BAB II
TINJAUAN PUSTAKA
2.1 Analisis Gerombol
2.1.1 Pengertian Analisis Gerombol
Cluster atau ‘gerombol’ dapat diartikan ‘kelompok’ dengan demikian, pada dasarnya analisis gerombol akan menghasilkan sejumlah gerombol (kelompok). Analisis ini diawali dengan pemahaman bahwa sejumlah data tertentu sebenarnya mempunyai kemiripan di antara anggotanya; karena itu, dimungkinkan untuk mengelompokkan anggota-anggota yang ‘mirip’ atau mempunyai karakteristik yang serupa tersebut dalam satu atau lebih dari satu gerombol (Santoso, 2010).
Analisis gerombol melakukan sebuah usaha untuk menggabungkan keadaan atau objek ke dalam suatu kelompok, dimana anggota kelompok itu tidak diketahui sebelumnya untuk dianalisis. Dengan kata lain analisis gerombol merupakan analisis statistik yang digunakan untuk mengelompokan n objek ke dalam k buah kelompok, dengan setiap objek dalam kelompok memiliki keragaman yang besar dibandingkan antar kelompok (Afifi & Clark, 1999).
Menurut Sharma (1996:185) yang dikutip dari Nuningsih (2010), analisis gerombol merupakan salah satu teknik multivariat metode interdependensi (saling ketergantungan). Oleh karena itu, dalam analisis gerombol tidak ada pembedaan antara variabel bebas (independent variable) dan variabel terikat (dependent variable).
Analisis gerombol adalah teknik yang digunakan untuk menggabungkan observasi ke dalam kelompok atau gerombol, sedemikian sehingga :
a. Setiap kelompok atau gerombol homogen mempunyai karakteristik tertentu. Hal ini berarti bahwa observasi dalam setiap kelompok sama dengan observasi lain dalam satu kelompok yang sama.
b. Setiap kelompok seharusnya berbeda dari kelompok lain dengan karakteristik yang sama. Hal ini berarti bahwa observasi dalam kelompok yang satu seharusnya berbeda dari observasi dalam kelompok lain.
Menurut Tan et al (2006:490) yang dikutip dari Nuningsih (2010), analisis gerombol digunakan untuk mengelompokkan data observasi yang hanya berdasarkan pada informasi yang ditemukan dalam data, di mana data tersebut harus menggambarkan observasi dan hubungannya. Oleh karena itu, tujuan dari analisis ini adalah observasi dalam satu kelompok mirip satu sama lain dan berbeda dari observasi dalam kelompok lain. Semakin besar kemiripan (homogenitas) dalam kelompok dan semakin besar perbedaan (heterogenitas) antar kelompok maka penggerombolan akan lebih baik atau lebih berbeda.
Pada prinsipnya analisis gerombol merupakan proses untuk mereduksi sejumlah objek yang besar menjadi lebih sedikit yang disebut gerombol. Analisis gerombol digunakan oleh peneliti yang belum mengetahui anggota dari suatu kelompok. Analisis gerombol disebut juga Q-analysis, classification analysis, pengenalan pola (pattern recognition), analisis segmentasi (numerical taxonomy) (Supranto, 2004).
2.1.2 Tujuan Analisis Gerombol
1. Mengetahui ada tidaknya perbedaan yang nyata (signifikan) antar kelompok yang terbentuk, dalam hal ini gerombol yang dihasilkan.
2. Melihat profil serta kecenderungan-kecenderungan dari masing-masing gerombol yang terbentuk.
3. Melihat posisi masing-masing objek terhadap objek lainnya dari gerombol yang terbentuk.
2.1.3 Asumsi Analisis Gerombol
Asumsi yang harus dipenuhi pada analisis gerombol: (Santoso, 2010)
1. Sampel yang diambil benar-benar bisa mewakili populasi yang ada. Memang tidak ada ketentuan jumlah sampel yang representatif, namun tetaplah diperlukan sejumlah sampel yang cukup besar agar proses clustering bisa dilakukan dengan benar.
2. Multikolinearitas, yaitu kemungkinan adanya korelasi antar objek. Sebaiknya tidak ada atau seandainya ada, besar multikolinearitas tersebut tidaklah tinggi (misal di atas 0,5). Jika sampai terjadi multikolinearitas, dianjurkan untuk menghilangkan salah satu variabel dari dua variabel yang mempunyai korelasi cukup besar.
2.1.4 Melakukan Analisis Gerombol
Analisis gerombol ini terdiri dari beberapa proses dasar, yaitu : 1. Merumuskan Masalah
Hal yang paling penting di dalam perumusan masalah analisis gerombol ialah pemilihan variabel-variabel yang akan dipergunakan untuk penggerombolan (pembentukan gerombol). Memasukkan satu atau dua variabel yang tidak relevan
dengan masalah penggerombolan/pengelompokan akan mendistorsi hasil penggerombolan yang kemungkinan besar sangat bermanfaat.
Pada dasarnya set variabel yang akan dipilih harus menguraikan kemiripan antara objek, yang memang benar-benar relevan dengan masalah riset pemasaran. Variabel harus dipilih berdasarkan penelitian sebelumnya, teori atau suatu pertimbangan berkenaan dengan hipotesis yang akan diuji. Di dalam riset eksplorasi peneliti harus menggunakan pertimbangan dan intuisi.
2. Memilih Ukuran Jarak atau Similaritas
Oleh karena tujuan penggerombolan ialah untuk mengelompokkan objek yang mirip dalam gerombol yang sama, maka beberapa ukuran diperlukan untuk mengakses seberapa mirip atau berbeda objek-objek tersebut. Pendekatan yang paling biasa ialah mengukur kemiripan dinyatakan dalam jarak (distance) antara pasangan objek (Supranto, 2004).
Objek dengan jarak yang lebih pendek antara mereka akan lebih mirip satu sama lain dibandingkan dengan pasangan dengan jarak yang lebih panjang. Ada 3 metode yang digunakan : (Santoso, 2010)
a. Mengukur korelasi antara sepasang objek pada beberapa variabel. Cara ini sebenarnya sederhana; jika beberapa data memang akan ‘tergabung’ menjadi satu gerombol, tentulah di antara data tersebut ada hubungan yang erat, atau disebut berkorelasi satu dengan yang lain. Metode ini mendasarkan besaran korelasi antara data untuk mengetahui kemiripan data satu dengan yang lain.
b. Mengukur jarak (distance) antara dua objek. Pengukuran ada bermacam-macam, yang paling popular adalah metode Euclidean Distance. Pada dasarnya, cara ini memasukkan sebuah data ke dalam gerombol tertentu dengan mengukur ‘jarak’ data tersebut dengan pusat gerombol. Jika data ada dalam jarak yang masih ada dalam batas tertentu, data tersebut dapat dimasukkan pada gerombol tersebut.
c. Mengukur asosiasi antar-objek. Pada dasarnya, cara ini akan mengasosiasikan sebuah data dengan gerombol tertentu; dalam praktek, cara ini tidak sepopuler kedua cara sebelumnya.
Korelasi dan distance digunakan jika data adalah metrik, sedangkan asosiasi digunakan jika data adalah non-metrik.
Dalam praktek, penggunaan metode Euclidean Distance adalah yang paling popular.
3. Melakukan Proses Standarisasi Data Jika Diperlukan
Setelah cara mengukur jarak ditetapkan, yang juga perlu diperhatikan adalah apakah satuan data mempunyai perbedaan yang besar. Sebagai contoh, jika variabel penghasilan mempunyai satuan juta (000.000), sedangkan usia seseorang hanya mempunyai satuan puluhan (00), maka perbedaan yang mencolok ini akan membuat perhitungan jarak (distance) menjadi tidak valid. Jika data memang mempunyai satuan yang berbeda secara signifikan, pada data harus dilakukan proses standarisasi dengan mengubah data yang ada ke Z-Score. Proses standarisasi menjadikan dua data dengan perbedaan satuan yang lebar akan otomatis menjadi menyempit (Santoso, 2010).
4. Memilih Suatu Prosedur Penggerombolan
Setelah data yang dianggap mempunyai satuan yang sangat berbeda diseragamkan, dan metode gerombol ditentukan (misal dipilih Eucledian), langkah selanjutnya adalah pengelompokan data, yang bisa dilakukan dengan dua metode:
a. Hierarchical Method, ialah metode yang memulai pengelompokannya dengan dua atau lebih obyek yang mempunyai kesamaan paling dekat, kemudian proses dilanjutkan ke objek lain yang mempunyai kedekatan kedua. Demikian seterusnya sehingga gerombol akan membentuk semacam “pohon” dimana ada hierarki (tingkatan) yang jelas antar objek, dari yang paling mirip sampai dengan yang paling tidak mirip. Secara logika semua objek pada akhirnya hanya akan membentuk sebuah gerombol. Dendogram biasanya digunakan untuk membantu memperjelas proses hierarki tersebut.
b. Non Hirarchical Method, ialah metode yang dimulai dengan menentukan terlebih dahulu jumlah gerombol yang diinginkan (dua gerombol, tiga gerombol atau yang lain). Dan kemudiaan baru dilakukan proses gerombol tanpa mengikuti proses hierarki. Biasa disebut metode K-Means Cluster. Dua kelemahan dari prosedur non-hierarki ialah bahwa banyaknya gerombol harus disebutkan/ditentukan sebelumnya dan pemilihan pusat gerombol sembarang. Lebih lanjut, hasil gerombol mungkin tergantung pada bagaimana pusat dipilih. Banyak program non-hierarki, memilih k objek (kasus) yang pertama, tanpa ada nilai yang hilang sebagai pusat
tergantung pada urutan observasi dalam data. Bagaimanapun juga, gerombol non-hierarki lebih cepat daripada metode hierarki dan lebih menguntungkan kalau jumlah objek/kasus atau observasi besar sekali (sampel besar).
5. Melakukan Interpretasi Terhadap Gerombol yang Telah Terbentuk.
Setelah sejumlah gerombol terbentuk dengan metode hierarki atau non-hierarki, langkah selanjutnya adalah melakukan interpretasi terhadap gerombol yang telah terbentuk, yang pada intinya memberi nama spesifik untuk menggambarkan isi gerombol tersebut.
6. Melakukan Validasi dan Profiling Cluster
Gerombol yang terbentuk kemudian diuji apakah hasil tersebut valid. Kemudian dilakukan proses profiling untuk menjelaskan karakteristik setiap gerombol berdasar profil tertentu (seperti usia konsumen pembeli rumah, tingkat penghasilannya dan sebagainya). Dari data profiling tersebut bisa dilakukan analisis lanjutan seperti Analisis Diskriminan.
2.1.5 Metode Pengelompokan
Dalam analisis gerombol, terdapat banyak metode untuk mengelompokkan observasi ke dalam gerombol. Secara umum metode pengelompokkan dalam analisis gerombol dibedakan menjadi hirarki (Hierarchical Clustering Method) dan metode non hirarki (Nonhierarchical Clustering Method). Metode hirarki digunakan apabila belum ada informasi jumlah gerombol yang dipilih. Sedangkan metode non hirarki bertujuan untuk mengelompokkan n objek ke dalam k gerombol (k < n), di mana nilai k telah ditentukan sebelumnya.
Metode analisis gerombol membutuhkan suatu ukuran ketakmiripan (jarak) yang didefinisikan untuk setiap pasang objek yang akan dikelompokan. Jarak yang biasa digunakan dalam analisis penggerombolan diantaranya (Johnson & Wichern, 2007) adalah :
a. Jarak Euclidian
Jarak Euclidian adalah jarak yang paling umum dan paling sering digunakan dalam analisis gerombol. Jarak Euclidian antara dua titik dapat terdefinisikan dengan jelas. Jarak digunakan adalah peubah kontinu.
Jarak Euclidian antara gerombol ke-i dan ke-j dari p peubah didefinisikan:
dengan :
d(i,j) = jarak antara objek i ke objek j = nilai tengah pada gerombol ke-i
= nilai tengah pada gerombol ke-j p = banyaknya peubah yang diamati b. Jarak Mahalanobis
Jarak Mahalanobis sangat berguna dalam menghilangkan atau mengurangi perbedaan skala pada masing-masing komponen. Pada permasalahan tertentu, pada saat menentukan jarak, perlu juga dipertimbangkan ragam dan peragam. Jarak Mahalanobis didefinisikan:
dengan :
d(i,j) = jarak antara objek i ke objek j = nilai tengah pada gerombol ke-i = nilai tengah pada gerombol ke-j
S-1 = matriks ragam peragam gabungan antara c. Jarak Manhattan
Ukuran ini merupakan bentuk umum dari jarak Euclidian, fungsi jaraknya didefinisikan:
dengan:
d(i,j) = jarak antara objek i ke objek j = nilai tengah pada gerombol ke-i = nilai tengah pada gerombol ke-j p = banyaknya peubah yang diamati d. Jarak Log Likehood
Jarak Log Likelihood dapat diterapkan untuk peubah kontinu maupun kategorik. Asumsi yang ada pada jarak ini adalah peubah kontinu menyebar normal, peubah kategorik menyebar multinomial dan antar peubahnya saling bebas. Metode
Two Step Cluster cukup tegar terhadap pelanggaran asumsi tersebut sehingga metode ini masih dapat digunakan ketika terjadi pelanggaran asumsi.
Jarak antara gerombol j dan s didefinisikan:
dengan :
Keterangan :
N = jumlah total observasi
= jumlah observasi di dalam gerombol j
Njkl = jumlah data di gerombol j untuk peubah kategorik ke-k dengan kategorik
ke-l
= ragam dugaan untuk peubah kontinu ke-k untuk keseluruhan observasi = ragam dugaan untuk peubah kontinu ke-k dalam gerombol j
KB = jumlah total peubah kategorik
Lk = jumlah kategorik untuk peubah kategorik ke-k
d(j,s) = jarak antara gerombol j dan s <j,s> = indeks kombinasi gerombol j dan s
Jarak Euclid dan jarak Manhattan digunakan jika antar peubah memiliki satuan yang sama dan korelasi antar peubahnya tidak nyata. Sedangkan jika satuan antar peubah tidak sama dapat menggunakan jarak Euclid maupun jarak Manhattan yang telah ditransformasi ke dalam bentuk baku. Jika adanya korelasi antar peubah yang nyata, jarak yang digunakan menggunakan jarak Mahalanobis atau jika menggunakan jarak Euclid maka peubah asal ditransformasi menggunakan analisis komponen utama (AKU).
1. Metode Hirarki
Pada dasarnya metode ini dibedakan menjadi dua metode pengelompokkan, yaitu:
a. Metode Penggabungan
Proses pengelompokan dengan pendekatan metode penggabungan (Down to Top) dimulai dengan n gerombol sehingga masing-masing gerombol memiliki tepat satu objek, kemudian tentukan dua gerombol terdekat dan gabungkan gerombol tersebut menjadi satu gerombol baru. Proses penggabungan dua gerombol diulangi sampai diperoleh satu gerombol yang memuat semua himpunan data. Perlu diperhatikan bahwa setiap penggabungan dalam metode ini selalu diikuti dengan perbaikan matriks jarak. Hasil analisis gerombol dari metode ini dapat disajikan dalam bentuk dendogram.
b. Metode Pemecahan
Proses pengelompokan dengan pendekatan metode pemecahan (Top to Down) dimulai dengan n objek yang dikelompokkan menjadi satu gerombol, kemudian gerombol tersebut dipartisi ke dalam dua gerombol pada setiap langkah sampai diperoleh n gerombol dengan setiap gerombol memiliki satu objek.
2. Metode Non-Hirarki
Metode penggerombolan tak berhirarki digunakan apabila banyak gerombol yang akan dibentuk sudah diketahui terlebih dahulu. Salah satu contohnya adalah metode K-means. Pada metode ini harus ditentukan terlebih dahulu besarnya k, yaitu banyaknya gerombol. Pemilihan k dapat ditentukan secara subjektif berdasarkan latar belakang bidang masing-masing. Jarak yang biasanya digunakan adalah jarak Euclidean.
Dalam metode ini data dibagi dalam k partisi, setiap partisi mewakili sebuah gerombol. Secara umum proses metode non-hirarki sebagai berikut :
a. Pilih k centroid gerombol awal atau seed, di mana k merupakan jumlah gerombol yang diinginkan.
b. Tempatkan setiap observasi ke dalam gerombol yang terdekat.
c. Tempatkan kembali setiap observasi ke dalam k gerombol menurut aturan penghentian yang sudah ditentukan.
d. Proses berhenti jika tidak ada observasi yang berpindah lagi, jika belum ulangi langkah kedua.
Beberapa algoritma non-hirarki berbeda dalam aturan untuk memperoleh centroid gerombol awal dan aturan yang digunakan untuk menempatkan kembali observasi. Beberapa aturan yang digunakan untuk memperoleh seed awal antara lain : 1) Pilih k observasi pertama dengan tidak ada data yang hilang sebagai centroid atau
seed gerombol awal.
2) Pilih observasi pertama dengan tidak ada data yang hilang sebagai seed gerombol pertama, lalu seed gerombol kedua dipilih dari observasi yang mempunyai jarak terjauh dari sebelumnya, dan seterusnya.
3) Pilih secara random k observasi dengan tidak ada data yang hilang sebagai pusat gerombol atau seed.
4) Perbaiki seed yang dipilih dengan menggunakan aturan tertentu sehingga jarak seed tersebut sejauh mungkin.
5) Gunakan heuristic tentang identifikasi pusat gerombol sehingga jarak pusat gerombol tersebut sejauh mungkin.
6) Gunakan seed yang disediakan oleh peneliti.
Setelah seed diidentifikasi, gerombol awal yang dibentuk akan menempatkan kembali n - k observasi sisanya ke dalam seed yang terdekat dengan observasi tersebut.
Beberapa algoritma non hirarki juga berbeda terkait dengan prosedur yang digunakan dalam penempatan kembali observasi ke dalam k gerombol. Adapun aturan penempatan kembali observasi sebagai berikut :
1) Hitung centroid setiap gerombol dan tempatkan kembali observasi ke dalam gerombol berdasarkan centroid terdekat. Centroid ke dalam k gerombol, centroid
dihitung ulang setelah penempatan kembali semua observasi yang telah dibuat. Jika perubahan dalam centroid gerombol lebih besar daripada kriteria konvergensi yang dipilih maka penempatan kembali setiap observasi terus dilakukan. Proses penempatan kembali dilanjutkan hingga perubahan centroid kurang dari kriteria konvergensi yang dipilih.
2) Hitung centroid setiap gerombol dan tempatkan kembali observasi ke dalam gerombol berdasarkan centroid terdekat. Untuk penempatan kembali setiap observasi, hitung ulang centroid gerombol di mana observasi ditempatkan dan gerombol dari mana observasi ditempatkan. Sekali lagi penempatan kembali dilanjutkan hingga perubahan centroid gerombol kurang dari kriteria konvergensi yang dipilih.
3) Tempatkan kembali observasi sedemikian sehingga beberapa fungsi objektif diminimumkan.
Pada dasarnya, algoritma non-hirarki dibedakan atas teknik partitioning, overlapping dan hybrid. Sebelum membahas partitioning sebagai dasar metode K-Means, secara singkat akan dibahas overlapping dan hybrid.
Overlapping terjadi apabila data tumpang tindih sehingga suatu objek dapat termasuk ke dalam beberapa gerombol. Dalam teknik ini data mempunyai nilai keanggotaan (membership). Sedangkan hybrid merupakan teknik penggabungan antara metode hirarki dan non-hirarki.
Dalam pendekatan partitioning, observasi dibagi ke dalam k gerombol tanpa menggunakan matriks jarak di antara semua pasangan titik seperti pada pendekatan
3. Metode Two Step Cluster
Metode Two Step Cluster merupakan suatu metode penggerombolan yang dapat mengatasi masalah skala pengukuran, khususnya untuk data berukuran besar dengan peubah yang memiliki tipe data kategorik dan kontinu, serta mengetahui gerombol optimasi yang terbentuk. Gerombol optimal memiliki jarak antar gerombol yang paling jauh, dan jarak antar obyek yang paling dekat. Fungsi jarak yang digunakan adalah jarak Euclidian atau jarak Log Likelihood. Karena menggunakan ukuran jarak tersebut, maka dimungkinkan digunakan berbagai tipe data baik kontinu maupun kategorik. Hasil akhir dari metode ini adalah pembentukan gerombol optimal berdasarkan kriteria tertentu (Bacher et al, 2004).
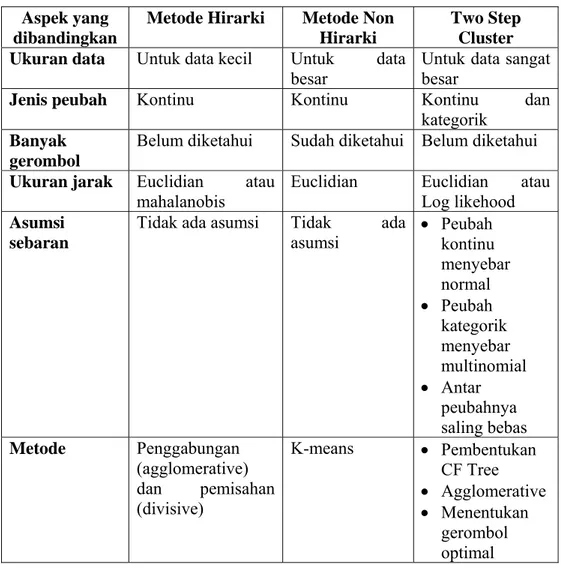
Menurut Chiu et al (2001) yang dikutip dari Karlina (2007) adapun perbedaan metode Hirarki, Non Hirarki dan Two Step Cluster yaitu :
Tabel 2.1 Perbandingan Metode Hirarki, Non Hirarki, dan Two Step Cluster
2.1.6 Metode K-means
K-Means merupakan salah satu metode data clustering non hirarki yang berusaha mempartisi data yang ada ke dalam bentuk satu atau lebih gerombol/cluster. Metode ini mempartisi data ke dalam gerombol sehingga data yang memiliki karakteristik sama dikelompokkan ke dalam satu gerombol yang sama. Dasar
Aspek yang dibandingkan
Metode Hirarki Metode Non Hirarki
Two Step Cluster Ukuran data Untuk data kecil Untuk data
besar
Untuk data sangat besar
Jenis peubah Kontinu Kontinu Kontinu dan
kategorik Banyak
gerombol
Belum diketahui Sudah diketahui Belum diketahui Ukuran jarak Euclidian atau
mahalanobis
Euclidian Euclidian atau
Log likehood Asumsi
sebaran
Tidak ada asumsi Tidak ada
asumsi Peubah kontinu menyebar normal Peubah kategorik menyebar multinomial Antar peubahnya saling bebas Metode Penggabungan (agglomerative) dan pemisahan (divisive) K-means Pembentukan CF Tree Agglomerative Menentukan gerombol optimal
pengelompokan dalam metode ini adalah menempatkan objek berdasarkan rata-rata (mean) gerombol terdekat (Jhonson & Wichern, 2007). Algoritma K-Means memerlukan 3 komponen yaitu:
1. Jumlah Gerombol K
Seperti yang telah dijelaskan sebelumnya, K-Means merupakan bagian dari metode non-hirarki sehingga dalam metode ini jumlah k terus harus ditentukan terlebih dahulu. Jumlah gerombol k dapat ditentukan melalui pendekatan metode hirarki. Namun perlu diperhatikan bahwa tidak terdapat aturan khusus dalam menentukan jumlah gerombol k, terkadang jumlah gerombol yang diinginkan tergantung pada subjektif seseorang.
2. Gerombol Awal
Gerombol awal yang dipilih berkaitan dengan penentuan pusat gerombol awal (centroid awal). Dalam hal ini, terdapat beberapa pendapat dalam memilih gerombol awal untuk metode K-Means sebagai berikut:
a. Pemilihan gerombol awal dapat ditentukan berdasarkan interval dari jumlah setiap observasi.
b. Pemilihan gerombol awal dapat ditentukan melalui pendekatan salah satu metode hirarki.
c. Pemilihan gerombol awal dapat secara acak dari semua observasi.
Oleh karena adanya pemilihan gerombol awal yang berada ini maka kemungkinan besar solusi gerombol yang dihasil akan berbeda pula.
3. Ukuran Jarak
Dalam hal ini, ukuran jarak digunakan untuk menempatkan observasi ke dalam gerombol berdasarkan centroid terdekat. Ukuran jarak yang digunakan dalam metode K-Means adalah jarak Euclid.
2.2 Analisis Diskriminan
Analisis diskriminan adalah teknik multivariat yang termasuk pada Dependence Method, dengan ciri adanya variabel dependen dan independen. Dengan demikian, ada variabel yang hasilnya tergantung pada variabel independen. Ciri khusus analisis diskriminan adalah data variabel dependen harus berupa data kategori, sedangkan data untuk variabel independen berupa data rasio.
Kegunaan analisis diskriminan ada dua yaitu pertama adalah kemampuan memprediksi terjadinya variabel dependen dengan memasukkan data variabel independen; kedua adalah kemampuan memilih mana variabel independen yang secara nyata memengaruhi variabel dependen dan mana yang tidak (Santoso, 2010). 2.2.1 Tujuan Analisis Diskriminan
Adapun tujuan analisis diskriminan adalah : (Yasril, 2009)
1. Membuat suatu fungsi diskriminan dari variabel independen yang bisa mendiskriminan atau membedakan kelompok variabel dependen, artinya mampu membedakan suatu objek masuk kelompok yang mana.
2. Menguji apakah ada perbedaan signifikan antara kelompok, dikaitkan dengan variabel independen.
4. Mengelompokkan (mengklasifikasikan) variabel dependen ke dalam suatu kelompok didasarkan pada nilai variabel independen.
2.2.2 Asumsi Analisis Diskriminan
Asumsi-asumsi yang harus dipenuhi untuk analisis diskriminan adalah : (Yasril, 2009)
1. Multivariate Normality
Bila menggunakan teknik analisis multivariat dengan analisa diskriminan, variabel independen seharusnya berdistribusi normal. Jika data tidak berdistribusi normal, hal ini akan menyebabkan masalah pada ketepatan fungsi (model) diskriminan. Regresi Logistik bisa dijadikan alternatif metode jika memang data tidak berdistribusi normal.
2. Matriks kovarians dari semua variabel independen seharusnya sama (equel) 3. Tidak adanya data yang sangat ekstrim (outlier) pada variabel independen.
Jika ada data outlier yang tetap diproses, hal ini bisa berakibat berkrangnya ketepatan klasifikasi dari fungsi diskriminan.
4. Tidak ada multikolinearitas antar variabel independen.
Multikolinearitas terjadi bila ada variabel independen yang berkorelasi sangat kuat dengan variabel independen lainnya. Untuk mengetahui adanya multikolinearitas dapat dilakukan dengan melihat korelasi antar variabel independen yaitu jika nilai r > 0,8 menunjukkan adanya multikolinearitas. 2.2.3 Model Analisis Diskriminan
Model analisis diskriminan berkenaan dengan kombinasi linier yang disebut juga fungsi diskriminan bentuknya sebagai berikut : (Yasril, 2009)
Zjk = a + W1X1k + W2X2k + … + WnXnk dimana
Zjk = Nilai (skor) diskriminan dari fungsi diskriminan j untuk objek k
a = Intercept
Wn = Timbangan diskriminan untuk variabel independen
Xnk = Variabel independen n untuk objek k
2.2.4 Langkah-Langkah Analisis Diskriminan
1. Desain penelitian untuk analisis diskriminan (Yasril, 2009): a. Pemilihan variabel dependen dan independen
Sebelum menggunakan analisis diskriminan, peneliti harus menentukan terlebih dahulu mana variabel dependen dan mana variabel independen. Sesuai dengan ketentuan di atas, variabel dependen harus merupakan variabel kategorik sedang variabel independen merupakan variabel numerik.
Berdasarkan jumlah kelompok variabel dependen yang dalam hal ini harus mutually exclusive dan exhaustive, analisis diskriminan dibedakan menjadi dua yaitu :
1) Analisis diskriminan dua kategorik/kelompok, dimana variabel dependen dikelompokkan menjadi 2 (dikotomi), diperlukan satu fungsi diskriminan. 2) Analisis diskriminan berganda (Multiple Discriminant Anlysis/MDA),
dimana variabel dependen dikelompokkan menjadi lebih dari 2 kelompok (multikotomi), diperlukan fungsi diskriminan sebanyak (k-1) kalau ada k kategori.
Pada analisis diskriminan tidak ada ketentuan untuk besar sampel, tetapi beberapa penelitian menyarankan 5-20 sampel untuk setiap variabel independen. Dengan demikian jika ada lima variabel independen, seharusnya minimal ada 25 sampel.
c. Pembagian Sampel
Ada beberapa cara pembagian sampel yang dilakukan, tetapi yang paling sering digunakan adalah membagi menjadi 2 kelompok yaitu kelompok sampel analisis yang digunakan untuk membuat estimasi nilai koefisien fungsi diskriminan dan kelompok validasi yang digunakan untuk menguji hasil diskriminan. Jumlah tiap kelompok biasanya sama besar walaupun ini tidak mutlak.
Apabila peran bagian pertama kemudian ditukar dengan peran bagian kedua, analisis diulangi, yang dipergunakan untuk estimasi kemudian untuk validasi, ini yang disebut double cross validation.
2. Pembentukan fungsi diskriminan
Ada dua metode dasar untuk membuat fungsi diskriminan :
a. Direct Method (Simultaneous Estimation), dimana semua variabel dimasukkan secara bersama-sama kemudian dilakukan proses dikriminan
b. Step-wise Discriminant Analysis, dimana variabel dimasukkan satu persatu ke dalam model diskriminan.
Untuk menguji signifikan fungsi diskriminan dilihat nilai signifikan dari Wilk’s Lambda, Pilai, F test dan lainnya (Santoso, 2010). Jika p > 0,05, maka menunjukkan bahwa fungsi diskriminan ini dapat memperlihatkan perbedaan yang jelas antara dua kelompok variabel dependen (Yasril, 2009).
4. Menguji ketepatan klasifikasi dari fungsi diskriminan
Untuk menguji ketepatan klasifikasi fungsi diskriminan dilakukan uji dengan Casewise Diagnostics. Jika fungsi diskriminan mempunyai ketepatan mengklasifikasi kasus > 50%, ketepatan model dianggap tinggi.
5. Melakukan interpretasi terhadap fungsi diskriminan tersebut 2.3 Program Kesehatan Ibu dan Anak (KIA)
2.3.1 Pengertian Program Kesehatan Ibu dan Anak (KIA)
Program Kesehatan Ibu dan Anak (KIA) merupakan salah satu prioritas utama pembangunan kesehatan di Indonesia. Program ini bertanggung jawab terhadap pelayanan kesehatan bagi ibu hamil, ibu melahirkan dan bayi neonatal. Salah satu tujuan program ini adalah menurunkan kematian dan kejadian sakit di kalangan ibu (Hasanbasri, 2007).
Pengelolaan program KIA bertujuan memantapkan dan meningkatkan jangkauan serta mutu pelayanan KIA secara efektif dan efisien. Pemantapan pelayanan KIA dewasa ini diutamakan pada kegiatan pokok sebagai berikut (Depkes, 2009) :
a. Peningkatan pelayanan antenatal di semua fasilitas pelayanan dengan mutu sesuai standar serta menjangkau seluruh sasaran.
b. Peningkatan pertolongan persalinan ditujukan kepada peningkatan pertolongan oleh tenaga kesehatan kebidanan secara berangsur.
c. Peningkatan deteksi dini risiko tinggi/komplikasi kebidanan, baik oleh tenaga kesehatan maupun masyarakat oleh kader dan dukun bayi serta penanganan dan pengamatannya secara terus menerus.
d. Peningkatan penanganan komplikasi kebidanan secara adekuat dan pengamatan secara terus menerus oleh tenaga kesehatan.
e. Peningkatan pelayanan neonatal dan ibu nifas dengan mutu sesuai standard yang menjangkau seluruh sasaran.
2.3.2 Tujuan Program Kesehatan Ibu dan Anak (KIA)
Tujuan Program Kesehatan Ibu dan Anak (KIA) adalah tercapainya kemampuan hidup sehat melalui peningkatan derajat kesehatan yang optimal, bagi ibu dan keluarganya untuk menuju Norma Keluarga Kecil Bahagia Sejahtera (NKKBS) serta meningkatnya derajat kesehatan anak untuk menjamin proses tumbuh kembang optimal yang merupakan landasan bagi peningkatan kualitas manusia seutuhnya (Erliana, 2009).
Sedangkan tujuan khusus program KIA adalah : (Nasir, 2008)
1. Meningkatnya kemampuan ibu (pengetahuan, sikap dan perilaku), dalam mengatasi kesehatan diri dan keluarganya dengan menggunakan teknologi tepat guna dalam upaya pembinaan kesehatan keluarga, paguyuban 10 keluarga, Posyandu dan sebagainya.
2. Meningkatnya upaya pembinaan kesehatan balita dan anak prasekolah secara mandiri di dalam lingkungan keluarga, paguyuban 10 keluarga, Posyandu, dan Karang Balita serta di sekolah Taman Kanak-kanak atau TK.
3. Meningkatnya jangkauan pelayanan kesehatan bayi, anak balita, ibu hamil, ibu bersalin, ibu nifas, dan ibu meneteki.
4. Meningkatkan mutu pelayanan kesehatan ibu hamil, ibu bersalin, ibu nifas, ibu meneteki, bayi dan anak balita.
5. Meningkatnya kemampuan dan peran serta masyarakat, keluarga dan seluruh anggotanya untuk mengatasi masalah kesehatan ibu, balita, anak prasekolah, terutama melalui peningkatan peran ibu dan keluarganya.
2.3.3 Pelayanan Kesehatan Ibu dan Anak (KIA) 1. Pelayanan Antenatal
Pelayanan antenatal merupakan pelayanan kesehatan oleh tenaga kesehatan professional (dokter spesialis obgyn, dokter umum, bidan dan perawat) seperti pengukuran berat badan dan tekanan darah, pemeriksaan tinggi fundus uteri, imunisasi tetanus toxoid (TT) serta pemberian tablet besi kepada ibu hamil selama masa kehamilannya sesuai pedoman pelayanan antenatal yang ada dengan titik berat pada kegiatan promotif dan preventif. Hasil pelayanan antenatal dapat dilihat dari cakupan palayanan K1 dan K4 (Dinkes Provsu, 2011).
Kunjungan baru ibu hamil (K1) adalah kunjungan ibu hamil yang pertama kali pada masa kehamilan. Sedangkan cakupan K4 ibu hamil adalah kontak ibu hamil dengan tenaga kesehatan yang keempat (atau lebih), untuk mendapatkan pelayanan
pada triwulan I, satu kali kontak pada triwulan II, dan dua kali kontak pada triwulan III (Depkes, 2009).
2. Pertolongan Persalinan oleh Tenaga Kesehatan dengan Kompetensi Kebidanan
Pertolongan persalinan oleh tenaga kesehatan adalah pertolongan persalinan oleh petugas kesehatan, tidak termasuk pertolongan pendampingan. Pertolongan persalinan dilakukan oleh dokter ahli, dokter, bidan atau petugas kesehatan lainnya yang telah memperoleh pelatihan tehnis untuk melakukan pertolongan kepada ibu bersalin. Dilakukan sesuai dengan pedoman dan prosedur teknis yang telah ditetapkan (Dinkes Provsu, 2011).
Periode persalinan merupakan salah satu periode yang berkontribusi besar terhadap Angka Kematian Ibu di Indonesia. Kematian saat bersalin dan 1 minggu pertama diperkirakan 60% dari seluruh kematian ibu. Sedangkan dalam target MDG’s, salah satu upaya yang harus dilakukan untuk meningkatkan kesehatan ibu adalah menurunkan angka kematian ibu menjadi 102 per 100.000 kelahiran hidup pada tahun 2015 dari 425 per 100.000 kelahiran hidup pada tahun 1992 (SKRT) serta meningkatkan pertolongan persalinan oleh tenaga kesehatan adalah pelayanan persalinan yang aman yang dilakukan oleh tenaga kesehatan dengan kompetensi kebidanan (Depkes, 2011).
3. Cakupan Pelayanan Kesehatan Ibu Nifas (KF3)
Masa nifas atau pueperium adalah masa setelah plasenta lahir dan berakhir ketika alat “kandungan” seperti keadaan sebelum hamil yang berlangsung selama ± 6 minggu. Pelayanan kesehatan ibu nifas adalah pelayanan kesehatan sesuai standar
pada ibu mulai 6 jam sampai 42 hari pasca persalinan oleh tenaga kesehatan. Untuk deteksi dini komplikasi pada ibu nifas diperlukan pemantauan pemeriksaan terhadap ibu nifas dengan melakukan kunjungan nifas minimal sebanyak 3 kali dengan distribusi waktu: 1) kunjungan nifas pertama (KF1) pada 6 jam setelah persalinan sampai 3 hari; 2) kunjungan nifas ke-2 (KF2) dilakukan dalam waktu hari ke-4 sampai dengan hari ke-28 setelah persalinan; dan 3) kunjungan nifas ke-3 (KF3) dilakukan dalam waktu hari ke-29 sampai dengan hari ke-42 setelah persalinan (Erliana, 2009).
Pelayanan kesehatan ibu nifas yang diberikan meliputi: 1) pemeriksaan tekanan darah, nadi, respirasi dan suhu; 2) pemeriksaan tinggi fundus uteri; 3) pemeriksaan lokhia dan pengeluaran per vaginam lainnya; 4) pemeriksaan payudara dan anjuran ASI eksklusif 6 bulan; 5) pemberian kapsul Vitamin A 200.000 IU sebanyak dua kali; 6) pelayanan KB pasca persalinan (Dinkes Provsu, 2011).
4. Rujukan Kasus Risti dan Penanganan Komplikasi
Dalam memberikan pelayanan khususnya oleh tenaga bidan di desa dan puskesmas, beberapa ibu hamil yang memiliki resiko tinggi (risti) dan memerlukan pelayanan kesehatan karena terbatasnya kemampuan dalam memberikan pelayanan, maka kasus tersebut perlu dilakukan upaya rujukan ke unit pelayanan kesehatan yang memadai.
