METODE K-MEANS
Diajukan untuk memenuhi salah satu syarat memperoleh gelar Sarjana Komputer
Disusun oleh:
Nama Nurhali saepudin NIM : 311510151
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS TEKNIK
UNIVERSITAS PELITA BANGSA KABUPATEN BEKASI
2019
i
iii
KATA PENGANTAR
Dengan memanjatkan puji syukur kehadirat Allah SWT. Tuhan Yang Maha Pengasih dan Maha Penyayang yang telah melimpahkan segala rahmat, hidayah dan inayah-Nya kepada penulis sehingga dapat menyelesaikan laporan tugas akhir skripsi yang berjudul “Penerapan Data Mining Terhadap Minat Siswa Dalam Mata Pelajaran Matematika Dengan Metode K-Means” laporan ini di susun untuk memenuhi salah satu syarat guna menyelesaikan pendidikan S1 (Strata Satu) Program Studi Teknik Informatika di Universitas Pelita Bangsa Cikarang.
Pada kesempatan kali ini, penulis ingin menyampaikan rasa terima kasih kepada pihak terkait. Karena penulis menyadari tanpa adanya uluran dan bantuan mereka belum tentu laporan ini dapat diselesaikan, pihak-pihak tersebut adalah :
1. Hamzah M.Mardi Putra, S.K.M, M.M sebagai Rektor Universitas Pelita Bangsa.
2. Putri Anggun Sari S.Pt.,M.Si selaku Dekan Fakultas Teknik Universitas Pelita Bangsa.
3. Aswan Sunge, S.E., M.Kom selaku Ketua Program Studi Teknik Informatika Universitas Pelita Bangsa.
4. Ikhsan Romli, S.SI.MSC selaku Dosen Pembimbing I dan Ir. Nanang Tedi Kurniadi, M.T. selaku Dosen Pembimbing II yang memberikan ide penelitian, serta informasi referensi yang penulis butuhkan.
5. Orang Tua, Kerabat dan Keluarga yang telah memberi motivasi dan dukungan sehingga kami dapat menyelesaikan studi di Universitas Pelita Bangsa.
6. Seluruh sahabat dan rekan-rekan yang telah banyak membantu dan atas dukungannya sehingga kami dapat menyelesaikan studi di Universitas Pelita Bangsa.
Dan pada akhirnya penulis hanya dapat berdo’a serta berharap semoga apa yang telah di berikan kepada penulis dapat dibalas dengan kebaikan Allah Subkhanahu Wa Ta’ala.
Penulis menyadari bahwa penulisan skripsi ini masih jauh dari kata sempurna, maka dari itu bahwasanya penulis memohon saran positif yang bersifat
membangun untuk kemajuan penulis di masa mendatang. Akhir kata semoga laporan tugas akhir skripsi ini dapat dipergunakan sebagaimana mestinya bagi penulis serta berguna bagi pembaca pada umumnya, Aamiin Yarobbal’Alamin.
Kabupaten Bekasi, 14 Januari 2020
Penulis
vii ABSTRAK
Kemampuan matematika yang diperlukan untuk menguasai dan menciptakan teknologi di masa depan, menjadikan matematika yang kuat perlu dibina sejak dini. Tujuan penelitian ini adalah Menerapkan metode K-Means untuk mengelompokan minat siswa terhadap mata pelajaran matematika dan untuk mendapatkan akurasi yang tepat dan cepat dalam mengelompok kan minat siswa terhadap mata pelajaran matematika menggunakan metode K-Means. Metode yang digunakan yaitu dengan teknik data mining menggunakan algoritma K- Means. Proses ini menghasilkan 2 cluster yaitu ( minat ) Matematika dan ( kurang minat ) matematika, dengan menggunakan teknik data mining menggunakan algoritma K-Means, dan akurasi diukur dengan Davies Bouldin Index. Pengujian menggunakan validasi DBI (Davies Bouldin Index) diperoleh nilai untuk tiap-tiap cluster. Untuk kelas 10 pengujian cluster 1 menghasilkan nilai DBI 0.941 dan cluster 2 nilai DBI 0.335. Dari perhitungan Davies Bouldin Index (DBI) dapat disimpulkan bahwa jika semakin kecil nilai Davies Bouldin Index (DBI) yang diperoleh (non negatif >= 0) maka cluster tersebut semakin baik.
Kata kunci : Data mining, Clustering, K-Means, Matematika, SMK Binamitra
viii ABSTRACT
The purpose of this mathematics is needed to design and develop future technology, to make mathematics that needs to be fostered early on. The purpose of this study is to apply the K-Means method to classify students 'interest in students' mathematics lessons in mathematics using the K-Means method. The method used is data mining techniques using the K-Means algorithm. This process produces 2 clusters, namely (mathematics) mathematics and (less interest) mathematics, using data mining techniques using the K-Means algorithm, and processing accuracy with the Bouldin Davies Index. Tests using DBI (Davies Bouldin Index) validation obtain values for each cluster. For class 10, cluster 1 testing produces DBI value 0.941 and cluster 2, DBI value 0.335.
From the calculation of Davies Bouldin Index (DBI) can determine the value if the smaller the value of Davies Bouldin Index (DBI) obtained (non negative> = 0), the better the cluster is.
Keywords: Data mining, Clustering, K-Means, mathematics, SMK Binamitra
ix DAFTAR ISI
PERSETUJUAN SKRIPSI ... i
PENGESAHAN DEWAN PENGUJI ... Error! Bookmark not defined. PERNYATAAN KEASLIAN SKRIPSI ... Error! Bookmark not defined. PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... Error! Bookmark not defined. KATA PENGANTAR ... v
ABSTRAK ... vii
ABSTRACT ... viii
DAFTAR ISI ... ix
DAFTAR GAMBAR... xiii
DAFTAR TABEL ... xiv
BAB I PENDAHULUAN ... 1
1.1 Latar belakang ... 1
1.2 Identifikasi Masalah ... 3
1.3 Rumusan Masalah... 3
1.4 Batasan Masalah ... 3
1.5 Tujuan Penelitian ... 3
1.6 Manfaat Penelitian ... 4
1.7 Sistematis Penulisan ... 4
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI ... 6
2.1 Tinjauan Pustaka ... 6
2.1.1 Pengelompokan Mahasiswa Menggunakan Algoritma K-Means ... 6
2.1.2 Penerapan K-Means Clustering Pada Data Penerimaan Mahasiswa Baru... 6
2.1.3 Implementasi Algoritma K-Means Untuk Menentukan Kelompok
Pengayaan Materi Mata Pelajaran Ujian Nasional ... 7
2.1.4 Memanfaatkan Algoritma K-Means Dalam Menentukan Pegawai Yang Layak Mengikuti Asessment Center Untuk Clustering Program SDP ... 8
2.1.5 Implementasi Algoritma K-Means Dalam Pengklasteran Mahasiswa Pelamar Beasiswa ... 8
2.1.6 Penerapan Algoritma K-Means Untuk Clustering Penilaian Dosen Berdasarkan Indeks Kepuasan Mahasiswa ... 9
2.2 Landasan Teori ... 10
2.2.1 Data Mining ... 10
2.2.2 Clustering ... 11
2.2.3 Algoritma K-Means ... 12
2.2.4 Keuntungan Algoritma K-Means ... 14
2.2.5 Kekurangan Algoritma K-Means ... 14
2.2.6 Matematika... 14
2.2.7 Faktor-Faktor Minat Siswa Terhadap Pelajaran Matematika ... 15
2.2.8 Teori Supervised Machine Learning Dan unsupervised learning ... 15
2.2.9 Validasi Davies Bouldin Index (DBI) ... 16
2.2.10 Pengertian Sistem ... 18
