1
UJI CHI SQUARE oleh: Ade Heryana, SST, MKM
Prodi Kesehatan Masyarakat FIKES Univ. Esa Unggul Email: [email protected] atau [email protected]
1. PENDAHULUAN
Uji Chi-Square merupakan uji statistik non-parametrik yang paling banyak digunakan dalam penelitian bidang kesehatan masyarakat, karena uji ini memiliki kemampuan membandingkan dua kelompok atau lebih pada data-data yang telah dikategorisasikan. Meski demikian, uji chi-square dapat pula dipakai pada pengujian satu kelompok dan berskala interval/rasio. Secara ringkas kegunaaan uji chi-square disajikan pada gambar1 berikut.
Gambar 1. Kegunaan Uji Chi-Square 2. DISTRIBUSI CHI-SQUARE
Distribusi Chi-square (dibaca “khai square” atau khai kuadrat dengan simbol 2)1 adalah distribusi probabilitas teoritis yang asimetrik dan kontinyu. Nilai sebuah 2 selalu positif antara
1 Mahasiswa sering salah membuat notasi chi-square dengan tanda X2
Syarat data
Fungsi
Jumlah kelompok
.
Square (Uji Chi-2)Satu Kelompok Menguji varians populasi Numerik (interval/ rasio) Menguji kesesuaian distribusi Kategorik (nominal/ ordinal) Dua Kelompok Menguji perbedaan 2 kelompok Kategorik (nominal/ ordinal) Menguji hubungan 2 variabel atau lebih Kategorik (nominal/ ordinal)
2
0 sampai dengan (tak hingga) atau 0 ≤ 2 ≤ , tidak seperti distribusi normal atau distribusi t yang dapat bernilai negatif. Nilai statistik 2 dihitung dengan rumus sebagai berikut:
𝜒2=(𝑓0− 𝑓𝑒)
2
𝑓𝑒
dimana, 𝑓0 = banyaknya frekuensi yang diobservasi dan 𝑓𝑒 = banyaknya frekuensi yang diharapkan.
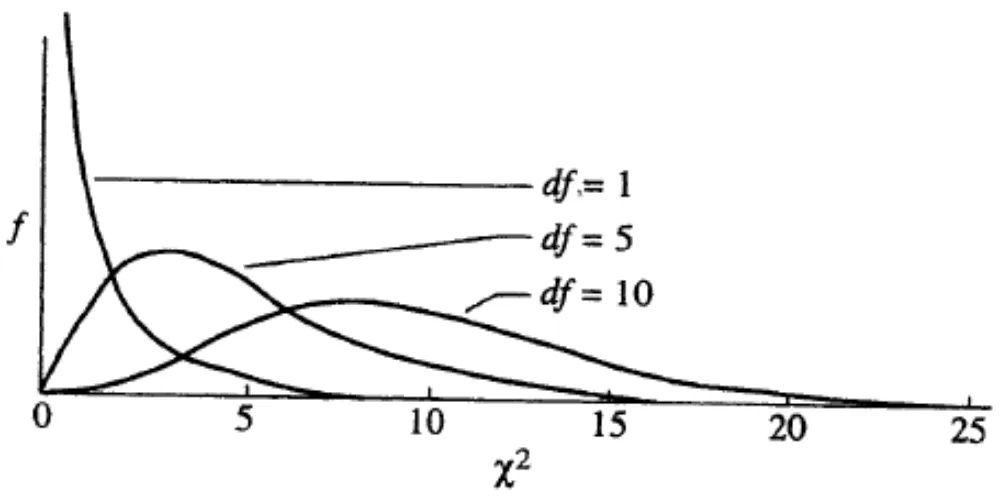
Gambar 1 menampilkan tiga jenis distribusi Chi-square dengan derajat kebebasan 1,5, dan 10. Tampak bahwa 1) semakin kecil derajat kebebasan, kemencengan kurva distribusi semakin positif artinya proporsi nilai rendah pada distribusi lebih besar; dan 2) semakin besar derajat kebebasan, kurva distribusi semakin simetris.
Gambar 1. Distribusi Chi-square dengan Derajat Kebebasan (df) yang Berbeda-beda (1, 5, dan 10)
(sumber: Sheskin, 2004, hal. 185)
Uji Chi-Square dapat digunakan untuk menguji 1 sampel, 2 sampel independen, dan k sampel (lebih dari 2 sampel).
3. UJI CHI SQUARE 1 SAMPEL
Uji Chi Square 1 Sampel digunakan untuk mengetahui 1) Varians dari populasi (jika data berskala interval/rasio) dan 2) Kesesuaian dengan distribusi Chi-square atau goodness of fit (jika data berskala kategorik/nominal).
a. Menguji varians dari populasi pada data interval/rasio
Rumusan uji hipotesa yang dievaluasi adalah “Apakah sampel dengan n subyek berasal dari populasi yang memilki nilai varians yang sama?” atau “Apakah sampel dengan nilai
3
estimasi varians ṡ2 diturunkan dari populasi dengan nilai estimasi varians 2?”. Bila hasil uji statistik signifikan, maka dapat disimpulkan bahwa terdapat kemungkinan sample berasal dari populasi dengan nilai varians tertentu selain 2.
Asumsi yang digunakan dalam uji hipotesa ini adalah: a. Populasi berdistribusi normal; dan
b. Sampel dipilih secara acak dari populasi CONTOH SOAL
Sebuah brosur yang diterbitkan oleh perusahaan yang memproduksi battery alat bantu pendengaran, mengklaim bahwa rata-rata waktu hidup selama 7 jam ( = 7) dengan varians 5 jam (2 = 5). Seorang pelanggan menyatakan bahwa nilai varians yang tertulis pada brosur terlalu rendah. Untuk membuktikan anggapannya, pada bulan September pelanggan mencatat waktu hidup pada 10 battery (dalam jam) dengan data sebagai berikut: 5, 6, 4, 3, 11, 12, 9, 13, 6, 8. Apakah data tersebut menunjukkan varians waktu hidup battery memilki nilai tertentu selain 2 = 5?
