Tentang Saya
• Husni
• Web site : Husni.trunojoyo.ac.id • Email : [email protected]
• Ruang kerja:
• Lab. SisTer, Teknik Informatika, UTM.
• Bidang Keahlian:
• Networking
• Web Application Development
Ukuran Internet (per 27 Agustus 2017)
Update
Internet
6,586,013,574 Pencarian per-Hari...
Search Engine Pencarian per-HariGoogle 4,464,000,000
Bing 873,964,000
Baidu 583,520,803
Yahoo 536,101,505
Search Engine:
Information Retrieval
• Information retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections (usually stored on computers) [Manning, 2008].
• Information retrieval (IR) is the activity of obtaining information resources relevant to an information need from a collection of information resources [Wikipedia].
Outline
• Pendahuluan
• Model Konseptual
• Pengindeksan Dokumen • Contoh: Model Boolean • Pemrosesan Query
• Menilai Hasil Temu-Balik • Latihan
Pendahuluan
• Definisi: Information Retrieval (IR) atau Temu-Kembali Informasi
adalah tugas mencari teks yang relevan di dalam suatu jumlah besar dari data tak-terstruktur
• Relevan ≡ pencocokan teks dengan beberapa kriteria tertentu.
• Contoh dari tugas IR: pencarian email dari seseorang yang diberikan,
pencarian suatu even (peristiwa) yang terjadi pada suatu tanggal tertentu menggunakan Internet, dll.
• Contoh dari sistem IR: www search engines, search engines spesifik (dokumen hukum, medis), dll.
• NB: DataBases Management Systems (DBMS) berbeda dari sistem IR (data disimpan dalam suatu DB tersifat terstruktur!)
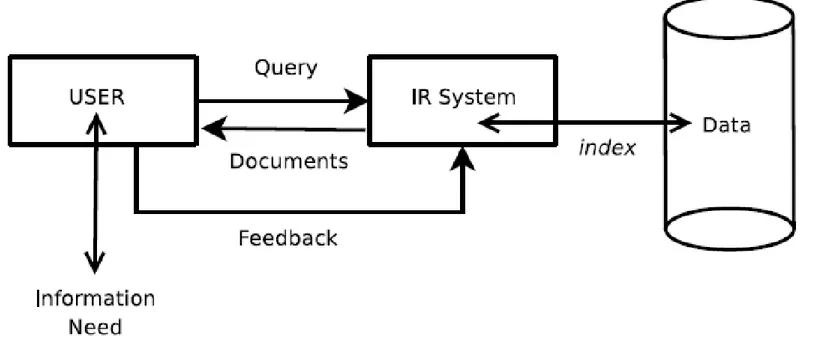
Model Konseptual
• Suatu tugas IR merupakan proses 3-langkah:
1. Menanyakan suatu pertanyaan: (bagaimana menggunakan bahasa untuk mendapatkan apa yang diinginkan?)
2. Membangun suatu jawaban dari data yang diketahui: (bagaimana mereferensi ke teks yang diberikan?)
3. Assessing jawabannya: (apakah ia mengandung informasi yang dicari?)
• Remarks:
• Model ini dapat me-loop, fase assessing kemudian membolehkan peningkatan kualitas jawaban (lebih lanjut nanti).
• Pengguna mungkin tidak mampu mendefinisikan dengan pasti pertanyaannya (yaitu mencirikan kebutuhan informasi mereka).
Pertimbangan Lebih Kognitif
• Aspek-aspek yang harus diperhtiungan dari sudut pandang sistem IR:
• How to allow to ask questions about information we are not aware of ?
• What if the question is ill-formed (aborting, looking for document matching close questions, asking for precisions) ?
• What if there is no answer (modifikasi otomatis dari pertanyaan) ?
• Apa format terbaik untuk jawaban tersebut (jawaban tunggal, jawaban terbentuk daftar berurut, dll.) ?
• Bagaimana memastikan bahwa jawaban akan dipahami (kosa kata yang digunakan, dll.) ?
• Semua pertanyaan ini harus dipertimbangkan dalam realisasi suatu
Gambar Besar
• Dalam kuliah ini, dianggap bahwa data sudah terpaket, sehingga kita lebih fokus pada bagaimana meretrieve dokumen-dokumen yang
Beberapa Istilah
• Suatu sistem IR mencari data yang cocok dengan beberapa kriteria yang didefinisikan oleh pengguna dalam querynya.
• Bahasa yang digunakan untuk mengajukan pertanyaan dinamakan bahasa query. • Query ini menggunakan keyword (kata kunci, item-item atomik yang mencirikan
beberapa data).