2.2.11 Pengertian Informasi... 18
2.2.12 Konsep Teknologi Informasi ... 19
2.2.13 Pengertian Object Oriented Programming (OOP) ... 19
2.2.14 Pengertian UML ... 21
2.2.15 Pengertian Use Case Diagram ... 22
2.2.16 Pengertian Activity Diagram ... 25
2.2.17 Pengertian Sequence Diagram ... 27
2.2.18 Pengertian Class Diagram ... 29
2.5 Pengertian PHP... 31
2.5.1 Pengertian Basis Data (Data Base) ... 31
2.5.2 Pengertian MySQL ... 32
2.5.3 Pengertian Penerapan... 32
2.5.4 Metode Pengembangan Sistem ... 32
2.5.5 XAMPP ... 34
2.5.6 Kerangka Berfikir ... 35
BAB III METODOLOGI PENELITIAN ... 35
3.1 Objek Penelitian ... 35
3.2 Jenis Data ... 35
3.3 Data Yang Digunakan ... 35
3.3.1 Data siswa ... 35
3.3.2 Metode Penelitian ... 35
3.3.3 Pengumpulan Data ( Dataset Collection ) ... 36
3.3.4 Preprocessing ... 37
3.3.5 Penerapan Algoritma ... 37
3.3.6 Evaluasi Dan Validasi Hasil ... 38
3.4 Implementasi Sistem ... 38
3.5 Analisa Berjalan ... 38
3.5.1 Use Case Diagram ... 38
3.5.2 Skenario Use Case ... 39
3.5.3 Activity Diagram ... 45
3.5.4 Sequence Diagram ... 53
3.5.5 Class Diagram ... 57
3.5.6 Perancangan basis data ... 58
3.5.7 Pengujian... 60
3.6. Kebutuhan Software dan Hardware ... 60
3.6.1 Kebutuhan Software ... 60
3.6.2 Kebutuhan Hardware ... 60
BAB IV HASIL PENGUJIAN DAN PEMBAHASAN ... 61
4.1 Dataset ... 61
4.2 Proses Pengujian ... 62
4.3 Pembahasan Hasil Pengujian ... 64
4.3.1 Pengujian Algoritma K-Means... 64
4.3.2 Pengujian Algoritma K-Means Menggunakan Sistem K-Means ... 71
4.4 Hasil Analisa ... 75
4.4.1 Hasil Davies bouldin index ( DBI ) ... 75
BAB V PENUTUP ... 84
5.1 Kesimpulan ... 84
5.2 Saran ... 84
DAFTAR PUSTAKA ... 85
LAMPIRAN ... 87
xiii
DAFTAR GAMBAR
Gambar 2. 1 Data mining sebagai dari proses knowledge discovery ... 10
Gambar 2. 2 Contoh pengelompokan dengan clustering [6]... 12
Gambar 3. 1 Metode Penelitian...36
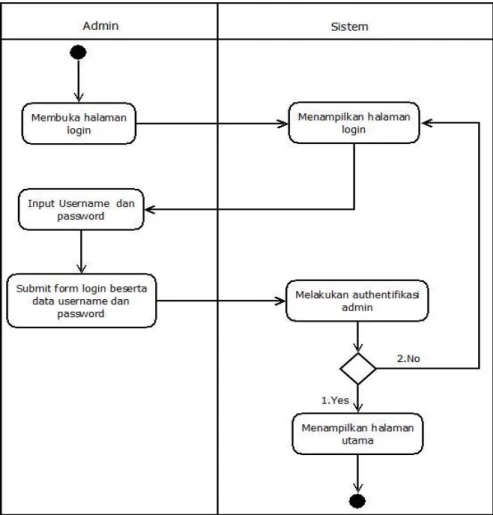
Gambar 3. 2 Skenario Use case login ... 39
Gambar 3. 3 Activity Login ... 45
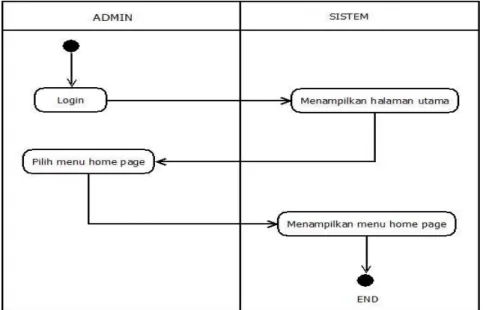
Gambar 3. 4 Activity view home ... 46
Gambar 3. 5 Activity View Profil ... 46
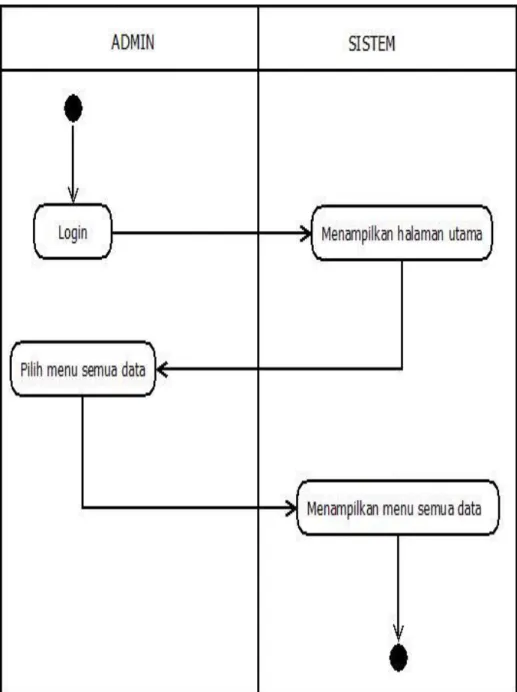
Gambar 3. 6 Activity Kelola Data ... 47
Gambar 3. 7 Import Data ... 48
Gambar 3. 8 Actifity Tambah Nama Objek ... 49
Gambar 3. 9 Tambah Input Cluster ... 50
Gambar 3. 10 Hasil Clustering ... 51
Gambar 3. 11 Hasil Diagram Clustering ... 52
Gambar 3. 12 Activity Log out... 53
Gambar 3. 13 Sequence diagram login ... 54
Gambar 3. 14 Sequence diagram view profil sekolah ... 54
Gambar 3. 15 Sequence diagram kelola data ... 55
Gambar 3. 16 Sequence diagram hasil cluster ... 56
Gambar 3. 17 Sequence diagram hasil diagram cluster ... 56
Gambar 3. 18 Sequence diagram logout ... 57
Gambar 3. 19 Class Diagram ... 58
xiv
DAFTAR TABEL
Tabel 2. 1 Daftar Simbol Use Case Diagram [24] ... 23
Tabel 2. 2 Simbol-Simbol Pada Activity Diagram[24]. ... 26
Tabel 2. 3 Simbol-simbol pada sequence diagram[24]... 27
Tabel 2. 4 Daftar Simbol Class Diagram[24] ... 30
Tabel 2. 5 Kerangka Berfikir... 35
Tabel 3.1 Data Siswa Kelas 10...37
Tabel 3. 2 Skenario Use case login ... 39
Tabel 3. 3 Skenario Usecase view Home ... 40
Tabel 3. 4 Skenario Usecase view profil ... 40
Tabel 3. 5 Skenario Usecase Kelola Data ... 41
Tabel 3. 6 Skenario Usecase Import Data... 41
Tabel 3. 7 Skenario Usecase Tambah Data Nama Objek ... 42
Tabel 3. 8 Skenario Usecase Tambah Input Cluster ... 42
Tabel 3. 9 Skenario Usecase Hasil Clustering ... 43
Tabel 3. 10 Skenario Usecase Hasil Diagram Clustering ... 43
Tabel 3. 11 Skenario Usecase Logout ... 44
Tabel 3. 12 Tabel login ... 58
Tabel 3. 13 Tabel centroid ... 59
Tabel 3. 14 id Diagram ... 59
Tabel 3. 15 Diagram centroid ... 59
Tabel 3. 16 Objek ... 59
Tabel 3. 17 Satukan ... 60
Tabel 4. 1 Hasil Dataset Kelas 10...61
Tabel 4. 2 Data Transformasi Kelas 10 ... 62
Tabel 4. 3 Kelas 10 Yang Akan Di Import Ke Sistem ... 63
Tabel 4. 4 Centroid Awal Kelas 10 Iterasi Ke 1 ... 64
Tabel 4. 5 Hasil Perhitungan Jarak Pusat Cluster Kelas 10 ... 65
Tabel 4. 6 Kelompok Jarak Data Dan Centroid Kelas 10 Iterasi 1 ... 66
Tabel 4. 7 Data Cluster Pertama Kelas 10 ... 67
xv
Tabel 4. 8 Data Centroid Baru Kelas 10 Iterasi Ke 2 ... 67
Tabel 4. 9 Data Centroid Baru Kelas 10 Iterasi Ke 4 ... 68
Tabel 4. 10 Data Centroid Terakhir Kelas 10 ... 68
Tabel 4. 11 Hasil Iterasi terakhir Kelas 10 ... 69
Tabel 4. 12 Hasil Clustering Kelas 10 ... 75
Tabel 4. 15 Hasil DBI Kelas 10 ... 75
1 BAB I
PENDAHULUAN
1.1 Latar belakang
Kemampuan matematika yang diperlukan untuk menguasai dan menciptakan teknologi di masa depan, menjadikan matematika yang kuat perlu dibina sejak dini. Masyarakat beranggapan bahwa matematika menjadi tolak ukur kecerdasan dan kepandaian anak dalam belajar. Namun demikian matematika masih dipandang sebagai salah satu bidang studi yang tidak disenangi atau bahkan bias jadi paling dibenci dan masih melekat kebanyakan siswa yang mempelajarinya sampai saat ini.
Hal itulah yang mempengaruhi minat seorang siswa dengan matematika, berbeda dengan siswa lainnya. Minat belajar menurut “Djamarah” dalam cenderung menghasilkan prestasi tinggi, sebaliknya minat belajar yang kurang akan menghasilkan prestasi yang rendah. Hal itulah yang menyebabkan minat setiap siswa berbeda dengan siswa lainnya[1].
Menurut Abraham S Lunchins dan Edith N Luchins, matematika dapat dijawab secara berbeda-beda tergantung pada bilamana pertanyaan itu dijawab, dimana dijawabnya, siapa yang menjawabnya, dan apa sajakah yang dipandang termasuk dalam matematika[2].
James, mengatakan bahwa matematika adalah ilmu tentang logika mengenai bentuk, susunan, besaran, konsep-konsep yang berhubungan satu dengan yang lainnya dengan jumlah yang banyak yang terbagi kedalam tiga bidang yaitu aljabar, analisis, dan geometris. Namun ada pula kelompok lain yang beranggapan bahwa matematika adalah ilmu yang dikembangkan untuk matematika itu sendiri. [2].
Berdasarkan Elea Tinggih, matematika berarti ilmu pengetahuan yang diperoleh dengan bernalar dan hasil yang jujur. Dalam hal ini dimaksudkan bukan berarti ilmu lain diperoleh tidak melalui penalaran, akan tetapi matematika lebih menekankan aktivitas dalam dunia rasio (penalaran), sedangkan dalam ilmu lain lebih menekankan hasil observasi atau eksperiment disamping penalaran[2].