Pemecahan soal
𝐻0 = 𝜎2= 5 (varians dari populasi sampel = 5)
𝐻𝑎= 𝜎2≠ 5 (varians dari populasi sampel < 5) Perhitungan uji statistik sebagai berikut:
Battery X X2 1 5 25 2 6 36 3 4 16 4 3 9 5 11 121 6 12 144 7 9 81 8 13 169 9 6 36 10 8 64 X = 77 X2 = 701 Varians sampel (ṡ2) adalah
ṡ2=∑ 𝑋 2−(∑ 𝑋)2 𝑛 𝑛 − 1 = 701 −(77)102 10 − 1 = 12,01
4 Nilai statistik uji chi-square (2)
2=(𝑛 − 1)ṡ 2
𝜎2 =
(10 − 1)(12,01)
5 = 21,62
Nilai 2 hitung = 21,62 diuji dengan tabel nilai distribusi Chi-square (terlampir) dengan derajat kebebasan (df) = n – 1. Karena uji hipotesa satu arah maka dengan = 0,05, maka Nilai 2 tabel (df = 9 dan = 0,05) yaitu 16,92.Hipotesa nol tidak ditolak jika nilai 2 hitung lebih kecil dari nilai 2 tabel. Nilai 2 hitung = 21,62 lebih besar dari nilai 2 tabel = 16,92 dengan demikian, hipotesa ditolak atau nilai varians waktu hidup battery memiliki nilai tertentu selain 2 = 5 atau anggapan pelanggan bahwa waktu hidup battery pada brosur terlalu rendah tidak terbukti secara statistik.
b. Menguji keseseuaian distribusi/goodness of fit pada data kategorik/nominal Uji hipotesa yang dievaluasi adalah “apakah populasi yang direpresentasikan dengan sampel, memiliki perbedaan frekuensi yang diobservasi dengan frekuensi yang diharapkan” atau “apakah terdapat perbedaan antara frekuensi yang diobserbasi dengan frekuensi yang diharapkan pada populasi yang diwakili dengan sampel tertentu”.
Pernyataan hipotesa tersebut dapat dijelaskan dengan model umum uji kesesuaian distribusi chi-square disajikan pada tabel 1.
Tabel 1. Model Umum dari Uji Kesesuaian Distribusi Chi-square
(Sumber: Sheskin, 2003, hal. 242)
Total Jumlah Observasi Sel/Kategori C1 C2 ... Ci ... Ck
Frekuensi Observasi O1 O2 - Oi - Ok n
Setiap n observasi (subyek atau obyek) pada percobaan di tabel dipilih secara acak dari populasi yang memiliki N observasi, dan dicatat sebagai salah satu dari k kategori yang mutual exclusive. Ci adalah sel/kategori ke-i dan Oi adalah frekuensi observasi ke-i. Jumlah total
observasi pada setiap sel disebut dengan n.
Asumsi yang diterapkan pada uji hipotesa ini adalah: a. Data berskala nominal/kategorik
b. Data terdiri dari n observasi independen yang dipilih secara acak dari populasi; dan c. Frekuensi diharapkan (fe) pada setiap sel tabel harus ≥ 5
5 CONTOH SOAL
Seorang pustakawan bermaksud mengetahui kemungkinan seseorang meminjam buku (bukan hanya membaca) pada jam buka perpustakaan (senin sampai sabtu). Pada hari minggu perpustakaan tutup. Untuk itu ia mencatat jumlah buku yang dipinjam selama 1 minggu dan diperoleh data sebagai berikut: Senin = 20 buku, Selasa = 14, Rabu = 18, Kamis = 17, Jumat = 22, dan Sabtu = 29. Diasumsikan setiap orang hanya boleh meminjam maksimal 1 buku selama 1 minggu. Apakah terdapat perbedaan jumlah buku yang dipinjam tiap hari dalam seminggu?
Pembahasan soal
Bila i adalah frekuensi observasi populasi pada sel ke-i dan i adalah frekuensi ekspektasi populasi pada sel ke-i, maka pada i adalah frekuensi observasi sampel pada sel ke-i dan i adalah frekuensi ekspektasi sampel pada sel ke-i, sehingga hipotesa dirumuskan sebagai berikut:
𝐻0: 𝜊𝑖 = 𝜀𝑖 (tidak terdapat perbedaan jumlah buku yang dipinjam tiap hari dalam seminggu)
𝐻𝑎: 𝜊𝑖 ≠ 𝜀𝑖 (terdapat perbedaan jumlah buku yang dipinjam tiap hari dalam seminggu).
Perhitungan nilai statistik 2 sebagai berikut:
𝜒2= ∑ [(Ο𝑖− Ε𝑖) 2 Ε𝑖 ] 𝑘 𝑖=1 𝚶𝒊 𝒊 (𝚶𝒊− 𝚬𝒊) (𝚶𝒊− 𝚬𝒊)𝟐 (𝚶𝒊− 𝚬𝒊)𝟐 𝚬𝒊 Senin 20 20 0 0 0 Selasa 14 20 -6 36 1,80 Rabu 18 20 -2 4 0,20 Kamis 17 20 -3 9 0,45 Jumat 22 20 2 4 0,20 Sabtu 29 20 9 81 4,05 120 120 0 𝜒2= 6,70
Hasil 2 hitung selanjutnya dibandingkan dengan tabel 2 tabel dengan derajat kebebasan 𝑑𝑓 = 𝑘 − 1. Berdasarkan tabel, nilai dengan derajat
kebebasan 𝑑𝑓 = 6 − 1 = 5 adalah 11,07. Nilai 2 hitung =6,70 < 11,07
sehingga hipotesa nol gagal ditolak, atau tidak terdapat perbedaan jumlah buku yang dipinjam tiap hari dalam seminggu.
4. UJI CHI SQUARE 2 KELOMPOK a. Tabel Kontinjensi b x k
Penggunaan lain dari Uji Chi-Square adalah pengujian hipotesis pada 2 kelompok menggunakan tabel kontinjensi 2 x 2 atau tabel b x k tertentu, dimana b adalah baris dan k
6
adalah kolom. Dalam hal ini, jumlah sel adalah k dikalikan b, sehingga untuk tabel 2 x 2 jumlah selnya adalah 4, tabel 2 x 3 jumlah selnya adalah 6, dan seterusnya. Data-data yang terdapat pada sel disebut dengan jumlah/frekuensi observasi dari subyek atau obyek. Contoh tabel kontinjensi b x k disajikan pada tabel 2.