• Satuan dasar dari data adalah dokumen (dapat berupa suatu file, artikel, paragraf, dll.).
• Suatu dokumen dapat disamakan sebagai teks bebas (dapat tak-terstruktur). • Semua dokumen dikumpulkan ke dalam suatu koleksi (atau corpus).
• Contoh:
1 juta dokumen, masing-masing mengandung sekitar 1000 kata Jika masing-masing kata diencode menggunakan 6 bye, maka total 109 × 1000 × 6/1024 ≃ 6GB
1. Pengindeksan Dokumen
(Document Indexing )
Indexing (1 / 4)
• Bagaimana menghubungkan kebutuhan informasi pengguna dengan beberapa isi dokumen?
• Gagasan: menggunakan index untuk menunjuk ke dokumen
• Biasanya index adalah daftar term yang hadir dalam dokumen, dapat direpresentasikan secara matematis sebagai:
index : doci
{∪
jkeywordj }• Di sini, index memetakan keywords ke daftar dokumen yang muncul dalam:
index′ : keywordj
{∪
idoci}Indexing (2 / 4)
Contoh dari inverted index:
kw1 → doc1 doc2 doc3 kw2 → doc7 doc9 doc15 ...
• Himpunan kata kunci (keyword) biasanya disebut kamus (dictionary atau vocabulary).
• Pengenal dokumen yang hadir dalam daftar yang diasosiasikan dengan suatu keyword disebut posting.
• Daftar pengenal dokumen yang diasosiasikan dengan suatu keyword yang diberikan disebut daftar posting (posting list).
Indexing (3 / 4)
• Pertanyaan yang hadir: Bagaimana membangun suatu index secara otomatis? Apa saja keyword yang relevan? (lebih lanjut nanti)
• Beberapa pertimbangan tambahan:
• Pemrosesan cepat dari koleksi besar dokumen,
• Operasi pencocokan harus fleksibel (robust retrieval),
• Harus mampu meranking dokumen yang diretrieve sesuai dengan relevansinya.
• Untuk memastikan requirement ini (khususnya pemrosesan cepat) terpenuhi, index itu digunakan komputasi selanjutnya.
Catat bahwa format dari index berpengaruh besar pada kinerja sistem.
Indexing (4 / 4)
NB: Suatu index dibangun dalam 4 tahapan:
1. Pengumpulan koleksi (setiap dokumen diberikan pengenal unik). 2. Segmentasi dari setiap dokumen ke dalam suatu daftar (list) berisi
token-token atomik (diacu sebagai operasi tokenisasi).
3. Pemrosesan linguistik token-token dalam rangka menormalkannya (misal: lemmatisasi).
4. Mengindeks dokumen-dokumen dengan menghitung kamus dan daftar postingnya.
Model Boolean: Pembangunan Index (1 / 4)
• → Model pertama teknik IR untuk membangun suatu index dan menerapkan query terhadap index ini.
• Contoh koleksi input (Sandiwara Shakespeare):
Doc1
I did enact Julius Caesar: I was killed i’ the Capitol; Brutus killed me.
Doc2
So let it be with Caesar. The
noble Brutus hath told you Caesar was ambitious
Model Boolean: Pembangunan Index (2 / 4)
• Pertama, dibangun daftar pasangan (keyword, docID)):
Model Boolean: Pembangunan Index (3 / 4)
• Kemudian daftar itu diurutkan berdasarkan keyword, ditambahkan informasi frekuensi :
Model Boolean: Pembangunan Index (4 / 4)
• Banyak kemunculan keyword kemudian digabung untuk membuat file kamus dan posting:
Pemrosesan Query Boolean
• Query menggunakan konektor logika seperti AND dan OR (NO lebih rumit).
• Perhatikan contoh yang mengandung (Brutus) AND mengandung (Capitol)
1. Cari keyword Brutus di dalam kamus
→ retrieve posting-nya
2. Cari keyword Capitol dalam kamus
→ retrieve posting-nya.
3. Gabungkan dua daftar posting tersebut mengikuti docID-nya
Pemrosesan Query Boolean (lanj.)
Algoritma penggabungan (Merging, dari [Manning et al., 07]):
1. merge(post1, post2) 2. answer <- []
3. while (post1 != [] AND post2 != []) 4. if (docID(post1) == docID(post2)) 5. then add(answer, docID(post1)) 6. post1 <- next(post1)
7. post2 <- next(post2) 8. Else
9. if (docID(post1) < docID(post2)) 10. then post1 <- next(post1)
11. else post2 <- next(post2) 12. Endif
13. Endif 14. Endwhile
15. return answer
Query Boolean Diperluas
• Generalisasi dari proses penggabungan:
• Bayangkan lebih dari 2 keyword hadir dalam query, misal:
• (Brutus AND Caesar) AND NOT (Capitol) • Brutus AND Caesar AND Capitol
• (Brutus OR Caesar) AND (Capitol) • ...