Dalam metode clustering mempartisi data ke dalam kelompok, sehingga data yang memiliki karakteristik yang sama dikelompokkan ke dalam satu cluster yang sama. Jumlah kelompok yang dapat diidentifikasi tergantung pada banyak dan variasi data obyek. Tujuan dari pengelompokan sekumpulan data obyek kedalam beberapa kelompok yang mempunyai karakteristik tertentu dan dapat dibedakan satu sama lainnya adalah untuk analis dan interprestasi lebih lanjut sesuai dengan tujuan penelitian yang dilakukan[1]
Pemilihan metode K-Means dikarenakan metode ini harus menggunakan data fisik tidak abstrak dan bersifat jelas, hal ini sesuai dengan data yang akan digunakan pada permasalahan di dalam pengelompokan bimbingan belajar di SMK Binamitra. Selain itu, metode ini bersifat fleksibel sebab pengguna dapat menentukan jumlah cluster yang akan dibuat.
Beberapa penulis terdahulu telah menerapkan teknik K-Means Clustering sebagai penelitian dalam hal pengelompokan data, diantaranya :
Wirta Agustin, Erlin (2016) Dalam penelitiannya yang berjudul
“Implementasi Metode K-Means Cluster Analysis Untuk Memilih Strategi Promosi Penerimaan Mahasiswa Baru”. Dalam penelitian ini penulis menjelaskan bahwa metode K-Means Clustering dapat membantu dalam pemilihan strategi promosi Penerimaan Mahasiswa Baru pada STMIK Amik Riau.
Ong Johan Oscar (2013) dengan penelitiannya yang mengangkat judul
“Implementasi Algoritma K-Means Clustering Untuk Menentukan Strategi Marketing President University”. Tujuan penulisan yang dijelaskan penulis dalam makalah ini menunjukkan bahwa hasil dari pengolahan data mahasiswa membantu pihak marketing President Unversity dalam melakukan pemasaran dan mencari calon mahasiswa baru dari berbagai kota di Indonesia. Dan hasilnya cukup efisien dan efektif.
Berdasarkan uraian latar belakang yang telah dijelaskan, penulis tertarik untuk melakukan penelitian yang terususun dalam skripsi yang berjudul
“PENERAPAN DATA MINING TERHADAP MINAT SISWA DALAM MATA PELAJARAN MATEMATIKA DENGAN METODE K-MEANS”.
1.2 Identifikasi Masalah
Mengidentifikasi masalah berdasarkan latar belakang masalah yang ada.
Adapun identifikasi masalah dari penelitian ini adalah sebagai berikut :
1. Belum diterapkan metode k-means dalam menentukan siswa yang minat dalam mata pelajaran matematika.
2. Proses analisa untuk menentukan siswa yang minat dalam mata pelajaran matematika masih membutuhkan waktu yang cukup lama.
1.3 Rumusan Masalah
1. Bagaimana menerapkan data mining menggunakan metode K-Means untuk mengelompokan minat siswa terhadap mata pelajaran matematika dan mendapatkan hasil analisa dengan cepat ?
1.4 Batasan Masalah
Agar penelitian ini terarah kepada pokok permasalahan, maka penulis membatasi masalah penelitian ini sebagai berikut :
1. Metode yang digunakan dalam penyelesaian masalah ini adalah metode K- Means.
2. Atribut pembentukan klarifikasi yang digunakan adalah Jurusan, nilai ulangan harian, nilai asli penilaian tengah semester ( PTS ), nilai akhir PTS.
3. Data yang digunakan adalah data dari nilai ujian semester kelas 10 semua jurusan.
1.5 Tujuan Penelitian
Tujuan penelitian ini adalah sebagai berikut :
1. Menerapkan metode K-Means untuk mengelompokan minat siswa terhadap mata pelajaran matematika.
2. Untuk mendapatkan akurasi yang tepat dan cepat dalam mengelompokan minat siswa terhadap mata pelajaran matematika menggunakan metode K- Means.
1.6 Manfaat Penelitian
Manfaat penelitian merupakan hal yang sangat penting dalam sebuah penelitian agar penelitian ini bermanfaat bagi pihak-pihak yang berkepentingan.
1. Bagi Penulis
Dapat menambah ilmu dengan penguasaan materi yang baru dari penelitian berupa skripsi yang dilakukan.
2. Bagi Mahasiswa
Sebagai acuan untuk pengembangan secara penulisan maupun penelitian berkelanjutan dengan adanya perbaikan terhadap hasil yang di peroleh pada penelitian ini.
3. Bagi Universitas Pelita Bangsa
Sebagai tambahan buku berupa skripsi dalam menunjang pengembangan ilmu pengetahuan di bidang teknologi informasi.
1.7 Sistematis Penulisan
Penelitian skripsi ini dikelompokan menjadi beberapa sub bab yang dijelaskan sebagai berikut
BAB I : PENDAHULUAN
Bab ini berisi latar belakang, maksud dan tujuan, rumusan masalah, batasan masalah, metode pengumpulan data dan sistematika penulisan.
BAB II : TINJAU PUSTAKA DAN LANDASAN TEORI
Bab ini berisi teori-teori relevan yang akan saya bahas pada penelitian ini dari sumber sumber yang relevan yang benar- benar sebagai panduan penyusunan penelitian skripsi.
BAB III : METODE PENELITIAN
Bab ini menjelaskan tentang objek/ subjek penelitian, dan teknik pengambilan data, metode pengumpulan data.
Merupakan inti pembahasan pengujian data menggunakan metode algoritma K-means dalam menentukan minat siswa terhadap mata pelajaran matematika.
BAB IV : HASIL DAN PEMBAHASAN
Bab ini menjelaskan dan menampilkan hasil prediksi dengan metode algoritma K-means.
BAB V : KESIMPULAN DAN SARAN
Bab ini berisi kesimpulan yang dapat diambil dari penelitian ini dan saran-saran keseluruhan penelitian yang telah dibahas.
6 BAB II
TINJAUAN PUSTAKA DAN LANDASAN TEORI
2.1 Tinjauan Pustaka
Pada bab ini akan membahas beberapa penelitian dan riset terdahulu yang berkaitan dengan metode data mining menggunakan algoritma K-Means yang menjadi acuan atau rujukan dalam membuat penelitian ini diantaranya :
2.1.1 Pengelompokan Mahasiswa Menggunakan Algoritma K-Means
Makalah ini membahas pengelompokan mahsiswa berdasarkan data akademik menggunakan teknik clustering dan membuat aplikasinya kemudian menganalisis hasilnya sehingga diharapkan mampu memberikan informasi bagi yang berkepentingan. Algoritma K-Means merupakan salah satu algoritma teknik clustering yang dimulai dengan pemilihan secara acak K, yang merupakan banyaknya cluster yang dibentuk dari data yang akan cluster yang ingin dibentuk dari data yang akan di cluster, yaitu nilai tes mahasiswa saat masuk dan indeks presetasi komulatif mahsiswa sampai dengan semester 8. Sistem yang dibuat menampilkan hasil clustering data akedemik mahasiswa, yaitu pola dari prestasi mahasiswa yang clusternya tetap, turun, dan naik, dan dapat terlihat dari asal program studi, asal kota dan asal SMA. Dari hasil studi kasus dapat diperoleh informasi mahasiswa yang tetap pada clusternya seperti awal masuk sebanyak 422 (45, 085%), mahasiswa yang naik cluster sebanyak 284 (30,342%), dan mahasiswa yang turun clusternya sebanyak 230(24,573%) [3] .
2.1.2 Penerapan K-Means Clustering Pada Data Penerimaan Mahasiswa Baru
Pembentukan cluster merupakan salah satu teknik yang digunakan dalam mengekstrak pola kecenderungan suatu data. Teknik ini ini digunakan dalam proses Knowledge discovery in database (KDD). Data mining biasanya identik dengan proses penggalian data-data yang cukup besar dan dikelompokkan menjadi data yang tersusun rapi. Dalam hal ini penulis mengelompokkan data mahasiswa baru tahun ajaran 2014/2015 dengan teknik clustering.
Pengelompokkan yang penulis terapkan menggunakan algoritma K-Means Clustering, algoritma K-Means Clustering mampu mengelompokkan data pada kelompok yang sama dan data yang berbeda pada kelompok yang berbeda.
Sehingga akan terlihat kelompok data mahasiswa baru tahun ajaran 2014/2015 pada Universitas Potensi Utama yang tidak terstruktur menjadi terstruktur. Tujuan dari penelitian ini adalah menerapkan algoritma K-means clustering pada data penerimaan mahasiswa baru tahun jaran 2014-2015(studi kasus : Universitas Potensi Utama ). Hasil K-means clustering yang diperoleh ada dua kelompok, pusat cluster dengan cluster 1 = 1 ; 1.75; 1.5 dan Cluster 2 = 2.95; 1.65;
1.4,Cluster pertama jika sekolah adalah sekolah menengah atas atau sekolah menengah keatas maka rata-rata jurusan yang diambil adalah sistem informasi dan kedua jika asal sekolahnya adalah sekolah menengah kejuruan rata-rata jurusan yang diambil adalah teknik informatika[4].
2.1.3 Implementasi Algoritma K-Means Untuk Menentukan Kelompok Pengayaan Materi Mata Pelajaran Ujian Nasional
Pengayaan materi merupakan salah satu persiapan peserta didik untuk menghadapi Ujian Nasional. Di SMP Negeri 101 Jakarta terdapat dua pengayaan materi, yaitu pengayaan materi wajib dan pengayaan materi khusus. Pengayaan materi khusus dilaksanakan dengan melihat hasil akhir rapor semester 5. Proses pengelompokkan kemampuan siswa untuk melaksanakan pengayaan materi khusus masih belum maksimal karena kemampuan siswa-siswi tersebut tidak hanya diukur dari rapor terakhir saja, melainkan nilai rapor semester 1 hingga 5 berikut nilai tes terakhir untuk menambah keakuratan data. Untuk itu diperlukan solusi yang dapat mengatasi kesulitan tersebut. Metode clustering dengan menggunakan algoritma K-Means diimplementasikan dalam aplikasi ini. Jumlah cluster ada empat sesuai jumlah mata pelajaran UN, sedangkan jumlah sampel data adlah 12 siswa yang memiliki nilai terendah. Aplikasi ini selain menampilkan pengelompokkan kemampuan siswa pada mata pelajaran Ujian Nasional, juga dapat digunakan untuk memantau perkembangan kemampuan setelah mengikuti pengayaan materi [5].
2.1.4 Memanfaatkan Algoritma K-Means Dalam Menentukan Pegawai Yang Layak Mengikuti Asessment Center Untuk Clustering Program SDP
Data mining merupakan teknik pengolahan data dalam jumlah besar untuk pengelompokan. Teknik data mining mempunyai beberapa metode dalam mengelompokan salah satu teknik yang dipakai penulis saat ini adalah K-means.
Dalam hal ini penulis mengelompokan data daftar program SDP tahun 2017 untuk mengetahui manakah pegawai yang layak lolos dalam program SDP sehingga dapat melakukan registrasi assessment center. Pengelompokan tersebut berdasarkan kriteria-kriteria data program SDP. Pada penelitian ini, penulis menerapkan algoritma K-means Clustering untuk pengelompokan data program SDP di PT.Bank Syariah. Dalam hal ini, pada umumnya untuk memamasuki program SDP tersebut disesuaikan dengan ketentuan dan parameter program SDP saja, namun dalam penelitian ini pengelompokan disesuaikan dengan kriteria – kriteria program SDP seperti kedisiplinan pegawai, target kerja pegawai, kepatuhan program SDP. Penulis menggunakan beberapa kriteria tersebut agar pengelompokan yang dihasilkan menjadi lebih optimal. Tujuan dari pengelompokan ini adalah terbentuknya kelompok SDP pada program SDP yang menggunakan algoritma K-Means clustering. Hasil dari pengelompokan tersebut diperoleh tiga kelompok yaitu kelompok lolos, hampir lolos dan tidak lolos.
Terdapat pusat cluster dengan Cluster-1= 8;66;13, Cluster-2= 10;71;14 dan Cluster-3=7;60;12. Pusat cluster tersebut didapat dari beberapa iterasi sehingga mengahasilakan pusat cluster yang optimal [6].
2.1.5 Implementasi Algoritma K-Means Dalam Pengklasteran Mahasiswa Pelamar Beasiswa
Pengelompokan data pelamar beasiswa bantuan belajar mahasiswa (BBM) dikelompokan menjadi 3 kelompok yaitu berhak menerima, dipertimbangkan dan tidak berhak menerima beasiswa. Pengelompokan menjadi 3 kelompok ini berguna untuk memudahkan dalam menentukan penerima beasiswa BBM.
Algoritma k-means merupakan algoritma dari teknik clustering yang berbasis
partisi. Teknik ini dapat mengelompokan data mahasiswa pelamar beasiswa.
Tujuan dari penelitian ini adalah untuk pengukuran kinerja algoritma. Pengukuran ini di lihat dari hasil cluster dengan menghitung nilai kemurnian (purity measure) dari masing-masing cluster yang di hasilkan. Data yang digunakan dalam penelitian ini adalah data mahasiswa yang mengajukan beasiswa kepada fakultas ilmu komputer UNSIKA sebanyak 36 mahasiswa. Data akan diubah menjadi 3 dataset dengan format yang berbeda-beda, yakni data atribut kodifikasi sebagian, atribut kodifikasi keseluruhan dan atribut data asli. Nilai purity pada dataset data kodifikasi sebagian untuk hasil cluster algoritma k-means sebesar 61.11%. Pada dataset kodifikasi keseluruhan nilai purity hasil cluster algoritma k-means sebesar 80.56%. Dan untuk dataset data asli nilai purity hasil cluster algoritma k-means sebesar 75%. Maka dapat di simpulkan bahwa algoritma kmeans lebih cocok digunakan pada dataset dengan format atribut yang dikodifikasi keseluruhan [7].
2.1.6 Penerapan Algoritma K-Means Untuk Clustering Penilaian Dosen Berdasarkan Indeks Kepuasan Mahasiswa
Dalam ruang lingkup perguruan tinggi, aktivitas penilaian kinerja juga diterapkan untuk menilai kinerja dosen. Dasar yang digunakan dalam penilaian tersebut menggunakan dasar tri dhrama perguruan tinggi. Dalam penilaian kinerjanya, diperlukan data terkait kepuasan mahasiswa terhadap dosen. Data yang digunakan dalam penelitian ini adalah data kepuasan mahasiswa jurusan ilmu pengetahuan alam, FMIPA, UNNES, berjumlah 146 untuk semua dosen di prodi yang berjumlah 12 dosen. Dalam pengambilan data menggunakan kuesioner dari badan penjaminan mutu unnes. Varibale yang digunakan yaitu: kehandalan dosen (reliability), sikap tanggap (responsiveness), jaminan (assurance), dan , empati (empathy). Data akan diolah dengan melakukan clustering kinerja dosen dalam cluster baik, atau kurang. Metode clustering yang digunakan dalam penelitian ini adalah metode K-Means. Cetroid data untuk cluster_baik 17.099 dan cluster_kurang 15.874. Sehingga diperoleh penilaian dosen berdasarkan indeks kepuasan mahasiswa dengan 5 dosen cluster_baik dan 7 dosen_clusterkurang. Hasil yang dari penelitian dapat digunakan untuk
meningkatkan kinerja dosen dalam mengajar untuk meningkatkan indeks kepuasan mahasiswa.
2.2 Landasan Teori 2.2.1 Data Mining
Istilah data mining memiliki beberapa pandangan, seperti knowledge discover ataupun pattern recognition. Kedua istilah tersebut sebenernya memiliki ketepatannya masing-masing, istilah knowledge discovery atau penemuan pengetahuan tepat karna digunakan tujuan utama dari data mining memang untuk mendapat pengetahuan yang masih tersembunyi di dalam bongkahan data [3,4].
Istilah pattern recognition atau pengenalan pola pun tetap untuk digunakan karena pengetahuan yang hendak digali memang berbentuk pola-pola yang juga masih perlu digali dari dalam bongkahan data yang tengah dihadapi[8].
Data Mining adalah teknik analisa data secara otomatis untuk membuka atau membongkar hubungan dari banyak data yang tidak diketahui sebelumnya.
Data Mining sering dihubungkan dengan analisa simpanan data di dalam sebuah warehouse. Secara umum ada tiga teknik utama data mining yaitu regresi, klasifikasi dan klastering[9].
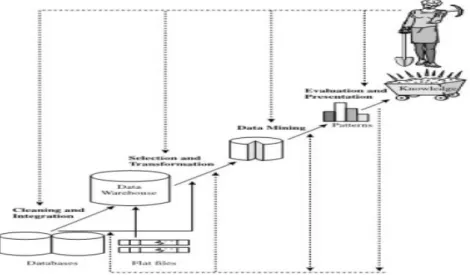
Data mining merupakan bagian dari proses knowledge discovery from data (KDD). Dibawah ini digambarkan skema dari proses KDD.
Gambar 2. 1 Data mining sebagai dari proses knowledge discovery
(sumber: Data mining concept and tehniques, Han & Kamber)[10]
Gambar diatas menunjukkan proses penjelajahan pengetahuan dimulai dari beberapa database dilakukan proses cleaning dan integration sehingga menghasilkan data warehouse. Dilakukan proses selection dan transformation yang kemudian disebut sebagai data mining hingga menemukan pola dan memperoleh pengetahuan dari data (knowledge).
Terdapat beberapa teknik data mining yang sering disebut-sebut dalam literatur. Namun ada 3 teknik data mining yaitu:
1) Association Rule Mining
Association Rule mining adalah teknik mining untuk menemukan asosiatif antara kombinasi atribut. Contoh dari aturan asosiatif dari analisa pembelian disuatu pasar swalayan dapat mengatur penempatan barangnya atau merancang strategi pemasaran dengan memakai kupon diskon untuk kombinasi barang tertentu.
2) Clustering
Berbeda dengan association rule mining dan klasifikasi dimana kelas data telah ditentukan sebelumnya, clustering dapat dipakai untuk memberikan label pada kelas data yang belum diketahui. Karena itu clustering sering digolongkan sebagai metode unsupervised learning. Prinsip clustring adalah memaksimalkan kesamaan antar cluster. Clustering dapat dilakukan pada data yang memiliki beberapa atribut yang dipetakan sebagai ruang multidimensi.
3) Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori. Sebagai contoh, penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu pendapatan tinggi, pendapatan sedang, pendapatan rendah [10].
2.2.2 Clustering
Analisis kelompok (cluster analysis) adalah mengelompokkan data (objek) yang didasarkan hanya pada informasi yang ditemukan dalam data yang menggambarkan objek tersebut dan hubungan diantaranya. Analisis cluster
sebagai metodologi untuk klasifikasi data secara otomatis menjadi beberapa kelompok dengan menggunakan ukuran asosiasi, sehingga data yang sama berada dalam satu kelompok yang sama dan data yang berbeda berada dalam kelompok data yang tidak sama. Masukan (input) untuk sistem analisis cluster adalah seperangkat data dan kesamaan ukuran (atau perbedaan) antara dua data.