Tabel 2 di atas menunjukkan contoh tabel kontinjensi b x k dengan baris ke-1, ke-2, sampai dengan dengan baris ke-n dan kolom ke-1, ke-2, sampai dengan kolom ke-n. Sehingga pada tabel 2 x 2 terdapat baris ke-1 dan ke-2 dan kolom ke-1 dan ke-2, lalu pada tabel 2 x 3 terdapat baris ke-1 dan ke-2 dan kolom ke-1, ke-2, dan ke-n, dan seterusnya. Jumlah frekuensi observasi pada baris ke-n dan kolom ke-n ditunjukkan dengan pada sel bnkn sehingga jumlah
frekuensi observasi pada baris ke-1 dan kolom ke-1 berada pada sel b1k1 lalu jumlah frekuensi
observasi pada baris ke-1 dan kolom ke-2 berada pada sel b1k2 dan seterusnya.
Tabel 2. Tabel Kontinjensi b x k
Kolom (k)
Kolom 1 Kolom 2 .... Kolom n Baris (b)
Baris 1 b1k1 b1k2 ... b1kn
Baris 2 b2k1 b2k2 ... b2kn
... ... ... ... ...
Baris n bnk1 bnk2 ... bnkn
Baris dan Kolom pada tabel kontinjensi dapat mewakili “kategori” dari data yang yang dipelajari sebagai representasi dari kelompok, sehingga tabel ini dapat dipakai pada berbagai contoh persoalan sebagai berikut:
1. Untuk mengetahui apakah terdapat perbedaan antara dua perlakuan/intervensi. Contohnya kejadian hipertensi pada dua kelompok2 “Sesudah Senam” dan “Sebelum Senam”, maka kelompok “Sesudah Senam” dapat diwakilkan dengan Baris dan kelompok “Sebelum Senam” diwakilkan dengan Kolom (lihat tabel 3). Pada tabel tersebut, jumlah observasi kejadian “hipertensi” pada kelompok “Sesudah Senam” dan kelompok “Sebelum Senam” adalah 10, jumlah observasi kejadian “tidak hipertensi” pada kelompok “Sesudah Senam” dan kelompok “Sebelum Senam” adalah 42, dan seterusnya.
2 Pengertian kelompok di sini adalah jenis intervensi/perlakukan sebelum dan sesudah (pre and post
7
Tabel 3. Contoh Aplikasi Tabel Kontinjensi b x k untuk Membandingkan Dua Kelompok Sebelum dan Sudah Intervensi
Kelompok “Sesudah Senam” Hipertensi Tidak Hipertensi Kelompok
“Sebelum Senam”
Hipertensi 10 54
Tidak Hipertensi 42 34
2. Untuk mengetahui apakah terdapat perbedaan kejadian pada kelompok Kasus dan kelompok Kontrol (pada desain studi Case-Control) sebagaimana disajikan pada tabel 4 menampilkan contoh kejadian Hipertensi dan Tidak Hipertensi pada kelompok Kasus dan kelompok Kontrol.
Tabel 4. Contoh Aplikasi Tabel Kontinjensi b x k untuk Membandingkan Dua Kelompok Kasus dan Kontrol
Kelompok “Kasus”
Hipertensi Tidak Hipertensi Kelompok “Kontrol” Hipertensi Tidak Hipertensi 10 54
42 34
3. Untuk mengetahui adanya hubungan/korelasi antara dua variabel atau lebih. Misalnya mengetahui hubungan antara kejadian hipertensi dengan usia (tabel 5) atau mengetahui hubungan antara kejadian hipertensi dengan Indeks Massa Tubuh/IMT pada tabel 4 x 2 (tabel 6) dan pada tabel 2 x 3 (tabel 7)3.
Tabel 5. Contoh Aplikasi Tabel Kontinjensi b x k untuk Mengetahui Hubungan antara Variabel Kejadian Hipertensi dengan Variabel Usia
Kejadian Hipertensi Positif Negatif
Usia > 45 tahun 10 54
≤ 45 tahun 42 34
Tabel 6. Contoh Aplikasi Tabel Kontinjensi b x k untuk Mengetahui Hubungan antara Variabel Kejadian Hipertensi dengan Variabel Indeks Massa Tubuh
Kejadian Hipertensi Positif Negatif IMT Obesitas 10 54 Overweight 34 7 Normal 42 34 Underweight 5 9
3 Pada contoh aplikasi tabel kontinjensi untuk mengetahui korelasi antara 2 variabel atau lebih, terdapat kesepakatan sebagai berikut: 1) variabel dependen disajikan sebagai Kolom dan variabel independen sebagai Baris; dan 2) Urutan baris dan kolom menunjukkan tingkat kemungkinan risiko, misalnya jika usia > 45 tahun memiliki risiko paling tinggi terhadap hipertensi maka sebagai Baris ke-1 adalah kejadian hipertensi positif dan Kolom ke-1 adalah usia > 45 tahun.
8
Tabel 7. Contoh Aplikasi Tabel Kontinjensi b x k untuk Mengetahui Hubungan antara Variabel Kejadian Hipertensi dengan Variabel Usia
Kejadian Hipertensi
Hipertensi Prehipertensi Normal
IMT Obesitas 10 23 54
Tidak Obesitas 42 6 34
b. Penggunaan Uji Chi-Square 2 Kelompok
Sebelum membahas kegunaan uji Chi-Square 2 Kelompok, terlebih dahulu perlu diketahui asumsi-asumsi yang dipakai, antara lain:
Data berskala ordinal/nominal dengan kategori data bersifat mutually exclusive
Data dipilih secara acak/random dari populasi yang ditentukan
Jumlah frekuensi observasi setiap sel pada tabel kontinjensi lebih besar atau sama dengan 5. Jika terdapat sel yang < 5 maka distribusi chi-square tidak akurat menghasilkan estimasi yang menggambarkan keadaan populasi. Untuk mengatasi hal ini, peneliti bisa menggabungkan sel yang jumlahnya < 5 agar tercapai syarat tersebut. Bila tabel 2 x 2 tetap menghasilkan sel dengan jumlah < 5, maka disarankan menggunakan uji distribusi hipergeometrik yaitu Uji Fisher-Exact.
Sebenarnya uji ini merupakan perluasan dari uji chi-square goodness of fit pada satu sampel, dengan penggunaannya meliputi dua jenis4 yaitu:
1. Uji Homogenitas
Uji homogenitas dilakukan ketika sampel independen yang terdiri dari dua atau lebih kelompok sampel (sebagai baris dalam tabel kontinjensi) dikategorisasikan ke dalam satu dimensi yang terdiri dari dua atau lebih sub kategori (sebagai kolom dalam tabel kontinjensi). Dengan demikian uji homogenitas digunakan untuk mengetahui homogenitas sampel berdasarkan proporsi kategorisasi menurut dimensinya. Bila data homogen maka proporsi observasi pada dimensi yang ditetapkan akan sama pada seluuruh kelompok sampel.
4 Kedua jenis uji ini menggunakan tabel kontinjensi b x k tabel sebagai alat untuk memperhitungkan nilai statistik 2
9
Asumsi yang digunakan pada uji homogenitas adalah: 1) seluruh data dipilih secara acak dari populasi tertentu; dan 2) jumlah kelompok pada variabel independen telah ditentukan terlebih dahulu oleh peneliti sebelum dilakukan pengumpulan data. 2. Uji Independensi
Uji independensi dilakukan ketika satu sampel dikategorisasikan ke dalam dua atau lebih dimensi atau variabel. Uji ini mengevaluasi hipotesa “apakah terdapat hubungan pada dua variabel atau apakah dua variabel tersebut saling independen?”. Dengan demikian, dua buah variabel yang saling independen tersebut tidak memiliki hubungan satu sama lain (zero correlation).
Asumsi yang digunakan pada uji independensi adalah 1) seluruh data dipilih secara acak dari populasi tertentu; dan 2) jumlah kategori untuk variabel pertama dan variabel kedua ditentukan oleh peneliti sebelum pengambilan data dilakukan.
c. Contoh Soal Uji Homogenitas5
Seorang peneliti sedang menyelidiki efek kebisingan terhadap perilaku altruistik6. Untuk itu dipilih secara acak 200 subyek untuk ditempatkan pada satu dari dua kelompok untuk menjalani eksperimen. Kedua kelompok tersebut diberikan tes kecerdasan semu selama satu jam. Kelompok pertama (yang terdiri dari 100 subyek) selama tes kecerdasan diberikan paparan suara berisik yang kontinyu agar terjadi kegagalan fungsi kognitif. Kelompok kedua (100 subyek lainnya) tidak diberikan paparan suara. Setelah menjalani tes kecerdasan, pada kedua kelompok ini “diumpan” kepeduliannya dengan meminta seseorang untuk berpura-pura menjadi orang yang tangannya sedang dibalut dan memohon subyek mengangkat barang-barang berat ke dalam mobilnya. Kemudian peneliti mencatat jumlah subyek yang ikut membantu orang tersebut mengangkat barang-barangnya. Hasilnya adalah 30 dari 100 subyek yang terpapar kebisingan ikut bantu menolong, sedangkan 60 dari 100 subyek yang tidak terpapar kebisingan ikut menolong. Apakah berdasarkan data tersebut, kebisingan mempengaruhi perilaku altruistik?
Pembahasan soal
Soal di atas merupakan contoh aplikasi Uji Homogenitas dengan Chi-Square, karena alasan sebagai berikut:
1. Pada kasus ini desain studi terdiri dari data kategorik dengan sampel indenpenden yang terbagi dalam satu dimensi (yaitu perilaku altruistik), atau dapat dikatakan bahwa perbedaan perlakukan/
5 Sumber: Sheskin, 2003, hal. 515
6 Perilaku altruistik adalah perilaku dan sikap yang mementingkan kepentingan orang lain dibanding dirinya sendiri
10
intervensi pada dua kelompok (terpapar kebisingan dan tidak terpapar kebisingan) merupakan variabel independen;
2. Peneliti telah menentukan terlebih dahulu 100 subyek yang akan diberikan perlakukan, hal ini sesuai dengan asumsi pada uji homogenitas yaitu jumlah kelompok pada variabel independen telah ditentukan terlebih dahulu oleh peneliti sebelum dilakukan pengumpulan data;
Sebagai variabel dependen pada soal di atas adalah perilaku altruistik yang terdiri dari dua ketegori yaitu “Menolong” dan “Tidak Menolong”. Sedangkan uji hipotesa yang akan dievaluasi adalah “apakah terdapat perbedaan antara dua intervensi/perlakuan” atau menguji hipotesa apakah terdapat hubungan antara intervensi kebisingan dengan perilaku altruistik, dan dirumuskan sebagai berikut:
𝐻0: 𝜊𝑖𝑗 = 𝜀𝑖𝑗 (tidak terdapat hubungan antara kebisingan dengan perilaku altruistik)
𝐻𝑎: 𝜊𝑖𝑗≠ 𝜀𝑖𝑗 (terdapat hubungan antara kebisingan dengan perilaku altruistik).
Tabel kontinjensi 2 x 2 untuk soal di atas adalah:
Perilaku Altruistik Menolong Tidak Menolong Jumlah Baris Paparan Terpapar kebisingan 30 70 100 Tidak terpapar kebisingan 60 40 100 Jumlah Kolom 90 110 200
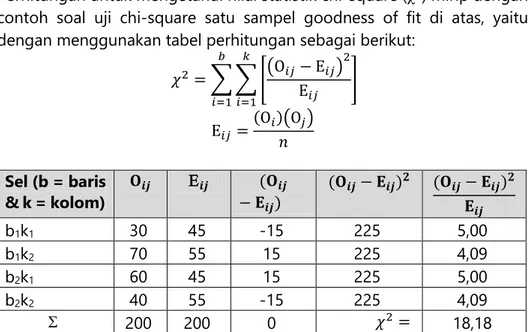
Perhitungan untuk mengetahui nilai statistik chi-square (2) mirip dengan contoh soal uji chi-square satu sampel goodness of fit di atas, yaitu dengan menggunakan tabel perhitungan sebagai berikut:
𝜒2= ∑ ∑ [(Ο𝑖𝑗− Ε𝑖𝑗) 2 Ε𝑖𝑗 ] 𝑘 𝑖=1 𝑏 𝑖=1 Ε𝑖𝑗 = (Ο𝑖)(Ο𝑗) 𝑛 Sel (b = baris & k = kolom) 𝚶𝒊𝒋 𝒊𝒋 (𝚶𝒊𝒋 − 𝚬𝒊𝒋) (𝚶𝒊𝒋− 𝚬𝒊𝒋)𝟐 (𝚶𝒊𝒋− 𝚬𝒊𝒋)𝟐 𝚬𝒊𝒋 b1k1 30 45 -15 225 5,00 b1k2 70 55 15 225 4,09 b2k1 60 45 15 225 5,00 b2k2 40 55 -15 225 4,09 200 200 0 𝜒2= 18,18
11 - untuk sel b1k1 = Ε𝑖𝑗=(Ο𝑖)(Ο𝑗) 𝑛 = (Ο1)(Ο1) 𝑛 = (100)(90) 200 = 45 - untuk sel b1k2 = Ε𝑖𝑗= (Ο𝑖)(Ο𝑗) 𝑛 = (Ο1)(Ο2) 𝑛 = (100)(110) 200 = 55 - untuk sel b2k1 = Ε𝑖𝑗=(Ο𝑖)(Ο𝑗) 𝑛 = (Ο2)(Ο1) 𝑛 = (100)(90) 200 = 45 - untuk sel b2k2 = Ε𝑖𝑗=(Ο𝑖)(Ο𝑗) 𝑛 = (Ο2)(Ο2) 𝑛 = (100)(110) 200 = 55
Kemudian hasil 𝜒2 hitung (18,18) dibandingkan dengan nilai 𝜒2 tabel
dengan derajat kebebasan 𝑑𝑓 = (𝑏 − 1)(𝑘 − 1) = (2 − 1)(2 − 1) = 1 dan
nilai =0,05 yaitu 3,84.
Karena hasil 𝜒2 hitung (18,18) lebih besar dibanding hasil 𝜒2 tabel (3,84) maka hipotesa nol ditolak, atau terdapat hubungan antara paparan kebisingan dengan perilaku altruistik.
d. Contoh Soal Uji Independensi7
Seorang peneliti ingin mengetahui apakah terdapat hubungan antara dimensi kepribadian introvert-extrovert dengan memilih jurusan Kesehatan Masyarakat pada mahasiswa yang mendaftar perguruan tinggi. Sebanyak 200 calon mahasiswa dipilih secara acak untuk ikut dalam studi ini. Seluruh subyek menjalani tes kepribadian yang hasilnya akan dikategorisasikan menjadi dua yaitu introvert atau extrovert. Setiap subyek kemudian ditanyakan jurusan perkuliahan yang dipilih apakah “Kesmas” dan “Non Kesmas”. Hasil pengumpulan data disajikan pada tabel 2x2 berikut:
Pemilihan Jurusan
Kesmas Non Kesmas Jumlah Baris
Kepribadian Introvert 30 70 100
Extrovert 60 40 100
Jumlah Kolom 90 110 200
Pembahasan soal
Soal di atas merupakan contoh aplikasi Uji Independensi dengan Chi-Square, karena alasan sebagai berikut:
1. Pada kasus ini desain studi terdiri dari satu sampel yang dikategorikan ke dalam dua dimensi; dan
2. Sampel yang terdiri dari 200 subyek dikategorikan ke dalam dua dimensi yang terdiri dari dua kategori yang mutually exclusive yaitu a) introvert dan extrovert; dan b) Kesmas dan Non-Kesmas
Sebagai variabel dependen pada soal di atas adalah pemilihan jurusan yang terdiri dari dua ketegori yaitu “Kesmas” dan “Non-Kesmas”, sedangkan sebagai variabel independen adalah jenis kepribadian yaitu “introvert” dan “extrovert”.
12
Uji hipotesa yang akan dievaluasi adalah “apakah antara pemilihan jurusan dengan kepribadian calon mahasiswa saling independen?” atau “Apakah terdapat hubungan antara pemilihan jurusan kuliah dengan jenis kepribadian?”, dan dirumuskan sebagai berikut:
𝐻0: 𝜊𝑖𝑗 = 𝜀𝑖𝑗 (tidak terdapat hubungan antara kepribadian dengan pemilihan jurusan kuliah)
𝐻𝑎: 𝜊𝑖𝑗≠ 𝜀𝑖𝑗 (tidak terdapat hubungan antara kepribadian dengan pemilihan jurusan kuliah).
Karena pada kasus ini, antara contoh soal uji homogenitas dan soal uji independensi sama-sama menggunakan tabel 2x2 dengan jumlah frekuensi selnya yang sama pula, maka perhitungan nilai chi-square sama dengan contoh soal homogenitas di atas, dengan kesimpulan terdapat hubungan antara kepribadian dengan pemilihan jurusan kuliah pada calon mahasiswa.
e. Cara Cepat Menghitung Nilai Chi-square (2) pada tabel 2x2
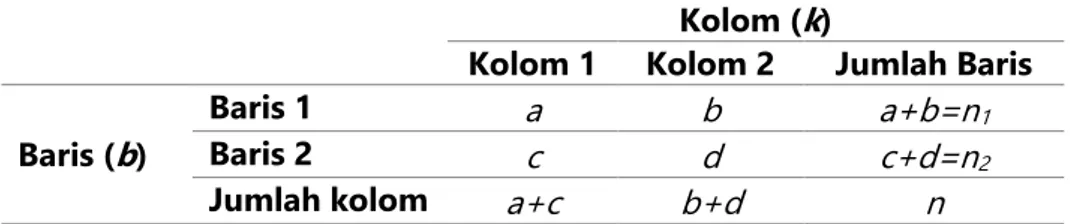
Cara cepat menghitung nilai statistik chi-square adalah dengan menggunakan notasi a,b,c,d untuk melambangkan jumlah frekuensi observasi pada masing-masing sel, sehingga tabel kontinjensi 2x2 sebagai berikut:
Tabel 8. Model Tabel Kontinjensi 2 x 2untuk Perhitungan Cepat
Kolom (k)
Kolom 1 Kolom 2 Jumlah Baris Baris (b)
Baris 1 a b a+b=n1
Baris 2 c d c+d=n2
Jumlah kolom a+c b+d n
Nilai statistik chi-square (2) dihitung dengan rumus sebagai berikut:
𝜒2= 𝑛(𝑎𝑑 − 𝑏𝑐)
2
(𝑎 + 𝑏)(𝑐 + 𝑑)(𝑎 + 𝑐)(𝑏 + 𝑑)
Sesuaid dengan contoh soal di atas, maka perhitungan nilai statistik chi-square (2) menggunakan cara cepat dengan rumus di atas adalah
𝜒2= 𝑛(𝑎𝑑 − 𝑏𝑐)
2
(𝑎 + 𝑏)(𝑐 + 𝑑)(𝑎 + 𝑐)(𝑏 + 𝑑)=
200[(30)(40) − (70)(60)]2
13
f. Mengukur Kekuatan Hubungan Variabel pada Uji Chi-Square dengan Odds Ratio (OR) dan Relative Risk (RR)
Kekuatan hubungan pada uji Chi-Square dengan menggunakan tabel kontinjensi, tergantung pada ukuran sampel dan proporsi pada masing-masing sel sehingga kekuatan hubungannya kurang akurat (terutama dibandingkan dengan t test). Pada uji t test, kekuatan hubungan tidak terpengaruh oleh ukuran sampel. Pengukuran kekuatan asosiasi/hubungan antar variabel pada tabel kontinjensi dapat dilakukan dengan berbagai metode, antara lain:
1. Koefisien Kontinjensi atau Koefisien Kontinjensi Pearson merupakan ukuran asosiasi yang dapat digunakan pada tabel kontinjensi dengan berbagai ukuran baris dan kolom
2. Koefisien Phi atau disingkat 𝜑 yang hanya dapat digunakan pada tabel kontinjensi
2 x 2 dengan data berskala nominal atau dikotomi
3. Koefisien Phi Cramer merupakan pengembangan dari Koefisien Phi untuk tabel kontinjensi lebih dari 2 x 2
4. Yule’s Q merupakan ukuran asosiasi untuk tabel kontinjensi 2x2 yang dapat digunakan pada tabel dengan data ordinal/berperingkat atau tidak berperingkat. Metode ini lebih jarang dipakai atau direkomendasikan dibanding Koefiesien Phi 5. Odds Ratio merupakan ukuran kekuatan/asosiasi yang bisa digunakan pada tabel
2x2 atau lebih dari 2x2 dan bukan merupakan fungsi dari chi-square (pada pengukuran asosiasi lainnya, kecuali Yule’s Q, menggunakan statistik 2 untuk menghitung kekuatan hubungan)
Pada artikel ini hanya akan dibahas ukuran asosiasi yang sering dipakai terutama pada penelitian epidemiologi dan kesehatan yaitu Odds Ratio (OR). Ukuran asosiasi lainnya yang sering digunakan dalam epidemiologi adalah Relative Risk (RR).
Kelebihan odds ratio dibandingkan ukuran asosiasi yang adalah 1) dapat digunakan pada berbagai format/bentuk angka; dan 2) dapat secara langsung menginterpretasikan hasil odds ratio dari tabel kontinjensi dibandingkan ukuran yang lain. Untuk memudahkan pembahasan, data tabel pada contoh soal uji independensi di atas disajikan kembali.
14
Pemilihan Jurusan
Kesmas Non Kesmas Jumlah Baris
Kepribadian Introvert 30 70 100
Extrovert 60 40 100
Jumlah Kolom 90 110 200
Konsep Relative Risk (RR) menunjukkan perbandingan probabilitas relatif dari variabel pemilihan jurusan, atau perbandingan antara probabilitas memilih jurusan Kesmas bila calon mahasiswa memiliki kepribadian introvert dengan probabilitas memilih jurusan Kesmas jika calon mahasiswa memiliki kepribadian extrovert. Berdasarkan data pada tabel di atas, probabilitas memilih jurusan Kesmas bila calon mahasiswa memiliki kepribadian introvert adalah 30/100 = 0,30 dan probabilitas memilih jurusan Kesmas bila calon mahasiswa memiliki kepribadian
extrovert adalah 60/100 = 0,60. Dengan menggunakan notasi sebagaimana
ditampilkan pada tabel 8, maka perhitungan di atas dapat ditulis dengan notasi matematis sebagai berikut:
𝑝(𝑀𝑒𝑚𝑖𝑙𝑖ℎ 𝐾𝑒𝑠𝑚𝑎𝑠 𝐾𝑒𝑝𝑟𝑖𝑏𝑎𝑑𝑖𝑎𝑛 𝐼𝑛𝑡𝑟𝑜𝑣𝑒𝑟𝑡⁄ ) = 𝑎 (𝑎 + 𝑏)⁄ 𝑝(𝑀𝑒𝑚𝑖𝑙𝑖ℎ 𝐾𝑒𝑠𝑚𝑎𝑠 𝐾𝑒𝑝𝑟𝑖𝑏𝑎𝑑𝑖𝑎𝑛 𝐸𝑥𝑡𝑟𝑜𝑣𝑒𝑟𝑡⁄ ) = 𝑐 (𝑐 + 𝑑)⁄
Sehingga Relative Risk nya adalah:
𝑅𝑅 = 𝑐 (𝑐 + 𝑑)⁄ 𝑎 (𝑎 + 𝑏)⁄ = 60 (60 + 40)⁄ 30 (30 + 70)⁄ = 2 atau 𝑅𝑅 = 𝑎𝑐 + 𝑏𝑐 𝑎𝑐 + 𝑎𝑑= (30)(60) + (70)(60) (30)(60) + (30)(40)= 2
Nilai RR = 2 berarti calon mahasiswa dengan kepribadian extrovert cenderung 2 kali lipat memilih Kesmas dibanding calon mahasiswa dengan kepribadian introvert.