• Gagasan: perhatikan keyword dengan daftar posting lebih pendek lebih dahulu (untuk mengurangi jumlah operasi).
Query Boolean Diperluas (lanj.)
• Algoritma gabungan umum (dari [Manning et al, 07]):
1. genMerge([t1 .. tn]) 2. terms <- sortByFreq([t1 .. tn]) 3. answer <- postings(head(terms)) 4. terms <- tail(terms) 5. Do 6. list <- postings(head(terms)) 7. terms <- tail(terms)
8. answer <- merge(answer, list)
9. while (terms != []) AND (answer != []) 10. Endwhile
Pemrosesan Query Lebih Cepat (1 / 2)
• Pertanyaan: bagaimana meningkatkan penggabungan list ini? • Gagasan: mengatur skip pointer antara ID-ID dokumen
• Pointer demikian merupakan suatu link ke suatu ID dokumen yang diletakkan selanjutnya dalam daftar posting
• Saat 2 daftar digabungkan, pointer-pointer ini memungkinkan melompati beberapa sub-daftar
Pemrosesan Query Lebih Cepat (2 / 2)
• Pertanyaan: dimana meletakkan skip pointers ?
a) Banyak skip pointers → banyak perbandingan dikerjakan tetapi lebih mungkin melompati sub-daftar (kecil).
b) Sedikit skip pointers → sedikit perbandingan, tetapi kurang kemungkinan melompati sub-daftar (besar).
• Heuristik tepat: untuk suatu daftar posting berukuran L, gunakan √L evenly-spaced skip pointers
• NB: dengan arsitektur hardware modern, biaya loading daftar besar lebih besar daripada mendapatkan daftar gabungan dengan melewati beberapa sub-daftar.
Keterangan Mengenai Model Boolean
• Model boolean memungkinkan untuk mengekspresikan query dengan tepat (kit atahu apa yang kita dapatkan, TETAPI tidak fleksibel
→ kecocokan tepat)
• Query boolean dapat diproes secera efisien (kompleksitas waktu dari algoritma gabungan adalah linier dalam jumlah panjang dari datar yang akan digabungkan)
Menilai Pemrolehan Kembali
• Apakah sistem menemukan kembali (retrieve) informasi yang dicari? • Evaluasi efisiensi dari sistem
• Untuk contoh, menggunakan himpunan data referensi, mengandung corpus dan juga himpunan query sehingga kita tahu dokumen mana yang mengandung jawaban yang diharapkan
• maksudnya dokumen-dokumen telah diberikan tanda (yaitu +, 0, -) with respect to beberapa query
• Dalam konteks ini, sistem IR yang bagus me-retrieve dokumen yang “bagus” dan hanya dokumen yang “bagus”
Assessing the retrieval (continued)
• Let us consider a query q. Let us call Rq the set of retrieved texts, and R+q , the set of relevant texts for q in the corpus.
• A first interesting measure is the proportion of relevant texts in the retrieval:
• A second interesting measure is the proportion of relevant texts found with respect to all texts marked relevant for the given query:
Contoh
• Perhatikan dokumen berikut dan tandai untuk query “Henry”:
(1) Henry AG (-) (2) Thierry Henry - Arsenal FC (+) (3) Henry Miller - writer (-) (4) Hotel Henry (-) (5) Henry’s goal (+)
• Sistem 1: meretrieve dokumen (2) dan (4), recall? presisi?
Recall dan Presisi
• Recall and precision measures get their meaning with respect to a given context
Contoh:
• Seorang dokter yang sedang mencari deskripsi penyakit tertentu di web, dia ingin semua teks yang relevan, prioritasnya adalahrecall
• Seorang jurnalis mencari berita olah raga di web, dia sangat tertarik
mendapatkan hanya beberapa teks yang relevan saja, prioritasnya adalah presisi.
• NB: Kita dapat mencapai 100% recall dengan mengembalikan semua dokumen, tapi recall tak berguna tanpa presisi
• NB2: Ukuran lain yang menarik adalah f-measure:
Ringkasnya...
• Hari ini, kita telah mengenal:
• Notasi dasar dari IR dan terminologi penting, • Model konseptual dari sistem IR,
• Model boolean dari IR
• Pada beberapa kuliah selanjutnya, kita akan fokus pada:
1. Pembangunan indeks dari dokumen mentah 2. Pemadatan (compressing) indeks
3. Pemrosesan query tangguh (robust) 4. Model ruang vektor
• Pembahasan sesi praktis untuk implementasi teknik IR diadakan jika memungkinkan.