Risti atau komplikasi kebidanan adalah keadaan penyimpangan dari normal, yang secara langsung menyebabkan kesakitan dan kematian ibu maupun bayi. Risti/komplikasi kebidanan meliputi; Hb < 8 g %, tekanan darah tinggi (sistole > 140
ketuban pecah dini, letak lintang pada usia kehamilan >32 minggu, letak sungsang pada primigravida, infeksi berat/sepsis, persalinan prematur (Dinkes Provsu, 2011).
Kejadian komplikasi kebidanan dan risiko tinggi diperkirakan terdapat pada sekitar 15-20% ibu hamil. Komplikasi dana kehamilan dan persalinan tidk selalu dapat diduga atau diramalkan sebelumnya, sehingga ibu hamil harus berada sedekat mungkin pada sarana pelayanan yang mampu memberikan Pelayanan Obstetri dan Neonatal Emergensi Dasar (PONED). Agar puskesmas mampu melaksanakan PONED maka harus didukung pula oleh tenaga medis terampil yang telah dilatih dan adanya sarana medis maupun non medis yang memadai.
Komplikasi obstetri ini merupakan penyebab langsung kematian ibu, yaitu perdarahan, infeksi, eklamsia, partus macet (persalinan kasip), abortus dan rupture uteri (robekan rahim). Sedangkan komplikasi neonatal adalah neonatal dengan penyakit dan kelainan yang dapat menyebabkan kesakitan, kecacatan, dan kematian yaitu seperti BBLR (berat badan lahir rendah <2500 gr.
Neonatal risti/komplikasi meliputi asfiksia, tetanus neonatorum, sepsis, trauma lahir, BBLR (berat badan lahir <2.500 gr), sindroma gangguan pernafasan dan kelainan neonatal. Neonatal risti/komplikasi yang tertangani adalah neonatal risti/komplikasi yang mendapat pelayanan oleh tenaga kesehatan terlatih, dokter dan bidan di polindes, puskesmas, rumah bersalin dan rumah sakit (Depkes, 2011).
5. Kunjungan Neonatal (KN1 dan KN3)
Kunjungan neonatal adalah kontak neonatal dengan tenaga kesehatan minimal 2 (dua) kali untuk mendapatkan pelayanan dan pemeriksaan kesehatan neonatal, baik
didalam maupun diluar gedung puskesmas (termasuk bidan desa, polindes dan kunjungan rumah) dengan ketentuan (Depkes, 2009) :
a. Kunjungan pertama kali pada hari pertama sampai pada hari ke tujuh (sejak 6 jam setelah lahir 7 hari)
b. Kunjungan kedua kali pada hari ke delapan sampai dengan hari keduapuluh delapan (8-28 hari)
Petugas kesehatan dalam melaksanakan pelayanan neonatus disamping melakukan pemeriksaan kesehatan bayi, juga dilakukan konseling perawatan bayi kepada ibunya. Pelayanan tersebut meliputi pelayanan kesehatan neonatal dasar (tindakan resusitasi, pencegahan hipotermia, pemberian ASI dini dan eksklusif, pencegahan infeksi berupa perawatan mata, tali pusat, kulit dan pemberian imunisasi), pemberian vitamin K, manajemen terpadu balita muda (MTBM) dan penyuluhan perawatan neonatus di rumah menggunakan buku KIA (Dinkes Provsu, 2011).
2.4 Kerangka Konsep
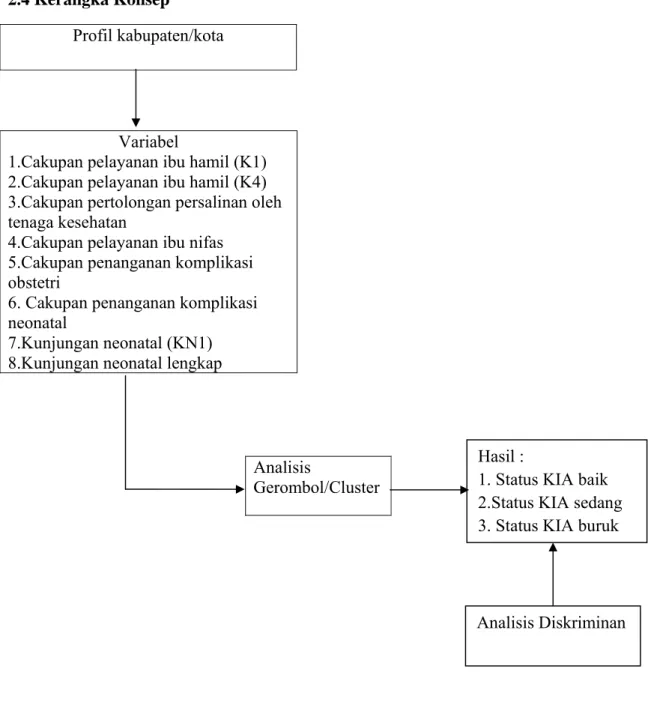
Gambar 2.1 Kerangka Konsep Penerapan Analisis Gerombol Untuk Profil Kesehatan Ibu dan Anak di Provinsi Sumatera Utara Tahun 2011
Profil kabupaten/kota
Variabel
1.Cakupan pelayanan ibu hamil (K1) 2.Cakupan pelayanan ibu hamil (K4) 3.Cakupan pertolongan persalinan oleh tenaga kesehatan
4.Cakupan pelayanan ibu nifas 5.Cakupan penanganan komplikasi obstetri
6. Cakupan penanganan komplikasi neonatal
7.Kunjungan neonatal (KN1) 8.Kunjungan neonatal lengkap
Analisis
Gerombol/Cluster
Hasil :
1. Status KIA baik 2.Status KIA sedang 3. Status KIA buruk