Sekarang kita menghitung Odds Ratio. Namun sebelum menghitung, ada baiknya kita memahami konsep dari odds. Secara konseptual, odds merupakan suatu kejadian (event X) yang akan terjadi, yang dihitung dengan membagi probabilitas suatu kejadian X akan terjadi dengan probabilitas suatu kejadian X tidak akan terjadi, atau secara matematis ditulis dengan
𝑂𝑑𝑑𝑠(𝑋) = 𝑝(𝑋 𝑎𝑘𝑎𝑛 𝑡𝑒𝑟𝑗𝑎𝑑𝑖) 𝑝(𝑋 𝑡𝑖𝑑𝑎𝑘 𝑎𝑘𝑎𝑛 𝑡𝑒𝑟𝑗𝑎𝑑𝑖)
15 Nilai odds bervariasi sebagai berikut:
1. Hasil perhitungan atau nilai odds akan berada antara 0 hingga tak terhingga
2. Bila nilai odds > 1, maka probabilitas suatu kejadian X akan terjadi > 0,50 atau makin besar nilai odds maka semakin besar pula probabilitas suatu kejadian X akan terjadi
3. Bila nilai odds < 1, maka probabilitas suatu kejadian X akan terjadi < 0,50 atau makin kecil nilai odds maka semakin kecil pula probabilitas suatu kejadian X akan terjadi
4. Bila nilai odds = 1, maka probabilitas suatu kejadian X akan terjadi = 0,50 atau kesempatan atau peluang terjadinya kejadian X adalah 50:50
Berdasarkan data di atas, maka nilai odds untuk masing-masing kejadian adalah:
𝑂𝑑𝑑𝑠(𝐾𝑒𝑠𝑚𝑎𝑠 𝐸𝑥𝑡𝑟𝑜𝑣𝑒𝑟𝑡⁄ ) = 𝑝(𝐾𝑒𝑠𝑚𝑎𝑠 𝐸𝑥𝑡𝑟𝑜𝑣𝑒𝑟𝑡⁄ ) 𝑝(𝑁𝑜𝑛𝐾𝑒𝑠𝑚𝑎𝑠 𝐸𝑥𝑡𝑟𝑜𝑣𝑒𝑟𝑡⁄ )= 60 100⁄ 40 100⁄ = 1,500 𝑂𝑑𝑑𝑠(𝐾𝑒𝑠𝑚𝑎𝑠 𝐼𝑛𝑡𝑟𝑜𝑣𝑒𝑟𝑡⁄ ) = 𝑝(𝐾𝑒𝑠𝑚𝑎𝑠 𝐼𝑛𝑡𝑟𝑜𝑣𝑒𝑟𝑡⁄ ) 𝑝(𝑁𝑜𝑛𝐾𝑒𝑠𝑚𝑎𝑠 𝐼𝑛𝑡𝑟𝑜𝑣𝑒𝑟𝑡⁄ )= 30 100⁄ 70 100⁄ = 0,429
Dari hasil perhitungan di atas, karena odds calon mahasiswa dengan kepribadian extrovert memilih jurusan Kesmas > 1 (yaitu 1,500), maka probabilitas terjadinya hal tersebut adalah > 0,50. Demikian pula, odds calon mahasiswa dengan kepribadian introvert memilih jurusan Kesmas < 1 (yaitu 0,429), maka probabilitas terjadinya hal tersebut adalah < 0,50.
Odds ratio merupakan perbandingan antara kedua odds di atas berdasarkan tabel kontinjensi. Berdasarkan perhitungan di atas maka nilai Odds Ratio-nya adalah:
𝑂𝑅 =𝑂𝑑𝑑𝑠(𝐾𝑒𝑠𝑚𝑎𝑠 𝐸𝑥𝑡𝑟𝑜𝑣𝑒𝑟𝑡⁄ ) 𝑂𝑑𝑑𝑠(𝐾𝑒𝑠𝑚𝑎𝑠 𝐼𝑛𝑡𝑟𝑜𝑣𝑒𝑟𝑡⁄ ) =
1,500
0,429= 3,500
Artinya adalah kejadian seorang calon mahasiswa berkepribadian extrovert memilih jurusan Kesmas 3,5 kali lebih besar dibanding seorang mahasiswa berkepribadian introvert memilih jurusan Kesmas.
Rumus menghitung Odds Ratio dapat pula dinotasikan dalam bentuk huruf sebagaimana model pada tabel 8 di atas, yaitu:
𝑂𝑅 =𝑎𝑑 𝑏𝑐
Bila sebelumnya dibahas menghitung Odds Ratio dengan tabel 2x2, lalu bagaimana cara menghitung OR dengan tabel kontinjensi lebih besar dari 2x2 ? Menghitung OR dengan tabel kontinjensi di atas 2x2 memungkinkan dilakukan namun interpretasi hasilnya lebih kompleks. Misalnya data tabel 2x2 di atas diganti menjadi tabel 3x2 sebagai berikut:
16
Pemilihan Jurusan
Kesmas Non Kesmas Jumlah Baris
Kepribadian
Introvert 30 70 100
Moderate 50 50 100
Extrovert 80 20 100
Jumlah Kolom 160 140 300
Dari tabel di atas, maka odds untuk kejadian pemilihan jurusan kesmas adalah sebagai berikut:
𝑂𝑑𝑑𝑠(𝐾𝑒𝑠𝑚𝑎𝑠 𝐸𝑥𝑡𝑟𝑜𝑣𝑒𝑟𝑡⁄ ) = 𝑝(𝐾𝑒𝑠𝑚𝑎𝑠 𝐸𝑥𝑡𝑟𝑜𝑣𝑒𝑟𝑡⁄ ) 𝑝(𝑁𝑜𝑛𝐾𝑒𝑠𝑚𝑎𝑠 𝐸𝑥𝑡𝑟𝑜𝑣𝑒𝑟𝑡⁄ )= 80 100⁄ 20 100⁄ = 4,00 𝑂𝑑𝑑𝑠(𝐾𝑒𝑠𝑚𝑎𝑠 𝑀𝑜𝑑𝑒𝑟𝑎𝑡𝑒⁄ ) = 𝑝(𝐾𝑒𝑠𝑚𝑎𝑠 𝑀𝑜𝑑𝑒𝑟𝑎𝑡𝑒⁄ ) 𝑝(𝑁𝑜𝑛𝐾𝑒𝑠𝑚𝑎𝑠 𝑀𝑜𝑑𝑒𝑟𝑎𝑡𝑒⁄ )= 50 100⁄ 50 100⁄ = 1,00 𝑂𝑑𝑑𝑠(𝐾𝑒𝑠𝑚𝑎𝑠 𝐼𝑛𝑡𝑟𝑜𝑣𝑒𝑟𝑡⁄ ) = 𝑝(𝐾𝑒𝑠𝑚𝑎𝑠 𝐼𝑛𝑡𝑟𝑜𝑣𝑒𝑟𝑡⁄ ) 𝑝(𝑁𝑜𝑛𝐾𝑒𝑠𝑚𝑎𝑠 𝐼𝑛𝑡𝑟𝑜𝑣𝑒𝑟𝑡⁄ )= 30 100⁄ 70 100⁄ = 0,43
Dengan demikian terdapat beberapa nilai Odds Ratio yang dapat dihitung yaitu
𝑂𝑅1= 𝑂𝑑𝑑𝑠(𝐾𝑒𝑠𝑚𝑎𝑠 𝐸𝑥𝑡𝑟𝑜𝑣𝑒𝑟𝑡⁄ ) 𝑂𝑑𝑑𝑠(𝐾𝑒𝑠𝑚𝑎𝑠 𝐼𝑛𝑡𝑟𝑜𝑣𝑒𝑟𝑡⁄ ) = 4,00 0,43= 9,300 𝑂𝑅2= 𝑂𝑑𝑑𝑠(𝐾𝑒𝑠𝑚𝑎𝑠 𝐸𝑥𝑡𝑟𝑜𝑣𝑒𝑟𝑡⁄ ) 𝑂𝑑𝑑𝑠(𝐾𝑒𝑠𝑚𝑎𝑠 𝑀𝑜𝑑𝑒𝑟𝑎𝑡𝑒⁄ )= 4,00 1,00= 4,000 𝑂𝑅3= 𝑂𝑑𝑑𝑠(𝐾𝑒𝑠𝑚𝑎𝑠 𝑀𝑜𝑑𝑒𝑟𝑎𝑡𝑒⁄ ) 𝑂𝑑𝑑𝑠(𝐾𝑒𝑠𝑚𝑎𝑠 𝐼𝑛𝑡𝑟𝑜𝑣𝑒𝑟𝑡⁄ ) = 1,00 0,43= 2,330
OR1 = 9,300 berarti kejadian calon mahasiswa berkepribadian extrovert memilih jurusan Kesmas 9,3 kali lebih besar terjadi dibanding kejadian calon mahasiswa berkepribadian introvert memilih jurusan Kesmas.
OR2 = 4,000 berarti kejadian calon mahasiswa berkepribadian extrovert memilih jurusan Kesmas 4,0 kali lebih besar terjadi dibanding kejadian calon mahasiswa berkepribadian moderate memilih jurusan Kesmas.
OR3 = 2,330 berarti kejadian calon mahasiswa berkepribadian moderate memilih jurusan Kesmas 2,33 kali lebih besar terjadi dibanding kejadian calon mahasiswa berkepribadian introvert memilih jurusan Kesmas.
REFERENSI
Sheskin, David J. (2004). Handbook of Parametric and Nonparametric Statistical Procedures, edisi 3. DC: Chapman & Hall/CRC
17 LATIHAN SOAL8
1. Seorang peneliti membuat studi untuk mengevaluasi kemampuan memecahkan masalah antara pria dewasa dengan wanita dewasa. Pada studi ini 100 pria dewasa 80 wanita dewasa dipilih secara acak dari populasi. Setiap subyek diberikan permainan menyusun gambar (puzzles) untuk dipecahkan jawabannya. Sebagai variabel dependen adalah sanggup atau tidak sanggup dalam menjawab permainan. Enam puluh dari 100 subyek pria dewasa sanggup menjawab permainan, dan hanya 30 dari 80 subyek wanita dewasa yang sanggup.
Berdasarkan data-data tersebut di atas:
a. Ujilah hipotesa yang menyatakan “Terdapat perbedaan signifikan antara wanita dan pria dalam memecahkan atau menjawab permainan puzzle”
b. Hitung Relative Risk dan Odds Ratio
2. Sebuah lembaga survey sedang meneliti antusias masyarakat dengan Status Ekonomi Sosial (SES) Tinggi dan Rendah terhadap program imunisasi. Lima ratus orang dipilih secara acak dari populasi tertentu untuk diwawancara menggunakan kuesioner. Hasil pengumpulan data disajikan pada tabel berikut:
Sikap terhadap Imunisasi
Antusias Kurang Antusias Jumlah Baris Status Ekonomi Sosial (SES) Tinggi 120 170 290 Rendah 160 50 210 Jumlah Kolom 280 220 500
Berdasarkan data tersebut:
a. Ujilah hipotesa yang menyatakan “ada hubungan antara Status Sosial Ekonomi dengan Antusiasme terhadap imunisasi”
b. Hitunglah Relative Risk dan Odds Ratio.
3. Sebuah penelitian dilakukan untuk mengetahui jumlah kunjungan ke klinik perusahaan dalam setahun pada karyawan dengan masa kerja tertentu. Hal ini dilakukan sebagai upaya perusahaan tersebut dalam menilai efektifitas klinik perusahaan. Sebanyak 280 karyawan dipilih secara acak dari total 1500 karyawan di perusahaan tersebut. diwawancarai dengan kuesioner, dan hasil jawaban disajikan pada tabel berikut:
18 Jumlah Kunjungan/Tahun 0 1-5 > 5 Jumlah Baris Masa Kerja (tahun) 0 – 7 20 16 24 60 8 – 15 30 10 10 50 16 – 23 50 30 10 90 > 23 19 11 50 80 Jumlah Kolom 119 67 94 280
Berdasarkan data tersebut:
a. Ujilah hipotesa yang menyatakan “ada hubungan antara Masa Kerja dengan Kunjungan ke Klinik Perusahaan”
19
LAMPIRAN: Tabel Distribusi Chi-Square untuk nilai = 0,005 hingga 0,995 dan derajat kebebasan (df) 1 sampai dengan 100.
(Sumber: diunduh dari website Department of Statistics Eberly College of Science, Penn State University http://stat.psu.edu/)