Tentang Kuliah ini
• Web page: http://husni.trunojoyo.ac.id
Berisi materi kuliah dan akan diupdate sesuai dengan kemajuan perkuliahan. • Evaluasi:
• Ujian Tengah Semester (UTS 30 %) : Take home • Ujian Akhir Semester (UAS, 40 %) : Take home
• Proyek Mesin Pencarian Mini (max. 2 orang, 30 %), deliverable: Laporan & Software
• Buku Teks Penting:
• Introduction to Information Retrieval. C. Manning, P. Raghavan and H. Schutze Cambridge University Press, 2008. URL: http://nlp.stanford.edu/IR-book/
• Search Engines: Information Retrieval in Practice (SEIRP). W. B. Croft, D. Metzler, and T. Strohman Cambridge University Press, 2009. URL: http://nlp.stanford.edu/IR-book/ • Information Retrieval: Implementing and Evaluating Search Engines. Stefan Buttcher,
Charlie Clarke, Gordon Cormack, MIT Press, 2010
• Foundations of Statistical Natural Language Processing. C. Manning and H Schutze MIT Press, 1999
Topik Bahasan
1. Pengantar Perkuliahan, sekilas IR 2. Pembangunan Indeks
3. Pemadatan Indeks 4. Temu-kembali Toleran 5. Model Ruang Vektor
6. Skema Pembobotan Lanjutan 7. Evaluasi Temu-Kembali Informasi
8. Umpan-Balik Relevansi dan Perluasan Query 9. Dasar-dasar Pencarian Web
10. Penghimpunan (Crawling) Web 11. Analisa Tautan (Link)
12. Dasar Klasifikasi Teks: KNN & Naive Bayes 13. Dasar Klasterisasi Teks: K-Mean & K-Medoid 14. Mengenal Sistem Rekomendasi
Tidak Mengikat, Dapat berubah sesuai kondisi!
Proyek: Membuat Search Engine Mini
Penerapan Konsep Temu-Kembali Informasi
Deadline: 01 Desember 2017 Inverted Index Crawler Halaman Tersimpan Statistika Situs & Halaman Internet Pembangkit Index
Pengurai Halaman Pembangkit Graf Web Graf Web
Analisa Tautan Pages Sisi Offline Sisi Online User Interface Caching
Indexing & Ranking
Query Ranking Halaman H al am an Ta ut an & An chor s Kata
No PHP for Offline Side Development!
Area Kerja Dalam IR
• Web Crawling: menghimpun data dari Web
• Data Extraction: mengambil informasi dan URL dari halaman web
• Preprocessing: menerapkan aturan bahasa untuk menyederhanakan proses IR
• Indexing: membuat index (pemetaan term ke dokumen)
• Penanganan Query: mendapatkan dokumen yang relevan dengan Query (kebutuhan informasi pengguna)
• Klasifikasi dan Klasterisasi
• Recommendation: memberikan dokumen yang sesuai dengan
kebutuhan/profil pengguna, berdasarkan kemiripan dokumen atau kemiripan pengguna
Latihan 1
Bagaimana kita memroses dua query berikut:
• Brutus AND NOT Caesar • Brutus OR NOT Caesar
Latihan 1
Bagaimana kita memroses dua query berikut: • Brutus AND NOT Caesar
• Brutus OR NOT Caesar Jawaban:
• Ambil daftar posting yang berkaitan dengan Brutus dan Caesar. • Pilih daftar yang lebih singkat, untuk setiap docID, jika daftar lain
mengandungnya, jangan simpan ia dalam daftar jawaban. • Algoritma gabungan baru...
Latihan 2
Berikan algoritma umum untuk pemrosesan query berikut: • (Brutus OR Caesar) AND (Capitol OR Julius)
Latihan 2
Berikan algoritma umum untuk pemrosesan query berikut: • (Brutus OR Caesar) AND (Capitol OR Julius)
Jawaban:
• Ambil frekuensi setiap keyword • Estimasikan ukuran setiap OR
Referensi
• C. Manning, P. Raghavan and H. Schutze, Introduction to Information Retrieval (chapter 1)
URL: http://nlp.stanford.edu/IR-book/pdf/chapter01-intro.pdf
• C.J. van Rijsbergen, Information Retrieval, Second Edition (introduction)
URL: http://www.dcs.gla.ac.uk/iain/keith/
• Searching through Shakespeare’s plays: