang terdiri dari:
1. Saya puas terhadap variasi menu produk makanan pada Restoran Por Kee 2. Saya puas terhadap rasa makanan Restoran Por Kee
3. Loyalitas pelanggan
Loyalitas pelanggan sebagai komitmen pelanggan bertahan secara mendalam untuk berlangganan kembali atau melakukan pembelian ulang produk/jasa secara konsisten di masa yang akan datang, meskipun pengaruh situasi dan usaha-usaha pemasaran mempunyai potensi untuk menyebabkan perubahan perilaku.
Indikator loyalitas yang digunakan dalam penelitian ini mengacu pada penelitian Deng, Lu, Wei, and Zhang (2010) yang terdiri dari:
1. Saya akan kembali mengunjungi restoran Por Kee dalam waktu dekat 2. Saya akan merekomendasikan restoran Por Kee kepada orang lain
3. Saya akan mengajak orang lain untuk berkunjung makan ke restoran Por Kee
3.4 Metode dan Prosedur Pengumpulan Data
Dalam rangka pengumpulan data primer, digunakan beberapa metode yaitu:
1. Observasi
Mengadakan pengamatan langsung kepada obyek yang diteliti guna mencocokkan hasil dari wawancara sehingga mendapatkan keyakinan terhadap kebenaran data.
2. Kuesioner
Teknik pengumpulan data yang dilakukan oleh peneliti berdasarkan daftar pertanyaan yangtelah disiapkan
3.5 Teknik Analisis Data
Analisis data yang digunakan dalam penelitian ini adalah The Structural Equation Modeling (SEM) dari paket software statistik AMOS dalam model dan pengujian hipotesis. Model persamaan structural, Structural Equation Modeling (SEM) adalah sekumpulan teknik-teknik statistical yang memungkinkan pengujian sebuah rangkaian hubungan relative “rumit” secara simultan. Hubungan yang rumit itu dapat dibangun antara satu atau beberapa variabel dependen dengan satu atau beberapa variabel independen. Masing-masing variabel dependen dan
independent dapat berbentuk faktor (atau konstruk, yang dibangun dari beberapa variabel indikator).
Keunggulan aplikasi Structural Equation Modeling (SEM) dalam penulisan manajemen adalah karena kemampuannya untuk mengkonfirmasi dimensi-dimensi dari sebuah konsep atau faktor (yang sangat lazim digunakan dalam manajemen) serta kemampuannya untuk mengukur pengaruh hubungan- hubungan secara teoritis Ferdinand (2002).
Sebuah pemodelan SEM yang lengkap pada dasarnya terdiri dari Measurement Model dan Structural Model. Measurement Model atau model pengukuran ditujukan untuk mengkonfirmasi sebuah dimensi atau faktor berdasarkan indikator-indikator empirisnya. Structural Model adalah model mengenai struktur hubungan yang membentuk atau menjelaskan kausalitas antara konstruk Ferdinand (2002).
Menurut Hair, et al. (1995) dan Ferdinand (2002), ada tujuh langkah yang harus dilakukan apabila menggunakan Structural Equation Modeling (SEM), yaitu:
1. Pengembangan model berbasis teori
Model teoritis dikembangkan dari telaah pustaka dan dijabarkan dalam bentuk model penelitian. Penjabaran model ini dikembangkan sesuai dengan permasalahan yang ada. Penarikan hipotesis akan tampak jelas bila eksplorasi ilmiah yang intens dilakukan. Sehingga akan tampak justifikasi yang kuat dalam penarikan hipotesis. Begitu pula dengan indikator-indikator dalam tiap variabel akan tampak pada saat eksplorasi ilmiah;
2. Pengembangan diagram alur (path diagram) untuk menunjukkan hubungan kausalitas.
Model teoritis yang telah dibentuk dari eksplorasi ilmiah akan dinyatakan dalam bentuk path diagram. Variabel-variabel yang dikemukakan punya telaah teoritis yang cukup untuk menyatakan suatu hubungan. Path diagram akan
yang datanya harus dicari melalui penelitian lapangan. Dalam SEM variabel ini digambarkan dalam bentuk persegi, (2) Variabel laten (Construct/Unobserved Variables) merupakan variabel bentukan yang dibentuk melalui indikator- indikator yang diamati dalam dunia nyata. Dalam SEM variabel ini digambarkan dalam bentuk elips.
Konstruk-konstruk yang dibangun dalam diagram alur dapat dibedakan menjadi dua, yaitu:
1) Konstruk Eksogen (Exogenous Constructs)
Konstruk Eksogen dikenal juga sebagai sources variables atau independent variables yang tidak diprediksi oleh variabel yang lain dalam model. Konstruk Eksogen adalah konstruk yang dituju oleh garis dengan satu ujung panah.
2) Konstruk Endogen (Endogenous Constructs)
Konstruk Endogen adalah konstruk yang diprediksikan oleh satu atau beberapa konstruk. Konstruk endogen dapat memprediksi satu atau beberapa konstruk endogen lainnya, tetapi konstruk eksogen hanya dapat berhubungan kausal dengan konstruk endogen.
3. Konversi diagram alur ke dalam persamaan
Persamaan model pengukuran digunakan untuk mengukur seberapa kuat struktur dari dimensi-dimensi yang membentuk sebuah variabel laten.
4. Memilih jenis input matriks dan estimasi model yang diusulkan
Model persamaan struktural berbeda dari teknik analisis multivariat lainnya, SEM hanya menggunakan data input berupa matriks varian / kovarian atau matriks korelasi. Data mentah observasi individu dapat dimasukkan dalam program AMOS, tetapi program AMOS akan merubah dahulu data mentah menjadi matriks kovarian atau matriks korelasi. Analisis terhadap data outlier harus dilakukan sebelum matriks kovarian atau korelasi dihitung.
Pada awalnya model persamaan struktural diformulasikan dengan menggunakan input matriks varian / kovarian (sehingga juga dikenal dengan
covariance structural analysis). Matriks kovarian memiliki kelebihan daripada matriks korelasi dalam memberikan validitas perbandingan antara populasi yang berbeda atau sampel yang berbeda. Namun demikian interpretasi hasil lebih sulit jika menggunakan matriks kovarian oleh karena nilai koefisien harus diinterpretasikan atas dasar unit pengukuran konstruk. Matriks korelasi memiliki range umum yang memungkinkan membandingkan langsung koefisien dalam model.
Walaupun demikian matriks korelasi sekarang mendapatkan popularitas di banyak penggunaan. Matriks korelasi dalam model persamaan struktural tidak lain adalah standardize varian / kovarian. Penggunaan korelasi cocok jika tujuan penelitiannya hanya untuk memahami pola hubungan antar konstruk, tetapi tidak menjelaskan total varian dari konstruk. Penggunaan lain adalah untuk membandingkan berbagai variabel yang berbeda, oleh karena dengan matriks kovarian dipengaruhi oleh skala pengukuran. Koefisien yang diperoleh dari matriks korelasi selalu dalam bentuk standardized unit sama dengan koefisien beta pada persamaan regresi dan nilainya berkisar antara – 1.0 dan + 1.0.
Teknik estimasi model persamaan struktural dilakukan dengan Maximum Likelihood Estimation yang lebih efisien dan unbiased jika asumsi normalitas multivariat dipenuhi.
5. Menilai identifikasi model structural
Selama proses estimasi berlangsung dengan program komputer, sering didapat hasil estimasi yang tidak logis atau meaningless dan hal ini berkaitan dengan masalah identifikasi model structural. Problem identifikasi adalah ketidakmampuan proposed model untuk menghasilkan unique estimate. Cara melihat ada tidaknya problem identifikasi adalah dengan melihat hasil estimasi yang meliputi:
a. Adanya nilai standar error yang besar untuk satu atau lebih koefisien.
b. Ketidakmampuan program untuk invert information matrix.
Jika diketahui ada problem identifikasi maka ada tiga hal yang harus dilihat:
a. Besarnya jumlah koefisien yang diestimasi relative terhadap jumlah kovarian atau korelasi, yang diindikasikan dengan nilai degree of freedom yang kecil.
b. Digunakannya pengaruh timbal-balik atau resiprokal antar konstruk.
c. Kegagalan dalam menetapkan nilai tetap (fix) pada skala konstruk.
6. Evaluasi Kriteria Goodness-of-Fit
Sebelum dilakukan evaluasi kesesuaian model (Goodness-of-fit), data yang akan digunakan dalam analisis ini harus diuji terlebih dahulu, apakah memenuhi asumsi-asumsi SEM atau tidak. Asumsi-asumsi tersebut meliputi Ferdinand (2002) :
a. Ukuran sampel, ketentuan jumlah sampel minimum adalah 100, dengan perbandingan 5 observasi untuk setiap estimated parameter Hair et al. dalam Ferdinand (2002).
b. Normalitas dan Linearitas, diuji dengan menggunakan metode statistik dengan mengamati skewness value dari data yang digunakan.
c. Outliers, terdapat dua macam outliers, yaitu Univariate outliers diuji dengan z-score (observasi yang mempunyai z-score ≥ 3 dikategorikan sebagai outlier) dan Multivariate outliers diuji dengan Mahalanobis distance.
Setelah pengujian data selesai, langkah selanjutnya adalah melakukan evaluasi kesesuaian model. Pengujian kesesuaian model ini dilakukan dengan menggunakan beberapa indeks kesesuaian (fit index) ntuk mengukur “kebenaran”
model yang diajukan. Indeks kesesuaian yang digunakan antara lain adalah Ferdinand (2002):
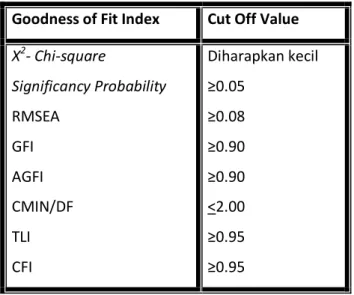
a. X² - Chi square statistic
Model yang diuji dipandang baik atau memuaskan apabila nilai chi- squarenya rendah. Semakin kecil nilai X² semakin baik model itu dan diterima berdasarkan probabilitas cut off value sebesar p>0.05 atau p>0.10 Hulland, et al (1996).
b. RMSEA (The Root Mean Square Error of Approximation)
Merupakan sebuah indeks yang dapat digunakan untuk mengkompensasi chi-square statistic dalam sampel yang besar Baumgartner dan Homburg
(1996). Nilai RMSEA menunjukkan nilai goodness-of-fit yang dapat diharapkan bila model diestimasi dalam populasi Hair, et al (1995). Nilai RMSEA yang lebih kecil atau sama dengan 0.08 merupakan indeks untuk dapat diterimanya model yang menunjukkan sebuah close fit dari model tersebut berdasarkan degrees of freedom GFI (Goodness of Fit Index) Merupakan ukuran non statistical yang mempunyai rentang nilai antara 0 (poor fit) sampai dengan 1.0 (perfect hit). Nilai yang tinggi dalam indeks ini menunjukkan sebuah “better fit”, Browne dan Cudeck (1993).
c. AGFI (Adjusted Goodness Fit Index)
Tingkat penerimaan yang direkomendasikan adalah bila AGFI mempunyai nilai sama dengan atau lebih besar dari 0.90 Hair, et al (1996). Nilai sebesar 0.95 dapat diinterpretasikan sebagai tingkatan yang good overall model fit (baik) sedangkan besaran nilai antara 0.90-0.95 menunjukkan tingkatan adequate fit (cukup) Hulland, et al (1996).
d. CMIN/DF
Merupakan the minimum sample discrepancy function (CMIN) yang dibagi dengan degree of freedom-nya menghasilkan indeks CMIN/DF, yang umumnya dilaporkan oleh para peneliti sebagai salah satu indikator untuk mengukur tingkat fitnya sebuah model. CMIN/DF merupakan statistic chi-square, X² dibagi dengan DF-nya sehingga disebut X² - relatif.
Nilai X² - relatif kurang dari 2.0 atau 3.0 adalah indikasi dari acceptable fit antara model dan data Arbuckle (1997).
e. TLI (Tucker Lewis Index)
Merupakan sebuah alternatif incremental fit index yang membandingkan sebuah model yang diuji terhadap sebuah baseline model Baumgartner dan Homburg, (1996), dimana nilai yang direkomendasikan sebagai acuan diterimanya sebuah model adalah ≥0.95 Hair, et al (1995) dan nilai yang sangat mendekati 1 menunjukkan a very good fit Arbuckle (1997).
f. CFI (Comparative Fit Index)
Indeks-indeks yang dapat digunakan untuk menguji kelayakan sebuah model adalah seperti yang diringkas dalam tabel berikut ini.
Tabel 3.1 Goodness-of-Fit Index Goodness of Fit Index Cut Off Value
X2- Chi-square
Significancy Probability RMSEA
GFI AGFI CMIN/DF TLI CFI
Diharapkan kecil
≥0.05
≥0.08
≥0.90
≥0.90
<2.00
≥0.95
≥0.95 Sumber: Ferdinand, 2002