Sedangkan keluaran (output) dari analisis cluster adalah sejumlah kelompok yang membentuk sebuah partisi atau struktur partisi dari kumpulan data[10]. Salah satu hasil tambahan dari analisis cluster adalah deskripsi umum dari setiap cluster dan hal itu sangat penting untuk analisis lebih dalam dari karakteristik data set tersebut[9]. Ada saatnya di mana set data yang akan diproses dalam data mining belum diketahui label kelasnya. Pengelompokan data dilakukan dengan menggunakan algoritma yang sudah ditentukan dan selanjutnya data akan diproses oleh algoritma untuk dikelompokkan menurut karakteristik alaminya.[6]
Gambar 2. 2 Contoh pengelompokan dengan clustering [6].
2.2.3 Algoritma K-Means
Algoritma K-means merupakan salah satu algoritma clustering (pengelompokan). K-means clustering merupakan metode clustering non-hirarki yang mengelompokkan data dalam bentuk satu atau lebih cluster/kelompok. Data- data yang memiliki karakteristik yang sama dikelompokkan dalam satu cluster/kelompok dan data yang memiliki karakteristik yang berbeda dikelompokkan dengan cluster/kelompok yang lain, sehingga data yang berada dalam satu cluster/kelompok memiliki tingkat variasi kecil[11].
Sedangkan menurut Wu & Kumar (2009:33) K-means adalah algoritma clustering yang mempartisi himpunan D menjadi k cluster data. Algoritma K-
means mengklaster semua titik data pada D sedemikian sehingga titik data xi menjadi satu-satunya k partisi. Dengan kata lain, satu titik data hanya masuk ke dalam satu cluster[11].
Langkah-langkah melakukan clustering dengan metode K-Means adalah sebagai berikut:
1) Tentukan nilai k sebagai jumlah klaster yang ingin dibentuk.
2) Inisialisasi k pusat cluster ini bisa dilakukan dengan berbagai cara, namun yang paling sering dilakukan adalah dengan cara random/acak yang di ambil dari data yang ada
3) Menghitung jarak setiap data input terhadap masing – masing centroid menggunakan rumus jarak Euclidean (Euclidean Distance) hingga ditemukan jarak yang paling dekat dari setiap data dengan centroid.
Berikut adalah persamaan Euclidian Distance : ( , ) =√( )² -(2.1)
Dimana :
d : titik dokumen xi : data kriteria
µj : centroid pada cluster ke-j
4) Mengklasifikasikan setiap data berdasarkan kedekatannya dengan centroid (jarak terkecil).
5) Memperbaharui nilai centroid. Nilai centroid baru di peroleh dari rata-rata cluster yang bersangkutan dengan menggunakan rumus:
(𝑡+1)
∑ j 𝜖 Dimana :
µj(t+1) : centroid baru pada iterasi ke (t+1) Nsj : banyak data pada cluster sj,
6) Melakukan perulangan dari langkah 2 hingga 5,sampai anggota tiap cluster tidak ada yang berubah.
Jika langkah 6 telah terpenuhi, maka nilai pusa cluster (µj) pada iterasi terakhir akan digunakan sebagai parameter untuk menentukan klasifikasi data[12].
2.2.4 Keuntungan Algoritma K-Means
Berikut ini beberapa keuntungan menggunakan algoritma K-means menurut saya pribadi :
1) Mudah dilakukan saat mengimplemantasikan dan dijalankan.
2) Waktu yang dibutuhkan untuk melakukan pembelajaran relative lebih cepat.
3) Sangat fleksibel, adaptasi yang mudah untuk di lakukan.
4) Sangat umum penggunaannya.
5) Menggunakan prinsip yang sederhana dapat di jelaskan dalam non- statistik.
2.2.5 Kekurangan Algoritma K-Means
Berikut ini beberapa kekurangan menggunakan algoritma K-means menurut saya pribadi :
1) Keluaran dari K-means bergantung pada centroid awal yang ditentukan secara acak
2) K-Means sering terjebak pada optimum lokal, dimana centroid akhir yang dihasilkan tidak benar-benar menjadi pusat cluster yang sesungguhnya.
3) K-Means tidak dapat menjamin konvergen pada optimum global.
2.2.6 Matematika
Matematika merupakan salah satu jenis pengetahuan yang dibutuhkan manusia dalam menjalankan kehidupannya sehari-hari. Misalnya ketika berbelanja maka kita perlu memilih dan menghitung jumlah benda yang akan dibeli dan harga yang harus dibayar. Saat akan pergi, kita perlu mengingat arah jalan tempat yang akan didatangi, berapa lama jauhnya, serta memilih jalan yang lebih bisa cepat sampai di tujuan [13].
Kata matematika berasal dari perkataan latin mathematika yang mulanya diambil dari perkataan Yunani mathematike yang berarti mempelajari. Perkataan itu mempunyai asal katanya mathema yang berarti pengetahuan atau ilmu (knowledge, science). Kata mathematike berhubungan pula dengan kata lainnya yang hampir sama, yaitu mathein atau mathenein yang artinya belajar (berpikir).
Jadi, berdasarkan asal katanya, maka perkataan matematika berarti ilmu pengetahuan yang didapat dengan berpikir (bernalar). Matematika lebih menekankan kegiatan dalam dunia rasio (penalaran), bukan menekankan dari hasil eksperimen atau hasil observasi matematika terbentuk karena pikiran-pikiran manusia, yang berhubungan dengan idea, proses, dan penalaran[14].
Matematika terbentuk dari pengalaman manusia dalam dunianya secara empiris. Kemudian pengalaman itu diproses di dalam dunia rasio, diolah secara analisis dengan penalaran di dalam struktur kognitif sehingga sampai terbentuk konsep-konsep matematika supaya konsepkonsep matematika yang terbentuk itu mudah dipahami oleh orang lain dan dapat dimanipulasi secara tepat, maka digunakan bahasa matematika atua notasi matematika yang bernilai global (universal). Konsep matematika didapat karena proses berpikir, karena itu logika adalah dasar terbentuknya matematika[14].
2.2.7 Faktor-Faktor Minat Siswa Terhadap Pelajaran Matematika
Faktor lain yang menyebabkan kecilnya minat siswa terhadap pelajaran matematika adalah metode maupun pendekatan pembejalaran yang digunakan oleh guru. Selain itu, pada setiap proses pembelajaran siswa hanya belajar dengan cara mendengarkan ceramah dan mencatat sehingga proses belajar dikelas terasa kurang menarik dan membosankan. Kurang menariknya proses pembelajaran tersebut mengakibatkan berkurangnya minat belajar siswa terutama pada mata pelajaran matematika. Pada akhirnya kurangnya pula minta belajar siswa tersebut menjadi salah satu factor penyebab rendahnya prestasi belajar[15].
2.2.8 Teori Supervised Machine Learning Dan unsupervised learning
Machine learning merupakan kemampuan komputer untuk melakukan pembelajaran tanpa harus menjelaskan secara eksplisit kepada komputer, Dengan kata lain machine learning adalah bagaimana memberikan kemampuan kepada komputer untuk melakukan aktivitas belajar guna menyelesaikan masalah secara mandiri. Algoritma machine learning dapat dikelompokkan berdasarkan masukan dan keluaran yang diharapkan dari algoritma. Adapun tipe algoritma machine learning diantaranya adalah supervised learning, unsupervised learning, semi-
supervised learning, reinforcement learning, developmental learning algorithm, transduction, dan learning to learn. Adapun supervised learning merupakan algoritma yang belajar berdasarkan sekumpulan contoh pasangan masukan dan keluaran yang diinginkan. Algoritma ini mengamati contoh-contoh tersebut dan kemudian menghasilkan sebuah model yang mampu memetakan masukan yang baru menjadi keluaran yang tepat. Sementara unsupervised learning mempunyai tujuan untuk mempelajari dan mencari pola-pola menarik pada masukan yang diberikan. Meskipun tidak disediakan keluaran yang tepat secara eksplisit. Salah satu algoritma unsupervised learning yang paling umum digunakan adalah clustering atau pengelompokan.[16]
2.2.9 Validasi Davies Bouldin Index (DBI)
Davies bouldin index (DBI) adalah metric untuk mengevaluasi atau mempertimbangkan hasil algoritma clustering. Pertama kali diperkenalkan oleh David L. Davies dan Donald W. Bouldin pada tahun 1979. Dengan menggunakan DBI suatu cluster akan dianggap memiliki skema clustering yang optimal adalah yang memiliki DBI minimal[17].
1) Sum Of Square Within-Cluster (SSW)
Untuk mengetahui kohesi dalam sebuh cluster ke-I salah satunya adalah dengan menghitung nilai dari Sum Of Square Within-Cluster (SSW).
Dengan rumus sebagai berikut :
∑ ……….…………(2.3) Dimana,
mi = jumlah data dalam cluster ke-i ci = centroid cluster ke-i
d( ) = jarak setiap data ke centroid i yang dihitung menggunakan jara jarak euclidiance.
2) Sum Of Square Between-Cluster (SSB)
Perhitungan Sum Of Square Between-Cluster (SSB) bertujuan untuk mengetahui separasi atau jarak antar cluster, dengan rumus perhitungan sebagai berikut:
....………(2.4) Dimana :
= jarak antara data ke i dengan data ke j di cluster lain.
3) Ratio (Rasio)
Perhitungan rasio (Ri,j) ini bertujuan untuk mengetahui nilai perbandingan antara cluster ke-i dan cluster ke-j untuk menghitung nilai rasio yang dimiliki oleh masing-masing cluster. indeks I dan j merupakan merepresentasikan jumlah cluster, dimana jika terdapat 4 cluster maka terdapat indeks sebanyak 4 yaitu i,j,k dan l. untuk menentukan nilai rasio dengan rumus sebagai berikut :
=
………
(2.5) Dimana :
= Sum Of Square Within-Cluster pada centroid i
= Sum of Square Between Cluster data ke i dengan j pada cluster yang berbeda
Pada rumus perhitungan 2.5 n akan berlanjut sejumlah cluster yang dipilih dengan syarat ni tidak sama dengan nj.
4) Davies Bouldin Index (DBI)
Nilai rasio yang diperoleh dari rumus 2.5 digunakan untuk mencari nilai DBI dengan menggunakan perhitungan sebagai berikut :
∑ ...(2.6)
Dimana, Ri,j merupakan ratio dari nilai SSW dan SSB melalui perhitungan rumus 2.5 dari perhitungan 2.6 maka dapat diketahui k adalah jumlah cluster. Dari perhitungan Davies Bouldin Index (DBI) dapat disimpulkan bahwa jika semakin kecil nilai Davies Bouldin Index (DBI) yang diperoleh (non negatif >= 0) maka cluster tersebut semakin baik[17].
2.2.10 Pengertian Sistem
Kata sistem berasal dari bahasa Yunani yaitu systema, yang mempunyai satu pengertian yaitu sehimpunan bagian atau komponen yang saling berhubungan secara teratur dan merupakan satau kesatuan yang tidak terpisahkan. Sistem secara teknis berarti seperangkat komponen yang saling berhubungan dan bekerja sama untuk mencapai suatu tujuan. Mendefinisikan sistem sebagai suatu kesatuan dari berbagai elemen atas bagianbagian yang mempunyai hubungan fungsional dan berinteraksi secara dinamis untuk mencapai hasil yang diharapkan. Dari ketiga definisi tersebut, dapat ditarik kesimpulan bahwa pengertian sistem adalah seperangkat bagian-bagian yang saling berhubungan erat satu dengan lainya untuk mencapai tujuan bersamasama[18].
Dari ketiga definisi tersebut, dapat ditarik kesimpulan bahwa pengertian sistem adalah seperangkat bagian-bagian yang saling berhubungan erat satu dengan lainya untuk mencapai tujuan bersamasama[18].
2.2.11 Pengertian Informasi
Sistem informasi merupakan sekumpulan komponen yang saling bekerja sama untuk mengumpulkan,mengolah, menyimpan dan menyebarkan informasi untuk mendukung pengambilan keputusan, koordinasi, pengendalian, analisis masalah, dan visualisasi dalam sebuah organisasi [19].
Sistem informasi merupakan sebuah kombinasi teratur yang terdiri dari orang-orang, jaringan komunikasi, hardware, software, dan sumber daya data yang mengumpulkan, menyimpan, mengubah dan menyebarkan informasi dalam suatu organisasi [20].
Berdasarkan definisi di atas, sistem informasi merupakan sekumpulan komponen yang terdiri dari orang-orang, jaringan komunikasi, hardware, software dan sumber daya data untuk mengumpulkan, mengolah, menyimpan dan menyebarkan informasi untuk mendukung pengambilan keputusan, koordinasi, pengendalian, analisis masalah, dan visualisasi dalam suatu organisasi[21]
2.2.12 Konsep Teknologi Informasi
Untuk mengetahui pengertian teknologi informasi terlebih dahulu kita harus mengerti pengertian dari teknologi dan informasi itu sendiri. Berikut ini pengertian teknologi dan informasi.
Teknologi adalah pengembangan dan aplikasi dari alat, mesin, material dan proses yang menolong manusia menyelesaikan masalahnya, sedangkan Informasi adalah hasil pemrosesan, manipulasi dan pengorganisasian/penataan dari sekelompok data yang mempunyai nilai pengetahuan (knowledge) bagi penggunanya. Istilah yang baru berkembang dan mulai banyak digunakan untuk menggantikan sistem informasi manajemen adalah teknologi informasi (Information Technology). Istilah teknologi informasi (TI) lebih berorientasi ke teknologinya. Teknologi informasi atau Information Technology (IT) adalah subsistem atau sistem bagian dari sistem informasi .
Pengertian teknologi informasi menurut beberapa ahli teknologi informasi Teknologi Informasi adalah studi atau peralatan elektronika, terutama komputer, untuk menyimpan, menganalisa, dan mendistribusikan informasi apa saja, termasuk kata-kata, bilangan, dan gambar .
Dapat disimpulkan bahwa Teknologi Informasi adalah suatu teknologi yang digunakan untuk mengolah data, termasuk memproses, mendapatkan, menyusun, menyimpan, memanipulasi data dalam berbagai cara untuk menghasilkan informasi yang berkualitas, yaitu informasi yang relevan, akurat dan tepat waktu, yang digunakan untuk keperluan pribadi, bisnis, dan pemerintahan dan merupakan informasi yang strategis untuk pengambilan keputusan. Teknologi yang memanfaatkan komputer sebagai perangkat utama untuk mengolah data menjadi informasi yang bermanfaat[18].
2.2.13 Pengertian Object Oriented Programming (OOP)
Object Oriented Programming (OOP) adalah suatu metode pemrograman yang berbasiskan pada objek, secara singkat pengertian dari OOP adalah koleksi objek yang saling berinteraksi dan saling memberikan informasi satu dengan yang
lainnya. Suatu program disebut dengan pemrograman berbasis obyek (OOP) karena terdapat:
1. Encapsulation (pembungkusan)
1) Variabel dan method dalam suatu obyek dibungkus agar terlindungi.
2) Untuk mengakses, variabel dan method yang sudah dibungkus tadi perlu interface.
3) Setelah variabel dan method dibungkus, hak akses terhadapnya bisa ditentukan.
4) Konsep pembungkusan ini pada dasarnya merupakan perluasan dari tipe data struktur.
2. Inheritance (pewarisan)
1) Sebuah class bisa mewariskan atribut dan method-nya ke class yang lain.
2) Class yang mewarisi disebut superclass.
3) Class yang diberi warisan disebut subclass.
4) Sebuah subclass bisa mewariskan atau berlaku sebagai superclass bagi class yang lain disebut multilevel inheritance.
Keuntungan Penggunaan Pewarisan
1) Subclass memiliki atribut dan method yang spesifik yang membedakannya dengan superclass, meskipun keduanya mirip (dalam hal kesamaan atribut dan method).
2) Dengan demikian pada pembuatan subclass, programmer bisa menggunakan ulang source code dari superclass disebut dengan istilah reuse.
3) Class-class yang didefinisikan dengan atribut dan method yang bersifat
umum yang berlaku baik pada superclass maupun subclass disebut dengan abstract class.
3. Polymorphism (polimorfisme–perbedaan bentuk)
Polimorfisme artinya penyamaran suatu bentuk dapat memiliki lebih dari satu bentuk[22].
2.2.14 Pengertian UML
Pada tahun 1995, Rational Software membawa tiga pemimpin industri bersama-sama untuk menciptakan pendekatan tunggal untuk pengembangan sistem berorientasi objek. Grady Booch, Ivar Jacobson, dan James Rumbaugh bekerja dengan orang lain untuk berkreasi satu set standar teknik diagram yang dikenal sebagai Unified Modeling Language (UML). Tujuan UML adalah untuk menyediakan kosakata umum berorientasi objek istilah dan teknik diagram cukup kaya untuk memodelkan setiap proyek pengembangan sistem dari analisis hingga implementasi[23].
Pada bulan November 1997, Manajemen Objek Group (OMG) secara resmi menerima UML sebagai standar untuk semua pengembang objek. Selama tahun-tahun berikutnya, UML telah mengalami beberapa revisi kecil. Versi saat ini UML, Versi 2.4, dirilis oleh OMG pada Januari 2011. Versi 2.4 dari UML mendefinisikan seperangkat teknik diagram empat belas yang digunakan untuk memodelkan suatu sistem. Diagram dipecah menjadi dua kelompok utama yaitu untuk pemodelan struktur sistem dan untuk perilaku pemodelan. Diagram struktur meliputi kelas, objek, paket, penyebaran, komponen, dan struktur komposit diagram. Diagram perilaku menyediakan analis dengan cara untuk menggambarkan hubungan dinamis di antara instance atau objek yang mewakili sistem informasi bisnis[23].
Berdasarkan definisi diatas, bahwa UML merupakan salah satu standard untuk pengembangan sebuah sistem berbasis objek. UML bertujuan untuk menyediakan ketetapan umum untuk pengembangan sebuah sistem berorientasi objek dari analisis hingga implementasi. Dalam permodelannya UML menggunakan beberapa teknik diagram diantaranya.
2.2.15 Pengertian Use Case Diagram
Use case atau diagram use case merupakan pemodelan untuk kelakukan (behaviour) sistem informasi yang akan dibuat. Use case mendeskripsikan sebuah interaksi antara satu atau lebih actor dengan sistem informasi yang akan di buat.
Secara kasar use case di gunakan untuk mengetahui fungsi apa saja dan siapa saja yang berhak menggunakan fungsi-fungsi itu dalam sebuah sistem informasi[24].
Ada dua hal utama pada use case yaitu pendefinisian apa yang disebut aktor dan use case.
1) Aktor merupakan orang, proses, atau sistem lain yang berinteraksi dengan system informasi yang akan di buat.
2) Use case merupakan fungsionalitas yang bersediakan system sebagai unit- unit yang saling bertukar pesan antar unit atau aktor.
Berdasarkan definisi diatas, Use case diagram merupakan suatu pemodelan untuk mendekripsikan sebuah interaksi atau kelakuan antara satu atau lebih actor
dengan sistem informasi yang akan di buat. Berikut adalah simbol-simbol yang ada pada use case diagram:
Tabel 2. 1 Daftar Simbol Use Case Diagram [24]
Simbol Nama Keterangan
Use Case
fungsi yang disediakan sistem sebagai unit-unit yang saling berkaitan bertukar pesan antar unit atau actor : biasanya di nyatakan dengan menggunakan kata kerja di awal frase nama use case
Actor
Orang, Proses,atau sistem lain yang berinteraksi dengan sistem informasi yang akan di buat di luar sistem informasi yang akan di buat itu sendiri, jadi walaupun simbol dari aktor adalah gambar orang, tapi aktor belum tentu merupakan orang:
biasanya dinyatakan menggunkan kata benda di awal frase nama actor
Ektensi
Relasi use case tambahan ke sebuah use case dimana use case yang ditambahkan dapat berdiri sendiri walau tanpa use case tambahan itu;
mirip dengan inheritance pada pemograman berorientasi objek,
Simbol Nama Keterangan
Generalisasi
biasanya usecase tambahan memiliki nama depan yang sama dengan use case yang ditambahkan. Misalnya arah panah mengarah pada usecase yang ditambahkan, biasanya use case yang menjadi extand-nya merupakan jenis
yang sama dengan use case yang menjadi induknya.
Generalisasi
Hubungan generalisasi dan spesialisasi (umum-khusus) antara dua buah use case dimana fungsi yang satu adalah fungsi yang lebih umum dari lainnya, misalnya : lebih umum dari lainnya, misalnya :Arah panah mengarah pada use case yang menjadi generalisasinya (umum).
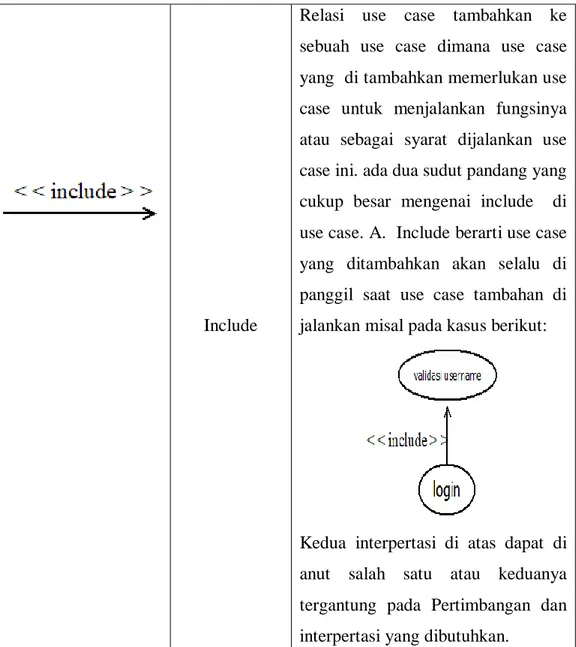
Include
Relasi use case tambahkan ke sebuah use case dimana use case yang di tambahkan memerlukan use case untuk menjalankan fungsinya atau sebagai syarat dijalankan use case ini. ada dua sudut pandang yang cukup besar mengenai include di use case. A. Include berarti use case yang ditambahkan akan selalu di panggil saat use case tambahan di jalankan misal pada kasus berikut:
Kedua interpertasi di atas dapat di anut salah satu atau keduanya
tergantung pada Pertimbangan dan interpertasi yang dibutuhkan.
2.2.16 Pengertian Activity Diagram
Diagram aktivitas atau activity diagram menggambarkan workflow (aliran kerja) atau aktivitas dari sebuah system atau proses bisnis atau menu yang ada pada perangkat lunak. Yang perlu di perhatikan disini bahwa diagram aktivitas menggambarkan aktivitas system bukan apa yang dilakukan aktor, jadi aktivitas yang dapat dilakukan oleh sistem[24].
Diagram aktivitas juga banyak di gunakan untuk mendefinisikan hal-hal berikut.
a. Rancangan proses bisnis dimana setiap urutan aktivitas yang di gambarkan merupakan proses bisnis sistem yang di definisikan.
b. Urutan dan pengelompokan tampilan dari sistem / user interface dimana setiap aktivitas di anggap memiliki sebuah rancangan antarmuka tampilan.
c. Rancangan pengujian dimana setiap aktivitas di anggap memerlukan sebuah pengujian yang perlu di definisikan kasus ujinya.
d. Rancangan menu yang di tampilkan pada perangkat lunak.
Berikut adalah symbol-simbol yang ada pada activity diagram : Tabel 2. 2 Simbol-Simbol Pada Activity Diagram[24].
Simbol Nama Keterangan
Status Awal
Status awal aktivitas sistem, sebuah diagram aktivitas memiliki sebuah staus awal.
Aktivitas
Aktivitas yang dilakukan sistem,aktivitas biasanya di awali dengan kata kerja.
Percabangan / decision
Asosiasi percabangan dimana jika ada pilihan aktivitas lebih dari satu.
Penggabungan / join
Asosiasi penggabungan dimana lebih dari satu aktivitas di gabungkan menjadi satu.
Status Akhir
Status akhir yang dilakukan sistem, sebuah diagram aktivitas memiliki sbuah status akhir.
Swimlane
Memisahkan organisasi bisnis yang bertanggung jawab terhadap aktivitas yang terjadi.
2.2.17 Pengertian Sequence Diagram
Diagram sequence menggambarkan kelakuan objek pada use case dengan mendekripsikan waktu hidup objek dan message yang di kirimkan dan diterima antar objek. Membuat diagram sekuen juga di butuhkan untuk melihat scenario yang ada pada use case[24].
Banyaknya diagram sekuen yang harus di gambar adalah minimal sebanyak pendefinisian use case yang memiliki proses sendiri atau yang penting semua use case yang telah di definisikan. Berikut adalah simbol-simbol yang ada pada diagram sekuen.
Tabel 2. 3 Simbol-simbol pada sequence diagram[24].
Simbol Nama Keterangan
Tanpa Waktu Aktif
Aktor
Orang, proses, atau system lain yang berinteraksi dengan system informasi yang akan dibuat diluar system informasi yang akan dibuat sendiri.
Garis hidup / Lifeline
Menyatakan kehidupan suatu objek.
Objek
Menyatakan objek yang berinteraksi pesan.
Simbol Nama Keterangan
Waktu Aktif
Menyatakan objek dalam keadaan aktif dan berinteraksi, semua yang terhubung dengan waktu aktif.
Pesan tipe create
Menyatakan suatu objek membuat objek yang lain, arah panah mengarah pada objek yang di buat.
Pesan tipe Destroy
Menyatakan suatu objek mengakhiri hidup objek yang lain.
Arah panah mengarah pada objek yang diakhiri, sebaiknya jika ada create maka ada destroy.
Pesan tipe call
Menyatakan suatu objek memanggil operasi/metode yang ada pada objek lain atau dirinya sendiri.
Arah panah mengarah pada objek yang memiliki operasi/metode,
karena ini memanggil
operasi/metode maka
operasi/metode yang di panggil harus ada pada diagram kelas sesuai dengan kelas objek yang berinteraksi.
Simbol Nama Keterangan
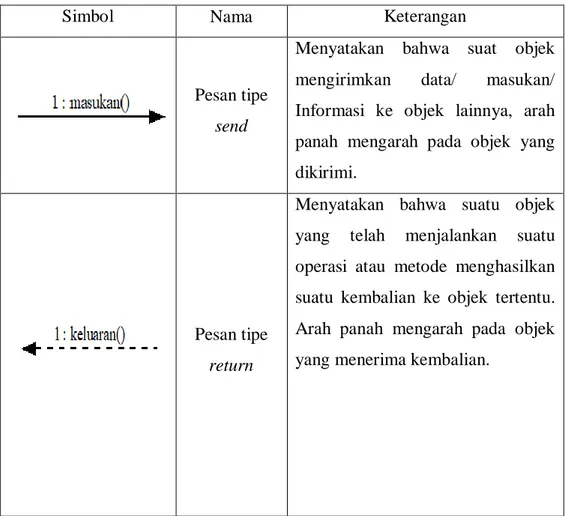
Pesan tipe send
Menyatakan bahwa suat objek mengirimkan data/ masukan/
Informasi ke objek lainnya, arah panah mengarah pada objek yang dikirimi.
Pesan tipe return
Menyatakan bahwa suatu objek yang telah menjalankan suatu operasi atau metode menghasilkan suatu kembalian ke objek tertentu.
Arah panah mengarah pada objek yang menerima kembalian.
2.2.18 Pengertian Class Diagram
Diagram kelas atau class diagram menggambarkan struktur sistem dari segi pendefinisian kelas-kelas yang akan dibuat untuk membangun sistem. Kelas memiliki apa yang disebut atribut dan metode atau operasi[24].
1) Atribut merupakan variable-variable yang dimiliki oleh suatu kelas.
2) Operasi atau metode adalah fungsi –fungsi yang dimiliki oleh suatu kelas.
Kelas-kelas yang ada pada struktur system harus dapat melakukan fungsi- fungsi sesuai dengan kebutuhan system.
Susunan struktur kelas yang baik pada diagram kelas sebaiknya memiliki jenis-jenis kelas berikut :
1) Kelas main
Kelas yang memiliki fungsi awal dieksekusi ketika system dijalankan.
2) Kelas yang menangani tampilan sistem (view)
Kelas yang mendefinisikan dan mengatur tampilan ke pemakai.
3) Kelas yang diambil dari pendefinisian usecase (controller).
Kelas yang menangani fungsi-fungsi yang harus ada diambil dari pendefinisian use case.
4) Kelas yang diambil dari pendefinisian data (model)
5) Kelas yang digunakan untuk memegang atau membungkus data yang menjadi sebuah kesatuan yang di ambil maupun akan disimpan ke basis data. Berikut simbol-simbol yang ada pada diagram kelas :
Tabel 2. 4 Daftar Simbol Class Diagram[24]
Simbol Nama Keterangan
Kelas
Kelas pada struktur sistem.
Antarmuka / Interface
Sama dengan konsep interface dalam pemograman berorientasi objek
Asosiasi / association
Relasi antarkelas dengan makna umum, asosiasi biasanya juga disertai dengan multiplicity.
Asosiasi berarah / directed Association
Relasi antarkelas dengan makna kelas yang satu digunakan oleh kelas yang lain, asosiasi biasanya juga disertai dengan multiplicity.
Generalisasi
Relasi antarkelas dengan makna generalisasi - spesialisasi (umum-khusus)
Simbol Nama Keterangan
Kebergantungan / dependecy
Relasi antarkelas dengan makna kebergantungan antar kelas.
Agregasi / aggregation
Relasi antarkelas dengan makna semua-bagian (whole- part)
2.5 Pengertian PHP
Menurut dokumen resmi PHP, PHP merupakan singkatan dari PHP Hypertex Processor. PHP merupakan bahasa berbentuk skrip yang ditempatkan dalam server dan diproses di server. Bermula pada tahun 1994 saat Rasmus Lerdorf membuat sejumlah skrip perl yang dapat mengamati siapa saja yang melihat-lihat riwayat hidupnya. Skrip-skrip ini selanjutnya dikemas mejadi tool yang disebut “Personal Home Page“. Paket inilah yang menjdi cikal bakal PHP.
Pada tahun 1995, Rasmus menciptakan PHP/FI versi 2. Pada versi ini pemogram dapat menempelkan kode terstruktur di dalam tag HTML. Selain itu, kode PHP juga bisa berkomunikasi dengan database dan melakukan perhitungan- perhitungan yang kompleks[25].
2.5.1 Pengertian Basis Data (Data Base)
Basis data merupakan merupakan kumpulan dari data yang saling berhubungan dengan yang lainnya, tersimpan di perangkat keras computer dan digunakan perangkat lunak untuk memanipulasinya.Database merupakan salah satu komponen yang penting dalam sistem informasi, Karena merupkan basis dalam menyediakan informasi bagi para pemakai.Penerapan database dalam sistem informasi disebut dengan database system.
Pengertian Basis Data menurut Fathansyah (2002) adalah “sekemupulan data persistence yang saling terkain, menggambarkan suatu organisasi (Enterprise).[26]
2.5.2 Pengertian MySQL
MySQL adalah salah satu dari sekian banyak sistem database yang merupakan terobosan solusi yang tepat dalam aplikasi database. MySQL merupakan turunan salah satu konsep utama dalam database sejak lama yaitu SQL (Structured Query Language). MySQL dikembangkan pada tahun 1994 oleh sebuah perusahaan pengembang software dan konsultan database di Swedia bernama TcX Data Konsullt AB. Tujuan awal dikembangkan MySQL adalah untuk mengembangkan aplikasi berbasis web pada client. Saat ini MySQL dapat di-download secara gratis di www.mysql.com[27].
2.5.3 Pengertian Penerapan
Menurut Kamus Besar Bahasa Indonesia (KBBI), pengertian penerapan adalah perbuatan menerapkan, sedangkan menurut beberapa ahli, penerapan adalah suatu perbuatan mempraktekkan suatu teori, metode, dan hal lain untuk mencapai tujuan tertentu dan untuk suatu kepentingan yang diinginkan oleh suatu kelompok atau golongan yang telah terencana dan tersusun sebelumnya. Kata penerapan (implementasi) bermuara pada aktifitas, adanya aksi, tindakan, atau mekanisme suatu sistem. Ungkapan mengandung arti bahwa penerapan (implementasi) bukan sekedar aktifitas tetapi suatu kegiatan yang terencana dan dilakukan secara sungguh-sungguh berdasarkan acuan norma tertentu untuk mencapai tujuan kegiatan.
2.5.4 Metode Pengembangan Sistem
Metode pengembangan sistem yang digunakan untuk proses pengembangan perangkat lunak adalah dengan menggunakan metode prototype.
Prototype merupakan suatu metode dalam pengembangan sistem yang menggunakan pendekatan untuk membuat sesuatu program dengan cepat dan bertahap sehingga segera dapat dievaluasi oleh pemakai. Selain itu prototype juga membuat proses pengembangan sistem informasi menjadi lebih cepat dan lebih mudah, terutama pada keadaan kebutuhan pemakai sulit untuk diidentifikasi.
Metode prototype menggunakan dua pendekatan dalam pengembangan sistem atau prototyping yaitu, throw-away prototyping atau rapid prototyping dan
evolutionary prototyping. Pada proses evolutionary prototyping, system dikembangkan tanpa mengetahui spesifikasi sistem yang benar di awal pengembangan atau kebutuhan system yang masih abstrak. Verifikasi terhadap sistem tidak memungkinkan untuk dilakukan karena tidak terdapat spesifikasi.
Proses validasi dilakukan dengan mendemonstrasikan kecukupan dari sistem.
sedangkan pada proses throw-away prototyping spesifikasi awal dari sistem sudah dapat diketahui di awal, sehingga proses prototyping ini ditujukan untuk mengurangi resiko kebutuhan yang tidak terpenuhi. Sehingga pada penelitian ini menggunakan pendekatan proses throw-away prototyping sebab agar dapat mempermudah dalam pembuatan sistem agar sesuai dengan kebutuhan user.
Tahapan-tahapan Model Prototyping : 1) Pengumpulan Data
Pengguna atau user dan pengembangan bersamasama mendefinisikan format seluruh perangkat lunak, mengedintifikasikan semua kebuthan dan Garis besar sistem yang akan dibuat.
2) Membangun prototype
Membangun prototyping dengan membuat perancangan sementara yang berfokus pada penyajian kepada pelanggan (misalnya dengan membuat input dan format output).
3) Menggunakan sistem
Evaluasi ini dilakukan oleh pelanggan apakah prototyping yang sudah dibangun sudah sesuai dengan keinginann pelanggan.
4) Mengkodekan sistem
Dalam tahap ini prototyping yang sudah di sepakati diterjemahkan ke dalam bahasa pemrograman yang sesuai.
5) Menguji sistem
Setelah sistem sudah menjadi suatu perangkat lunak yang siap pakai, harus dites dahulu sebelum digunakan. Pengujian ini dilakukan dengan White Box, Black Box, Basis Path, pengujian arsitektur dan lain-lain.
6) Evaluasi sistem
Pengguna mengevaluasi apakah sistem yang sudah jadi sudah sesuai dengan yang diharapkan.
7) Evaluasi protoptyping
Perangakat yang telah diuji dan diterima pelanggan siap untuk digunakan.
Tahap-tahap proses pembuatan prototype tipe kedua (throwaway prototype) : 1) Tentukan kebutuhan.
Tentukan apa kebutuhan user. Analis system mewawancarai user untuk mendapatkan ide tentang apa yang diinginkan oleh user dari system yang akan dikembangkan.
2) Buat prototype.
Analis system bekerja sama dengan ahli komputer yang lain, dengan memanfaatkan satu atau beberapa alat bantu untuk pembuatan prototype, mengembangkan prototype.
3) Evaluasi
Analis sistem memperkenalkan prototype kepada user, menuntun user untuk mengenali karakteristik dari prototype. Dari kesempatan uji coba ini, user akan memberikan pendapatnya pada analis sistem.Kalau prototype diterima dilanjutkan ketahap selanjutnya. Kalau ada perbaikan maka langkah berikutnya adalah mengulangi tahap1, 2 dan 3 dengan pengertian yang lebih baik tentang apa yang diinginkan oleh user.
2.5.5 XAMPP
Xampp adalah installer yang membundel Apache, PHP,dan MySQL untuk Windows dalam satu paket. XAMPP adalah sebuah software web server apache yang didalamnya sudah tersedia database server mysql dan support php programming. XAMPP merupakan software yang mudah digunakan gratis dan mendukung instalasi di linux dan windows. Keuntungan lainya adalah cuma menginstal satu kali sudah tersedia apache web server, mysql database server, php support (php4 dan php5) dan beberapa modul lainya hanya bedanya kalau versi windows selalu dalam bentuk instalasi grafis dan yang linux dalam bentuk file terkompresi tar.gz. kelebihan lain yang berbeda dari versi untuk windows adalah memeliki fitur untuk mengaktifkan sebuah serve rsecara grafis, sedangkan linux
masih berupa perintah-perintah di dalam console. Oleh karena itu versi untuk linux sulit untuk dioperasikan.[28]
2.5.6 Kerangka Berfikir
Tabel 2. 5 Kerangka Berfikir